AI编程案例拆解|基于机器学习XX评分系统-后端篇
文章目录
- 5. 数据集生成
- 使用KIMI生成数据集
- 6. 后端部分设计
- 使用DeepSeek生成神经网络算法设计
- 初始化项目
- 在Cursor中生成并提问
- 前后端交互
- 运行后端命令
- 注意事项
- 关注不迷路,励志拆解100个AI编程、AI智能体的落地应用案例
- 为了用户的隐私性,关键信息会全部打码
5. 数据集生成
在这一阶段,我们需要为系统准备合适的数据集。以下是具体步骤:
使用KIMI生成数据集
- 定义数据需求:明确系统所需的数据类型和格式,如学生成绩、运动项目等。
这里以运动成绩举例:
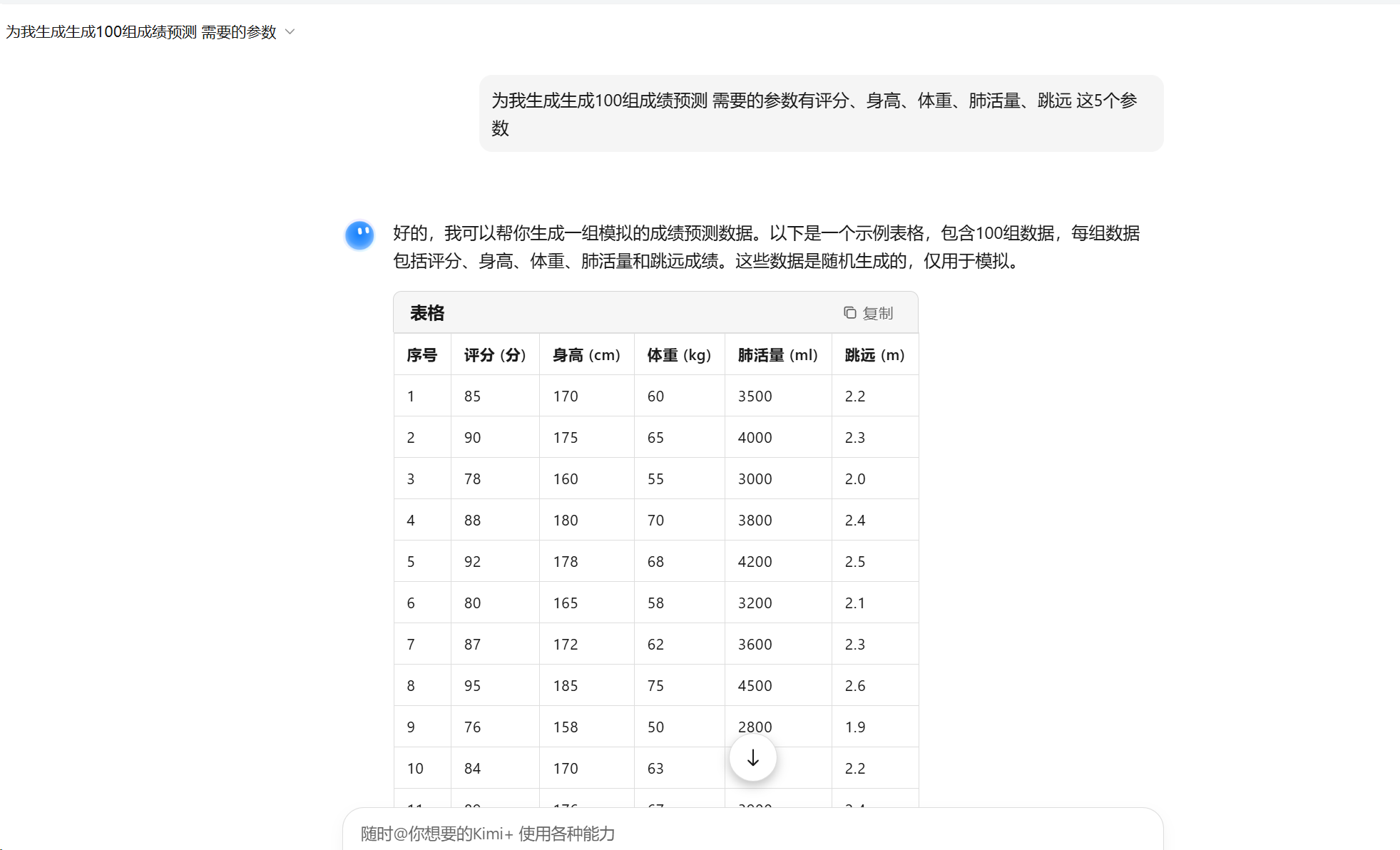
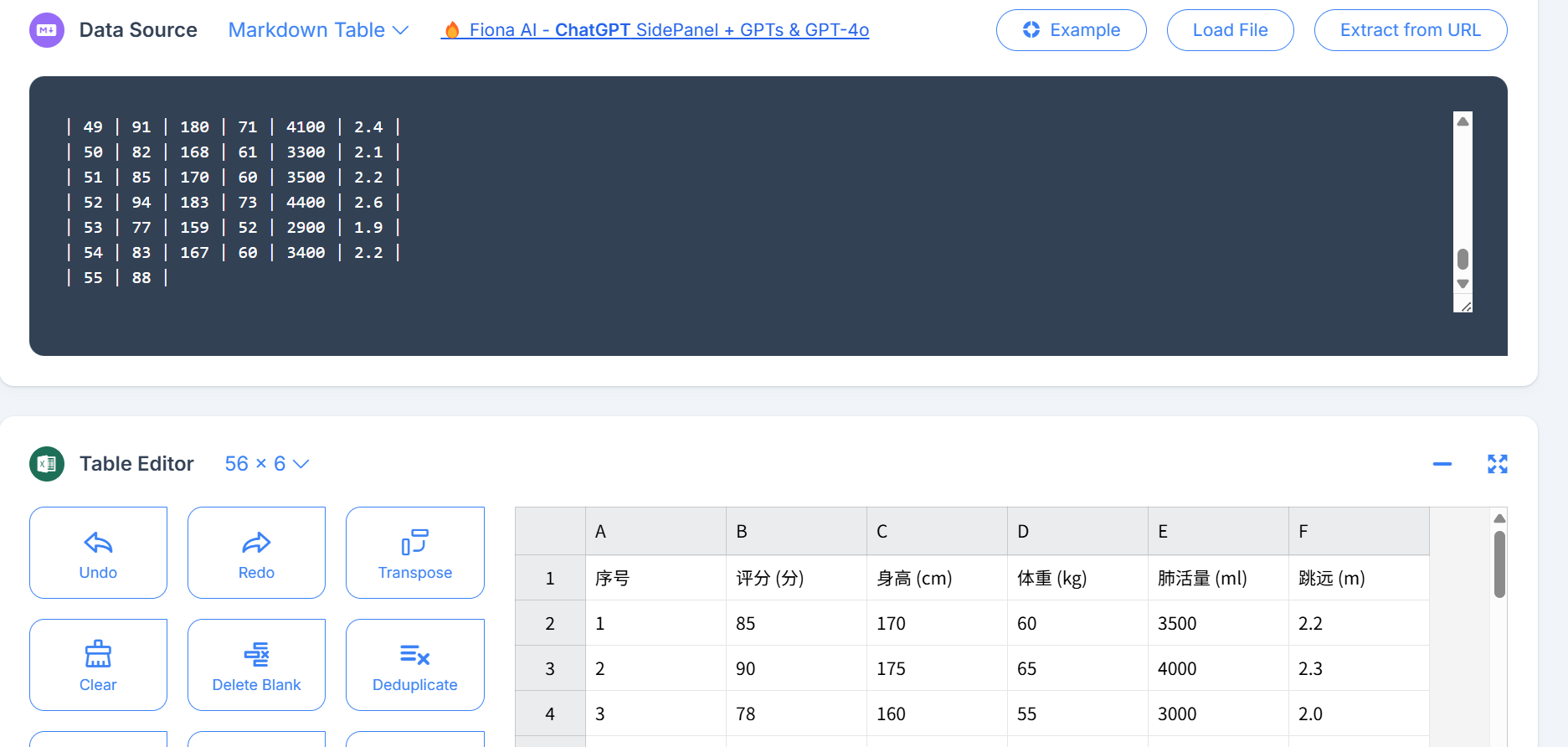
注意生成后的数据如果用右上角的复制按钮是不能直接贴到excel或者csv文件中的,这里需要用在线工具转换一下再复制
https://tableconvert.com/markdown-to-excel
6. 后端部分设计
使用DeepSeek生成神经网络算法设计
- 需求输入:将系统的功能需求输入DeepSeek,生成后端架构设计方案。
注意
这里的提示词有提到 mermaid 这是一种标记语言,常用来绘制流程图,比如
mermaid在线转义网址
其次是一个完整的机器学习的算法是需要数据集、预处理、神经网络定义、训练和预测这些算法的大致步骤需要作为提示词输入,避免太大的随机性

一般来说deepseek第一轮结果返回的设计结构都会比较复杂,需要通过提示词再优化一下训练模型的设计

初始化项目
- 配置环境:配置开发环境,确保项目能够顺利运行。
这里选择使用python3.8,安装完成后需要通过cmd命令来确认安装的版本,网上教程很多,这里不做赘述
- 使用脚手架工具:选择合适的脚手架工具,快速生成项目的基础结构。
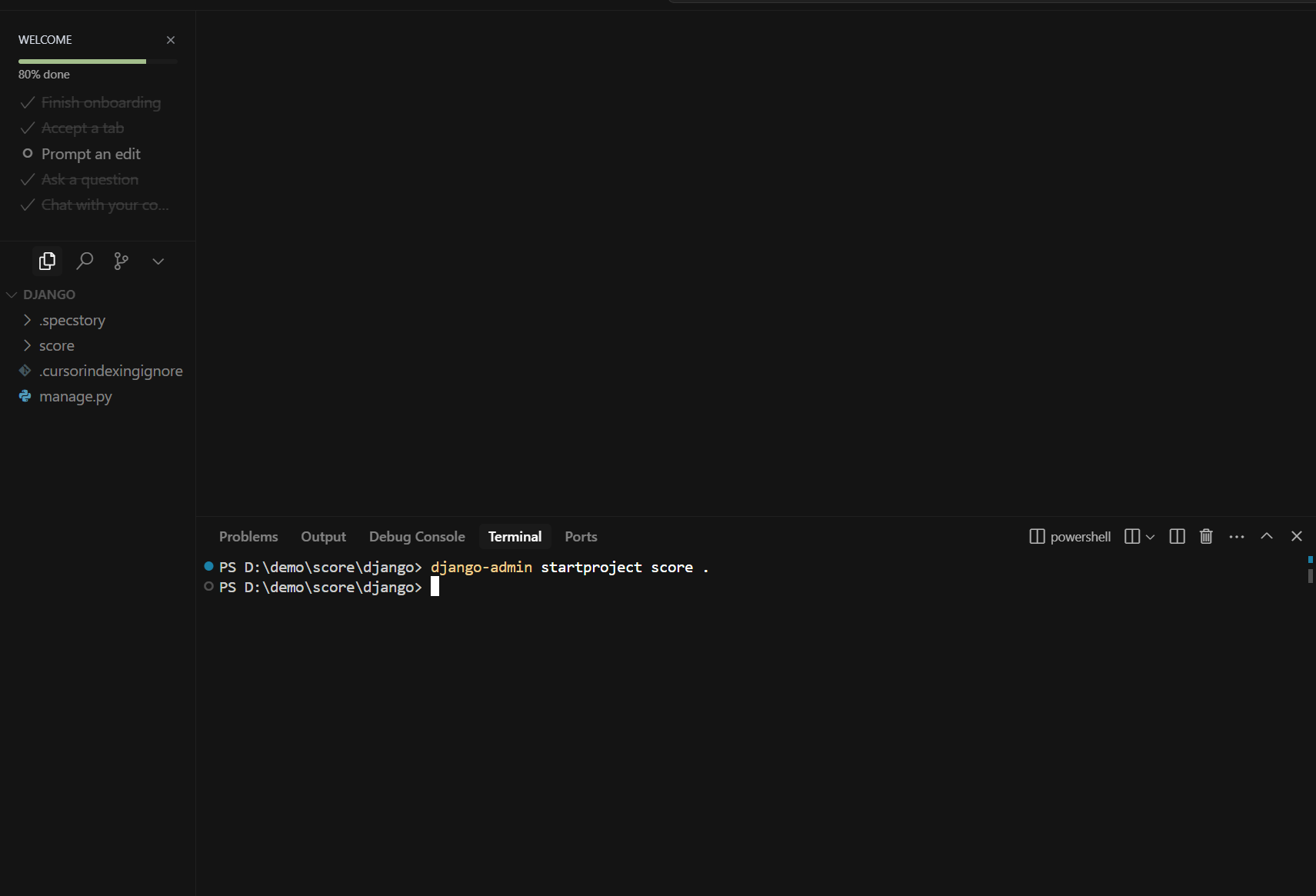
框架类不要依赖AI生成,会有很多随机性,且后端的代码一般很长稍微生成错一位就会导致源源不断的问题,这里的脚手架选用django-admin
django-admin startproject score .
在Cursor中生成并提问
- 导入设计:将DeepSeek生成的神经网络设计输入到Cursor中。
- 逐步提问:使用Cursor的agent模式,逐步验证和完善后端逻辑。
- 提问示例
gpt-4o/claude-3.5 使用要具有分段提示的思想 他们是不支持太长的上下文,提示词大致流程:
- 提问示例
* 我要完成 xxxxx 功能以下是功能的 mermaid 图,接下来我会逐流程向你提问,收到回复1* 然后一步一步的向它提问
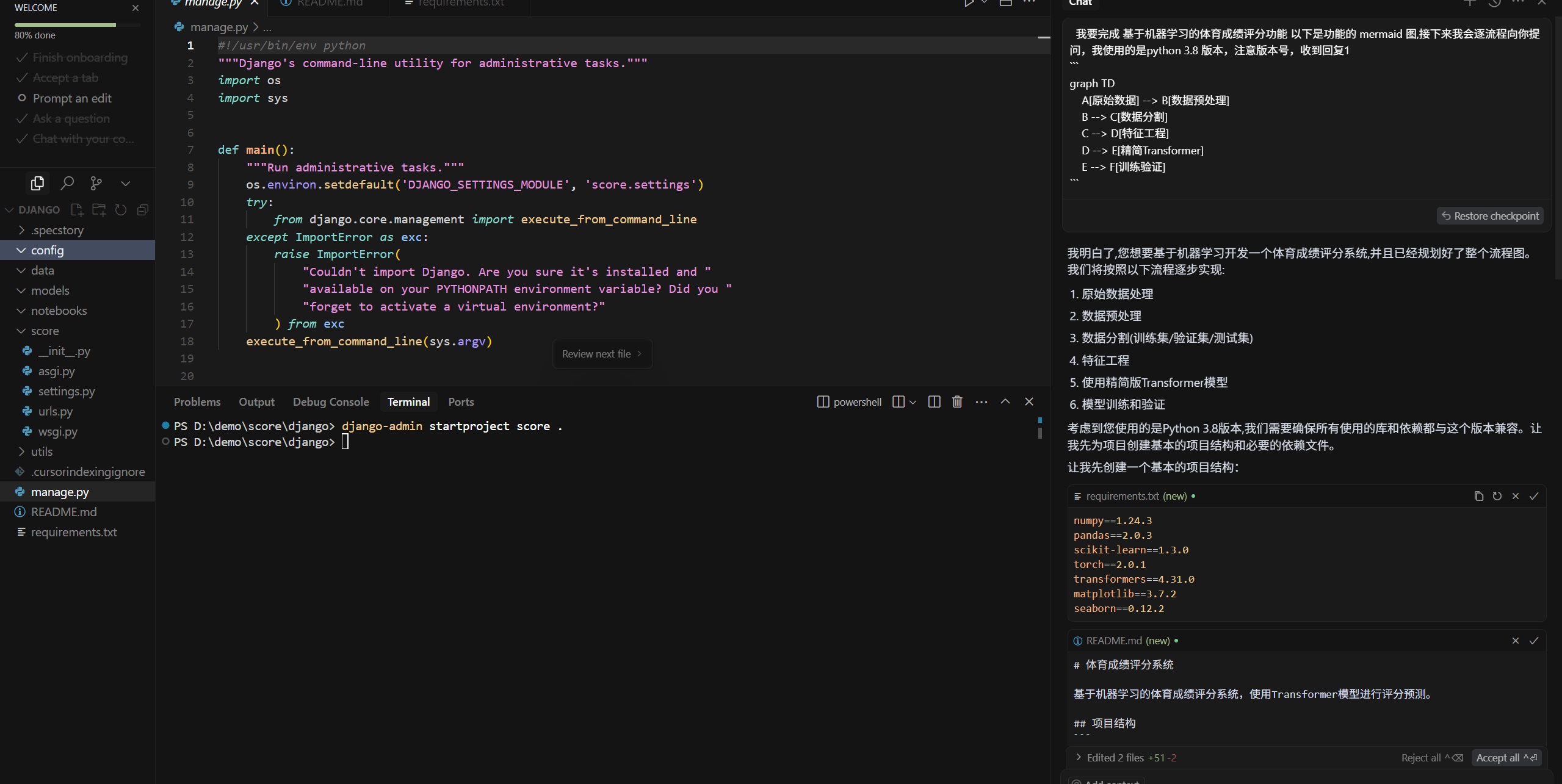
用上一步deepseek输出的算法框架,一步步的喂给cursor,让它输出代码
执行完全部步骤后运行训练主函数,开始训练模型
- 保存模型:
这里最好新开一个窗口,避免无关的上下文太长,让cursor把训练好的模型保存下来,再提供一个测试方法展示如何调用这个模型输出结果,一般是.pth结尾的模型结果文件
前后端交互
向cursor将前端定义好的参数json对象放agent模式中,让cursor生成分数返回给前端,通过调用保存模型生成好的测试方法,将前端参数转换到对应的入参
运行后端命令
# 创建新的虚拟环境
python -m venv .venv
# 激活环境
.venv\Scripts\activate
# 使用阿里云安装所有依赖
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
# 运行
python manage.py runserver 127.0.0.1:8086
注意事项
- 实测下来机械学习算法的后端部分,小白用纯AI其实是很难完成的,
本身是需要有硬解的能力,比如debug和排查,理解算法的大致步骤,包括使用工具post接口- 比如实际遇到的问题1:模型训练中一直不收敛,预测效果一直不达标,可能是deepseek本身生成的算法的问题,或者cursor生成错误,这种时候最好就重新生成设计算法了,可以通过提示
数据集的分布情况和数量来尝试生成新算法 - 比如实际遇到的问题2:模型训练完成了,输入参数也能返回结果但是结果就是不正确,最后通过debug排查发现是MinMaxScaler方法的原因,是通过当前的输入来做的归一化,而测试输入的数据调用这个函数归一化的特性集就是0-1分布导致输出模型后导致结果不一样。
- 比如实际遇到的问题1:模型训练中一直不收敛,预测效果一直不达标,可能是deepseek本身生成的算法的问题,或者cursor生成错误,这种时候最好就重新生成设计算法了,可以通过提示
from sklearn.preprocessing import OneHotEncoder, MinMaxScalerscaler = MinMaxScaler()scaled_features = scaler.fit_transform(df[feature_columns])
-
cursor在xlsx读取方面没有特别擅长,需要通过代码读取,而且一般来说
训练集也不能直接作为上下文会有超长的问题,因此数据样式需要复制出来作为提示词输出给cursor来生成 -
数据集问题需要提前和用户沟通,确认是需要开源的数据集还是自己随机生成就行
-
生成机器学习算法时,提示
基于已有的文献来生成,带有点创新性并返回参考的文献地址,个人感觉是比较重要的,因为算法如果完全随机生成,在设计上可以被说是乱编的没有意义