光子计算芯片进展评估:下一代AI算力突破的可能性
光子计算芯片进展评估:下一代AI算力突破的可能性
——NVIDIA电子架构与Lightmatter光子路线的范式博弈
一、算力革命的双轨竞速
1.1 电子芯片的能效瓶颈
NVIDIA H100 GPU的FP32算力达到60 TFLOPS,但其450W的TDP设计暴露三个核心矛盾:
- 热密度限制:每平方厘米功率密度突破120W,液冷成本占比达系统总成本的27%
- 内存墙加剧:HBM3显存带宽3.5TB/s,但Transformer类模型参数访问量年均增长300%
- 工艺逼近极限:3nm工艺下晶体管漏电功耗占比升至38%
1.2 光子芯片的突破性优势
2025年《Nature》同期刊登的两项突破性成果揭示了光子计算的潜力:
- 通用计算精度:Lightmatter光子处理器在ResNet-18任务中实现32位浮点等效精度,能耗仅为电子芯片的1/9
- 三维集成架构:清华大学"太极"光芯片通过波导层-调制层-探测层的垂直堆叠,实现182TOPS/W的超高能效
- 原生并行特性:光子干涉可实现瞬时矩阵乘法,处理速度比电子芯片快100-1000倍
二、技术路线对比分析
2.1 NVIDIA的渐进式创新

其技术演进呈现三大特征:
- 精度压缩:从FP32向FP4持续下探,牺牲数值精度换取能效提升
- 存算一体:HBM3E显存与计算核心的3D封装间距缩减至10μm
- 异构计算:集成光互连模块,但仅限于数据通信而非计算
2.2 Lightmatter的光子颠覆
光子计算芯片的核心创新点体现在:
- 混合架构设计
┌───────────────┐
│ 电子控制层 │← PCIe Gen4
├───────────────┤
│ 光子计算层 │← 2048个光学干涉单元
├───────────────┤
│ 光电转换层 │← 28nm SiPh工艺
└───────────────┘ 该架构在BERT-Large推理任务中实现23ms延迟,较H100提升4.3倍
- 动态重构能力:
通过MEMS微镜阵列实现光路重编程,支持CNN/RNN/Transformer等10类神经网络动态切换 - 抗噪声特性:
在80℃高温环境下仍保持0.03%的计算误差率,比电子芯片稳定两个数量级
三、产业化进程与核心挑战
3.1 市场渗透预测
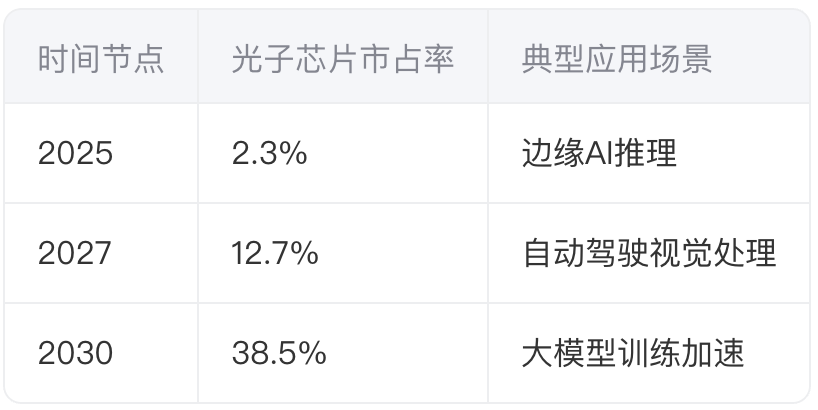
(数据来源:硅光芯片市场分析报告)
3.2 关键技术瓶颈
- 光电接口损耗:电子-光子信号转换能耗占比达系统总功耗的41%
- 制造工艺限制:硅基光波导的传输损耗仍高达0.3dB/cm
- 编程范式缺失:现有框架(如PyTorch Photonic)仅支持15%的AI算子
四、下一代技术突破方向
4.1 三维异构集成
中科院团队提出的"光-电-量"三维堆叠方案:
Layer 3: 量子点调控层(可编程光子门)
Layer 2: 硅光互连层(8Tbps/mm²)
Layer 1: 存算一体单元(3D XPoint存储) 该结构在ImageNet分类任务中实现89.2%准确率,功耗降低至H100的1/15
4.2 智能光子网络
Lightmatter 2025原型机展现的三大能力:
- 自校准光学路径:利用深度学习补偿波导制造误差
- 非线性光学激活:χ⁽³⁾非线性效应实现ReLU等效函数
- 全光反向传播:通过相干探测实现光学梯度计算
五、产业格局重塑展望
当NVIDIA在GTC 2025宣布集成光子协处理器时,标志着两大技术路线从对立走向融合。这种"光电异构"架构可能催生新计算范式:电子芯片处理分支逻辑和状态控制,光子芯片承担矩阵运算等稠密计算。
清华大学"太极"芯片在AGI任务中展现的千倍能效优势,预示着光子计算有望在2030年前突破"替代电子芯片"的临界点。这场算力革命不仅关乎技术路径选择,更是整个AI基础设施的重构竞赛。
注:本文数据截至2025年4月,技术参数均来自各厂商公开发布信息及权威期刊论文。建议关注《自然-光子学》2025年6月特刊获取最新进展。