spark总结
文章目录
- 一 spark简介
- 1.1 什么是spark
- 1.2 spark运行过程
- 1.2.1 组成
- 1.2.2 过程
- 1.2.3 事例(词频统计WordCount程序)
- 1.3 spark运行模式
- 1.4 pyspark
- 二 SparkCore
- 2.1 RDD介绍
- 2.2 RDD编写
- 2.3 RDD算子
- 2.4 RDD的持久化
- 2.4.1 为什么需要缓存和检查点机制?
- 2.4.2 缓存
- 2.4.3 检查点机制(CheckPoint)
- 2.4.4 缓存和CheckPoint的对比
- 2.4.5 注意
- 2.5 RDD的共享变量
- 2.5.1 广播变量
- 2.5.2 累加器
- 2.6 Spark的内核调度(重点)
- 2.6.1 DAG(有向无环图)
- 2.6.2 DAG的宽窄依赖和阶段划分
- 2.6.3 内存迭代计算
- 2.6.4 Spark并行度
- 2.6.5 Spark任务调度
- 三 SparkSql
- 3.1 SparkSQL概述
- 3.2 DataFrame
- 3.2.1 DataFrame组成
- 3.2.2 两种编程风格DSL\SQL
- 3.2.3 全局表和临时表
- 3.3 SparkSQL函数定义
- 3.3.1 三种类型:UDF\UDAF\UDTF
- 3.3.2 两种定义方式
- 3.3.3 开窗函数
- 3.4 SparkSQL的执行流程
- 3.4.1 CataLyst优化器
- 3.5 SparkSQL整合Hive
视频链接: 【黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程】 https://www.bilibili.com/video/BV1Jq4y1z7VP/?p=41&share_source=copy_web&vd_source=8f9078186b93d9eee26026fd26e8a6ed
一 spark简介
1.1 什么是spark
-
spark定义
spark是一种分布式计算分析引擎,借鉴MapReduce思想发展而来,保留了分布式计算的优点并改进了MapReduce的缺点,让中间数据存储在内存中提高了运行速度,提供了丰富的数据处理的API,提高了开发速度 -
spark的作用:
可以处理结构化数据、半结构化数据、非结构化数据,支持python,sql,scala,R,java语言,底层语言使用scala写的 -
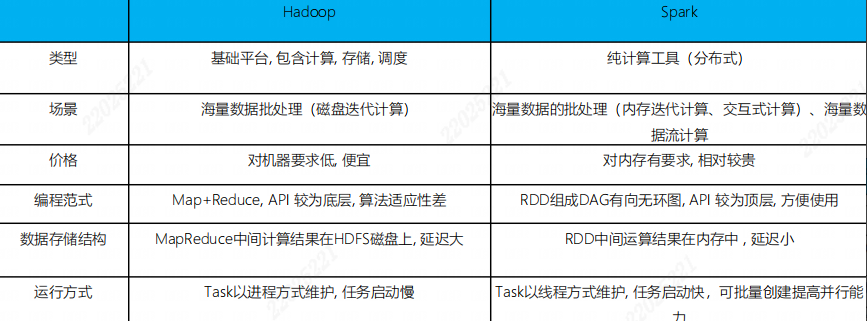
与Hadoop框架的区别
-
spark的特点:速度快、易使用、通用性强、支持多种运行方式
-
spark组成
- Sparkcore
- Sparkcore是spark的核心,数据抽象是RDD,可以编程进行海量离线数据批量处理
- 可以处理结构化和非结构化数据
- Sparksql
- Sparksql是基于Sparkcore,数据抽象是DataFrame,使用sql语言进行离线数据开发,针对流式计算,其提供StructuredStreaming模块,以sparksql为基础,进行流式计算
- 有两种模式DSL和SQL,DSL可以处理结构化和非结构化数据,SQL可以处理结构化数据
- Sparkstreaming
- 是以sparkcore为基础,提供流式处理
- SparkMLlib
- 是以sparkcore为基础,进行机器学习计算,内置大量机器学习库
- SparkGraphX
- Apache Spark 生态系统中的图计算框架,主要用于大规模图数据的处理和分析,用于大规模图数据处理;图分析;图可视化;图机器学习
- Sparkcore
1.2 spark运行过程
1.2.1 组成
spark架构的组成与Yarn很相似,也是采用主从架构,Yarn是由ResouseManager、NodeManager、ApplicationMaster、Container组成,类比到spark也是由4部分组成:Master、Worker、Driver、Executor
- Master:集群大管家, 整个集群的资源管理和分配
- Worker:单个机器的管家,负责在单个服务器上提供运行容器,管理当前机器的资源
- driver:单个Spark任务的管理者,管理Executor的任务执行和任务分解分配, 类似YARN的ApplicationMaster;
- excutor:具体干活的进程, Spark的工作任务(Task)都由Executor来负责执行
1.2.2 过程
-
用户程序创建sparkcontext,sparkcontext连接到clustermanager,clustermanager根据所需的内存、cpu等信息分配资源,启动executor
-
driver将用户程序划分为不同的执行阶段stage,每一阶段stage由一组相同的task组成,每一个task即为一个线程,每一个task分处在不同的分区。在stage和task创建完成后,driver会向executor发送task
-
executor在接受到task后,会下载task的运行时依赖,在准备好task执行环境后,执行task,然后将task的执行状态汇报给driver
-
driver根据接收到的task运行状态处理不同的状态更新。task分为两种,一种是shuffle map task,一种是result task,前一种负责数据重新洗牌,洗牌的结果保存到executor节点的文件系统中,后一种是负责生成结果数据
-
driver会不断地调用task,将task发送到executor执行,在所有的task都正确执行或者超过执行次数限制仍然没有执行成功时停止
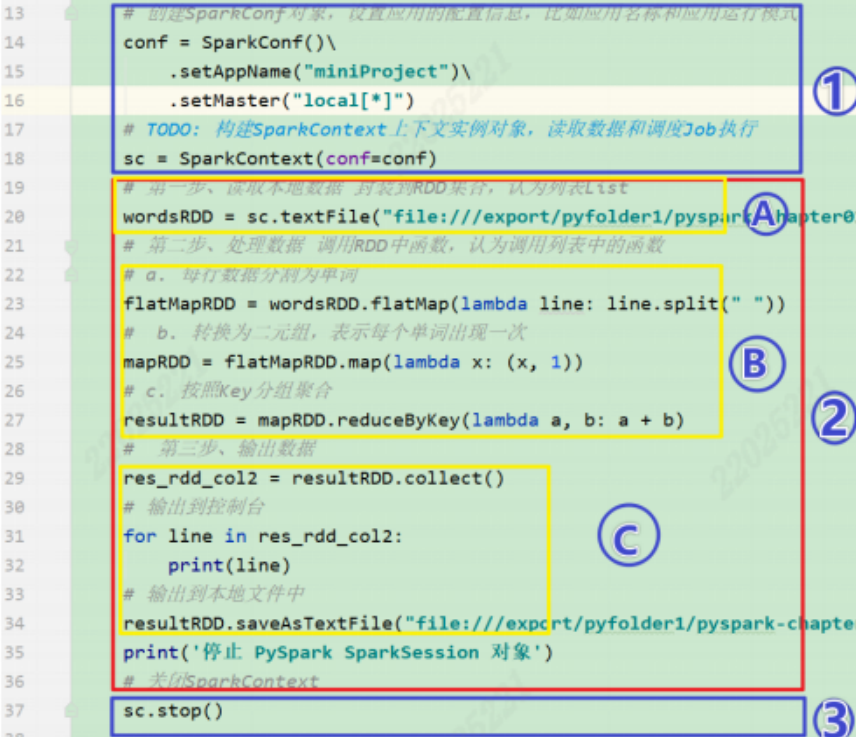
1.2.3 事例(词频统计WordCount程序)
-
①和③是在driver上执行,提交和关闭sparkcontext资源,将所需要的cpu、内存等资源提交给Master
-
②过程都在Executors上执行,其中A是数据加载,B是处理数据,C是保存数据,这是一个job
1.3 spark运行模式
主要介绍两种
-
StandAlone HA模式
为什么需要StandAlone HA模式:
在主从模式的(master-slaves)集群下,存在着Master单点故障(SPOF)的问题,StandAlone HA模式就是为了解决这个问题基于zookeeper实现HA,zookeeper使用Leader Elective机制,利用其可以保证虽然集群存在多个Master,但是只有一个Active的,其他都是Standby,当active的master出现故障,Standby Master会被选举出来。由于集群的信息(Worker、Driver、Application的信息)都已经持久化到文件系统中,因此在切换过程中只会影响新的Job提交,对于正在进行的Job没有任何的影响。
-
SparkOnYarn模式
- 为什么需要SparkOnYarn模式:
因为在企业中主流的数据管理用的Hadoop集群,如果再搭建一个Spark StandAlone HA集群,产生了资源浪费(提高资源利用率),所以在企业中,多数场景下,会将Spark运行到Yarn集群中,这样的话,只需要找一台服务器充当Spark客户端即可,将任务提交到Yarn集群中运行 - SparkOnYarn本质:
master:yarn中的resourcemanager替代
worker:yarn中的nodemanager替代
driver角色运行在yarn容器内,或提交任务的客户端进程中,真正干活的executor在yarn容器内 - SparkOnYarn需要啥:
-
- yarn集群
-
- spark客户端:将spark程序提交到yarn中运行
-
- 需要被提交的代码程序(我们自己写)
-
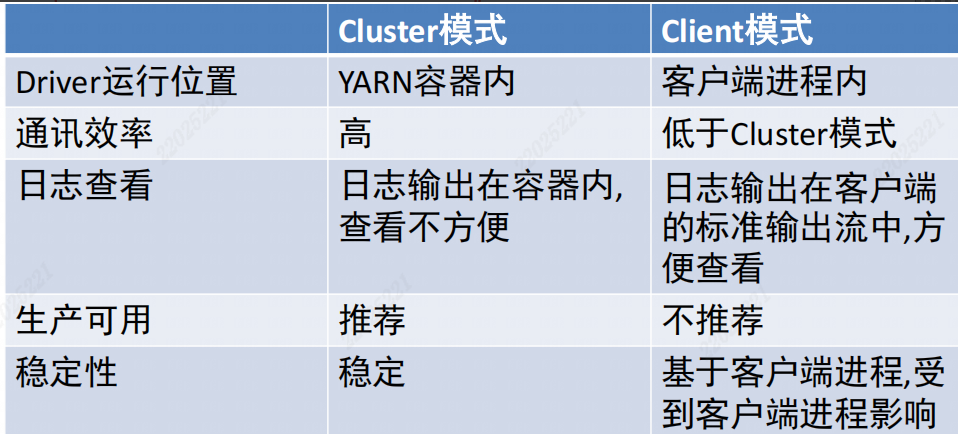
- 两种运行模式(Cluster和Client)
- Cluster模式即: Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
- Client模式即: Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
- 区别:
- 为什么需要SparkOnYarn模式:
1.4 pyspark
-
什么是pyspark:是使用python语言应用spark框架的类库,内置了完全的spark api,可以通过pyspark类库来编写spark程序
-
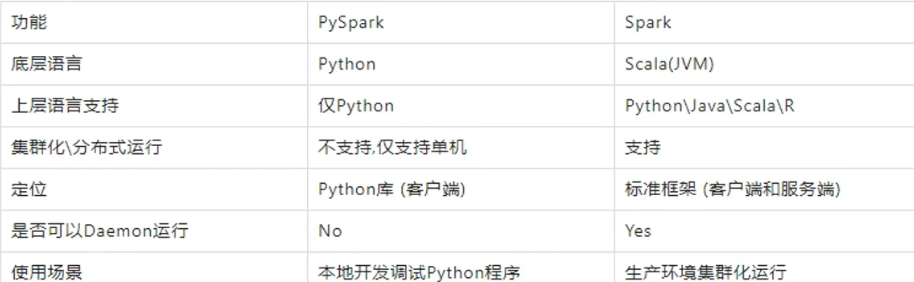
pyspark与标准spark框架的对比
-
python on spark的执行原理
pyspark宗旨是在不破坏spark已有运行架构基础上,在spark架构外层包装一层python API,借助pyj4实现python和java的交互,进行实现python编写spark的应用程序
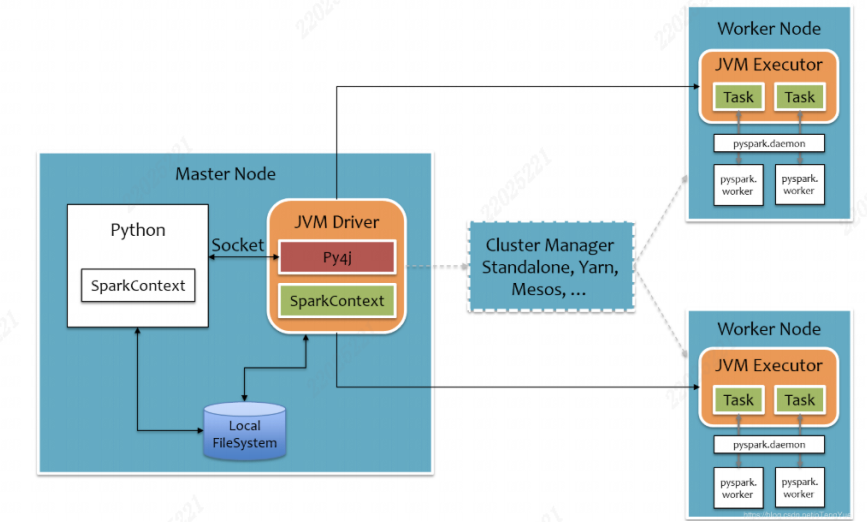
在driver端,python的driver代码会翻译成JVM代码,由py4j模块完成,再执行JVM driver运行,转化后的代码传到worker,但由于使用java语言所能使用的算子太少,不好翻译,于是使用pyspark.daemon守护进程做一个中转站,在底层的executor执行,执行的是python语言。
即python–>JVM代码–>JVM Driver–>调度JVM Eexcutor–>pyspark中转–>python executor进程
二 SparkCore
2.1 RDD介绍
-
为什么需要RDD:
分布式计算需要分区控制、Shuffle控制、数据存储\序列化、数据计算API等一些列功能,而python中的本地集合对象(如list、set等)不能满足,所以在分布式框架中,需要一个数据抽象对象,实现分布式计算所需功能,这数据抽象就是RDD -
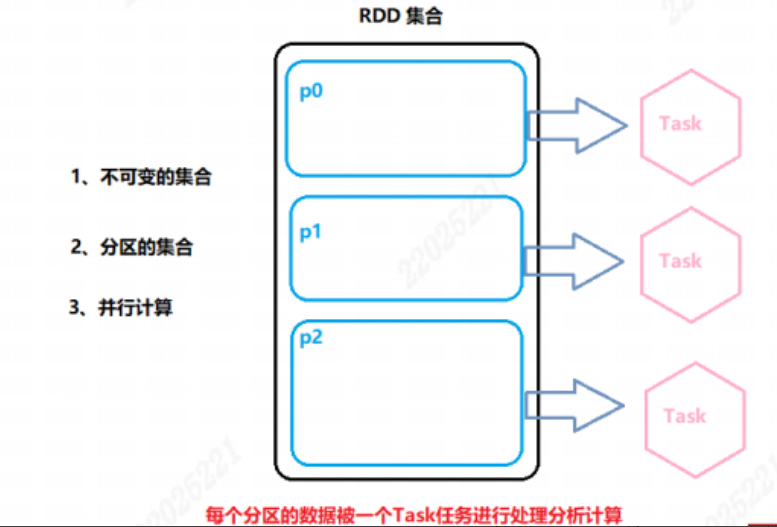
RDD(Resilient Distributed Dataset,弹性分布式数据集)是Spark中最基本的数据抽象,代表一个不可变、可分区、可并行计算的集合
- Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中
- Dataset:一个数据集合,用于存放数据的。
-
RDD的五大特性
- RDD是有分区的
- RDD的方法会作用到所有分区上
- RDD之间是有相互依赖关系的(RDD有血缘关系)
- Key-Value型的RDD可以有分区器
- RDD的分区规划,会尽量靠近数据所在的服务器上
2.2 RDD编写
-
程序入口SparkContext对象
RDD编程的程序入口对象是SparkContext,基于它才能调用API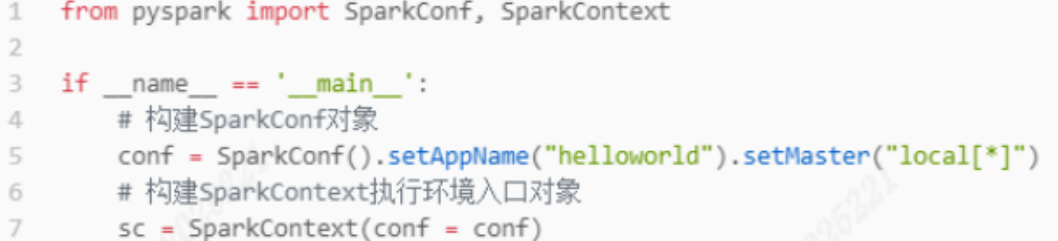
-
RDD创建(两种方式)
- 通过并行化集合创建,rdd = sc.parallelize()
- 读取外部数据源, rdd = sc.textFile();rdd=sc.wholeTextFile()
-
算子
分布式集合对象上的API,叫做算子,分为两类:transformation算子、action算子,transformation算子是懒加载的,如果没有action算子启动,它是不工作的。transformation算子相当于在构建执行计划,action是一个指令,让这个计划开始工作- transformation算子
- action算子
- 学习地址: https://spark.apache.org/docs/latest/api/python/reference/pyspark.html
2.3 RDD算子
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.html
2.4 RDD的持久化
RDD数据是过程数据,一旦处理完成,就会清理,这特性是为了最大化利用资源,给后续计算腾出资源
2.4.1 为什么需要缓存和检查点机制?
如果在后续过程中还应用到计算过rdd数据,对其缓存,实现多次利用,这样就不用再重新计算。如果不进行缓存,RDD会依据血缘关系重新计算,耗费了时间
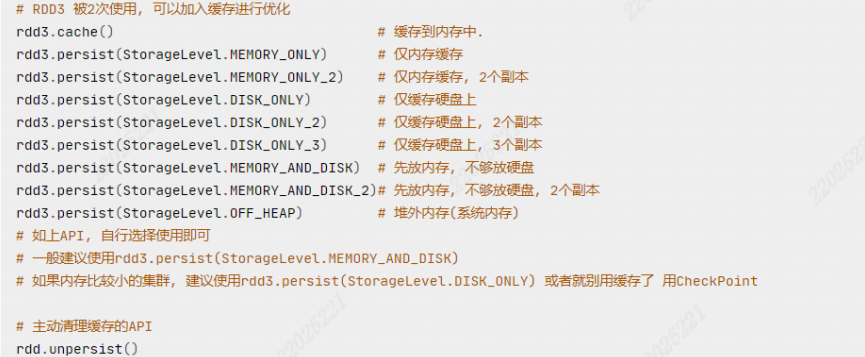
2.4.2 缓存
特点:
- 缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上
- 这个保存在设定上是认为不安全的,认为有丢失的风险
- 缓存保留RDD之间的血缘关系,缓存一旦丢失,可基于血缘关系,重新计算RDD的数据
缓存如何丢失:
- 断电、计算任务内存不足,把缓存清理给计算让路
- 硬盘损坏也可能造成丢失
缓存是如何保存的:每个分区自行将其数据保存在其所在的Executor内存和硬盘上,即分散存储
2.4.3 检查点机制(CheckPoint)
- 也是保存RDD数据,仅支持硬盘存储
- 它被设计认为是安全的,不保留血缘关系
- CheckPoint存储RDD数据,是集中收集各个分区数据进行存储,存储在HDFS上

2.4.4 缓存和CheckPoint的对比
- CheckPoint不管多少分区,风险是一样的,缓存分区越多,风险越大
- CheckPoint支持写入HDFS,缓存不行,HDFS是高可靠存储,所以CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以,缓存是写入内存,性能比CheckPoint要好一些
- CheckPoint因为设计上认为是安全的,所以不保留血缘关系,而缓存因为设计上认为是不安全的,所以保留
2.4.5 注意
- CheckPoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,或者数据量很大,采用它比较合适,如果数据量小,计算快,就没有必要了,直接使用缓存就行
- cache和checkpoint两个API都不是Action类型,所以想要其工作,需要后面接上Action,这样做的目的是为了让RDD有数据
2.5 RDD的共享变量
2.5.1 广播变量
为什么使用广播变量?
A表是一张维度表,B表是一张明细表,是RDD对象,两表做关联,A需要被发送到每个分区的处理线程上使用,如果在一个executor内,也就是一个进程中,有多个线程,因为executor是进程,进程内资源共享,进程中只保留一个表A即可,也就是说没必要每个线程上都有表A(这样会造成内存浪费),广播变量就是为了这个问题

使用方式

2.5.2 累加器
-
需求:想要对map算子计算中的数据,进行计数累加,得到全部数据计算完后的累加结果
-
累加器对象架构方式:sc.accumulator(初始值)构建,这个对象可以从各个Executor中收集他们的执行结果,作用回自己身上
-
需要注意的是:使用累加器时,要注意,因为rdd是过程数据,如果rdd被多次使用,可能会重建此rdd,如果累加器累加代码在重新构建的步骤中,累加器累加代码就可能被多次执行
2.6 Spark的内核调度(重点)
2.6.1 DAG(有向无环图)
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心的重要一环,管理任务调度,就是如何组织任务去处理RDD每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效完成任务计算
- 1个Action=1个DAG=1个JOB
- 层级关系:(一个代码运行起来,就是一个application)
1个Application,可以有多个JOB,每一个JOB内含一个DAG,同时每一个JOB都是由一个Action产生
2.6.2 DAG的宽窄依赖和阶段划分
- 宽依赖:父RDD的一个分区,全部数据发送给子RDD的一个分区
- 窄依赖(即shuffle):父RDD的一个分区,将数据发送给子RDD的多个分区
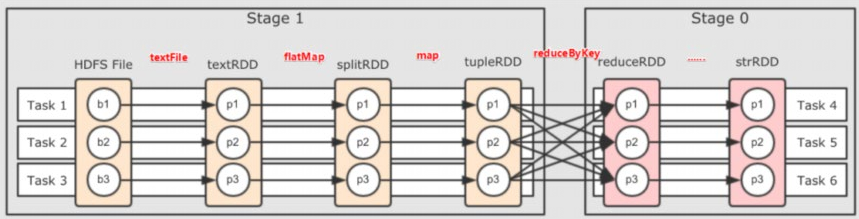
按照宽依赖,划分不同的DAG阶段,从后向前,遇到宽依赖就划分出一个阶段stage,stage内部一定都是窄依赖
2.6.3 内存迭代计算
-
spark默认受全局并行度的限制,除了个别算子的特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数
-
Spark为什么比MapReduce快:
- spark的算子丰富,而mapreduce缺乏算子,使其很难处理复杂任务
- spark可以执行内存迭代,算子之间形成DAG,基于依赖划分阶段,在阶段内形成迭代管道,而mapreduce的map和reduce之间交互式通过硬盘交互的
2.6.4 Spark并行度
- 在同一时间内,有多少个task在同时进行
- 全局并行度配置:spark.default.parallelism 全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建,或者会产生额外的shuffle
- 如何在集群中规划并行度:设置为CPU总核心的2-10倍
2.6.5 Spark任务调度

- DAG调度器:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
- Task调度器:基于DAG Scheduler的产出,来规划这些逻辑的task,应该在那些物理的executor上运行,以及监督管理它们的运行
三 SparkSql
3.1 SparkSQL概述
-
SparkSQL用于处理大规模结构化数据的计算引擎,在企业中广泛应用,性能极好
-
支持SQL语言\性能强\可以自动优化\API简单\兼容HIVE等等
-
应用场景:离线开发、数仓搭建、科学计算、数据分析
-
特点
- 融合性:SQL可以无缝集成在代码中,随时用SQL处理数据
- 统一数据访问:一套标准API可读写不同数据源
- HIVE兼容:spark直接计算生成hive数据表
- 支持标准的JDBC\ODBC连接,方便各种数据库进行交互
-
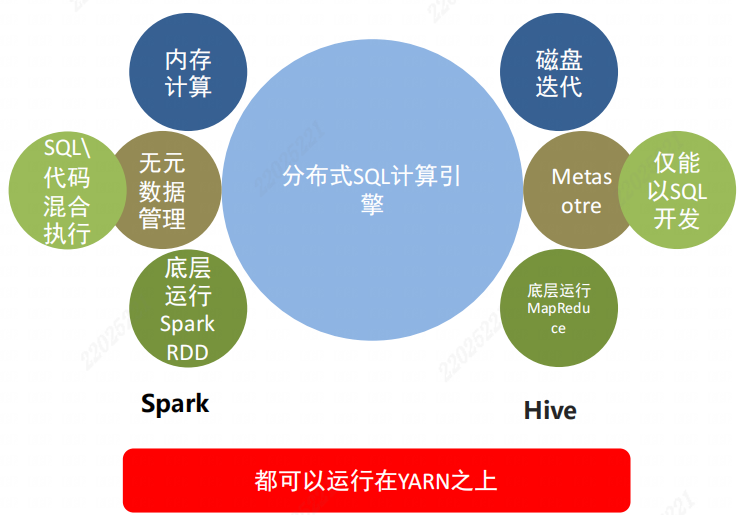
SparkSQL和Hive的不同
3.2 DataFrame
- DataFrame是SparkSQL的数据抽象,存储的是二维表结构数据
- DataFrame和RDD比较:
rdd可以存储任意结构的数据,dataframe存储二维表结构化数据
dataframe和rdd是:弹性的,分布式的,数据集
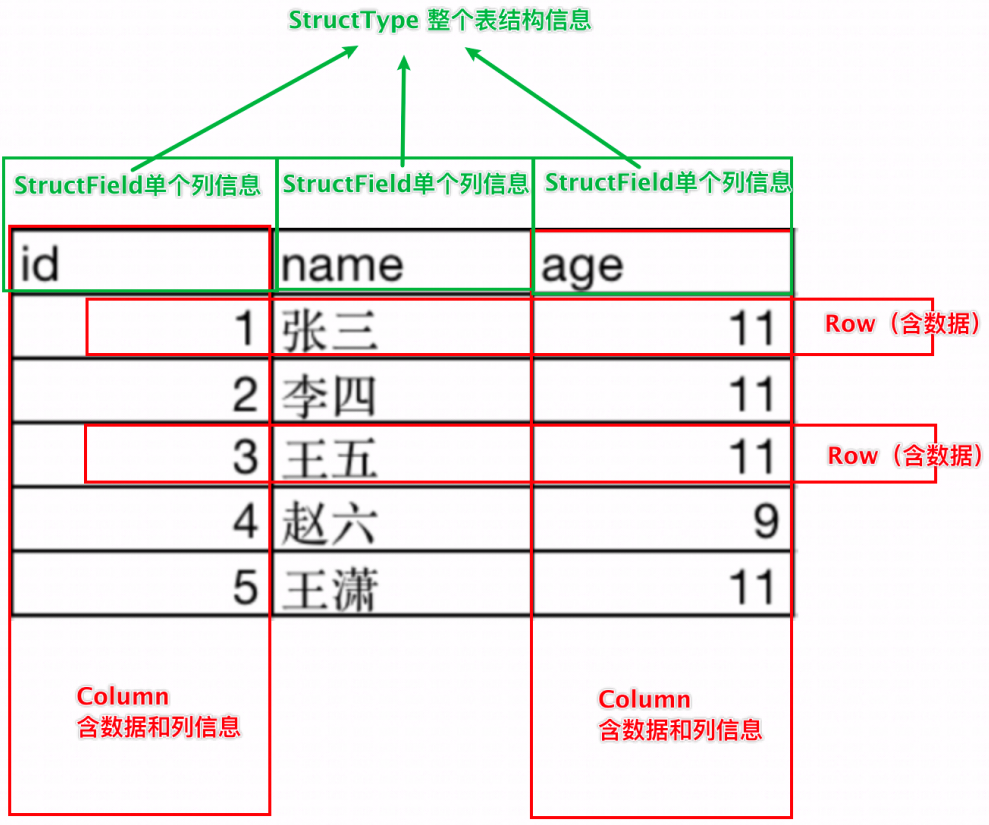
3.2.1 DataFrame组成
-
dataframe是二维表结构,离不开行、列、表结构描述
-
表结构层面:
- StructType对象:描述整个DataFrame的表结构
- StructField对象:描述一个列的信息
-
数据层面:
- Row对象:记录一行数据
- Column对象:记录一列数据并包含列的信息
将RDD转换为DataFrame:因为RDD和dataframe都是分布式数据集,只需要转换一下内部存储结构,转换为二维表结构,有三种转换方式
3.2.2 两种编程风格DSL\SQL
- 两种编程风格(DSL\SQL):DSL处理数据的灵活性更强,可以通过自定义函数处理非结构化数据;SQL使用sql语句只能处理结构化数据
官方文档: https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/index.html
3.2.3 全局表和临时表
-
跨SparkSession对象使用,一个程序内多个SparkSession中均可使用,查询前带上前缀 global_temp.
-
临时表:只在当前SparkSession中可用
3.3 SparkSQL函数定义
3.3.1 三种类型:UDF\UDAF\UDTF
-
udf:一对一的关系,输入一个值经过函数以后输出一个值;在hive中继续udf类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法
-
udaf:聚合函数,多对一的关系,输入过个值输出一个值,通常与groupBy联合使用
-
udtf:一对多的关系,输入一个值输出多个值(一行变多行);用户自定义生成函数,有点像flatMap
3.3.2 两种定义方式
-
sparksession.udf.register()
注册的udf可以用于DSL和SQL,返回值用于DSL风格,传参内给的名字用于SQL风格 -
pyspark.sql.funcations.udf
仅能用于DSL风格
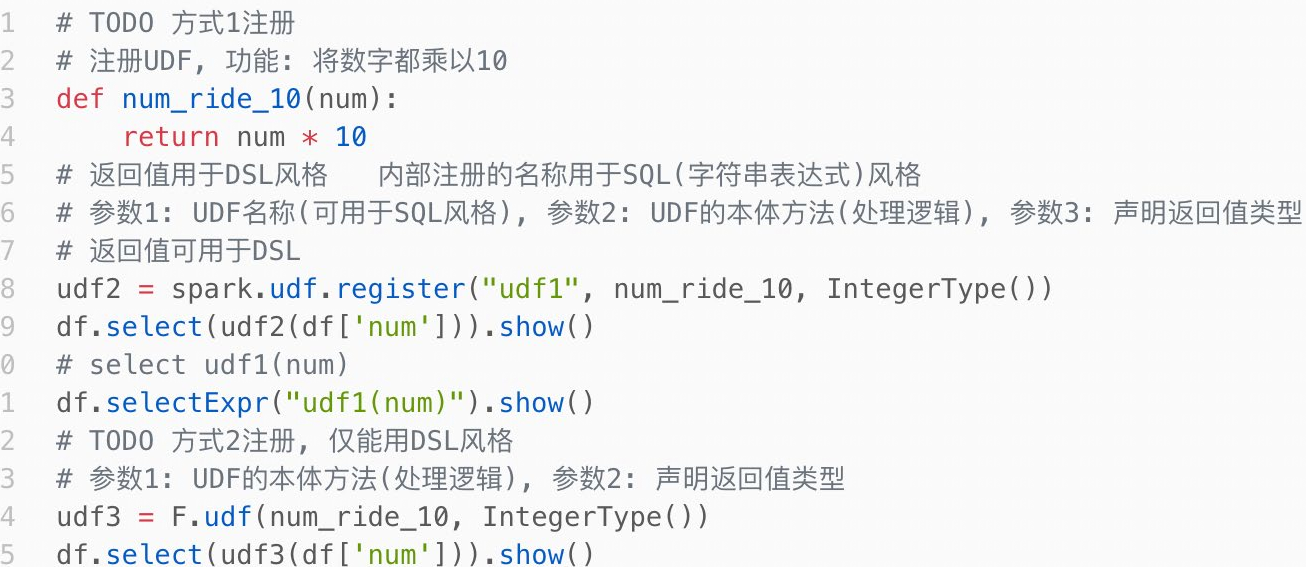
3.3.3 开窗函数

3.4 SparkSQL的执行流程
-
RDD执行流程回顾
- RDD(代码)–>DAG调度器逻辑任务–>Task调度器任务分配和管理监控–>worker干活
-
SparkSQL自动优化
- RDD的运行会完全按照开发者的代码执行,如果开发者水平有限,RDD的执行效率也会受到影响,而SparkSQL会对写完的代码,执行“自动优化”,以提升代码运行效率,避免开发这水平影响到代码执行效率
-
为什么SparkSQL可以自动优化,而RDD不可以
- RDD:内含数据类型不限格式和结构,难以形成统一
- DataFrame:100%是二维表结构,可以被针对
-
SparkSQL的自动优化:依赖于CataLyst优化器
3.4.1 CataLyst优化器

- CataLyst是为了解决过多依赖hive的问题,具体流程:
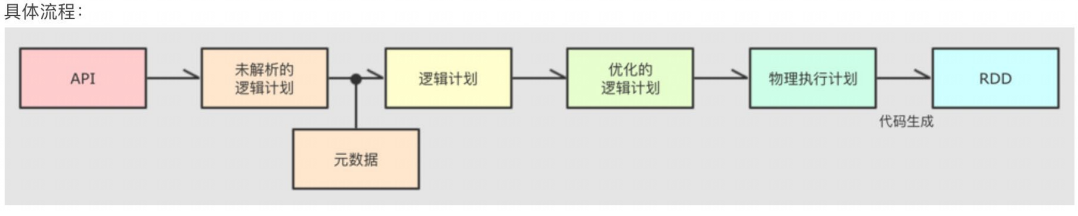
- 优化方向:断言下推(行过滤,提前where),列值裁剪(列过滤,提前规划select的字段数量)
- SparkSQL执行流程
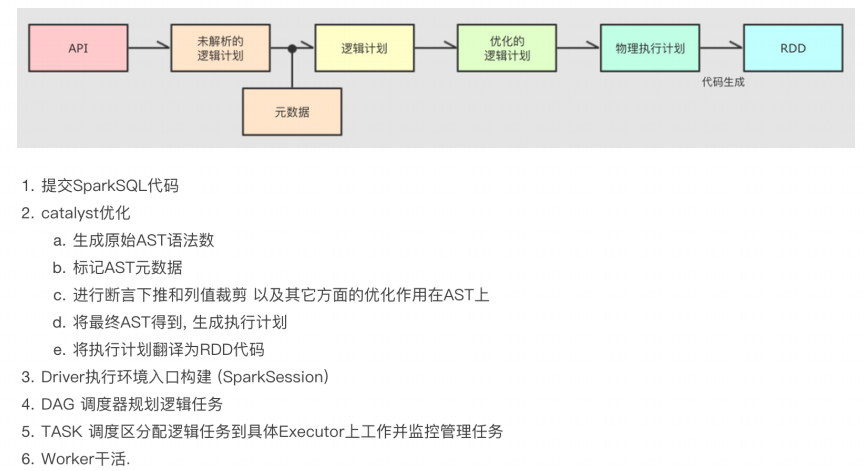
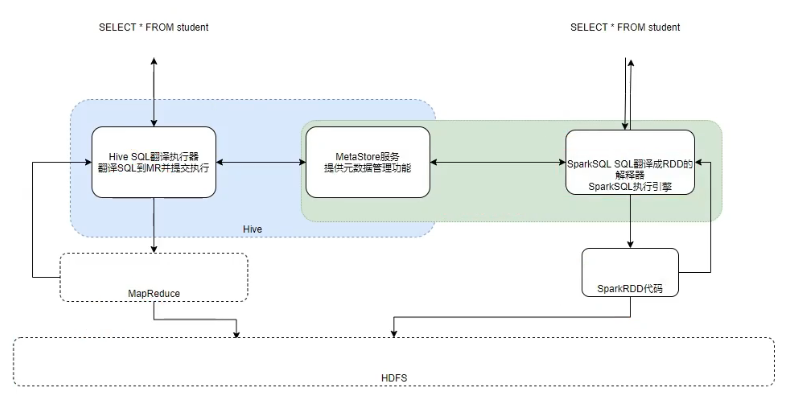
3.5 SparkSQL整合Hive
本质上sparksql借助hive的元数据管理功能,实现对表结构的读取,然后通过执行RDD代码执行读取HDFS的数据,所以说spark连接上hive的MateStore即可