一篇入门之-评分卡变量分箱(卡方分箱、决策树分箱、KS分箱等)实操例子
一、评分卡分箱-有哪些分箱方法
评分卡的分箱,是指将变量进行离散化。评分卡的分箱方法一般有:等频分箱、等距分箱、卡方分箱、决策树分箱、KS分箱等等。它们都属于自动分箱方法,其中,卡方分箱是实际中最常用的分箱方法。
1.1.等频分箱
等频分箱是将样本分为k个箱,每个箱子中的数据点数量相等,它助于消除数据的偏差,使得每个区间内的数据分布更加均匀,如下所示:

1.2.等距分箱
在等距分箱中,数据根据数值范围被划分为若干个箱子,每个箱子的区间长度相等。这意味着每个箱子中的数据范围是相同的,如下所示:

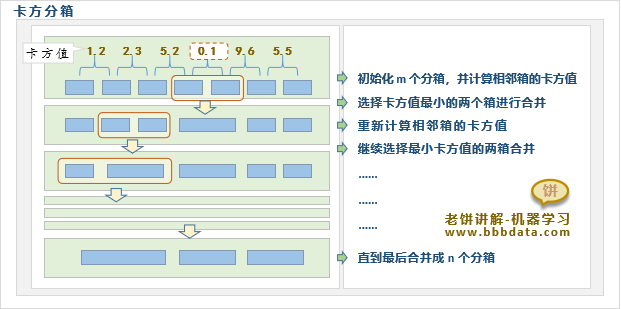
1.3.卡方分箱
卡方分箱是基于卡方值进行分箱的一种方法,卡方分箱先初始化m个分箱,卡方分箱用卡方值判断哪两个分箱的类别分布最没区分度,就合并哪两个分箱。直到分箱数只剩n个。如下所示:
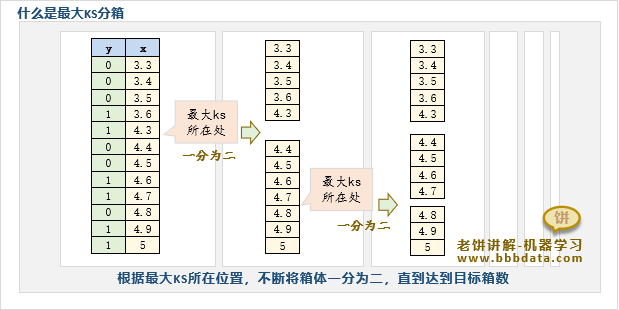
1.4.最大KS分箱
最大KS分箱是基于KS值来进行分箱的一种方法,它先把所有样本初始化为一个分箱,然后根据KS点对分箱不断切割,直到数据分为n个分箱。 如下,KS分箱就是根据最大KS值所在处,将分箱不断一分为二,直到达到目标分箱个数:
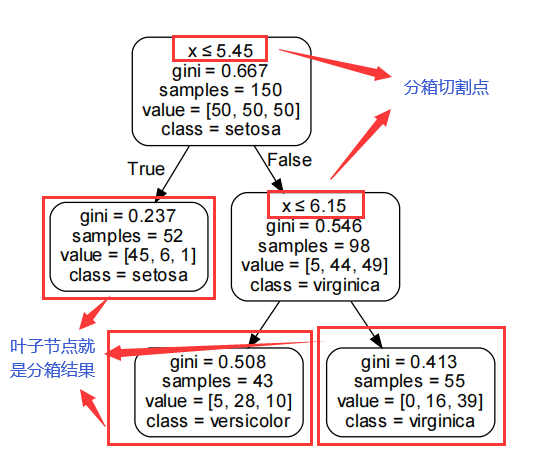
1.5.决策树分箱
决策树分箱是指用变量x与y构建决策树,使用决策树最后的叶子节点作为分箱结果, 如下,使用x、y构建一颗CART决策树,最终的叶子节点就是分箱的结果:
二、评分卡分箱-实现方法
在python中对变量分箱,可以使用bbbrisk来实现。
如果没有bbbrisk,则需要先用pip进行安装,如下:
pip install bbbrisk
安装完后,就可以调用bbbrisk的相关分箱函数进行分箱了。
2.1.连续变量的分箱方法
如果变量是连续变量,可以使用br.bins.merge.chi2、ks、tree等函数进行分箱。
代码示例如下:
import bbbrisk as br
data = br.datasets.load_bloan() # 加载数据
x = data['rev'] # rev变量
y = data['is_bad'] # 样本标签# 卡方分箱
bin_set = br.bins.merge.chi2(x,y,bin_num=5,init_bin_num=10) # 进行卡方分箱,bin_num是目标箱数,init_bin_num是初始箱数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* 卡方分箱结果:\n',bin_stat) # 显示分箱结果# KS分箱
bin_set = br.bins.merge.ks(x,y,bin_num=5,min_sample=None) # 进行KS分箱,bin_num是目标箱数,min_sample是最小样本数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* KS分箱结果:\n',bin_stat) # 显示分箱结果# 决策树分箱
bin_set = br.bins.merge.tree(x,y,max_depth=3,min_sample=None) # 进行决策树分箱,max_depth是树深度,min_sample是叶子最小样本数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* 决策树分箱结果:\n',bin_stat) # 显示分箱结果
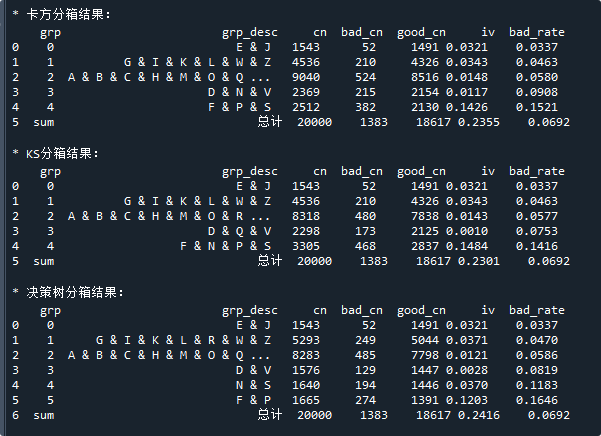
代码中的rev变量,就是我们需要进行分箱的变量,而is_bad则是样本的标签(好样本为0,坏样本为1)。代码运行后的结果如下:
2.2.枚举变量的分箱方法
如果变量是枚举变量(例如城市、婚姻状态这类型的变量),可以使用br.bins.merge.chi2Enum、ksEnum、treeEnum等函数进行分箱。代码示例如下:
import bbbrisk as br
data = br.datasets.load_bloan() # 加载数据
x = data['city'] # city变量
y = data['is_bad'] # 样本标签# 卡方分箱
bin_set = br.bins.merge.chi2Enum(x,y,bin_num=5,init_bin_num=10) # 进行卡方分箱,bin_num是目标箱数,init_bin_num是初始箱数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* 卡方分箱结果:\n',bin_stat) # 显示分箱结果# KS分箱
bin_set = br.bins.merge.ksEnum(x,y,bin_num=5,min_sample=None) # 进行KS分箱,bin_num是目标箱数,min_sample是最小样本数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* KS分箱结果:\n',bin_stat) # 显示分箱结果# 决策树分箱
bin_set = br.bins.merge.treeEnum(x,y,max_depth=3,min_sample=None) # 进行决策树分箱,max_depth是树深度,min_sample是最小样本数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* 决策树分箱结果:\n',bin_stat) # 显示分箱结果
代码运行结果如下:
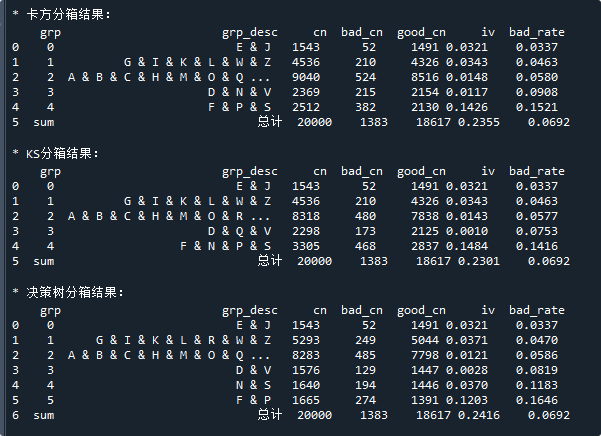
三、评分卡分箱结果怎么看
代码里运行的结果不够美观,一般需要将它复制到EXCEL里,添加颜色,再给各位领导看。
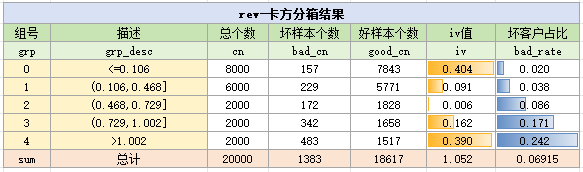
可以看到,加了颜色就好看多了,特别是最后一列的坏客户占比,使用色条标示,就显得专业多了,领导看了都觉得花个几万八千请我真是赚大发了。
3.1. 分箱结果解读-badrate
好了,分箱结果怎么看呢,一般不先看第一列,而是看最后一列bad_rate,它代表分组的坏客户占比,即坏样本个数/总个数。
先看Badrate趋势明不明显,上面的例子,Badrate看起来就很有区分度,非常好。
3.2. 分箱结果解读-IV值
看完了badrate,就到iv值了,抛开IV是什么不谈,IV的意义如下:

例如上面的例子, iv值1.052,一看就知道这个变量强到爆了,赶紧将它入模!
3.3. 分箱结果解读-业务逻辑
最后,还需要审查一下业务逻辑是否合理,仔细看下每个分箱(第2列)与对应的badrate是不是符合业务逻辑,如果业务逻辑不合理,那赶紧检查问题,如果业务逻辑合理,那就过关啦!
好了,以上就是评分卡如何变量分箱了。无惊无险,又到终点!收工!下班!
相关文章:
1.《评分卡-完整建模代码》
2.《一篇入门-IV值是什么》
3. 《bbbrisk-完整说明文档》