【第三十三周】BLIP论文阅读笔记
BLIP
- 摘要
- Abstract
- 文章信息
- 引言
- 方法
- MED
- 预训练
- CapFilt
- 关键代码
- 实验结果
- 总结
摘要
本博客介绍了BLIP(Bootstrapping Language-Image Pre-training),这是一种创新的视觉-语言预训练框架,旨在通过统一模型架构和高效数据增强策略,同时解决现有视觉-语言模型在理解与生成任务上的割裂性以及网络数据噪声对性能的制约。其核心思想包含两方面:模型层面提出多模态混合编码器-解码器(MED),通过共享参数支持三种模式——单模态编码器(对齐全局特征)、跨模态编码器(细粒度匹配)和跨模态解码器(生成描述),联合优化图像-文本对比(ITC)、匹配(ITM)和语言建模(LM)损失,从而统一理解(如检索)与生成(如描述)任务;数据层面设计Captioning 和 Filtering(CapFilt)方法,利用预训练(使用网上获取的有噪声的数据)的MED生成合成描述(Captioner模块)并过滤原始网络文本与合成文本中的噪声(Filter模块),从噪声数据中提炼高质量训练样本。实验表明,BLIP在图像-文本检索、图像描述生成等任务上达到SOTA,且零样本迁移至视频任务时表现优异。其优势在于通过灵活架构与数据增强突破多任务瓶颈,但数据清洗的计算成本较高,且未深入时序建模。未来可探索多轮数据增强、生成多样性优化及视频-语言扩展,进一步释放模型潜力。
Abstract
This blog introduces BLIP (Bootstrapping Language-Image Pre-training), an innovative vision-language pre-training framework designed to address the limitations of existing models in unifying understanding and generation tasks, while mitigating performance degradation caused by noisy web data. Its core innovations lie in two aspects: Model-wise, it proposes a Multimodal Mixture of Encoder-Decoder (MED) architecture that supports three modes—unimodal encoders (for global feature alignment via image-text contrastive loss, ITC), cross-modal encoders (for fine-grained matching via image-text matching loss, ITM), and cross-modal decoders (for caption generation via language modeling loss, LM)—jointly optimized to bridge understanding (e.g., retrieval) and generation (e.g., captioning). Data-wise, it introduces Captioning and Filtering (CapFilt), a bootstrapping strategy where a pre-trained MED generates synthetic captions (via the Captioner module) and filters noise from both web-derived and synthetic texts (via the Filter module), thereby distilling high-quality training data. Experiments demonstrate BLIP’s state-of-the-art performance on tasks like image-text retrieval and captioning, along with strong zero-shot transfer to video-language tasks. While its flexible architecture and data enhancement overcome multi-task bottlenecks, challenges include higher computational costs in data purification and limited exploration of temporal modeling. Future directions may explore iterative data augmentation rounds, optimizing generation diversity, and extending to video-language domains to unlock further potential.
文章信息
Title:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Author:Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
Source:https://arxiv.org/abs/2201.12086
引言
CLIP 之后,各种视觉语言与训练模型(Vision-Language Pre-training, VLP)相继被提出,显著提高了各种视觉语言任务的性能。然而,现有的 VLP 方法主要存在以下两个问题:
- 模型的角度:BLIP之前的大多数方法要么是基于编码器的模型,要么就是基于编码器-解码器的模型,但基于编码器的模型难以完成文本生成任务,基于编码器-解码器的模型难以完成图像-文本检索任务。
- 数据角度:大多数方法的数据是来自网络上的,尽管通过扩大数据集对模型性能的提升有帮助,但直接从网上获取的数据有噪声,有噪声的文本对视觉-语言学习来说是次优的。
为了让 VLP 同时具有图文多模态的理解和生成能力,BLIP提出一种全新的多模态混合架构 MED(Multimodal mixture of Encoder and Decoder),为了去除网络上获得的数据的噪声,BLIP在预训练完成的 MED 基础上引入了 CapFilt。
方法
BLIP 全称是 Bootstrapping Language-Image Pre-training,是一种统一视觉语言理解与生成的预训练模型。BLIP的网络架构如下图所示:

MED
BLIP 采用了基于 编码器 - 解码器的多模态混合结构 (Multimodal mixture of Encoder-Decoder, MED),其包括两个单模态编码器:图像编码器和文本编码器,两个多模态编码器:基于图像的文本编码器和解码器。
- 单模态图像编码器:其实就是一个VIT,将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征。
- 单模态文本编码器:基于BERT架构,其中 [CLS] token 附加到文本输入的开头以总结句子。作用是提取文本特征做对比学习。
- 以图像为基础的文本编码器:在 Text Encoder 的 self-attention 层和前馈网络之间加入 交叉注意 (cross-attention, CA) 层用来注入视觉信息,并将 [Encode] token 加到输入文本的开头以以标识特定任务。作用是根据 ViT 给的图片特征和文本输入做二分类,判断图文是否匹配。
- 以图像为基础的文本解码器:与Image-grounded text encoder 不同的是,双向自注意力层换为了causal self-attention(因果关系注意力),并将 [Decode] token 和 [EOS] token 加到输入文本的开头和结尾以标识序列的开始和结束。作用是生成符合图像的文本描述。
lmage Encoder、Text Encoder、Image-grounded text encoder、Image-grounded text decoder 三个模块的结构比较相似,而且共享了部分参数(架构图中相同颜色的部分,比如三个模块的Feed Foward的颜色一样,共享参数)。另外,每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型。
预训练
预训练时需要共同优化三个目标,包括两个理解任务的目标函数和一个生成任务的目标函数,具体如下:
- 图文对比损失(Image-Text Contrastive Loss, ITC):ITC作用于单模态的图像编码器和文本编码器,通过对比学习对齐图像和文本的特征空间(类似于CLIP)。具体方法为最大化正样本图像 - 文本对的相似度且最小化负样本图像 - 文本对的相似度,使匹配的图文对在特征空间中更接近,非匹配对更远离。另外,这里用到了ALBEF 中的动量编码器,其目的是产生一些伪标签以辅助模型的训练。
- 图文匹配损失 (Image-Text Matching Loss, ITM):ITM作用于单模态图像编码器和多模态的基于图像的文本编码器,通过学习图像 - 文本对的联合表征实现视觉和语言之间的细粒度对齐。具体方法是通过一个二分类任务,预测图像文本对是正样本还是负样本(图文对是否匹配)。另外,这里用到了ALBEF 中的 hard negative mining 技术以更好地捕捉负样本信息。
- 语言建模损失(Language Modeling Loss, LM):LM作用于单模态图像编码器和多模态的基于图像的文本解码器(生成任务),目标是根据给定的图像以自回归方式来生成关于文本的描述。具体方法是通过优化交叉熵损失函数,训练模型以自回归的方式最大化文本的概率。
CapFilt
高质量的人工注释图像-文本对 { ( I h , T h ) } \{(I_h,T_h)\} {(Ih,Th)}(如CoCo)的数量有限,所以之前的方法都是用网上获取的大量图像-文本对 { ( I w , T w ) } \{(I_w,T_w)\} {(Iw,Tw)}作为训练数据,但这些网络数据中的文本难以精准地描述图像内容,存在大量噪声。

如上图,图片是巧克力蛋糕,而其文本却不是对图片的描述,属于噪声数据。
BLIP 提出 CapFilt 的机制来从有大量噪声的数据中获取质量更高的数据。其具体方法和步骤如下图:

CapFilt 包含两个模块,过滤模块 Filter 和生成文本模块 Captioner:
- Filter:用于去除噪声图文对,基于文本编码器 Image-grounded text encoder 实现,使用 ITC 和 ITM 损失函数在 COCO 数据集上进行微调。
- Captioner:用于生成给定图像的描述文本,基于文本解码器 Image-grounded text decoder 实现,使用 LM 损失函数在 COCO 数据集上进行微调。

BLIP 先使用含有噪声的网络数据集进行预训练;
再用COCO数据集对 Image-grounded text encoder 和 Image-grounded text decoder 进行微调,得到 Filter 和 Captioner ,然后利用 Captioner 生成图片对应的生成描述文本( T s T_s Ts),Filter 对网上获取的图文对进行过滤,去除其认为不匹配的图文对,同时对 Captioner 生成的图像文本对 { ( I w , T s ) } \{(I_w,T_s)\} {(Iw,Ts)}进行过滤,最终得到高质量的数据集 { ( I w , T w ) } + { ( I w , T s ) } \{(I_w,T_w)\}+\{(I_w,T_s)\} {(Iw,Tw)}+{(Iw,Ts)}(这里的数据都是经过过滤的);
过滤后的数据加上高质量的COCO数据集 { ( I h , T h ) } \{(I_h,T_h)\} {(Ih,Th)},作为训练集,重新训练一个BLIP(从头训练),得到一个高性能的 BLIP。
关键代码
BLIP_Base 类:实现了 Text Encoder 和 Image-grounded Text Encoder ,当 mode 为 ‘multimodal’ 时实现的是Image-grounded Text Encoder。
class BLIP_Base(nn.Module):def __init__(self, med_config = 'configs/med_config.json', image_size = 224,vit = 'base',vit_grad_ckpt = False,vit_ckpt_layer = 0, ):"""Args:med_config (str): 混合编码器 - 解码器模型的配置文件路径image_size (int): 输入图像的大小vit (str): 视觉Transformer的模型大小""" super().__init__()# 创建视觉编码器self.visual_encoder, vision_width = create_vit(vit,image_size, vit_grad_ckpt, vit_ckpt_layer)# 初始化分词器self.tokenizer = init_tokenizer() # 从JSON文件加载Bert配置med_config = BertConfig.from_json_file(med_config)# 设置编码器宽度med_config.encoder_width = vision_width# 创建文本编码器self.text_encoder = BertModel(config=med_config, add_pooling_layer=False) def forward(self, image, caption, mode):# 确保模式参数为 'image', 'text', 'multimodal' 之一assert mode in ['image', 'text', 'multimodal'], "mode parameter must be image, text, or multimodal"# 对输入的文本进行分词处理text = self.tokenizer(caption, return_tensors="pt").to(image.device) if mode=='image': # 返回图像特征image_embeds = self.visual_encoder(image) return image_embedselif mode=='text':# 返回文本特征text_output = self.text_encoder(text.input_ids, attention_mask = text.attention_mask, return_dict = True, mode = 'text') return text_output.last_hidden_stateelif mode=='multimodal':# 返回多模态特征image_embeds = self.visual_encoder(image) image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device) text.input_ids[:,0] = self.tokenizer.enc_token_idoutput = self.text_encoder(text.input_ids,attention_mask = text.attention_mask,encoder_hidden_states = image_embeds,encoder_attention_mask = image_atts, return_dict = True,) return output.last_hidden_state
VisionTransformer 类:实现 image encoder
class VisionTransformer(nn.Module):""" Vision TransformerA PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -https://arxiv.org/abs/2010.11929"""def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,num_heads=12, mlp_ratio=4., qkv_bias=True, qk_scale=None, representation_size=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=None, use_grad_checkpointing=False, ckpt_layer=0):"""Args:img_size (int, tuple): 输入图像的大小patch_size (int, tuple): 图像块的大小in_chans (int): 输入通道数num_classes (int): 分类头的类别数embed_dim (int): 嵌入维度depth (int): Transformer的深度num_heads (int): 注意力头的数量mlp_ratio (int): MLP隐藏维度与嵌入维度的比例qkv_bias (bool): 是否启用qkv的偏置qk_scale (float): 覆盖默认的qk缩放比例representation_size (Optional[int]): 启用并设置表示层的大小drop_rate (float): 丢弃率attn_drop_rate (float): 注意力丢弃率drop_path_rate (float): 随机深度率norm_layer: (nn.Module): 归一化层"""super().__init__()self.num_features = self.embed_dim = embed_dim # 为了与其他模型保持一致norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)# 图像块嵌入层self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)num_patches = self.patch_embed.num_patches# 分类标记self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# 位置嵌入self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))# 位置丢弃层self.pos_drop = nn.Dropout(p=drop_rate)# 随机深度衰减规则dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] self.blocks = nn.ModuleList([Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,use_grad_checkpointing=(use_grad_checkpointing and i>=depth-ckpt_layer))for i in range(depth)])# 归一化层self.norm = norm_layer(embed_dim)# 初始化位置嵌入和分类标记trunc_normal_(self.pos_embed, std=.02)trunc_normal_(self.cls_token, std=.02)self.apply(self._init_weights)
BLIP_Decoder 类:实现image-grounded decoder
class BLIP_Decoder(nn.Module):def __init__(self, med_config = 'configs/med_config.json', image_size = 384,vit = 'base',vit_grad_ckpt = False,vit_ckpt_layer = 0,prompt = 'a picture of ',):"""Args:med_config (str): 混合编码器 - 解码器模型的配置文件路径image_size (int): 输入图像的大小vit (str): 视觉Transformer的模型大小prompt (str): 提示文本""" super().__init__()# 创建图像编码器self.visual_encoder, vision_width = create_vit(vit, image_size, vit_grad_ckpt, vit_ckpt_layer)# 初始化分词器self.tokenizer = init_tokenizer() # 从JSON文件加载Bert配置med_config = BertConfig.from_json_file(med_config)# 设置编码器宽度med_config.encoder_width = vision_width# 创建文本解码器self.text_decoder = BertLMHeadModel(config=med_config) self.prompt = promptself.prompt_length = len(self.tokenizer(self.prompt).input_ids) - 1def forward(self, image, caption):# 获取图像特征image_embeds = self.visual_encoder(image) image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image.device)# 对输入的文本进行分词处理text = self.tokenizer(caption, padding='longest', truncation=True, max_length=40, return_tensors="pt").to(image.device) text.input_ids[:, 0] = self.tokenizer.bos_token_id# 生成解码器的目标标签decoder_targets = text.input_ids.masked_fill(text.input_ids == self.tokenizer.pad_token_id, -100) decoder_targets[:, :self.prompt_length] = -100# 进行解码操作decoder_output = self.text_decoder(text.input_ids, attention_mask = text.attention_mask, encoder_hidden_states = image_embeds,encoder_attention_mask = image_atts, labels = decoder_targets,return_dict = True, ) # 获取语言模型损失loss_lm = decoder_output.lossreturn loss_lmdef generate(self, image, sample=False, num_beams=3, max_length=30, min_length=10, top_p=0.9, repetition_penalty=1.0):# 获取图像特征image_embeds = self.visual_encoder(image)if not sample:# 复制图像特征以进行波束搜索image_embeds = image_embeds.repeat_interleave(num_beams, dim=0)image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image.device)model_kwargs = {"encoder_hidden_states": image_embeds, "encoder_attention_mask": image_atts}# 生成提示文本的输入IDprompt = [self.prompt] * image.size(0)input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids.to(image.device) input_ids[:, 0] = self.tokenizer.bos_token_idinput_ids = input_ids[:, :-1] if sample:# 核采样outputs = self.text_decoder.generate(input_ids=input_ids,max_length=max_length,min_length=min_length,do_sample=True,top_p=top_p,num_return_sequences=1,eos_token_id=self.tokenizer.sep_token_id,pad_token_id=self.tokenizer.pad_token_id, repetition_penalty=1.1, **model_kwargs)else:# 波束搜索outputs = self.text_decoder.generate(input_ids=input_ids,max_length=max_length,min_length=min_length,num_beams=num_beams,eos_token_id=self.tokenizer.sep_token_id,pad_token_id=self.tokenizer.pad_token_id, repetition_penalty=repetition_penalty,**model_kwargs) captions = [] for output in outputs:# 解码生成的文本caption = self.tokenizer.decode(output, skip_special_tokens=True) captions.append(caption[len(self.prompt):])return captions
实验结果
下表对比了不同数据集上的预训练模型的性能
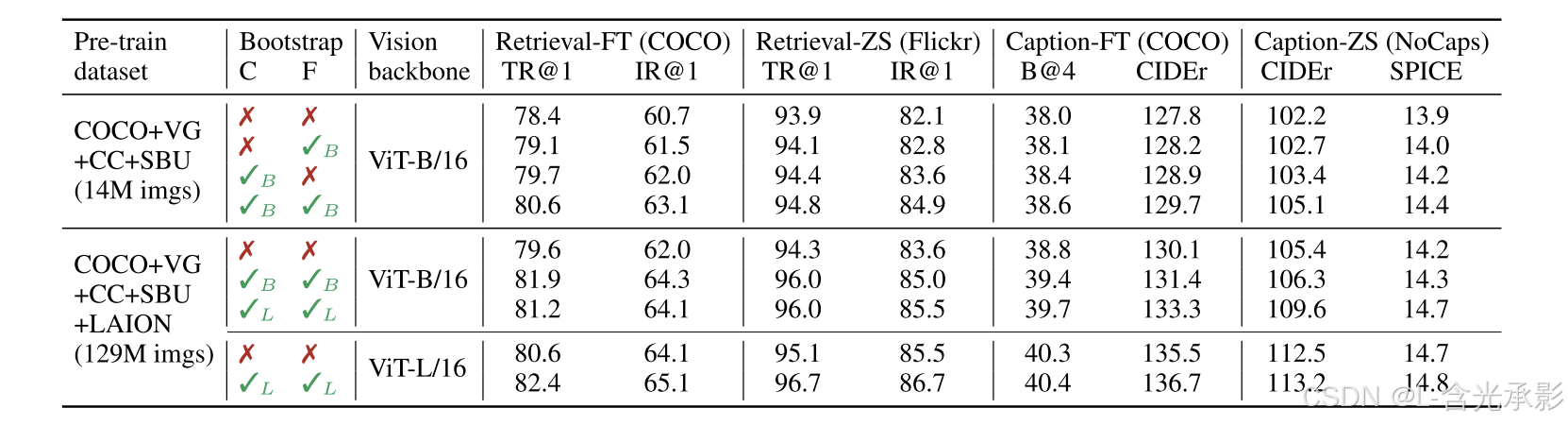
当模型一样时,使用更大的数据集,一般会带来更好的性能。当使用一样的数据集时,更大的模型效果更好。另外,论文提出的CapFilt对模型性能提升有帮助,特别是Captioner。
另外,第一次预训练模型和微调是为了得到Captioner和Filter,从而获得质量更高、更大的数据集,此次的模型与第二次预训练的模型没有任何关系,第二次训练得到的模型才是最终的模型。
总结
BLIP是一种创新的视觉-语言预训练框架,旨在统一跨模态理解(如图像检索)与生成(如图像描述)任务,同时解决网络数据噪声对模型性能的负面影响。其核心架构多模态混合编码器-解码器(MED)通过共享参数实现三种模式:单模态编码器(用于图像-文本对比学习ITC对齐全局特征)、基于图像的文本编码器(通过图像-文本匹配损失ITM学习细粒度对齐)和基于图像的文本解码器(通过语言建模损失LM生成描述),三者联合优化以支持多任务学习。BLIP提出Captioning & Filtering(CapFilt)策略:首先利用预训练的MED生成合成描述(Captioner模块),再通过过滤模块(Filter)剔除原始网络文本和合成文本中的噪声样本,最终结合高质量数据重新训练模型,显著提升跨模态对齐能力。BLIP的优势在于通过统一架构和高效数据增强实现了多任务SOTA性能,且零样本迁移能力强;缺点可能在于大规模数据清洗的计算成本较高,且对复杂时空建模(如视频任务)尚未深入。未来方向可探索多轮数据增强、多模态生成多样性优化,以及结合时序建模扩展至视频-语言领域。