基于 Amazon RDS 数据库之间复制数据并屏蔽个人身份信息
在不同数据库之间移动和转换数据是许多组织机构的常见需求。将生产数据库中的数据复制到较低级别或同级别环境中,同时屏蔽个人身份信息 (PII) 以满足法规要求,可让我们在不影响关键系统或暴露客户敏感数据的前提下进行开发、测试和报告。然而,如果人工对克隆的信息进行匿名化处理,这对于安全和数据库团队来说可能是一项繁重的任务。
有了 Amazon Glue Studio,无需编写代码即可对数据复制进行设置,以屏蔽其中的个人身份信息。Amazon Glue Studio 的可视化编辑器提供了一个低代码编写要求的图形化环境,可供您创建、运行和监控提取、转换和加载 (ETL) 脚本。Amazo Glue 会在后台处理底层的资源配置、作业监控和重试,无需您主动管理基础设施。因此,您可专注于在关键系统之间快速构建合规的数据流。
在本文中,将介绍如何利用Amazon Glue在适用于 PostgreSQL 的亚马逊关系数据库服务 (Amazon RDS) 数据库之间复制数据,同时屏蔽个人身份信息。您将学习如何准备多账户环境,以便从 Amazon Glue 访问数据库;您将了解如何设计一个自动屏蔽个人身份信息的 ETL 数据流模型,从而确保在数据传输过程中,不会原封不动地将敏感信息复制到目标数据库。最终,您将能够在数据源与目标数据库之间快速构建数据传输管道,兼具隐藏和保护个人身份信息的功能,而且无需人工编写代码。
亚马逊云科技为开发者提供了众多免费云产品。想深入体验如何利用Amazon Glue在适用于 PostgreSQL 的亚马逊关系数据库服务 ,可以访问亚马逊云科技。
解决方案概述
下图展示了该解决方案的架构:
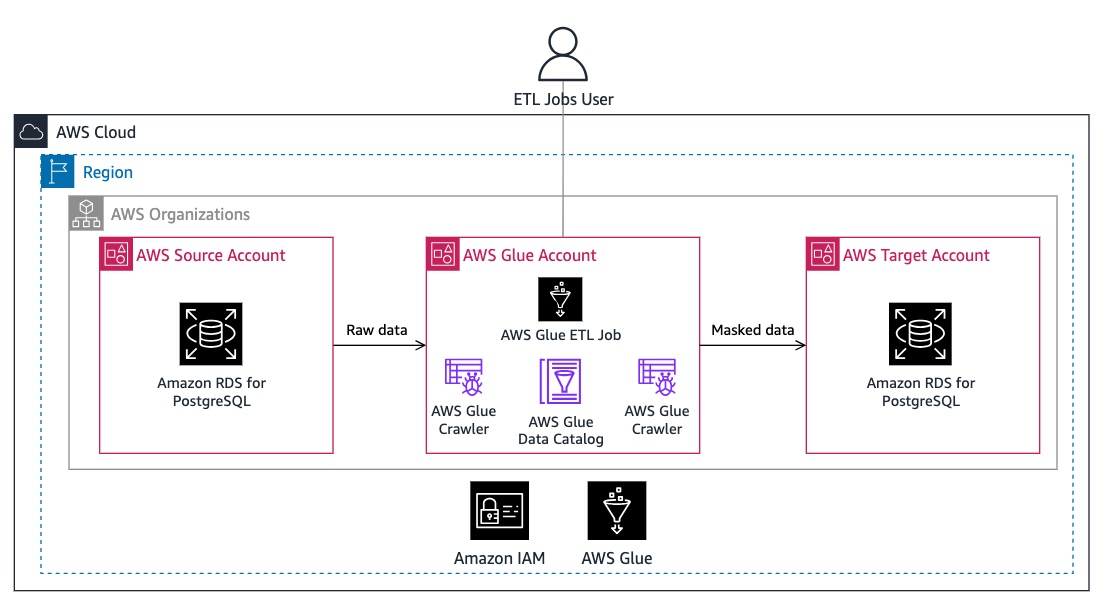
该方案使用 Amazon Glue 作为 ETL 引擎,从 Amazon RDS 源数据库中提取数据,再利用内置的数据转换功能通过预定义的屏蔽函数来清除包含个人身份信息的列。最后,Amazon Glue ETL 作业将去除了隐私信息的数据插入 Amazon RDS 目标数据库中。
操作指南
实施此解决方案时,请遵照本操作指南执行以下步骤:
- 启用从 Amazon Glue 账户至源账户和目标账户的连接
- 为 ETL 作业创建 Amazon Glue 组件
- 创建和运行 Amazon Glue ETL 作业
- 验证结果
先决条件
要按照本文进行操作,需要满足以下先决条件:
三个 Amazon 账户,具体如下所示:
-
源账户:托管源 Amazon RDS for PostgreSQL 数据库。该数据库包含一个内含敏感信息的表,并且位于私有子网中。为方便后期查阅,请记下与 Amazon RDS 数据库相关的虚拟私有云(VPC)ID、安全组和私有子网。
-
目标账户:包含目标 Amazon RDS for PostgreSQL 数据库,其表结构与源表一致,但初始状态为空。该数据库位于私有子网中。同样,请记下相关的 VPC ID、安全组 ID 和私有子网。
-
Amazon Glue 账户:该专用账户包含一个 VPC、一个私有子网和一个安全组。如 Amazon Glue 文档中所述,该安全组包括一个适用于所有 TCP 和 TCP 端口(0-65535)的自引用入站规则,以允许 Amazon Glue 与其组件通信。
下图显示了 Amazon Glue 账户安全组所需的自引用入站规则。

确保三个 VPC CIDR 不会相互重叠,具体如下表所示:
| 虚拟私有云 | 私有子网 | |
|---|---|---|
| 源账户 | 10.2.0.0/16 | 10.2.10.0/24 |
| Amazon Glue 账户 | 10.1.0.0/16 | 10.1.10.0/24 |
| 目标账户 | 10.3.0.0/16 | 10.3.10.0/24 |
下图展示了满足所有先决条件的环境:
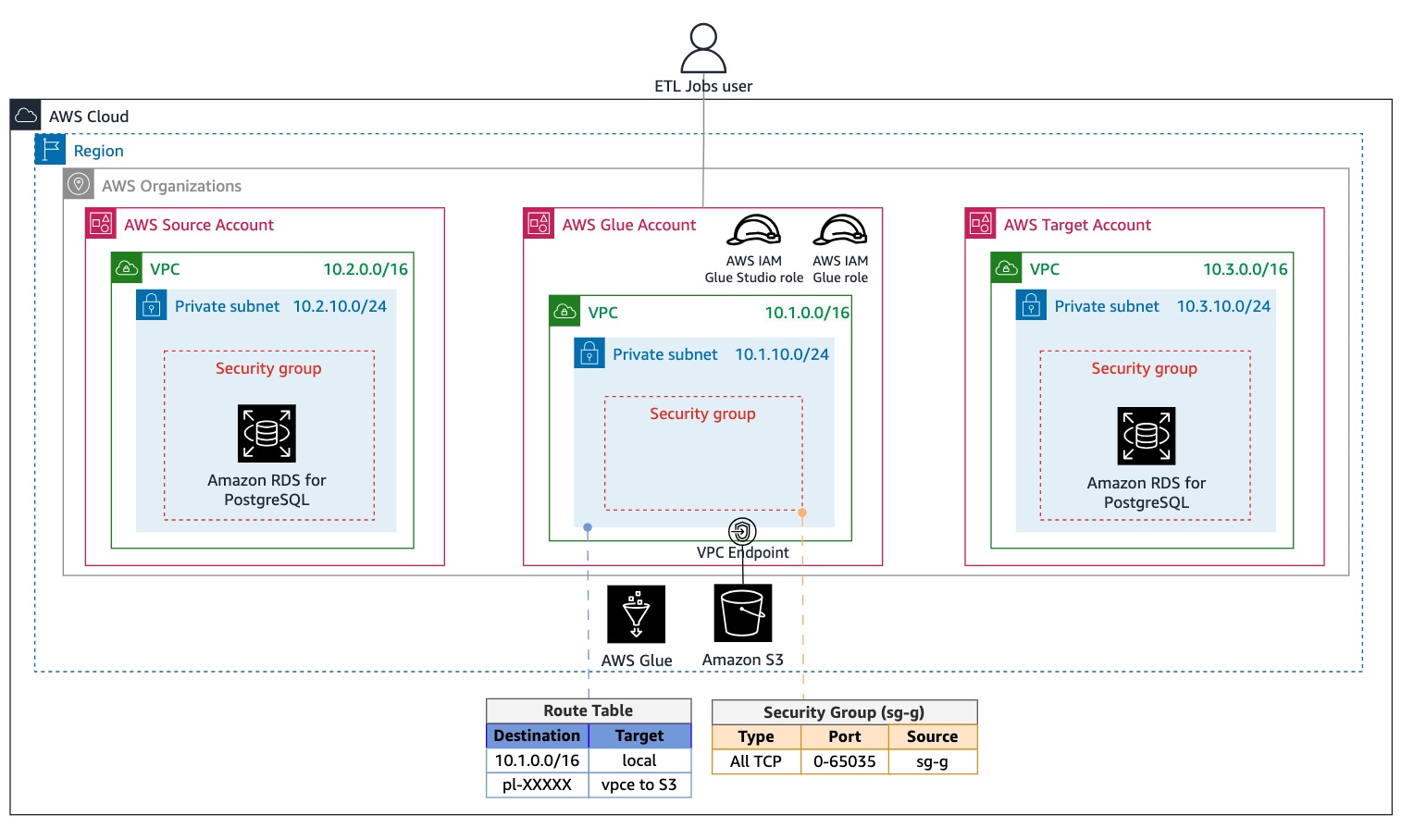
为简化设置先决条件的步骤,可按照此 GitHub 仓库中 README 文件的说明进行操作。
数据库表
在本示例中,源数据库和目标数据库均包含一个结构完全一致的客户表。但源数据库预先填充了数据,具体如下图所示:
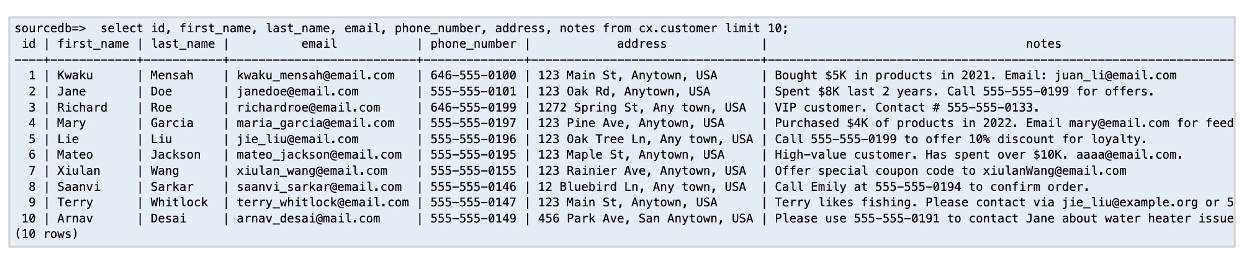
您即将创建的 Amazon Glue ETL 作业专注于对特定列中的敏感信息进行屏蔽处理。这些列包括 last_name、email、phone_number、ssn、notes。
如果您想使用同样的表结构和数据,此 GitHub 仓库中提供了 SQL 语句。
第 1 步 – 启用从 Amazon Glue 账户至源账户和目标账户的连接
在创建 Amazon Glue ETL 作业时,提供 Amazon Glue 访问 JDBC 数据库所需的 Amazon IAM 角色、VPC ID、子网 ID 和安全组。
在本示例中,角色、组和其他信息均位于专用的 Amazon Glue 账户中。但为了打通 Amazon Glue 与数据库的连接,需要在 Amazon Glue 账户的子网和安全组中启用对源数据库和目标数据库的访问。
亚马逊云科技为开发者提供了众多免费云产品。想深入体验如何利用Amazon Glue在适用于 PostgreSQL 的亚马逊关系数据库服务 ,可以访问亚马逊云科技。
按以下步骤操作:
-
为 Amazon Glue 账户 VPC 和数据库 VPC 建立对等连接
-
更新路由表
-
更新数据库安全组
为 Amazon Glue 账户 VPC 和数据库 VPC 建立对等连接
在 Amazon VPC 控制台中,执行以下步骤:
- 在 Amazon Glue 账户中,按照创建 VPC 对等连接中的说明创建两个 VPC 对等连接,一个用于源账户 VPC,一个用于目标账户 VPC。
- 在源账户中,接受 VPC 对等连接请求。有关说明,请参阅接受 VPC 对等连接。
- 在目标账户中,同样接受 VPC 对等连接请求。
- 在 Amazon Glue 账户中,为每个对等连接启用 DNS 设置。这将允许 Amazon Glue 解析数据库的私有 IP 地址。
完成上述步骤后,Amazon Glue 账户中的对等连接列表应如下图所示:

请注意,源账户和目标账户的 VPC 之间并未建立对等连接,因为这两个账户之间不需要连接。
更新子网路由表
此步骤将允许来自 Amazon Glue 账户 VPC 的流量到达源账户和目标账户中关联到数据库的 VPC 子网。
在 Amazon VPC 控制台中,执行以下步骤:
-
在 Amazon Glue 账户的路由表中,对于每个 VPC 对等连接,为关联到数据库的每个私有子网添加一条路由,以便 Amazon Glue 能够建立与数据库的连接,并将来自 Amazon Glue 账户的流量限制在仅关联到数据库的子网内。
-
在关联到数据库的源账户的私有子网路由表中,为 Amazon Glue 账户的 VPC 对等连接添加一条路由。此路由将允许流量返回至 AmazonS Glue 账户。
-
对于目标账户的路由表,重复执行第 2 步操作。
更新数据库安全组
此步骤是必需的,以允许来自 Amazon Glue 账户安全组的流量到达关联到数据库的源安全组和目标安全组。
在 Amazon VPC 控制台中,执行以下步骤:
-
在源账户的数据库安全组中添加一条入站规则,类型设置为 PostgreSQL,源设置为 Amazon Glue 账户安全组。
-
在目标账户的数据库安全组中,重复第 1 步操作。
下图展示了从 Amazon Glue 账户至源账户和目标账户的连接已启用的环境:
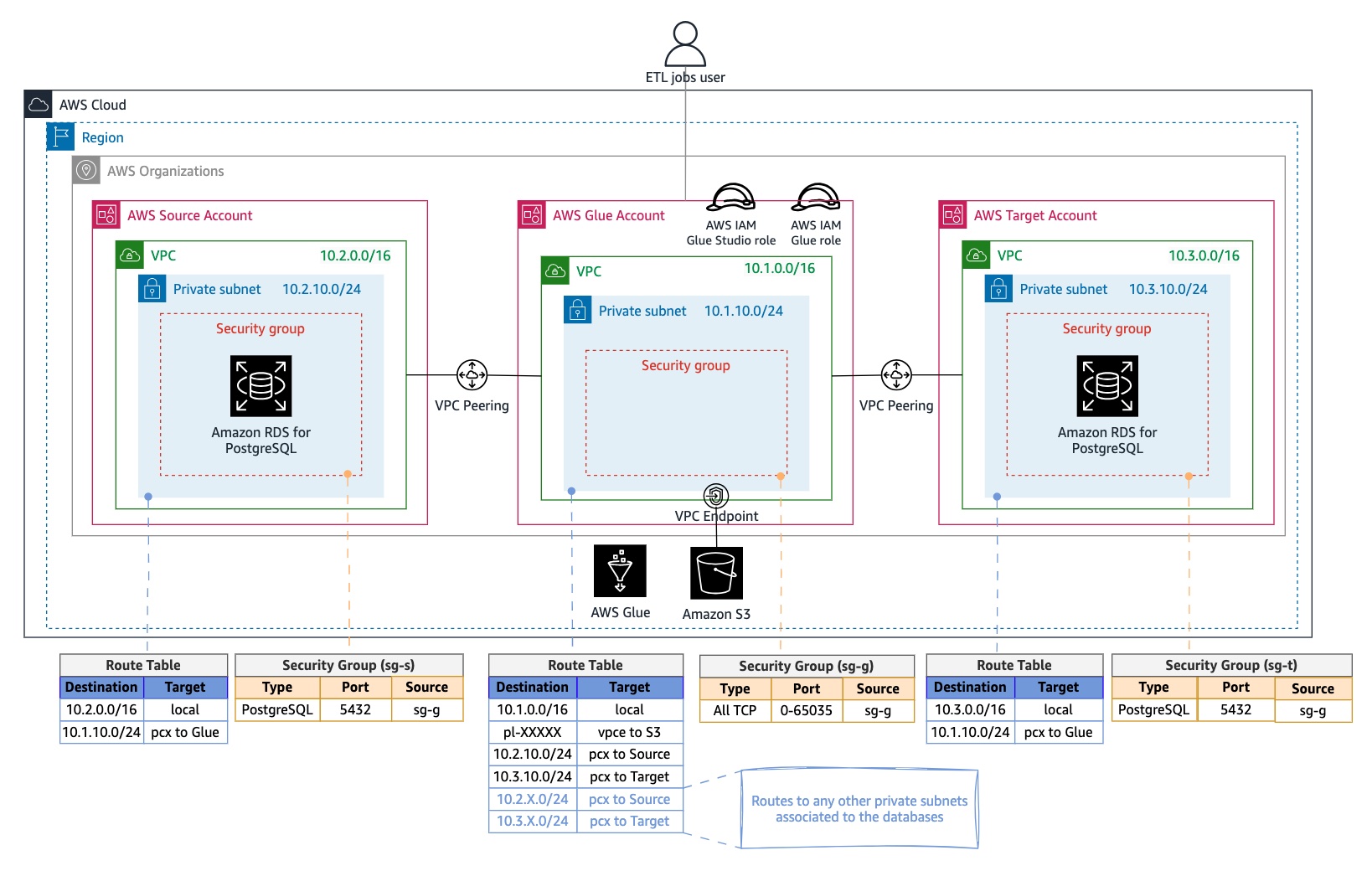
第 2 步 – 为 ETL 作业创建 Amazon Glue 组件
下一个任务是创建 Amazon Glue 组件,以实现源数据库和目标数据库模式与 Amazon Glue Data Catalog 的同步。
请按以下步骤操作:
-
为每个 Amazon RDS 数据库创建一个 Amazon Glue 连接。
-
创建 Amazon Glue 爬虫以填充Data Catalog。
-
运行爬虫。
创建 Amazon Glue 连接
创建连接后,Amazon Glue 就能访问您的数据库。创建 Amazon Glue 连接的一大好处在于,连接可以节省时间,因为您不必在每次创建作业时都指定所有连接详情。随后,您可以在 Amazon Glue Studio 中创建作业时重复使用这些连接,无需每次手动输入连接详情。这不仅加快了作业的创建过程,还提高了一致性。
在 Amazon Glue 账户中,执行以下步骤:
-
在 Amazon Glue 控制台中,选择导航窗格中的“数据连接”链接。
-
点击“创建连接”,按照“创建连接”向导中的说明进行操作:
a. 在“选数据源”中,选择 JDBC 作为数据源。
b. 在“配置连接”中:
- 对于 JDBC URL,输入源数据库的 JDBC URL。对于 PostgreSQL,语法如下:*jdbc:postgresql://database-endpoint:5432/database-name*
- 在源账户的 Amazon RDS 控制台中,可以找到 database-endpoint。
- 展开“网络选项”。对于 VPC、子网和安全组,选择集中式 Amazon Glue 账户中的相应项,具体如下图所示:
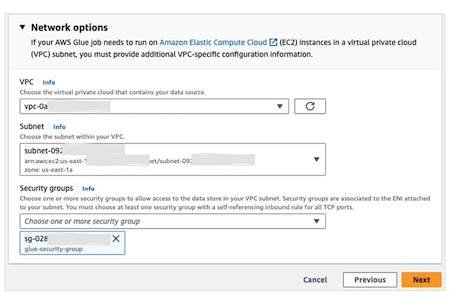
c. 在“设置属性”中,对于“名称”,输入 Source DB connection-Postgresql。
- 重复第 1 步和第 2 步操作,创建至目标 Amazon RDS 数据库的连接。将该连接命名为 Target DB connection-Postgresql。
现在您已经建立了两个连接,每个 Amazon RDS 数据库各一个。
创建 Amazon Glue 爬虫
Amazon Glue 爬虫可以实现数据源和目标的数据发现和编目过程的自动化。爬虫能够探索数据存储,并自动生成元数据以填充 Data Catalog,将发现的表注册到 Data Catalog中。这有助于您发现数据并利用数据构建 ETL 作业。
要为每个 Amazon RDS 数据库创建爬虫,请在 Amazon Glue 账户中执行以下步骤:
-
在 Amazon Glue 控制台中,选择导航窗格中的“爬虫”。
-
点击“创建爬虫”,按照“添加虫”向导中的说明进行操作:
a. 在“设置爬虫属性”中,对于“名称”,输入 Source PostgreSQL database crawle。
b. 在“选择数据源和分类器”中,点击“暂不选择”。
c. 在“添加数据源”中,对于“数据源”,选择 JDBC,如下图所示:
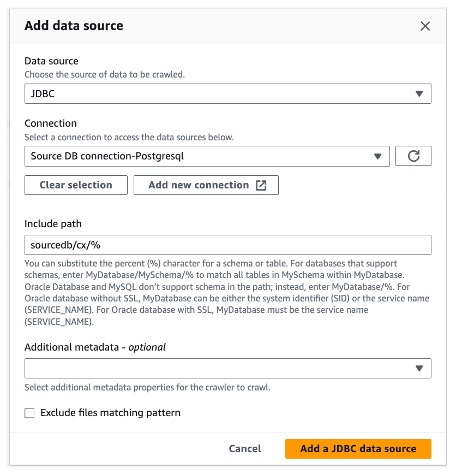
d. 对于“连接”,选择 Source DB Connection - Postgresql。
e. 对于“包含路径”,输入包括模式在内的数据库路径。在我们的示例中,路径是 sourcedb/cx/%,其中 sourcedb 是数据库的名称,cx 是包含客户表的模式。
f. 在“配置安全设置”中,选择作为先决条件之一创建的 Amazon IAM 服务角色。
g. 在“设置输出和调度”中,由于我们在 Data Catalog 中还没有用于存储源数据库元数据的数据库,请选择“添加数据库”,并创建一个名为 sourcedb-postgresql 的数据库。
- 重复第 1 步和第 2 步操作,以创建目标数据库的爬虫:
a. 在“设置爬虫属性”中,对于“名称”,输入 Target PostgreSQL database crawler。
b. 在“添加数据源”中,对于“连接”,选择 Target DB Connection-Postgresql,对于“包含路径",输入 targetdb/cx/%。
c. 在“添加数据库”中,对于“名称”,输入 targetdb-postgresql。
现在您已经创建了两个爬虫,每个 Amazon RDS 数据库各一个,具体如下图所示:
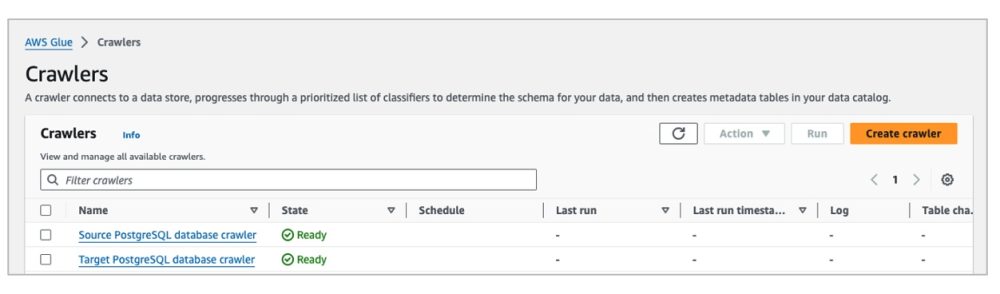
运行爬虫
接下来运行爬虫。运行爬虫时,爬虫会连接到指定的数据存储,并自动利用元数据表定义(列、数据类型、分区等)填充 Data Catalog。与手动定义模式相比,这节省了不少时间。
在爬虫列表中,选择 Source PostgreSQL database crawler 和 Target PostgreSQL database crawler,再点击“运行”。
运行完成后,每个爬虫都会在 Data Catalog 中创建一个表。这些表均为客户表的元数据表示。
现在您已经拥有了创建 Amazon Glue ETL 作业所需的全部资源,即刻开始吧!
第 3 步 - 创建并运行 Amazon Glue ETL 作业
所述的 ETL 作业需要执行四个任务:
-
源数据提取 - 建立与 Amazon RDS 源数据库的连接,并提取需要复制的数据。
-
个人身份信息检测 ( PII ) 与清理。
-
数据转换 - 调整和删除不必要的字段。
-
建立与目标 Amazon RDS 数据库的连接,并插入已屏蔽 PII 的数据。
现在我们进入 Amazon Glue Studio 中创建 Amazon Glue ETL 作业。
-
使用您的 Amazon Glue 账户登录 Amazon Glue 控制台。
-
在导航窗格中选择 ETL 作业。
-
选择可化 ETL,具体如下图所示:
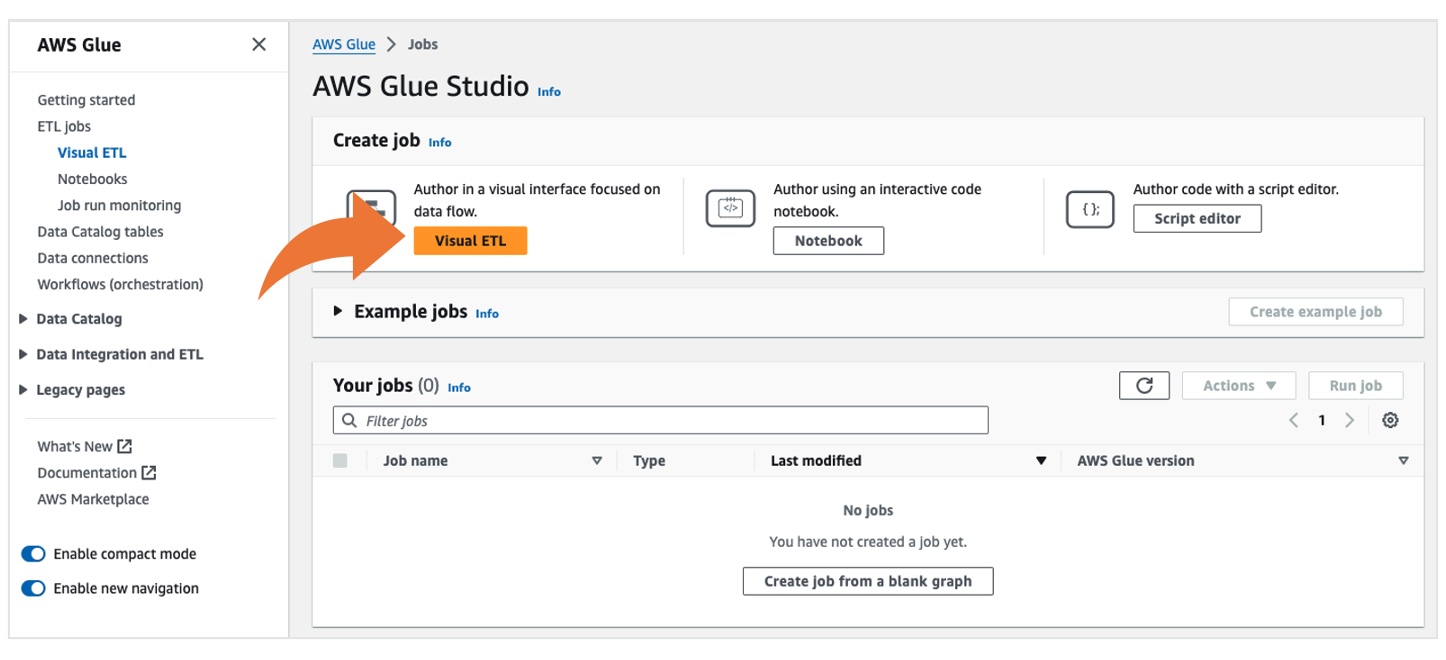
任务 1 - 源数据提取
添加一个节点以连接至 Amazon RDS 源数据库:
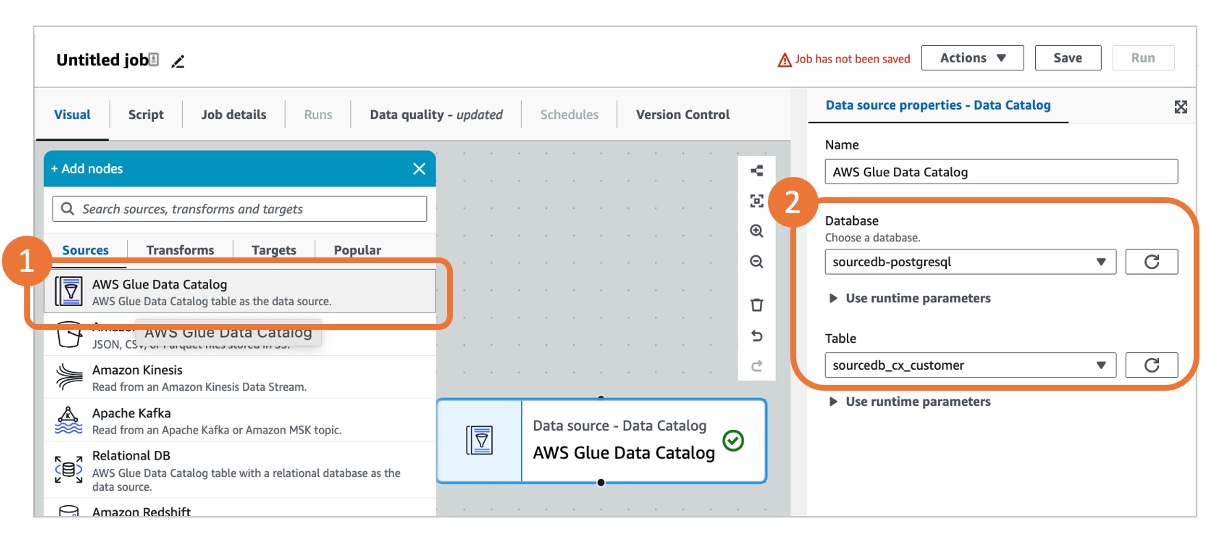
- 从源中选择“Amazon Glue Data Catalog**”。**这将在画布上添加一个数据源节点。
- 在数据源属性面板上,在“Data Catalog”中选择 sourcedb-postgresql 数据库和 source_cx_customer 表,具体如下图所示:
任务 2 - PII 检测与清理
要检测和屏蔽 PII,需要在“转换”选项卡中选择检测敏感数据节点。
让我们深入了解“检测敏感数据节点”属性面板上的转换选项:
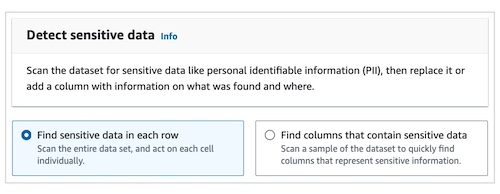
- 首先,您可以选择数据扫描方式。您可以选择在每一行中查找敏感数据,或查找包含敏感数据的列,具体如下图所示。选择前者会扫描所有行以进行全面的 PII 识别,而后者则以较低的成本扫描样本以确定 PII 的位置。
选择在每一行中查找敏感数据,这将允许您指定细粒度的操作覆盖。如果您了解自己的数据,您可通过细粒度操作从检测中排除某些列。您还可以自定义待检测的实体,针对数据集中的每一列,并跳过您知道不在特定列中的实体。这样可以消除对这些实体不必要的检测调用,从而提高作业性能,并对每个列和实体组合执行唯一的操作。
在我们的示例中,我们了解我们的数据,并希望对特定列应用细粒度操作,因此让我们选择在每一行中查找敏感数据。下面我们将进一步探讨细粒度操作。
- 接下来,选择需要检测的敏感信息类型。花些时间研究一下三个不同的选项。
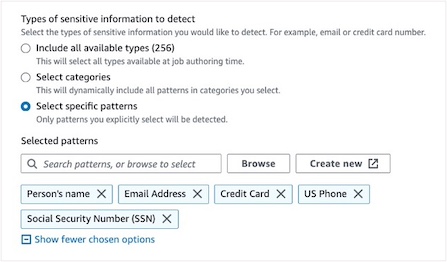
在我们的示例中,由于我们对数据非常了解,这里我们选择“选择特定模式”。对于选定的模式,选择 Person’s name, Email Address, Credit Card, Social Security Number (SSN) 和 US Phone,具体如下图所示。请注意,某些模式(如 SSN)仅适用于美国,可能无法检测其他国家的 PII 数据。但如果有适用于其他国家的可用类别,还可在 Amazon Glue Studio 中使用正则表达式创建检测实体以满足您的特定需求。
-
接下来,选择检测敏感度级别。保留默认值(高)。
-
接下来,选择需要对检测到的实体执行的全局操作。选择 REDACT 并输入 ** 作为编辑文本。
-
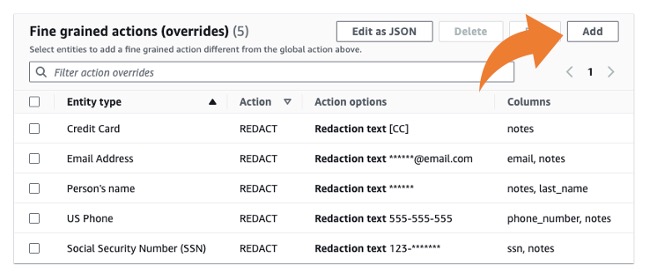
接下来,您可以指定细粒度操作(覆盖)。覆盖是可选的,但在我们的示例中,我们想要在检测中排除某些特定的列,仅扫描特定列上的某些 PII 实体类型,并为不同实体类型指定不同的编辑文本设置。
点击“添加”以指定每个实体的细粒度操作,具体如下图所示:
任务 3 - 数据转换
在**“检测敏感数据”**节点的运行过程中,它将 id 列转换为字符串类型,并在输出中添加一个名为 DetectedEntities 的列,其中包含 PII 检测元数据。我们不需要在目标表中存储这样的元数据信息,我们需要将 id 列转换回整形数据。因此,我们向 ETL 作业添加了一个“更改模式”转换节点,具体如下图所示。这将为我们执行这些更改。
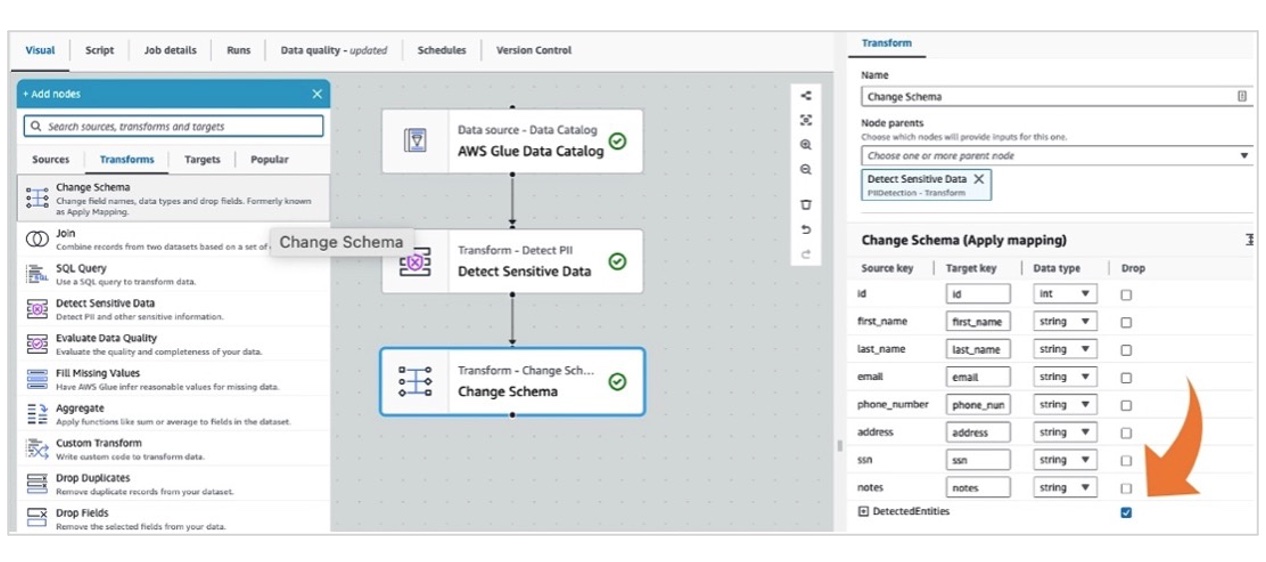
注意:您必须选中 DetectedEntities Drop 复选框,转换节点才能删除添加的字段。
任务 4 - 目标数据加载
ETL 作业的最后一个任务是,建立与目标数据库的连接并插入已屏蔽 PII 的数据:
-
从目标中选择“Amazon Glue Data Catalog”。这将在画布上添加一个数据目标节点。
-
在数据目标属性面板上,选择 targetdb-postgresql 和 target_cx_customer,具体如下图所示。
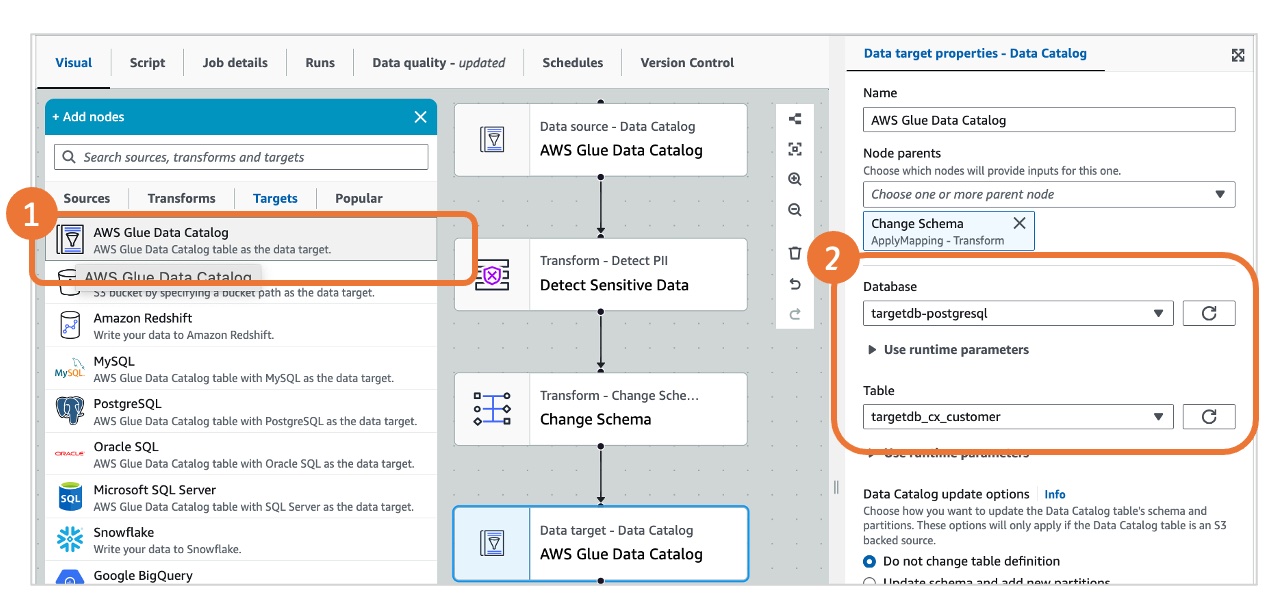
保存并运行 ETL 作业
在“作业详情”选项卡中,对于名称,输入 ETL - Replicate customer data。
-
对于 IAM 角色,选择作为先决条件之一创建的 Amazon Glue 角色。
-
点击保存,再点击运行。
在导航窗格中,可监控作业的执行情况,直至成功完成作业。
第 4 步 - 验证结果
连接到 Amazon RDS 目标数据库,验证复制的行是否包含已清理的 PII 数据,确认在数据库之间传输时已正确屏蔽敏感信息,具体如下图所示:
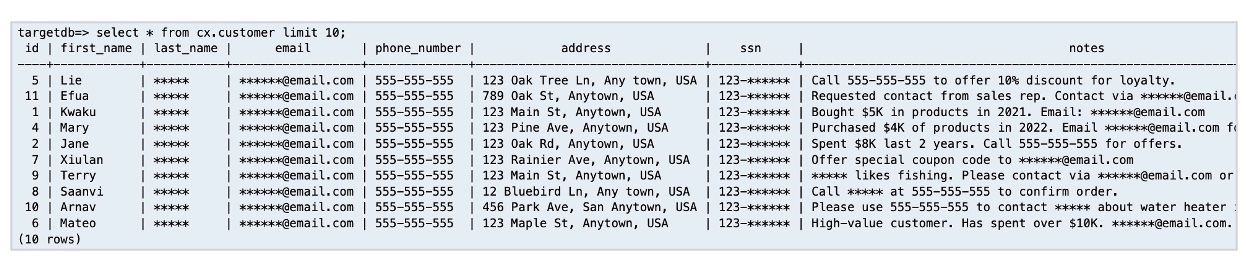
就是这样!有了 Amazon Glue Studio,您可以创建 ETL 作业,以实现不同数据库之间数据的复制,并在这个过程中进行数据转换,无需编写任何代码。您可以尝试其他类型的敏感信息,以此保护复制过程中的敏感数据。您还可以尝试添加和组合多个异构的数据源和目标。
清理
要清理创建的资源:
-
删除 Amazon Glue ETL 作业、爬虫、Data Catalog 数据库和连接。
-
删除 VPC 对等连接。
-
删除添加到路由表的路由,以及三个 Amazon 账户中添加到安全组的入站规则。
-
在 Amazon Glue 账户中,删除关联的 Amazon S3 对象。这些对象位于名称中包含 Amazon-glue-assets-account_id-region 的 S3 存储桶中,其中 account-id 是您的 Amazon Glue 账户 ID,region 是您使用的亚马逊云科技区域。
-
倘若不再需要,请删除您创建的 Amazon RDS 数据库。如果您使用了此 GitHub 仓库,请删除 Amazon CloudFormation 栈。
总结
在本文中,您学习了如何利用 Amazon Glue Studio 构建 ETL 作业,该作业可将数据从一个 Amazon RDS 数据库复制到另一个数据库,自动检测 PII 数据并在传输过程中屏蔽PII数据,无需编写代码即可实现。
组织可使用 Amazon Glue 进行数据库复制,无需手动查找隐藏的 PII,也无需编写定制化的转换脚本,只需通过构建集中化、可视化的数据清理管道即可实现。这不仅提高了安全性和合规性,还加快了测试或分析数据提供的上线时间。
亚马逊云科技为开发者提供了众多免费云产品。想深入体验如何利用Amazon Glue在适用于 PostgreSQL 的亚马逊关系数据库服务 ,可以访问亚马逊云科技。