[mysql]数据类型精讲
目录
数据类型精讲:
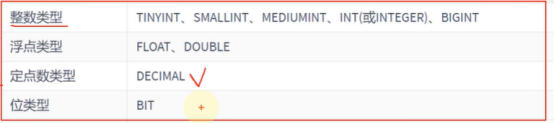
整数类型
浮点类型
日期和时间类型
文本字符串类型
数据类型精讲:
精度问题:不能损失数据
性能问题:表的设计,范式的讲解.
表设计的时候需要设置字段,我们现在要把字段类型讲完.,细节点一点点给大家拆解.
Float和double是有精度的损失的,这边推荐使用的是DECIMAL,
![]()
时间是非常重要的,日志,修改都要进行时间的记录
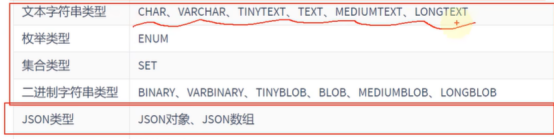
第一行是纯文本类型的,枚举类型的就是多选1,集合类型是有多个数据的
二进制代表音乐,视频这种非文本类型的数据
JSON是服务业和数据库端的
![]()
地图类型的,大家只要了解就可以

Unsigned是代表这个字段只能的正数,比如年龄之类.
字符集就是我们之前创建数据库的时候指定的了字符集 CHARACTER SET name这是我们在创建表的时候指明字符集,比如CREATE TABLE temp(id INT) CHARACTER SET ‘utf8’
我们在建立字符串的时候,我们也可以创建’’
CREATE TABLE temp(id INT CHARACTER SET ‘utf8’,name varchar(15)CHARACTER)
如果你不声明字段的字符集,那它就跟表的字符集,表也没声明就是数据库的字符集
我们要查看表的字段的字符集,所以建立数据库的时候记得指明,其他就不用指明的,下面我们开始讲解
整数类型
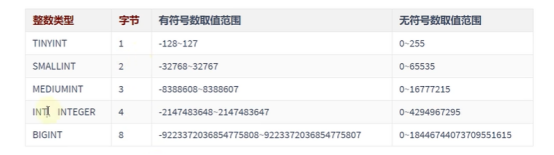
如果我们声明了UNSIGNED,范围就会从0开始
我们知道一个字节是8bit,每个bit可以是0或者1,那么,范围就是这么计算的,1个字节的范围就是2的8次方,2个字节就是2的16次方

我们接下来的讲解和使用都建议在5.7内测试
原因是因为5.7里面会显示指明的字节大小
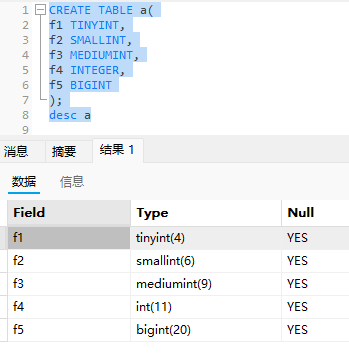
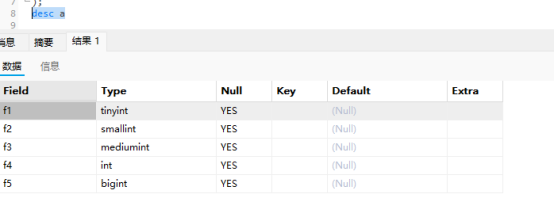
8.0中就没有括号,
因为我们没有指明unsigned,所以这个数字是显示数值的宽度,并不是符合宽度就对,也得在范围内才行
可选属性:
M代表宽度,M显示4的取值范围是0-255
如果我们写 CREATE TABLE 表 (f3 int(5) ZEROFILL)代表的就是如果加上ZEROFILL会让你输入的值被填充到5,如果不足5位使用0填充,比如123,00123,如果超过5就不会填充.
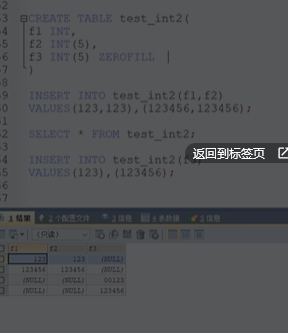
如果我们SHOW CREATE TABLE
会发现我们如果写了ZEROFILL就会自动获得UNSIGNED属性.当你使用ZEROFILL的时候,自动添加.写不写都可以.
![]()
当整数类型在版本8.017之后不推荐使用(5),因为不使用ZEROFILL没有意义,所以8.0也就都没有(宽度)了.
UNSIGNED
DESC
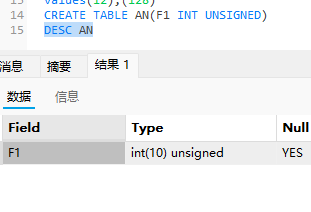
使用了unsigned就自动把范围变成10了.
使用场景: TINYINT类型一般在系统设定取值范围的时候,使用
SMALLINT 较小范围的统计数据,比如工厂的固定资产库存数量
MEDIUMINT 是1千600万左右,也就是每日客流量这种类型数据,当然INT也可以
INT\INTEGER,取值范围足够大,不用考虑超过限,用的最多,比如商品编号
BIGINT:当你处理特别巨大的整数才会用到,比如双11的交易量,大型网站点击率,证券衍生物产品.
这里我们由于存储空间就越小越好,但是可靠性上来说,要考虑不断迭代,日积月累,保证mediumint这种数据类型要能可靠,支撑.由于系统故障产生的成本远远超过增加几个字段存储空间的成本.所以我们要考虑扩展的情况..如果不能确保的情况,要限考虑最大的类型.
浮点类型
浮点是包含整数类型,范围比整数大一些,也就是小数.

我们有两种类型,float和double,double的范围会更大些.其他编程语言也是字节数4和8.double的存储范围要比float大很多.他们的区别就是精度double的范围高.
本来在整数里,我们无符号是有符号的一倍,但是double是不一样的,他的存储考个试是符号,尾数,阶码.所以代表我们取无符号,只是不给符号了,所以我们不用特意声明浮点类型的声明,unsigned
精度说明,:
非标准语法:float(M,D),M是精度,D是标度.M是比如定义float(5,2),范围就是-999.99到999.99.M代表了整数和小数的大小,D代表了小数的大小.7.58
如果我们的数字小数超过了小数位,就会进行四舍五入,并且四舍五入后不能超过整数位,如果超过就会报错
精度误差,浮点数的缺陷,FLOAT和DOUBLE的精度问题
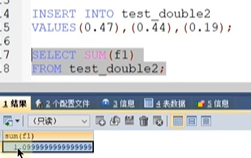
我们这3个数应该加起来是1.1,但是我们结果是1.099999并且我们和小数1.1对比的时候,是不相等的.
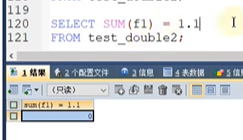
定点数
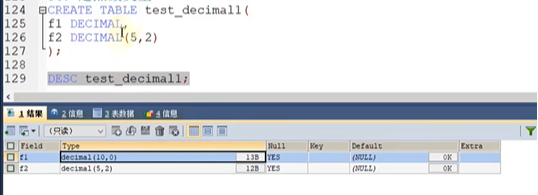
由于精度问题,我们就要引入,定点数,DECIMAL(M,D)字节数是M+2
1:DECIMAL和我们DOUBLE的区别在于相同的M和D情况下,显示数值范围是DOUBLE更大..如果我们,不指定D的时候定点数的小数为0.
由于定点数的底层逻辑是用字符串来储存,所以结果是非常精确的.
浮点数和定点数
什么时候使用浮点数,什么时候使用定点数呢.
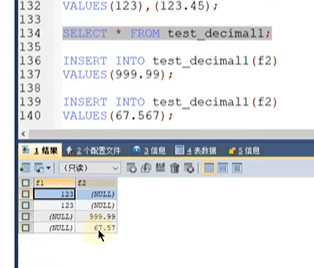
我们执行的时候
我们前面说8.0已经不支持我们输入M和D了,但是decimal是需要输入M和DECIMAL也是存在四舍五入
.
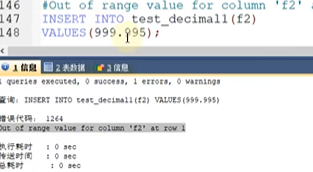
这里四舍五入之后,就会导致4位数,那么就会出现报错.
精度问题
我们把DOUBLE类型用 ALTER table 表 modify 字段 DECIMAL
就会发现,这次精度就是相等了
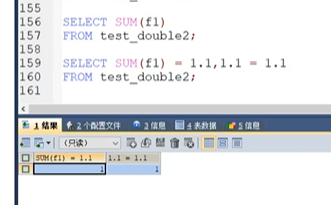
.所以如果我们需要大的范围,但是不用那么精准,由于浮点型类型范围比较大,所以就可以使用浮点.
所以有利有弊
开发中的话,我们除了极少数商品编号要用到整数,其他的小数全部都用定点数,一分钱也不能差
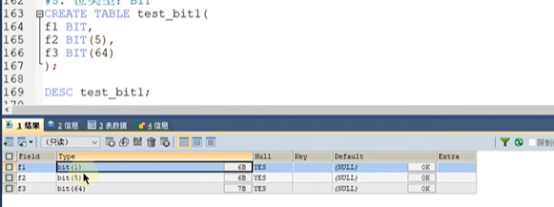
位类型BIT
BIT(M)范围是0-64
当我们没有声明的时候,宽度就是1,如果我们插入2就会报错.因为存储是10.超过宽度1了
![]()
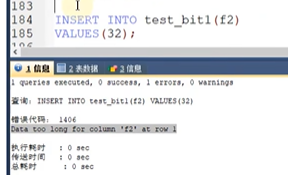
这里32就是100000.所以就会报错.因为M是5
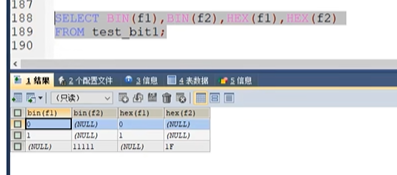
在命令行是以16进制显示的,如果我们用加0就可以用十进制类型,储存了.
日期和时间类型
日期和时间有那啥数据类型呢,主要是这些类型
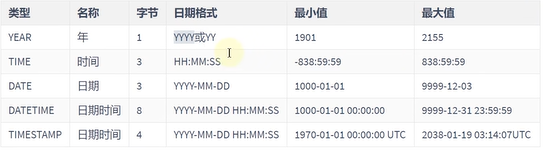
Year 只存一个年,字节也只有1个,很小,一共只有256种情况,1901到2155
TIME注意这个哥们,-838:59:59 839:59:59是也可以保持多日的时间间隔
DATE,DATETIME,TIMESTAMP后面我们会一一细说
YEAR类型:
写法YYYY,字符串或者数字格式表示
如果用2位表示,01-69是代表2000年的数据2001-2069
如果是70-99的话就是1970-1999年的数据
,数值型取的是00那就是0000如果是字符串0那就是2000
时间戳我们都是1970年开始,所以70代表1970,69代表2069,所以大家要尽量不要使用2位
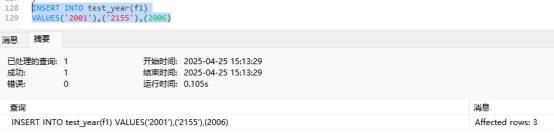
INSERT INTO test_year(f1)
VALUES('2001'),('2155'),(2006)
这里的2155是可以添加成功的
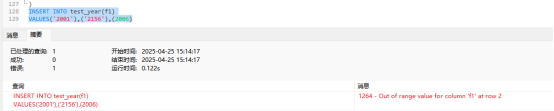
2156就不可以了.现在我们看看两位的转换
-
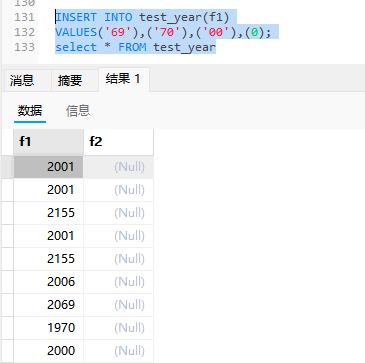
DATE是用3个字节存储的,用YYYY-MM-DD来存储的YYYYMMDD格式来存储也是可以的,后者会被转化为前者
YY-MM-DD格式或者YYMMDD的前两位数是按照年的存储规则进行的
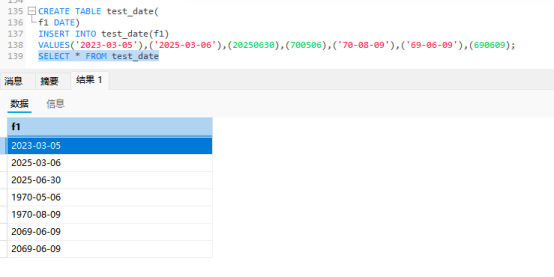
这些格式都是可以被用于储存的,记得69代表2069,70代表1970
不推荐这么写,只作用于了解,不加引号就更不推荐了,最好是使用yyyy-mm-dd和yyyymmdd字符串存储.
添加当前的日期,可以直接用CURRENT(),CURRENT_DATE,NOW(),这里的NOW是包含时间了,但是只储存日期.
TIME类型:
我们使用HH:MM:SS字符串存储,也可以使用’D HH:MM:SS’
这里需要注意了如果是4个数,’HH:MM’代表的是小时和分钟,不是分钟秒
如果是’D HH’,只有2个数字字符串’ss’代表的就是秒
如果不带引号,那么导入的数据就是MMSS代表的就是分钟和秒钟
所以我们还是不要搞这些花里胡哨的
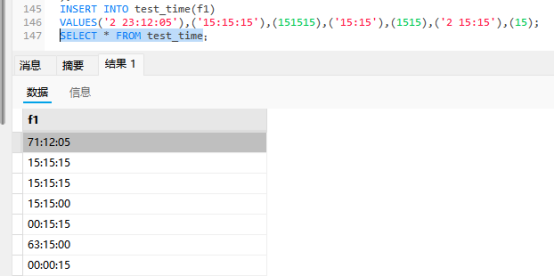
这里吧这些例子距离一下
DATETIME类型
这个哥们占用了8个字节数,是最多的.
TIME3个字节,DATE3个字节,用2个字段不是还更省.
但是我们DATETIME的范围是比较大的.存储也是加短横线的类型
‘YYYY-MM-DD HH:MM:SS’
我们也是和上面的存储是一样的规则
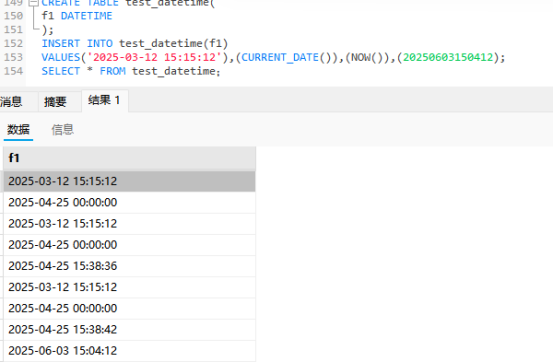
TIMESTAMP类型
它也可以表示日期时间,范围会比我们的DATETIME范围小很多,这里类型的字段满足储存的格式和什么的类型是一样,如果范围超过了就会报错
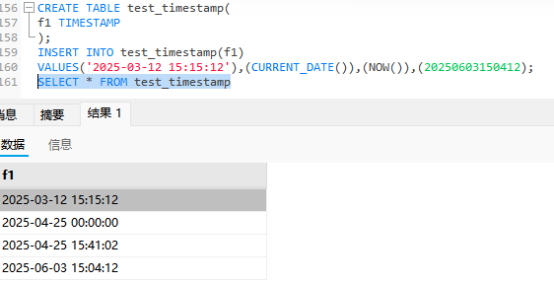
中间的-使用@替换也是可以的.,
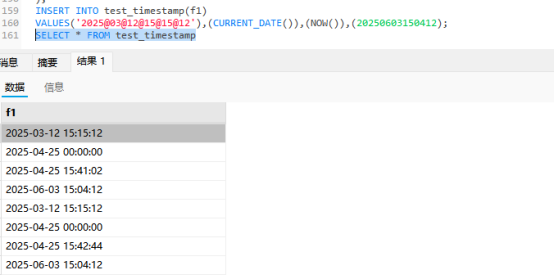
他们俩的区别是:
对比DATETIME和TIMESTAMP
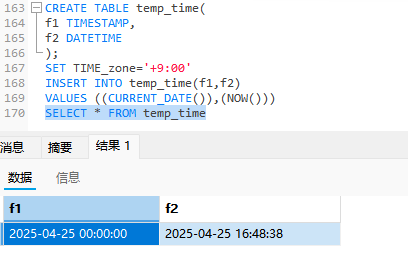
我们会发现日期差了16小时,
我们储存timestamp时间的时候,它会考虑这个时区的问题,由于它的底层逻辑是使用毫秒级的存储方式,如果你要查询这个数据,它就会按照你的时区来转化为时间日期,那么结果就和我们的tiemdate不大一样了.
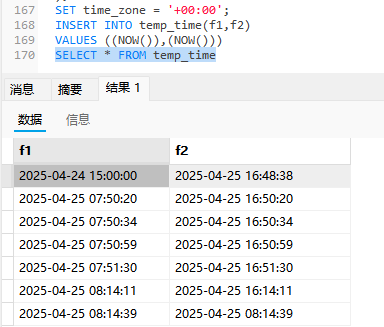
他们的区别:
比较大小,timestamp比较快
总结:
开发中的经验,我们开发中尽量使用DATETIME,范围大,而且完整的记录的日期和时间信息,我们不推荐分散在不同的字段,查询也要多个字段查询,我们直接用DATETIME,范围也广.我们为什么不用timestamp,只有注册时间和商品发布时间就它方便与计算,我们可以使用UNIX_TIMESTAMP获取当前时间
文本字符串类型
CHAR(M)
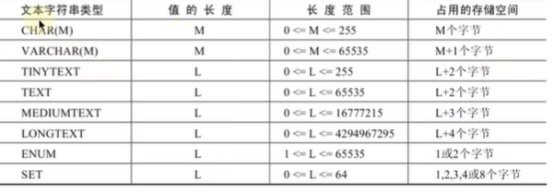
CHAR固定长度字符串
VARCHAR代表的是不固定长度的字符串
ENUM和SET可以放在一起,可以放多个字符串逗号连接起来,和另外的文本字符串有点区别
CHAR和VARCHAR类型的区别
CHAR是固定长度,比如你设定10个字符长度录入5个,那么它会补齐10个(它会用空格填充,但是你是看不到的)
VARCHAR是变化长度,比如你录入5个,它会使用6个字符存储,5个是存储字符,还有一个是用于记录长度.
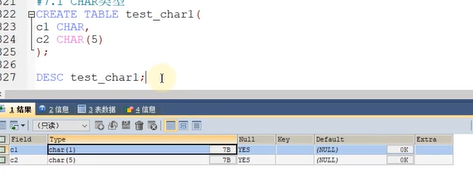
如果我们不指明的话,那么就只有一个字符
超过范围就会报错,我们的汉字是一个占用字符,所以汉字也可以储存对应的长度数.
如果长度不够,那么我们是看不见那个空格的我们可以用concat来字符串连接一下,我们可以使用***连接在前面,我们还是看不见长度,如果我们录入空格的时候,长度计算的时候,它也会忽略长度.
VARCHAT()类型
是必须指定长度,4.0以下()内的长度代表的是字符集,最大是65535
如果写的是5.最多只能存5个字符.
Char是有一定空间的浪费
我们应该选那个比较好呢,
固定长度的时候,我们就要选择char,char的检索效率高,存储量不大的时候用char
存储很短的信息用char就好,比如门牌号101,202.就比如买车手续费100可以接受,买自行车200块钱收100块钱手续费我们就不好接受了.
固定长度的时候比如身份证等就用char
如果要经常获取这个字符串的长度,那么就还是用char,因为varchar不好计算,计算速度比char比较慢
InnoDB建议用VARCHAR,因为他没有区分长度,主要影响因素是存储长度了.
TEXT类型
报错文本类型
存储文本数据的,一段文章,不能用于主键,因为长度变化太大
TEXT存储的时候不用指定长度
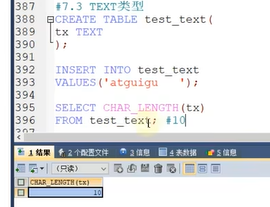
它存储空格的时候,也会计算长度
长度不是太大就用char,但是如果文本长度超过char的极限那么最好还是用text
还有一件事,如果text经常被操作,或者说经常删除,那么空间就会出现空洞,导致文件非常的碎片化,所以建议最好是把text单独保存到一个表中.