OCR(Optical Character Recognition),光学字符识别
参考:如何让机器读懂图片上的文字?飞桨助您快速了解OCR - 知乎
OCR(Optical Character Recognition),译为光学字符识别,是指通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。
OCR技术的应用场景非常广泛:
(1)拍照/截图识别
使用OCR技术,实现拍照文字识别、相册图片文字识别和截图文字识别,可应用于搜索、书摘、笔记、翻译等移动应用中,方便用户进行文本的提取或录入,有效提升产品易用性和用户使用体验。
(2)内容审核与监管
(3)视频内容分析
(4)纸质文档电子化
OCR技术原理
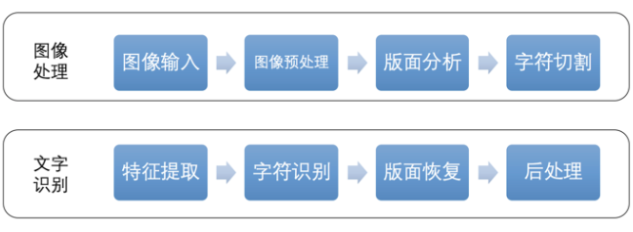
图像处理阶段:包含图像输入、图像预处理、版面分析、字符切割等子步骤。
文字识别阶段:包含特征提取、字符识别、版面恢复、后处理等子步骤。
【文本检测】
图像输入:读取不同格式的图像文件。
图像预处理:包含灰度化、二值化、图像降噪、倾斜矫正等预处理步骤。
版面分析:针对左右两栏等特殊排版,进行版面分析并划分段落。
字符切割:对图像中的文本进行字符级的切割,尤其注意字符粘连等问题。
【文本识别】
特征提取:对字符图像提取关键特征并降维,用于后续的字符识别算法。
字符识别:依据特征向量,基于模版匹配分类法或深度神经网络分类法,识别出字符。
版面恢复:识别原文档的排版,按照原排版的格式将识别结果输出。
后处理:引入语言模型或人工检查,修正“分”和“兮”等形近字。
参考:OCR二次开发宝典:飞桨联合多家企业和高校发布《OCR产业范例20讲》 - 知乎
基于PaddleOCR完成一个范例的完整流程一般包含数据准备、模型训练、推理部署三个部分,具体来说:
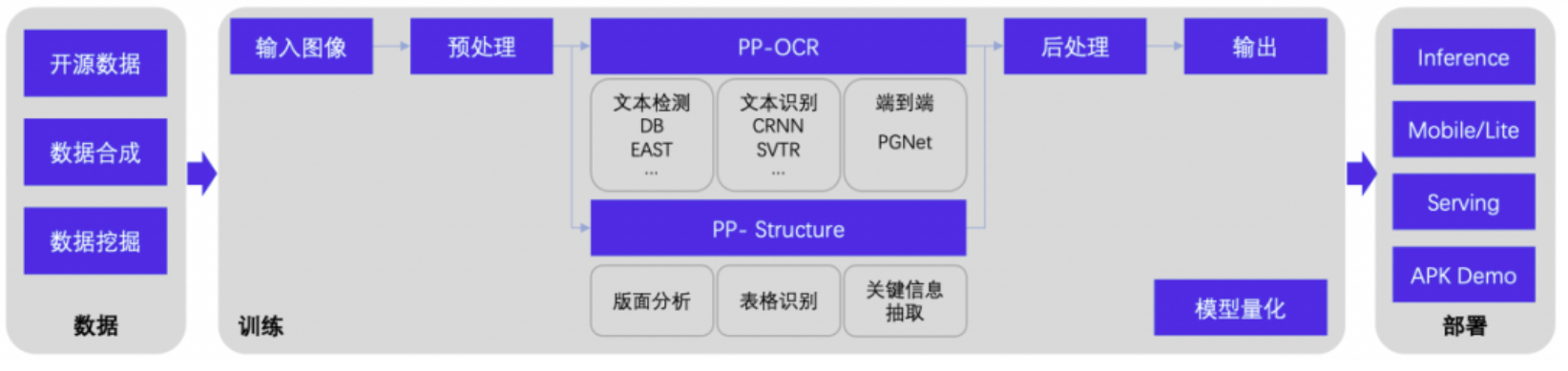
模型训练
PP-OCR和PP-Structure系列模型都使用了大量训练数据,在通用场景可以一定程度地保证精度和泛化性,因此一般建议基于飞桨PP系列模型进行模型微调(finetune),从而实现使用较少的业务数据达到预期效果。基于不同场景业务数据训练的模型,有时需要针对前后处理进行任务适配,往往能进一步提升整体效果,偶尔甚至有“奇效”。如车牌识别范例中,通过后处理优化特殊符号的识别结果,大幅提升了整体识别精度。
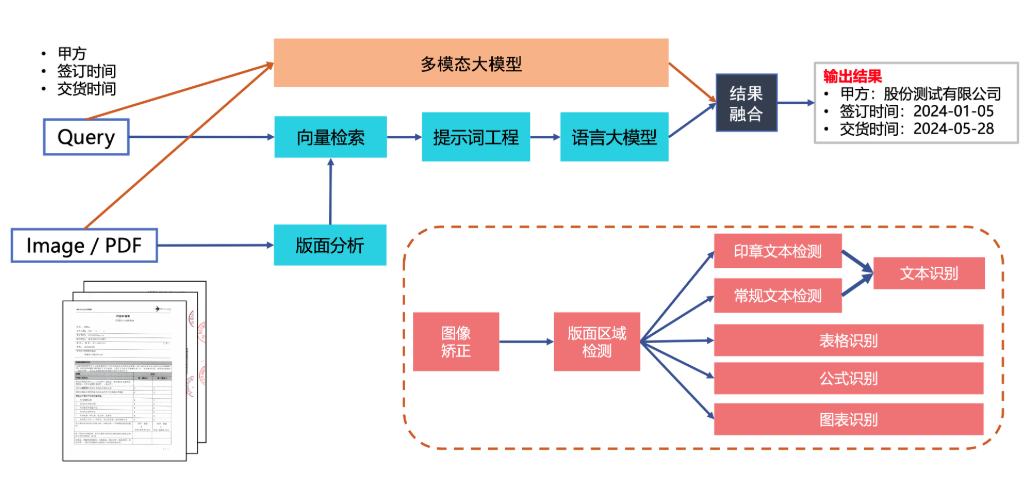
银行回单是企业财务记账的重要原始凭证之一。目前是由财务人员进行人工读取,提取账单中的收付款人、流水单号、金额等关键信息,结合财务记账规则进行处理,加工成记账凭证、资产负债表、开具发票。针对该场景,本范例基于PP-Structure训练命名实体识别、关系抽取模型并基于Hub Serving完成关键信息抽取的服务化部署,实现代替记账公司实现自动化记账报税功能。
文档场景信息抽取v4产线 - PaddleX 文档
通用OCR产线 - PaddleX 文档
OCR(光学字符识别,Optical Character Recognition)是一种将图像中的文字转换为可编辑文本的技术。它广泛应用于文档数字化、信息提取和数据处理等领域。OCR 可以识别印刷文本、手写文本,甚至某些类型的字体和符号。
通用 OCR 产线用于解决文字识别任务,提取图片中的文字信息以文本形式输出,本产线集成了业界知名的 PP-OCRv3 和 PP-OCRv4 的端到端 OCR 串联系统,支持超过 80 种语言的识别,并在此基础上,增加了对图像的方向矫正和扭曲矫正功能。基于本产线,可实现 CPU 上毫秒级的文本内容精准预测,使用场景覆盖通用、制造、金融、交通等各个领域。本产线同时提供了灵活的服务化部署方式,支持在多种硬件上使用多种编程语言调用。不仅如此,本产线也提供了二次开发的能力,您可以基于本产线在您自己的数据集上训练调优,训练后的模型也可以无缝集成。
通用OCR产线中包含必选的文本检测模块和文本识别模块,以及可选的文档图像方向分类模块、文本图像矫正模块和文本行方向分类模块。其中,文档图像方向分类模块和文本图像矫正模块作为文档预处理子产线被集成到通用OCR产线中。
如果您更注重模型的精度,请选择精度较高的模型;如果您更在意模型的推理速度,请选择推理速度较快的模型;如果您关注模型的存储大小,请选择存储体积较小的模型。