大模型奖励建模新突破!Inference-Time Scaling for Generalist Reward Modeling
传统的RM在通用领域面临准确性和灵活性挑战,而DeepSeek-GRM通过动态生成principle和critic,结合并行采样与meta RM引导的投票机制,实现了更高质量的奖励信号生成。论文通过Self-Principled Critique Tuning (SPCT)方法,显著提升了奖励模型(RM)的推理时扩展能力,且推理时扩展性能优于单纯增大模型规模。未来,这一技术有望成为强化学习与语言模型对齐的关键工具。点击阅读,探索通用奖励建模的前沿突破!
论文标题
Inference-Time Scaling for Generalist Reward Modeling
来源
arXiv:2504.02495v2 [cs.CL] 5 Apr 2025
https://arxiv.org/abs/2504.02495
文章核心
研究背景
大语言模型(LLM)发展迅速,强化学习(RL)作为其训练方法被广泛应用,奖励建模(RM)是RL中为LLM生成准确奖励信号的关键部分。然而,当前高质量奖励信号主要依赖特定环境或手工规则获取,在通用领域获取高质量奖励信号面临挑战。
研究问题
- 通用奖励建模需要对不同输入类型具有灵活性,现有方法难以满足这一要求,如成对RM难以处理单响应输入,标量RM难以生成多样奖励信号。
- 有效推理时可扩展性要求RM能随推理计算增加生成更高质量奖励信号并学习可扩展行为,但现有学习方法很少关注推理时可扩展性及相关行为与RM推理时可扩展性有效性的联系,导致性能提升有限。
- 在通用领域,奖励生成标准复杂多样,缺乏明确参考或事实,使得奖励建模更具挑战性。
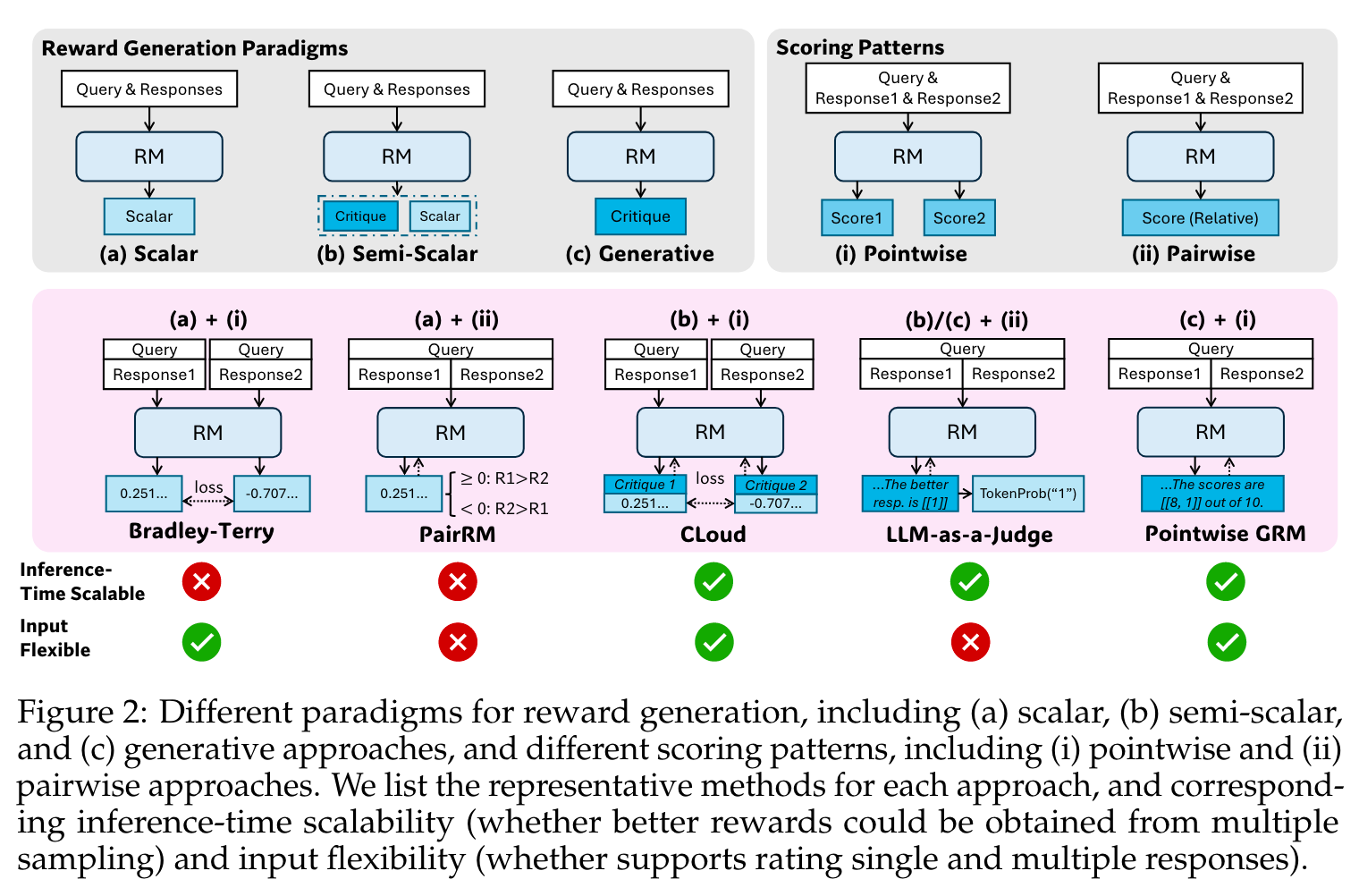
主要贡献
- 提出新的学习方法:提出Self-Principled Critique Tuning(SPCT)方法,用于点向生成式奖励建模(GRM),使GRM能自适应生成原则和评论,显著提升奖励质量和推理时可扩展性,由此得到DeepSeek-GRM模型;引入元RM,进一步提高DeepSeek-GRM的推理时缩放性能。
- 实验验证优势:通过实验证明,SPCT在多个综合RM基准测试中,显著提升了GRM的质量和推理时可扩展性,优于现有方法和多个强大的公共模型。
- 探索新的发现:将SPCT训练方案应用于更大规模的LLM,发现推理时缩放性能优于训练时模型尺寸缩放。
方法论精要
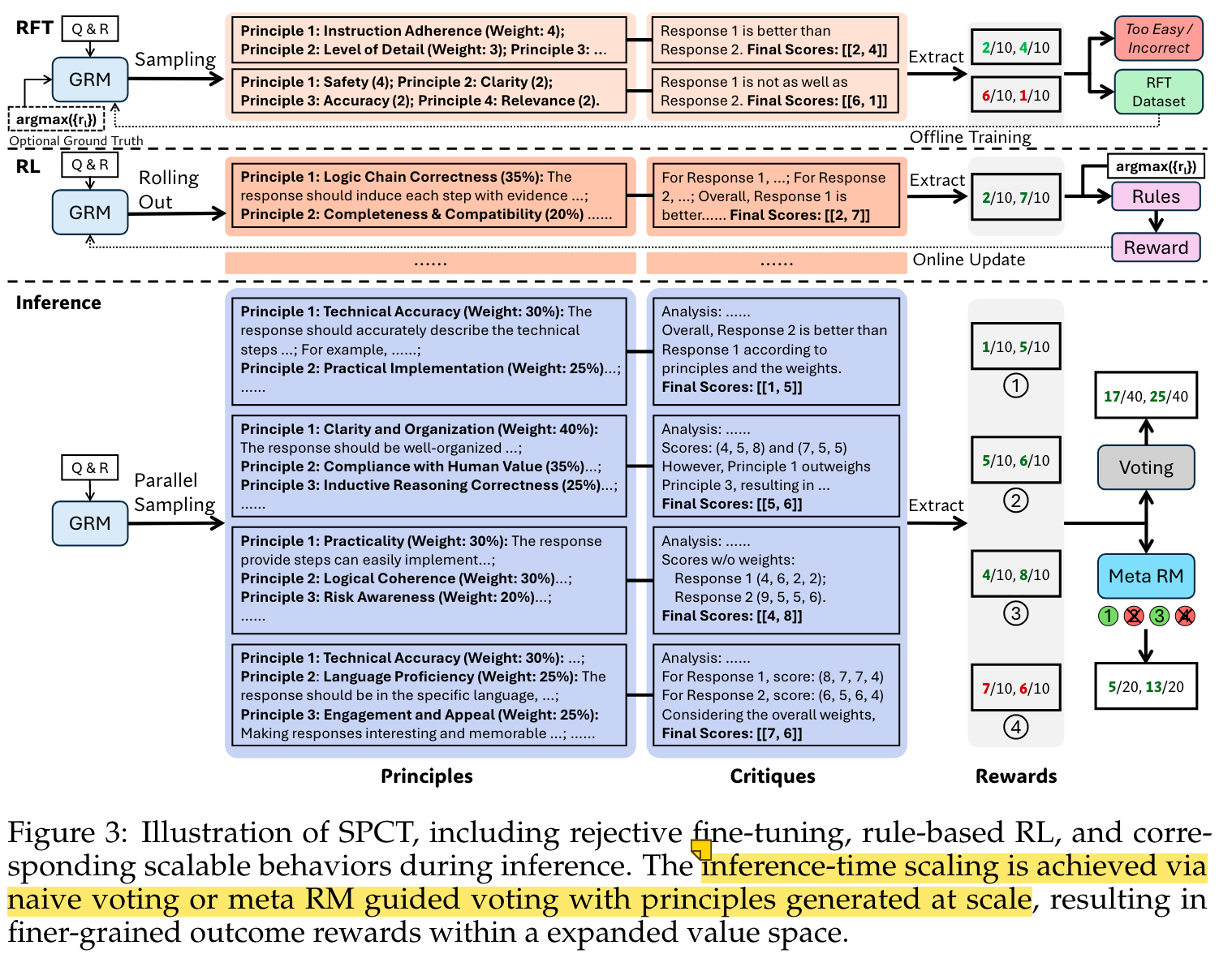
- 核心算法/框架:采用点向Pointwise奖励建模(GRM),并提出Self-Principled Critique Tuning(SPCT)方法。SPCT由**拒绝微调(Rejective Fine-Tuning,RFT)和基于规则的在线强化学习(RL)**两部分组成。在拒绝微调阶段,使用预训练的GRM对不同数量的response和prompt进行轨迹采样,构建数据并筛选,让GRM适应生成正确格式的principle和critic。基于规则的在线RL阶段,利用GRPO(Generalized Reinforce Policy Optimization)原设置和基于规则的结果奖励对GRM进一步微调,鼓励GRM区分最佳响应,以实现有效的推理时缩放。
- 关键参数设计原理:在基于规则的在线RL中,使用标准GRPO设置,通过网格搜索确定超参数β = 0.08为最稳定配置,此时能避免GRM在基准测试的某些子集上出现偏差。设置组大小G = 4,平衡效率和性能。在数据构建方面,训练集包含1250K RFT数据(1070K通用指令数据和186K拒绝采样数据)和237K RL数据。对于拒绝采样,使用DeepSeek-v2.5 - 0906生成轨迹,采样时间 N R F T N_{RFT} NRFT设为3;在Hinted采样时,添加偏好强度作为提示,并移除对DeepSeek-V2-Lite-Chat来说过于简单的样本。
- 创新性技术组合
- principle生成转变:将principle生成从理解环节转移到生成环节,使GRM能根据输入prompt和response自适应生成principle,进而生成critic,且通过对GRM的后训练可提升principle和critic的质量与粒度。
- 并行采样与投票:通过并行采样扩展计算使用,对生成的多组principle和critic进行投票得到最终奖励。由于每次采样的奖励通常在小离散范围内(如1 - 10),投票过程扩大了奖励空间,使GRM能生成更多principle,提高最终奖励的质量和粒度。为避免位置偏差和增加多样性,采样前会对响应进行shuffle。
- meta-RM指导投票:训练元RM指导投票过程。meta-RM是pointwise scalar RM,通过二元交叉熵损失训练,用于识别DeepSeek-GRM生成的principle和critic的正确性。其训练数据集包含RFT阶段的非Hinted采样轨迹和DeepSeek-GRM的采样轨迹,以提供正负奖励并减轻训练和推理策略间的差距。指导投票时,meta-RM为k次采样奖励输出meta-reward,最终结果由meta-reward排名前 k m e t a ≤ k k_{meta}≤k kmeta≤k的奖励投票得出,从而过滤低质量样本。
- 实验验证方式:在多个不同领域的RM基准测试中评估模型性能,包括Reward Bench、PPE、RMB、ReaLMistake等。选用多个基线方法进行对比,如LLM-as-a-Judge、DeepSeek-BTRM-27B、CLoud-Gemma-2-27B、DeepSeek-PairRM-27B等,并基于Gemma-2-27B重新实现这些基线方法,保证训练数据和设置与DeepSeek-GRM兼容。在实验设置中,使用标准评估指标,如在Reward Bench、PPE和RMB中选取最佳响应的准确率,ReaLMistake中的ROC-AUC。对于多响应预测奖励的平局情况,通过shuffle和arg max操作确定最佳响应。
实验洞察
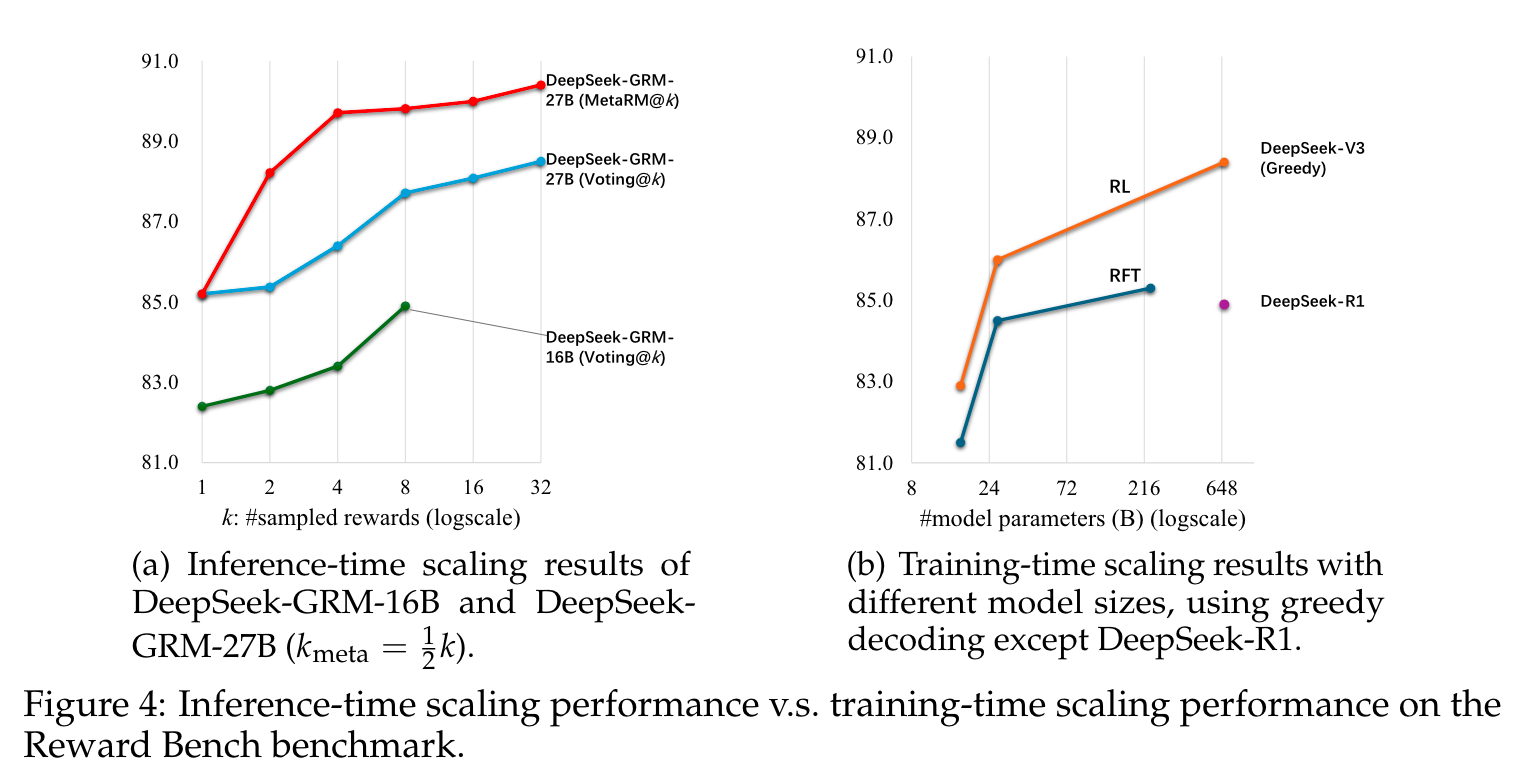
- 性能优势:在RM基准测试中,DeepSeek-GRM-27B总体性能优于基线方法,与强大的公共RM(如Nemotron-4-340B-Reward和GPT-4o)相比也具有竞争力。通过推理时缩放,DeepSeek-GRM-27B性能进一步提升,如在Voting@32设置下,总体得分达到71.0,MetaRM指导投票时可达72.8。在不同基准测试的具体指标上,如Reward Bench的准确率、PPE的正确性、RMB的各项指标等,DeepSeek-GRM-27B均有出色表现。
- 效率突破:采用并行采样进行推理时缩放,在合理采样次数(如8次)下,奖励生成延迟不会显著增加。与训练时缩放模型尺寸相比,DeepSeek-GRM-27B的推理时缩放更有效,例如直接投票32次的DeepSeek-GRM-27B性能与671B MoE模型相当,MetaRM指导投票8次时效果最佳。
- 消融研究:通过对SPCT不同组件的消融实验发现,principle生成对DeepSeek-GRM-27B的贪婪解码和推理时缩放性能都至关重要;非提示采样似乎比提示采样更重要;即使没有拒绝采样的冷启动,经过在线RL后,通用指令调整的GRM仍有显著性能提升,表明在线训练对GRM很重要。
本文由AI辅助完成。