priority_queue的学习
priority_queue的介绍
- 优先级队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
- 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
- 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
- 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
- empty():检测容器是否为空
- size():返回容器中有效元素个数
- front():返回容器中第一个元素的引用
- push_back():在容器尾部插入元素
- pop_back():删除容器尾部元素
- 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
- 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。
它的主要特点是:
- 最大堆实现:
priority_queue默认是一个最大堆,这意味着最高优先级的元素(最大值)总是位于队列的前端。 - 不直接支持索引访问:与数组或向量不同,优先队列不支持通过索引访问元素。
- 只允许在队尾插入元素:新元素只能被添加到队列的末尾。
- 只允许在队首删除元素:只能从队列的前端移除元素,这通常是最高优先级的元素。
- 不保证元素的顺序:除了最高优先级的元素总是在队首外,其他元素的顺序是未定义的。
priority_queue的使用

优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意:默认情况下priority_queue是大堆。
来看一下它的函数接口有哪些吧.
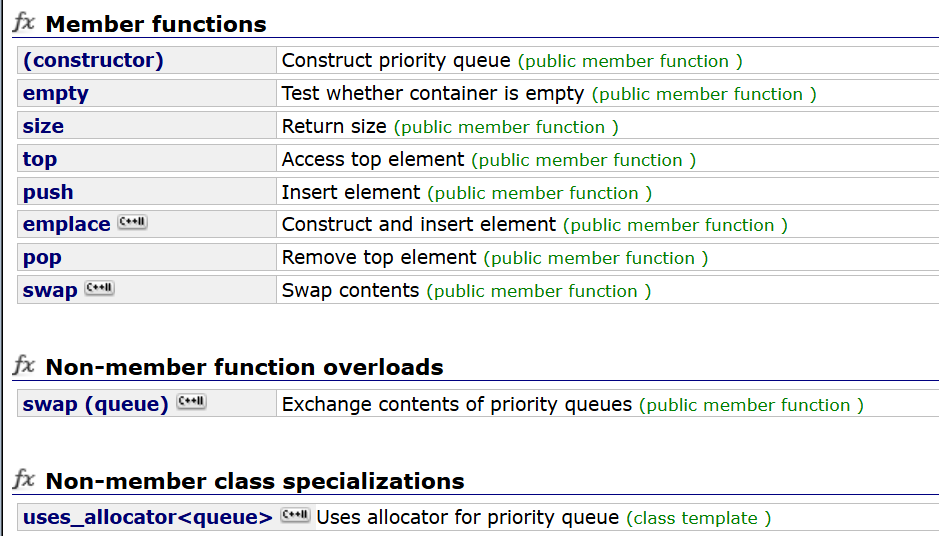
下面我们就来模拟实现其中一些常用的函数接口吧。
基本结构:
template<class T, class Container = vector<T>>
class priority_queue{private:Container _con;}
top
const T& top()
{return _con[0];
}
取得优先级最高的元素,其实就是vector的第一个元素。
empty & size
bool empty()
{return _con.empty();
}size_t size()
{return _con.size();
}
由于底层容器是vector,所以进行操作的时候也是对vector的操作一样。
push
void adjust_up(int child)
{int parent = (child - 1) / 2;while (child > 0){if (_con[parent] < _con[child]){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
void push(const T& x)
{_con.push_back(x);adjust_up(_con.size() - 1);
}
pop
void adjust_down(int parent)
{size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && _con[child] < _con[child + 1]){++child;}if (_con[parent] < _con[child]){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void pop()
{swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);
}
我们已经知道priority_queue类似堆,所以进行加入或者删除数据的时候,其实就是跟堆一样,在添加完之后要满足大堆或者小堆的性质。而要满足堆的性质,就需要用到向上调整算法和向下调整算法。如果有不知道这个算法的同学,可以点开下面这个链接,里面详细介绍了这2种算法。(向上调整算法在堆插入里面)
向上调整和向下调整算法
仿函数
仿函数(Functor)是一种对象,它的行为类似于函数。仿函数可以被当作函数使用,但它们实际上是对象,这意味着它们可以拥有状态(成员变量)和行为(成员函数)。仿函数通常用于算法中,例如标准模板库(STL)中的算法,允许用户自定义比较或操作逻辑。下面来看一个例子:
struct Add
{int operator()(int x, int y){return x + y;}
};int main()
{Add add;int ret = add(1, 2);cout << ret << endl;return 0;
}
在上面的代码中,我们定义了Add的结构体,里面重载了operator()这个运算符,实现了2个整数相加的逻辑。在主函数中,我们创建了一个Add的实例化对象add,并通过调用函数调用运算符对两个整数进行相加。由于跟普通函数调用的方法一样,只是多了需要实例化一个对象这一步骤,所以 称之为仿函数。那么为什么不直接写一个函数来实现加法运算,而要用到仿函数呢?这就要提到普通函数与仿函数的区别了。
- 对象 vs 非对象:
- 仿函数是一个对象,它可以拥有状态(成员变量)和行为(成员函数)。
- 普通函数不是一个对象,它没有状态,只能执行预定义的操作。
- 调用方式:
- 仿函数通过重载
operator()来实现调用,可以像普通函数那样使用参数列表进行调用。 - 普通函数通过其函数名直接调用,需要符合函数签名。
- 仿函数通过重载
- 状态保持:
- 仿函数可以维护状态,因为它有成员变量,可以在多次调用之间保持数据。
- 普通函数不能维护状态,因为它们没有成员变量。
- 多态性:
- 仿函数可以实现多态性,不同的仿函数可以有不同的
operator()实现。 - 普通函数是静态的,它们在编译时类型就已经确定,不具备运行时多态性。
- 仿函数可以实现多态性,不同的仿函数可以有不同的
- 参数传递:
- 仿函数可以作为对象传递,可以被赋值给其他对象或作为参数传递给函数。
- 普通函数可以通过函数指针或函数引用传递,但不能作为对象传递。
- 泛型编程:
- 仿函数可以与模板结合使用,实现泛型编程,适用于多种数据类型。
- 普通函数是特定类型的,不能直接用于泛型编程。
C语言中函数指针用法如下:
int Add(int x, int y)
{return x + y;
}int main()
{int(*pf3)(int, int) = Add;printf("%d\n", (*pf3)(2, 3)); //5printf("%d\n", pf3(3, 5)); //8return 0;
}

函数指针其实就是用来存放函数的地址,未来通过地址能够调⽤函数的。如果我们要将函数的地址存放起来,就得创建函数指针变量。
在C语言中如果我们想将一个函数作为参数传给其它函数,那么就要在这个函数中准确写出函数指针的类型,所以这就是要使用仿函数的原因之一。
看完了仿函数之后,如果我们想将优先队列按照小堆的方式排列,难道还需要改变2个算法之间的符号方向吗?这肯定是不需要的,只要我们写出比较大小的仿函数就行了,按照自己的规则来比较大小。另外还需要在模板参数中传入第3个参数。
template<class T>
class Less
{bool operator()(const T& x, const T& y){return x < y;}
};template<class T>
class Greater
{bool operator()(const T& x, const T& y){return x > y;}
};
完整版代码:
#pragma once
#include<vector>namespace hjw
{template<class T, class Container = vector<T>,class Compaer = Less<T>>class priority_queue{public:priority_queue(){}void adjust_up(int child){Compaer com;int parent = (child - 1) / 2;while (child > 0){if(com(_con[parent],_con[child]))//if (_con[parent] < _con[child]){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjust_down(int parent){Compaer com;size_t child = parent * 2 + 1;while (child < _con.size()){//if (child + 1 < _con.size() && _con[child] < _con[child + 1])if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){++child;}//if (_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}void push(const T& x){_con.push_back(x);adjust_up(_con.size() - 1);}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);}bool empty(){return _con.empty();}const T& top(){return _con[0];}size_t size(){return _con.size();}private:Container _con;};
}
使用less的时候是大堆,使用greater是小堆。