【Langchain】RAG 优化:提高语义完整性、向量相关性、召回率--从字符分割到语义分块 (SemanticChunker)
RAG 优化:提高语义完整性、向量相关性、召回率–从字符分割到语义分块 (SemanticChunker)
背景:提升 RAG 检索质量
在构建基于知识库的问答系统(RAG)时,如何有效地将原始文档分割成合适的文本块(Chunks)是影响检索召回率和最终答案质量的关键步骤之一。最初,我们的项目采用了 Langchain 提供的 RecursiveCharacterTextSplitter。
RecursiveCharacterTextSplitter 的原理相对简单:它根据预设的字符列表(如换行符、空格)递归地分割文本,并尝试维持指定的块大小 (chunk_size) 和重叠量 (chunk_overlap)。这种方法的优点是实现简单、速度快。然而,它的主要缺点在于 缺乏对文本语义的理解。它可能会在句子中间或者一个语义完整的段落内部进行切割,导致生成的文本块语义不完整,影响后续向量检索的相关性。当用户提问时,如果相关的上下文被分割到了不同的块中,模型可能无法获取足够的信息来生成准确的答案。
具体问题案例
- prompt:你是一个检索助手,你将根据检索到的上下文信息回答简明扼要地用户问题,接着说“以下是依据的检索信息:”,附带上你依据的上下文信息。如果根据检索到的上下文信息不足以回答用户的问题,请你直接告知:“根据检索到的上下文信息不足以回答您的问题”,并且附带上检索到的上下文信息。
- 检索文件:RAG-QA-PRD.pdf
- Q:RAG是为了解决什么问题?
- AI根据检索内容回复了两点。
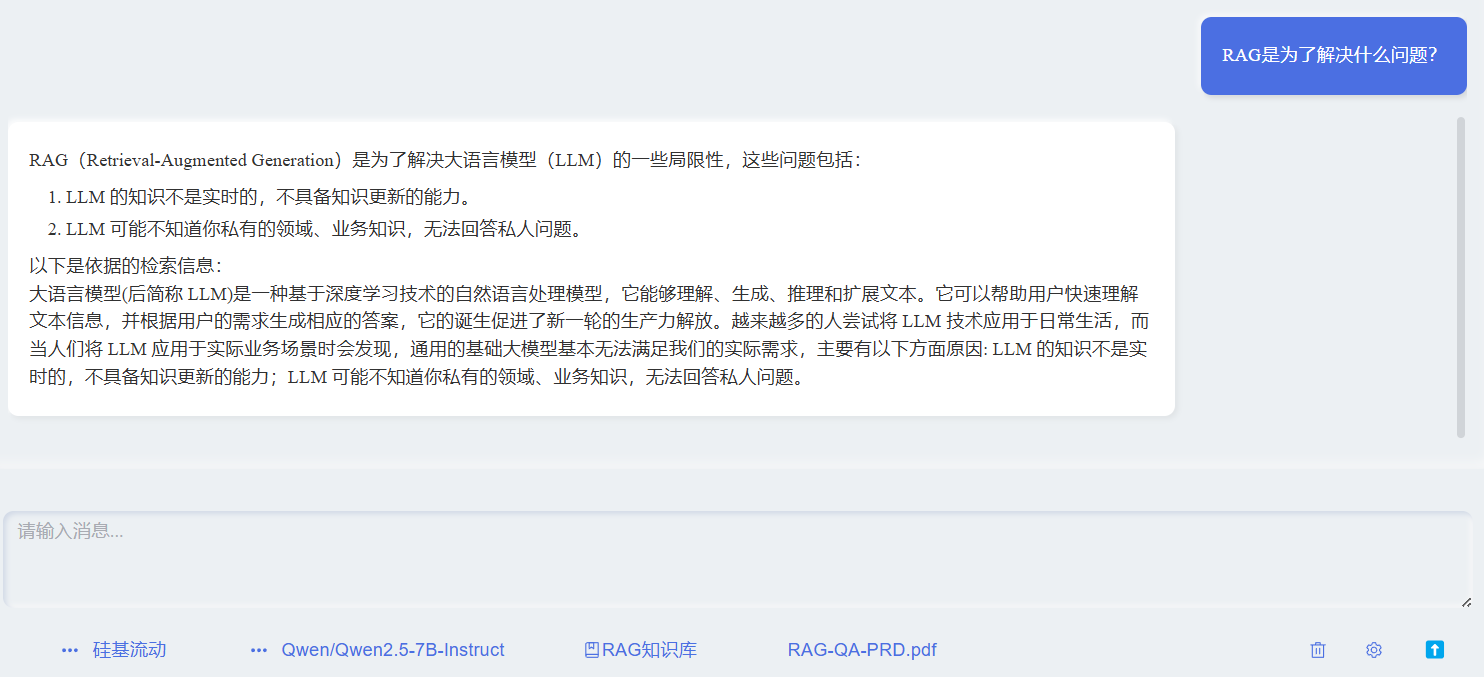
!而实际原本有三点内容
[!NOTE] RAG-QA-PRD.pdf 原文本相关片段
大语言模型(后简称 LLM)是一种基于深度学习技术的自然语言处理模型,它能够理解、生成、推理和扩展文本。它可以帮助用户快速理解文本信息,并根据用户的需求生成相应的答案,它的诞生促进了新一轮的生产力解放。越来越多的人尝试将 LLM 技术应用于日常生活,而当人们将 LLM 应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际需求,主要有以下几方面原因:
LLM 的知识不是实时的,不具备知识更新的能力。
LLM 可能不知道你私有的领域、业务知识,无法回答私人问题。
LLM 有时会在回答中生成看似合理但实际上是错误的信息,这就是典型的"幻觉"现象。
为了解决以上问题 RAG 由此诞生,RAG 即 Retrival-Augmented Generation,是一种基于检索技术的对话系统,它可以帮助用户快速理解文本信息,并根据用户的需求生成相应的答案。RAG 具有以下优势:
这是因为RecursiveCharacterTextSplitter 的局限性,它将原本相关的文本切成了两个部分,第一个部分被召回,而第二个部分因为包含的信息更少,其向量相关性也下降了,没有被召回。
这就导致了检索质量不理想,因为RecursiveCharacterTextSplitter既影响了语块完整性,也影响了语块的向量相关性。
探索:寻找更优的文本分割方案
为了克服 RecursiveCharacterTextSplitter 的局限性,提升检索质量,我开始调研 Langchain 提供的其他文本分割器。查阅官方文档后,我考虑了以下几种方案:
-
基于句子边界的分割器 (
NLTKTextSplitter,SpacyTextSplitter): 利用 NLP 工具包识别句子边界进行分割。这能保证句子完整性,但可能产生过细的粒度。 -
基于文档结构的分割器 (
MarkdownHeaderTextSplitter,HTMLHeaderTextSplitter): 利用 Markdown 或 HTML 的标题结构。效果好但仅适用于特定格式文档。 -
语义分块 (
SemanticChunker): 这是 Langchain 实验性功能中的一个分割器。它利用嵌入模型 (Embeddings) 计算句子间的语义相似度,在语义关联较弱的地方进行切分。其核心目标是创建语义上内聚的文本块。
决策: SemanticChunker
考虑到我们的核心目标是 最大化文本块的语义相关性 以提升 RAG 效果,SemanticChunker 成为了最具吸引力的选项。尽管它处于实验阶段,但其设计理念与我们的需求高度契合。我们决定尝试引入它,接受其可能带来的挑战。
测试效果
我们先来看看改造效果。
-
完成了
SemanticChunker配置与代码集成后 -
重新上传文件,这次使用
SemanticChunker进行分块
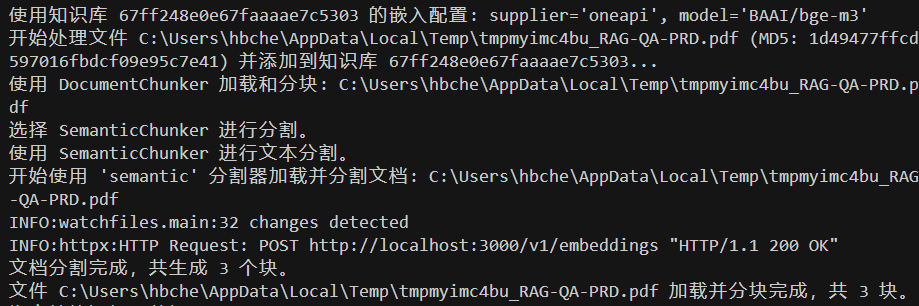
-
新建一个会话,避免历史会话的影响
-
重新发送完全一致的问题和配置项
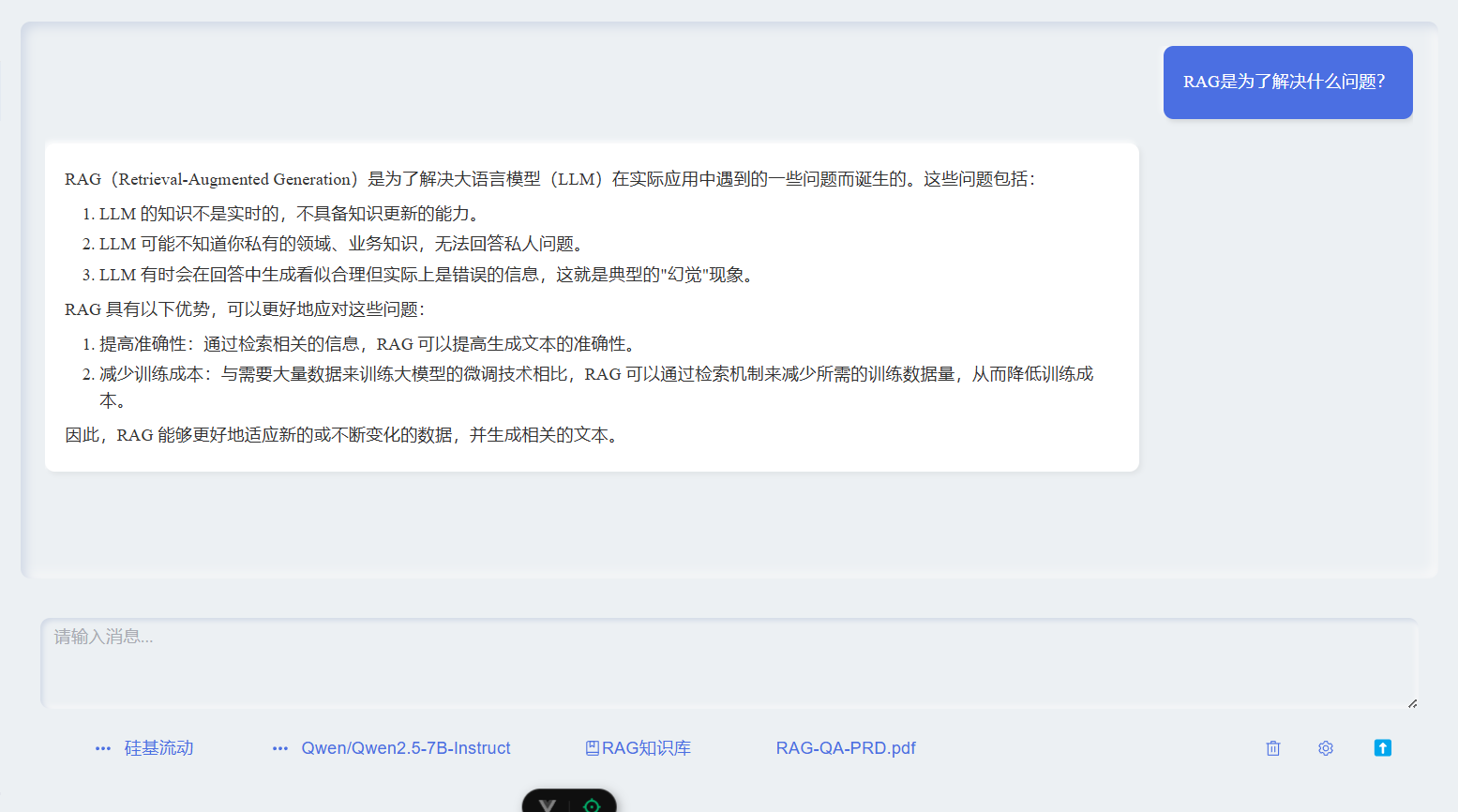
这次我们可以看到AI回复了完整的三个点,甚至还附带了原文中的RAG解决问题的优势。
因为它们语义相似,SemanticChunker 将它们分割在一个块中。这样就保证了语块的完整性,提高了语块的向量相关性,从而提高了召回率和检索质量。
实施:配置与代码集成
让我们来看详细的实践
1. 环境配置与依赖
SemanticChunker 依赖一些额外的库。我们需要通过包管理工具 (pdm) 安装它们:
pdm add langchain_experimental sentence-transformers bert_score
langchain_experimental: 包含SemanticChunker本身。sentence-transformers: 常用于计算文本嵌入,SemanticChunker底层依赖它。bert_score:SemanticChunker在某些配置或计算中断点时可能需要。
2. 核心代码修改
关键的改动发生在 src/utils/DocumentChunker.py 和 src/utils/Knowledge.py 中。
a) DocumentChunker 的改造
我们修改了 DocumentChunker 的 __init__ 方法,使其能够接受 splitter_type 和 embeddings 参数:
# src/utils/DocumentChunker.py
from typing import Optional
from langchain_core.embeddings import Embeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
try:from langchain_experimental.text_splitter import SemanticChunkerLANGCHAIN_EXPERIMENTAL_AVAILABLE = True
except ImportError:LANGCHAIN_EXPERIMENTAL_AVAILABLE = FalseSemanticChunker = None
class DocumentChunker(BaseLoader):# ... (其他代码)def __init__(self,file_path: str,chunk_size: int = 300,chunk_overlap: int = 30,splitter_type: str = "recursive", # 'recursive' 或 'semantic'embeddings: Optional[Embeddings] = None, # 用于 semantic) -> None:# ... (加载器初始化代码)self.splitter_type = splitter_typeif self.splitter_type == "semantic":print("选择 SemanticChunker 进行分割。")if not LANGCHAIN_EXPERIMENTAL_AVAILABLE:raise ImportError("langchain_experimental 未安装。")if embeddings is None:raise ValueError("必须为 'semantic' 分割器提供 embeddings 参数。")if SemanticChunker is None:raise RuntimeError("SemanticChunker 未成功导入。")try:# 使用传入的 embeddings 初始化 SemanticChunkerself.text_splitter = SemanticChunker(embeddings=embeddings,breakpoint_threshold_type="percentile" # 或其他策略)print("使用 SemanticChunker 进行文本分割。")except Exception as e:print(f"初始化 SemanticChunker 时出错: {e}")raiseelif self.splitter_type == "recursive":self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)print(f"使用 RecursiveCharacterTextSplitter ...")else:raise ValueError(f"不支持的 splitter_type: '{self.splitter_type}'")def load(self) -> list:print(f"开始使用 '{self.splitter_type}' 分割器加载并分割文档...")# ... (调用 self.loader.load_and_split(self.text_splitter))
这个改动使得 DocumentChunker 可以根据传入的 splitter_type 选择初始化 RecursiveCharacterTextSplitter 或 SemanticChunker。关键在于,当选择 semantic 时,它需要一个 Embeddings 对象的实例。
b) Knowledge 类传递 Embeddings
SemanticChunker 需要的 Embeddings 对象从哪里来?在我们的架构中,Knowledge 类负责处理知识库的创建和文档添加,并且它本身就持有用于向量化的 _embeddings 实例。因此,我们在 Knowledge.add_file_to_knowledge_base 方法中,将这个 _embeddings 传递给 DocumentChunker:
# src/utils/Knowledge.py
class Knowledge:def __init__(self, _embeddings=None, reorder=False, splitter="semantic"): # 可以增加 splitter 参数控制默认行为self.reorder = reorderself._embeddings = _embeddingsself.splitter = splitter # 存储选择的分割器类型# ...async def add_file_to_knowledge_base(self, kb_id: str, file_path: str, file_name: str, file_md5: str) -> None:# ...if not self._embeddings:raise ValueError("无法处理文件,因为缺少 embedding 函数。")# --- 1. 加载和分块文档 ---try:print(f"使用 DocumentChunker (类型: {self.splitter}) 加载和分块: {file_path}")# 根据 self.splitter 决定如何实例化 DocumentChunkerloader = DocumentChunker(file_path,splitter_type=self.splitter, # 使用类实例的 splitter 配置embeddings=self._embeddings if self.splitter == "semantic" else None, # 仅在 semantic 时传递 embeddings)documents: List[Document] = loader.load()# ...except ImportError as e:print(f"错误:缺少 SemanticChunker 所需库: {e}")raiseexcept ValueError as e:print(f"配置错误: {e}")raiseexcept Exception as e:print(f"加载/分块时出错: {e}")raise# --- 2. 准备并注入元数据 ---# ...# --- 3. 添加到 ChromaDB ---# ...
这样,Knowledge 类在初始化时就可以决定使用哪种分割器(可以通过参数传入或硬编码),并在处理文件时将必要的 embeddings 对象传递给 DocumentChunker。
关于RAG
你可能关心
- 你知不知道像打字机一样的流式输出效果是怎么实现的?AI聊天项目实战经验:流式输出的前后端完整实现!图文解说与源码地址(LangcahinAI,RAG,fastapi,Vue,python,SSE)-CSDN博客
- 如何让你的RAG-Langchain项目持久化对话历史\保存到数据库中_rag保存成数据库-CSDN博客
- 分享开源项目oneapi的部分API接口文档【oneapi?你的大模型网关】-CSDN博客
关于作者
- Github 更多开源项目
- CSDN 更多实用攻略