对卡尔曼滤波的理解和简单示例实现
目录
一、概述
二、基本公式解释
1)状态转移方程
2)状态更新方程
3)卡尔曼系数更新方程
4)误差协方差估计方程
三、一个简单示例
一、概述
经典卡尔曼滤波算法在线性系统中运用非常广泛,可以对数据实现很好的平滑处理,降低噪声,使滤波后的数据更加接近真实值。此处不对卡尔曼滤波做深入的数学原理分析,相关的资料已经很多,只是讲解卡尔曼滤波的基本使用方法。卡尔曼滤波核心思想就是利用当前时刻的测量值与前一时刻对当前时刻的估计值进行加权求和后,得到当前时刻的最优值,这个值被认为是最接近真实值的结果。
二、基本公式解释
卡尔曼基本公式有5个,分别是估计和更新两部分。估计公式如下:
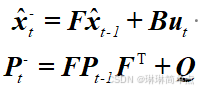
更新公式如下:
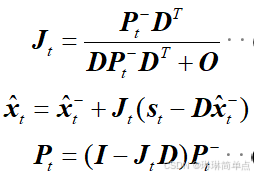
1)状态转移方程
估计公式中的第一个方程称为状态转移方程,它的作用是利用前一时刻的最优估计值计算当前时刻的估计值。公式中,F为状态转移矩阵,B为控制矩阵,u为控制量,x为状态量,这些量均为矩阵形式。状态转移方程具体如何构造,则与实际对象直接相关。比如对一个直线运动的物体,对不同时刻下测得的距离数据进行滤波处理。我们首先需要做的就是构建卡尔曼滤波需要使用到的状态转移方程,就是如何利用前一时刻的状态得到当前时刻的状态。很明显,这里最直观的状态量就是距离,那么如何通过前一个距离得到下一个距离呢?很自然我们会想到在这个场景中物体的运动可能满足这个数学模型r1=r0+v*dt。这是一个最简单的匀速直线运动数学模型,用它就可以关联起前后两个时刻的距离信息。为了说明的简单,这里我们就默认已知这个运动就是匀速直线运动,不考虑加速度,考虑也只是状态量的维度增加而已。
那么如何将这个数学模型转换为状态转移方程呢?首先我们要搞清楚方程中每个变量的实际含义:
u为控制量,它是从上一个状态到下一个状态期间,外界额外施加的影响,比如在当前这个场景中额外施加一个变化的力,这个力会影响距离值。此处没有这个影响,所以u直接取0。
B为控制矩阵,就是将这个u转换为我们所需要的状态量所使用的转换矩阵,它反映了u和x之间的关系。此处也可以不需要。
x为状态量,是卡尔曼滤波的关键。直观的我们是要得到物体的距离,所以很自然会将距离纳入到状态向量中,但是在这个场景中状态向量不仅包含距离。从数学模型中我们看到,模型中还用到了速度v和时间间隔dt。我们知道这个dt是用来表征过程的,不属于物体的状态,而v表征的是物体的速度,所以在此模型中,状态向量x应为x = [r;v],构造为列向量。那么根据这个数学模型,我们就可以写出状态转移方程F为:
![]()
通过对状态转移方程的说明,可知道:构造状态转移方程的前提是假设出实际场景中前后状态之间的数学模型,这个模型可以不是绝对准确,但要基本要反映前后状态的关系。如果不知道前后状态之间有何关系,不能提供一个符合度较好的数学模型,则是不能继续后续工作,也就不能使用卡尔曼滤波了。再者就是状态向量是根据数学模型分析出来的,它包含测量量,也可以包含未测量的量,如v。或许有人会问这个未测量的量怎么赋值,这个不用担心,我们只需提供一个初始随机值,在后续计算中这个值会逐渐趋于稳定(如果场景真是一个匀速运动)。
2)状态更新方程
此处跳过其它方程而直接对状态更新方程进行说明,主要是遵循卡尔曼滤波的核心思想,便于更好理解滤波的具体实现流程。状态转移方程利用前后时刻状态之间的关系,通过使用上一时刻的最优估计值得到了对当前时刻的估计值,当然这个值不是真实值。我们也不可能得到真实值,但我们希望最终能够得到最接近真实的值。
状态更新方程就是将估计值与测量值进行叠加,得到对当前时刻的最优估计结果。在状态更新方程中,J就是卡尔曼系数、s就是测量的状态量、D是观测矩阵。
卡尔曼系数J:从状态更新方程的形式上我们可以看出,J其实表征了观测量和估计量在最终的最优估计中所占比重的大小,J越大,则观测量占比重越大,反之越小。其计算后续再说明。
观测量s 就是测得的距离值。
观测矩阵D表示状态量与观测量之间的关系,在此处,观测量s只有一个距离r,而状态量包括r和v,所以,要将状态量x转换到观测量s的形式需要一个矩阵D,在此处D=[1 0],因为只需要保留状态量中的距离值。
3)卡尔曼系数更新方程
更新方程中的第一个方程即为卡尔曼系数更新方程,这个方程表示了卡尔曼系数的计算方法,也表针该系数在每步滤波后都会重新计算。式中,P为误差协方差矩阵,O为测量噪声协方矩阵。结合估计方程中的第二个计算P的方程,从形式上看,我们可以简单理解为,卡尔曼系数反映了在测量噪声和状态噪声中,状态噪声所占的比重。结合前面的分析,我们可以发现下面的关系:
状态噪声——卡尔曼系数——观测量占比,这三个量呈正相关关系,也就是说,如果状态噪声越大,那么观测量在最优估计值中的占比也就越大。这正与我们的期望是一致的,即如果状态噪声过大,说明我们建立的模型不够准确,状态转移方程会引入较大的估计误差,因此我们更愿意相信测量的结果。上述关系对应测量噪声O正好相反。
下面再说明卡尔曼系数更新方程中参数的取值,此处只说明测量噪声O,或者叫观测噪声。这个参数在此处就是一个常数,因为我们只有一个观测量。它的大小是多少需要根据实际情况来设定,而不是通过计算得来的,它表示的是我们仪器的测量误差,也就是测量噪声。
4)误差协方差估计方程
估计方程中的第二个方程就是误差协方差估计方程,该方程用于估计误差协方差矩阵P。P反映的是我们的状态估计量的误差之间的相关性,同时包含了估计误差的大小,方程中加入了状态转移噪声协方差矩阵Q,反映了不同状态变量之间的噪声关系,它的取值有一些经验公式。
在滤波过程中,P是在不断变化的,它的初始值对滤波初期的影响较大,它反映了对初始估计值的可信程度,设置不合理可能导致滤波初期误差偏大。
三、一个简单示例
以下是基于MATLAB实现的一个简单示例,加载的数据文件包含3列数据,分别是时间、距离和速度,滤波只使用了时间、距离信息。在滤波过程中对速度进行了估计,并比对速度估计结果。
clear;
clc;
weizhi = load("weizhi-int.txt");
t = weizhi(:,1);
z = weizhi(:,2);
V_true = weizhi(:,3);%提取出真实速度
%plot(t,z);
count = length(weizhi(:,2));
%noise = randn(1,count)*50;
%z = z + noise';
%首先初始化相关参数
H = [1 0];%测量矩阵
F = [1 0.05;0 1];%状态转移矩阵
dt = 0.05;
sigma_a = 200;
Q = [dt^4/4 dt^3/2; dt^3/2 dt^2] * sigma_a^2;%过程噪声
R = 0.1;%测量噪声
P = [1 0; 1 0];%初始状态协方差矩阵
I = eye(2);
% 初始化
x_true = [0; 0]; % 真实状态 [位置; 速度]
x_est = [z(1); 0]; % 估计状态
estimations = zeros(2,count);
estimations(:,1) = z(1);
R_pre = zeros(1,count);%存放位置预测值
Rerror = zeros(1,count);%存放位置预测误差
V_pre = zeros(1,count);%存放速度估计值
V_error = zeros(1,count);%存放速度估计误差
%开始计算
for i = 1:count%%预测x_pred = F * x_est;%对当前位置的预测值P_pred = F * P * F' + Q;% --- 更新步骤 ---K = P_pred * H' / (H * P_pred * H' + R); % 卡尔曼增益x_est = x_pred + K * (z(i) - H * x_pred);%得到最优估计值P = (I - K * H) * P_pred;%更新协方差矩阵% 存储估计结果estimations(:,i) = x_est;%当前位置的最优估计结果R_pre(i) = x_pred(1);Rerror(i) = x_pred(1)-z(i);if i > 20%取1s间隔估计速度V_pre(i) = x_pred(1)-R_pre(i-20);elseif i > 1V_pre(i) = (x_pred(1)-R_pre(1))/(0.05*(i-1));endendV_error(i) = V_pre(i)-V_true(i);
end
figure(1);
subplot(2,1,1);
plot(t,z);
hold on;
plot(t,R_pre,'.');
%plot(t,estimations(1,:),'.');
legend("测量值","预测值");
xlabel("时间(s)");
ylabel("距离(m)");
grid on;
subplot(2,1,2);
plot(t,Rerror,'.');
xlabel("时间(s)");
ylabel("距离预测误差(m)");
grid on;
figure(2);
subplot(2,1,1);
plot(t,V_pre,'.');
hold on;
plot(t,V_true);
legend("估计值","实测值");
xlabel("时间(s)");
ylabel("速度(m/s)");
grid on;
grid on;
subplot(2,1,2);
plot(t,V_error,'.');
xlabel("时间(s)");
ylabel("速度估计误差(m)");
grid on;