使用 AutoGen 与 Elasticsearch
作者:来自 Elastic Jeffrey Rengifo

学习如何使用 AutoGen 为你的 agent 创建一个 Elasticsearch 工具。
Elasticsearch 拥有与行业领先的生成式 AI 工具和提供商的原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic 向量数据库构建可投入生产的应用。
为了为你的使用场景构建最佳搜索解决方案,现在就开始免费云试用,或者在本地机器上试用 Elastic。
AutoGen 是微软的一个框架,用于构建可以与人类互动或自主行动的应用程序。它提供了一个完整的生态系统,具备不同层级的抽象,取决于你需要自定义的程度。
如果你想了解更多关于 agent 及其工作原理的内容,建议你阅读这篇文章。

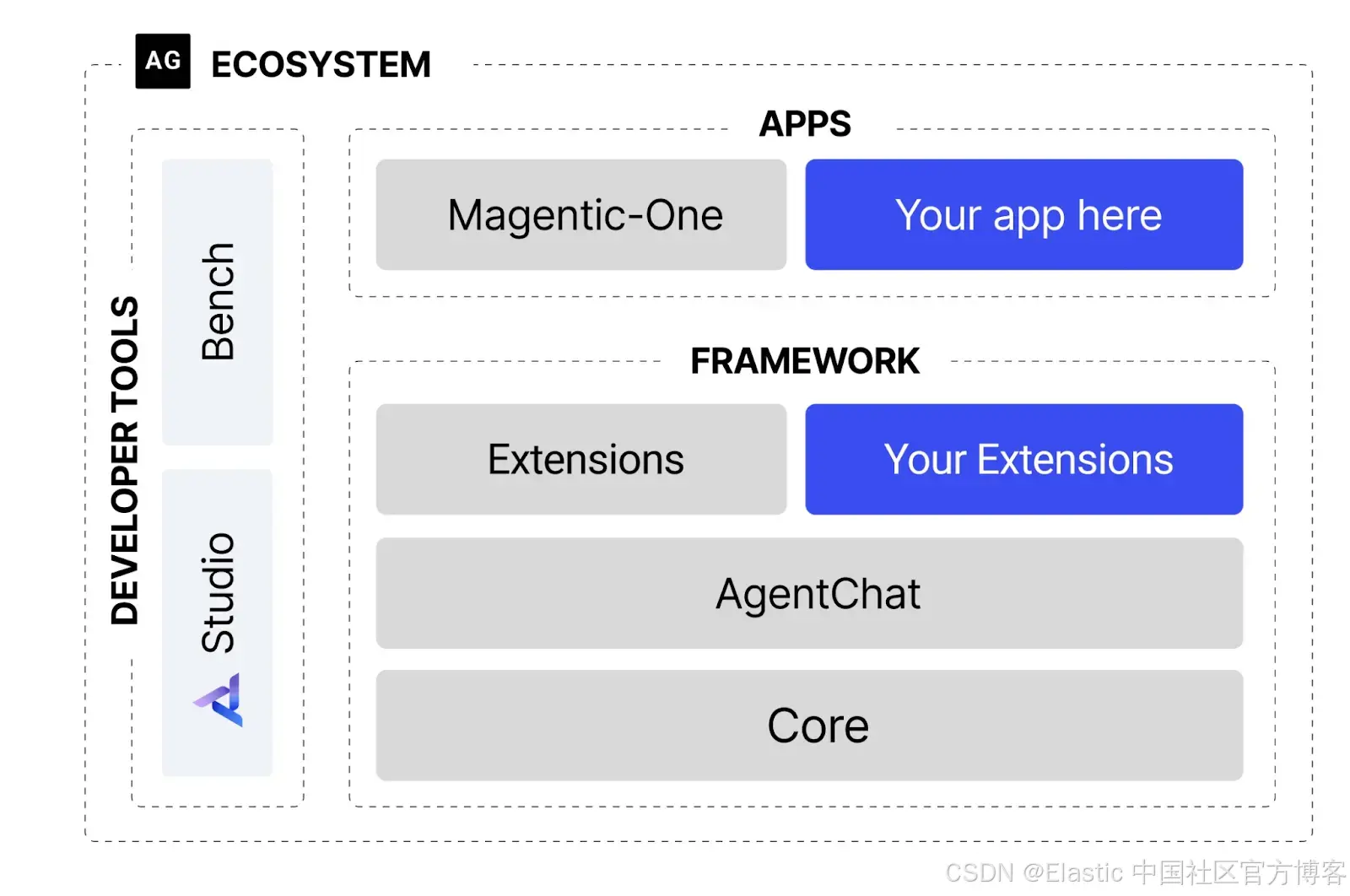
AgentChat 让你可以轻松地在 AutoGen 核心之上实例化预设的 agent,从而配置模型提示词、工具等内容。
在 AgentChat 之上,你可以使用扩展来增强其功能。这些扩展既包括官方库中的,也包括社区开发的。
最高层级的抽象是 Magnetic-One,这是一个为复杂任务设计的通用多 agent 系统,在介绍该方法的论文中已经预先配置好。
AutoGen 以促进 agent 之间的沟通而闻名,提出了具有突破性的交互模式,例如:
-
群聊 - group chat
-
多 agent 辩论
-
agent 混合
-
并发 agent
-
任务交接
在本文中,我们将创建一个使用 Elasticsearch 作为语义搜索工具的 agent,使其能够与其他 agent 协作,在 Elasticsearch 中存储的候选人简历与在线职位之间寻找最佳匹配。
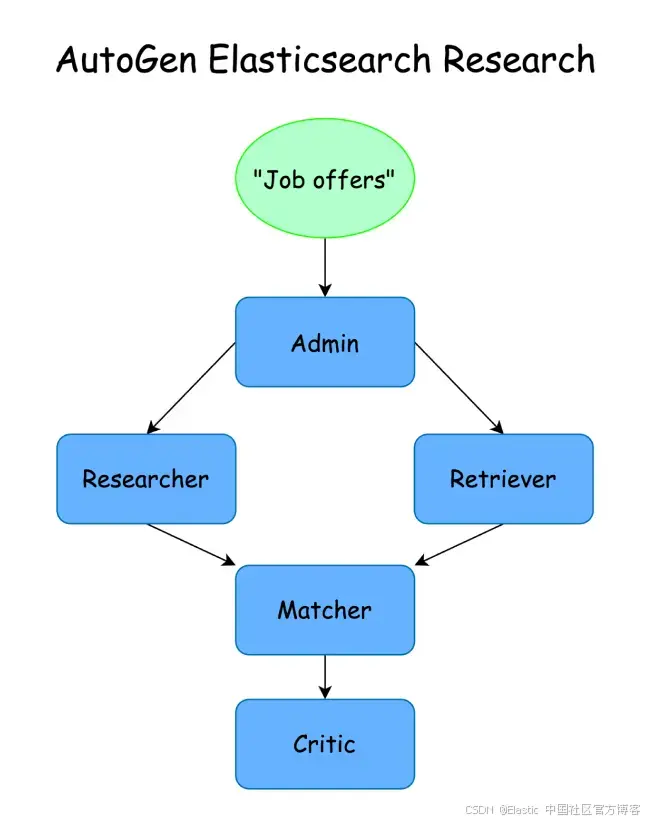
我们将创建一组共享 Elasticsearch 和在线信息的 agents,尝试将候选人与职位进行匹配。我们将使用 “Group Chat” 模式,其中一个管理员负责协调对话和执行任务,而每个 agent 专注于特定任务。
完整示例可在此 Notebook 中查看。
步骤:
-
安装依赖并导入包
-
准备数据
-
配置 agent
-
配置工具
-
执行任务
安装依赖并导入包
pip install autogen elasticsearch==8.17 nest-asyncioimport json
import os
import nest_asyncio
import requestsfrom getpass import getpass
from autogen import (AssistantAgent,GroupChat,GroupChatManager,UserProxyAgent,register_function,
)
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulknest_asyncio.apply()准备数据
设置密钥
对于 agent 的 AI 接口,我们需要提供一个 OpenAI API 密钥。我们还需要一个 Serper API 密钥,以赋予 agent 搜索能力。Serper 在注册时提供 2,500 次免费的搜索调用。我们使用 Serper 让 agent 具备访问互联网的能力,更具体来说,是获取 Google 搜索结果。agent 可以通过 API 发送搜索查询,Serper 会返回 Google 的前几条结果。
os.environ["SERPER_API_KEY"] = "serper-api-key"
os.environ["OPENAI_API_KEY"] = "openai-api-key"
os.environ["ELASTIC_ENDPOINT"] = "elastic-endpoint"
os.environ["ELASTIC_API_KEY"] = "elastic-api-key"Elasticsearch client
_client = Elasticsearch(os.environ["ELASTIC_ENDPOINT"],api_key=os.environ["ELASTIC_API_KEY"],
)推理端点与映射
为了启用语义搜索功能,我们需要使用 ELSER 创建一个推理端点。ELSER 允许我们运行语义或混合查询,因此我们可以向 agent 分配宽泛的任务,而无需输入文档中出现的关键字,Elasticsearch 就能返回语义相关的文档。
try:_client.options(request_timeout=60, max_retries=3, retry_on_timeout=True).inference.put(task_type="sparse_embedding",inference_id="jobs-candidates-inference",body={"service": "elasticsearch","service_settings": {"adaptive_allocations": {"enabled": True},"num_threads": 1,"model_id": ".elser_model_2",},},)print("Inference endpoint created successfully.")except Exception as e:print(f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }")映射
对于映射,我们将把所有相关的文本字段复制到 semantic_text 字段中,以便我们可以对数据执行语义或混合查询。
try:_client.indices.create(index="available-candidates",body={"mappings": {"properties": {"candidate_name": {"type": "text","copy_to": "semantic_field"},"position_title": {"type": "text","copy_to": "semantic_field"},"profile_description": {"type": "text","copy_to": "semantic_field"},"expected_salary": {"type": "text","copy_to": "semantic_field"},"skills": {"type": "keyword","copy_to": "semantic_field"},"semantic_field": {"type": "semantic_text","inference_id": "positions-inference"}}}})print("index created successfully")
except Exception as e:print(f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }")将文档导入 Elasticsearch
我们将加载关于求职者的数据,并要求我们的 agent 根据他们的经验和期望薪资找到最适合的职位。
documents = [{"candidate_name": "John","position_title": "Software Engineer","expected_salary": "$85,000 - $120,000","profile_description": "Experienced software engineer with expertise in backend development, cloud computing, and scalable system architecture.","skills": ["Python", "Java", "AWS", "Microservices", "Docker", "Kubernetes"]},{"candidate_name": "Emily","position_title": "Data Scientist","expected_salary": "$90,000 - $140,000","profile_description": "Data scientist with strong analytical skills and experience in machine learning and big data processing.","skills": ["Python", "SQL", "TensorFlow", "Pandas", "Hadoop", "Spark"]},{"candidate_name": "Michael","position_title": "DevOps Engineer","expected_salary": "$95,000 - $130,000","profile_description": "DevOps specialist focused on automation, CI/CD pipelines, and infrastructure as code.","skills": ["Terraform", "Ansible", "Jenkins", "Docker", "Kubernetes", "AWS"]},{"candidate_name": "Sarah","position_title": "Product Manager","expected_salary": "$110,000 - $150,000","profile_description": "Product manager with a technical background, skilled in agile methodologies and user-centered design.","skills": ["JIRA", "Agile", "Scrum", "A/B Testing", "SQL", "UX Research"]},{"candidate_name": "David","position_title": "UX/UI Designer","expected_salary": "$70,000 - $110,000","profile_description": "Creative UX/UI designer with experience in user research, wireframing, and interactive prototyping.","skills": ["Figma", "Adobe XD", "Sketch", "HTML", "CSS", "JavaScript"]},{"candidate_name": "Jessica","position_title": "Cybersecurity Analyst","expected_salary": "$100,000 - $140,000","profile_description": "Cybersecurity expert with experience in threat detection, penetration testing, and compliance.","skills": ["Python", "SIEM", "Penetration Testing", "Ethical Hacking", "Nmap", "Metasploit"]},{"candidate_name": "Robert","position_title": "Cloud Architect","expected_salary": "$120,000 - $180,000","profile_description": "Cloud architect specializing in designing secure and scalable cloud infrastructures.","skills": ["AWS", "Azure", "GCP", "Kubernetes", "Terraform", "CI/CD"]},{"candidate_name": "Sophia","position_title": "AI/ML Engineer","expected_salary": "$100,000 - $160,000","profile_description": "Machine learning engineer with experience in deep learning, NLP, and computer vision.","skills": ["Python", "PyTorch", "TensorFlow", "Scikit-Learn", "OpenCV", "NLP"]},{"candidate_name": "Daniel","position_title": "QA Engineer","expected_salary": "$60,000 - $100,000","profile_description": "Quality assurance engineer focused on automated testing, test-driven development, and software reliability.","skills": ["Selenium", "JUnit", "Cypress", "Postman", "Git", "CI/CD"]},{"candidate_name": "Emma","position_title": "Technical Support Specialist","expected_salary": "$50,000 - $85,000","profile_description": "Technical support specialist with expertise in troubleshooting, customer support, and IT infrastructure.","skills": ["Linux", "Windows Server", "Networking", "SQL", "Help Desk", "Scripting"]}
]def build_data():for doc in documents:yield {"_index": "available-candidates", "_source": doc}try:success, errors = bulk(_client, build_data())if errors:print("Errors during indexing:", errors)else:print(f"{success} documents indexed successfully")except Exception as e:print(f"Error: {str(e)}")配置 agent
AI 端点配置
让我们根据在第一步中定义的环境变量配置 AI 端点。
config_list = [{"model": "gpt-4o-mini", "api_key": os.environ["OPENAI_API_KEY"]}]
ai_endpoint_config = {"config_list": config_list}创建 agents
我们将首先创建管理员,负责主持对话并执行其他 agent 提出的任务。
然后,我们将创建执行每个任务的 agents:
-
管理员:领导对话并执行其他 agent 的行动。
-
研究员:在网上搜索职位信息。
-
检索员:在 Elastic 中查找候选人。
-
匹配员:尝试将职位和候选人进行匹配。
-
评审员:在提供最终答案之前,评估匹配的质量。
user_proxy = UserProxyAgent(name="Admin",system_message="""You are a human administrator.Your role is to interact with agents and tools to execute tasks efficiently.Execute tasks and agents in a logical order, ensuring that all agents performtheir duties correctly. All tasks must be approved by you before proceeding.""",human_input_mode="NEVER",code_execution_config=False,is_termination_msg=lambda msg: msg.get("content") is not Noneand "TERMINATE" in msg["content"],llm_config=ai_endpoint_config,
)researcher = AssistantAgent(name="Researcher",system_message="""You are a Researcher.Your role is to use the 'search_in_internet' tool to find individualjob offers realted to the candidates profiles. Each job offer must include a direct link to a specific position,not just a category or group of offers. Ensure that all job offers are relevant and accurate.""",llm_config=ai_endpoint_config,
)retriever = AssistantAgent(name="Retriever",llm_config=ai_endpoint_config,system_message="""You are a Retriever.Your task is to use the 'elasticsearch_hybrid_search' tool to retrievecandidate profiles from Elasticsearch.""",
)matcher = AssistantAgent(name="Matcher",system_message="""Your role is to match job offers with suitable candidates.The matches must be accurate and beneficial for both parties.Only match candidates with job offers that fit their qualifications.""",llm_config=ai_endpoint_config,
)critic = AssistantAgent(name="Critic",system_message="""You are the Critic.Your task is to verify the accuracy of job-candidate matches.If the matches are correct, inform the Admin and include the word 'TERMINATE' to end the process.""", # End conditionllm_config=ai_endpoint_config,
)配置工具
对于这个项目,我们需要创建两个工具:一个用于在 Elasticsearch 中搜索,另一个用于在线搜索。工具是一个 Python 函数,我们将在接下来注册并分配给 agent。
工具方法
async def elasticsearch_hybrid_search(question: str):"""Search in Elasticsearch using semantic search capabilities."""response = _client.search(index="available-candidates",body={"_source": {"includes": ["candidate_name","position_title","profile_description","expected_salary","skills",],},"size": 10,"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"match": {"position_title": question}}}},{"standard": {"query": {"semantic": {"field": "semantic_field","query": question,}}}},]}},},)hits = response["hits"]["hits"]if not hits:return ""result = json.dumps([hit["_source"] for hit in hits], indent=2)return resultasync def search_in_internet(query: str):"""Search in internet using Serper and retrieve results in json format"""url = "https://google.serper.dev/search"headers = {"X-API-KEY": os.environ["SERPER_API_KEY"],"Content-Type": "application/json",}payload = json.dumps({"q": query})response = requests.request("POST", url, headers=headers, data=payload)original_results = response.json()related_searches = original_results.get("relatedSearches", [])original_organics = original_results.get("organic", [])for search in related_searches:payload = json.dumps({"q": search.get("query")})response = requests.request("POST", url, headers=headers, data=payload)original_organics.extend(response.json().get("organic", []))return original_organics将工具分配给 agent
为了让工具正常工作,我们需要定义一个调用者,它将确定函数的参数,以及一个执行者,它将运行该函数。我们将定义管理员为执行者,并将相应的 agent 作为调用者。
register_function(elasticsearch_hybrid_search,caller=retriever,executor=user_proxy,name="elasticsearch_hybrid_search",description="A method retrieve information from Elasticsearch using semantic search capabilities",
)register_function(search_in_internet,caller=researcher,executor=user_proxy,name="search_in_internet",description="A method for search in internet",
)执行任务
我们现在将定义一个包含所有 agent 的群聊,其中管理员为每个 agent 分配轮次,指定它要调用的任务,并在根据先前的指令满足定义的条件后结束任务。
groupchat = GroupChat(agents=[user_proxy, researcher, retriever, matcher, critic],messages=[],max_round=50,
)manager = GroupChatManager(groupchat=groupchat, llm_config=ai_endpoint_config)user_proxy.initiate_chat(manager,message="""Compare the candidate profiles retrieved by the Retriever with the job offersfound by the Researcher on the internet.Both candidate profiles and job offers are related to the software industry.Ensure that each match is accurate and beneficial for both parties.Each candidate should be matched with a single job offer.Include the job offer link provided by the Researcher.""",
)推理
(格式化以提高可读性)
输出将如下所示:
Admin (to chat_manager):Compare the candidate profiles retrieved by the Retriever with the job offers found by the Researcher on the internet. Both candidate profiles and job offers are related to the software industry. Ensure that each match is accurate and beneficial for both parties. Each candidate should be matched with a single job offer. Include the job offer link provided by the Researcher.Admin (to chat_manager):Compare the candidate profiles retrieved by the Retriever with the job offers found by the Researcher on the internet. Both candidate profiles and job offers are related to the software industry. Ensure that each match is accurate and beneficial for both parties. Each candidate should be matched with a single job offer. Include the job offer link provided by the Researcher.Next speaker: Matcher
Matcher (to chat_manager):I currently do not have access to external databases or the ability to retrieve specific candidate profiles or job offers. However, I can help guide you on how to effectively match candidates with job offers based on their qualifications and the requirements of the jobs.1. **Identify Key Qualities**: For each job offer, list the key qualifications, skills, and experience required. Look for programming languages, technologies, years of experience, and any other competencies that are mentioned.2. **Analyze Candidate Profiles**: For each candidate, evaluate their skills, education, and experience. Pay special attention to their technical skills and past roles to ensure they align with the job requirements.3. **Create Matching Criteria**: Develop criteria for grading matches, such as:- Exact match (essential skills/experience)- General match (related skills/experience)- Desirable match (preferred qualifications)4. **Match Candidates to Job Offers**: Based on the above analysis, start matching candidates to job offers. Aim to find roles that play to the candidate's strengths and career aspirations.5. **Link Job Offers**: Ensure that for every candidate matched, the corresponding job offer link is provided.Once you have the specific candidate profiles and job offers, you can follow these steps to create accurate and beneficial matches. If you have specific examples or data, I can help you formulate the matches!Next speaker: Retriever
Retriever (to chat_manager):***** Suggested tool call (call_0yjI5x0gvcLAJeDbiDKYPtFD): elasticsearch_hybrid_search *****
Arguments:
{"question":"Retrieve candidate profiles related to software development and engineering."}
********************************************************************************************Next speaker: Admin
>>>>>>>> EXECUTING FUNCTION elasticsearch_hybrid_search...
Call ID: call_0yjI5x0gvcLAJeDbiDKYPtFD
Input arguments: {'question': 'Retrieve candidate profiles related to software development and engineering.'}Admin (to chat_manager):
***** Response from calling tool (call_0yjI5x0gvcLAJeDbiDKYPtFD) *****
[{
…. Researcher (to chat_manager):
***** Suggested tool call (call_X0bSSvAKuilPJ9hY90AJvMud): search_in_internet *****
Arguments:
{"query": "Software Engineer job offers Python Java AWS Microservices Docker Kubernetes"}
….Next speaker: Critic
Critic (to chat_manager):The matches are accurate and beneficial for both candidates and job offers. **Matches Summary:**
1. **John** - Lead Software Engineer, Full Stack (Java, Python, AWS) at Capital One.
2. **Daniel** - Quality Assurance Engineer for Homey - Taro.
3. **Michael** - DevOps Engineer - Kubernetes, Terraform, Jenkins, Ansible, AWS at Cisco.
4. **Sophia** - AI/ML Engineer at Chesterfield, Missouri, United States.
5. **David** - UX/UI Designer at HR Force International in New York.Admin has been informed of the successful candidate-job offer matches.
**TERMINATE**结果
(格式化以提高可读性)
### Candidate: John
- **Profile**: Experienced software engineer with expertise in backend development, cloud computing, and scalable system architecture.
- **Skills**: Python, Java, AWS, Microservices, Docker, Kubernetes.
- **Expected Salary**: $85,000 - $120,000.
- **Match**: [Lead Software Engineer, Full Stack (Java, Python, AWS) at Capital One](https://www.capitalonecareers.com/en/job/new-york/lead-software-engineer-full-stack-java-python-aws/1732/77978761520)### Candidate: Daniel
- **Profile**: Quality assurance engineer focused on automated testing, test-driven development, and software reliability.
- **Skills**: Selenium, JUnit, Cypress, Postman, Git, CI/CD.
- **Expected Salary**: $60,000 - $100,000.
- **Match**: [Quality Assurance Engineer for Homey - Taro](https://www.jointaro.com/jobs/homey/quality-assurance-engineer/)### Candidate: Michael
- **Profile**: DevOps specialist focused on automation, CI/CD pipelines, and infrastructure as code.
- **Skills**: Terraform, Ansible, Jenkins, Docker, Kubernetes, AWS.
- **Expected Salary**: $95,000 - $130,000.
- **Match**: [DevOps Engineer - Kubernetes, Terraform, Jenkins, Ansible, AWS at Cisco](https://jobs.cisco.com/jobs/ProjectDetail/Software-Engineer-DevOps-Engineer-Kubernetes-Terraform-Jenkins-Ansible-AWS-8-11-Years/1436347)### Candidate: Sophia
- **Profile**: Machine learning engineer with experience in deep learning, NLP, and computer vision.
- **Skills**: Python, PyTorch, TensorFlow, Scikit-Learn, OpenCV, NLP.
- **Expected Salary**: $100,000 - $160,000.
- **Match**: [AI/ML Engineer - Chesterfield, Missouri, United States](https://careers.mii.com/jobs/ai-ml-engineer-chesterfield-missouri-united-states)### Candidate: David
- **Profile**: Creative UX/UI designer with experience in user research, wireframing, and interactive prototyping.
- **Skills**: Figma, Adobe XD, Sketch, HTML, CSS, JavaScript.
- **Expected Salary**: $70,000 - $110,000.
- **Match**: [HR Force International is hiring: UX/UI Designer in New York](https://www.mediabistro.com/jobs/604658829-hr-force-international-is-hiring-ux-ui-designer-in-new-york)注意,在每个 Elasticsearch 存储的候选人末尾,你可以看到一个匹配字段,显示最适合他们的职位!
结论
AutoGen 允许你创建多个 agents 群组,它们协作解决问题,复杂度可根据需求调整。可用的模式之一是 “群聊 - group chat”,管理员在 agent 之间主持对话,最终达成成功的解决方案。
你可以通过创建更多 agent 为项目增加更多功能。例如,将匹配结果存储回 Elasticsearch,然后使用 WebSurfer agent 自动申请职位。WebSurfer agent 可以使用视觉模型和无头浏览器浏览网站。
要在 Elasticsearch 中索引文档,你可以使用类似于 elasticsearch_hybrid_search 的工具,但需要添加额外的导入逻辑。然后,创建一个特殊的 agent “ingestor” 来实现索引。完成后,你可以按照官方文档实现 WebSurfer agent。
原文:Using AutoGen with Elasticsearch - Elasticsearch Labs