机器学习之二:指导式学习
正如人们有各种各样的学习方法一样,机器学习也有多种学习方法。若按学习时所用的方法进行分类,则机器学习可分为机械式学习、指导式学习、示例学习、类比学习、解释学习等。这是温斯顿在1977年提出的一种分类方法。
有关机器学习的基本概念,可看我文章:机器学习的基本概念-CSDN博客
有关机械式学习,可看我文章:机器学习之一:机械式学习-CSDN博客
接下来我们先探讨第二种:指导式学习。
一、什么是指导式学习
(一)基本思想与定义
1. 基本思想
指导式学习(Directed Learning),又称监督学习(Supervised Learning),是机器学习中最经典的范式之一。其核心思想是通过 带标签的训练数据 指导模型学习输入与输出之间的映射关系,即从已知的“输入 - 输出对”中归纳出普遍规律,进而对未知输入进行预测。这种学习方式如同学生在教师的明确指导下学习,训练数据中的标签(如分类类别、回归目标值)相当于教师提供的“标准答案”,模型通过分析这些“例题”与“答案”的对应关系,掌握解决问题的能力。
指导式学习的关键在于利用显式监督信号调整模型参数,使模型能够泛化到未见过的数据。其核心流程包括:
(1)数据层面:输入特征空间 X 与输出标签空间 Y 的映射关系由训练集![]() 显式定义;
显式定义;
(2)模型层面:通过假设空间![]() 定义可能的映射函数,其中θ为模型参数;
定义可能的映射函数,其中θ为模型参数;
(3)优化层面:通过损失函数 L(f(x), y) 度量预测误差,利用优化算法(如梯度下降)最小化经验风险 ![]() 。
。
2. 形式化定义
给定训练数据集![]() ,其中
,其中![]() 为 d 维特征向量,
为 d 维特征向量,![]() 为标签(分类任务中 Y = {1, 2, ..., C},回归任务中
为标签(分类任务中 Y = {1, 2, ..., C},回归任务中![]() )。指导式学习的目标是从假设空间 F 中选择一个函数
)。指导式学习的目标是从假设空间 F 中选择一个函数,使得在新样本
上的期望风险
![]() 最小化。
最小化。
核心公式:
(1)经验风险最小化(ERM):
![]()
(2)损失函数示例:
1)回归任务(均方误差,MSE):![]()
2)二分类任务(交叉熵损失):![]()
3)多分类任务(Softmax交叉熵):![]() ,其中
,其中为真实标签的独热编码,
为预测概率。
3. 与其他学习范式的区别
(1)对比机械式学习:指导式学习通过归纳而非简单记忆实现泛化,能处理未见过的输入(如线性模型通过参数拟合新样本),而机械式学习仅能检索已知输入;
(2)对比无监督学习:指导式学习依赖显式标签,而无监督学习仅利用无标签数据发现内在结构(如聚类、降维);
(3)对比强化学习:指导式学习的监督信号是静态标签,而强化学习的监督信号是延迟奖励,且需与环境交互。
(二)表示形式与实现过程
1. 模型表示形式
指导式学习模型可分为 参数化模型 和 非参数化模型,其核心区别在于是否通过固定数量的参数描述映射关系。
(1)参数化模型
定义:假设空间由有限维参数 θ决定,模型形式为 f(x; θ),如线性模型、神经网络。
示例:
线性回归:![]() ,参数为
,参数为 ![]() (权重)和
(权重)和![]() (偏置);
(偏置);
逻辑回归:![]() ,其中
,其中![]() 为 Sigmoid 函数,用于二分类;
为 Sigmoid 函数,用于二分类;
神经网络:多层非线性变换,如隐藏层![]() ,输出层
,输出层![]() ,参数为所有层的权重 W 和偏置 b。
,参数为所有层的权重 W 和偏置 b。
(2)非参数化模型
定义:假设空间不依赖固定参数,模型复杂度随数据量增长,如决策树、支持向量机(SVM)、最近邻算法。
示例:
决策树:通过递归划分特征空间生成树结构,节点为特征判断条件,叶子节点为预测结果(如ID3算法基于信息增益分裂节点);
支持向量机:通过最大间隔超平面分类,决策函数为![]() ,其中 w 和 b 由支持向量决定,隐含无限维参数(通过核函数映射到高维空间)。
,其中 w 和 b 由支持向量决定,隐含无限维参数(通过核函数映射到高维空间)。
2. 实现过程
指导式学习的实现可分为 数据预处理、模型构建、训练优化、评估部署 四大核心步骤,每个步骤包含具体技术细节。
(1)数据预处理
数据清洗:去除噪声样本、处理缺失值(如均值填充、删除含缺失样本);
特征工程:
1)数值型特征:归一化(![]() )或标准化(
)或标准化(![]() );
);
2)类别型特征:独热编码(One-Hot Encoding,如颜色特征“红、绿、蓝”转换为三维二进制向量);
3)文本特征:词袋模型(Bag-of-Words)或 TF-IDF(词频 - 逆文档频率),如将句子转换为词频向量;
4)数据集划分:将数据分为训练集(80%)、验证集(10%)、测试集(10%),用于模型选择和泛化能力评估。
示例:房价数据预处理
输入特征包含“面积(平方米)”和“房龄(年)”,标签为“价格(万元)”:
归一化面积:![]() (假设面积范围 50-200㎡);
(假设面积范围 50-200㎡);
标准化房龄:![]() ,其中 μ_age 为房龄均值,σ_age 为标准差。
,其中 μ_age 为房龄均值,σ_age 为标准差。
(2)模型构建
任务类型选择:
1)回归任务:输出连续值,选择线性回归、随机森林回归等;
2)分类任务:输出离散类别,选择逻辑回归、SVM、神经网络等;
模型架构设计:
1)参数化模型需定义网络层数、神经元数量、激活函数(如ReLU、Sigmoid);
2)非参数化模型需设定超参数(如决策树的最大深度、SVM 的核函数类型)。
示例:二分类模型架构
使用逻辑回归模型,输入层维度 d=10(10 维特征),输出层为 Sigmoid 函数,输出概率值 p ∈ [0, 1],通过阈值 0.5 判断类别。
(3)训练优化
损失函数定义:根据任务类型选择损失函数(如回归用MSE,分类用交叉熵);
优化算法:
1)梯度下降家族:批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(Mini-Batch SGD);
2)自适应算法:Adam(结合动量和 RMSprop)、AdaGrad;
正则化:防止过拟合,如 L2 正则化(权重衰减)![]() ,L1 正则化
,L1 正则化![]() 。
。
SGD算法流程:
1)初始化参数 (如全零或随机初始化);
2)对每个epoch,随机打乱训练集;
3)对每个小批量数据,计算梯度
![]() ;
;
4)更新参数 ![]() ,其中α为学习率。
,其中α为学习率。
(4)评估部署
评估指标:
1)回归任务:MSE、均方根误差(RMSE)、决定系数;
2)分类任务:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数、AUC-ROC;
模型调整:通过验证集调优超参数(如学习率、正则化系数),使用网格搜索或随机搜索;
部署应用:将训练好的模型封装为 API,对新输入实时预测(如垃圾邮件分类系统接入邮箱服务器)。
(三)算法描述
1. 回归算法:线性回归
(1)模型假设
假设输入输出关系为线性函数:
![]()
其中![]() 为权重向量,
为权重向量,![]() 为偏置。
为偏置。
(2)损失函数
均方误差(MSE):![]()
其中![]() 为特征矩阵,
为特征矩阵,![]() 为全 1 向量,
为全 1 向量,![]() 为标签向量。
为标签向量。
(3)梯度计算
对权重和偏置求导:
![]()
(4)参数更新(SGD)
![]()
2. 分类算法:逻辑回归
(1)模型假设
通过Sigmoid函数将线性组合转换为概率:
![]()
二分类预测为 ![]() ,其中
,其中为指示函数。
(2)损失函数
对数似然损失(交叉熵损失):
![]()
(3)梯度计算
利用 Sigmoid 函数的导数![]() ,梯度为:
,梯度为:
![]()
3. 非参数化算法:决策树(ID3算法)
(1)核心思想
通过信息增益选择最优分裂特征,递归构建决策树。
熵:衡量数据纯度,![]() ,其中
,其中为类别 c 的样本集;
信息增益:分裂前后熵的减少量,![]() ,其中
,其中为特征 A 取值为 v 时的子集。
(2)算法流程
(1)若节点样本全属同一类别,设为叶子节点;
(2)计算所有特征的信息增益,选择增益最大的特征 A;
(3)按特征 A 的取值分裂节点,对每个子节点递归调用算法;
(4)直到信息增益为 0 或达到最大深度。
(3)示例:鸢尾花分类
特征为“花瓣长度”,标签为类别(山鸢尾、杂色鸢尾、维吉尼亚鸢尾)。
1)根节点熵
![]() ;
;
2)按花瓣长度分裂(阈值5cm),左子节点(花瓣长度< 5cm)全为山鸢尾,熵0;右子节点熵
![]() ;
;
3)信息增益 IG = 1.58 - (0.33 × 0 + 0.67 × 1) = 0.91,选择该特征分裂。
二、典型案例
案例一:塞缪尔跳棋程序的指导式学习模块
1. 案例背景
塞缪尔(Arthur Samuel)的跳棋程序(1950s)是早期机器学习的里程碑,其核心目标是通过自我对弈提升棋力。虽然整体采用强化学习思想,但其中 评估函数的训练 部分依赖指导式学习:通过人类专家对弈数据或自我对弈的高质量走法,训练一个评估函数 v(s),用于估计棋盘状态 s 的胜率。
2. 指导式学习实现
(1)数据收集
输入特征:棋盘状态编码为特征向量,包括棋子位置、控制区域、历史走法等(约100维特征);
输出标签:由专家或高质量对弈生成的状态价值 y ∈ [0, 1](0 表示必输,1 表示必胜)。
(2)模型选择
使用 线性评估函数:![]() ,其中
,其中![]() 为状态特征向量,w 为权重向量。
为状态特征向量,w 为权重向量。
(3)训练过程
1)损失函数:均方误差,目标是使评估函数输出接近真实价值 y;
2)优化算法:批量梯度下降,利用自我对弈生成的大量状态-价值对更新权重;
3)泛化策略:通过交叉验证调整正则化参数,避免过拟合棋盘的特定布局。
(4)流程说明
1)状态编码:将棋盘转化为特征向量![]() ,例如统计各区域棋子数、国王数量等;
,例如统计各区域棋子数、国王数量等;
2)数据生成:程序与自身对弈,记录中间状态,对关键状态由人工或高分策略赋予价值标签;
3)模型训练:使用梯度下降最小化![]() ,得到权重
,得到权重 ;
4)对弈应用:在选择走法时,对每个候选状态 s' 计算![]() ,选择价值最高的走法。
,选择价值最高的走法。
3. 技术创新与局限
创新点:首次将指导式学习用于序列决策任务,通过状态特征工程构建评估函数;
局限:依赖人工设计特征,泛化能力有限(仅适用于跳棋规则),且未处理动态环境中的概念漂移。
案例二:工业设备故障预测(现代工程应用)
1. 案例背景
某工厂需对电机设备进行故障预测,通过传感器采集振动信号、温度、电流等数据,利用指导式学习模型提前识别异常状态,降低停机损失。
2. 数据准备
(1)特征工程
原始数据:每秒采集1000个振动信号样本(时域数据),转换为频域特征(通过傅里叶变换计算各频率分量的能量);
衍生特征:计算统计量(均值、方差、峰度)、时频域特征(如梅尔频率倒谱系数,MFCC),最终得到50维特征向量。
(2)标签定义
正常状态(标签 0):设备运行无异常;
早期故障(标签 1):轴承磨损、转子不平衡等初期故障;
严重故障(标签 2):设备即将停机的临界状态。
3. 模型构建与训练
(1)模型选择
采用 多层卷积神经网络(CNN),利用卷积层提取信号的局部特征,全连接层完成分类:
1)输入层:50维特征向量(展平为1×50的矩阵);
2)卷积层:32个3×1卷积核,提取相邻特征的相关性;
3)池化层:最大池化降维;
4)输出层:Softmax激活函数,输出三类概率。
(2)训练细节
损失函数:多分类交叉熵;
优化器:Adam(学习率 0.001);
数据增强:对振动信号添加高斯噪声、时间偏移,提升泛化能力;
早停策略:当验证集损失连续 5 轮不下降时停止训练,避免过拟合。
(3)训练流程代码(Python 伪代码)
python代码:
import tensorflow as tffrom sklearn.preprocessing import StandardScaler# 数据预处理scaler = StandardScaler()X_train = scaler.fit_transform(X_train) # 标准化特征X_test = scaler.transform(X_test)# 构建模型model = tf.keras.Sequential([tf.keras.layers.Reshape((50, 1), input_shape=(50,)), # 转换为时间序列格式tf.keras.layers.Conv1D(32, kernel_size=3, activation='relu'),tf.keras.layers.MaxPooling1D(pool_size=2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(3, activation='softmax')])# 编译与训练model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])history = model.fit(X_train, y_train,epochs=50,batch_size=32,validation_split=0.2,early_stopping=tf.keras.callbacks.EarlyStopping(patience=5))4. 模型评估与部署
评估指标:测试集准确率 98.2%,各类别召回率均 > 95%;
部署方式:将模型转换为 TensorFlow Lite 格式,嵌入设备边缘计算模块,实时接收传感器数据并输出故障概率;
实际效果:提前 72 小时检测到轴承磨损故障,使计划维护成本降低 40%。
案例三:自然语言处理——情感分析(NLP典型应用)
1. 案例背景
分析电商平台用户评论,判断评论情感极性(正面、负面、中性),帮助商家改进产品和服务。
2. 数据处理
(1)文本预处理
分词:使用NLTK库将中文评论切分为词语(如“质量很好”→“质量”“很好”);
去除停用词:过滤“的”“了”等无意义词汇;
特征表示:TF-IDF向量(词汇表大小10,000),每个样本表示为10,000维稀疏向量。
(2)标签标注
人工标注评论情感:正面(1)、负面(-1)、中性(0)。
3. 模型选择:支持向量机(SVM)
(1)核函数选择
使用径向基函数(RBF)核:![]()
通过网格搜索确定超参数γ 和正则化系数 C。
(2)决策函数
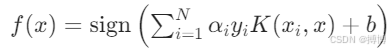
其中 为拉格朗日乘子,仅非零值对应支持向量。
4. 训练与评估
训练过程:使用 SMO(序列最小优化)算法求解SVM的对偶问题,最大化分类间隔;
评估结果:在测试集上F1分数 89.5%,中性评论识别准确率85%,显著优于基于规则的情感分析方法。
三、理论深度拓展:指导式学习的泛化理论
(一)偏差-方差分解
指导式学习模型的泛化误差可分解为偏差、方差和噪声:
![]()
其中![]() 为模型预测的期望。
为模型预测的期望。
偏差:模型对真实关系的拟合能力(欠拟合时偏差高);
方差:模型对训练数据波动的敏感度(过拟合时方差高)。
(二)VC 维与模型复杂度
VC维(Vapnik-Chervonenkis Dimen)衡量模型的假设空间容量,对于二分类模型,VC 维 d_VC 是最大可打散样本数(即能完美分类任意标签组合的最大样本数)。
线性模型的VC维为 d+1(d 为特征数);
神经网络的VC维随层数和神经元数量指数增长,需通过正则化控制复杂度。
(三)统计学习理论核心不等式
对于二分类问题,模型的泛化误差以至少 1-δ 的概率满足:
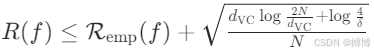
该不等式表明:样本量 N 越大、VC维 d_VC 越小,泛化误差上界越低。
总结与未来方向
1. 核心价值
指导式学习通过显式标签构建输入输出映射,是当前工业界应用最成熟的机器学习范式,支撑了图像识别、自然语言处理、金融预测等关键领域。其成功依赖于 高质量标注数据 和 合理的特征工程,而深度学习的兴起进一步提升了其处理高维复杂数据的能力。
2. 挑战与前沿
(1)数据标注成本:依赖人工标注,小样本学习(Few-Shot Learning)和自监督学习成为研究热点;
(2)可解释性:深度神经网络的“黑箱”特性限制其在医疗、金融等领域的应用,需发展可解释模型(如决策树、注意力机制可视化);
(3)动态环境适应:处理概念漂移(如用户偏好变化),需结合在线学习和迁移学习。
3. 王永庆理论的延伸
《人工智能原理与方法》中强调的“学习系统四要素”在指导式学习中体现为:
(1)学习环境:带标签的训练数据集;
(2)学习能力:模型的假设空间容量(如VC维)和优化算法效率;
(3)知识应用:通过训练好的模型对新样本预测;
(4)性能提升:通过损失函数优化和正则化提高泛化能力。
指导式学习作为机器学习的基石,其理论和方法将持续演进,与无监督学习、强化学习深度融合,推动人工智能从“有监督的专项智能”向“自主学习的通用智能”迈进。