《深入浅出Git:从版本控制原理到高效协作实战》
Git的原理和使用
- 1、Git初识与安装
- 2、Git基本操作
- 2.1、创建Git本地仓库
- 2.2、配置Git
- 2.3、认识工作区、暂存区、版本库
- 2.4、修改文件
- 2.5、版本回退
- 2.6、撤销修改
- 2.7、删除文件
- 3、Git分支管理
- 3.1、理解分支
- 3.2、创建、切换、合并分支
- 3.3、删除分支
- 3.4、合并冲突
- 3.5、合并模式
- 3.6、分支管理策略
- 3.7、bug分支
- 3.8、强制删除分支
- 4、Git远程操作
- 4.1、理解分布式版本控制系统
- 4.2、创建远程仓库
- 4.3、克隆远程仓库
- 4.4、向远程仓库推送
- 4.5、拉取远程仓库
- 4.6、忽略特殊文件
- 4.7、配置命令别名
- 5、标签管理
- 5.1、操作标签
- 5.2、推送标签
- 6、多人协作
- 6.1、完成准备工作
- 6.2、协作开发
- 6.3、将内容合并进master
- 6.4、多人协作2
- 6.5、解决本地打印已被删除分支的方法
- 7、企业级开发模型
- 7.1、企业级开发流程
- 7.2、系统开发环境
- 7.3、Git分支设计模型
- 7.4、企业级项目管理准备工作
- 7.5、企业级项目管理开发场景实操
1、Git初识与安装
假设今天你的老板让你实现一份设计文档,你做完之后将它发给你老板,老板说这做的不好,继续改一下。这时候你进行了第一次修改,然后再发给他。老板还是觉得不好让你继续修改。这时候你进行第二次修改,如此往复直到第五次修改完之后,你老板说怎么改的还没第一次改得好,你现在把第一次改的发给我吧。那么这时候就有问题了,你在改设计文档的时候都是在原来那份上改的,现在你已经不知道第一次改的那份文档是啥样的了,所以你也就无法发给老板了。
那么现在还是修改设计文档,第一次修改完之后你把这份文档命名为设计文档v1,当老板不满意需要你继续修改时,你就拷贝一份副本然后修改,最后命名为设计文档v2。如此一直到设计文档v5,当你的老板要你第一次修改的文档时,你就可以将之前保存的设计文档v1发给他了。但是随着版本的不断增多,维护好版本是很有挑战的。而且各自版本修改的内容我们不一定能记得了。
所以就需要版本控制器:记录每次修改以及版本迭代的一个管理系统。目前最主流的就是Git。
Git可以控制电脑上的所有格式的文档,对于我们开发人员来说可以控制项目中的源代码文档。
还需要再明确一点,所有的版本控制系统,Git也不例外,其实只能跟踪文本文件的改动,比如TXT文件,网页,所有的程序代码等等。版本控制系统可以告诉你每次的改动,比如在第5行加了一个单词 “Linux”,在第8行删了一个单词 “Windows”。 而图片、视频这些二进制文件,虽然也能由版本控制系统管理,但没法跟踪文件的变化,只能把二进制文件每次改动串起来,也就是只知道图篇从100KB改成了120KB,但到底改了啥,版本控制系统不知道,也没法知道。
使用如下命令查看是否安装了git:
git --version
CentOS可以使用以下命令安装:
sudo yum -y install git
Ubuntu可以使用以下命令安装:
sudo apt install git
2、Git基本操作
2.1、创建Git本地仓库
要提前说的是,仓库是进行版本控制的一个文件目录。我们要想对文件进行版本控制,就必须先创建一个仓库出来。创建一个Git本地仓库对应的命令为git init ,注意命令要在文件目录下执行。
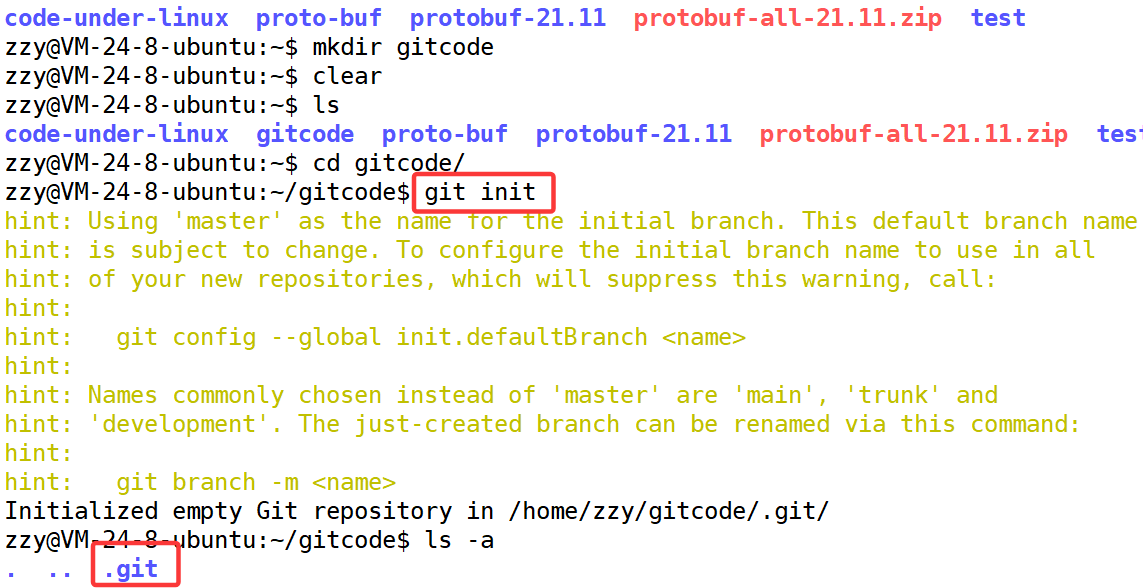
创建后当前目录下会多出一个.git的隐藏文件。
2.2、配置Git
当安装Git后首先要做的事情是设置你的用户名称和e-mail地址,这是非常重要的。
git config [--global] user.name "Your Name"
git config [--global] user.email "email@example.com"
# 把 Your Name 改成你的昵称
# 把 email@example.com 改成邮箱的格式,只要格式正确即可。
查看配置的命令为:
git config -l
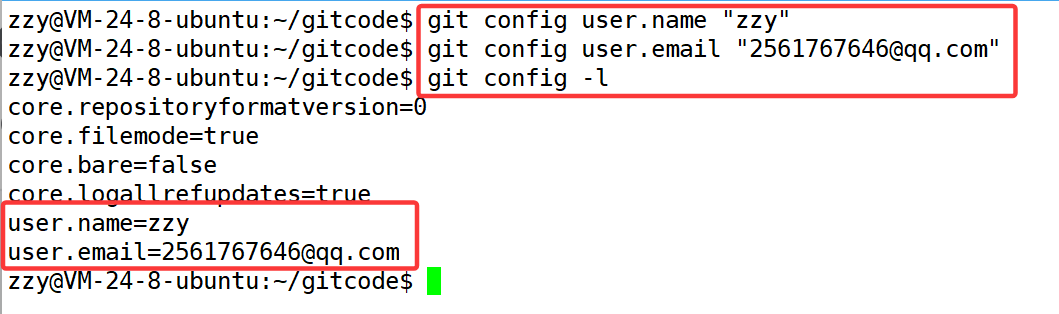
想要取消配置可以使用如下命令:
git config [--global] --unset user.name
git config [--global] --unset user.email
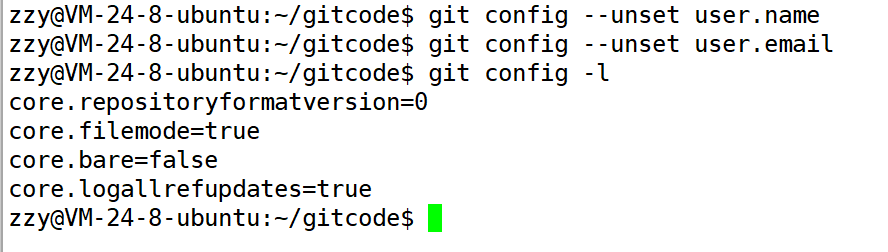
其中--global是一个可选项。如果使用了该选项,表示这台机器上所有的Git仓库都会使用这个配置。如果你希望在不同仓库中使用不同的name或e-mail,可以不要--global选项,但要注意的是,执行命令时必须要在仓库里。
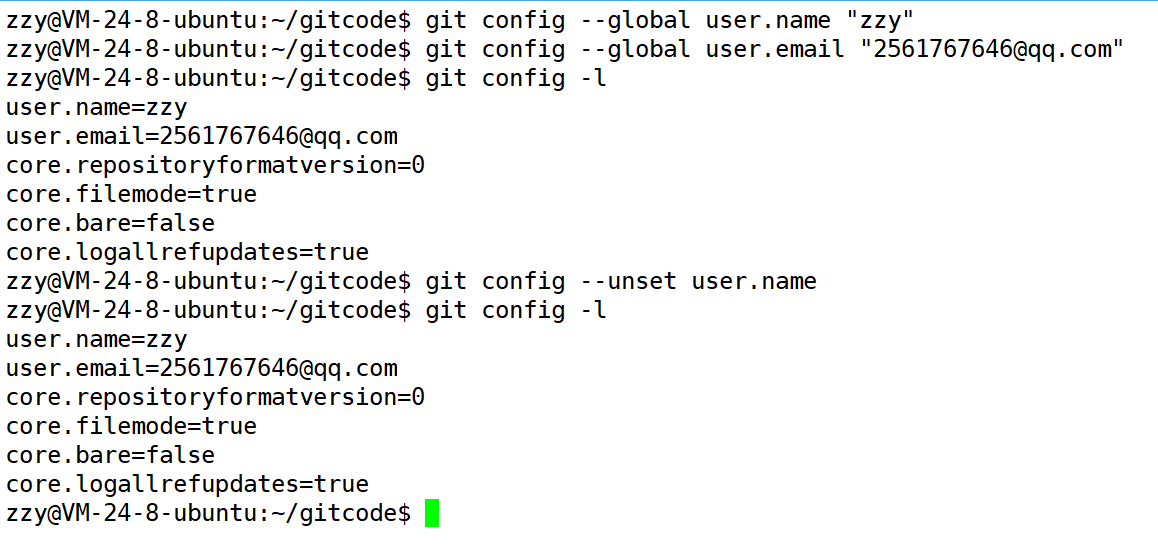
当我们使用了--global,那么直接--unset是无法移除配置的,需要同时携带--global和--unset。
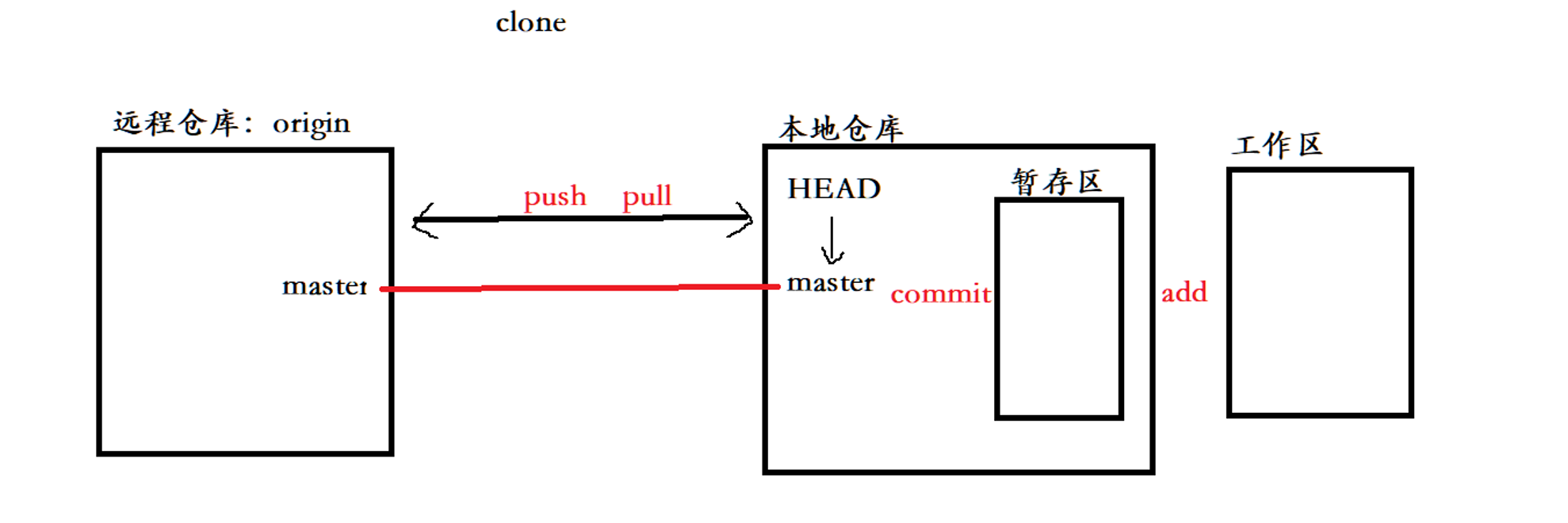
2.3、认识工作区、暂存区、版本库
我们在之前初始化仓库目录下创建要给ReadMe文件。目前情况下,Git能否管理ReadMe文件?答案是不行。
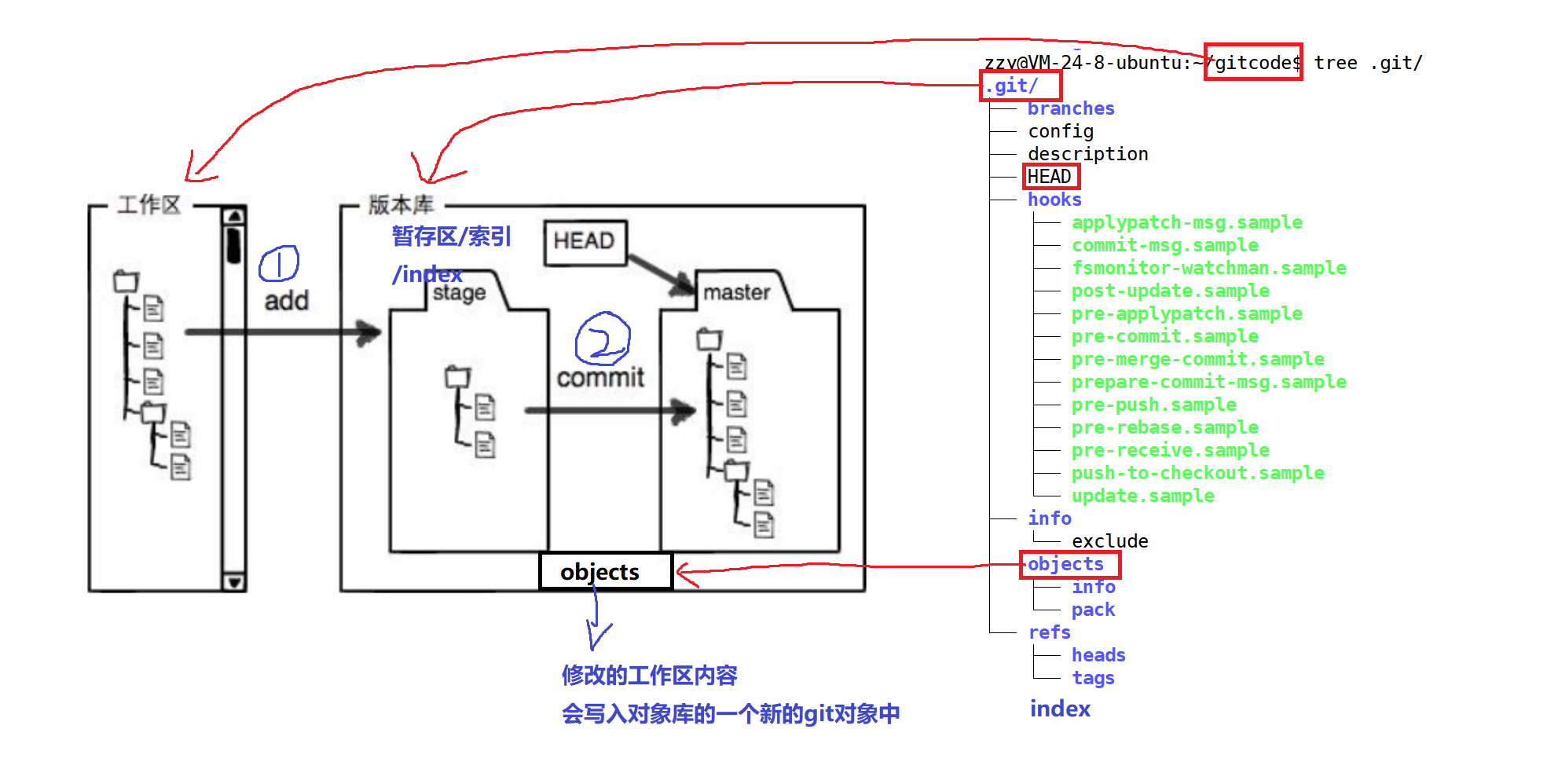
如图,我们所在的gitcode实际上是工作区,而.git是版本库,也就是我们所说的仓库。那我们能直接把ReadMe放到.git目录下进行管理吗?答案是不行的,不允许在.git下手动修改!实际上我们需要经过两步:1、git add将工作区修改的内容添加到版本库的stage中,这个就是暂存区/索引。2、git commit将暂存区的内容提交到master分支下。通过这两步才算是真正将内容放到了版本库中。另外暂存区还会有一个对象库objects,当我们修改工作区的内容会写入对象库中一个新的git对象。暂存区里面存放的就是对象库中的git对象的索引,master也是如此,暂通过git commit会将暂存区中的内容添加到master中。暂存区是在.git/index下的,但是当前我们并没有这个文件,因为我们是刚创建的仓库,还没有进行add。
• 在创建Git版本库时,Git会为我们自动创建一个唯一的master分支,以及指向master的一个指针叫HEAD。(分支和HEAD的概念后面再说)
• 当对工作区修改(或新增)的文件执行git add命令时,暂存区目录树的文件索引会被更新。
• 当执行提交操作git commit时,master分支会做相应的更新,可以简单理解为暂存区的目录树才会被真正写到版本库中。
由上述描述我们便能得知:通过新建或粘贴进目录的文件,并不能称之为向仓库中新增文件,而只是在工作区新增了文件。必须要通过使用git add和git commit命令才能将文件添加到仓库中进行管理!!!
那么下面就对我们创建的这个文件添加到版本库中:

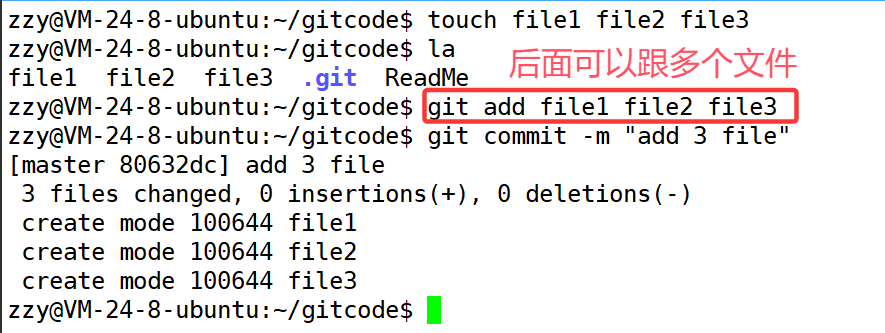
我们创建三个文件继续添加:
通过git log查看提交日志信息:

commit后面的内容就是commit id,并且可以看到之前我们设置的name和email,以及提交的日期,HEAD指针是指向master的。
通过git log --pretty=oneline查看可观的提交信息:

下面我们再看看.git目录发生的变化:
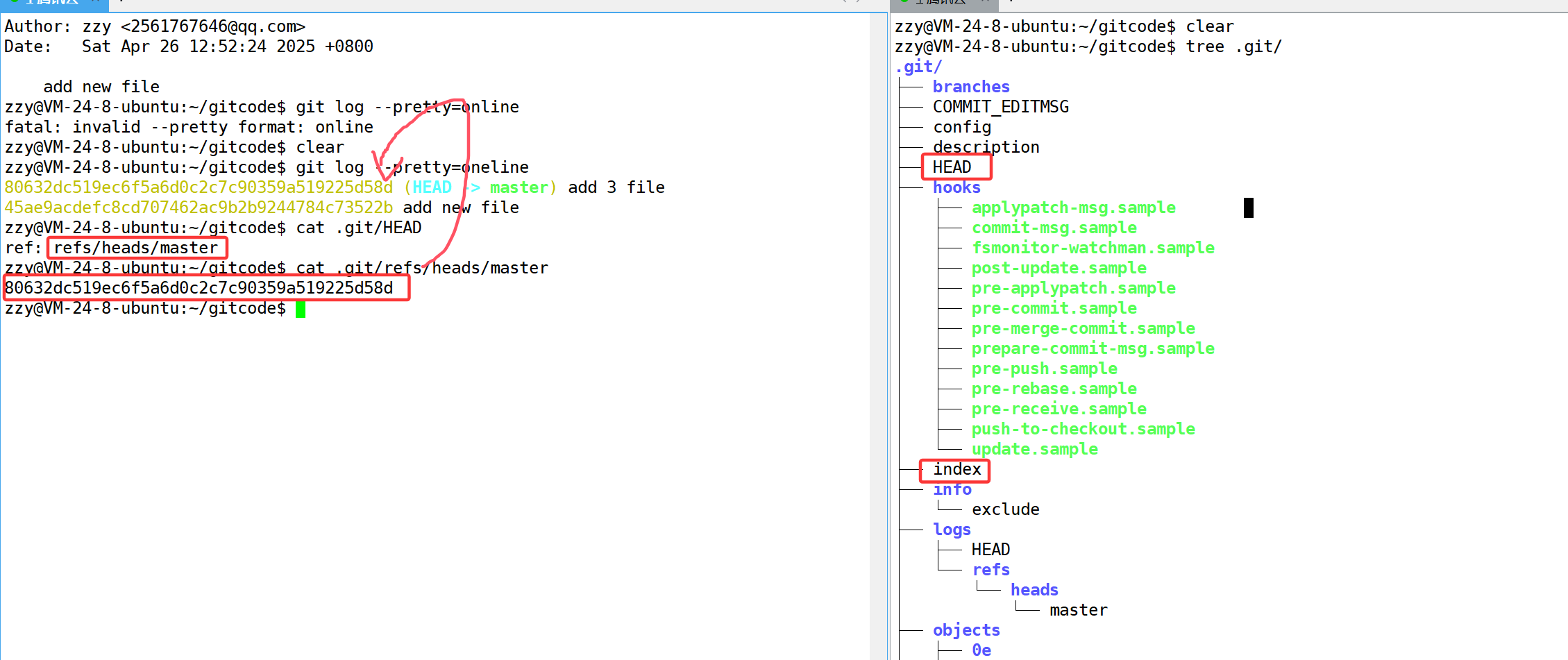
我们发现果然多了一个index文件,这个就是上面所说的暂存区了。我们使用cat命令打印HEAD内容,发现它果然是指向master的,接着我们再打印master的内容,里面存放的就是最新的commit id。这个实际上就是一个git对象。
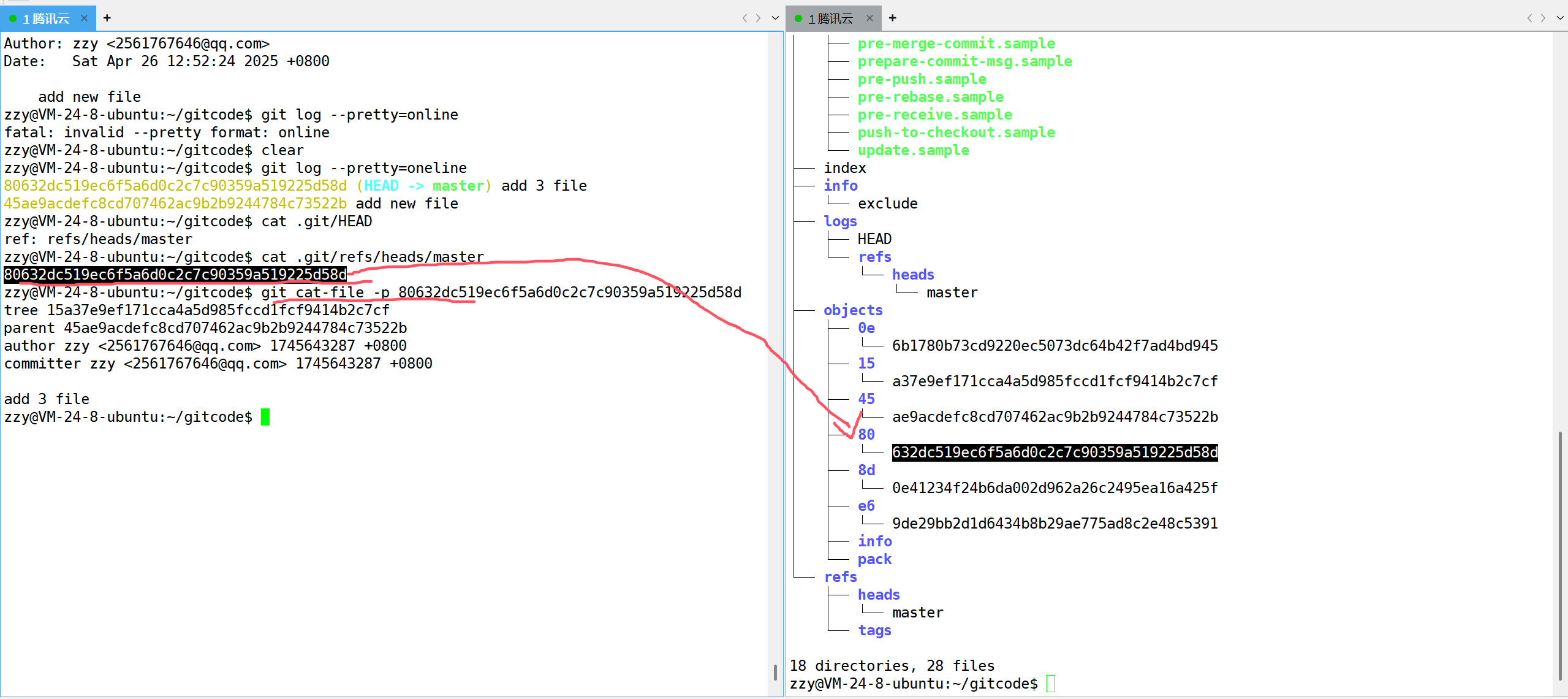
这个id我们需要分成两个部分来看,前两位80表示目录,后面的就是文件了,对应右边.git目录结构所示。接下来我们需要使用git cat-file -p来查看这个git对象里面保存了什么信息。-p表示pretty,让格式好看一些。
同时我们呢可以注意到parent就是上一次提交的commit id。接下来我们再打印tree的内容看看里面保存的是什么:
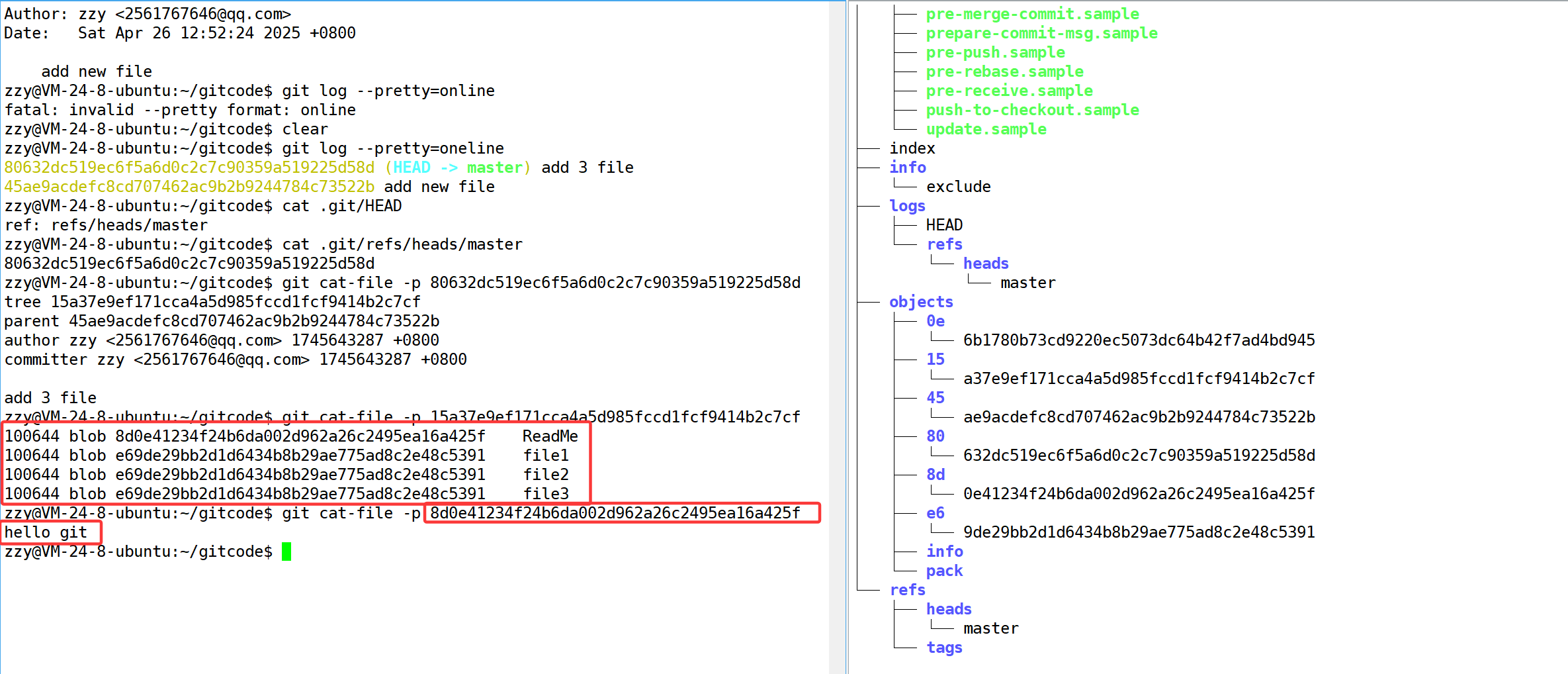
获取tree的内容后我们继续打印对于ReadMe的信息,我们发现我们添加了以行hello git被记录了下来,所以将来我们对于文件修改(增加、修改、删除)的操作,通过add commit之后,都会被对象库中的git对象记录下来。
2.4、修改文件
Git比其他版本控制系统设计得优秀,因为Git跟踪并管理的是修改,而非文件。 什么是修改?比如你新增了一行,这就是一个修改,删除了一行,也是一个修改,更改了某些字符,也是一个修改,删了一些又加了一些,也是一个修改,甚至创建一个新文件,也算一个修改。
下面我们给ReadMe文件添加以行hello word。
接着我们使用git status可以查看工作区的状态:
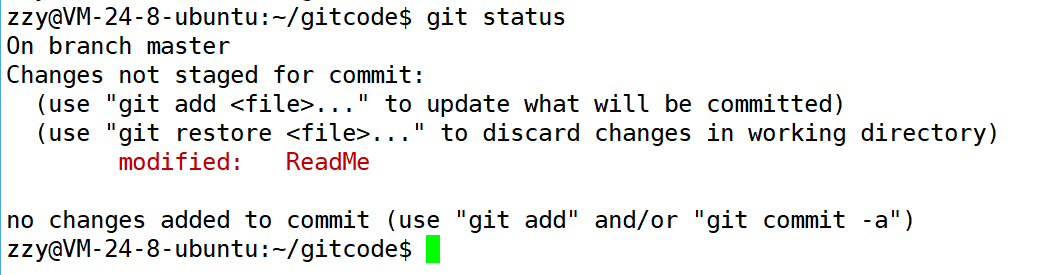
没有暂存区的内容可以提交,因为我们还没有add添加到暂存区。并且可以看到我们ReadMe文件在工作区被修改了。
但是我们怎么知道新增了哪些内容呢?因为上面我们进行测试只有两行,但是将来写代码可能会有成百上前行,你并不一定能记得住。所以就需要使用git diff命令查看工作区和版本库文件的区别:
git diff [file]命令用来显示暂存区和工作区文件的差异,显示的格式正是Unix通用的diff格式。也可以使用git diff HEAD – [file]命令来查看版本库和工作区文件的区别。
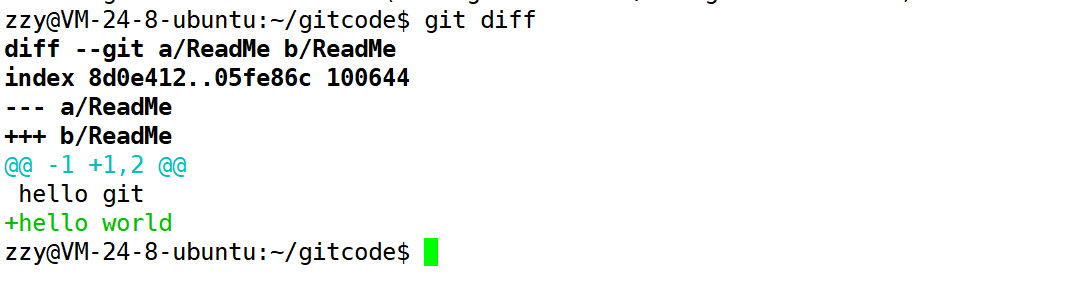
a/ReadMe表示修改前的ReadMe文件,b/ReadMe表示修改后的ReadMe文件。—表示修改前,+++表示修改后。-1表示修改前的第一行,+1,2表示修改后的第一行和第二行。下面显示我们新增了hello world内容。
接着我们添加到仓库中:
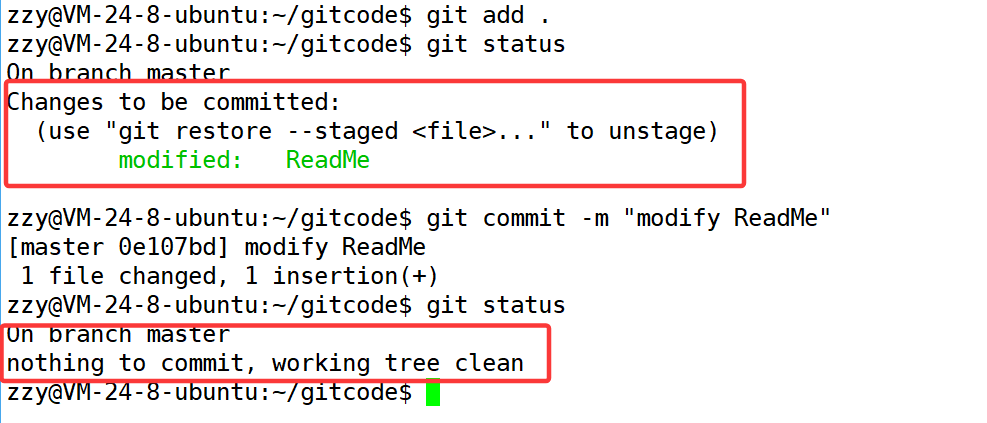
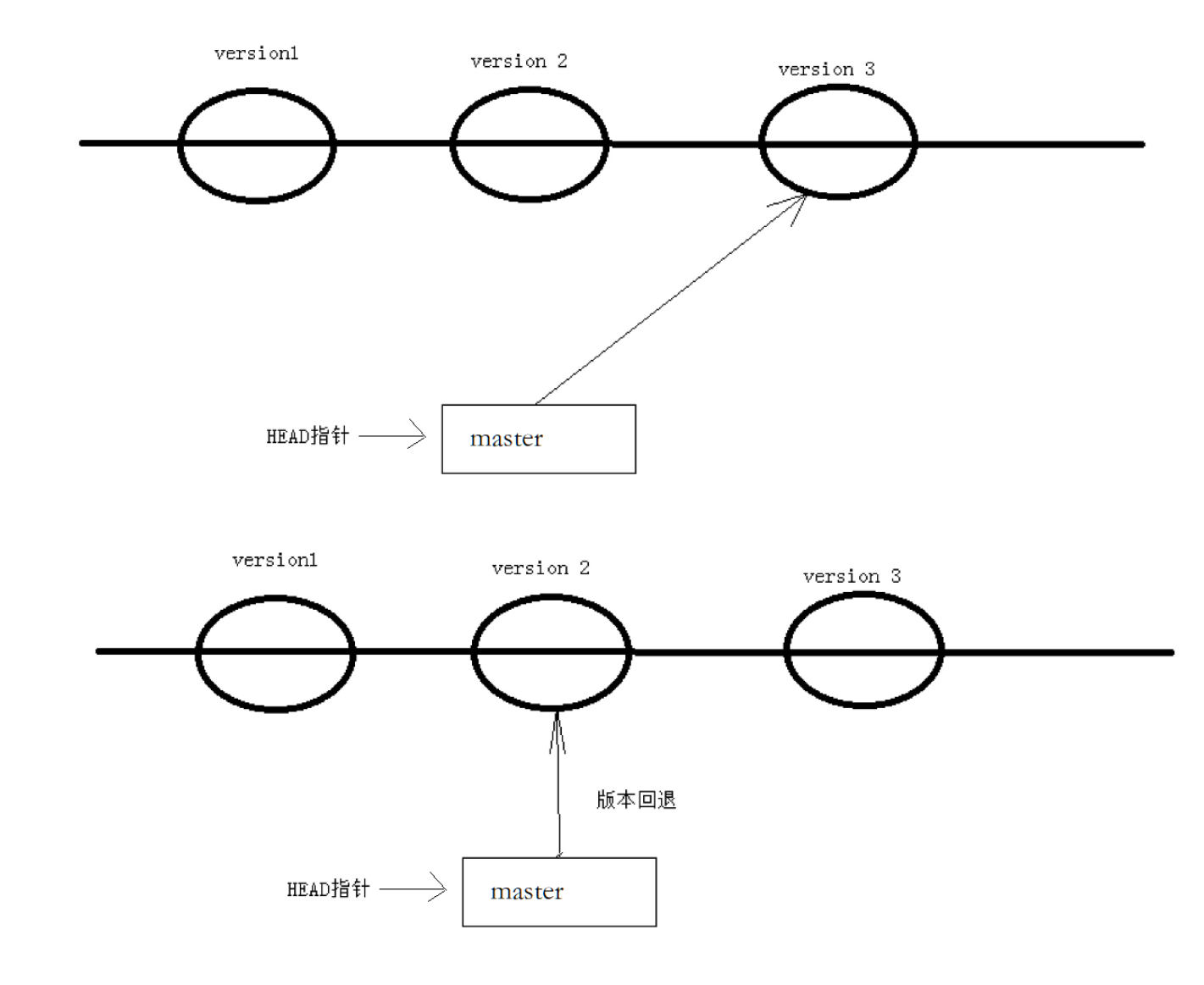
2.5、版本回退
之前我们也提到过,Git能够管理文件的历史版本,这也是版本控制器重要的能力。如果有一天你发现之前前的工作做的出现了很大的问题,需要在某个特定的历史版本重新开始,这个时候,就需要版本回退的功能了。
执行git reset命令用于回退版本,可以指定退回某一次提交的版本。要解释⼀下回退本质是要将版本库中的内容进行回退,工作区或暂存区是否回退由命令参数决定:
git reset 命令语法格式为: git reset [–soft | --mixed | --hard] [HEAD]
• --mixed为默认选项,使用时可以不用带该参数。该参数将暂存区的内容退回为指定提交版本内容,工作区文件保持不变。
• --soft参数对于工作区和暂存区的内容都不变,只是将版本库回退到某个指定版本。
• --hard参数将暂存区与工作区都退回到指定版本。切记工作区有未提交的代码时不要用这个命令,因为工作区会回滚,你没有提交的代码就再也找不回了,所以使用该参数前⼀定要慎重。

我们以之前写的为例:

ReadMe现在有两行,我们以git和world简写替代,对于工作区、暂存区、版本库现在都是一样的,都有git、world。现在我们需要进行版本回退,回退到ReadMe文件中只有git,如果使用了--soft选项,那么就只有版本库进行了回退。如果使用了--mixed,暂存区和版本库都回回退,这是默认选项。如果使用了--hard选项,那么工作区、暂存区、版本库中就都只剩下git内容了,所以这个选项一定要慎用。
下面回退到只有hello git的时候:我们以--hard演示
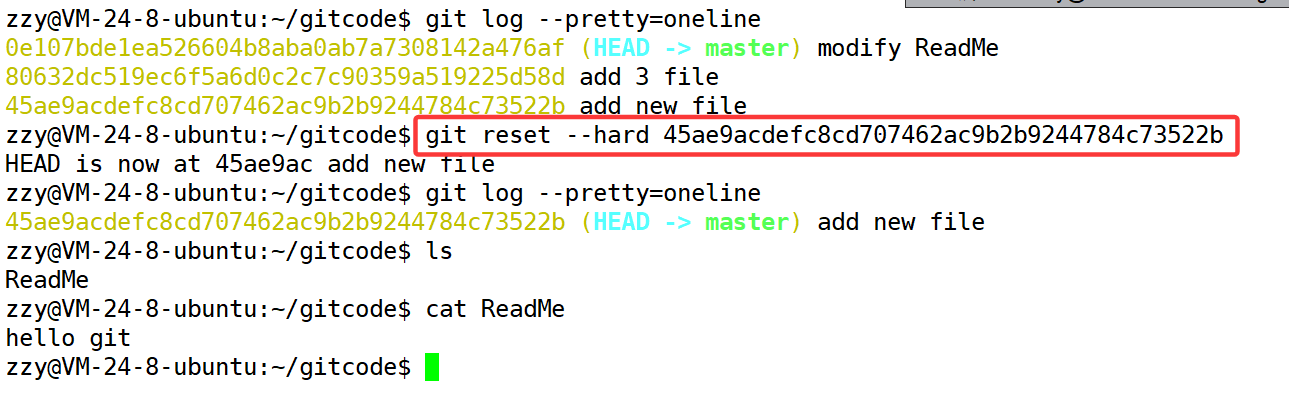
如图,成功实现了版本回退,但是如果我后悔了怎么办,没关系,我们可以继续使用git reset恢复:
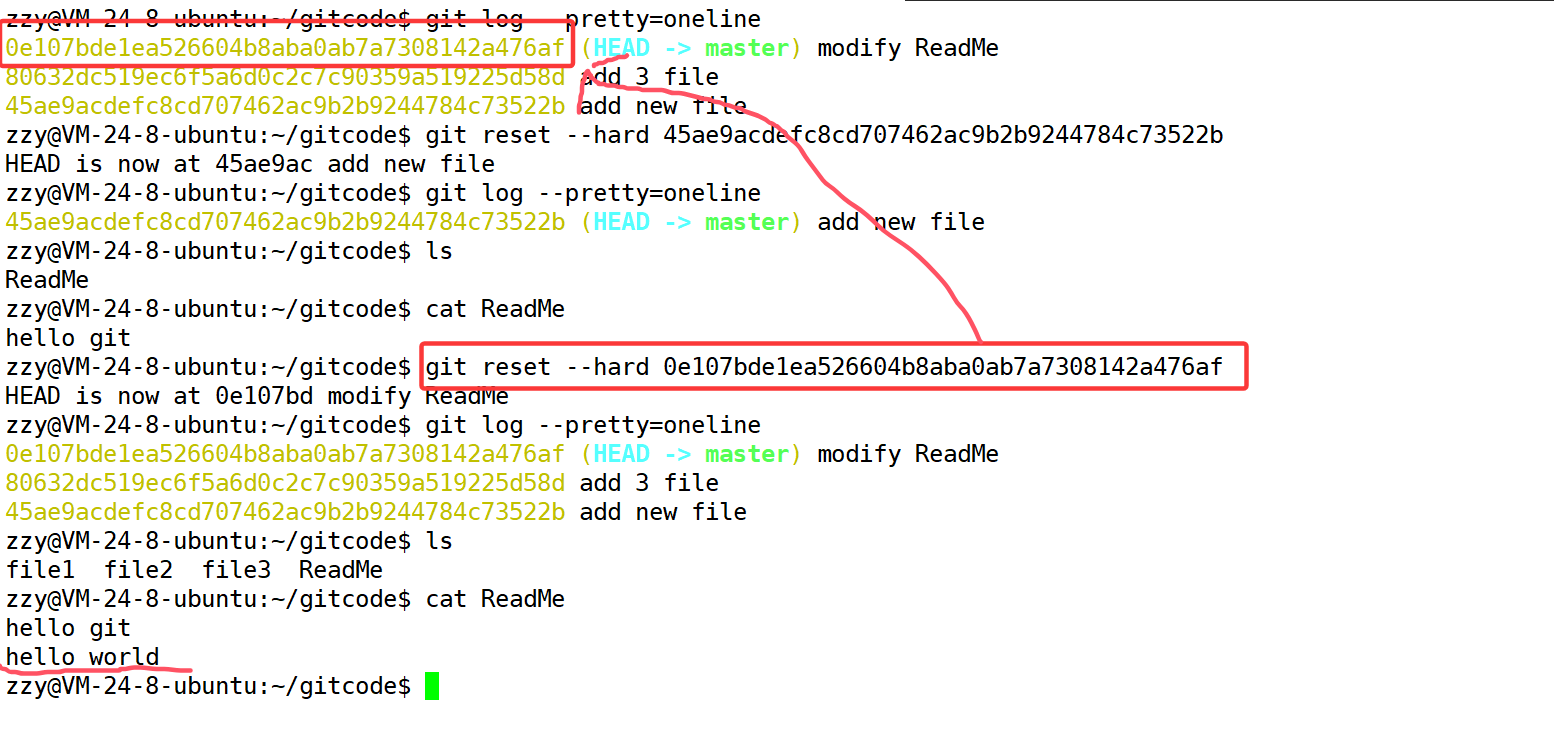
这是因为我们刚才打印了日志获取到了commit id,所以可以通过这个id恢复回来。
那如果我们不知道这个id呢?Git 还提供了一个git reflog命令能补救一下,该命令用来记录本地的每一次命令。
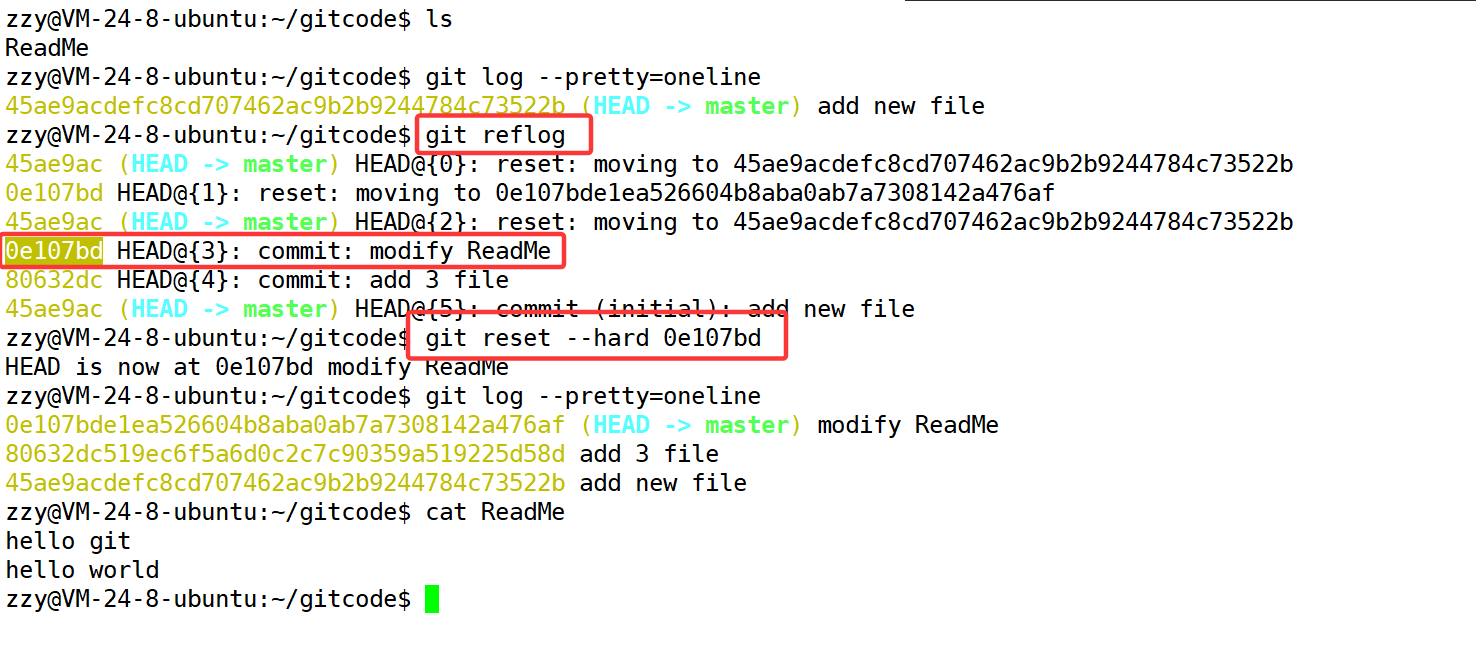
这个0e107bd实际上就是commit id,只不过他是完整的commit id的一部分,通过这个我们可以进行版本回退,成功恢复。但是随着长时间的开发,过一段时间如果想回退,可能commit id已经找不到了,这时候就没办法回退了。
并且我们注意到Git回退版本的速度非常之快,这是因为版本回退本质上是回退版本库的内容,实际上就是修改master。
2.6、撤销修改
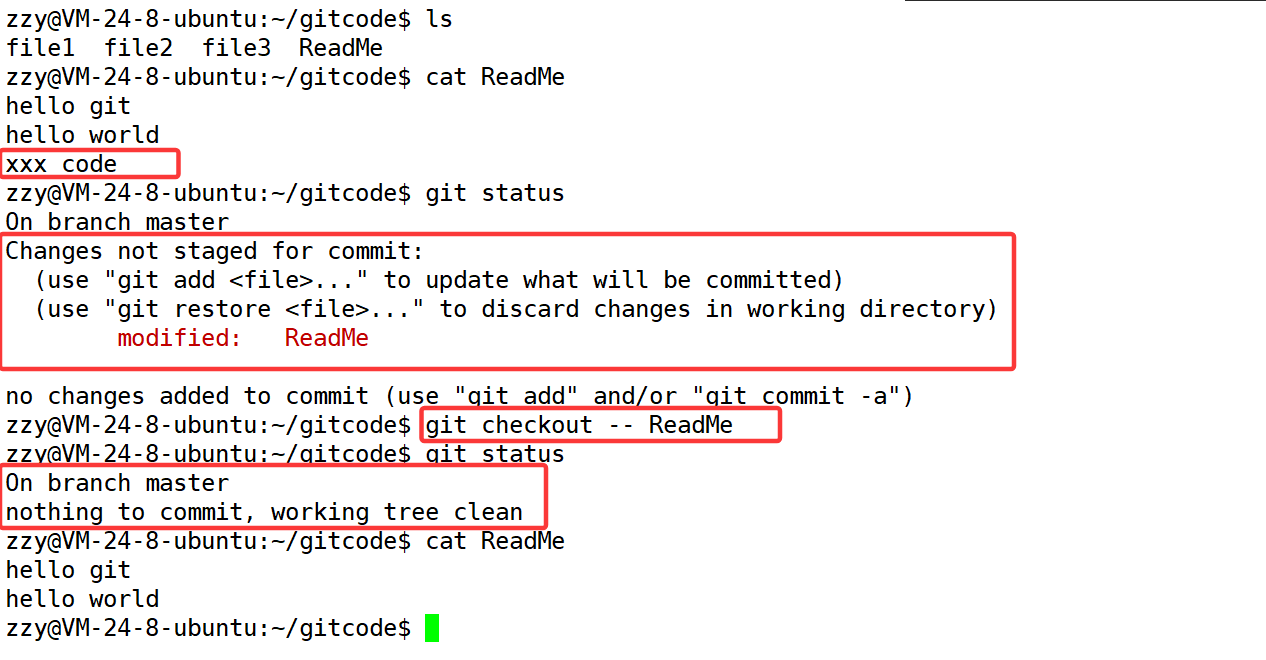
如果我们在我们的工作区写了很长时间代码,越写越写不下去,觉得自己写的实在是垃圾,想恢复到上一个版本。那么这就有以下三种情况:1、未add。2、已add,未commit。3、已add、已commit。

我们给ReadMe文件添加一行:xxx code,分别演示这三种情况。
情况一:仅修改了工作区,暂存区和版本库都未修改。这时候我们可以手动修改ReadMe文件,但是如果文件很大呢?所以需要使用git checkout -- ReadMe。
情况二:修改了工作区,并且add添加到了暂存区。这时候我们使用git reset进行回退。
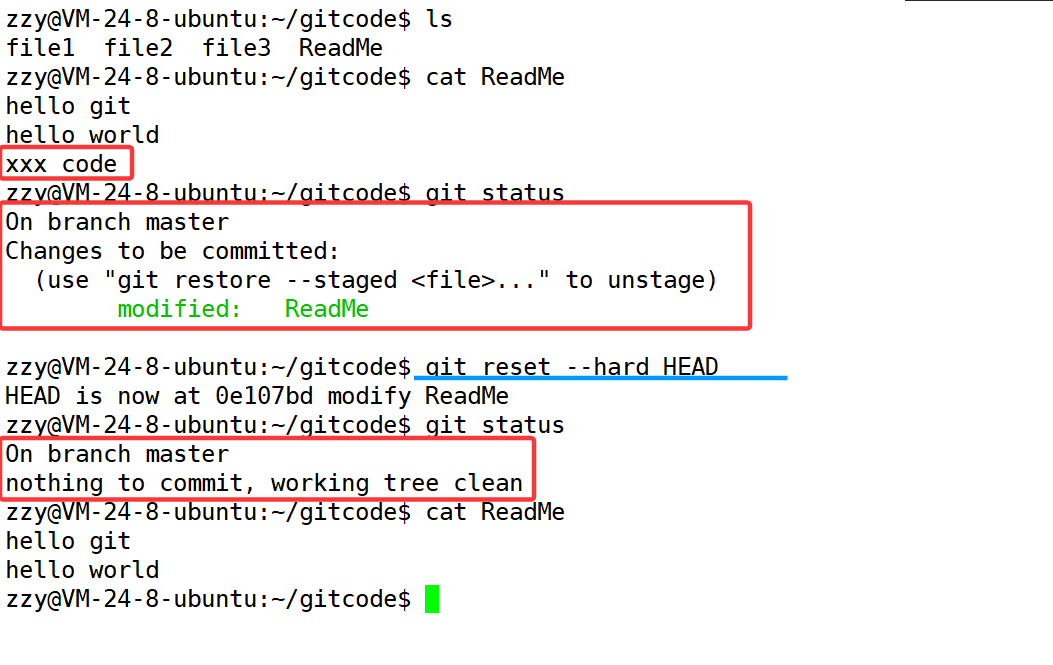
情况三:我们修改了工作区,并进行了add和commit,此时我们需要保证有一个前提条件,实际上将来还有一个远端仓库,我们将工作区内容添加到暂存区是通过git add实现的,将暂存区内容添加到版本库是通过git commit实现的,将版本库内容添加到远端仓库是通过git push实现的。但是我们需要保证commit之后并没有push。这时候我们使用git reset进行版本回退即可。

2.7、删除文件
删除一个文件有两种方式。
第一种方式:删除工作区下的某个文件,然后进行git add和git commit,因为Git管理的是文件的修改(包含增加、修改、删除),删除也算是一种修改。
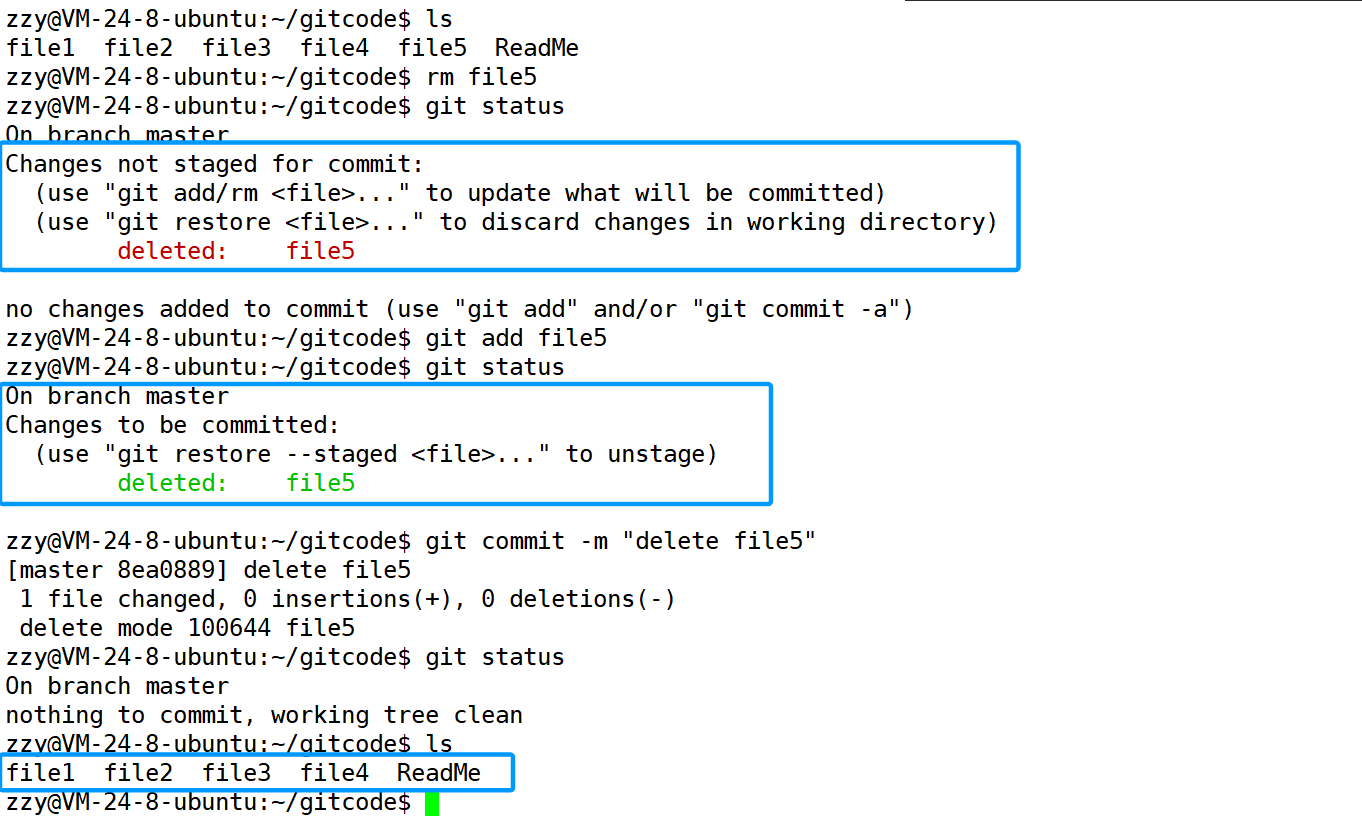
在上面的方式我们需要进行三步操作。使用第二种方式我们可以简化成两步操作。
第二种方式:使用git rm删除文件,可以简化成两步。
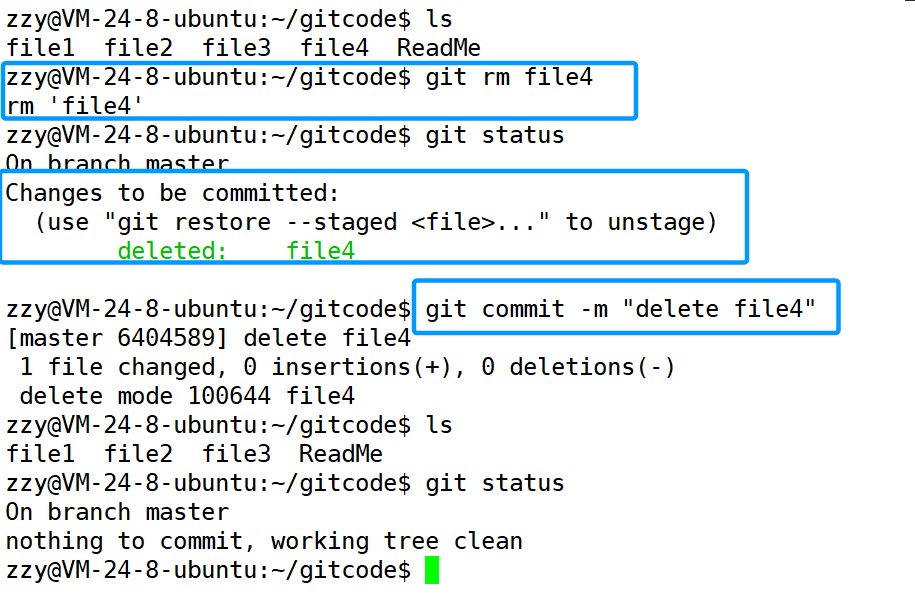
使用git rm删除文件,不仅会修改工作区,还会添加到暂存区中,这时候我们只需要再进行git commit即可。
3、Git分支管理
3.1、理解分支
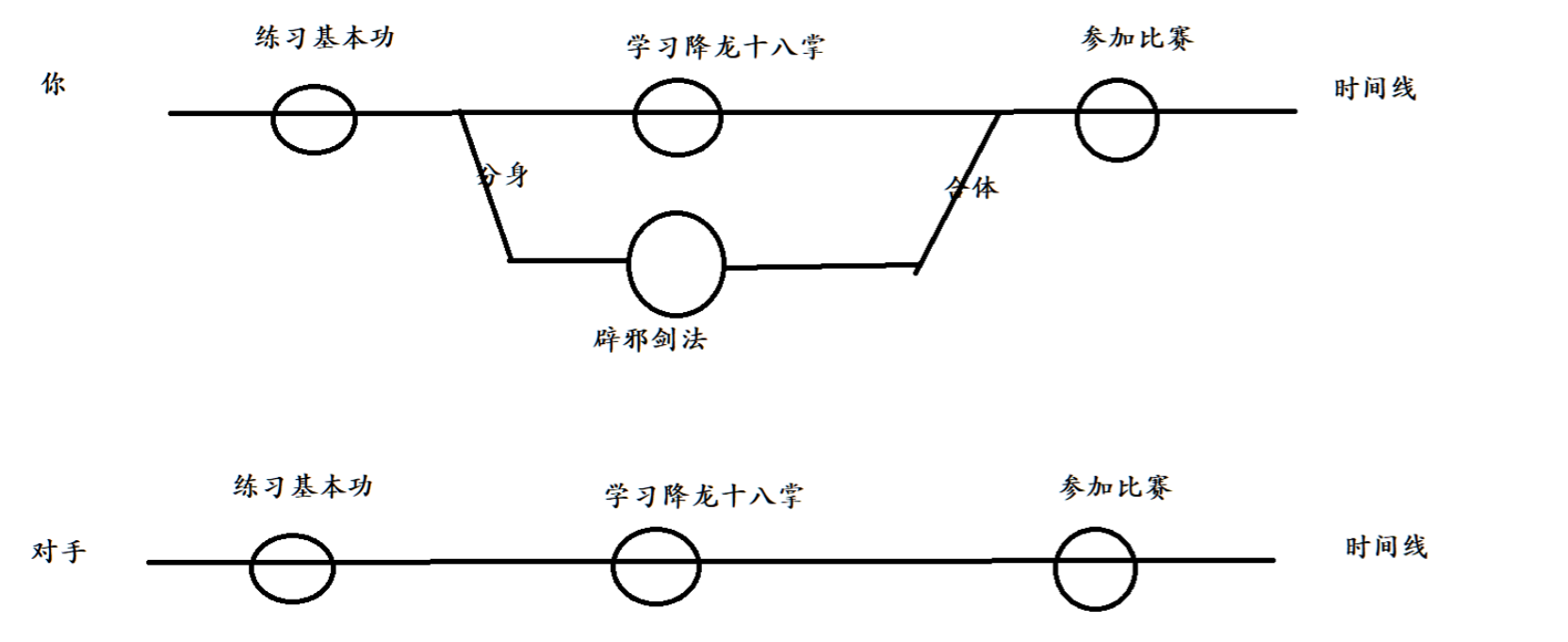
假设三个月后要进行武林大会,获胜者可以迎娶村长的女儿。所以你就开始练习,第一个月你学习了基本功,之后两个月你就学习降龙十八掌,然后参加比赛,这是正常的时间线。而你的对手跟你的学习能力一样,所以对手也是如此。那么为了能够打败你的对手,你首先练习基本功,然后释放一个分身去学习辟邪剑法,而你则学习降龙十八掌,最后要参加比赛前进行合体,这样你就比对手多学习了一门功法。
面再回过头来看一下HEAD的内容:
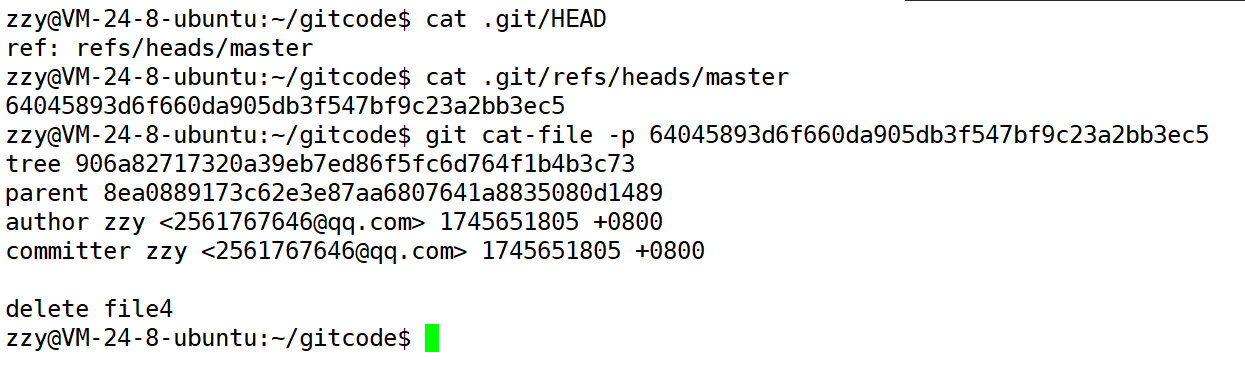
前面我们说过HEAD指向了master,我们继续查看master,master保存的是最近一次提交的commit id,接着我们继续查看这个git对象信息,里面保存了parent,上一次提交的commit id。
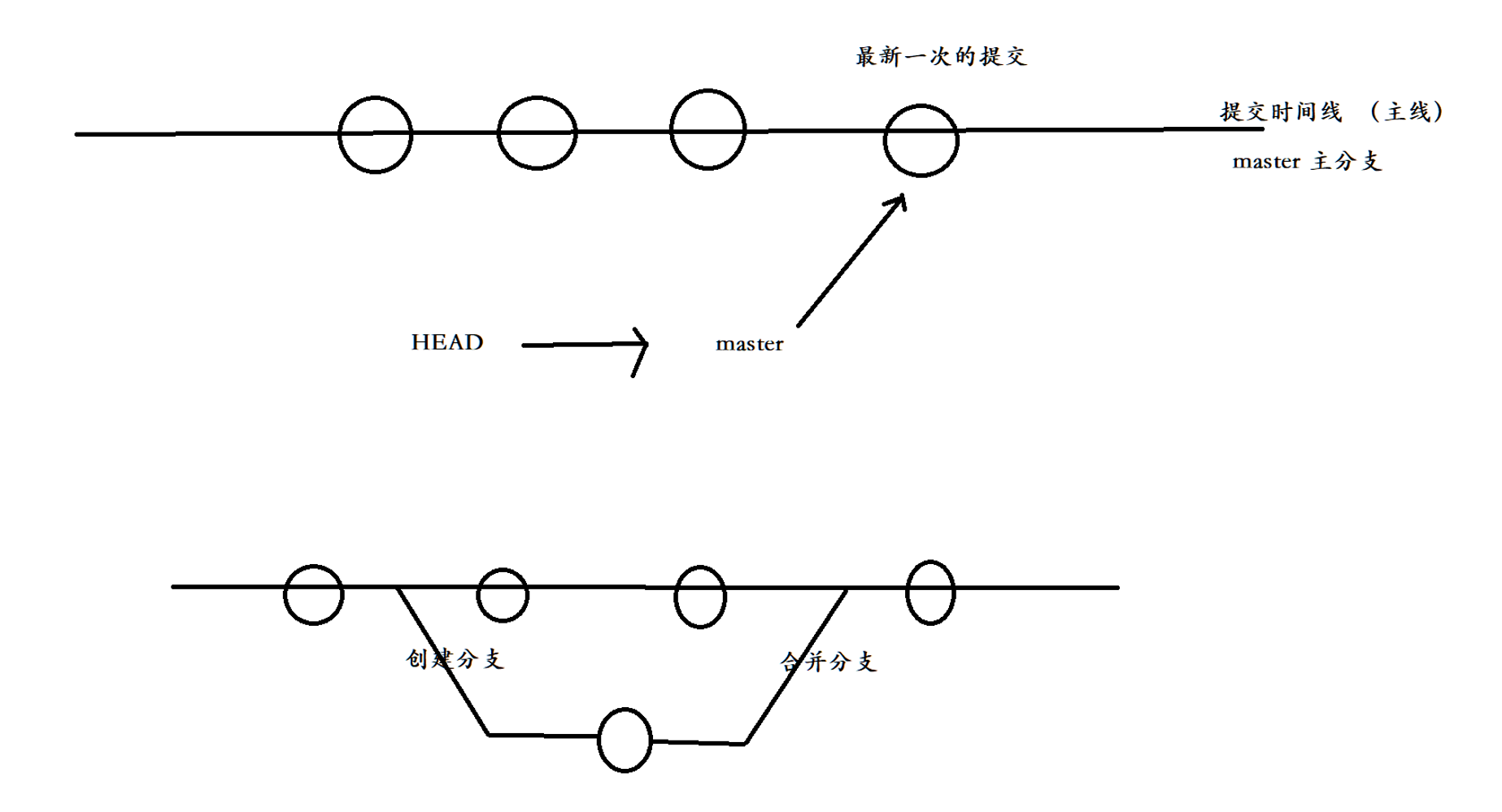
因此就会有如上图所示,HEAD指向master,master指向最近一次的提交,然后我们可以获取最近一次提交信息,然后再获取上一次的提交,所以可以不断地向前回溯。这本质就是一条提交时间线,我们称之为主线,所以我们把master理解为主分支。
我们也可以向上面学武一样,创建一条分支出来,然后将来这条分支提交的信息和主分支提交的信息进行合并。
另外,HEAD不仅可以指向master分支,还可以指向其他分支,如果指向其他分支,被指向的分支就是当前正在工作的分支。
3.2、创建、切换、合并分支
使用git branch查看分支:

*出现在master前面,表示当前工作分支为master主分支。在创建本地仓库的时候,git会自动给我们创建要给master主分支。
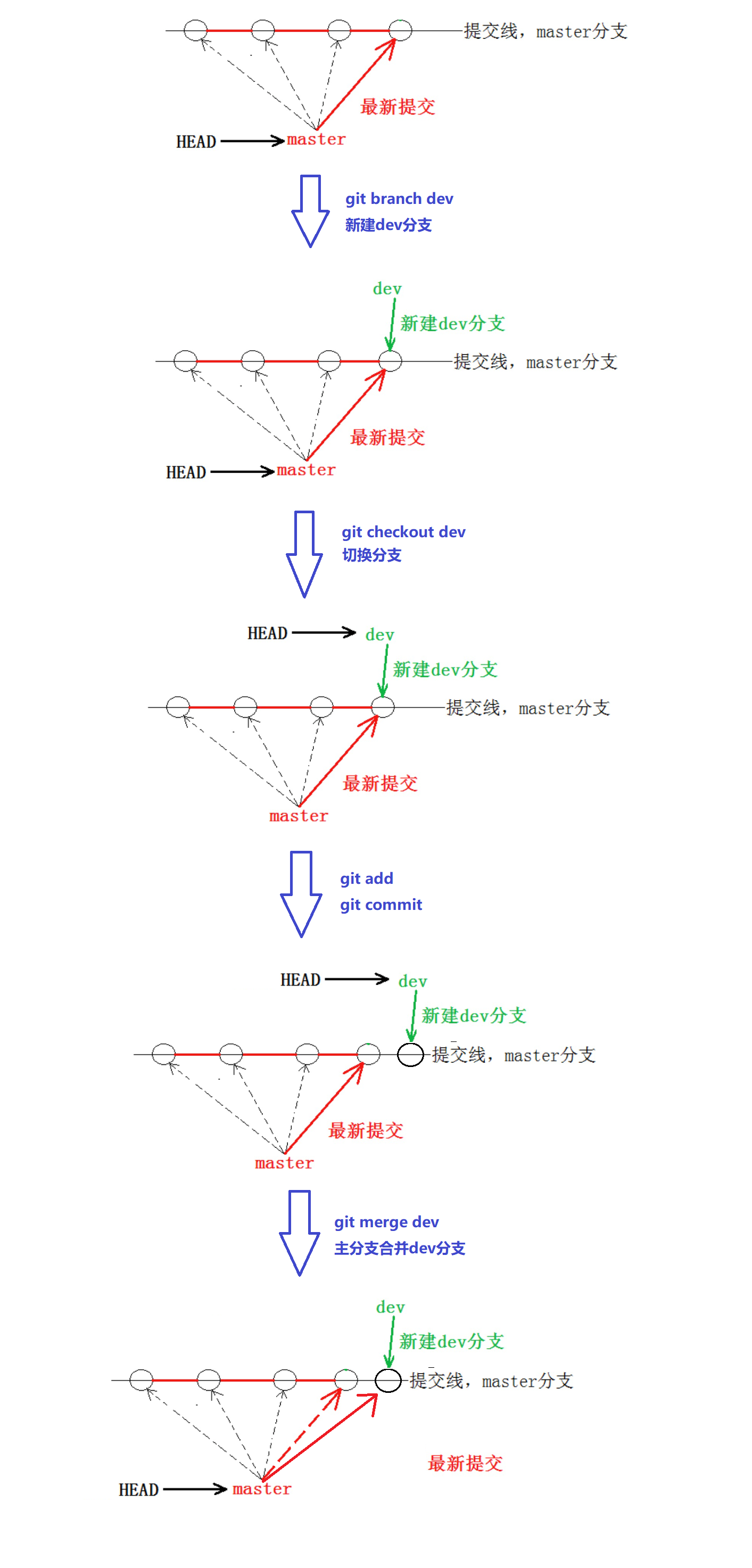
下面演示一下创建分支、切换分支、合并分支的一个过程。
首先使用git branch 分支名,创建一个分支:
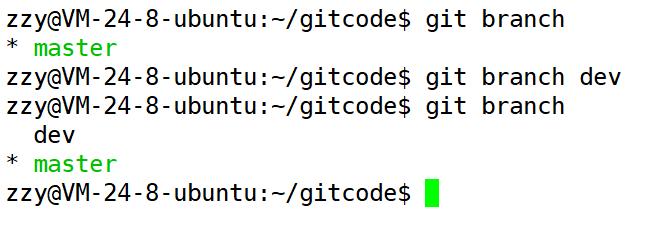
然后使用git checkout 分支名,切换分支:此时*出现在了dev前面,说明当前工作分支是dev分支。

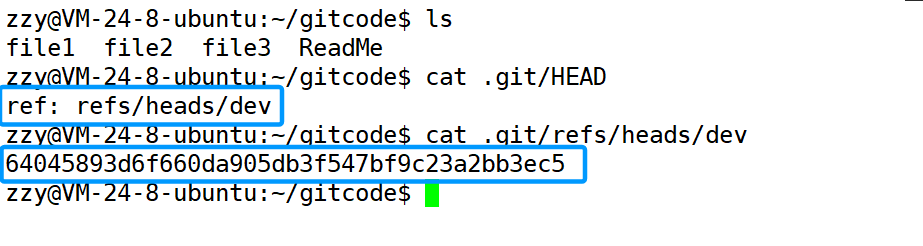 同时我们发现此时HEAD指向的就是dev分支了,打印dev的内容,我们发现存储的是之前master分支最新的一次提交。
同时我们发现此时HEAD指向的就是dev分支了,打印dev的内容,我们发现存储的是之前master分支最新的一次提交。
接着我们往ReadMe文件中添加一行内容,然后进行add和commit。
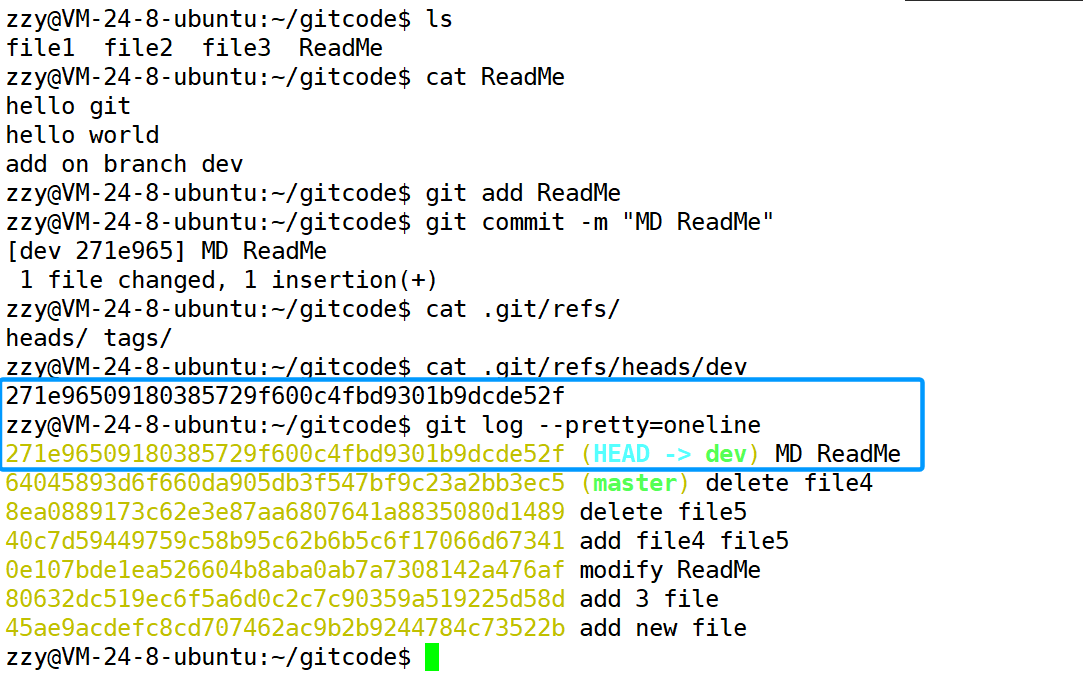
此时我们发现分支dev指向的不再是之前master最新的一次提交,而是在dev分支下刚进行的提交。**
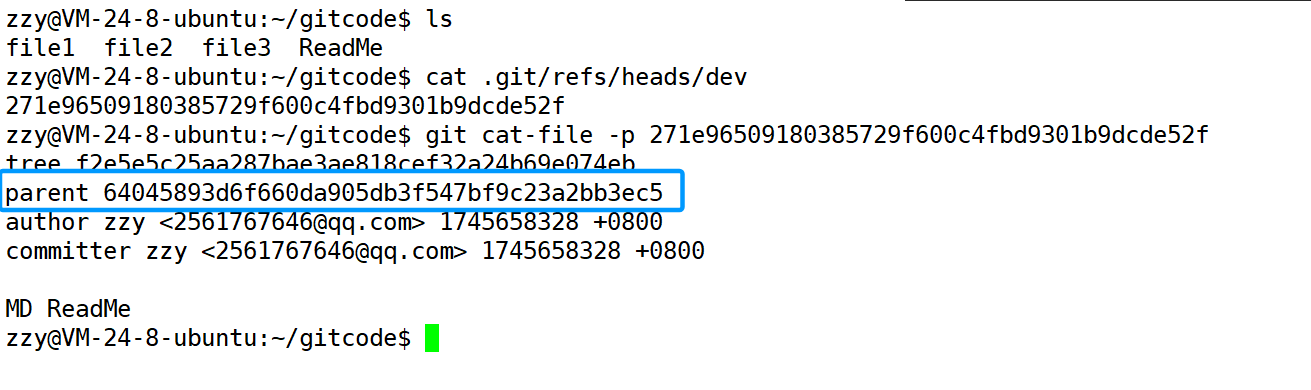
同时我们打印最新一次提交的内容,我们发现它的上一次提交就是master中最新的那一次。
然后我们再切回master主分支,看看在主分支中是否能看到ReadMe文件被添加的内容。
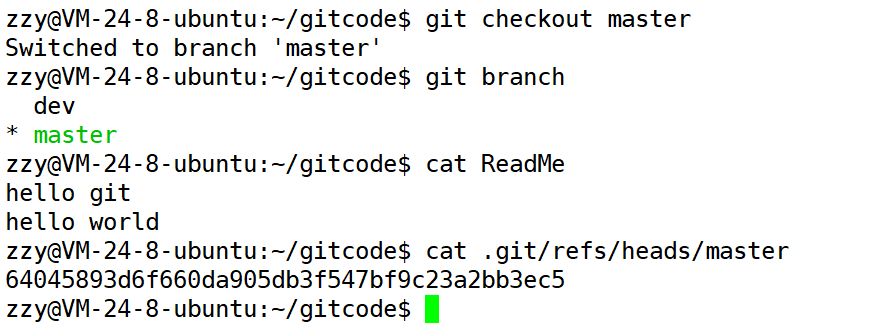
切回master分支后查看ReadMe文件,我们发现并没有新增的第三行内容。并且master分支还是指向之前主分支最新的一次提交。
接着我们将dev分支合并到master分支中,需要工作分支在master分支中进行。
使用git merge 分支名,将分支合并到master主分支中:
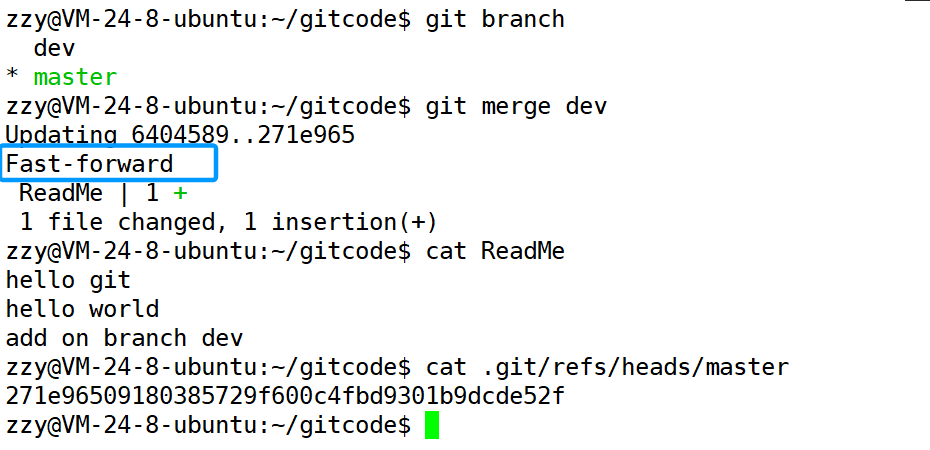
合并后在主分支中我们就可以看到刚才在dev分支中在ReadMe文件中添加的第三行。并且在查看master分支,此时指向了刚才在dev的提交。Fast-forward表示快进模式,直接就将master原来指向自己所在分支的最新一次提交改为了指向dev分支中的最新一次提交。
上面创建分支,切换分支进行add和commit,然后合并分支的流程图如下:
3.3、删除分支
合并完成后,dev分支对于我们来说就已经没有用了,所以需要删除分支,免得分支占用资源。
使用git brach -d 分支名,来删除分支。
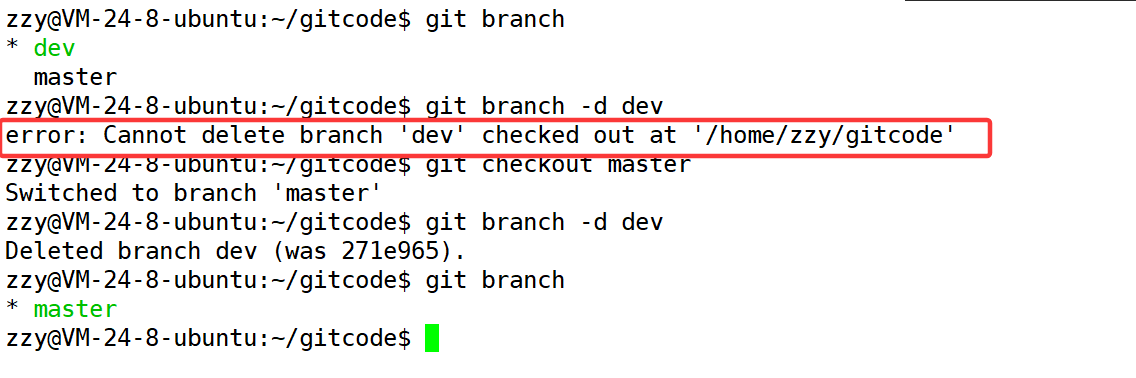
删除dev分支时,当前工作分支不能是dev分支,可以是其他的任意分支。
因为创建、合并和删除分支非常快,所以Git鼓励你使用分支完成某个任务,合并后再删掉分支,这和直接在master分支上工作效果是一样的,但过程更安全。
3.4、合并冲突
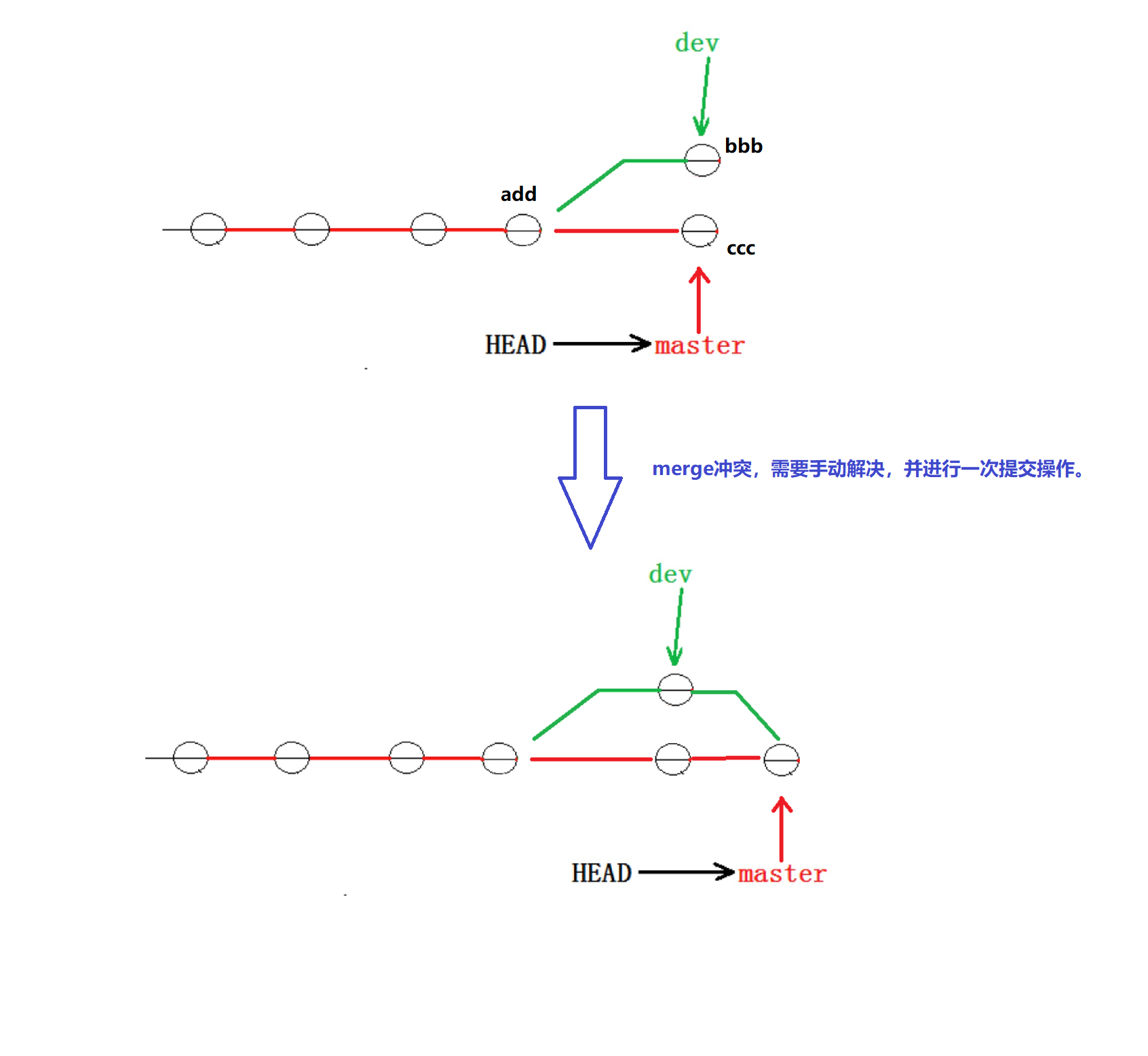
上面分支合并的时候是没有问题的,但是也可能出现分支合并冲突的情况。
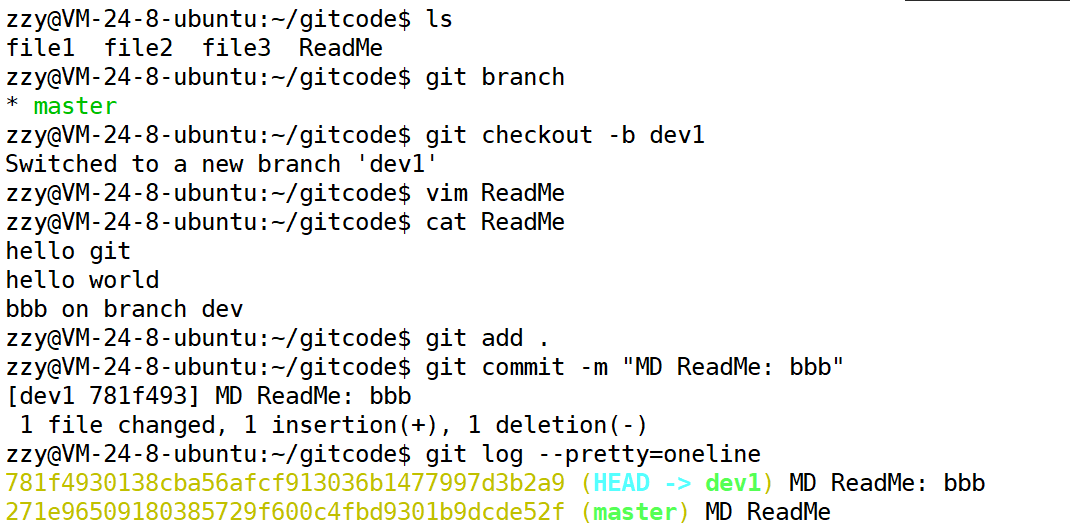
比如我们ReadMe文件目前第三行是:add on branch dev,现在假设这个不满足我们的需求,然后我们在dev1分支中对其进行修改为:bbb on branch dev,与此同时在master分支中也对齐修改为:ccc on branch dev。那么将来进行合并的时候,git没办法知道你是要保留bbb还是ccc,这时候就会出现合并冲突的问题。
首先创建分支dev1然后修改ReadMe并提交:
之前我们需要先git branch创建分支然后再git checkout切换分支,这里介绍一个方法直接创建并切换:
git checkout -b 分支名。
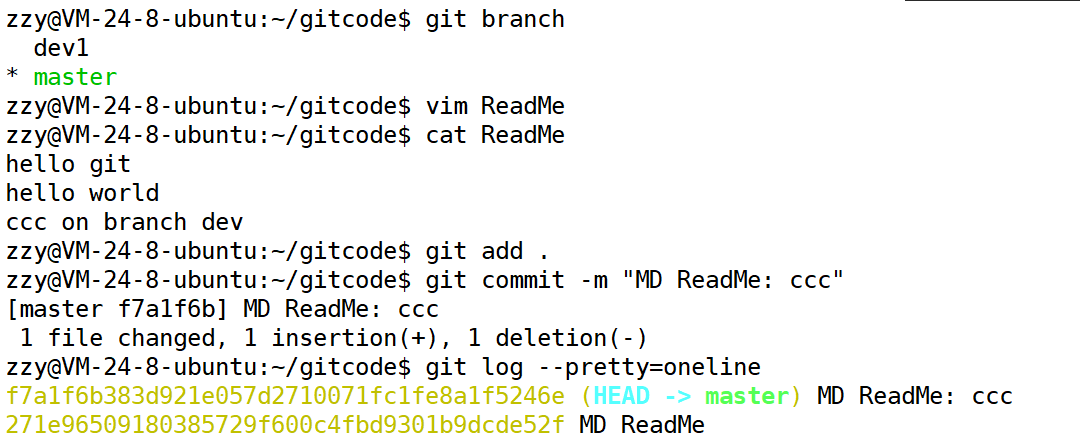
接着我们切回master分支,在master分支中修改ReadMe文件进行提交:
接着合并dev1分支:

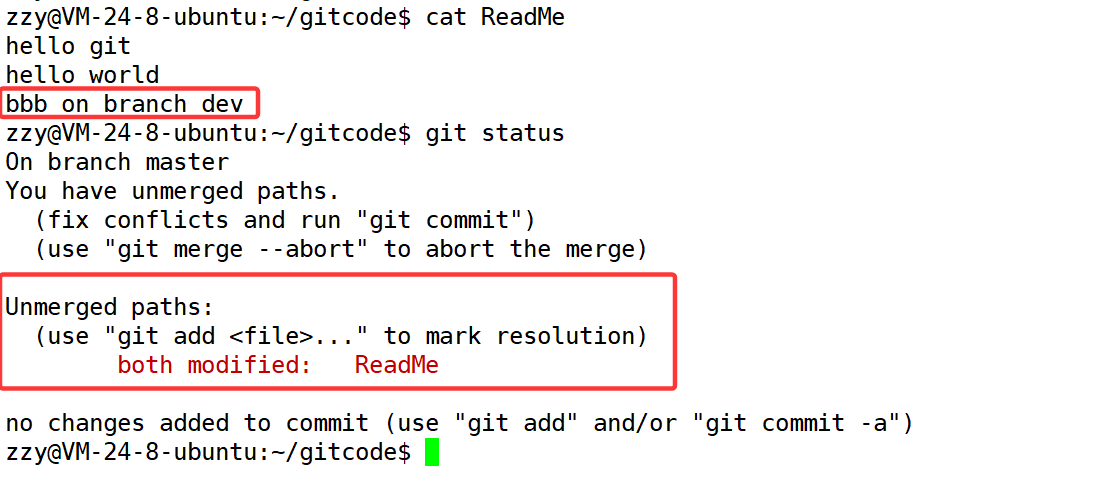
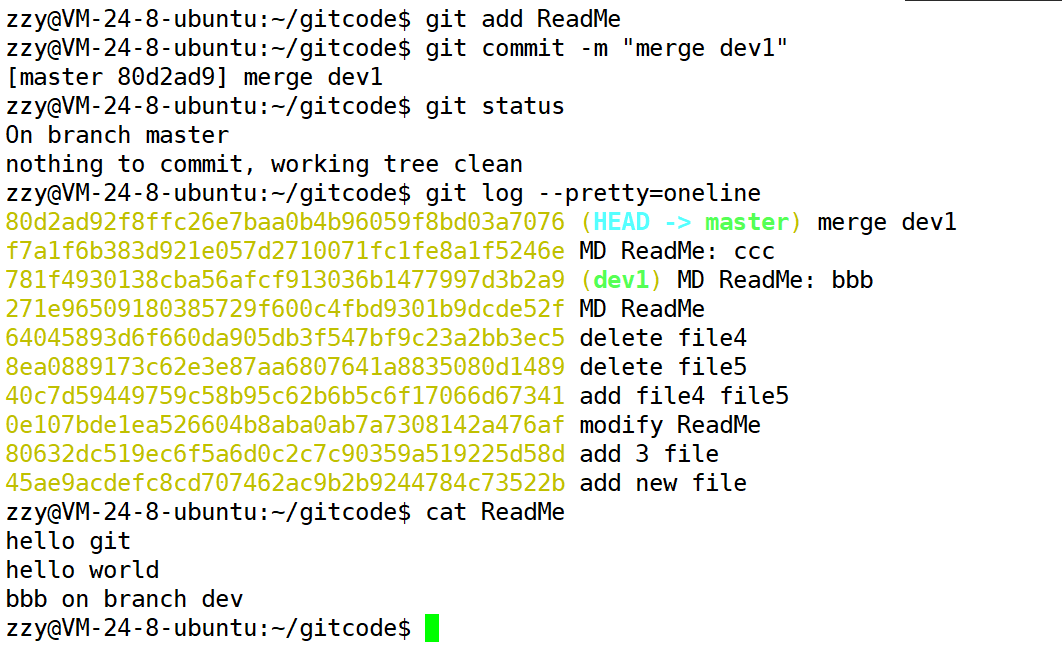
显示ReadMe文件合并冲突,自动合并失败,需要修正冲突并重新提交结果。此时我们再打开ReadMe文件看一下:

上面的<到=之间的内容表示当前工作分支主分支最新提交的内容,=到>表示分支dev1最新提交的内容。我们可以保留bbb或ccc中的其中一个,也可以两个都保存下来,需要我们自行修改内容然后再重新提交。
我们以保留bbb为例:
将其他内容删除只保留bbb这一行,然后我们可以git status查看一下状态。
接着我们进行提交:
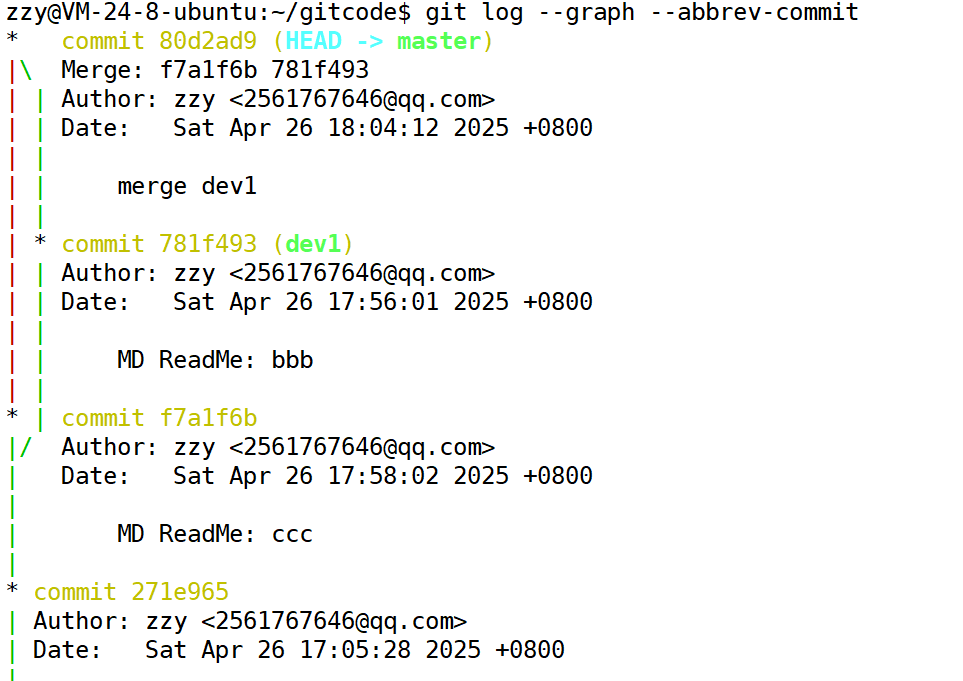
另外git log也可以可视化的查看提交的日志信息。我们可以使用如下命令:
git log --graph --abbrev-commit
3.5、合并模式
上面我们合并了两次,第一次是正常合并,是Fast-forward,第二次是合并冲突,是非Fast-froward。
下面我们再次创建分支dev2,然后给ReadMe文件添加一行:abc内容,接着进行提交,然后切回主分支进行合并。
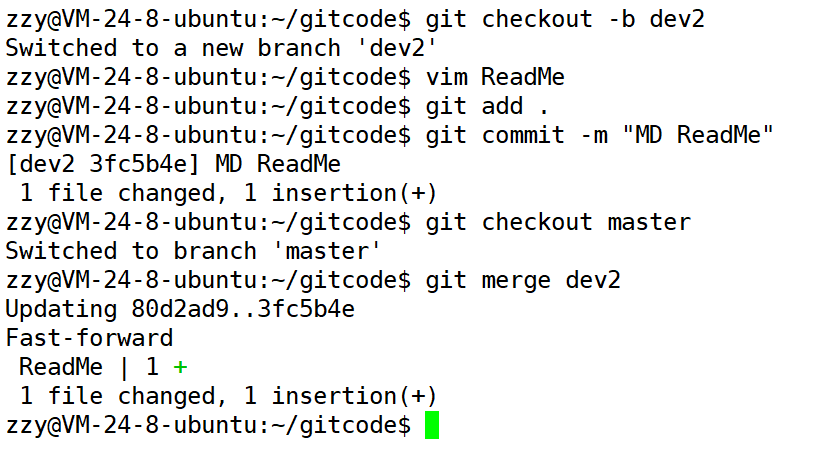
合并成功后,我们使用:git log --graph --abbrev-commit查看提交信息:
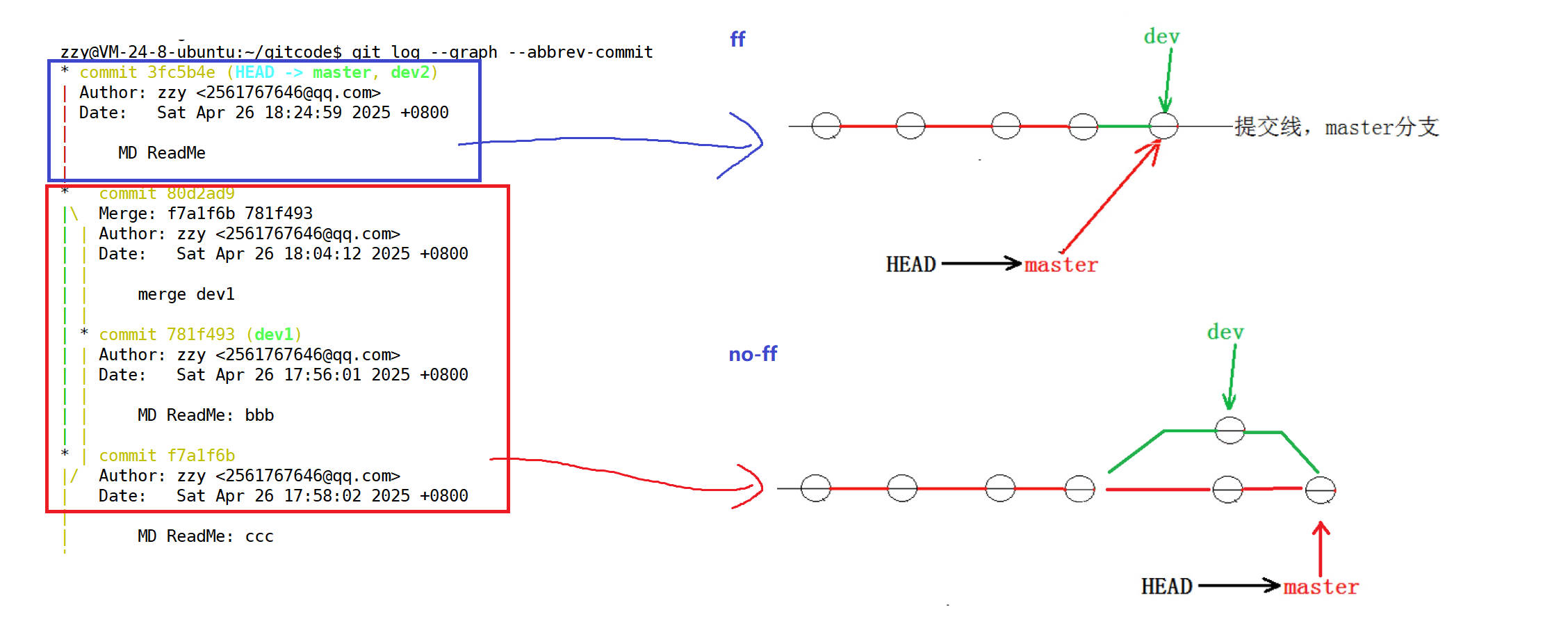
我们发现不发生冲突的合并是Fast-forward模式,我们简称为ff模式,此时我们查看提交日志时,看不出来最新提交到底是merge进来的还是正常提交的。而no-ff模式下可以很明显看到是由其他分支merge进来的。
那如果我想要no-ff这种合并方式呢。我们可以在git merge的时候带上–no-ff选项。同时我们注意到no-ff这种方式需要创建一个新的提交节点,所以需要再带上-m。
下面切换到dev2分支,再ReadMe文件中abc中最后加上de,然后切回master分支进行合并。
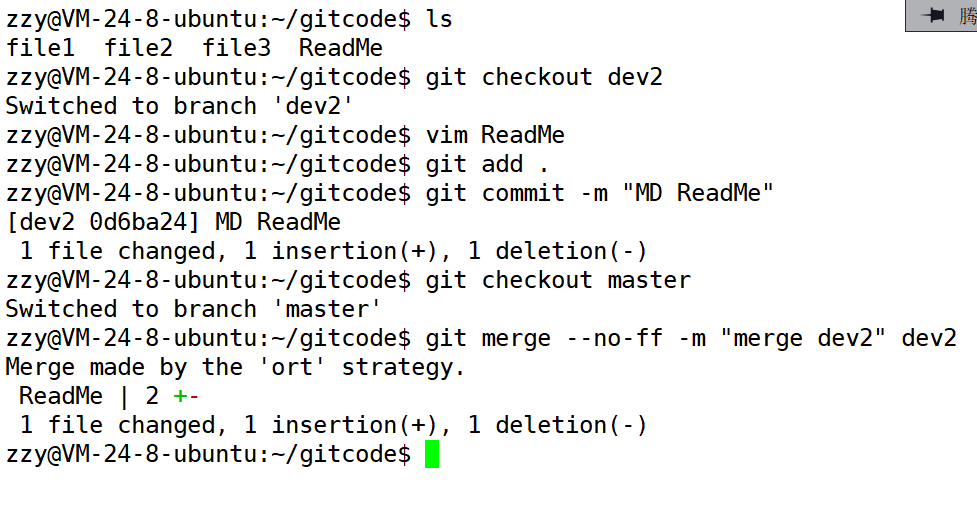
然后再次查看提交日志信息:

所以在合并分支时,加上–no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并,而fast forward合并就看不出来曾经做过合并。
3.6、分支管理策略
在实际开发中,我们应该按照几个基本原则进行分支管理:
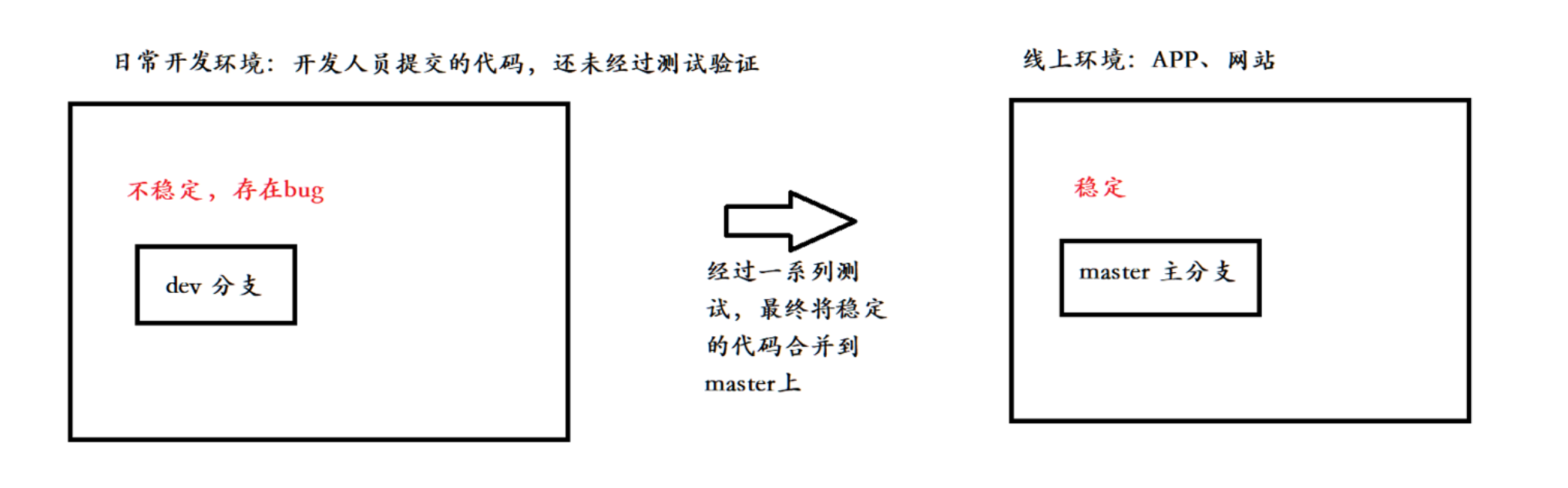
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;所以线上环境APP、网站等的代码都是master主分支上的代码。
那在哪干活呢?干活都在dev分支上,也就是说dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本;
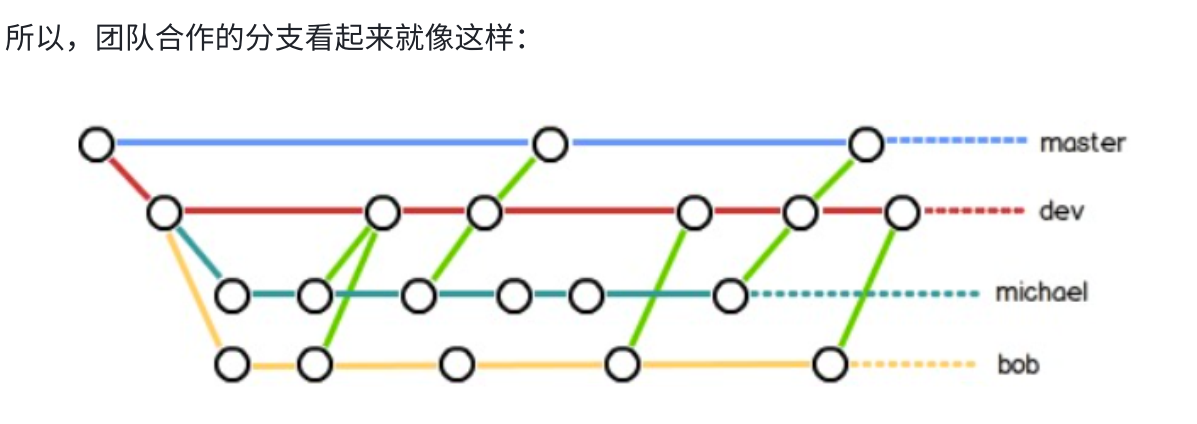
你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。
3.7、bug分支
假如我们现在正在dev2分支上进行开发,开发到一半,突然发现master分支上面有bug,需要解决。在Git中,每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支删除。
首先我们先创造出环境,我们在dev2分支中ReadMe文件添加i am coding…内容:
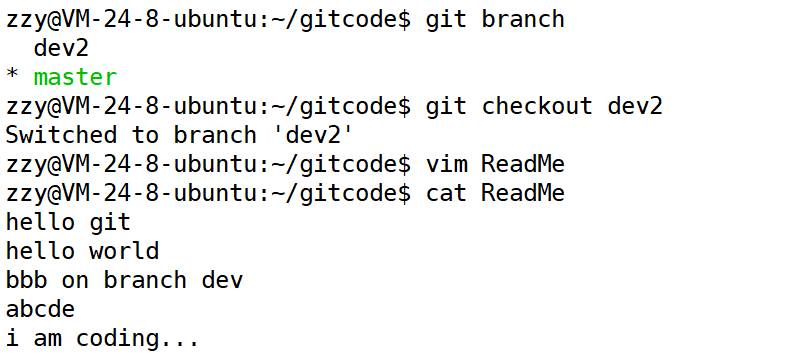
接着我们发现主分支master有bug,这时候我们切回主分支,但是发现有问题:
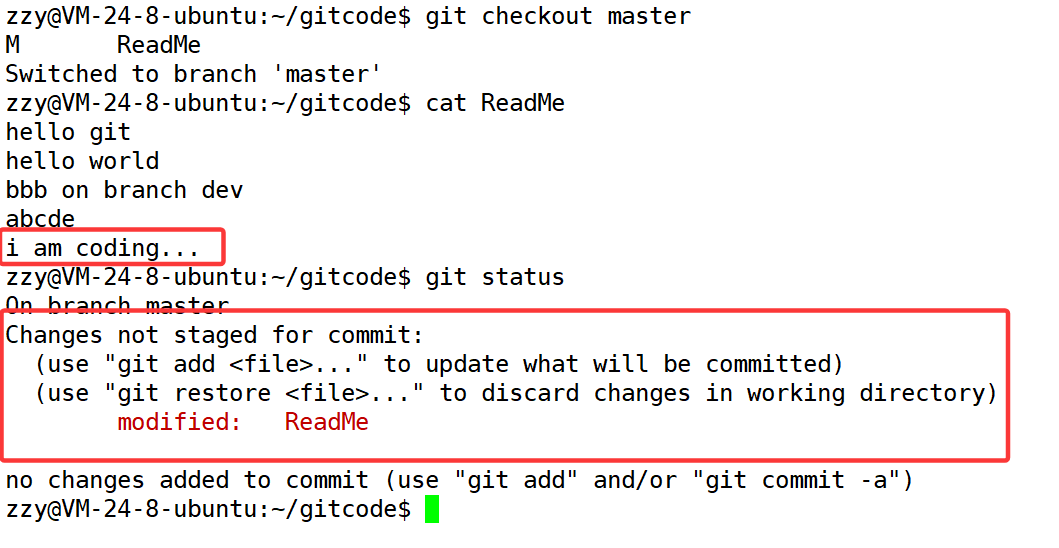
我们之前在dev2分支上进行开发,修改了工作区,这时候直接切回主分支,我们发现dev2开发的代码影响到了主分支,因此不能直接切回来。
我们重新切回dev2分支,当我们开发一半master分支出了问题,这时候我们需要使用:git stash将我们开发的代码储存起来。
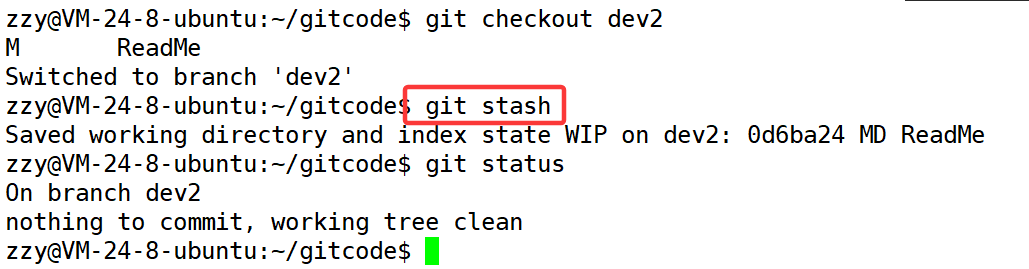
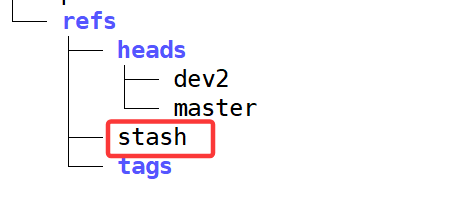
同时发现.git目录下的refs目录多了一个名为stash的名字。本质上就是将我们工作区修改的内容储存到stash中。
这时候我们就可以切回master分支了,这时候就不会影响主分支了。接下来我们需要修改bug,修改bug当然也可以直接在dev2分支上修改,不过这是我们用来进行开发的分支,所以最好的做法是另外创建一个fix_bug分支来修复bug。
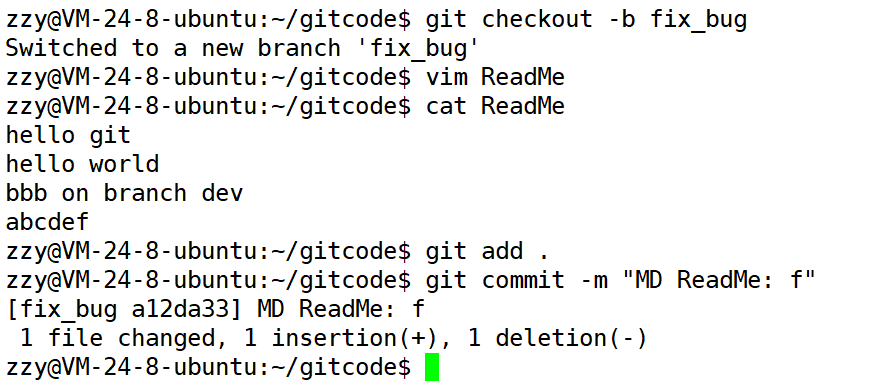
我们假设ReadMe的最后一行少了一个f,我们修改后提交。
接着我们需要切回主分支,然后合并fix_bug分支,完成bug修复。(这里合并应该使用--no-ff以适应下面的图)
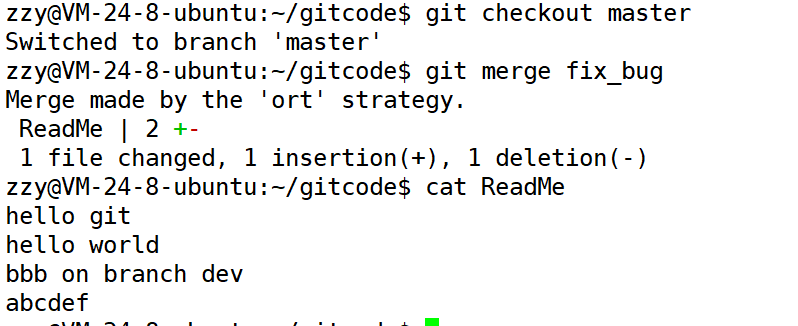
修复bug成功后,我们就可以切回dev2分支继续开发工作,开发完后进行提交。
使用git stash list可以查看我们保存了哪些修改内容:

使用git stash pop可以将之前修改的内容从stash恢复出来:
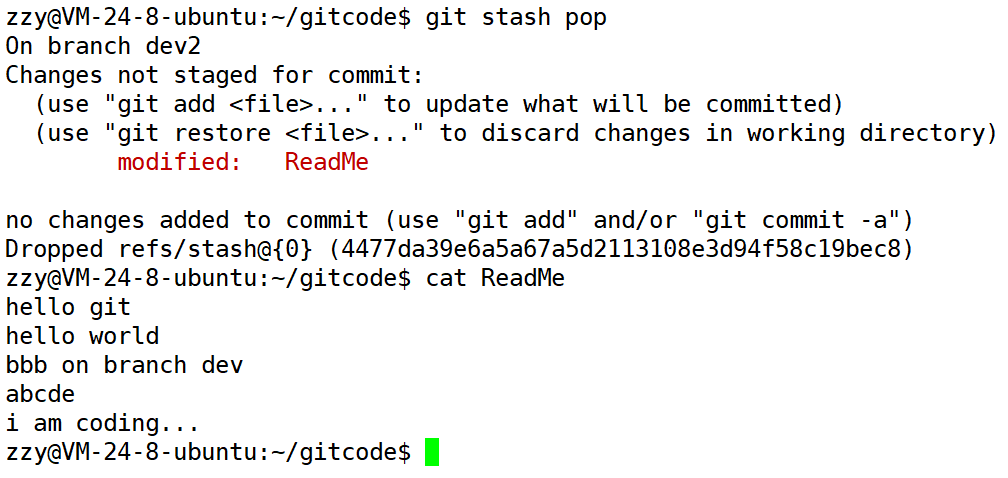
最后我们在后面加上Done表示开发工作完成,接着提交:
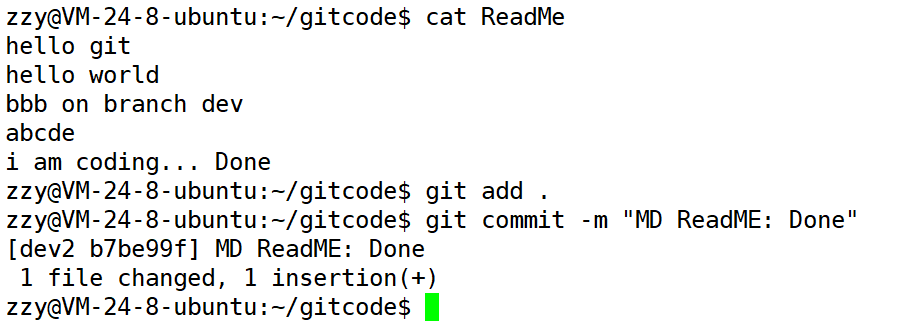
接下来就会有问题了,如果我们直接切回master分支,然后合并dev2分支,那么就会出现合并冲突,我们需要手动解决,而手动解决极有可能导致master代码出错。所以这种做法是肯定不行的,如下图:
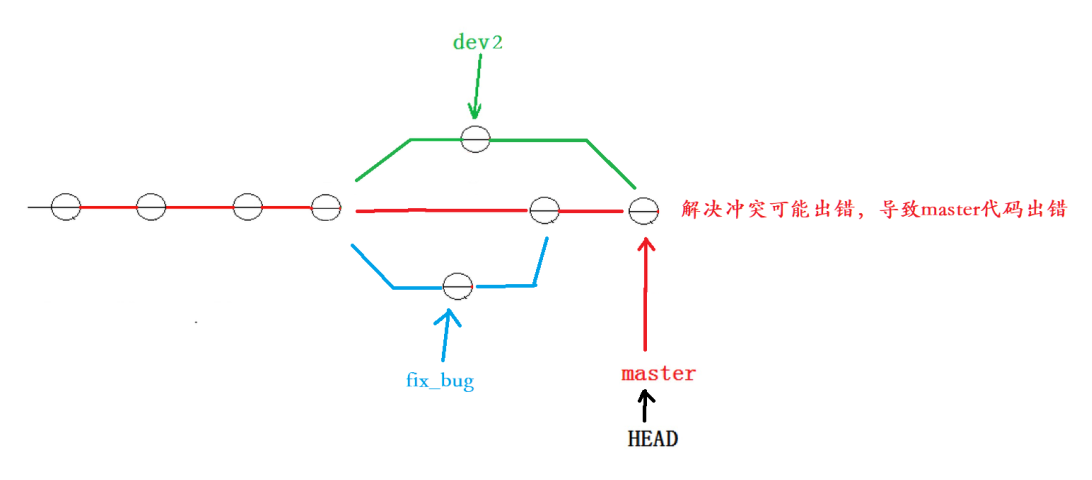
正确做法应该是:首先dev2合并master分支的代码,合并后就算有问题我们也可以在dev2分支下多次修改测试,不会影响master的代码。当我们修改测试完后,在回到master分支中合并dev2分支。如下图:
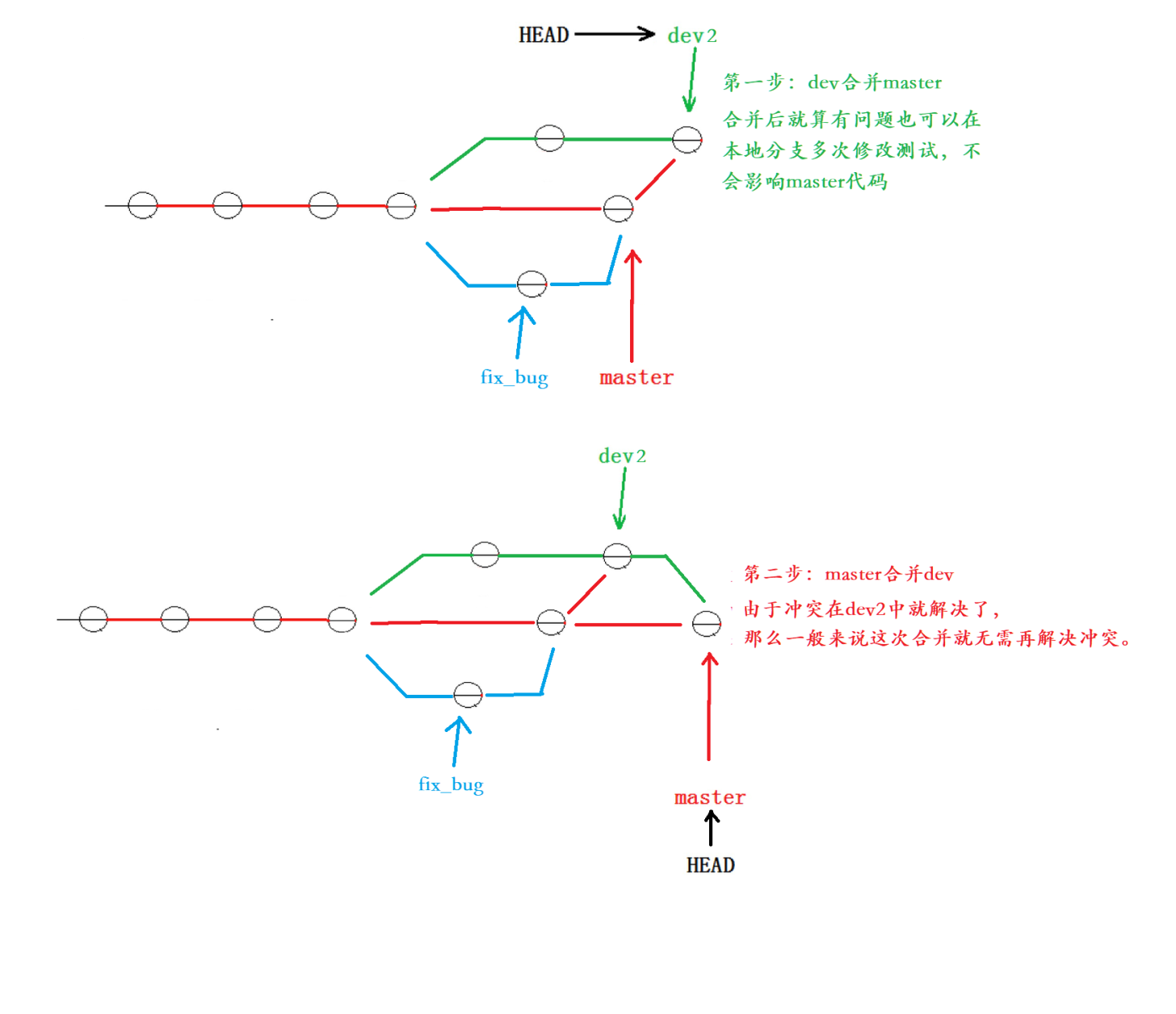
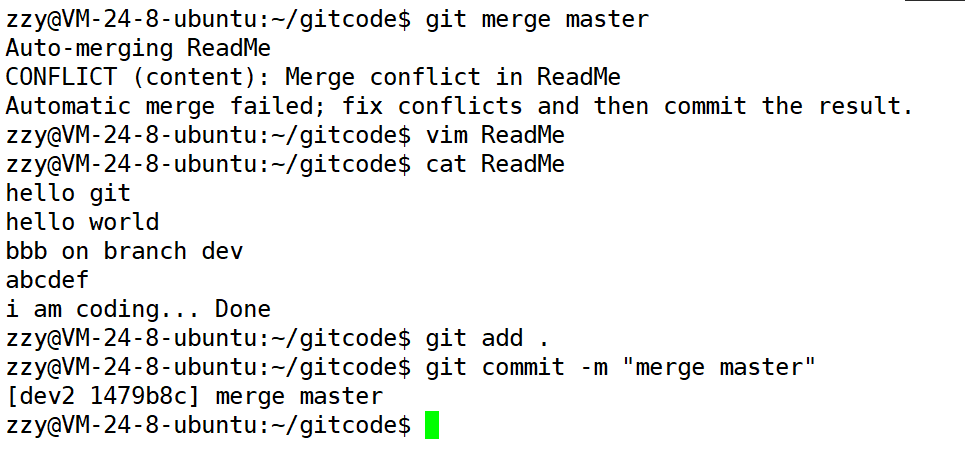
下面我们在dev2分支中合并master分支,然后解决合并冲突:记得解决冲突后还需要提交。
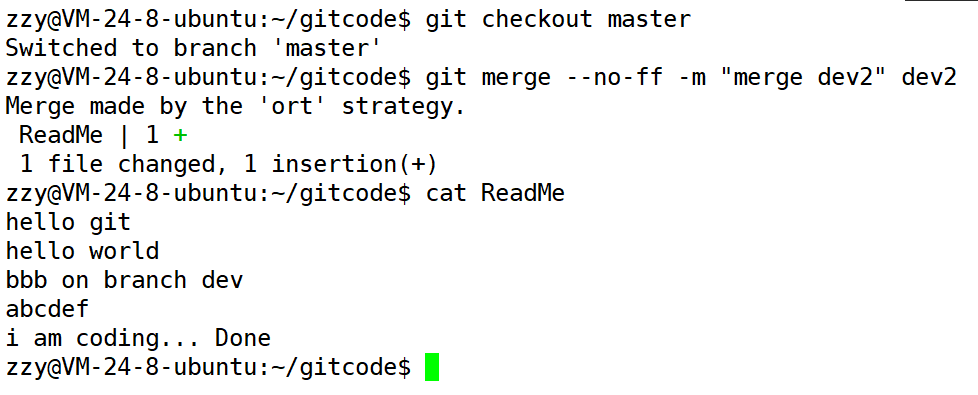
最后我们回到主分支,合并dev2分支即可:
3.8、强制删除分支
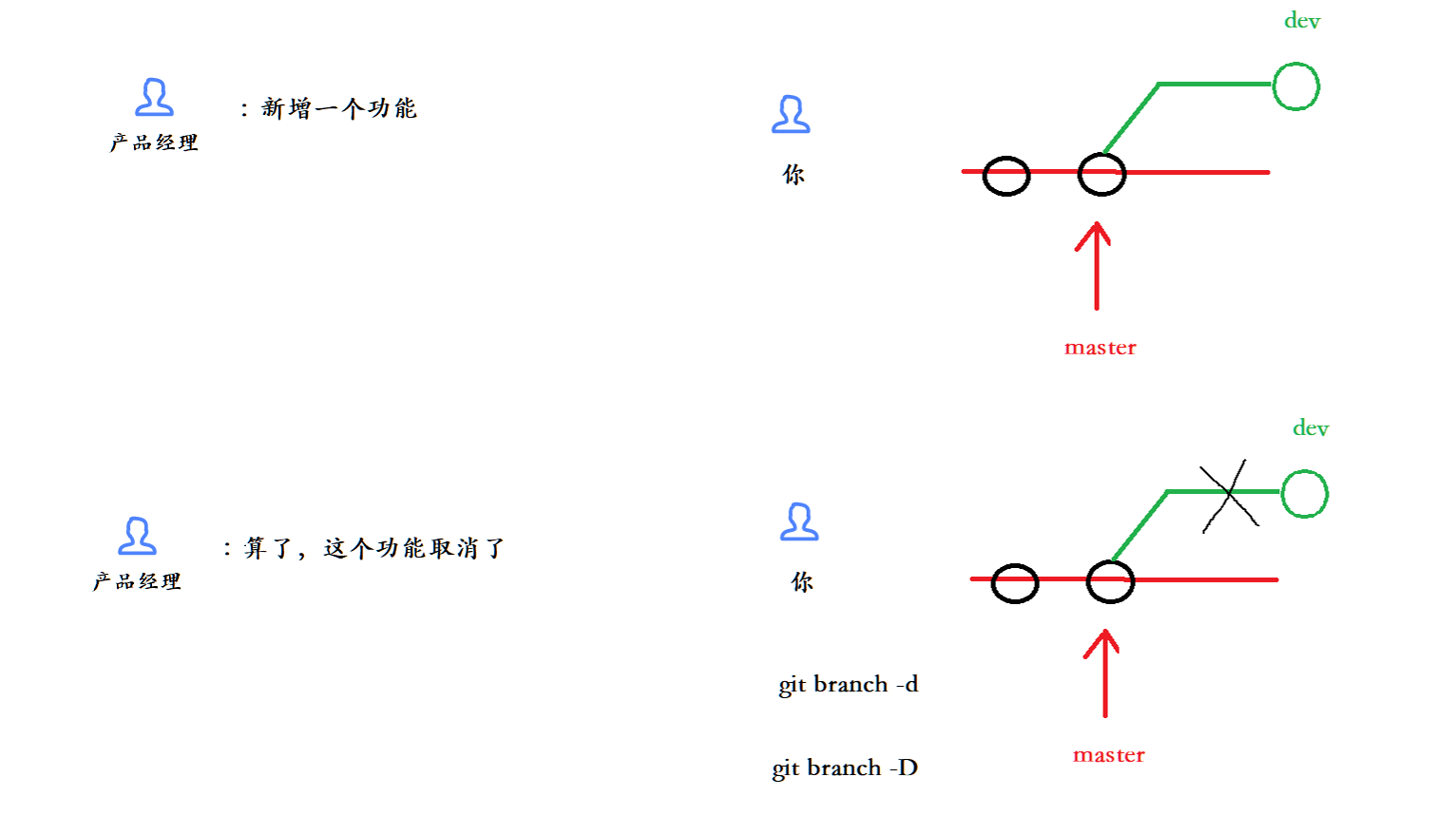
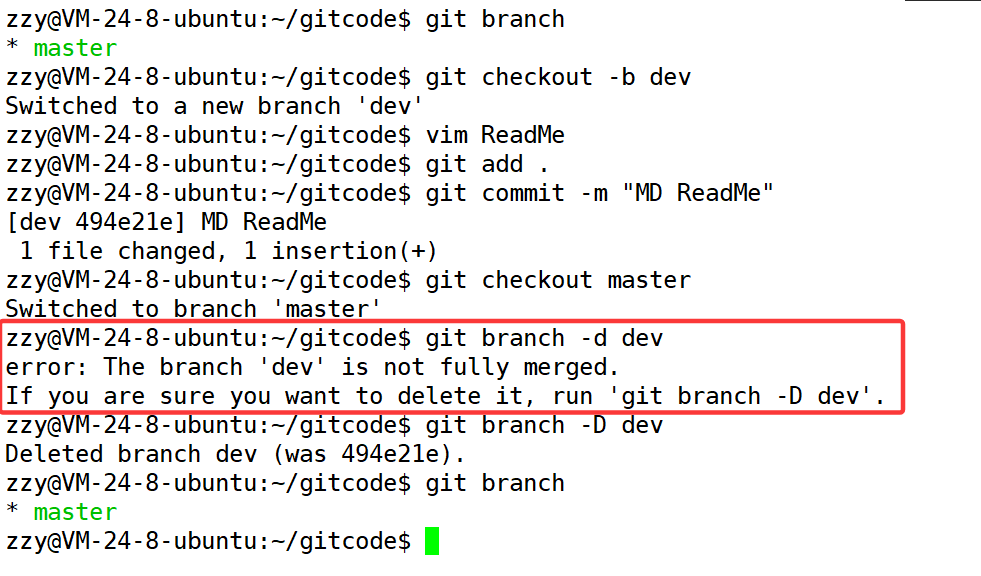
现在遇到一种情况,产品经理让你开发一个新功能,所以你就创建了一个dev分支然后进行开发,过了一段时间产品经理突然又说这个功能要取消了,这时候你也只能删除这个分支了。我们之前删除分支都是在主分支merge其他分支之后,才把其他分支删除的。而现在我们在dev分支开发了一部分,也有进行提交,这时候如果要删除dev分支,由于dev分支还没有被merge到master分支中,所以使用git branch -d是无法删除的。如果这时候我们要删除就需要使用git branch -D强制删除。
下面我们就演示一下这个过程:
4、Git远程操作
4.1、理解分布式版本控制系统
我们目前所说的所有内容(工作区,暂存区,版本库等等),都是在本地!也就是在你的笔记本或者计算机上。而我们的Git其实是分布式版本控制系统!
可以简单理解为,我们每个人的电脑上都是一个完整的版本库,这样你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在⼀个局域网内,两台电脑互相访问不了。也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当中央服务器的电脑,但这个服务器的作用仅仅是用来方便交换大家的修改,没有它大家也一样干活,只是交换修改不方便而已。有了这个中央服务器的电脑,这样就不怕本地出现什么故障了(比如运气差,硬盘坏了,上面的所有东西全部丢失,包括git的所有内容)
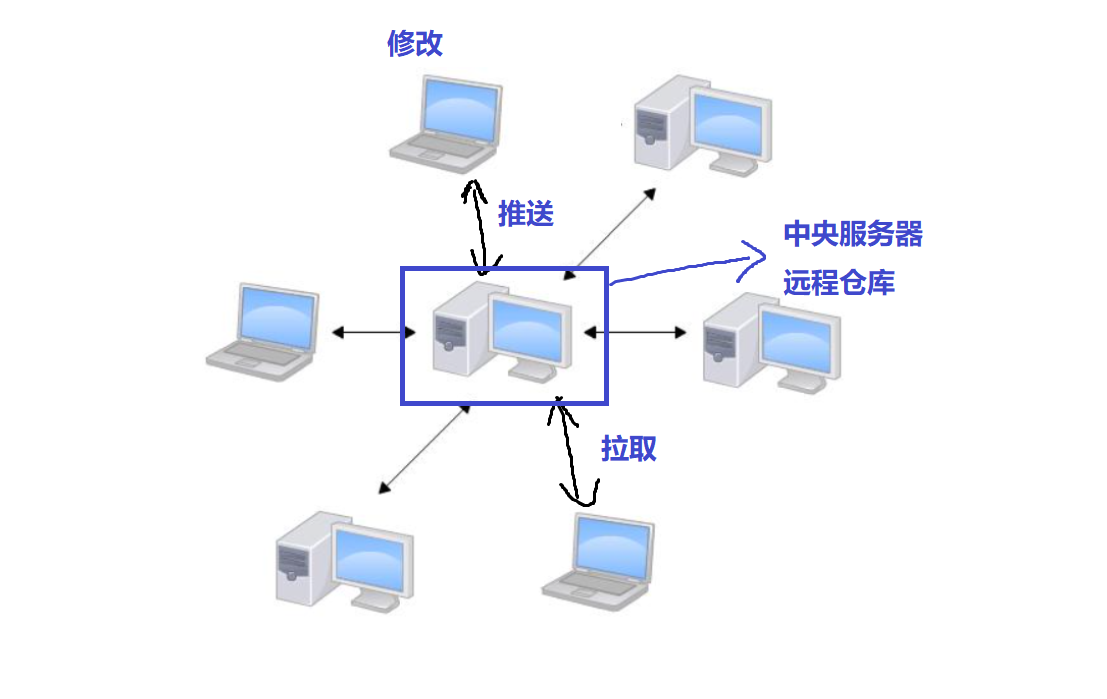
实际情况往往是这样,找一台电脑充当服务器的角色,每天24小时开机,其他每个人都从这个服务器仓库克隆一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交。
这个中央服务器已经有现成的了,就是github和gitee。github由于是国外的网站,访问起来比较麻烦,后面的操作我们就用gitee来做。
4.2、创建远程仓库
我们在gitee上创建一个远程仓库:
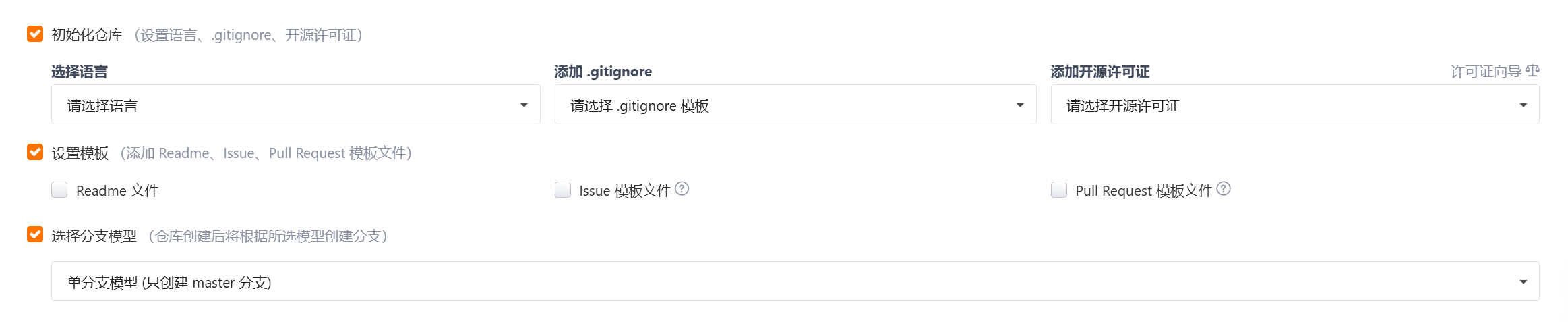
可以勾选初始化仓库,选择你这个仓库代码是何种语言的,也可以添加开源许可证,也可以添加.gitnore文件这个后面会说。勾选设置模板,第一个Readme文件就是进入远程仓库页面最先显示出来的,有关远程仓库的介绍信息。选择分支模型,可以选择单分支模型和其他分支模型。
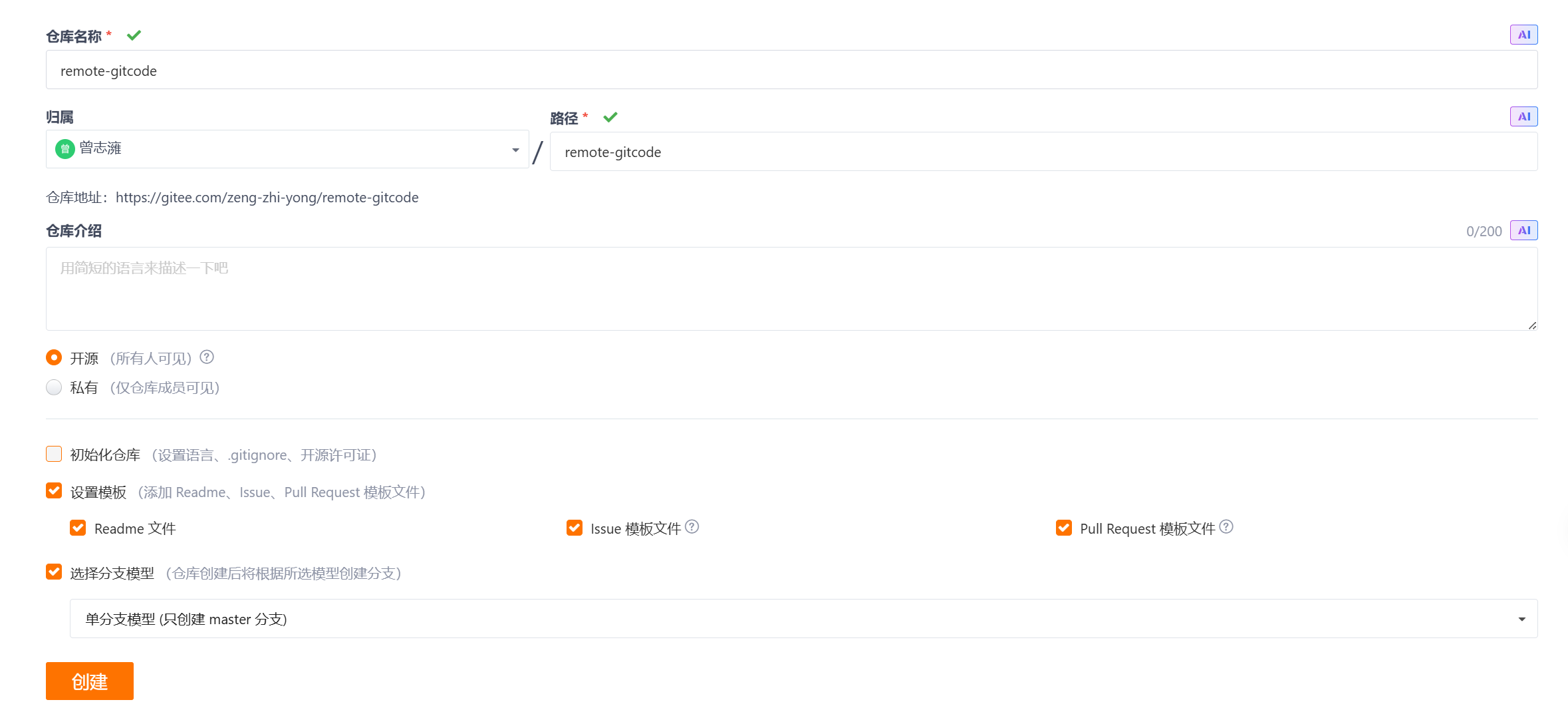
如图,设置好后创建即可。
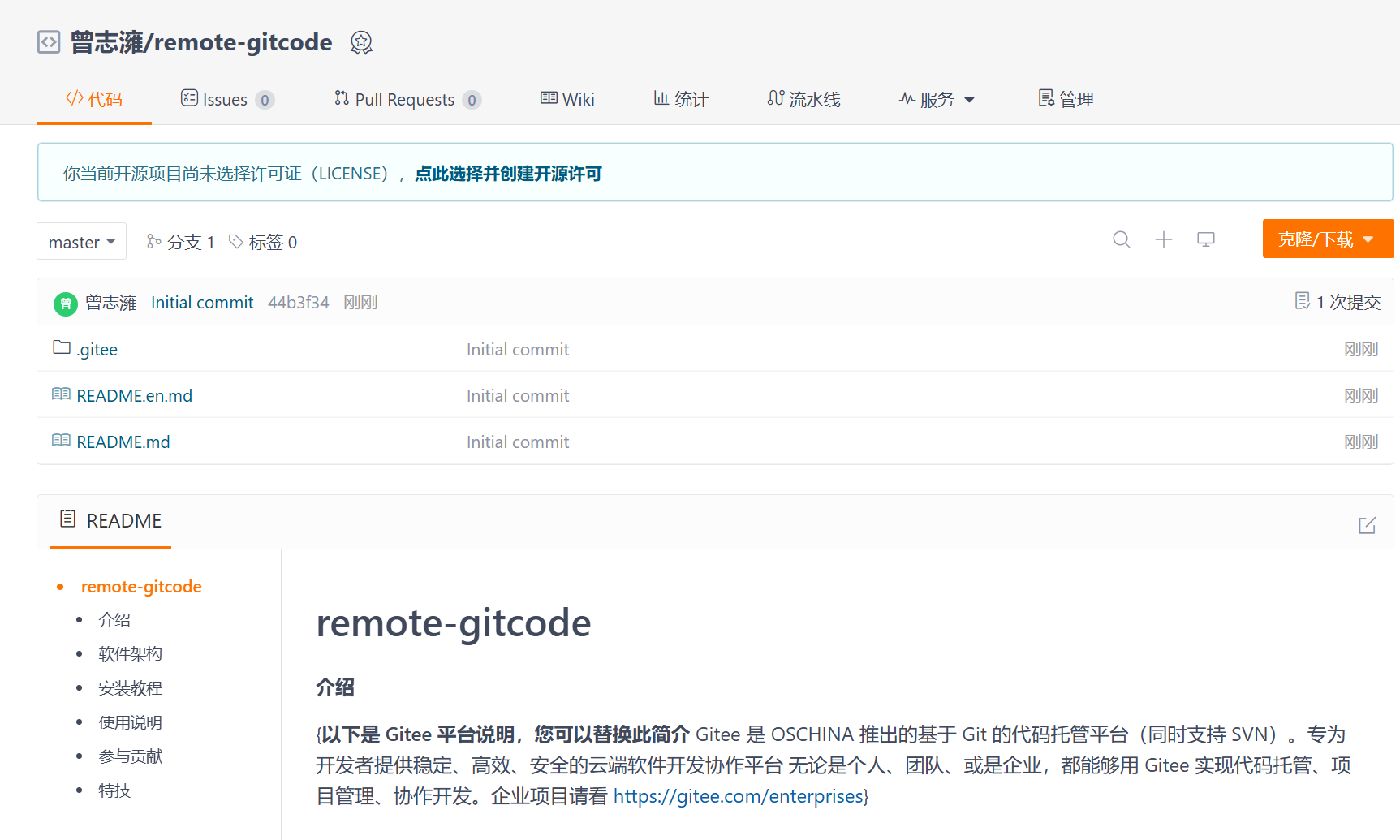
进入仓库,我们最先看到的就是README文件,这个文件就是用来介绍仓库相关内容的。

切换到管理页面,我们选择仓库成员管理,可以看到仓库有四种成员:报告者、观察者、开发者、管理员。
我们在创建仓库的时候还选择了Issue模板文件和Pull Request模板文件,下面来看看这两个是什么
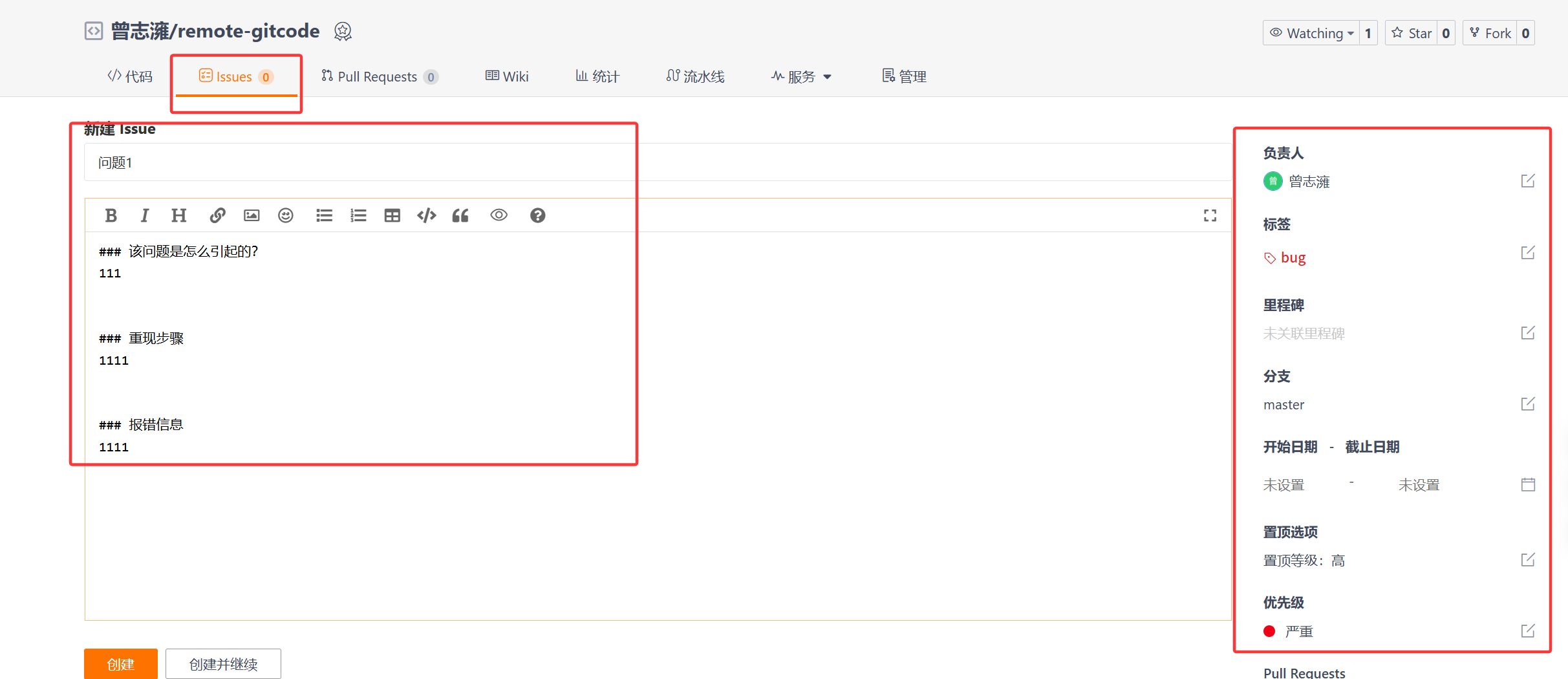
点击Issues,然后点击创建,就可以看到如图所示,这个实际上就是别人看你的仓库代码,发现你仓库代码有bug,那么就可以通过创建Issue来告诉仓库成员,右边可以选负责人、标签、哪个分支等信息,然后左边可以写问题、重现步骤、报错信息等。
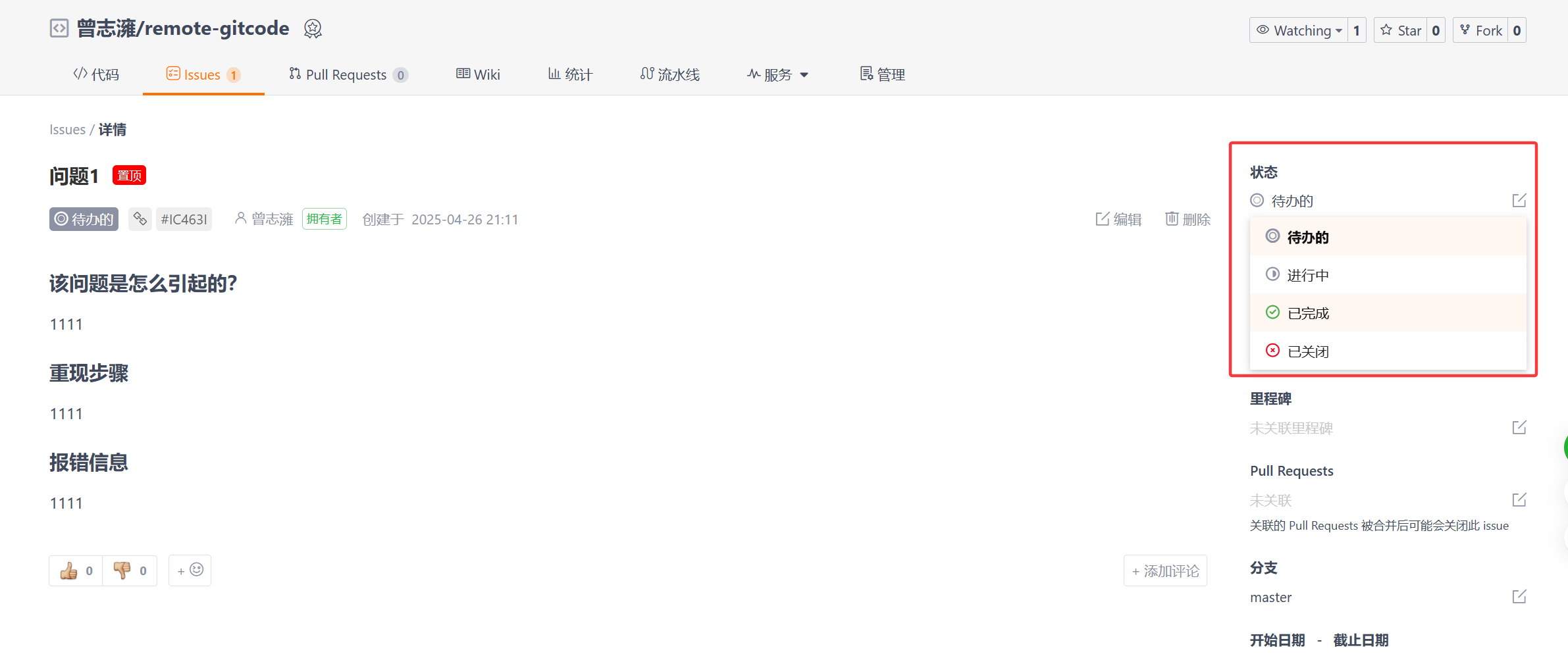
在处理完bug之后,就可以对该Issue进行设置,将其状态改为已完成。
再说Pull Request,我们之前开发创建了dev分支进行开发,开发后直接回到master分支进行合并。但是实际上并不能这样做,万一有bug就出问题了,所以在merge之前是需要提交一个PR:合并申请单的,管理员接收后同意才能进行合并。
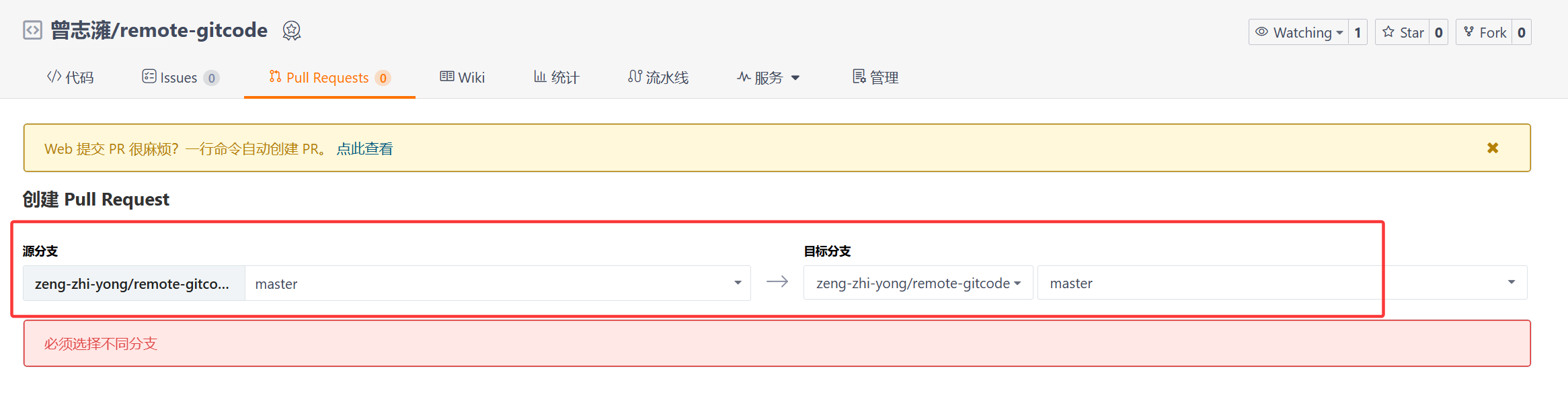
进入Pull Request模块中,然后点击创建Pull Request,我们可以填写从哪个源分支合并到哪个目标分支,提交给管理员。
4.3、克隆远程仓库
首先复制仓库的HTTPS连接:

然后在Linux上使用git clone 连接,进行克隆远程仓库:
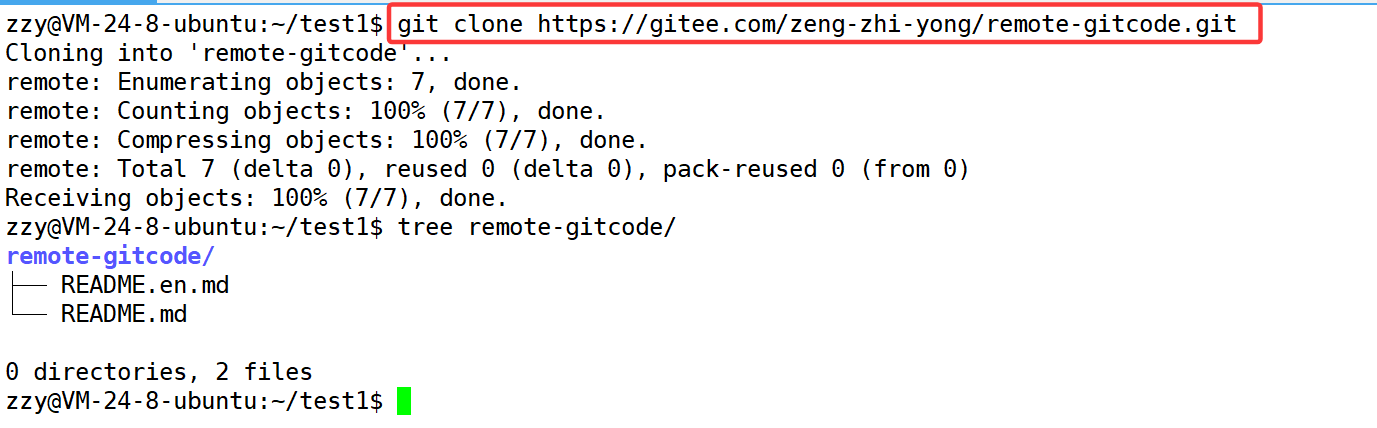
下面使用git remote查看远程仓库的名称,使用git remote -v查看更详细信息:
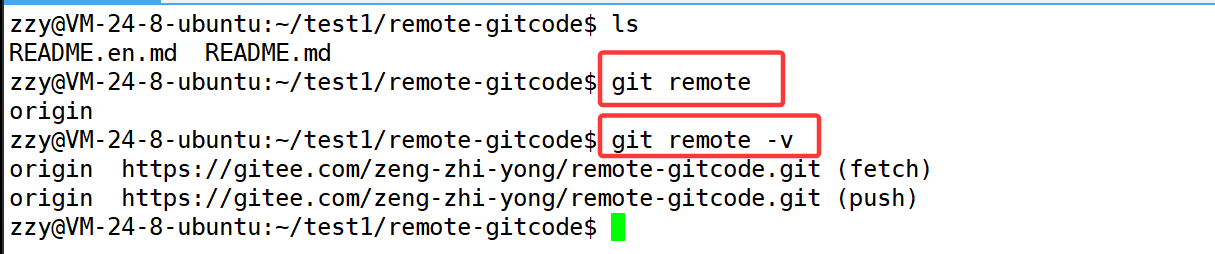
远程仓库的默认名称为orgin,查看更详细信息发现有push和fetch,表示具有推和拉取的权限。
下面介绍使用SSH进行克隆的方式,首先必须将Linux服务器上的公钥放到gitee上,才可以克隆成功。
首先进入设置:
左边选择SSH公钥:可以看到我当前是没有配置任何公钥的。
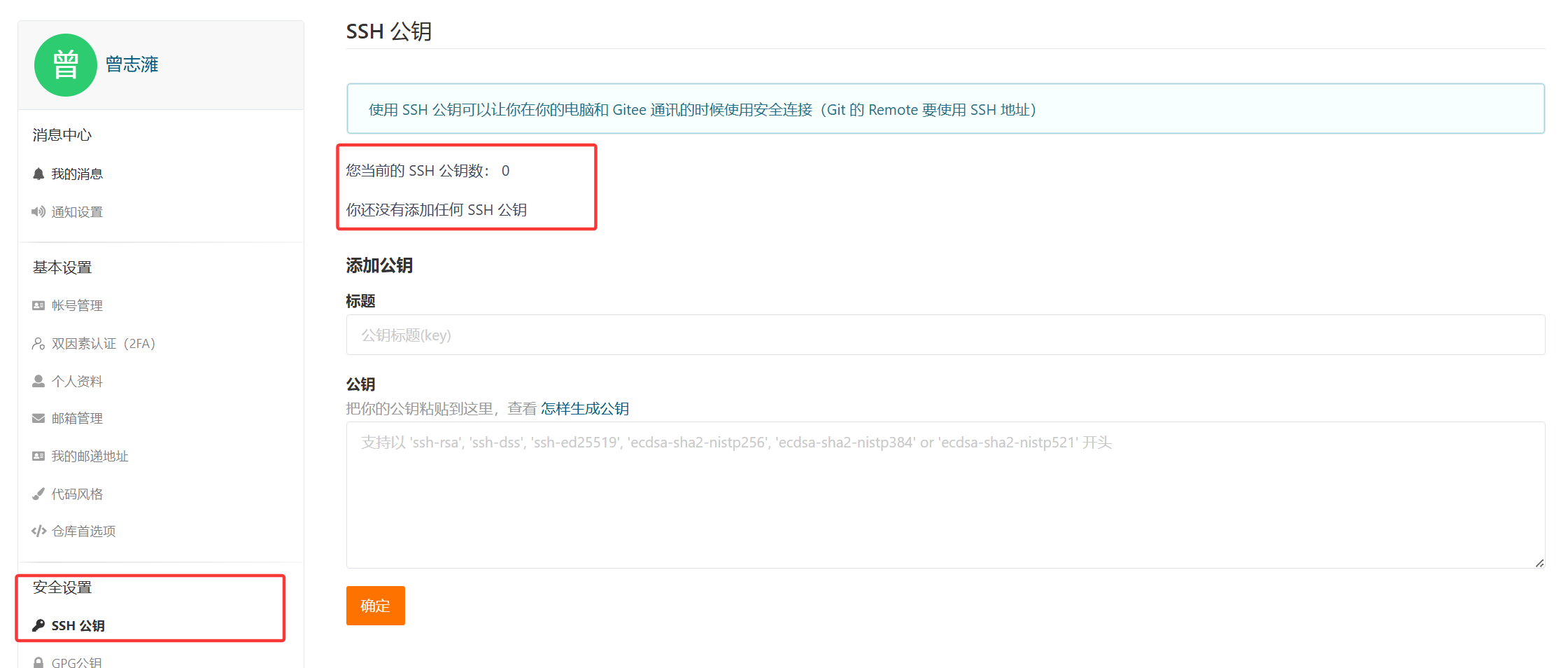
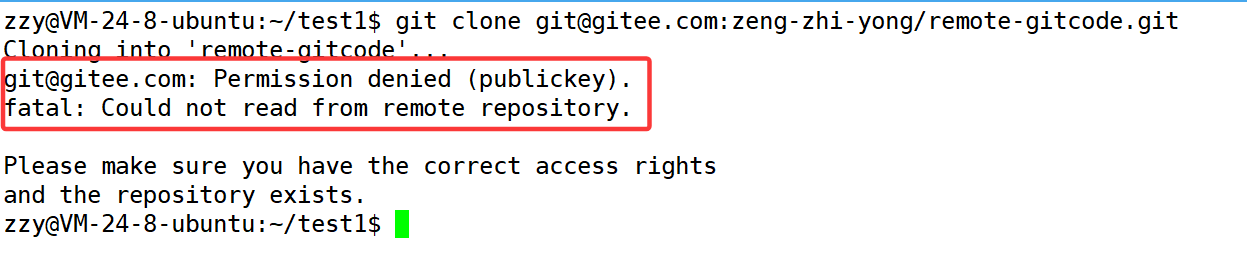
这时候我们直接使用SSH进行克隆会出错:因为没有配置公钥
第一步:创建SSH Key。在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果已经有了,可直接跳到下一步。如果没有,需要创建SSH Key:

我们发现我们有.ssh文件,但是.ssh文件下并没有上述的两个文件,所以需要我们创建:
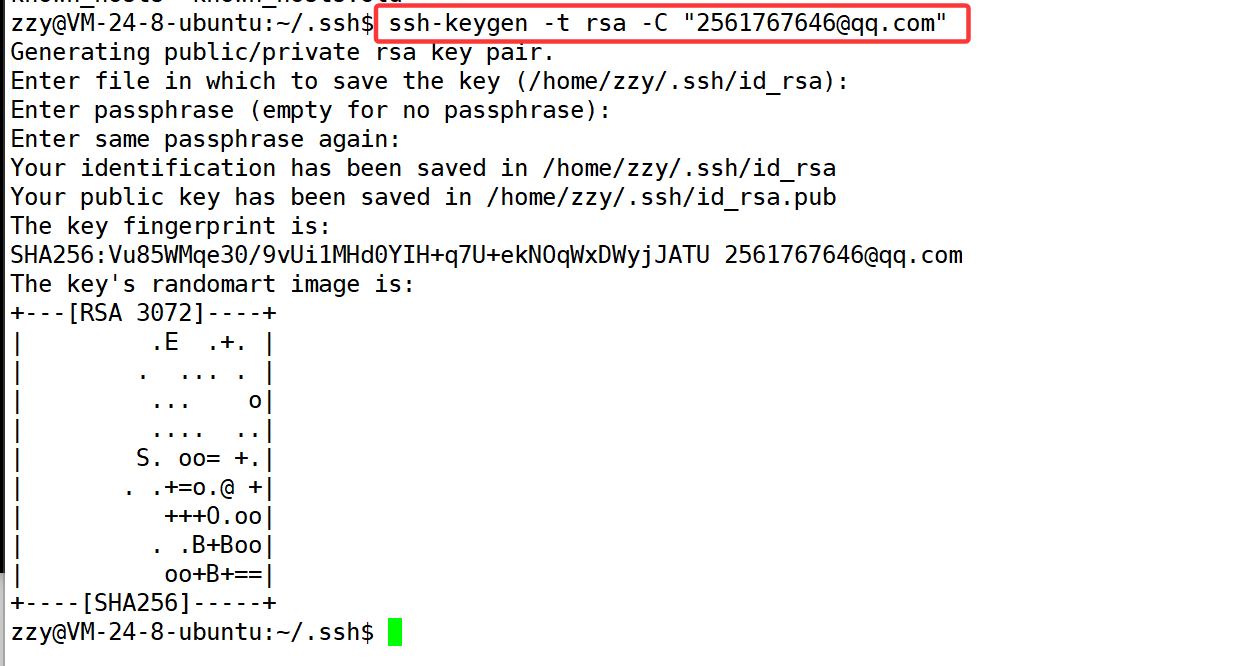
注意,后面的这个邮箱必须和你gitee上绑定的邮箱一致。然后一路回车即可。
此时再查看.ssh目录就发现有上述的两个文件了。接着将公钥获取出来:

将公钥复制到gitee上进行配置:
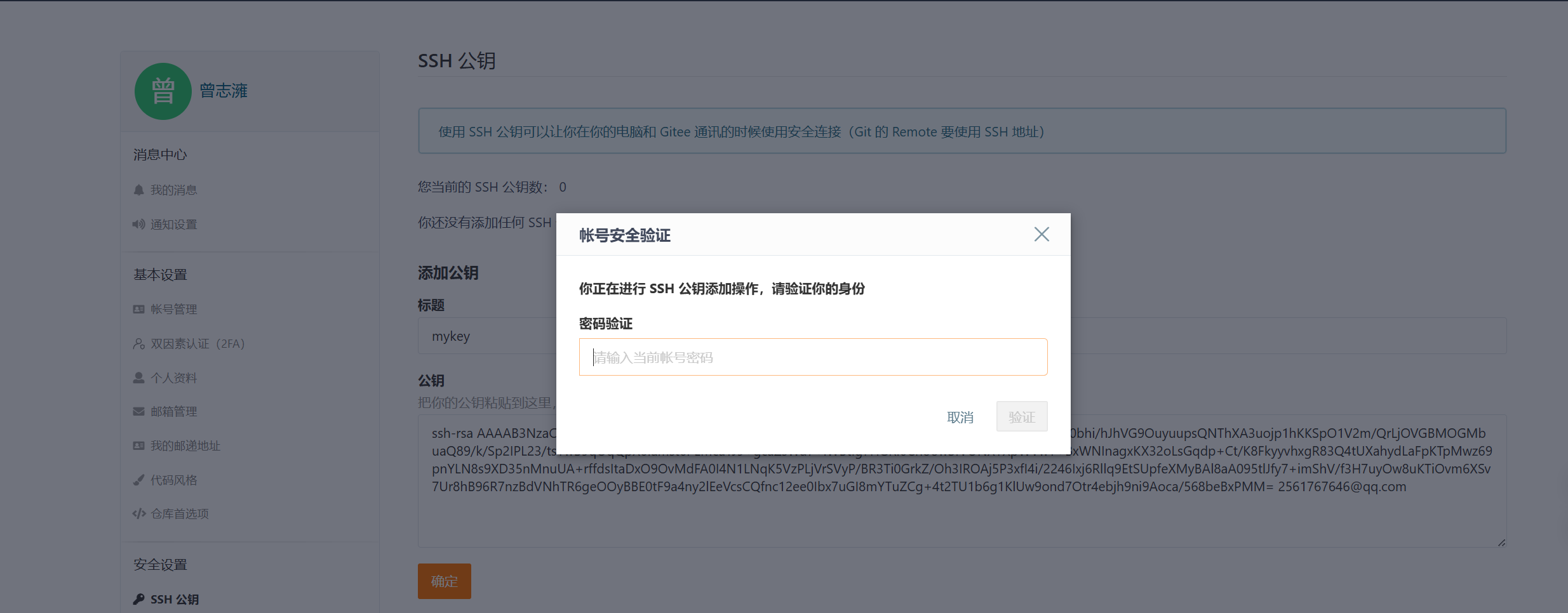
配置成功后即可进行克隆:

4.4、向远程仓库推送
从远程仓库克隆后,现在我们Linux上有一个remote-gitcode目录,这个目录就是工作区,里面的.git就是本地仓库。我们在工作区修改后需要git add添加到暂存区中,然后再git commit添加到master分支,再使用git push推送到远程仓库,这样远程仓库就能看到我们的改动了。需要注意的是,推送的是本地仓库的某个分支推送到远程仓库的某个分支,push是分支和分支之间的交互!
下面首先需要配置我们的本地仓库:
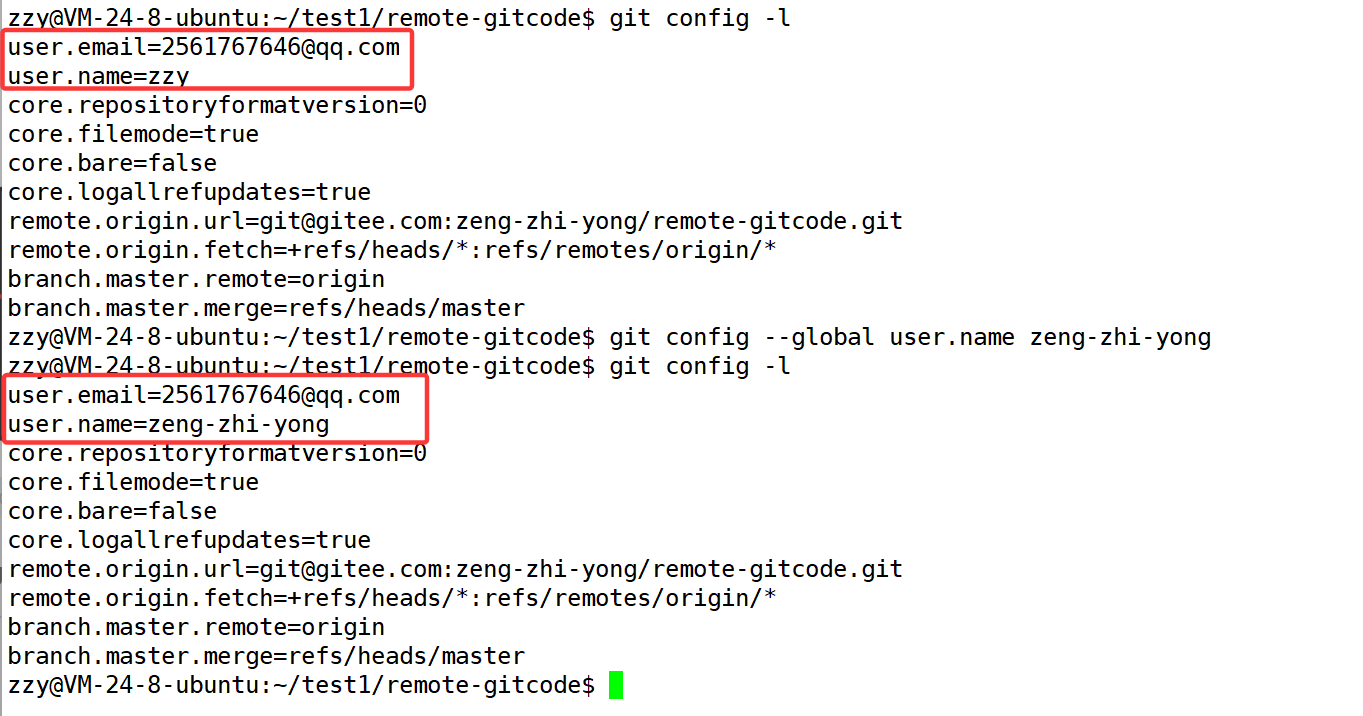
我们发现已经有了name和email的配置,这是因为在前面讲配置的时候我才用了全局配置,所以所有本地仓库都生效。但是要注意,这里的name和email得和gitee上的保持一致,所以上面我修改了name。
然后创建一个file.txt,写入内容,进行add和commit,并push到远程仓库:
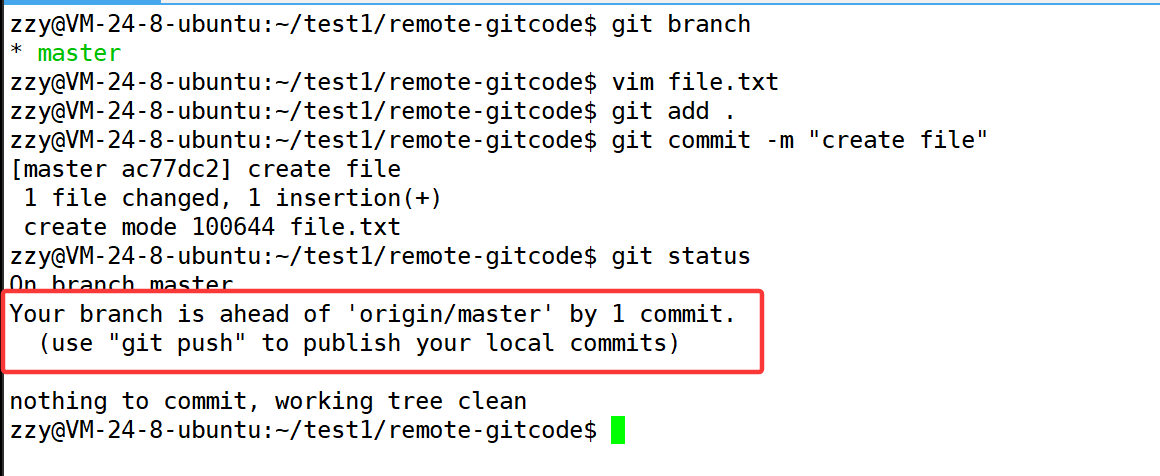
这次我们提交后再查看仓库的状态,相比之前,多出来了git push的内容。
接着我们使用git push推送到远程仓库:
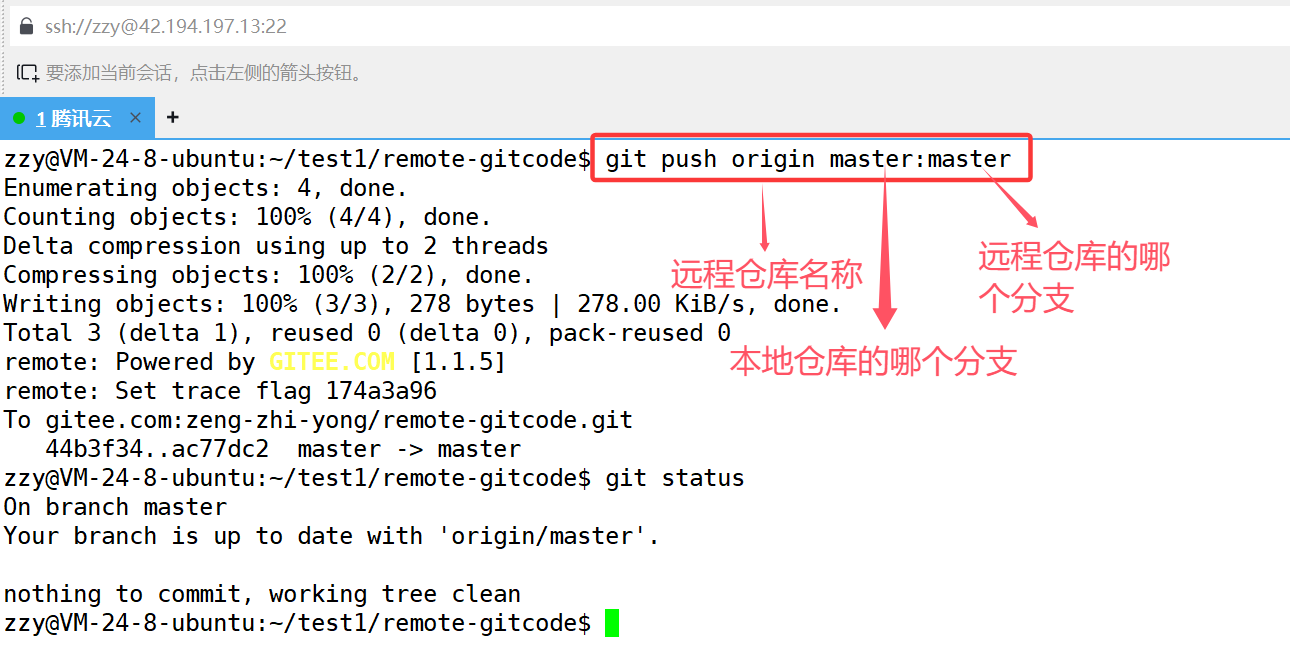
由于本地仓库的分支和要推送的远程仓库的分支都是master,是一样的,所以可以写成git push origin master。
推送成功后再来看远程仓库就发现多了一个文件:
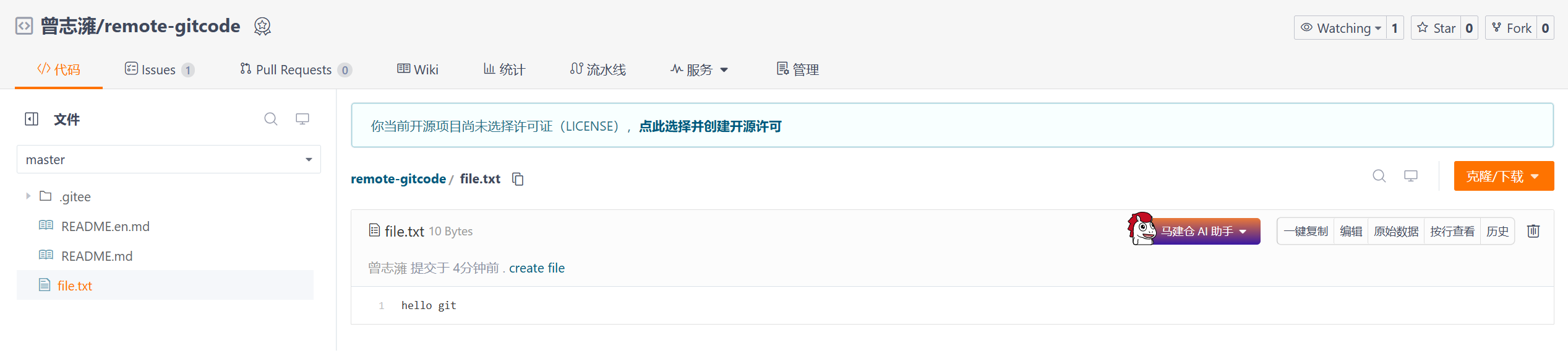
4.5、拉取远程仓库
上面是本地仓库的代码领先于远程仓库的代码,我们使用git push推送到远程仓库。如果当远程仓库的代码领先于本地仓库的代码,我们需要使用git pull将远程仓库的内容拉取到本地仓库。
当你写了hello git提交到远程仓库后,可能有其他人将远程仓库克隆,然后在本地仓库修改后再推送到远程仓库,这时候远程仓库就领先于你的本地仓库了。
下面我们简单一些,直接在gitee上修改:

此时远程仓库是要比我们本地仓库来的新的,所以我们要使用git pull命令拉取:
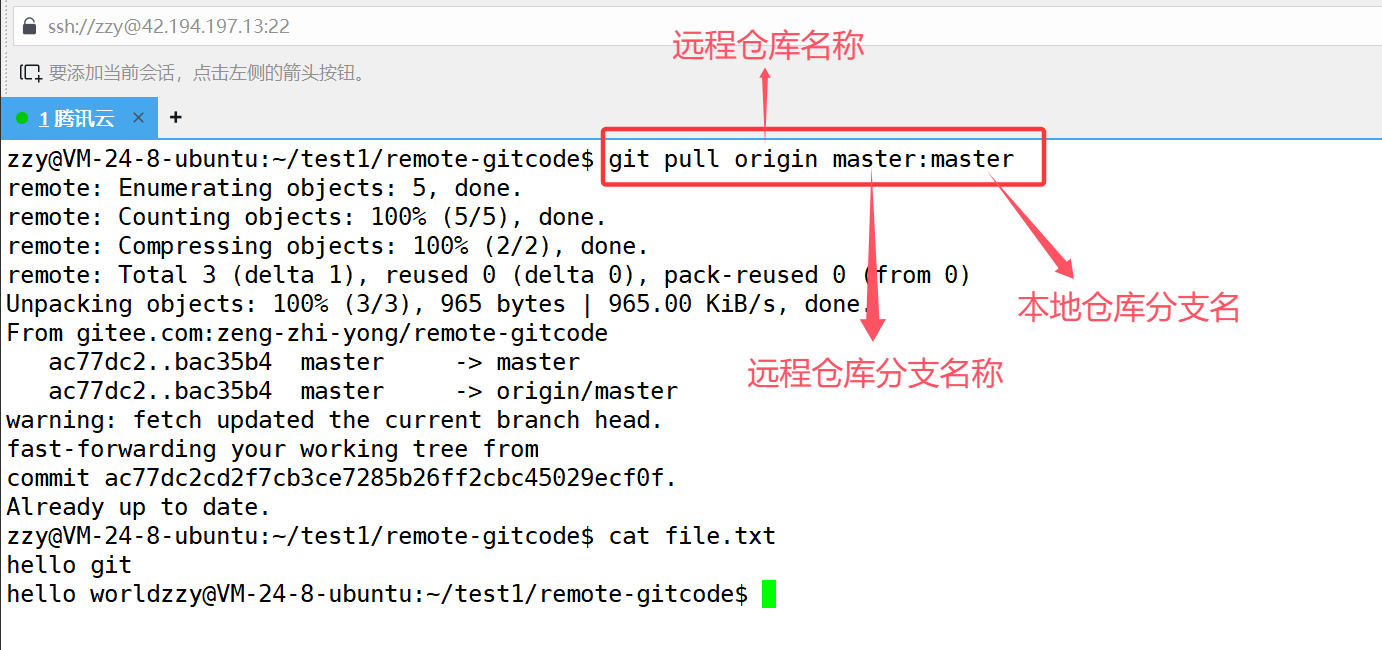
同样的,远程仓库的分支master和本地仓库的分支master是同名的,所以可以直接写成git pull origin master。
4.6、忽略特殊文件
在日常开发中,我们有些文件不想或者不应该提交到远端,比如保存了数据库密码的配置文件,那怎么让Git知道呢?在Git工作区的根目录下创建一个特殊的.gitignore文件,然后把要忽略的文件名填进去,Git就会自动忽略这些文件了。
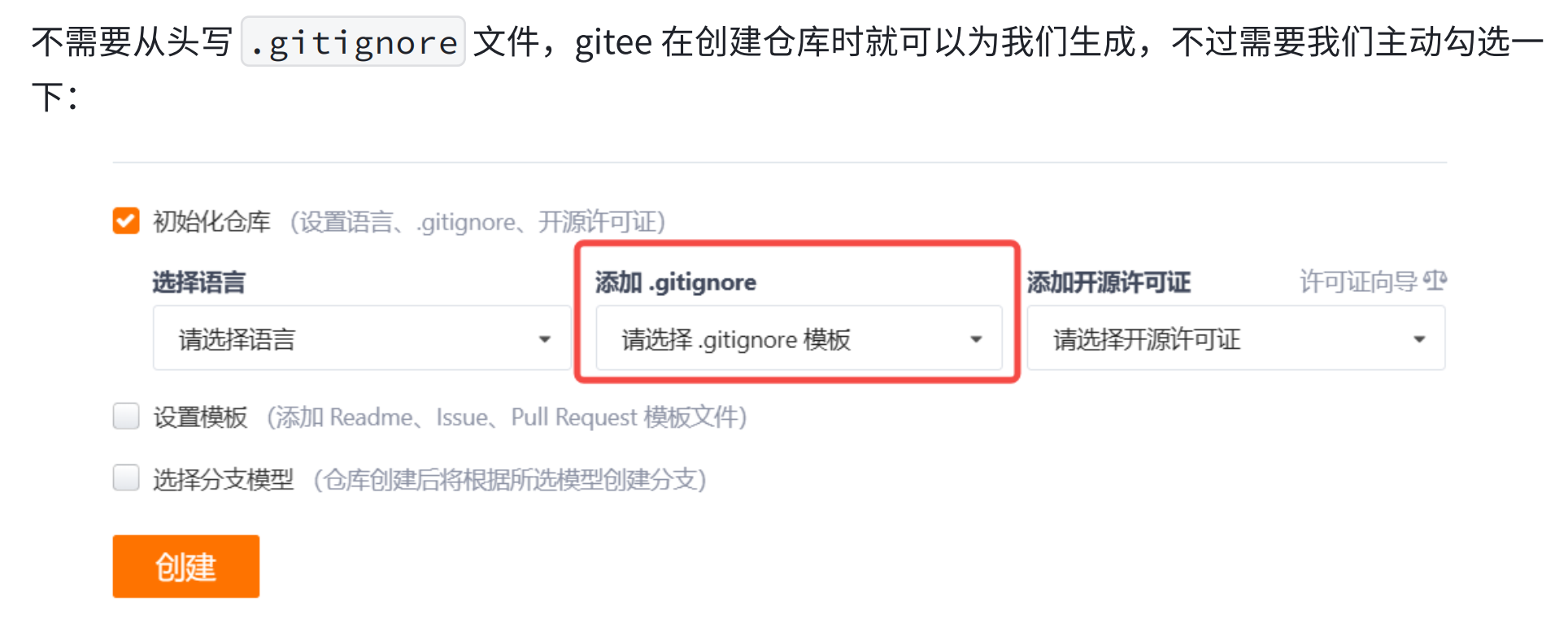
由于我们当时没有添加,所以手动创建一个。
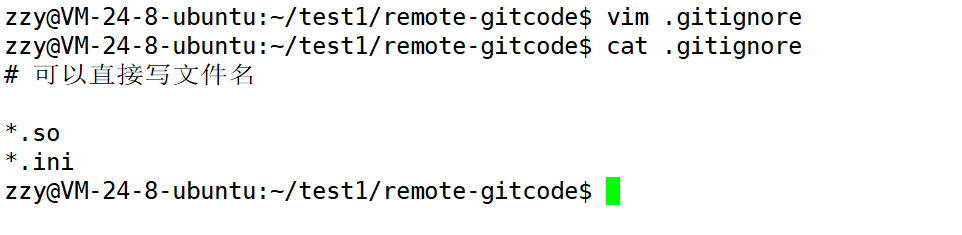
我们在工作区创建了一个.gitignore文件,里面的内容如图,第一行#开头表示的是注释。我们可以直接写忽略某个文件的文件名,也可以忽略一类文件,比如*.so,忽略以.so结尾的所有文件。
下面就在工作区创建a.so进行测试:
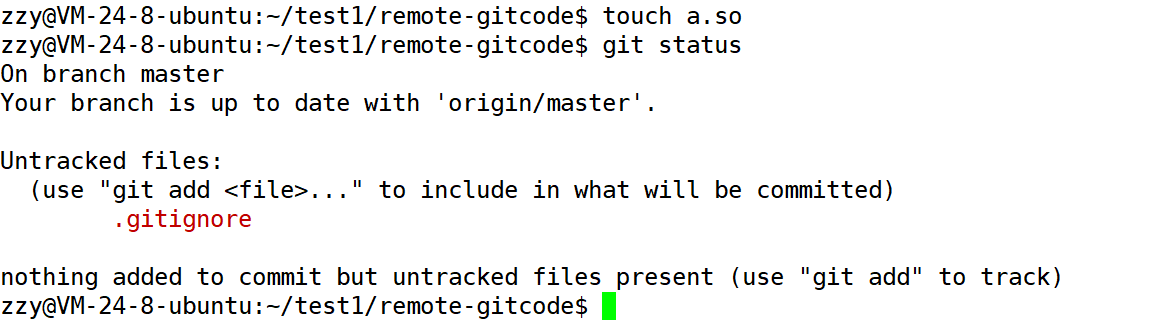
创建a.so后我们使用git status查看工作区状态,我们发现可以添加.gitignore,但是我们也创建a.so文件,正常来说也是要显示的,这里之所以没有显示就是因为.gitignore中配置了,所以就忽略了。
下面使用git add .,将修改添加到暂存区中:
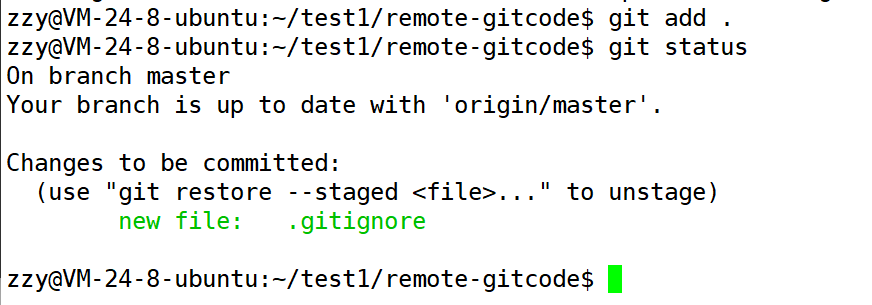
可以发现只有.gitignore被添加到了暂存区中,a.so文件被忽略了。
假设现在我创建了b.so文件,但是我就是想将该文件添加到暂存区,可以使用git add -f 文件名:
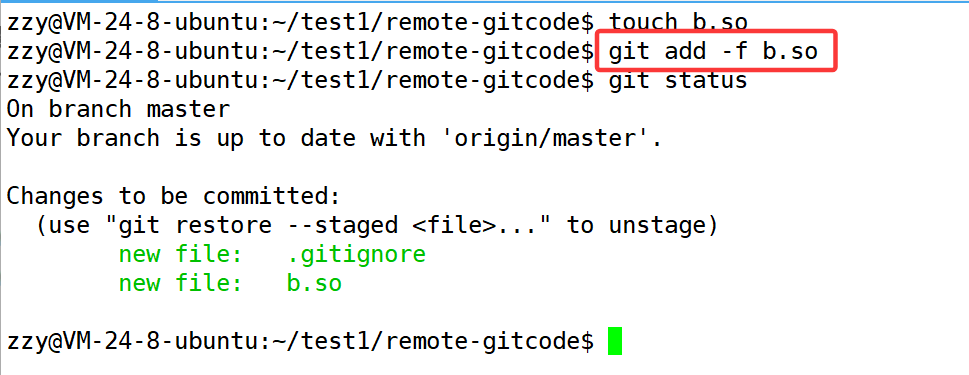
但是我们尽量不要使用这种方式,因为我们不想破坏.gitignore的规则,所以我们还有另一种方式,在.gitignore文件中配置专门不排除某个文件,下面配置不排除c.so文件:在.gitignore中添加!c.so
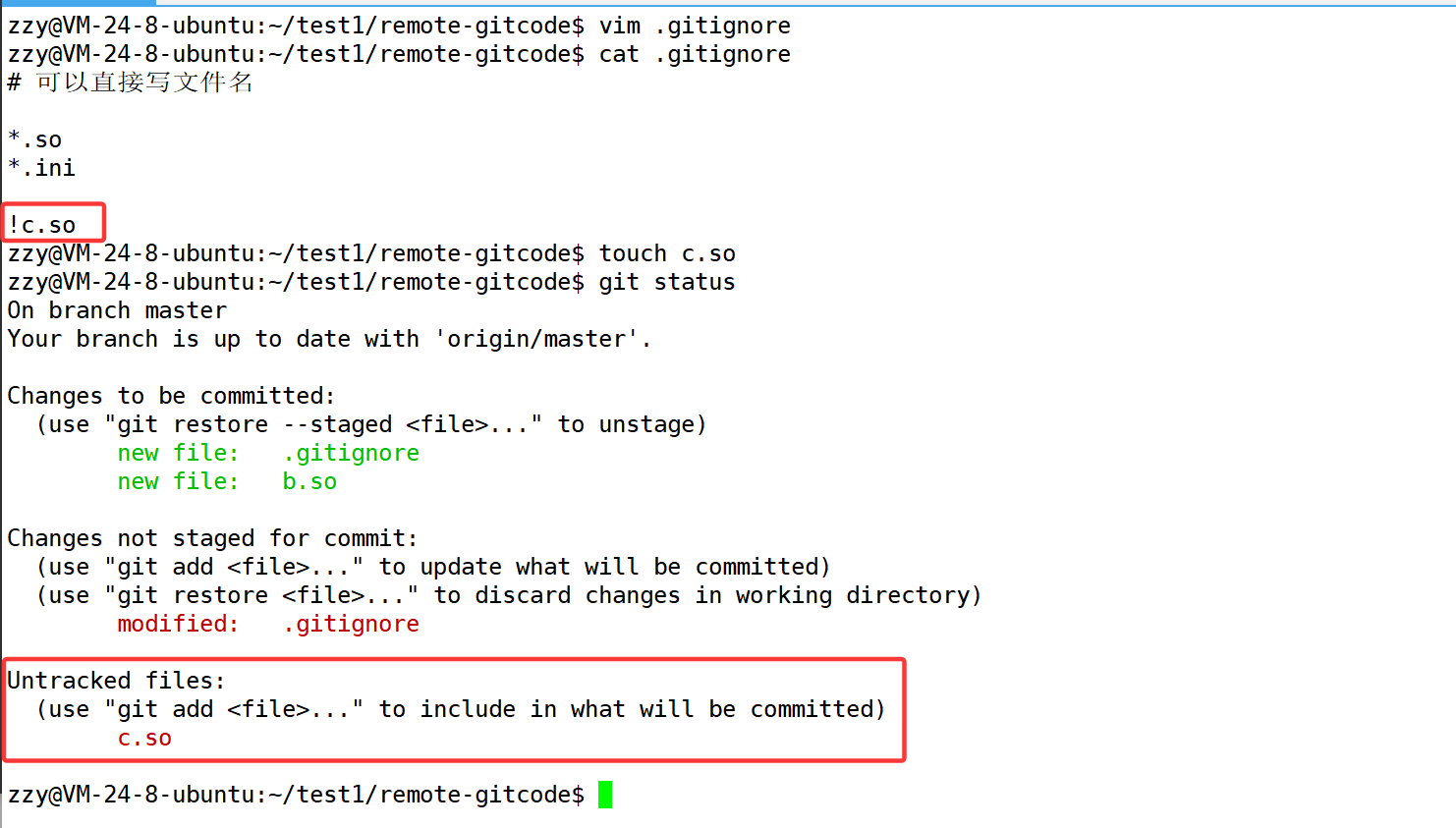
如图,此时我们在工作区再创建c.so文件,再查看状态就可以看到c.so了,此时c.so就没有被忽略了。
当.gitignore文件很大了,某天我们创建了d.so文件,但是不知道为什么d.so文件被忽略了,这时候我们可以使用以下命令查看:
git check-ignore -v d.so

4.7、配置命令别名
比如我们在使用git status查看仓库状态的时候,我们觉得这样写太麻烦了,想改成git st,可以使用以下命令进行配置:
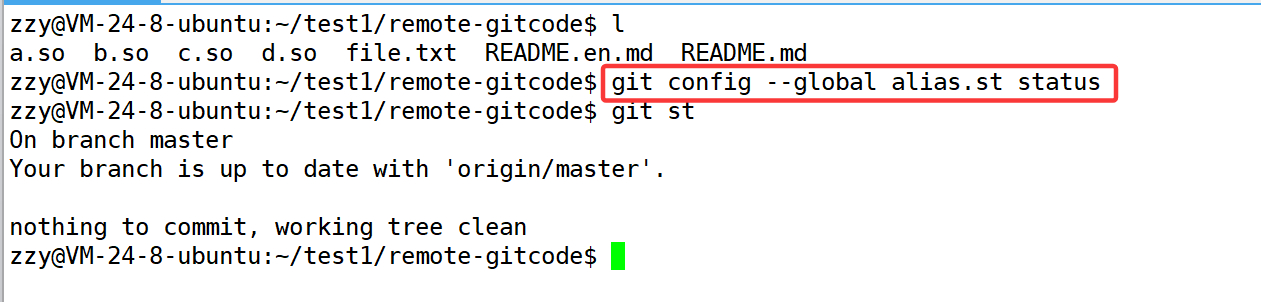
带--global全局生效,alias.后面跟起的别名,最后面跟要起别名的命令。
再比如对于之前查看日志信息进行重命名:

5、标签管理
5.1、操作标签
加粗样式
标签tag,可以简单的理解为是对某次commit的一个标识,相当于起了一个别名。例如,在项目发布某个版本的时候,针对最后一次commit起一个v1.0这样的标签来标识里程碑的意义。 这有什么用呢?相较于难以记住的commit id,tag很好的解决这个问题,因为tag一定要给一个让人容易记住,且有意义的名字。当我们需要回退到某个重要版本时,直接使用标签就能很快定位到。
使用git tag xxx添加一个标签,使用git tag查看所有标签:


可以看到,上面添加的标签默认是给最新一次的提交添加的。
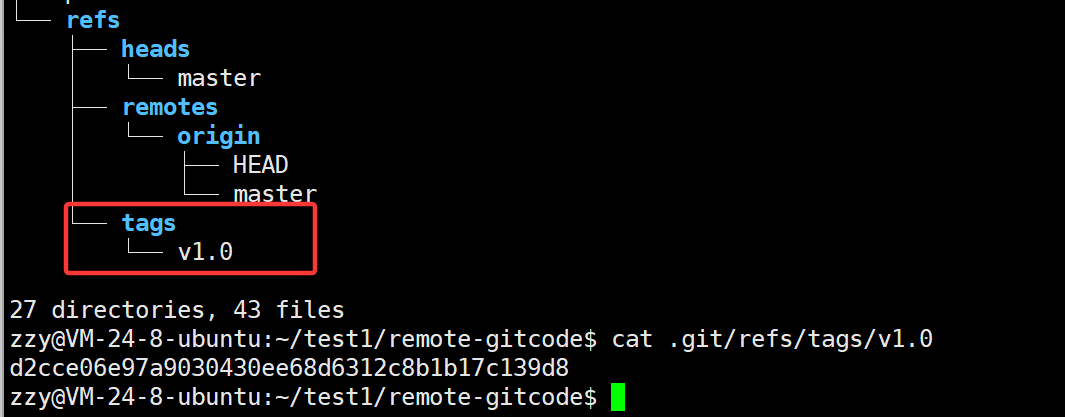
我们看到.git目录下的refs目录下新增一个目录tags,里面有一个v1.0文件就是我们刚才添加的标签,输出该标签的信息,里面保存的就是最新一次提交的commit id。
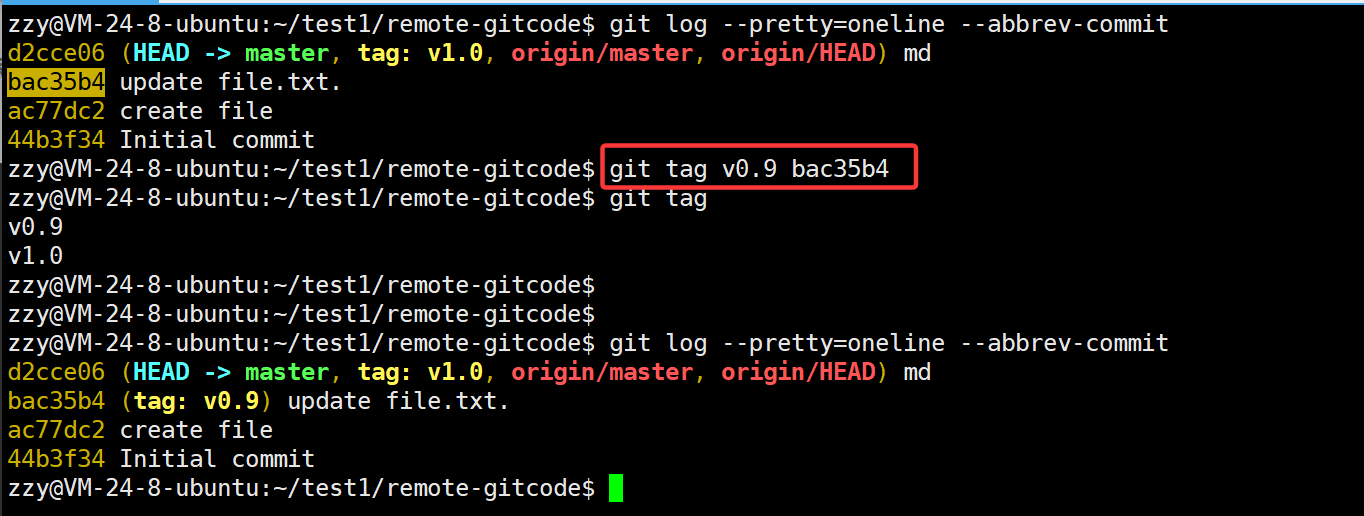
前面添加的标签默认是给最新的一次提交添加的,如果我想给前面的提交添加的话需要在后面带上commit id。
上述两个添加标签我们只是单纯的添加标签,我们还可以给标签添加描述:
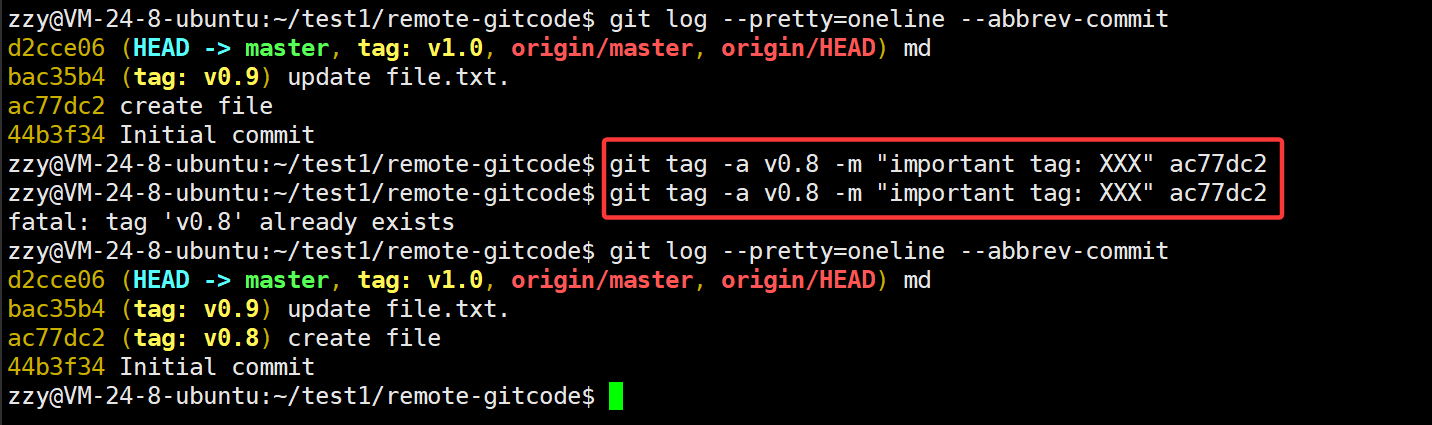
首先带-a后面跟标签名,再带-m添加你的描述内容,默认给最新的一次提交打标,后面跟commit id表示要给对应的提交打标。
使用git show查看标签的详细信息:后面直接跟上标签名即可
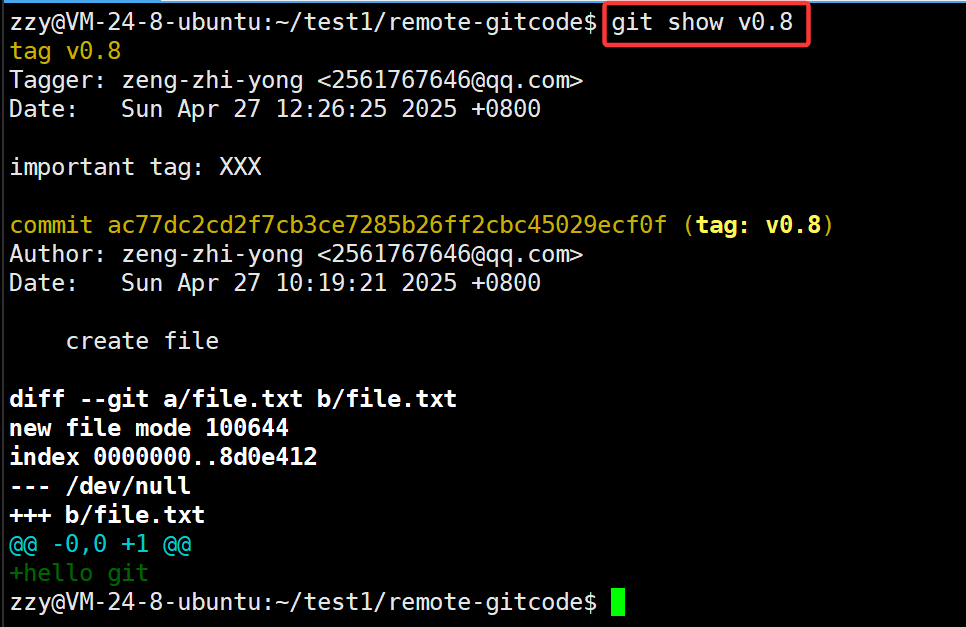
使用git tag -d删除标签:后面直接跟标签名即可
5.2、推送标签
我们远程仓库现在是没有标签的,需要使用git push将本地标签推送到远程仓库中:


git push origin后面跟标签名,可以将本地仓库的标签推送到远程仓库中。
另外我们还可以使用git push origin --tags推送所有本地标签至远程仓库中:
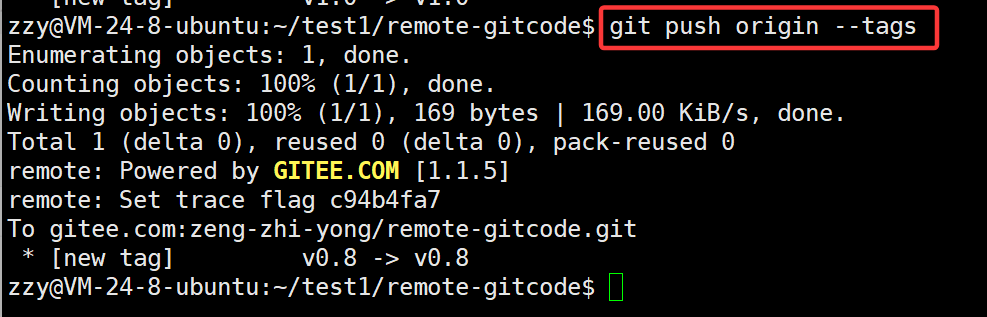
如果我们要删除标签,可以直接在远程仓库中进行操作,但是这种做法不推荐。
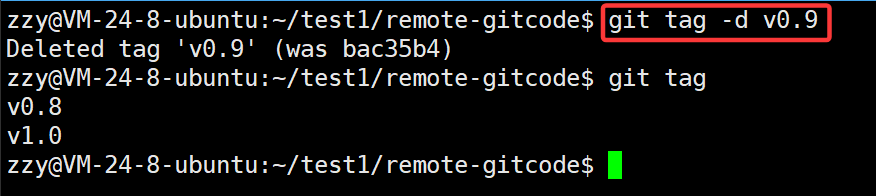
我们可以现在本地删除标签,然后再推送到远程仓库中:
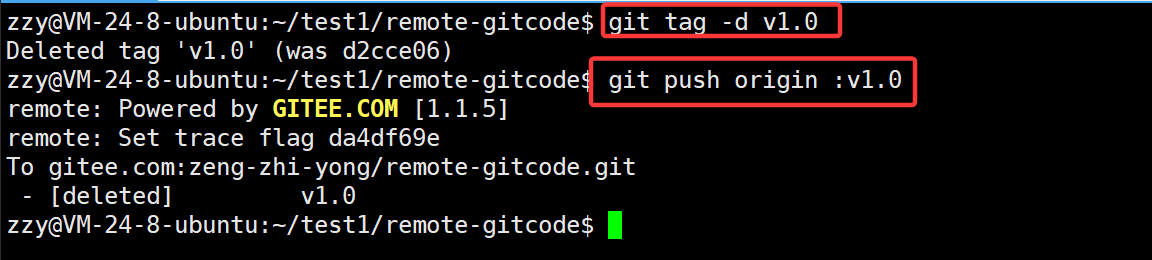
冒号左侧表示本地仓库,右边表示远程仓库,我们在右边加上标签即可。
6、多人协作
6.1、完成准备工作
目标:远程master分支下file.txt文件新增"aaa"和"bbb"。
实现:由开发者1新增aaa,开发者2新增bbb。
条件:在一个分支下协作完成。
开发者1在Linux上进行开发,开发者2在Windows上将仓库克隆下来模拟第二个开发人员。
这个分支肯定不能是master分支,所以我们需要创建一个dev分支。我们首先在gitee上创建一个dev分支:

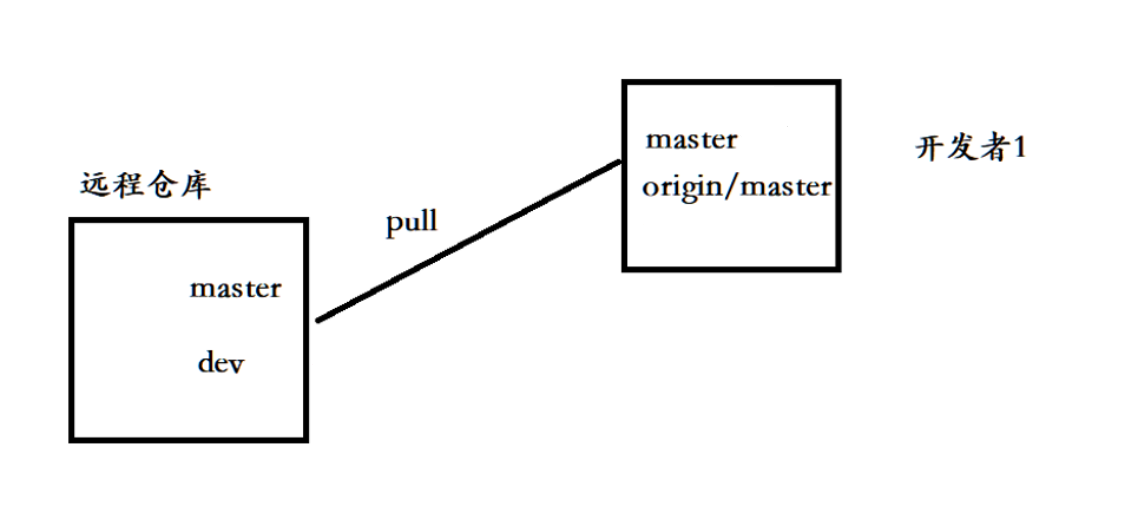
所以选在远端仓库有master和dev分支,我们Linux服务器上有一个master分支,还有一个远程的origin/master分支。

我们可以使用git branch -r查看远程的分支。这时候我们看不到dev分支,所以可以使用git pull拉取。
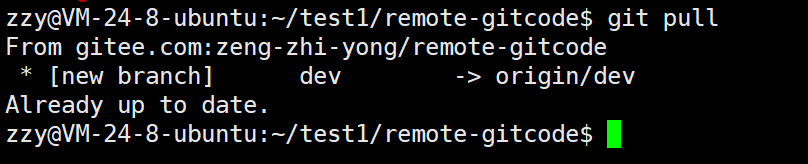
我们可以直接使用git pull拉取相信的内容。
下面我们可以使用git branch -a查看本地分支和远程分支信息:
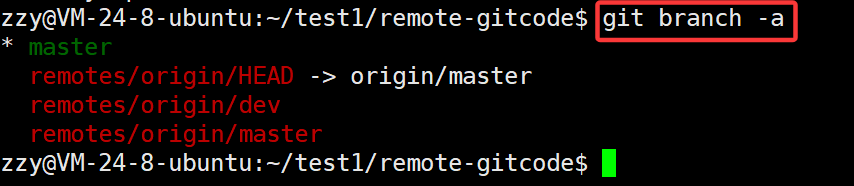
注意:之前使用的git push origin master,指定了远程并且也指定了分支。当我们制定远程仓库或者远程分支的时候是不需要建立接连的。当我们使用简写git push的时候,我们需要建立连接,这时候git才知道是从哪个分支到哪个分支的。包括pull也是如此。
对于开发者1准备工作完成,现在需要完成开发者2的准备工作。在windows下我们克隆远端仓库:

6.2、协作开发
首先完成开发者1的任务,我们肯定是不能直接切到远程的dev分支进行开发的,因此需要在本地仓库中创建一个dev分支:
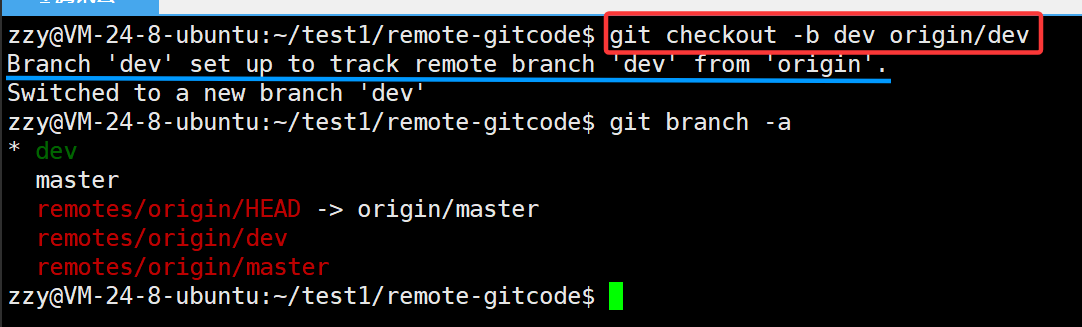
创建一个dev分支,并在后面加上origin/dev,然后我们查看所有分支,发现成功创建了dev分支并且切换到了dev分支。哪么我们还发现多打印了一行,这是建立了dev分支和远程origin/dev分支的连接。
可以使用git branch -vv查看建立的连接:

可以看到dev分支和远程dev分支建立了连接,master分支也和远程的master分支建立了连接。
此时如图所示:
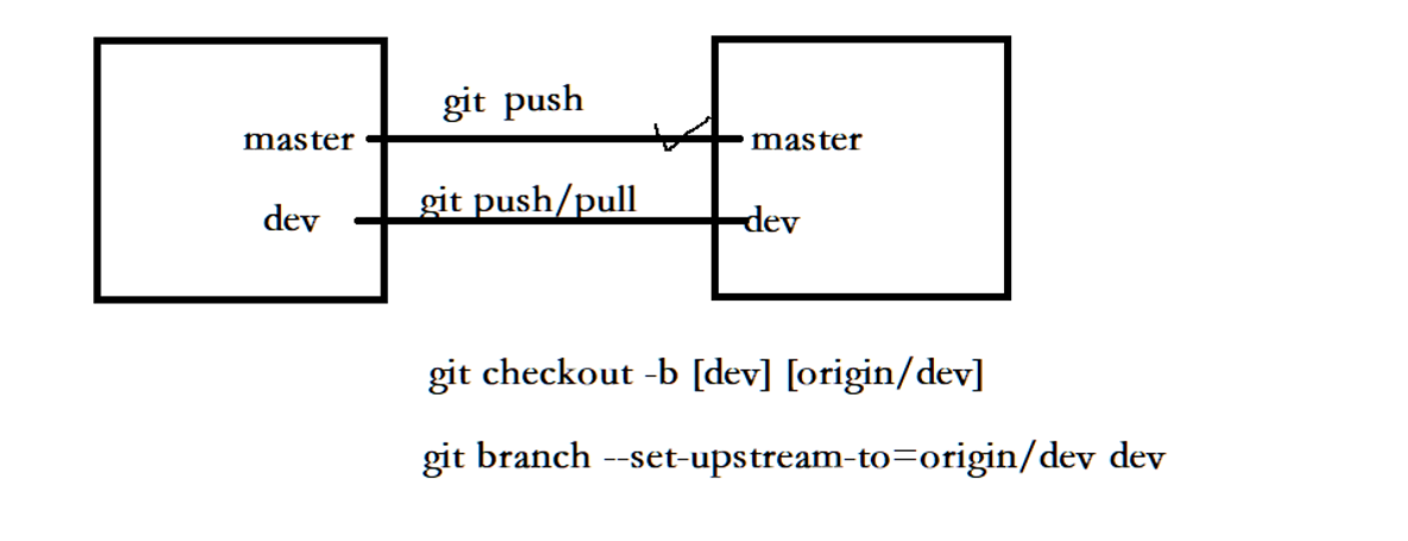
那么建立了连接的一个好处就是,当我们对dev分支进行提交需要推送或者从远端拉取的时候,我们就可以简写成git push/git pull了,不需要后面再跟远程仓库名和分支名了。
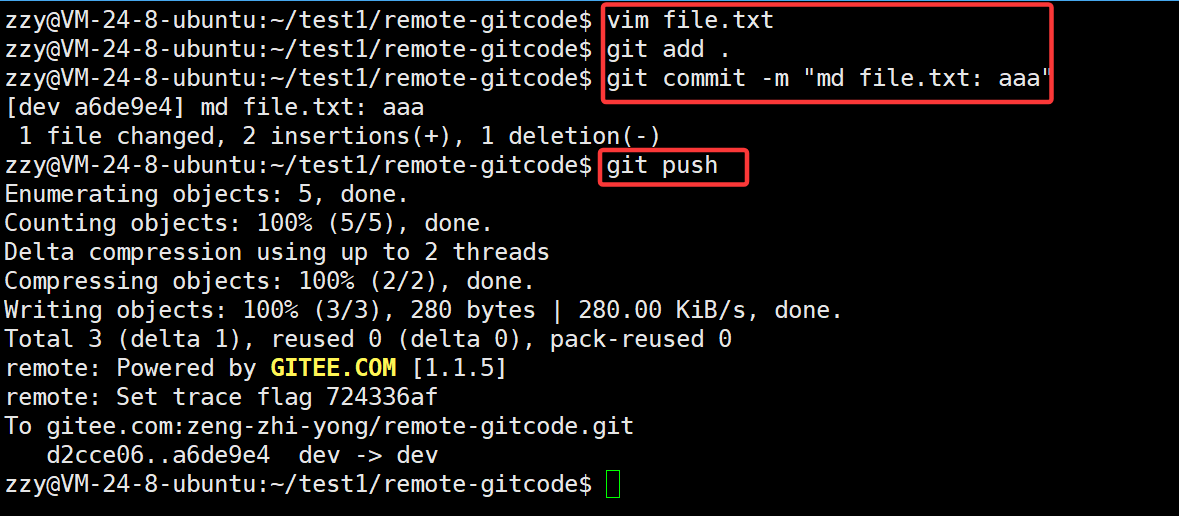
下面完成开发者1的开发任务:
接下来对于开发者2需要先创建一个dev分支,我们演示一下后面不跟远程分支,这样就不会建立两个分支的连接:
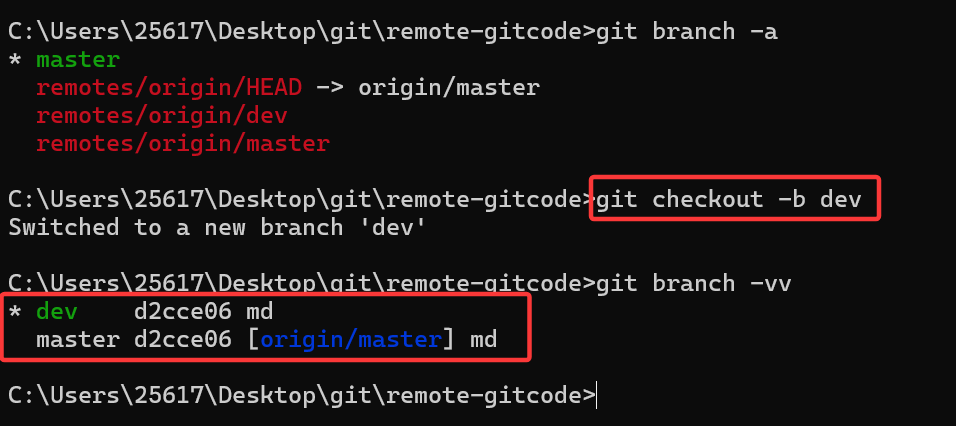
可以看到此时本地的dev分支就没有和远程的dev分支建立连接。
因为没有建立连接,所以我们不能直接简写成git push/git pull,需要在后面加上远程仓库名和分支名,下面我们直接git pull拉取试试看:
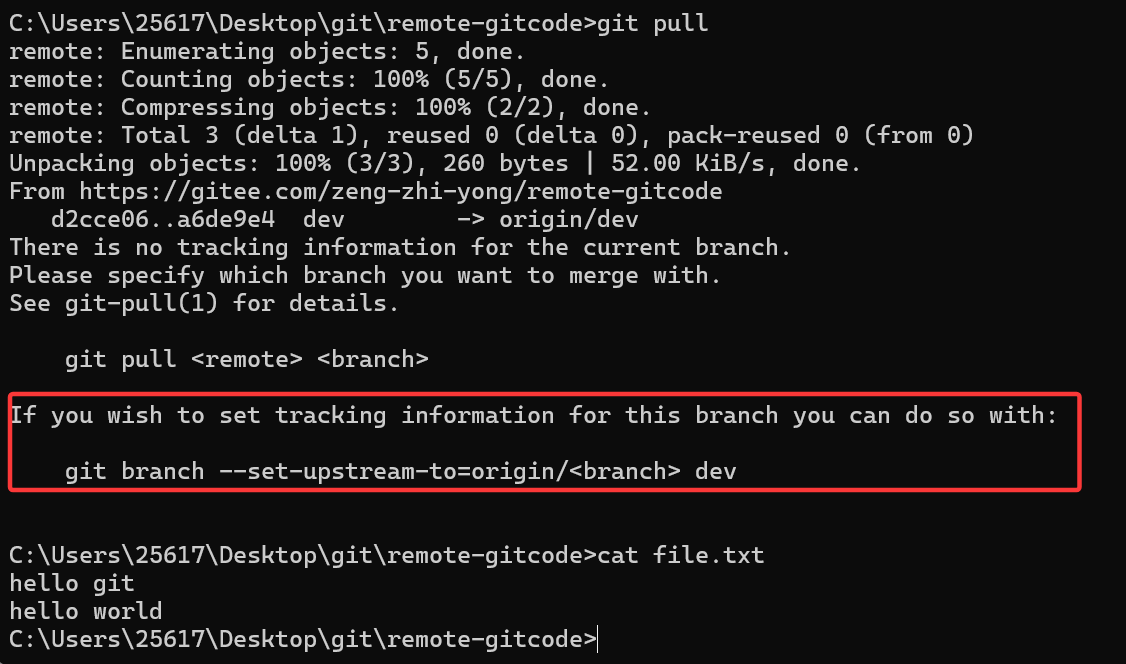
可以看到直接git pull拉取,我们的file.txt文件内容是不变的。所以需要建立本地dev分支和远程dev分支的连接。
我们使用以下命令建立连接:
git branch --set-upstream-to=origin/ dev

接着我们进行开发,在file.txt文件中加上bbb:
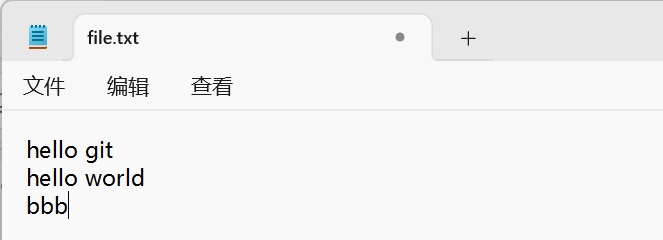
保存退出后进行add、commit、push:
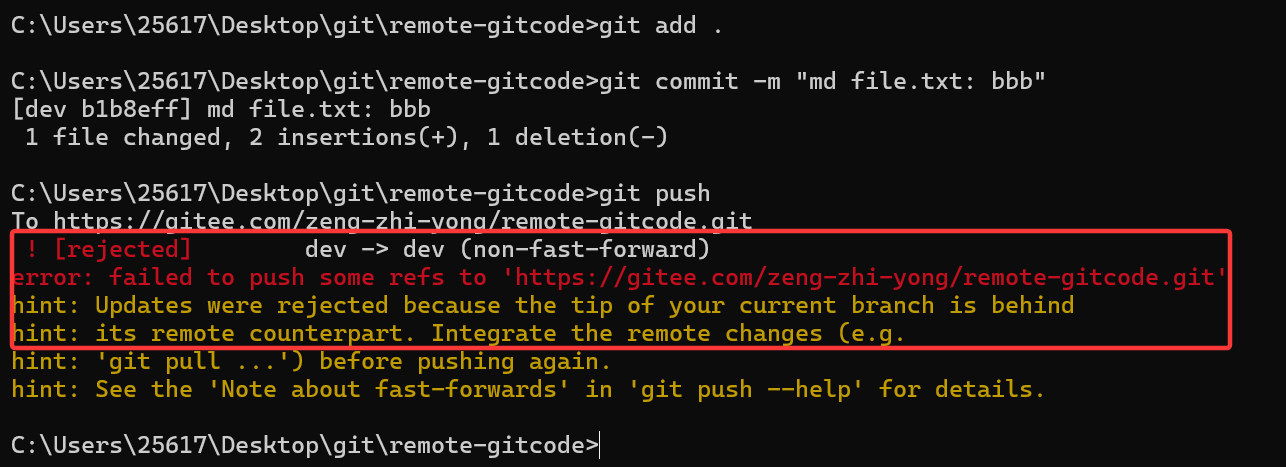
这时候在推送的时候远端就拒绝了,这是因为远端现在file.txt有aaa的内容,然后我们本地file.txt有bbb内容,这时候直接推送就有冲突,但是git并不知道要保留哪份。所以需要先git pull拉取远端修改的内容,然后在本地解决冲突的问题,再推送到远端即可。


拉取后解决冲突,重新提交再推送。
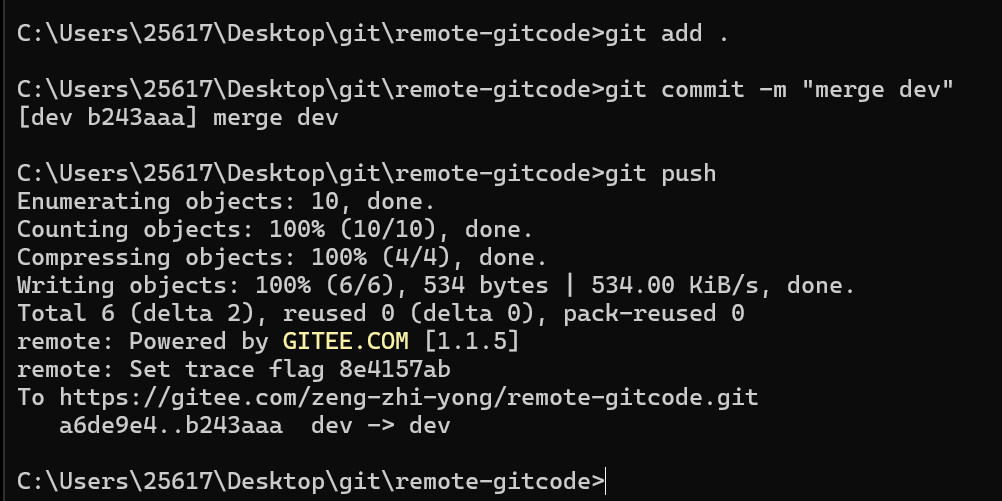
6.3、将内容合并进master
此时远端仓库的dev分支file.txt中已经有了aaa和bbb,但是master分支还没有,因为我们还没将dev分支合并到master分支中,接下来我们就完成这个步骤。
有两种方式:
1、我们通过pull request提交一个PR申请单,然后管理员进行合并操作。
2、本地master分支合并dev分支,接着把master再推送到远程仓库中。
我们推荐的是走PR工单这一种方式,这是需要通过审查员审核的。不过这里我们就采用本地的这种方案。
但是在master分支merge dev分支可能出现冲突,所以我们可以在dev分支中先merge master分支,有冲突在dev分支中解决,接着再让master分支来merge dev分支。
在dev分支merge master分支的时候,我们要保证master分支是最新的。所以要先让master进行git pull操作。
下面我们以开发人员1进行操作,由于开发人员1的file.txt只有aaa,所以需要先进行git pull,更新一下本地的dev分支:
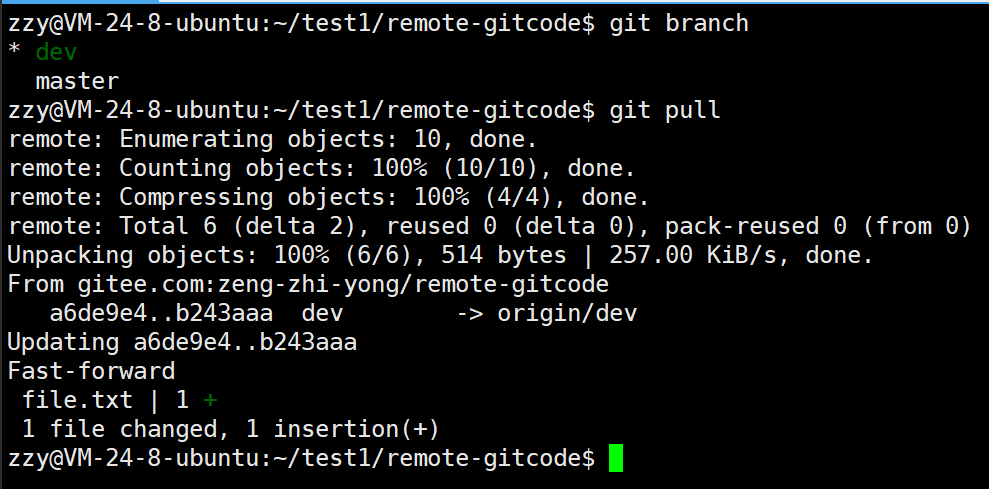
接着要先切到master分支拉取一下,保证master是最新的:
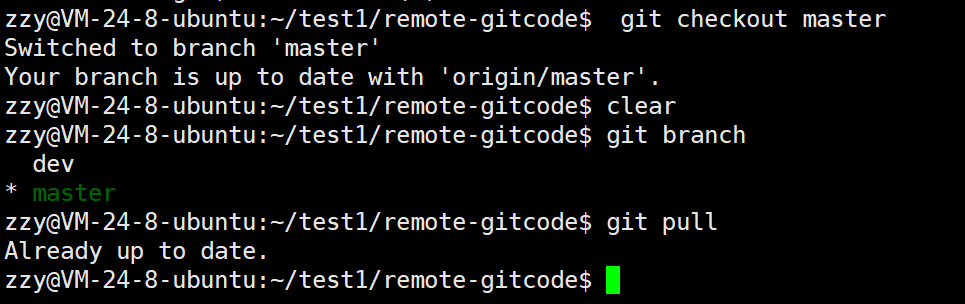
再切回dev分支,然后合并master分支:
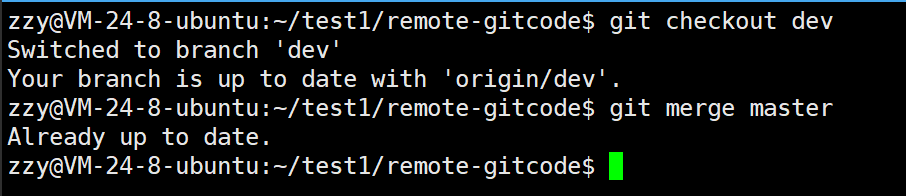
此时没有冲突,所以我们可以直接切回master分支合并dev,如果有冲突解决后再合并即可:
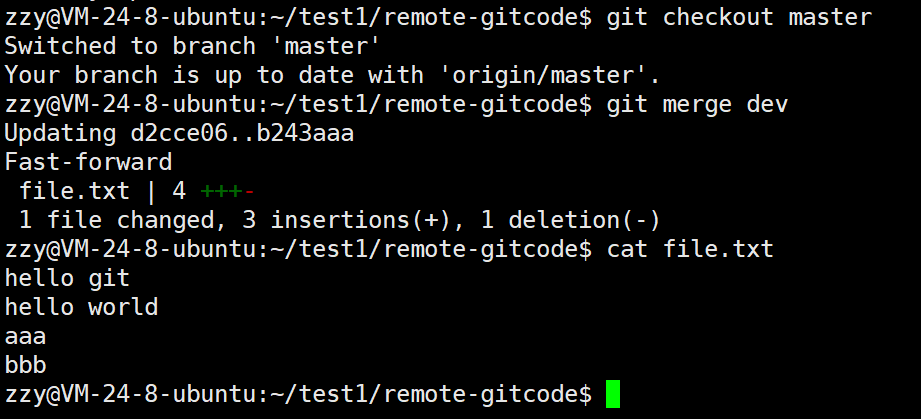
最后我们就可以使用git push将本地分支推送到远端:
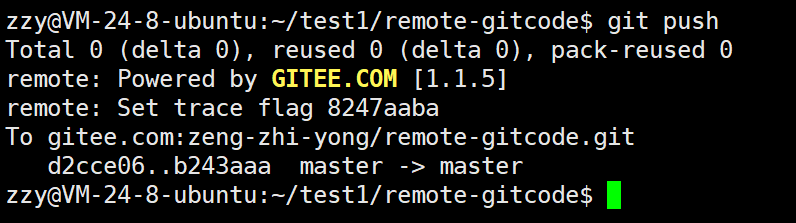
此时开发完成,那么远端的dev分支就没用了,可以删除了。
总结一下,在同一分支下进行多人协作的工作模式通常是这样:
• 首先,可以试图用 git push origin branch-name 推送自己的修改;
• 如果推送失败,则因为远程分支比你的本地更新,需要先用 git pull 试图合并;
• 如果合并有冲突,则解决冲突,并在本地提交;
• 没有冲突或者解决掉冲突后,再用git push origin branch-name推送就能成功!
• 功能开发完毕,将分支 merge 进 master,最后删除分支。
6.4、多人协作2
目标:远程master分支下新增funcion1和function2文件。
实现:由开发者1新增functino1,开发者2新增function2。
条件:在不同分支下协作完成。
我们让某一个功能私有某一个分支。
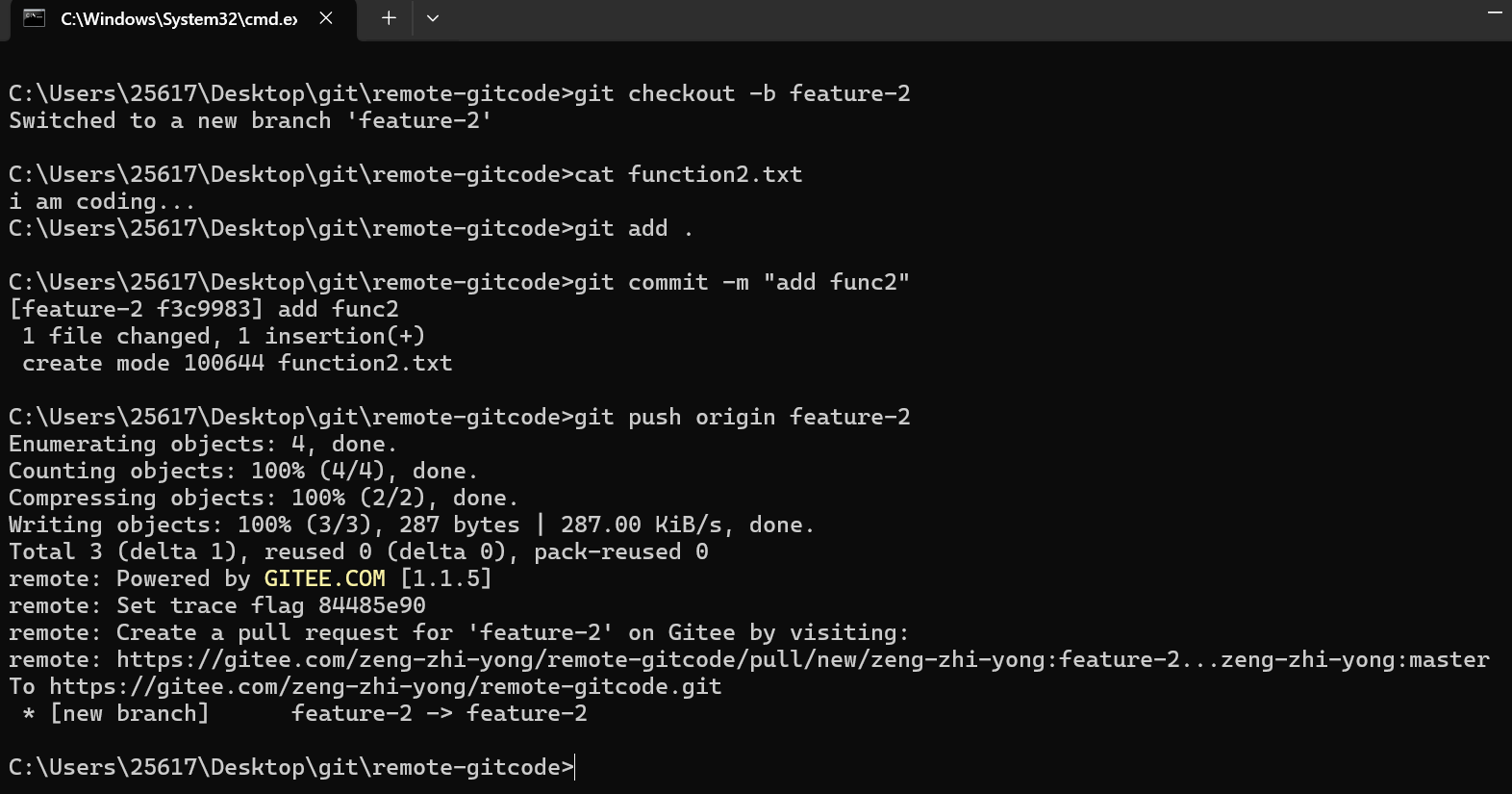
这回我们不再远程创建分支,我们让开发者1在本地创建一个分支feature-1进行开发(不过我们推荐的是在远程创建分支):

这次我们没有办法在后面跟上远程分支建立连接了,因为远程仓库并没有对应分支。
接着我们进行开发:
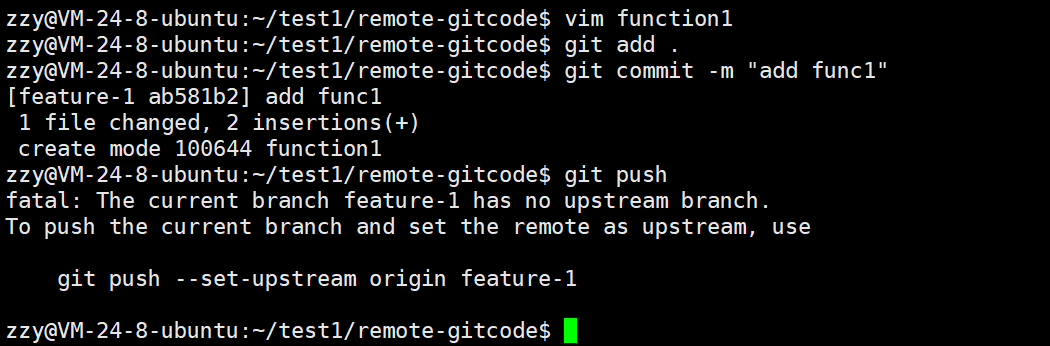
最后使用git push进行推送,但是我们发现无法推送,这是因为本地的feature-1分支并没有与远程仓库分支建立连接,所以无法直接使用git push推送。
建立连接有两种方式,但是我们无法建立,因为远程仓库中没有这个分支。
所以只能是git push后面跟上远程仓库名:
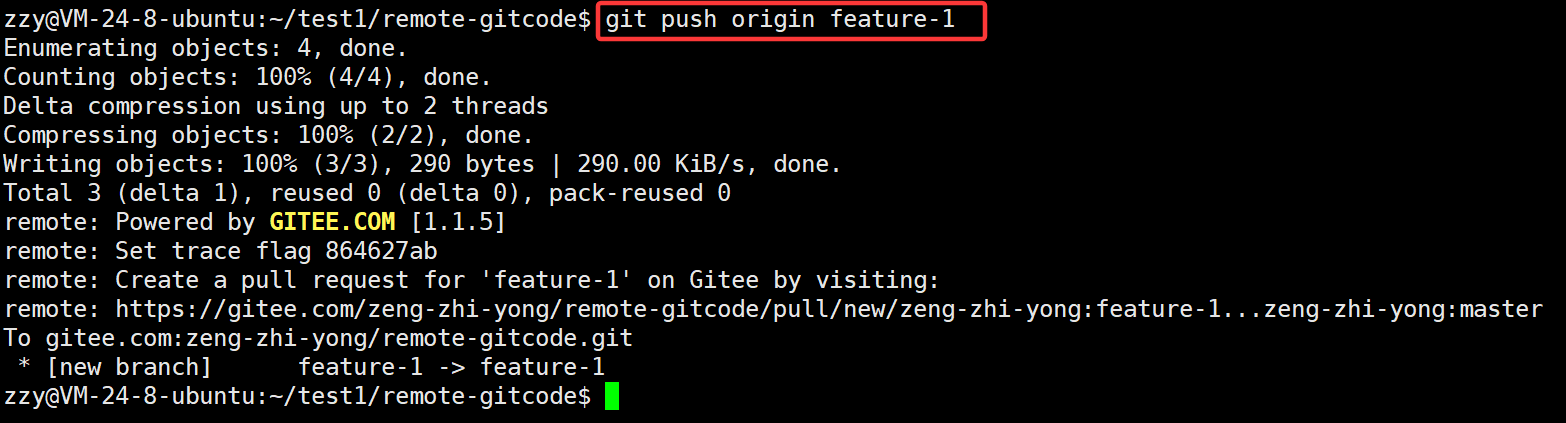
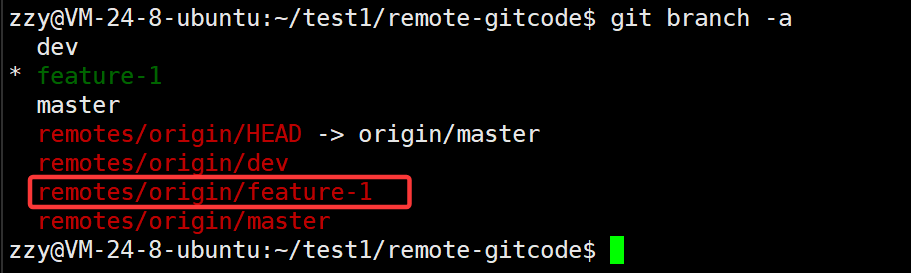
此时再查看分支就可以看到远程多了一个feature-1分支:
接下来完成开发者2的任务,首先开发者2的本地master分支并不一定是最新的,所以需要先git pull一下。
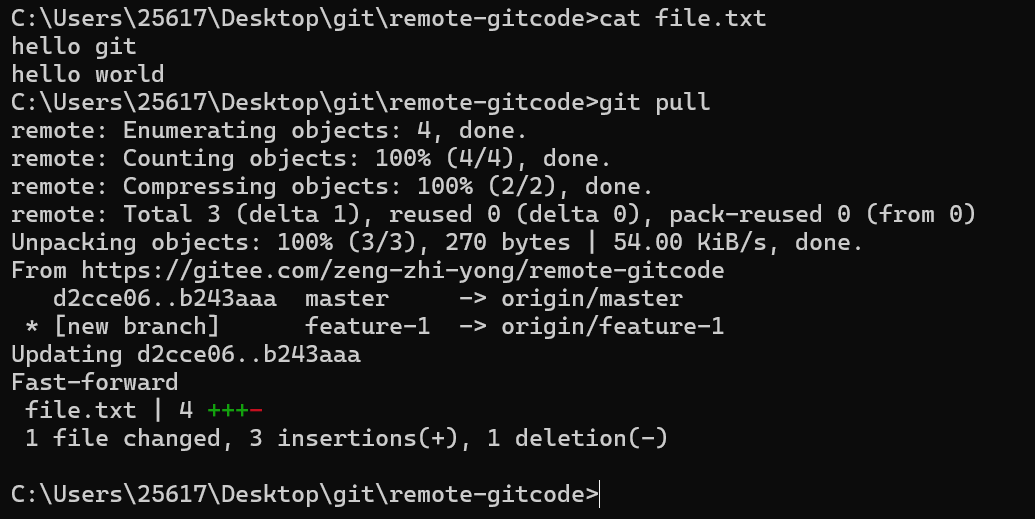
此时再基于master分支去创建本地分支feature-2,就能保证是最新的代码了,然后我们进行开发并提交推送:
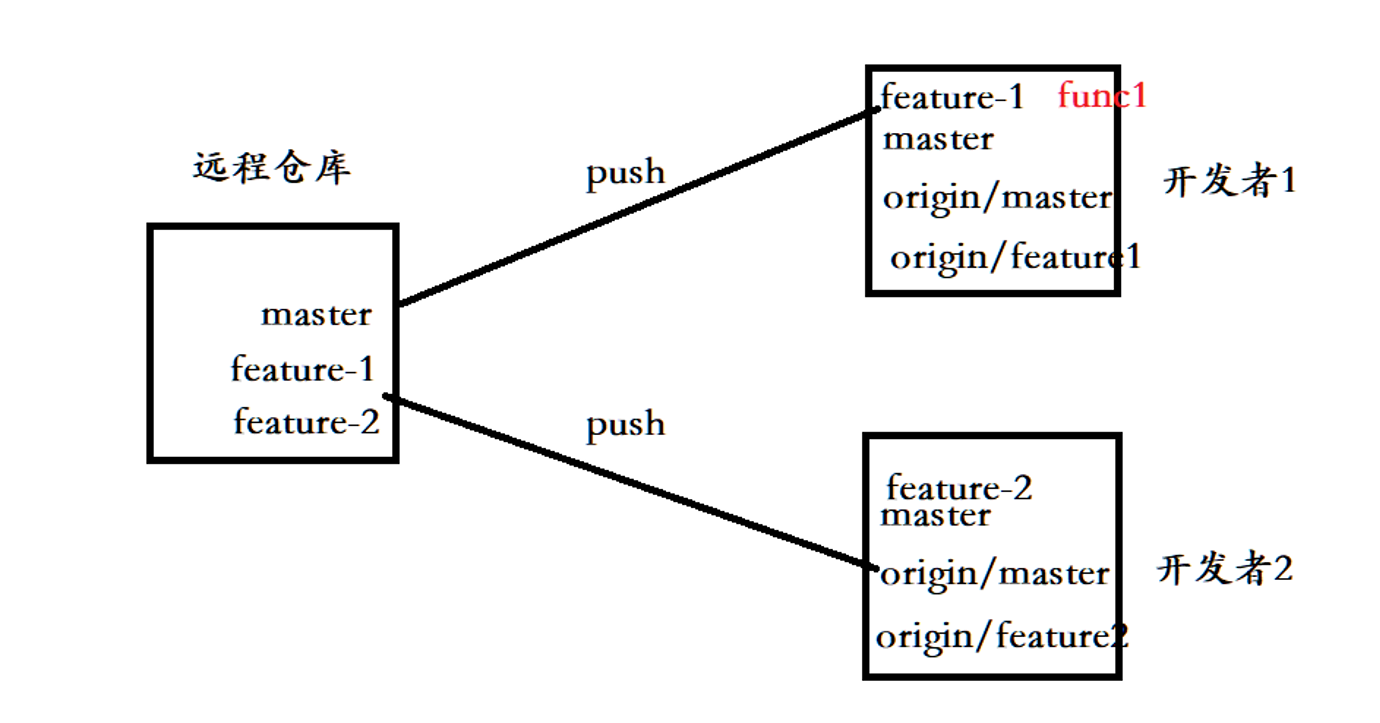
相比于前面一种的多人协作,这种多人协作在push的时候是不会发生冲突的,因为它们是各自一个分支。
但天有不测风云,你的小伙伴突然生病了,但需求还没开发完,需要你帮他继续开发,于是他便把feature-2分支名告诉你了。这时你就需要在自己的机器上切换到feature-2分支帮忙继续开发。
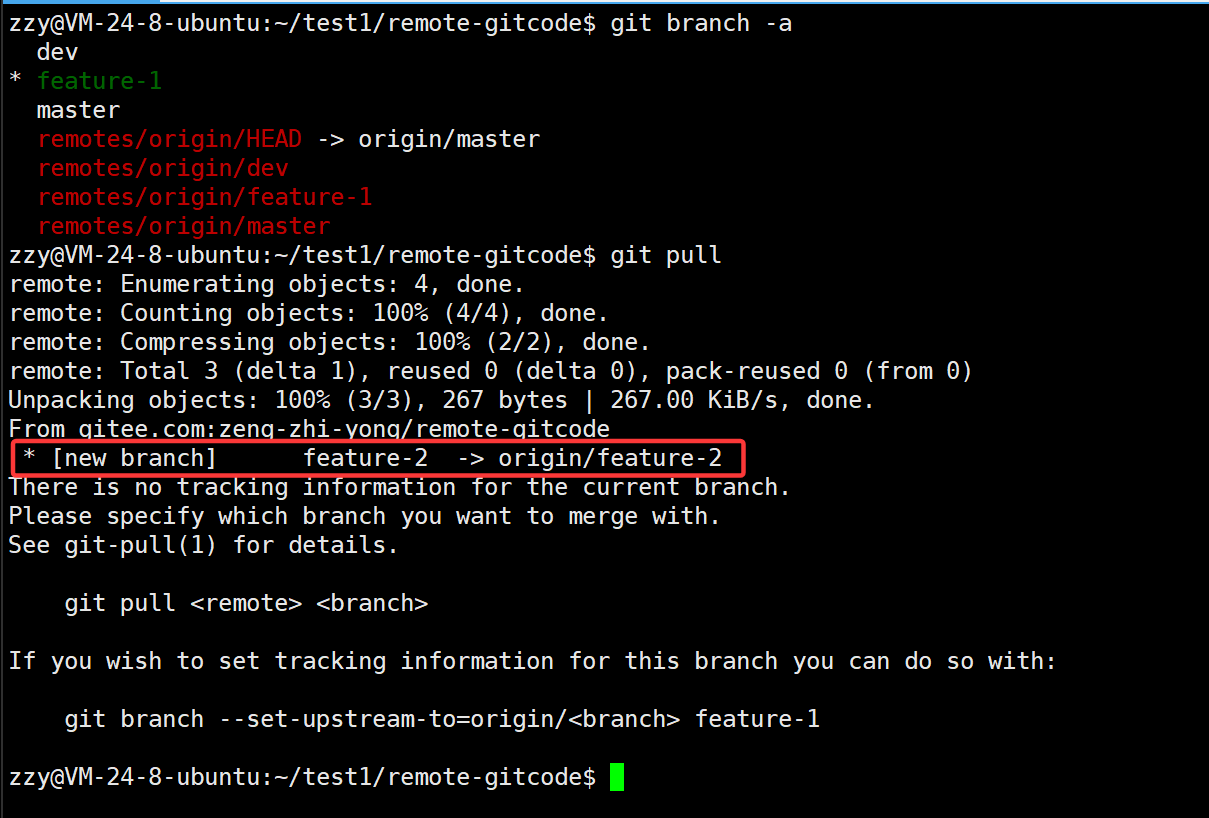
我们先查看分支信息,发现是看不到feature-2的,所以需要先使用git pull拉取。但由于当前是在feature-1分支,当前分支没有和远程仓库的分支建立连接,所以报出需要建立连接的信息。但是我们还是把feature-2分支拉取下来了。
使用git pull有两种场景:
1、拉取分支的内容,此时必须要建立当前分支和远程分支的连接。
2、拉取仓库的内容,此时不需要建立连接,使用git pull可以直接拉取下来。
拉取下来后,但是我们本地是没有feature-2分支的,所以需要创建一个分支并与远程的feature-2分支建立连接:

接着开发者1帮开发者2开发一部分内容,并进行提交推送到远程仓库:
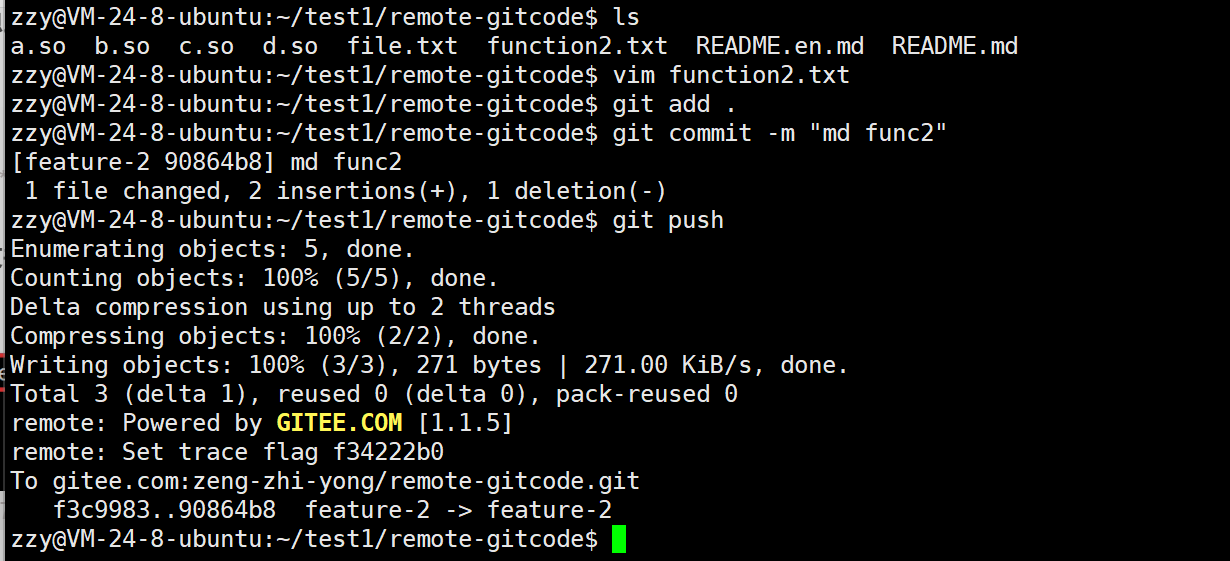
现在开发者2病好了,开发者2需要继续进行开发,但是这时候开发者1已经开发了一部分了,所以需要使用git pull拉取远程仓库的内容。
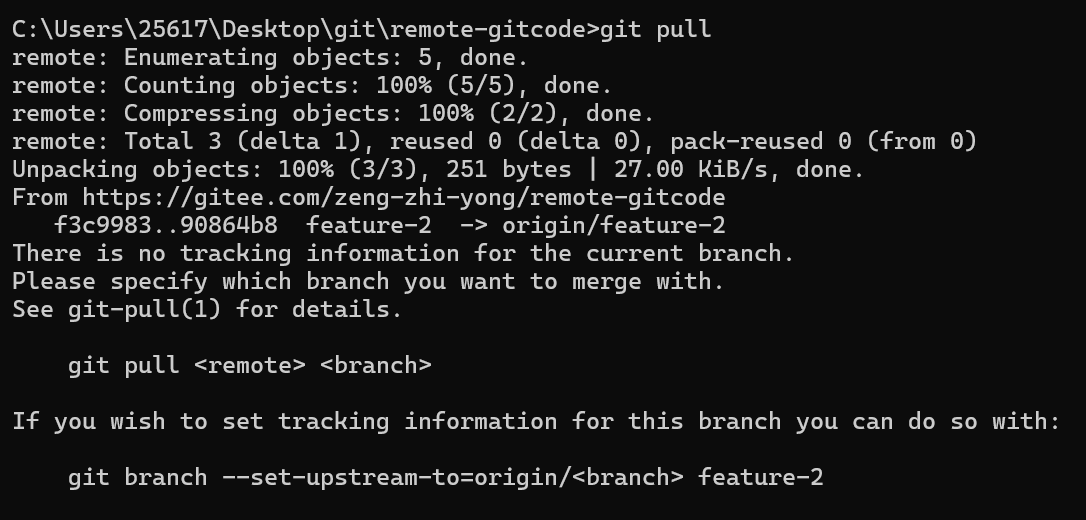
我们直接pull是失败的,因为本地的分支没有和远程仓库的分支建立连接。
所以我们先建立连接,再进行pull操作,当然不建立连接也可以,pull的时候指定要pull哪个分支即可:
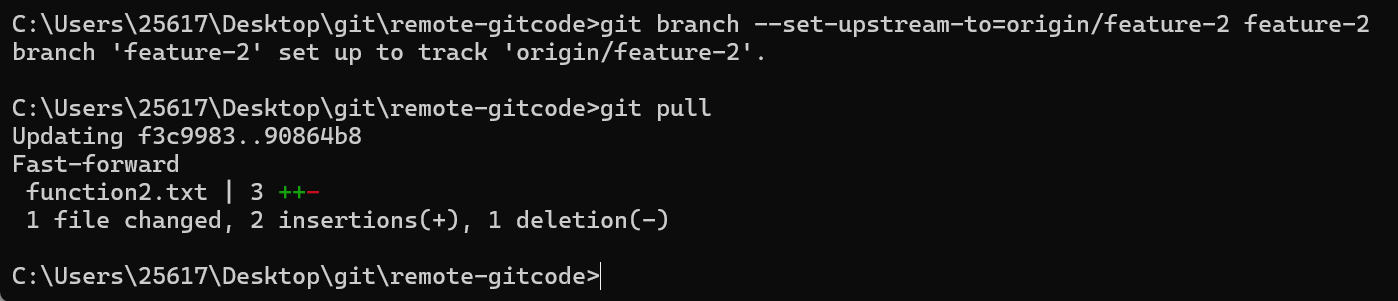
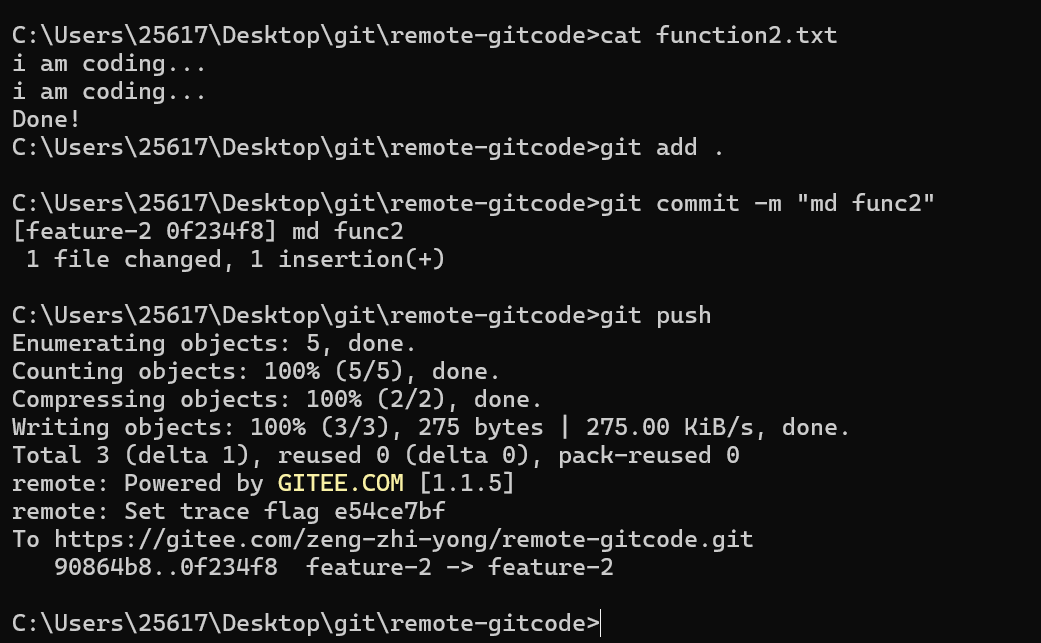
此时开发者2结束最终开发内容,然后提交并推送:
现在我们需要将feature-1和feature-2分支合并到master分支中,我们采用发起pull request的方式来实现。
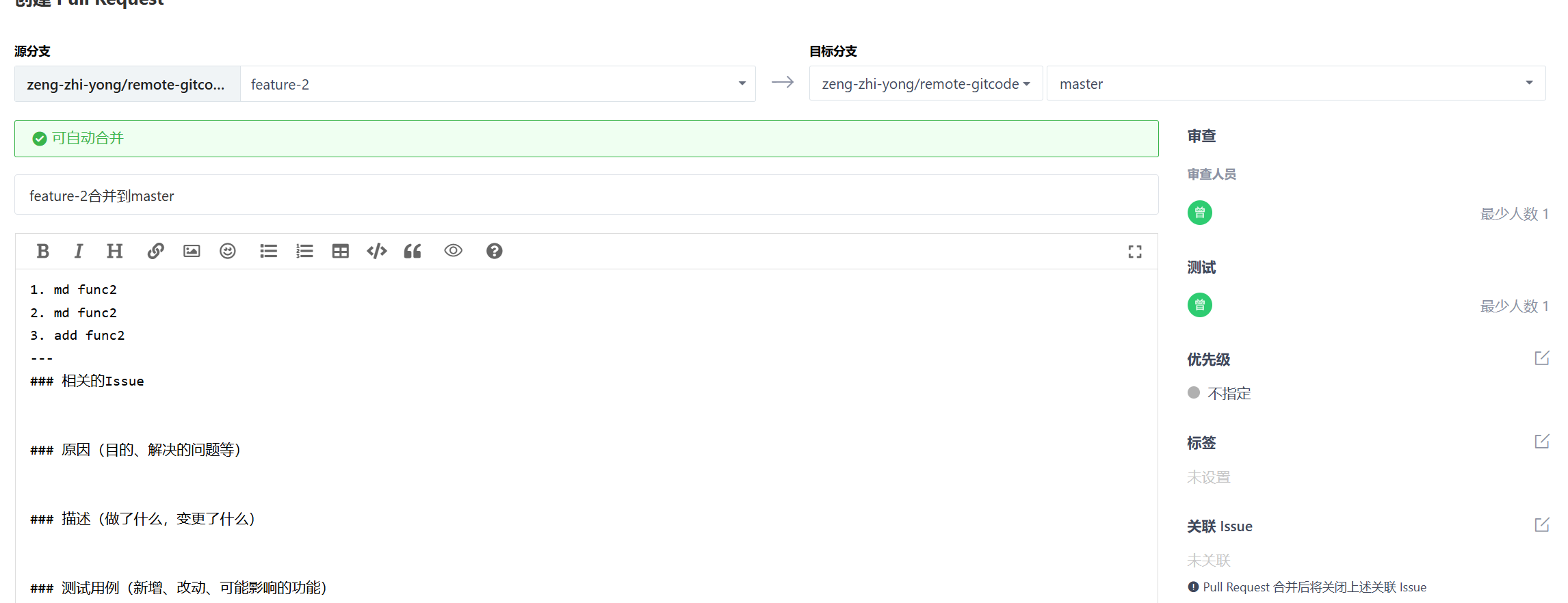
首先创建一个pull request。
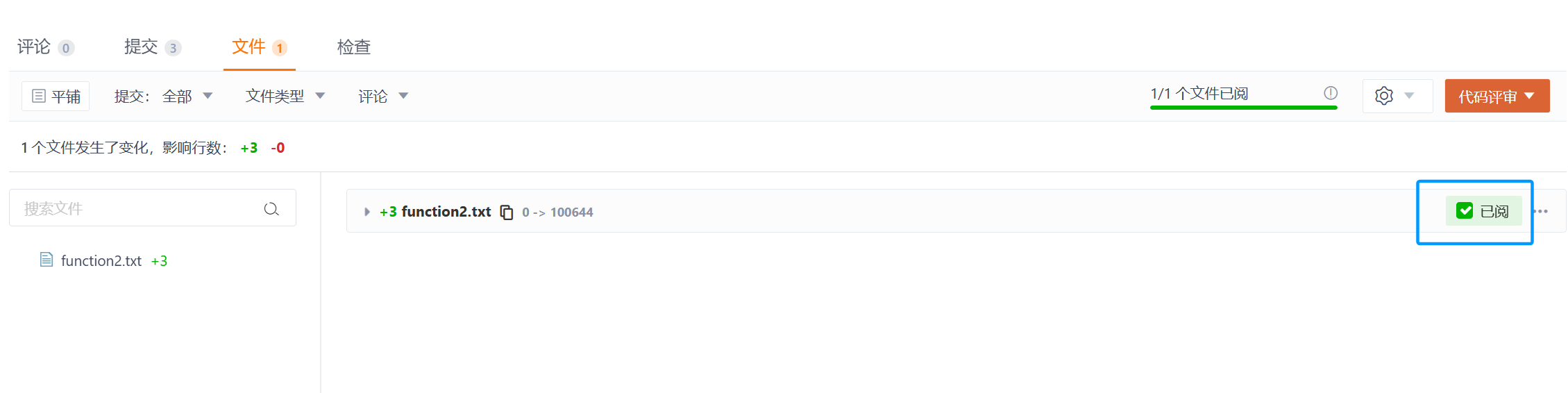
然后进入pull request模块,点击我们刚才创建的PR申请单,下面可以查看代码提交等信息,然后可以选择已阅:
然后可以点击代码评审
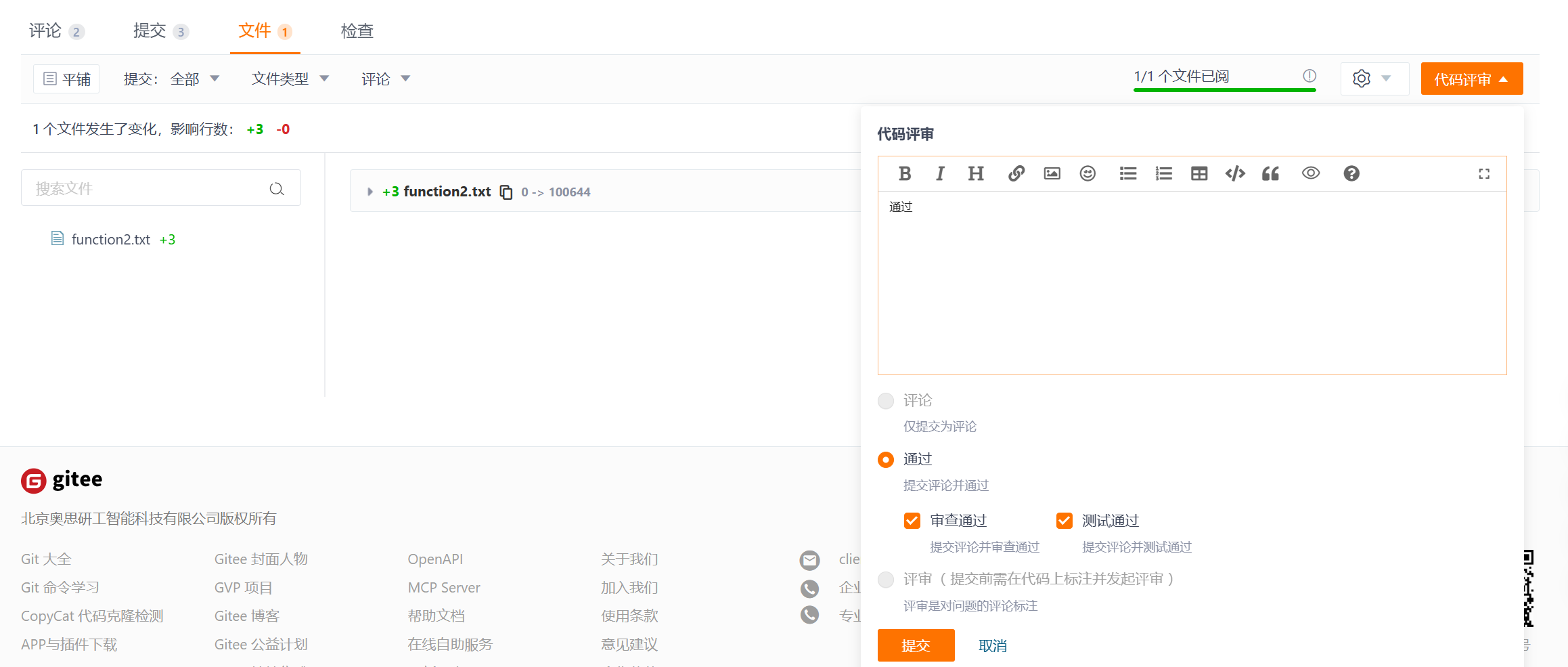
选择审查通过、测试通过并提交。
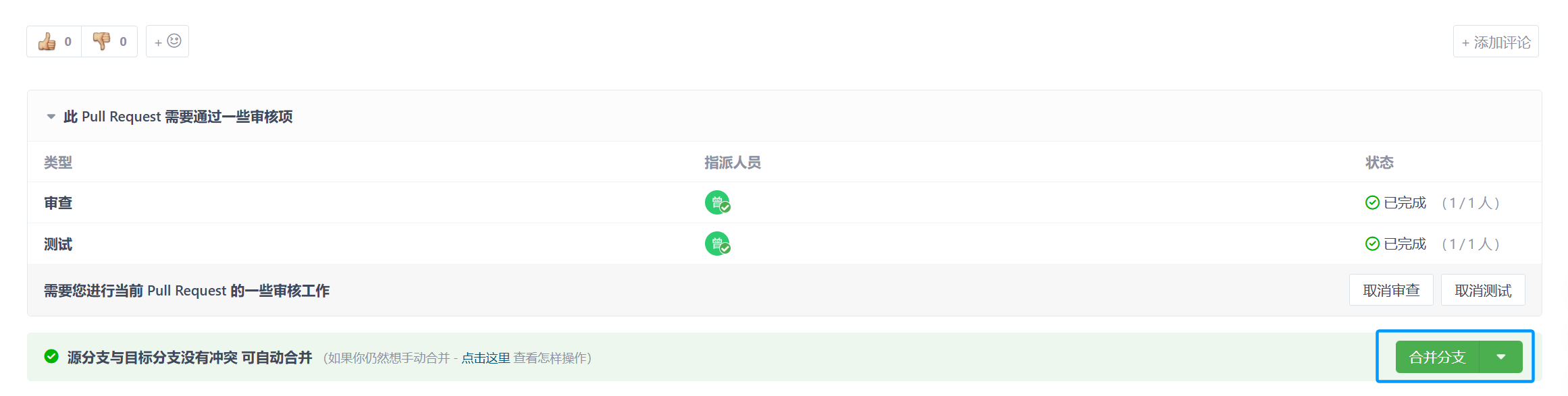
然后就可以合并分支了:
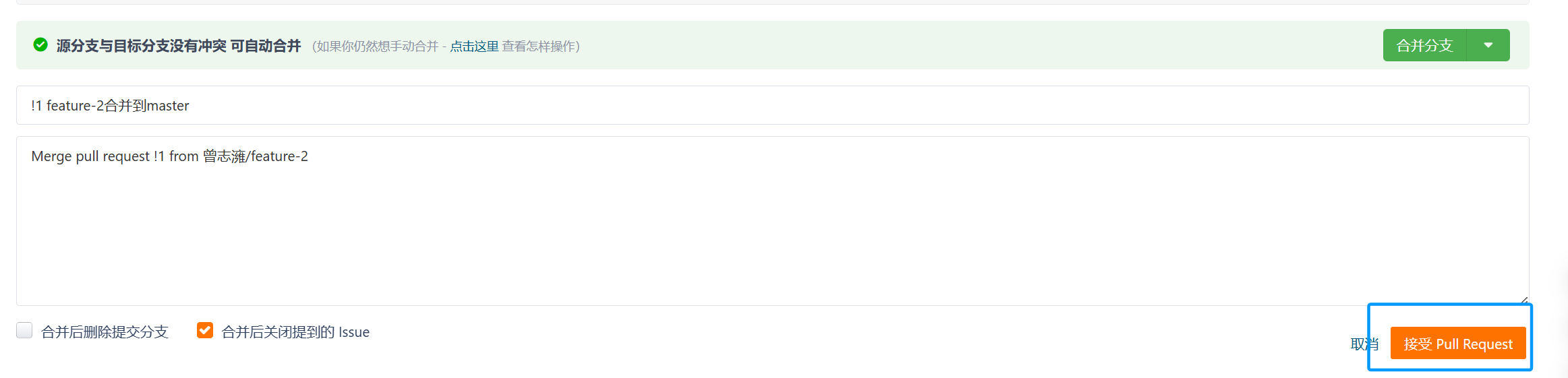
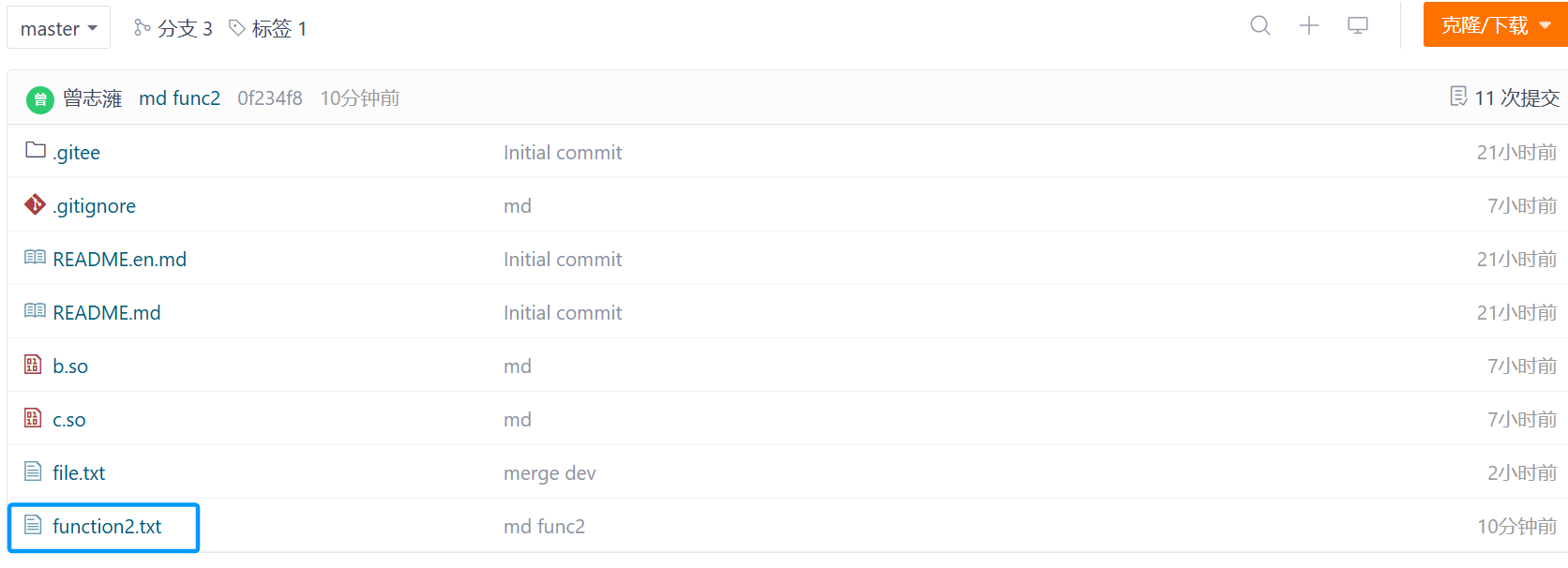
此时再看master分支,就可以看到function2.txt文件了。
接着还要合并feature-1分支,这时候当然可以直接再提交一个PR申请单,但是可能在合并的时候发生冲突。而如果直接合并到master,然后发生了冲突,我们需要手动解决,这时候可能解决会出更大的问题,因此不能这么做。需要先让feature-1先合并master分支,如果出现冲突就在本地feature-1分支中解决,这样就不会影响master。最后再让master分支合并feature-1分支。(当然对于master合并feature-2分支的时候也是如此)
首先要进行feature-1合并master分支,但是此时master并不一定是最新的,所以需要先切到master从远程仓库拉取一下:
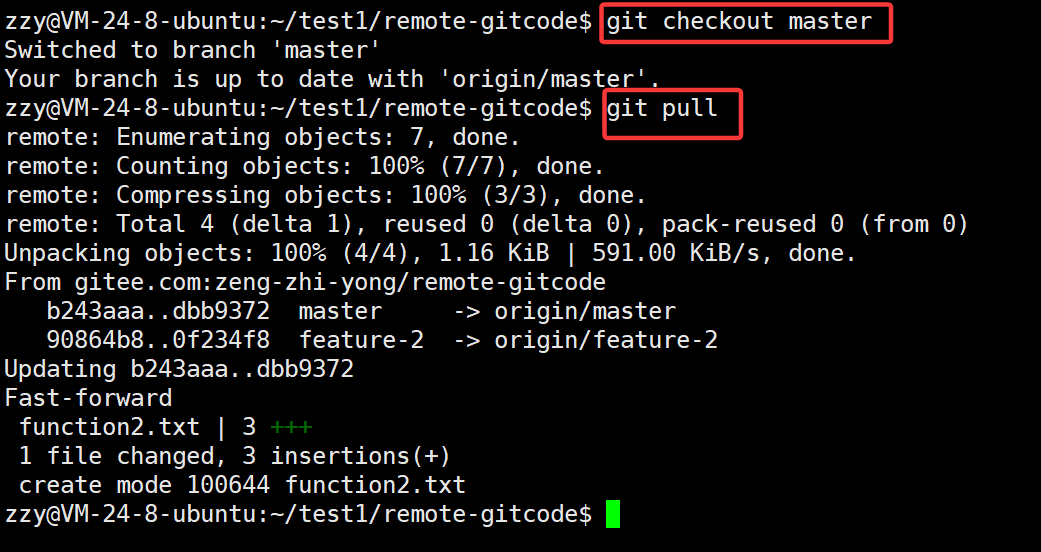
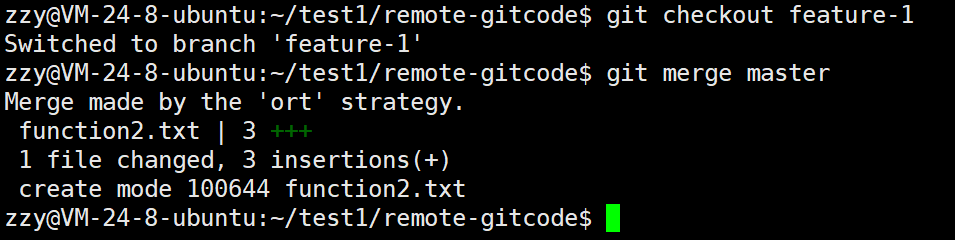
接着切回feature-1分支合并master:

此时如果没有冲突会出现上面的页面,我们直接退出即可。
由于此时没有建立连接,所以直接git push失败,我们使用长命令来实现:
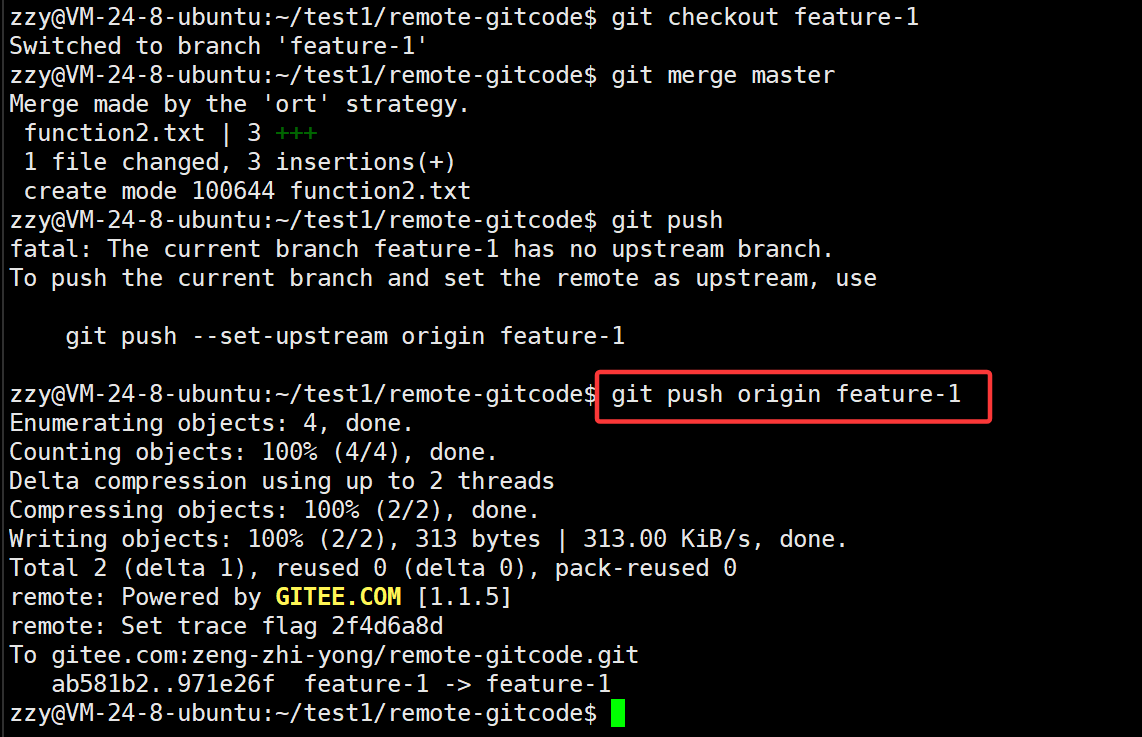
接下来同feature-2,创建一个PR,然后通过合并。合并后feature-1和feature-2分支就可以删掉了。
6.5、解决本地打印已被删除分支的方法
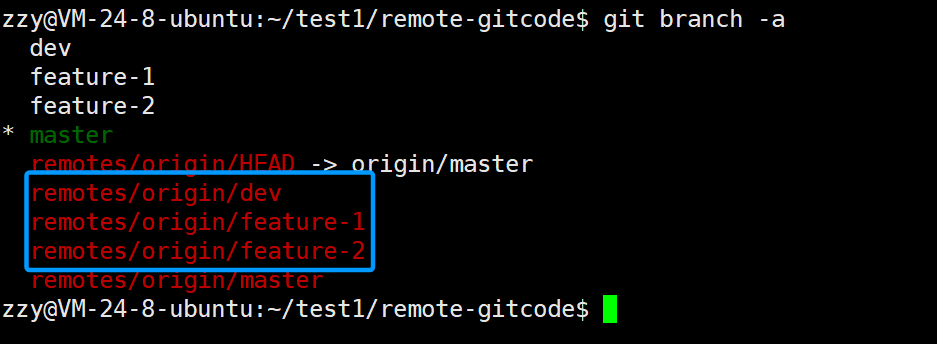
我们此时远程已经只剩下master分支了,但是已被删除的分支在本地仓库打印的时候还是存在。
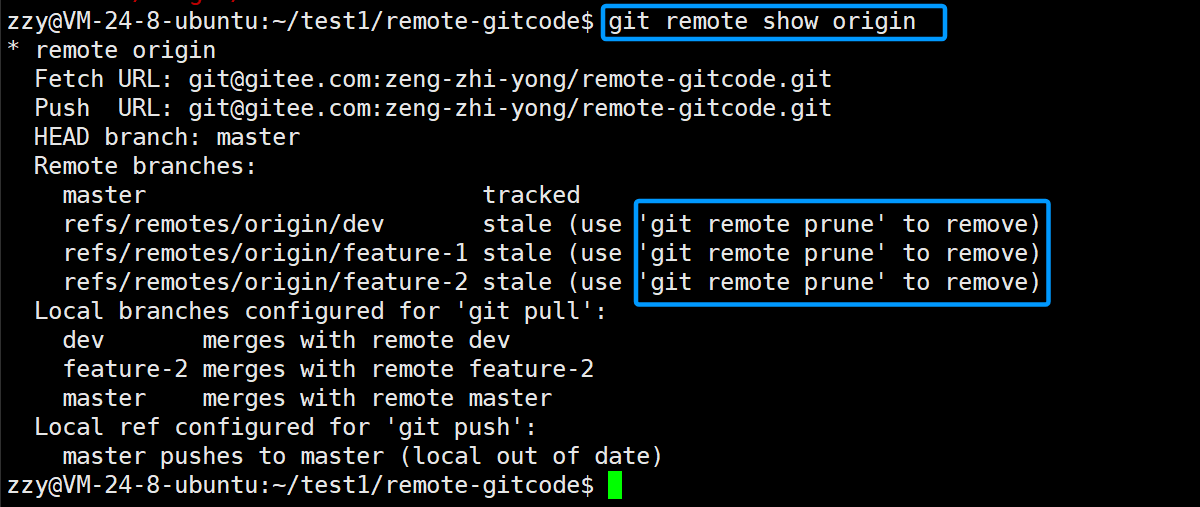
我们可以使用git remove show origin查看远程分支的情况:
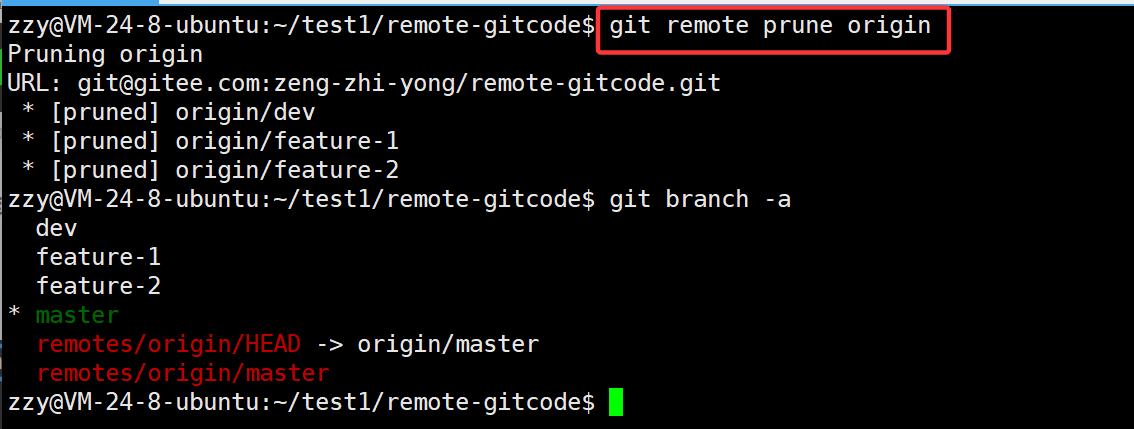
然后我们可以使用git remote prune origin修剪:
7、企业级开发模型
7.1、企业级开发流程
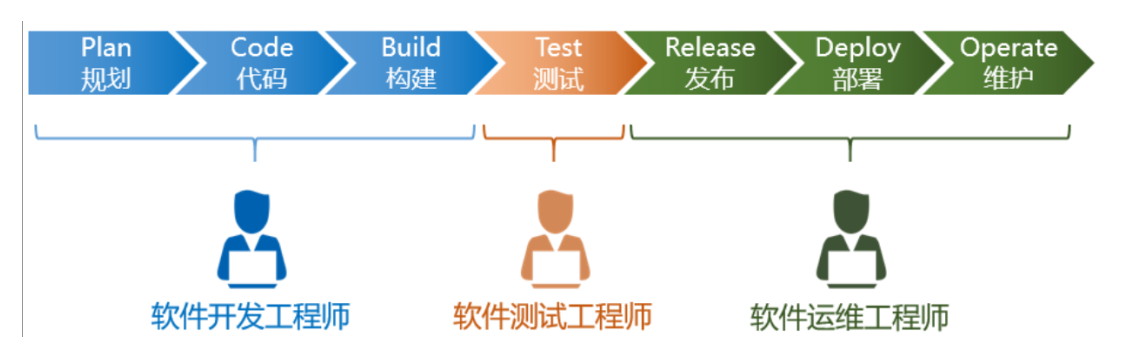
我们知道,一个软件从零开始到最终交付,大概包括以下几个阶段:规划、编码、构建、测试、发布、部署和维护。
最初,程序比较简单,工作量不大,程序员一个人可以完成所有阶段的工作。但随着软件产业的日益发展壮大,软件的规模也在逐渐变得庞大。软件的复杂度不断攀升,一个人已经hold不住了,就开始出现了精细化分工。如下图所示:
但在传统的IT组织下,开发团队(Dev)和运维团队(Ops)之间诉求不同:
• 开发团队(尤其是敏捷团队)追求变化
• 运维团队追求稳定
双方往往存在利益的冲突。比如,精益和敏捷的团队把持续交付作为目标,而运维团队则为了线上的稳定而强调变更控制。部门墙由此建立起来,这当然不利于IT价值的最大化。
为了弥合开发和运维之间的鸿沟,需要在文化、工具和实践方面的系列变革⸺DevOps正式登上舞台。
DevOps(Development和Operations的组合词)是⼀种重视软件开发⼈员(Dev)和IT运维技术人员(Ops)之间沟通合作的文化、运动或惯例。透过自动化软件交付和架构变更的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。在DevOps的软件开发过程包含计划、编码、构建、测试、预发布、发布、运维、监控,由此可见DevOps的强大。 讲了这么多,这个故事到底和我们课程的主题Git有什么关系呢?
举一个很简单的例子就能说明这个问题。一个软件的迭代,在我们开发人员看来,说白了就是对代码进行迭代,那么就需要对代码进行管理。如何管理我们的代码呢,那不就是 Git(分布式版本控制系统) !所以 Git 对于我们开发人员来说其重要性就不言而喻了。
7.2、系统开发环境
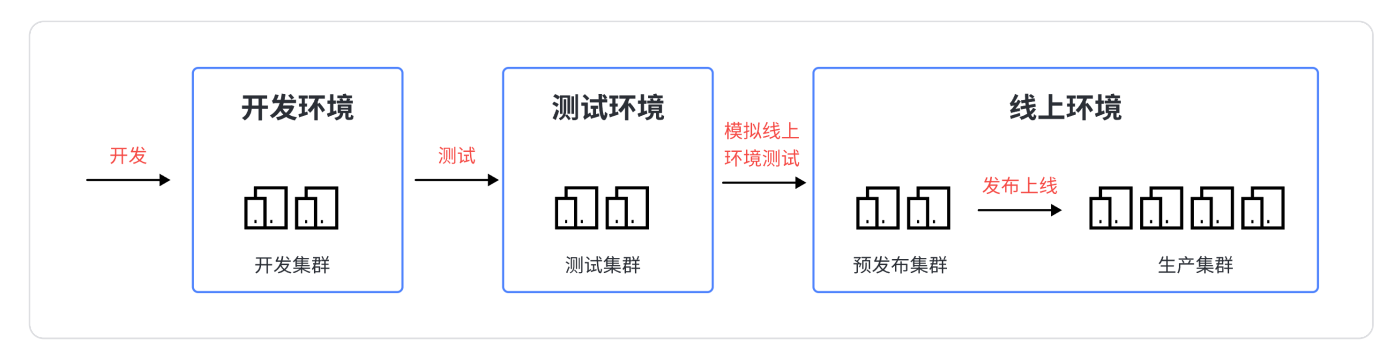
1、开发环境:开发环境是程序猿们专门用于日常开发的服务器。为了开发调试方便,一般打开全部错误报告和测试⼯具,是最基础的环境。
2、测试环境:一个程序在测试环境工作不正常,那么肯定不能把它发布到生产机上。该环境是开发环境到生产环境的过渡环境。
3、预发布环境:该环境是为避免因测试环境和线上环境的差异等带来的缺陷漏测而设立的一套环境。其配置等基本和生产环境一致,目的是能让我们发正式环境时更有把握!所以预发布环境是你的产品质量最后一道防线,因为下一步你的项目就要上线了。要注意预发布环境服务器不在线上集成服务器范围之内,为单独的一些机器。
4、生产环境:是指正式提供对外服务的线上环境,例如我们⽬前在移动端或PC端能访问到的APP都是生产环境。
这几个环境也可以说是系统开发的三个重要阶段:开发->测试->上线。一张图总结:
7.3、Git分支设计模型
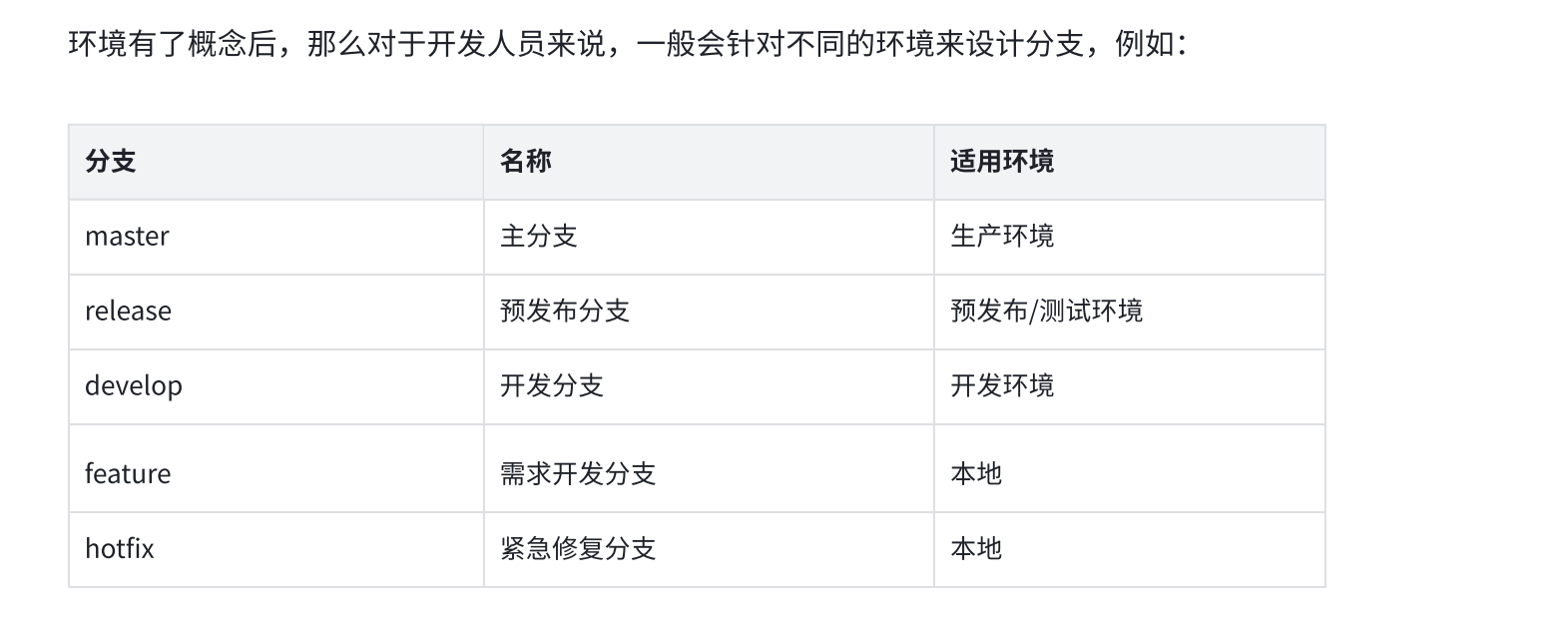
master分支:
1、master为主分支,该分支为只读且唯一分支。用于部署到正式发布环境,一般由合并release分支得到。
2、主分支作为稳定的唯一代码库,任何情况下不允许直接在master分支上修改代码。
3、产品的功能全部实现后,最终在master分支对外发布,另外所有在master分支的推送应该打标签(tag)做记录,方便追溯。
4、master分支不可删除。
feature分支:
1、feature分支通常为新功能或新特性开发分支,以develop分支为基础创建feature分支。
2、命名以feature/开头,建议的命名规则:feature/user_createtime_feature 。
3、新特性或新功能开发完成后,开发人员需合到develop分支。
4、一旦该需求发布上线,便将其删除。
develop分支:
1、develop为开发分支,基于master分支创建的只读且唯一分支,始终保持最新完成以及bug修复后的代码。可部署到开发环境对应集群。
2、可根据需求大小程度确定是由feature分支合并,还是直接在上面开发(非常不建议)。
release分支:
1、release 为预发布分支,基于本次上线所有的feature分支合并到develop分支之后,基于develop分支创建。可以部署到测试或预发布集群。
2、命名以release/开头,建议的命名规则:release/version_publishtime。
3、release分支主要用于提交给测试人员进行功能测试。发布提测阶段,会以release分支代码为基准进行提测。
4、如果在release分支测试出问题,需要回归验证develop分支看否存在此问题。
5、release分支属于临时分支,产品上线后可选删除。
hotfix分支:
1、hotfix分支为线上bug修复分支或叫补丁分支,主要用于对线上的版本进行bug修复。当线上出现紧急问题需要马上修复时,需要基于master分支创建hotfix分支。
2、命名以hotfix/开头,建议的命名规则:hotfix/user_createtime_hotfix
3、当问题修复完成后,需要合并到master分支和develop分支并推送远程。一旦修复上线,便将其删除。
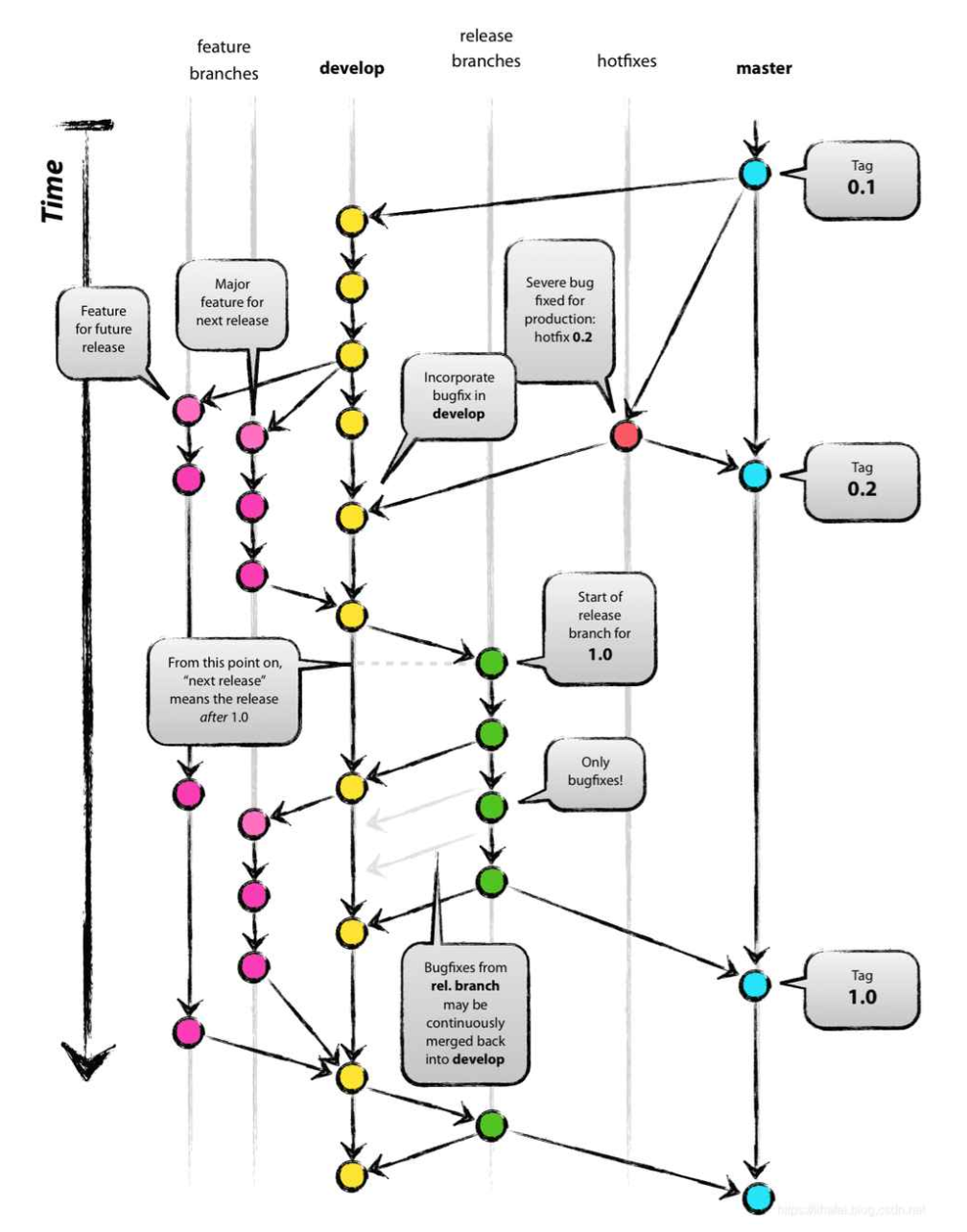
以上是企业级常用的一种Git分支设计规范:Git Flow模型。
7.4、企业级项目管理准备工作
我们前面讲过DevOps,现在我们就需要使用DevOps,而gitee正好是有的,所以我们直接使用gitee了。
Gitee企业版免费版

我们选择项目。然后点击新建项目,选择敏捷项目然后下一步。
输入项目名称和项目编号,点击新建。
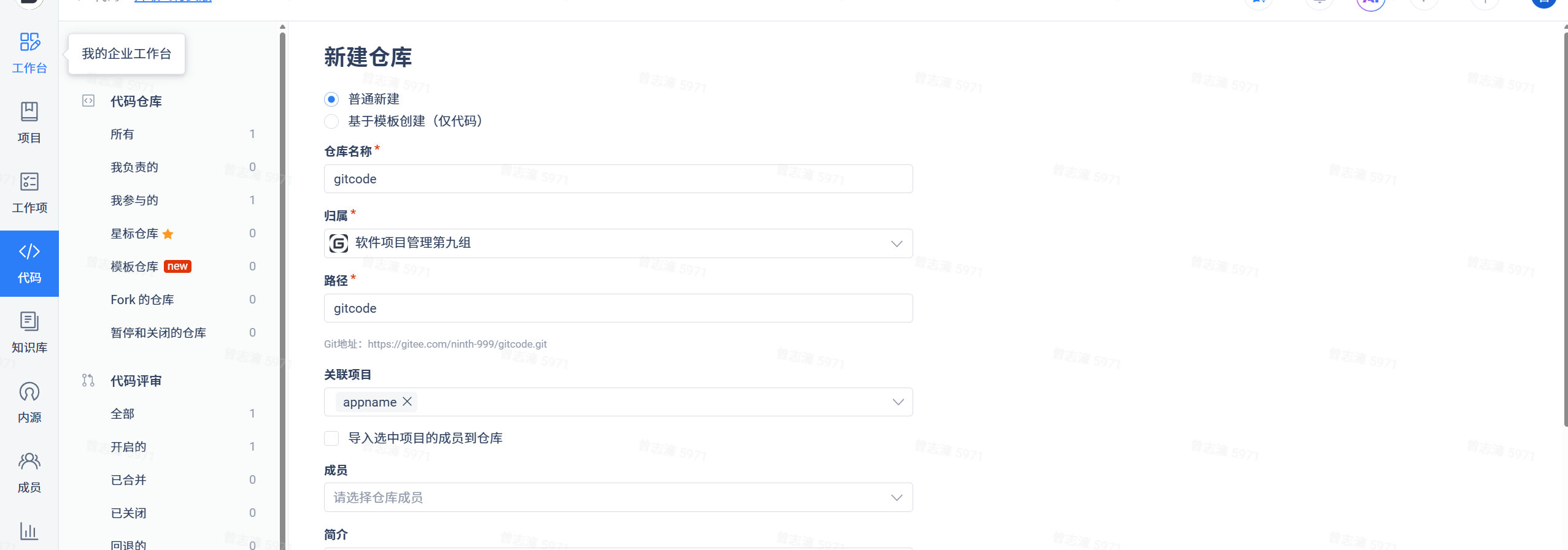
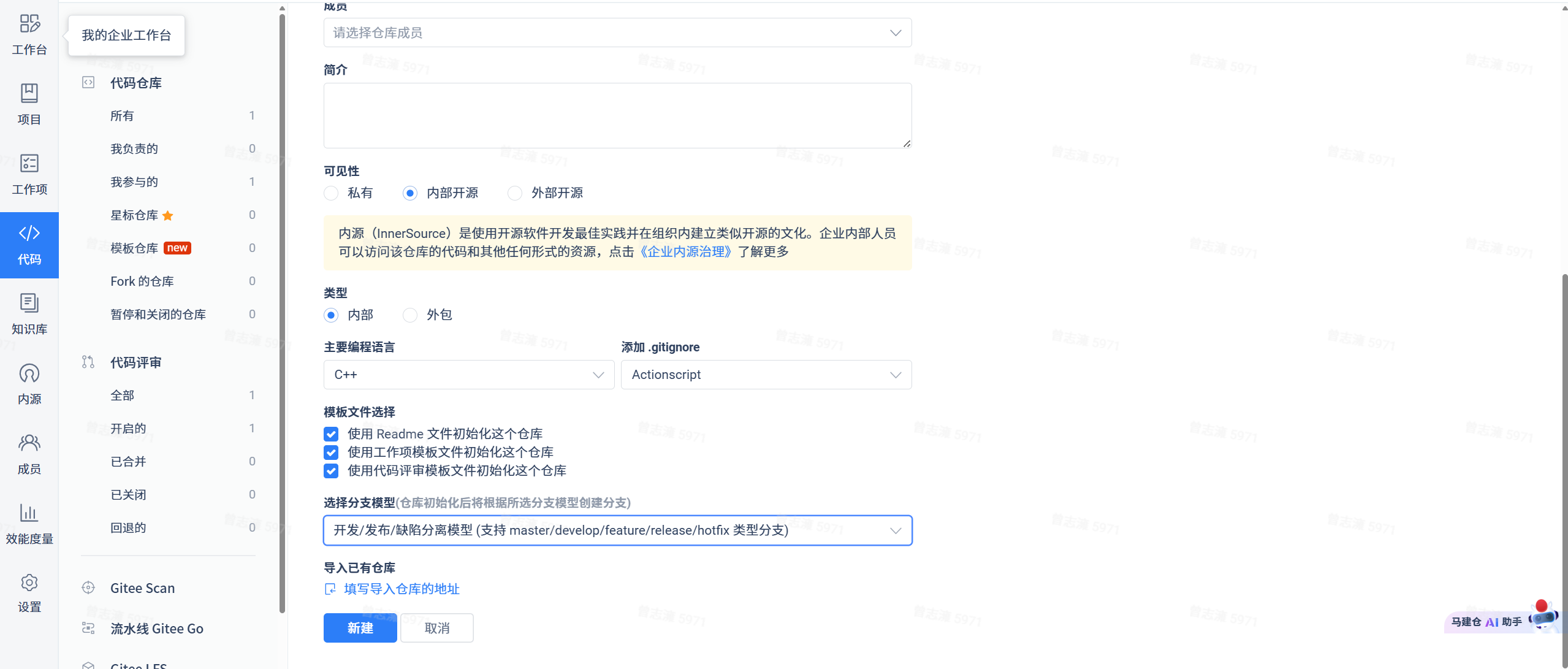
进入代码模块,选择新建一个仓库,填充相应信息,下方选择分支模型。
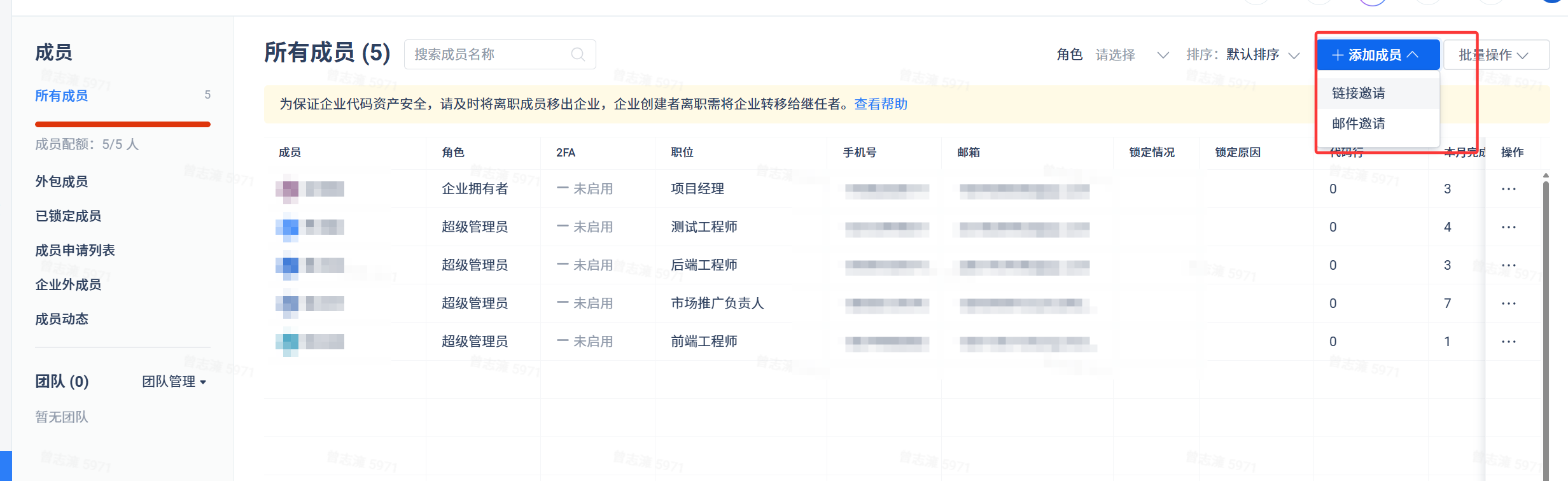
刚开始是没有成员的,我们可以点击成员模块进行添加成员。添加企业成员后就可以给项目和仓库添加成员了。
7.5、企业级项目管理开发场景实操
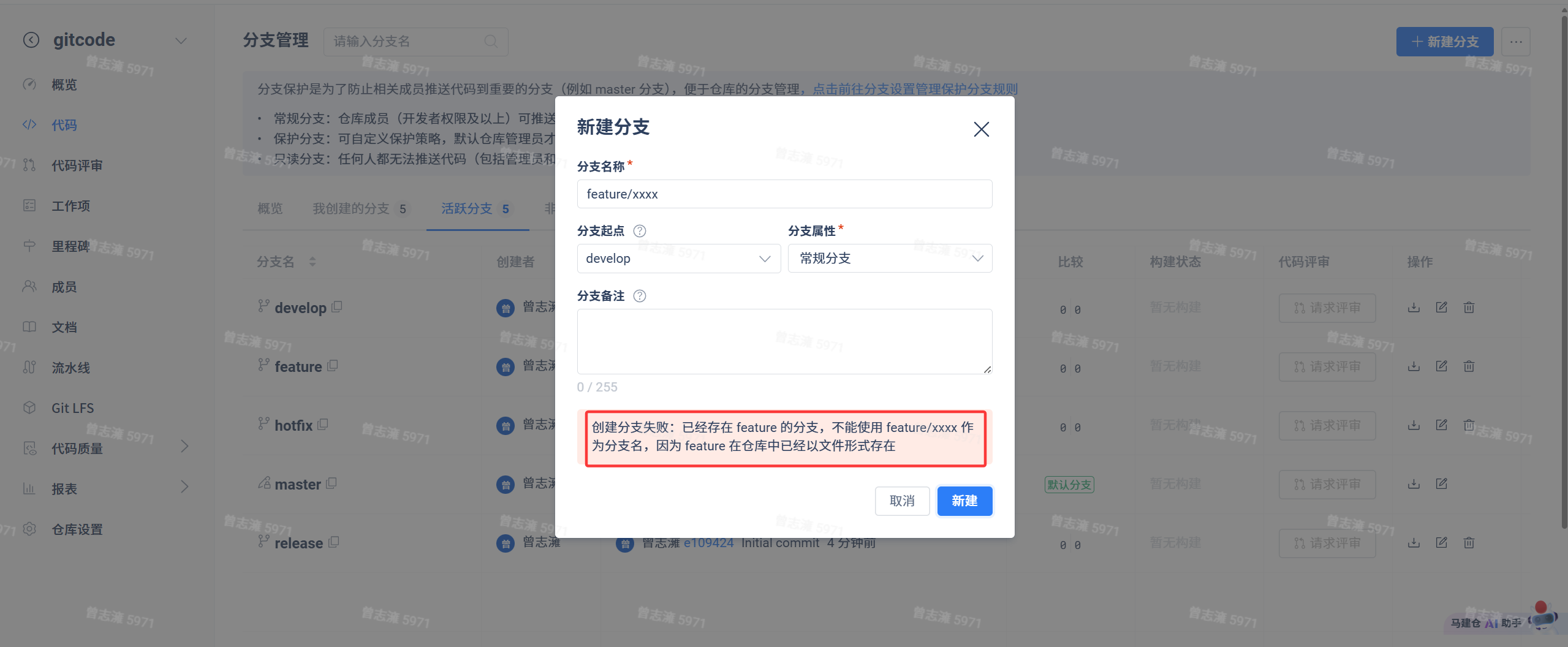
现在我们要开发一个新功能,所以我们需要创建一个feature/xxx分支,我们进入代码仓库中,选择分支管理,右上角有个新建分支,我们新建一个feature/xxxx,但是点击新建的时候发现创建分支失败了。这是因为仓库中已经存在了feature分支。
这是因为之前在创建仓库的时候我们选择了创建五个分支模型,那么这样就不能再创建分支了。但实际上我们期望的是master和develop分支是唯一的,剩下的三个分支我们要自己创建。因此我们删掉仓库重新创建:
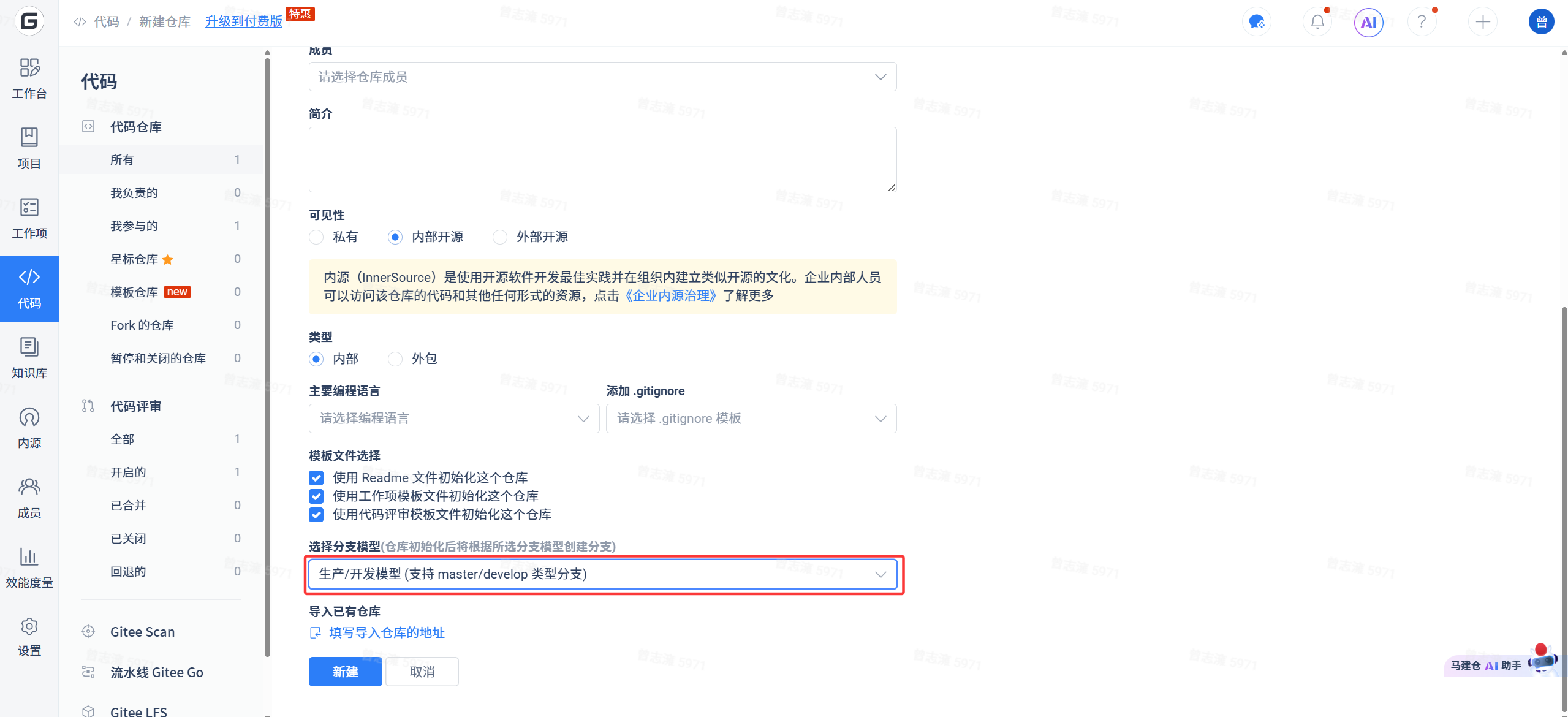
此时我们选择生产开发模型。
接着我们再创建分支,假设为支付功能的设计:
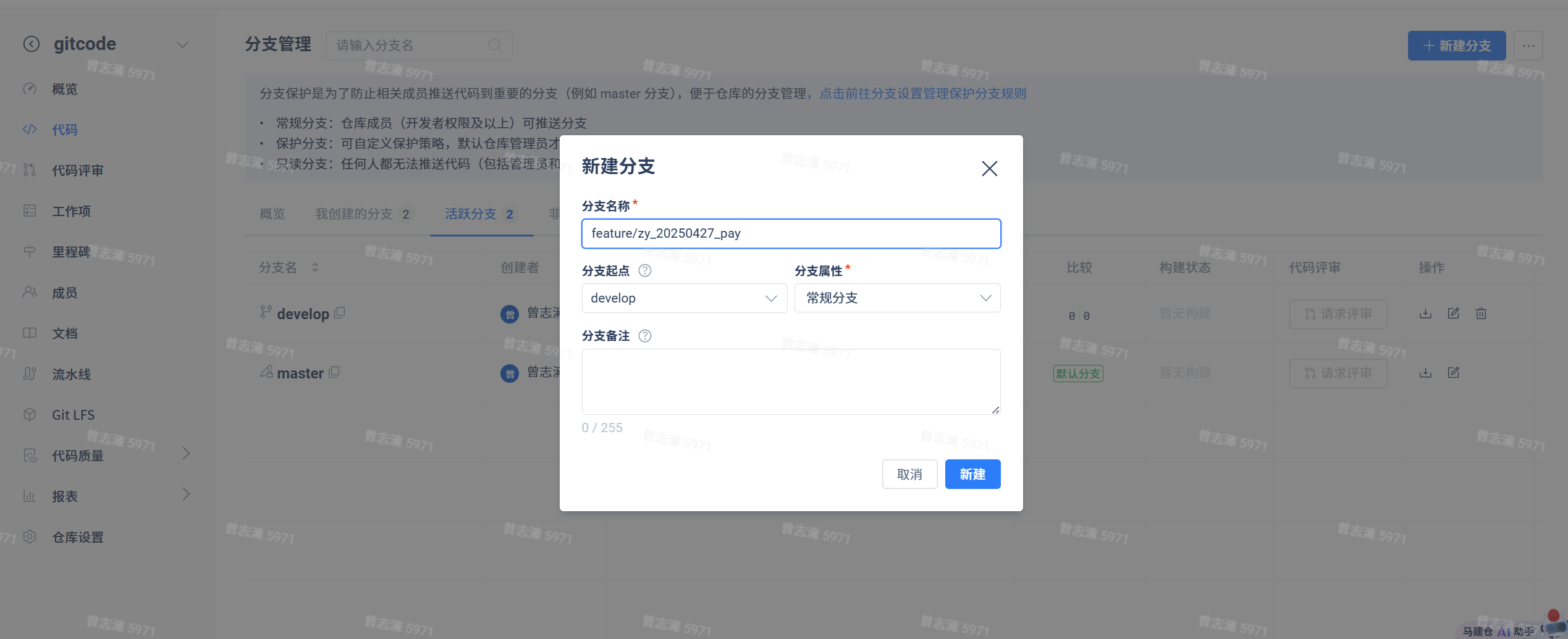
然后我们模拟一个开发过程,将仓库克隆到本地,然后开发后提交并push到远端。
首先创建一个本地分支同时与远端的分支关联:
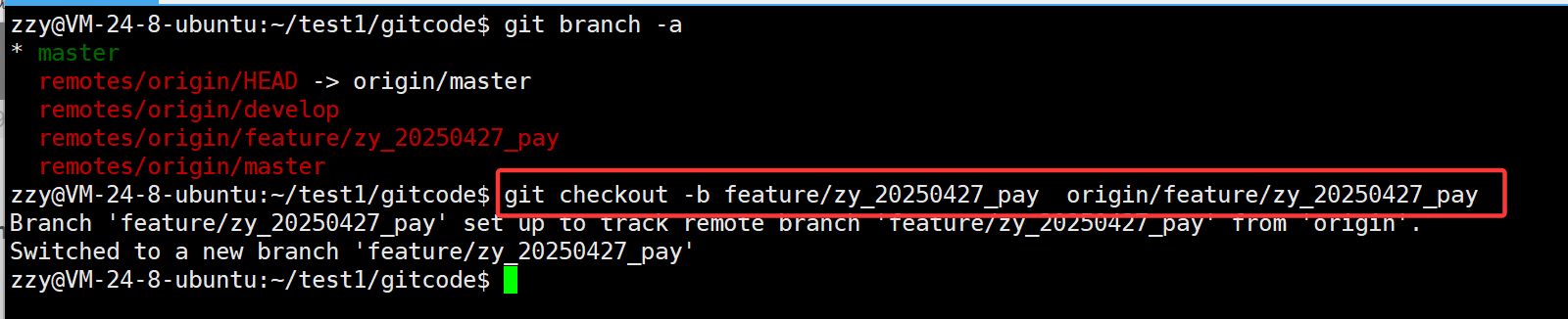
接着完成开发然后提交并推送:
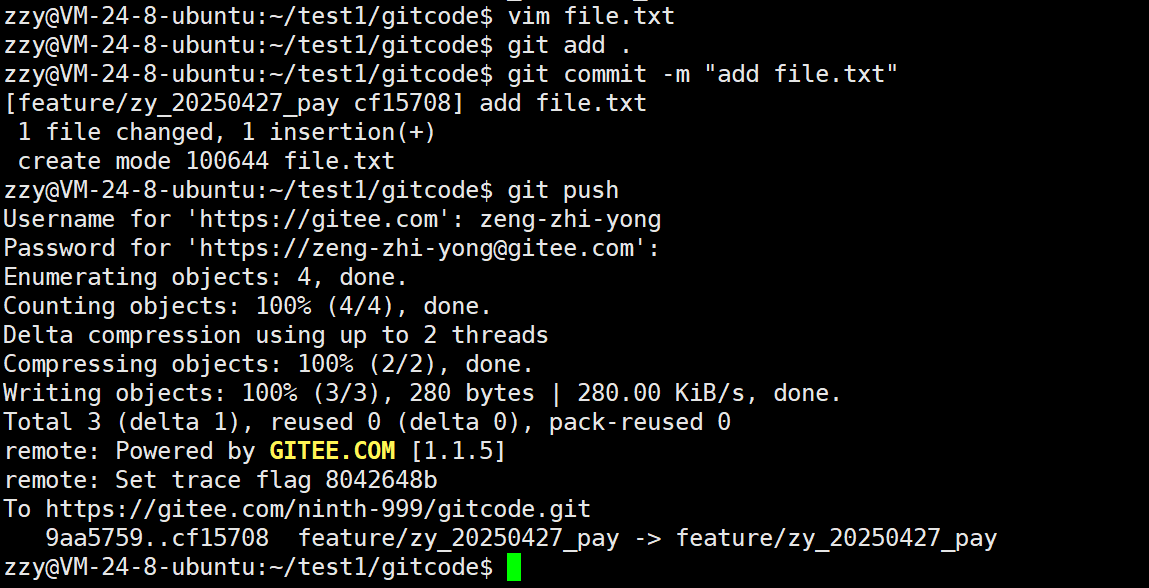

此时再看远程仓库已经多了一个我们开发的文件。
接下来我们需要将feature分支合并到develog分支:
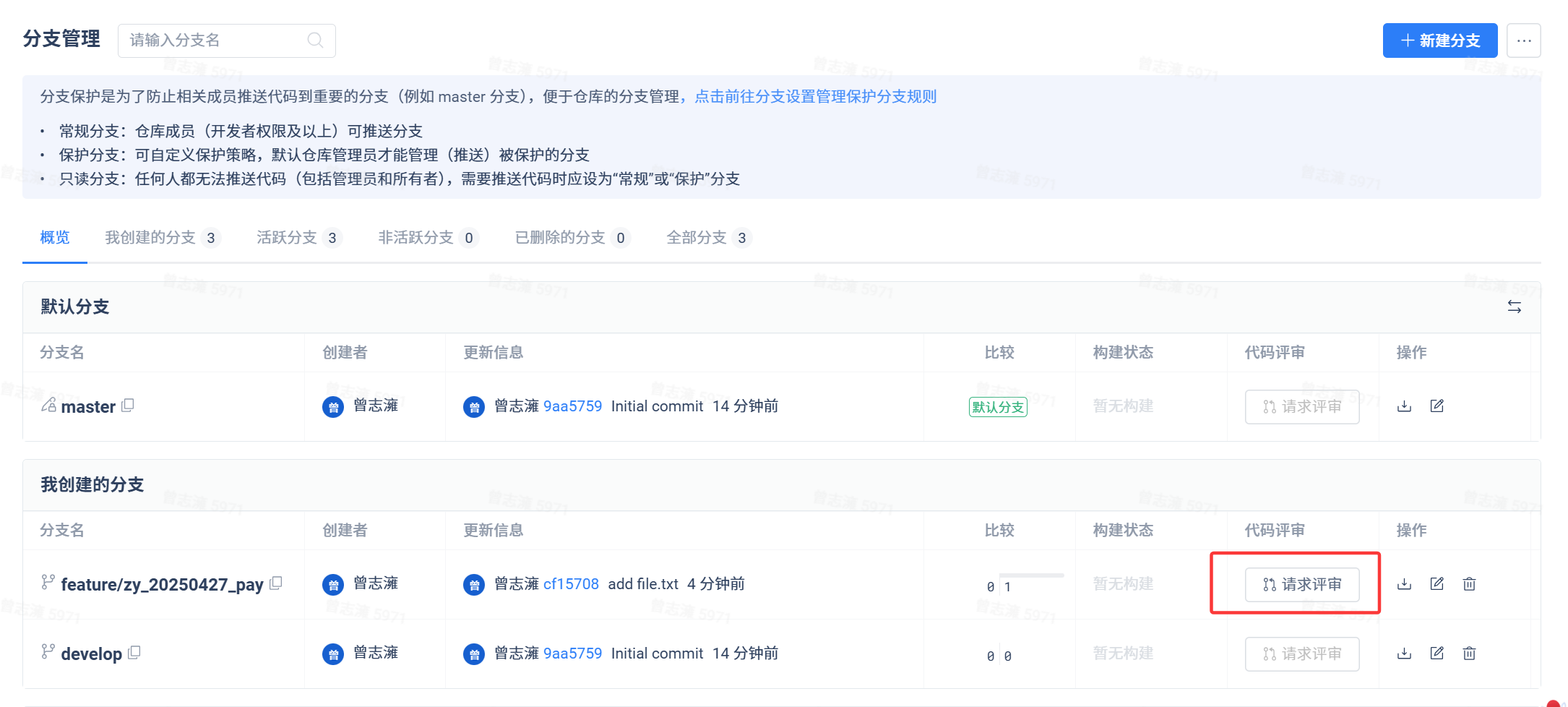
我们进入分支管理中找到feature分支,点击请求评审。
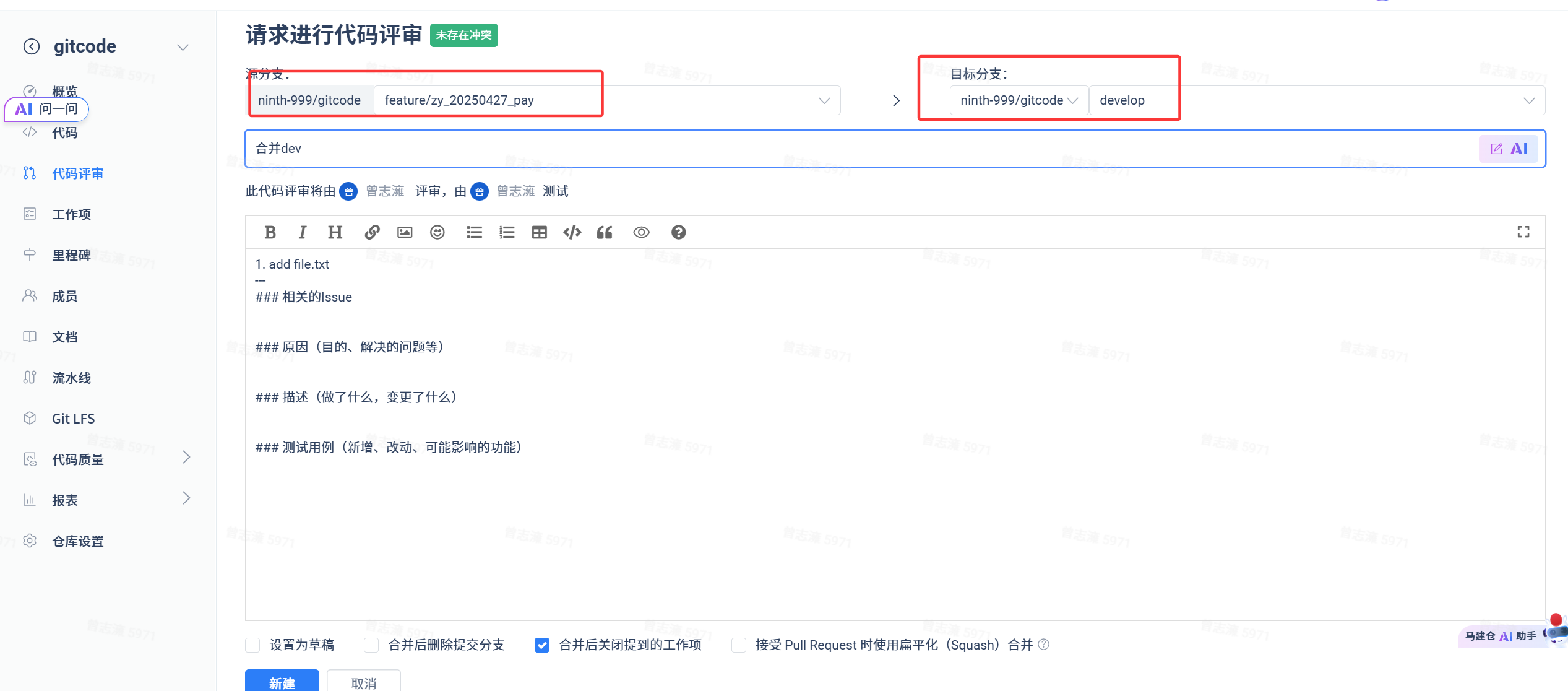
选择好请求分支和目标分支,填写相关信息,然后新建。
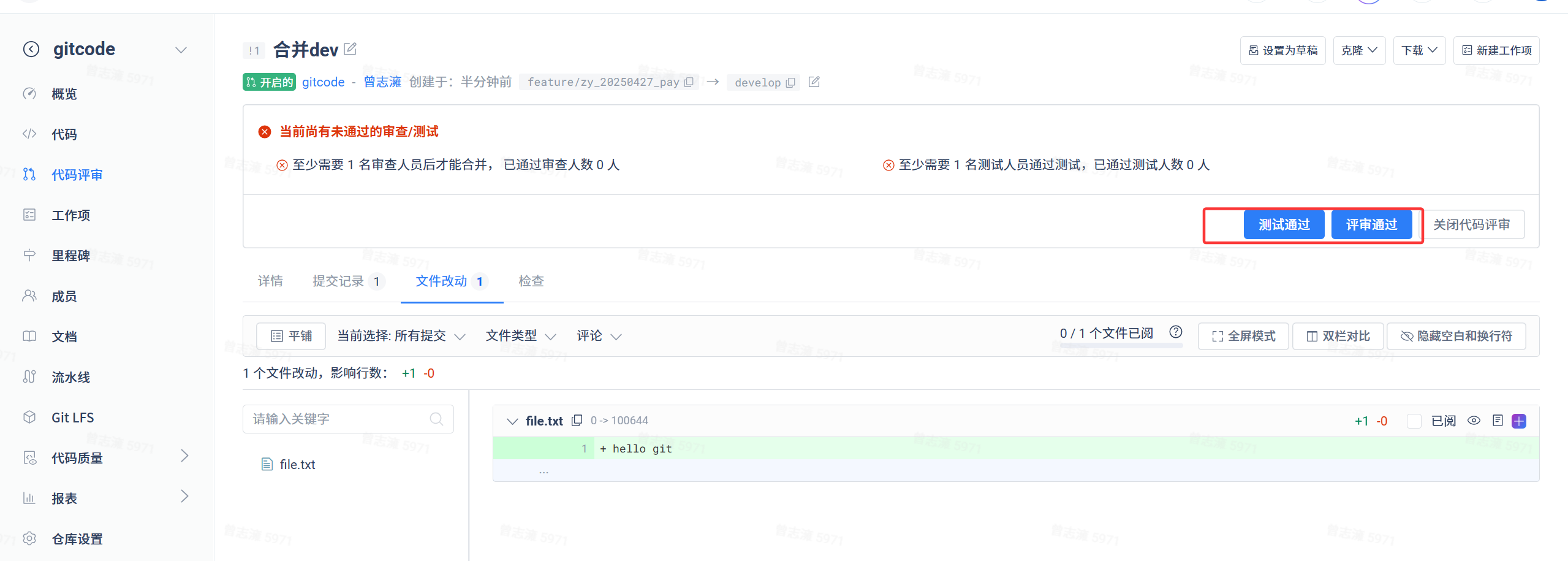
接着到达审查人的页面,审查人可以查看详情、提交记录、文件改动等。审查过后可以点击测试通过、评审通过。
然后点击合并:

合并后我们回到develop分支就可以看到我们新提交的文件。那么这时候就进入部署的环节了,在gitee也有对应的功能,就是流水线,当然这个就是要付费才能玩的了。我们知道有这么一个环节即可。
开发人员部署测试完之后就交给测试人员了,测试人员要基于develop分支创建出一个release分支,要保证基于的develop分支一定是最新代码。下面我们就创建一个release分支:
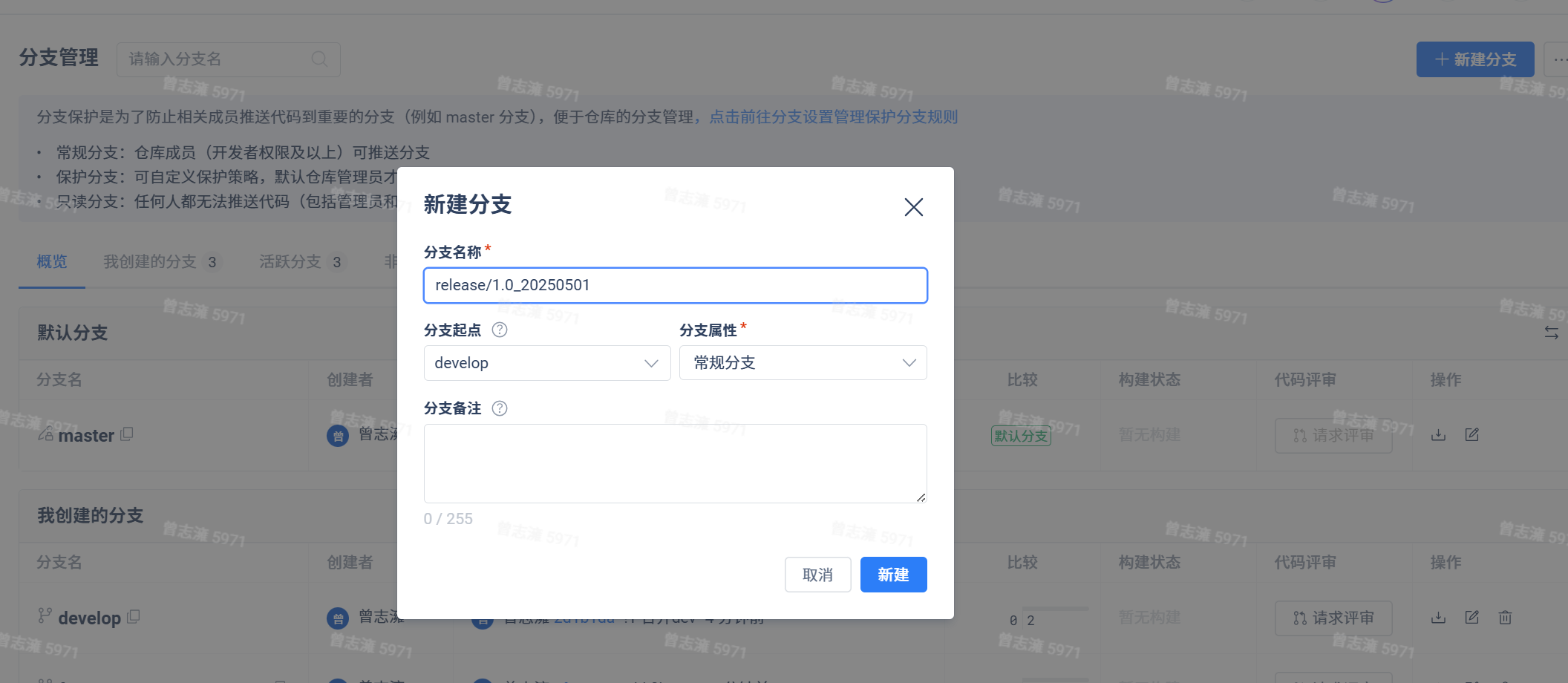
这时候就可以将release分支部署到测试环境上,然后测试人员进行测试。
测试完成后就需要将release分支合并到master分支上。所以我们继续创建一个请求评审:同时下方我们选择合并后删除提交分支,将来合并后release分支就会被删除。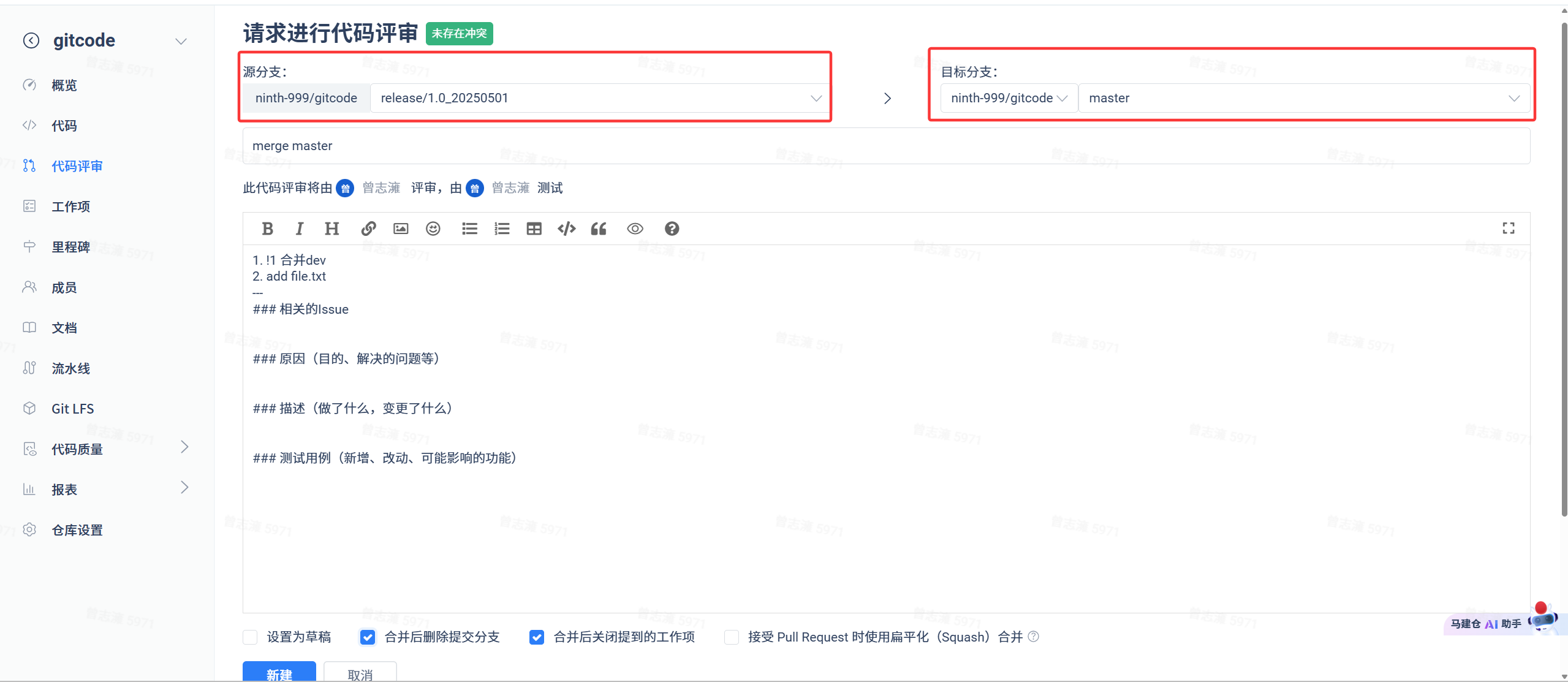
接着审查人员和测试人员进行审查和测试,然后进行合并:
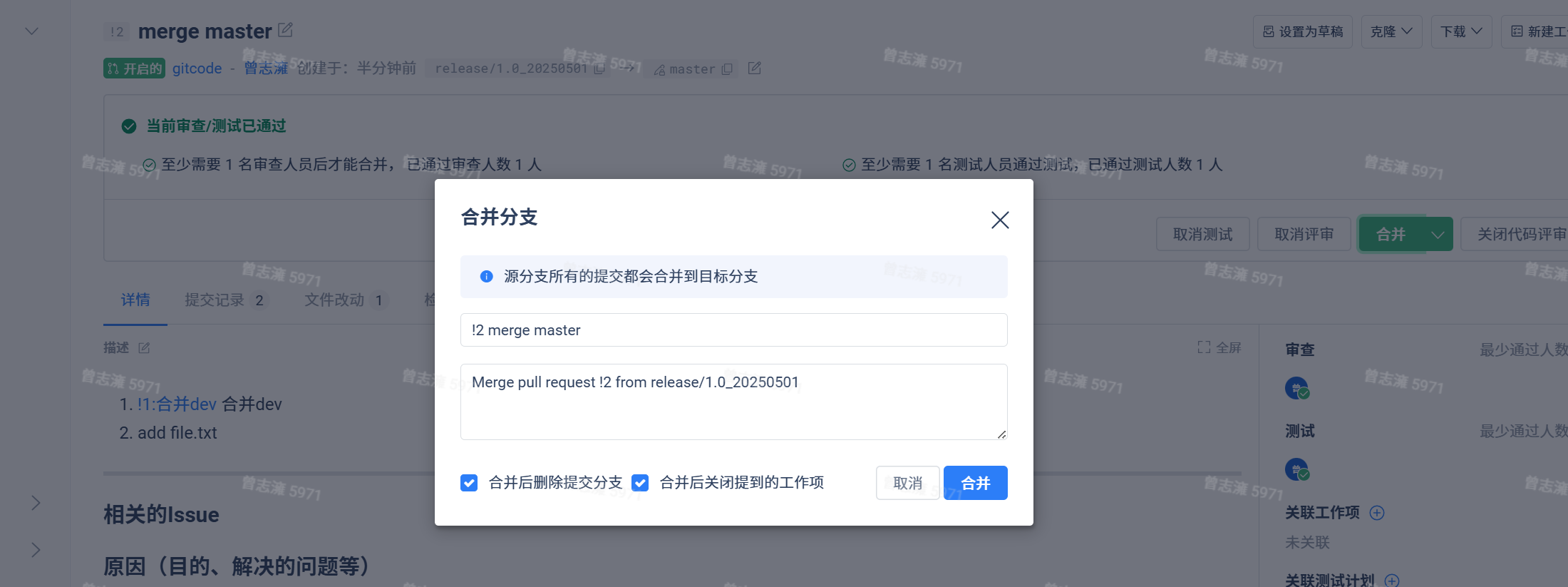
此时回到master分支,可以看到我们新增的file.txt文件,同时我们也看不到release分支了,接着我们可以把feature分支也删除了。我们发现develop分支会一直保存我们最新的提交信息。
**修复测试环境Bug:在develop测试出现了Bug,建议大家直接在feature分支上进行修复。 修复后的提测上线流程与新需求加入的流程⼀致。 **
修改预发布环境Bug:在release测试出现了Bug,首先要回归下develop分支是否同样存在这个问题。 如果存在,修复流程与修复测试环境Bug流程一致。 如果不存在,这种可能性比较少,大部分是数据兼容问题,环境配置问题等。
修改正式环境Bug:在master测试出现了Bug,首先要回归下release和develop分支是否同样存在这个问题。如果存在,修复流程与修复测试环境Bug流程一致。 如果不存在,这种可能性也比较少,大部分是数据兼容问题,环境配置问题等。
紧急修复正式环境Bug:需求在测试环节未测试出Bug,上线运行一段时候后出现了Bug,需要紧急修复的。 有的企业面对紧急修复时,支持不进行测试环境的验证,但还是建议验证下预发布环境。可基于master创hotfix/xxx 分支,修复完毕后发布到master验证,验证完毕后,将master代码合并到develop分支,同时删掉hotfix/xxx分支。