NVIDIA GPU 计算能力与 COLMAP 编译配置指南【2025最新版!!!】
一、引言
NVIDIA 的不同代显卡具有不同的计算能力(Compute Capability),这会影响到使用 CUDA 编译 COLMAP 时的配置选项。下面将详细列出了各代 GPU 的计算能力以及相应的 COLMAP 编译参数,以便后续查询使用
二 20系显卡 (Turing 架构)
2.1 计算能力:
- RTX 2080 Ti, RTX 2080 Super, RTX 2080: 7.5
- RTX 2070 Super, RTX 2070, RTX 2060 Super, RTX 2060: 7.5
- GTX 1660 Ti, GTX 1660 Super, GTX 1660, GTX 1650: 7.5
2.2 COLMAP 编译配置:
cmake .. -DCUDA_ARCHS="Turing"
# 或者具体指定
cmake .. -DCUDA_ARCHS="7.5"
三、30系显卡 (Ampere 架构)
3.1 计算能力:
- RTX 3090, RTX 3080 Ti, RTX 3080: 8.6
- RTX 3070 Ti, RTX 3070, RTX 3060 Ti, RTX 3060: 8.6
- RTX A6000, RTX A5000, RTX A4000: 8.6
3.2 COLMAP 编译配置:
cmake .. -DCUDA_ARCHS="Ampere"
# 或者具体指定
cmake .. -DCUDA_ARCHS="8.6"
四、40系显卡 (Ada Lovelace 架构)
4.1 计算能力:
- RTX 4090, RTX 4080, RTX 4070 Ti, RTX 4070, RTX 4060 Ti, RTX 4060: 8.9
4.2 COLMAP 编译配置:
使用 CUDA 11.8 或更低版本时(不支持 8.9):
cmake .. -DCUDA_ARCHS="Ampere"
# 或
cmake .. -DCUDA_ARCHS="8.6"使用 CUDA 12.0 或更高版本时(支持 8.9):
cmake .. -DCUDA_ARCHS="Ada"
# 或
cmake .. -DCUDA_ARCHS="8.9"
五、50系显卡 (Blackwell 架构)
5.1 计算能力:
- RTX 5090 及其他 50 系列: 9.0
5.2 COLMAP 编译配置:
使用 CUDA 12.3 或更高版本:
cmake .. -DCUDA_ARCHS="Blackwell"
# 或
cmake .. -DCUDA_ARCHS="9.0"
使用 CUDA 12.0-12.2 时(不支持 9.0):
cmake .. -DCUDA_ARCHS="Ada"
# 或
cmake .. -DCUDA_ARCHS="8.9"
使用 CUDA 11.x 时(不支持 8.9 及以上)
cmake .. -DCUDA_ARCHS="Ampere"
# 或
cmake .. -DCUDA_ARCHS="8.6"
5.3 针对混合多卡环境的配置
如果系统包含多种不同架构的显卡,可以指定多个架构:
# 例如同时有 30 系和 40 系显卡
cmake .. -DCUDA_ARCHS="8.6;8.9"
5.4、CUDA 版本与最高支持计算能力对照
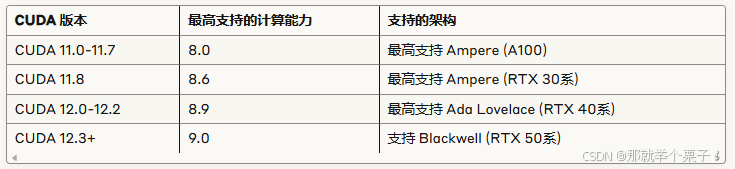
5.6 重要说明
(1)向后兼容性:较新的 GPU 可以运行为旧架构编译的代码,只是可能无法利用新架构的特定优化。
(2)显式指定多个架构:如果想为多个架构优化,可以同时指定它们:
cmake .. -DCUDA_ARCHS="7.5;8.6" # 为 Turing 和 Ampere 同时优化
(3)命名架构与数字对应关系:
- “Turing” = 7.5
- “Ampere” = 8.0, 8.6
- “Ada” 或 “Lovelace” = 8.9
- “Blackwell” = 9.0
最佳实践:通常选择当前 CUDA 版本支持的最高架构即可。对于跨架构使用的代码,可以指定多个架构值或使用架构族名称(如"Ampere")。
六、编译运行(4090、CUDA11.8)
6.1 cmake标准版本
cd /root/autodl-tmp/gaussian-splatting/submodules/colmap-3.7/rm -rf build
rm -rf build
mkdir build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release \-DCMAKE_CUDA_ARCHITECTURES=89 # 这里改成你的GPU
make -j$(nproc)命令解释:
-DCMAKE_BUILD_TYPE=Release:启用编译优化(比如 -O3),绝对必要!否则默认是 Debug 模式,很慢。-DCMAKE_CUDA_ARCHITECTURES=86:让 CUDA 代码生成对应你显卡的高效代码。make -j$(nproc):并行编译,$(nproc)自动使用全部 CPU 核心,大幅加速编译速度。6.2 Ninja(效率更高)
sudo apt install ninja-build
cd /root/autodl-tmp/gaussian-splatting/submodules/colmap-3.7/rm -rf build
rm -rf build
mkdir build
cd build
cmake .. -GNinja \-DCMAKE_BUILD_TYPE=Release \-DCMAKE_CUDA_ARCHITECTURES=89
ninja