LeNet5 神经网络的参数解析和图片尺寸解析
1.LeNet-5 神经网络
以下是针对 LeNet-5 神经网络的详细参数解析和图片尺寸变化分析,和原始论文设计,通过分步计算说明各层的张量变换过程。
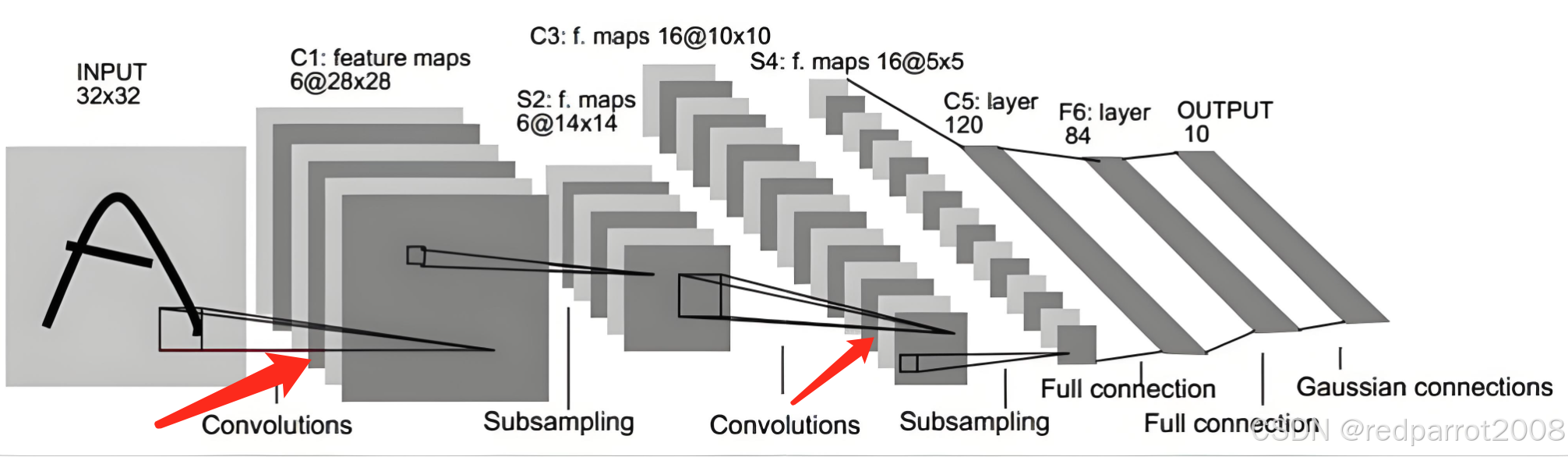
经典的 LeNet-5架构简化版(原始论文输入为 32x32,MNIST 常用 28x28 需调整)。完整结构如下:
-
网络结构:
输入 → Conv1 → 激活/池化 → Conv2 → 激活/池化 → 展平 → FC1 → FC2 → FC3 → 输出 -
适用场景:
经典的小型 CNN,适合处理低分辨率图像分类任务(如 MNIST、CIFAR-10)。
class LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5) # C1: 输入1通道,输出6通道,5x5卷积self.pool1 = nn.AvgPool2d(2, 2) # S2: 2x2平均池化self.conv2 = nn.Conv2d(6, 16, 5) # C3: 输入6,输出16,5x5卷积self.pool2 = nn.AvgPool2d(2, 2) # S4: 2x2平均池化self.fc1 = nn.Linear(16*5*5, 120) # C5: 全连接层self.fc2 = nn.Linear(120, 84) # F6: 全连接层self.fc3 = nn.Linear(84, 10) # 输出层def forward(self, x):x = F.relu(self.conv1(x)) # 卷积 + ReLU 激活x = F.max_pool2d(x, 2) # 2x2 最大池化x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(-1, 16*5*5) # 展平特征图x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x) # 输出层(通常不加激活函数)return x1.2. 定义卷积层
定义
输入通道是指输入数据中独立的“特征平面”数量。对于图像数据,通常对应颜色通道或上一层的特征图数量。
self.conv1 = nn.Conv2d(1, 6, 5) # 第一层卷积
self.conv2 = nn.Conv2d(6, 16, 5) # 第二层卷积nn.Conv2d 参数说明conv1:
输入通道数 1(适用于单通道灰度图,如 MNIST)。
输出通道数 6(即 6 个卷积核,提取 6 种特征)。
卷积核大小 5x5。conv2:
输入通道数 6(与 conv1 的输出一致)。
输出通道数 16(更深层的特征映射)。
卷积核大小 5x5。作用
通过卷积操作提取图像的空间特征(如边缘、纹理等),通道数的增加意味着学习更复杂的特征组合。每个输出通道由一组卷积核生成:
如果输出通道数为 6,则会有 6 个不同的卷积核(每个核的尺寸为 5x5,在单输入通道下),分别提取不同的特征。输出通道的维度:
输出数据的形状为 (batch_size, output_channels, height, width)。例如:
nn.Conv2d(3, 16, 5) # 输入通道=3(RGB),输出通道=16
该层会使用 16 个卷积核,每个核的尺寸为 5x5x3(因为输入有 3 通道)。每个核在输入数据上滑动计算,生成 1 个输出通道的特征图,最终得到 16 个特征图。1.3定义全连接层
self.fc1 = nn.Linear(16*5*5, 120) # 第一个全连接层
self.fc2 = nn.Linear(120, 84) # 第二个全连接层
self.fc3 = nn.Linear(84, 10) # 输出层nn.Linear 参数说明fc1:
输入维度 16*5*5(假设卷积后特征图尺寸为 5x5,共 16 个通道,展平后为 400 维)。
输出维度 120(隐藏层神经元数量)。fc2:
输入维度 120,输出维度 84(进一步压缩特征)。fc3:
输入维度 84,输出维度 10(对应 10 个分类类别,如数字 0~9)。作用
将卷积层提取的二维特征展平为一维向量,通过全连接层进行非线性变换,最终映射到分类结果。2. 参数解析(以输入 32x32 为例)
(1) 卷积层参数计算
-
公式:
参数量 =(kernel_height× kernel_width ×input_channels+ 1) ×output_channels
(+1为偏置项)
| 层名 | 参数定义 | 参数量计算 | 结果 |
|---|---|---|---|
| C1 | nn.Conv2d(1, 6, 5) | (5×5×1 + 1)×6 | 156 |
| C3 | nn.Conv2d(6, 16, 5) | (5×5×6 + 1)×16 | 2416 |
(2) 全连接层参数计算
-
公式:
参数量 =(input_features + 1) × output_features
| 层名 | 参数定义 | 参数量计算 | 结果 |
|---|---|---|---|
| C5 | nn.Linear(16*5*5, 120) | (400 + 1)×120 | 48120 |
| F6 | nn.Linear(120, 84) | (120 + 1)×84 | 10164 |
| 输出 | nn.Linear(84, 10) | (84 + 1)×10 | 850 |
总参数量:156 + 2416 + 48120 + 10164 + 850 = 61,706
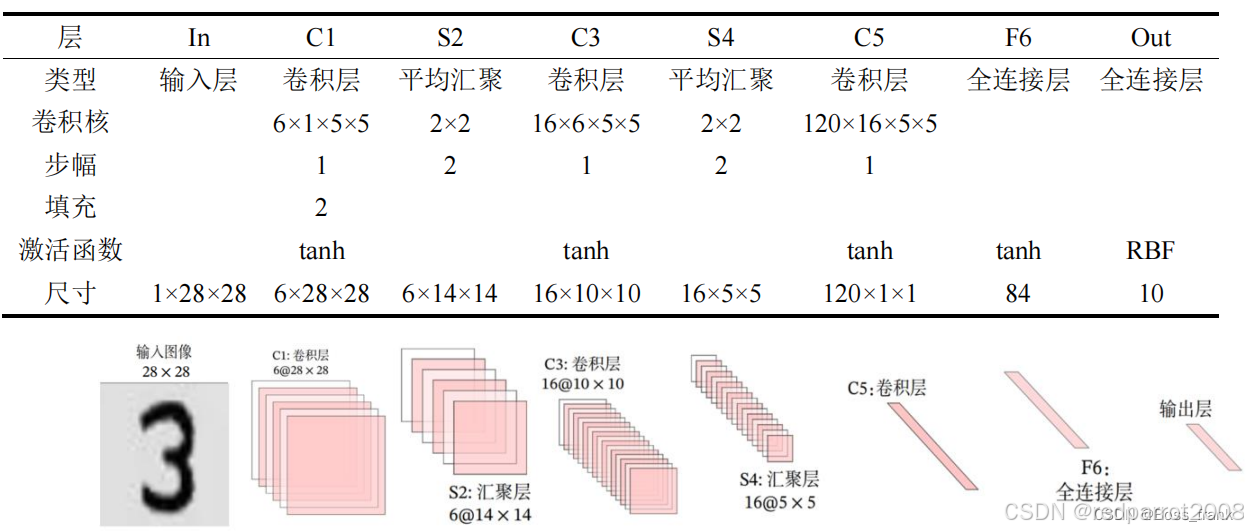
3. 图片尺寸解析(输入 32x32)
(1) 尺寸变化公式
-
卷积层:
H_out = floor((H_in + 2×padding - kernel_size) / stride + 1)
(默认stride=1,padding=0) -
池化层:
H_out = floor((H_in - kernel_size) / stride + 1)
(通常stride=kernel_size)
(2) 逐层尺寸变化
| 层名 | 操作类型 | 参数 | 输入尺寸 | 输出尺寸计算 | 结果 |
|---|---|---|---|---|---|
| 输入 | - | - | 1×32×32 | - | 1×32×32 |
| C1 | 卷积 | kernel=5, stride=1 | 1×32×32 | (32 - 5)/1 + 1 = 28 | 6×28×28 |
| S2 | 平均池化 | kernel=2, stride=2 | 6×28×28 | (28 - 2)/2 + 1 = 14 | 6×14×14 |
| C3 | 卷积 | kernel=5, stride=1 | 6×14×14 | (14 - 5)/1 + 1 = 10 | 16×10×10 |
| S4 | 平均池化 | kernel=2, stride=2 | 16×10×10 | (10 - 2)/2 + 1 = 5 | 16×5×5 |
| C5 | 展平+全连接 | - | 16×5×5 | 展平为 400 维向量 | 120 |
| F6 | 全连接 | - | 120 | - | 84 |
| 输出 | 全连接 | - | 84 | - | 10 |
(3) 关键问题解答
Q1: 为什么全连接层 fc1 的输入是 16*5*5?
-
经过两次卷积和池化后,特征图尺寸从
32x32→28x28→14x14→10x10→5x5,且最后一层有 16 个通道,因此展平后的维度为16×5×5=400。
Q2: 如果输入是 28x28(如 MNIST),尺寸会如何变化?
-
调整方式:
修改第一层卷积的padding=2(在四周补零),使输出尺寸满足(28+4-5)/1 +1=28(保持尺寸不变),后续计算与原始 LeNet-5 一致。self.conv1 = nn.Conv2d(1, 6, 5, padding=2) # 保持28x28Q3: 参数量主要集中在哪部分?
-
全连接层
C5占总数 78% (48120/61706),这是 LeNet-5 的设计瓶颈。现代 CNN 通常用全局平均池化(GAP)替代全连接层以减少参数。
5. 完整尺寸变换流程图(输入 32x32)
输入: 1×32×32 ↓ [C1] Conv2d(1,6,5)
6×28×28 ↓ [S2] AvgPool2d(2,2)
6×14×14 ↓ [C3] Conv2d(6,16,5)
16×10×10 ↓ [S4] AvgPool2d(2,2)
16×5×5 ↓ 展平
400 ↓ [C5] Linear(400,120)
120 ↓ [F6] Linear(120,84)
84 ↓ 输出
10使用下面代码,可以看到具体参数量:
# 遍历模型的所有子模块
for name, param in model.named_parameters():if param.requires_grad:print(f"Layer: {name}")if 'weight' in name:print(f"Weights:{param.data.shape}")if 'bias' in name:print(f"Bias:{param.data.shape}\n")
输出:
Layer: feature_extractor.0.weight
Weights:torch.Size([6, 1, 5, 5])
Layer: feature_extractor.0.bias
Bias:torch.Size([6])Layer: feature_extractor.2.weight
Weights:torch.Size([16, 6, 5, 5])
Layer: feature_extractor.2.bias
Bias:torch.Size([16])Layer: classifier.1.weight
Weights:torch.Size([120, 400])
Layer: classifier.1.bias
Bias:torch.Size([120])Layer: classifier.2.weight
Weights:torch.Size([84, 120])
Layer: classifier.2.bias
Bias:torch.Size([84])Layer: classifier.3.weight
Weights:torch.Size([10, 84])
Layer: classifier.3.bias
Bias:torch.Size([10])
写完文章,疑问终于搞明白了。大家也可以参考下面这个连接。
https://blog.csdn.net/lihuayong/article/details/145671336?fromshare=blogdetail&sharetype=blogdetail&sharerId=145671336&sharerefer=PC&sharesource=lihuayong&sharefrom=from_link