Simple-BEV论文解析
背景
现有的工作为了避免昂贵的激光雷达,只使用多图像输入来生成BEV特征表示,忽略了radar数据;并且大多数技术都着重如何将图像特征lift到BEV平面,使用更大分辨率的输入与Backbone,这导致在多视角BEV感知下什么是最重要的这个问题缺乏研究。
贡献
- 只使用了简单的无参lift投影操作获取BEV特征图,重点研究了batch、图像分辨率、数据增强与lift策略等的影响,消融实验做的好,说明batch,图像分辨率用的好能提高指标,而lift操作的差别影响不大。
- 提出了radar+camera融合,能极好地提升指标质量,这是由于radar能识别远距离物体,并且受恶劣环境影响小
,能够与相机进行有效互补,但其数据稀疏,且有噪声。
方法
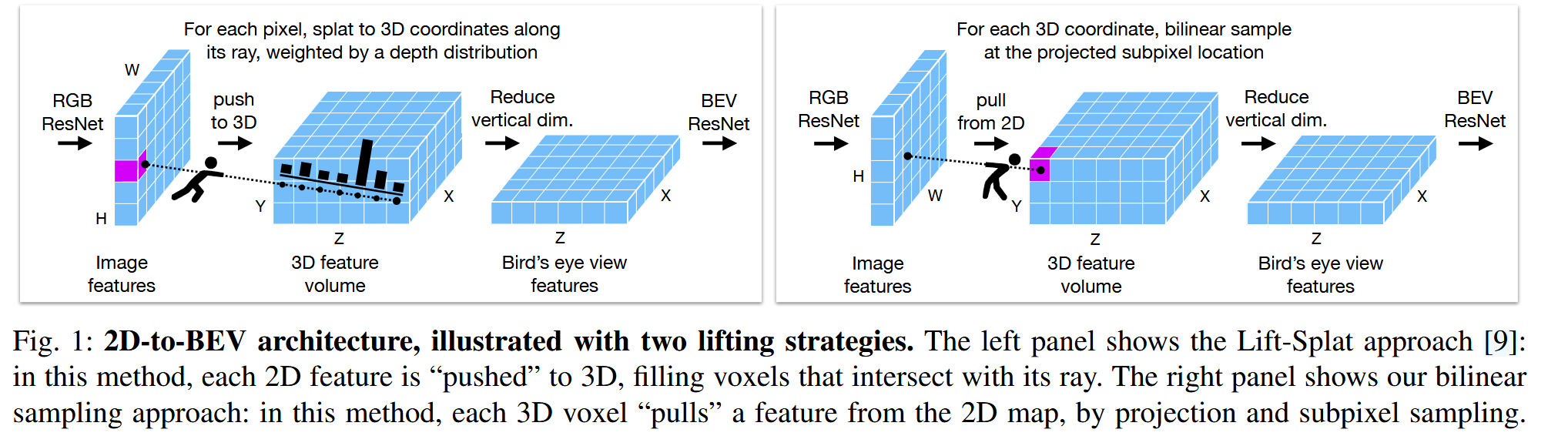
配置与总体架构
数据输入是多视角图像、radar甚至lidar,传感器内外参已知并且传感器之间很好地数据同步。模型定义3D感知范围,前后、左右100m,上下10m,平面分辨率设为200×200,高度分辨率设为8,而这个体素空间以前置摄像头为中心,左右方向为X轴,上下方向为Y轴,前后方向为Z轴。
总体架构上,使用ResNet提取每个相机的特征,将其lift到3D再拍扁成BEV,最后对BEV视角再用ResNet得到输出