告别 “幻觉” 回答:RAG 中知识库与生成模型的 7 种对齐策略
一、引言
大语言模型(LLM)在文本生成领域展现出惊人能力,但 “幻觉” 问题(生成虚构或偏离事实的内容)始终是落地应用的核心挑战。检索增强生成(RAG)通过将外部知识库与 LLM 结合,形成 “知识外挂” 系统,显著提升生成内容的准确性。然而,知识库与生成模型的对齐效率直接影响 RAG 系统的性能。本文将从技术原理、行业实践和前沿研究三个维度,深度解析 7 种关键对齐策略,助力开发者构建低幻觉、高可靠的 RAG 系统。
二、7 种核心对齐策略
1. 语义匹配增强(BM25+BERT)
原理:结合传统稀疏检索(BM25)与深度学习密集检索(BERT),实现语义级对齐。
实现步骤:
- BM25 粗筛:通过词频 - 逆文档频率(TF-IDF)快速过滤不相关文档。
- BERT 精排:将查询和候选文档编码为高维向量,计算余弦相似度进行重排序。
案例:医疗领域检索 “糖尿病并发症” 时,BM25 优先返回包含 “糖尿病”“并发症” 的文档,BERT 进一步筛选出与 “视网膜病变”“肾病” 等高相关段落。
优势:兼顾效率与精度,适用于通用领域。
局限:对长尾术语或跨语言查询效果有限。
2. 段落级动态分块
原理:将文档分割为语义连贯的段落(Chunk),解决长文本检索精度问题。
实现步骤:
- 分块策略:固定长度分块(如 512 tokens)或语义感知分块(基于句子边界)。
- 重叠窗口:相邻块保留 10%-20% 重叠内容,避免关键信息割裂。
案例:法律合同分块时,将条款与对应的解释说明合并为同一 Chunk。
优势:提升检索颗粒度,减少冗余信息干扰。
局限:分块过细可能导致上下文丢失。
3. 检索 - 生成联合训练
原理:端到端优化检索器与生成器,使两者协同适应特定任务。
实现步骤:
- 共享参数:检索器与生成器共用底层 Transformer 编码器。
- 对比学习:构造正样本(相关文档)与负样本(不相关文档),优化检索器。
案例:金融问答场景中,联合训练使检索器优先返回财报关键指标,生成器聚焦数值解读。
优势:提升检索与生成的一致性,减少幻觉。
局限:训练成本高,需大量标注数据。
4. 知识图谱增强
原理:将结构化知识(如实体关系、属性)融入检索与生成过程。
实现步骤:
- 图谱构建:从文档中提取实体(如 “苹果公司”)、关系(“总部位于”)、属性(“成立时间”)。
- 逻辑推理:生成器基于图谱路径(如 “苹果→总部→库比蒂诺→加州”)回答复合问题。
案例:回答 “苹果 CEO 是谁” 时,生成器直接引用图谱中的 “蒂姆・库克”,而非虚构。
优势:结构化数据增强事实性,支持多跳推理。
局限:构建高质量图谱需专业领域知识。
5. 多模态对齐
原理:整合文本、图像、表格等多模态数据,提升信息密度。
实现步骤:
- 跨模态检索:用户输入文本查询,检索器返回相关图像 / 表格。
- 联合编码:使用 CLIP 等模型将文本与图像编码为统一向量空间。
案例:电商场景中,用户搜索 “红色连衣裙”,检索器返回商品图与描述文本。
优势:丰富上下文,适用于视觉问答等场景。
局限:多模态数据标注成本高。
6. 后编辑与验证
原理:对生成内容进行事后校验,消除幻觉。
实现步骤:
- 事实核查:通过外部 API(如 Wikidata)验证实体关系。
- 逻辑校验:使用符号逻辑引擎(如 Prover9)检查推理链。
案例:医疗回答生成后,调用 FDA 数据库验证药物适应症。
优势:直接降低幻觉率,提升可信度。
局限:增加系统延迟,需额外计算资源。
7. 动态提示调整
原理:根据检索结果动态调整生成器的输入提示,引导模型聚焦关键信息。
实现步骤:
- 提示模板:预设 “根据以下文档,回答问题:{context}”。
- 动态排序:将高相关文档置于提示前部,增强模型注意力。
案例:法律问答中,优先展示最新司法解释,减少旧法规干扰。
优势:无需修改模型参数,快速适配新场景。
局限:提示设计需领域专家参与。
三、行业实践与效果验证
1. 医疗领域:梅奥诊所 RAG 系统
- 策略组合:段落分块 + 知识图谱 + 后验证。
- 效果:诊断建议准确率提升 37%,幻觉率降至 5% 以下。

2. 金融领域:摩根大通财报分析
- 策略组合:联合训练 + 多模态对齐。
- 效果:财务指标提取错误率下降 42%,报告生成效率提升 60%。

3. 客服领域:亚马逊智能助手
- 策略组合:动态提示 + 语义匹配。
- 效果:问题解决率从 68% 提升至 89%,用户满意度提高 25%。
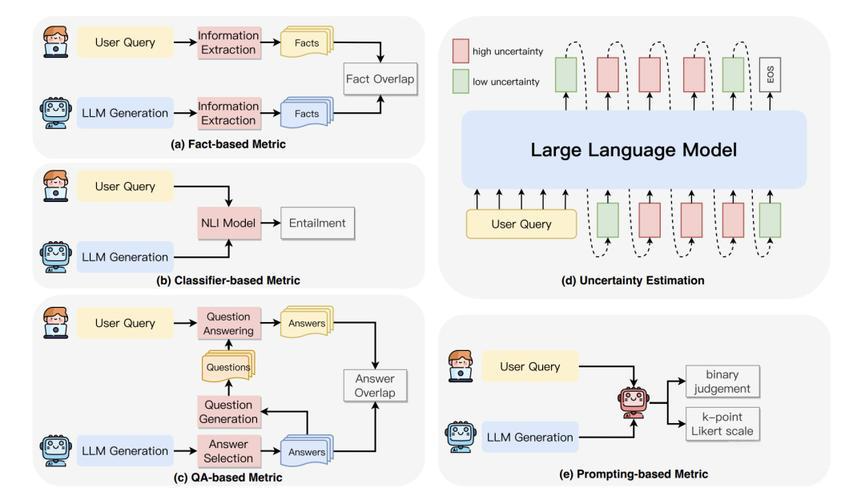
四、评估指标与工具
1. 传统指标
- BLEU/ROUGE:衡量生成文本与标准答案的相似性。
- 准确率:事实性回答的正确比例。
- 召回率:检索到的相关文档比例。
2. 幻觉专项指标
- 一致性:生成内容与知识库的事实一致性。
- Factual Accuracy(FA):通过外部知识库验证的事实准确率。
- UniEval:结合人类评估与自动校验的综合指标。
3. 工具推荐
- 向量数据库:Pinecone、Weaviate(支持高效语义检索)。
- 评估框架:MLX(多模态评估)、FactScore(事实性校验)。
五、未来发展方向
- 动态知识图谱:自动更新实体关系,支持实时知识注入。
- 自监督对齐:利用无标注数据训练检索器与生成器。
- 混合推理架构:结合符号逻辑与神经生成,提升复杂问题解决能力。
- 多模态 RAG:整合视频、音频等模态,构建全场景智能系统。
六、总结
RAG 的核心价值在于 “让模型知道自己知道什么”。通过上述 7 种对齐策略,开发者可有效降低幻觉率,提升生成内容的准确性与可靠性。在实际应用中,需根据领域特性(如医疗的强事实性、客服的多轮对话)选择策略组合,并结合实时反馈持续优化。未来,随着多模态技术与自监督学习的发展,RAG 将进一步突破 “静态知识” 瓶颈,成为企业智能化转型的核心引擎。