自然语言to SQL的评估
一、怎么进行一个自然语言to SQL评估?
1.DB——准备可用的数据表
2.准备问题集,自然语言|正确的预期SQL
3.大模型执行完成的SQL
4.Table.json——一个存储表格数据或者数据库表结构信息的 JSON 文件。当前是存储的表结构信息的,存储数据库表的元数据,例如表名、列名、列类型、主键、外键等信息。
二、获取Spider数据集,以及评估代码
https://yale-lily.github.io/spider
个人理解:如有错误请指出
baselines\ :包含不同基线模型的代码和文档。
- nl2code\ :可能是一个将自然语言转换为代码的基线模型目录。
- seq2seq_attention_copy\ :包含序列到序列注意力复制模型的代码和脚本。
- sqlnet\ :包含 Modified SQLNet 基线模型的代码和文档。
- typesql\ :包含 Modified TypeSQL 基线模型的代码和文档。
evaluation_examples\ :包含评估示例文件。
preprocess\ :包含数据预处理的脚本和文档。
evaluation.py :用于评估模型的 Python 脚本。
process_sql.py :用于处理 SQL 查询的 Python 脚本。
三、以上调试成功后,执行命令结果
python evaluation.py --gold [gold file] --pred [predicted file] --etype [evaluation type] --db [database dir] --table [table file]arguments:[gold file] gold.sql file where each line is `a gold SQL \t db_id`[predicted file] predicted sql file where each line is a predicted SQL[evaluation type] "match" for exact set matching score, "exec" for execution score, and "all" for both[database dir] directory which contains sub-directories where each SQLite3 database is stored[table file] table.json file which includes foreign key info of each database[gold file] 提供了正确的 SQL 答案和对应的数据库标识,而 [predicted file] 包含了模型生成的 SQL 预测结果,二者共同用于模型评估。
[evaluation type]:这是对不同评估方式的分类。
- -match(精确集合匹配得分):当使用 “match” 评估类型时,主要关注的是被评估对象与给定集合在元素上的精确匹配程度。例如在文本处理中,判断一段文本中的词汇集合是否与标准词汇集合完全一致,根据匹配的程度来计算得分。
- -exec(执行得分):“exec” 评估类型侧重于对某个操作、程序或任务执行结果的评估。比如在代码执行场景下,根据代码执行是否成功、执行结果是否符合预期等方面来计算得分。
- -all(两者兼具):选择 “all” 意味着同时考虑精确集合匹配得分和执行得分,综合这两个方面来对对象进行评估。
四、结果分析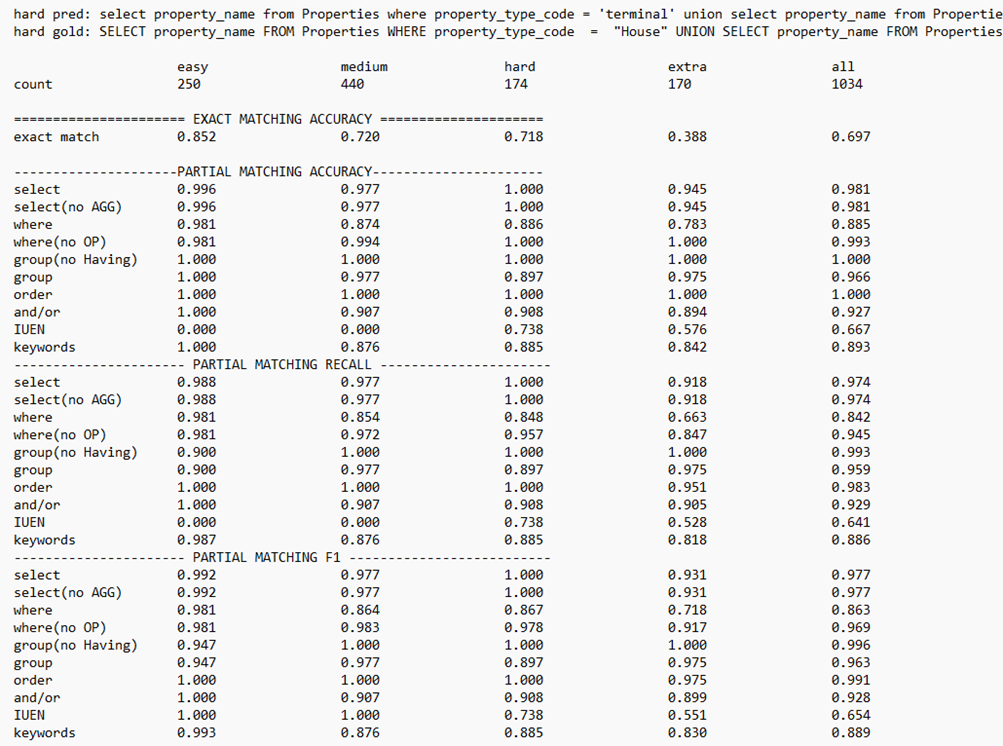
各难度样本数量
count 行展示不同难度级别样本数量,easy有 250 个,medium有 440 个,hard有 174 个,extra有 170 个,总计 1034 个。评估指标
exact match(完全匹配准确率)
衡量预测 SQL 与标准 SQL 完全一致的比例。各难度级别分别为easy:0.852、medium:0.720、hard:0.718、extra:0.388 ,整体为 0.697 。数值越高,完全匹配情况越好,extra难度下表现较差,说明复杂场景完全匹配难。
partial matching(部分匹配相关指标 )
- 准确率(Accuracy):判断预测 SQL 中特定子句(如select 、where等 )正确的比例。如select子句在easy难度准确率 0.996 ,hard难度 1.000 ,反映不同难度下子句预测正确性。
- 召回率(Recall):关注标准 SQL 中特定子句被正确预测出的比例。如where子句在medium难度召回率 0.854 ,体现对标准子句的捕捉能力。
- F1 值(F1):综合准确率和召回率的指标。如group(no Having)子句在all难度下 F1 值 0.996 ,越高说明子句预测综合表现越好。