语音合成之八-情感化语音合成的演进路线
情感化语音合成的演进路线
- 引言:情感在语音合成中的重要性
- 开源情感化语音合成模型
- EmotiVoice
- EmoSphere-TTS
- Orpheus-TTS
- 技术解析:原理、思想与实现
- 情感标签的整合:嵌入技术与条件机制
- 韵律控制:音高和时长操作方法
- 强化学习的作用:融入用户反馈以增强情感表达
- 幕后剖析:开源模型中的网络结构、损失函数和训练数据考量
- 研究热点与潜在突破
- 迈向更细粒度的情感控制与表现力
- 探索跨语言和个性化情感语音合成
- 语境理解在情感化语音合成中的融合
- 该领域的新兴趋势与潜在突破
引言:情感在语音合成中的重要性
人类的交流沟通本质上是充满情感的。无论是日常对话还是正式演讲,语音都不仅仅是信息的载体,更是情感、态度和意图的表达方式 。情感化语音合成(Emotional Speech Synthesis, ESS)旨在弥合功能性文本到语音(Text-to-Speech, TTS)系统与真正类人交互之间的鸿沟。它赋予机器通过语音表达各种情感的能力,使得人机交互更加自然、生动和富有同理心 。情感化语音合成技术对于提升用户体验至关重要,尤其是在虚拟助手、游戏、个性化服务等应用场景中,能够显著增强系统的亲和力和吸引力 。
早期 TTS 系统主要关注于生成清晰可懂的语音 。随着技术的发展,人们逐渐认识到情感在人际交流中的核心作用,开始探索如何让机器也能“说”出情感 ,学术界和工业界也从追求语音的准确性到关注其情感表达的演变。如今,能够以人类般的方式进行交流(包括情感表达)变得越来越重要,这直接关系到用户满意度和交互的有效性 。
早期TTS基于规则与声带模拟方法,其情感化语音合成技术很大程度上依赖于人类专家对情感在声学特征中表现方式的理解。基于对语音学以及情感与语音之间关系的深刻认识 ,通过人工设计的规则来修改音高、时长等声学参数,以表达不同的情感 。
随着21世纪初连接式合成与共振峰合成技术的出现,这些技术添加情感包括为每种情感创建单独的数据库,或者在连接过程中修改韵律特征 。例如,使用双音素连接时,只有音高和时长容易修改 ,这限制了通过音质表达情感的能力。
早期的系统听起来常常很机械,缺乏人类情感语音的细微差别 。单调的语调使得听众难以产生共鸣 。一个关键的限制是难以复制人类语音的韵律、语调和可变性 。书面文本缺乏口语的情感线索 。情感和表现力有限是显著的缺点,系统难以传达基本类别之外的复杂情感 。
获取高质量、情感标注的语音数据的困难是更具表现力的 TTS 系统发展中反复出现的瓶颈 。创建此类数据集既昂贵又耗时,并且情感的主观性增加了进一步的复杂性 。
过去 20 年来,由于计算能力更强、数据集更大以及机器学习的进步,情感化的语音合成从又发展出了数据驱动和统计参数方法。数据驱动的模型克服了规则系统受到人类理解和对语音与情感之间复杂关系进行编码能力的限制,使得机器能够从大量数据中直觉学习语音特征与情感表达的复杂性和统计规律性,并提供更大的灵活性。
开源情感化语音合成模型
早期数据驱动的方法结合了统计参数法,如专门探索了基于隐马尔可夫模型 (HMM) 和深度学习的情感语音生成方法的Emotional-Text-to-Speech),突显了技术上的转变。他们关于微调情感语音的实验 揭示了在小型数据集上对齐和过拟合的挑战。
EmoSphere-TTS、Cosyvoice2等较新的项目通过分别利用球形情感向量和大型语言模型,代表了情感控制和自然度方面的进步。EmotiVoice 以其多语音功能和基于提示的情感合成而著称,表明系统正朝着更用户友好和可控的方向发展。
EmotiVoice
EmotiVoice 是一个多语音、提示控制的 TTS 引擎,支持英语和中文,拥有超过 2000 种不同的声音。如此大规模的语音选项是一项显著的特征。其主要特点是情感合成,允许控制快乐、悲伤、愤怒等各种情感 。这使得生成广泛的表现力语音成为可能。它使用提示来控制风格和情感 ,提示格式为 |<style_prompt/emotion_prompt/content>||。这为用户提供了一种灵活直观的方式来指导合成。该模型基于 PromptTTS 论文 ,表明其侧重于使用文本描述进行控制,体现了对自然语言理解在风格迁移方面的依赖。它提供了一个 Web 界面和脚本界面 ,使其更易于广大用户使用。该模型支持语音克隆 ,这项功能最近发布,扩展了其潜在应用。它利用音高、速度、能量和情感作为风格因素 ,突出了正在控制的关键声学参数。
EmotiVoice 的优势在于其庞大的语音库和用户友好的基于提示的控制,使其适用于各种需要不同情感声音的应用。如此多的声音 加上通过提示控制情感的能力 ,表明 EmotiVoice 专为需要各种具有不同情感表达的角色或人物的场景而设计,例如游戏或虚拟故事讲述。通过 Web 和脚本界面易于使用进一步增强了其对开发人员和内容创建者的吸引力。
EmoSphere-TTS
EmoSphere-TTS 采用球形情感向量来控制情感风格和强度 ,这是其核心思想,允许对情感进行连续控制。它使用唤醒度 (Arousal)、效价 (Valence) 和支配度 (Dominance) (AVD) 的伪标签进行情感建模,无需人工标注 ,解决了标注数据有限的挑战。该模型利用笛卡尔坐标到球坐标的转换来建模情感的复杂性 ,从而更直观地表示情感空间。它还具有双重条件对抗网络,以提高语音质量 ,表明其专注于生成高保真音频。该模型的官方实现基于 PyTorch ,使其易于被深度学习研究社区使用。
EmoSphere-TTS 通过超越离散的情感标签,转向连续的球形表示,代表了在细粒度情感控制方面的进步,可能实现更细致和真实的情感表达。使用球形情感向量 可以独立控制情感风格(球形空间中的方向)和强度(与中心的距离),与仅从预定义的情感集中选择相比,提供了一种更精细和直观的方式来操作情感。伪标签的使用进一步解决了数据稀疏问题。
Orpheus-TTS
Orpheus-TTS 是一个基于 Llama-3b 主干的最先进的开源 TTS 系统 ,这利用了 LLM 强大的语言理解能力。它展示了具有自然语调、情感和节奏的类人语音 ,声称具有卓越的质量,表明在逼真合成方面取得了重大进展。该模型提供零样本语音克隆 ,允许在没有特定训练数据的情况下合成新的声音。它还允许通过简单的标签进行引导式情感和语调控制 ,例如使用 和 等标签,为用户提供了一种友好的方式来影响输出。该模型实现了低延迟,适用于实时应用 ,延迟约为 200 毫秒,使其适用于交互式系统。
Orpheus-TTS 展示了利用大型语言模型进行语音合成的潜力,实现了高度的自然性和表现力,包括有效捕捉和传达情感的能力。使用像 Llama-3b 这样强大的 LLM 为 Orpheus 提供了强大的语言理解能力,这可能有助于其生成更自然和情感恰当的语音。零样本语音克隆和情感标签进一步增强了其在各种应用中的多功能性和易用性。
技术解析:原理、思想与实现
情感标签的整合:嵌入技术与条件机制
早期的方法在训练期间使用 one-hot 编码的情感嵌入 ,这是一种表示离散情感的直接方式。后来的工作普及了使用全局风格令牌 (Global Style Tokens, GST) 来进行说话风格的无监督学习,隐式地捕捉情感 。这使得在没有显式标签的情况下学习富有表现力的风格成为可能。情感相关的潜在表示通常从参考音频中学习 ,将情感视为一种需要迁移的风格。一些方法涉及在小型情感数据集上微调预训练的 TTS 模型 ,这是将通用 TTS 模型适应于情感的常用方法。图神经网络 (Graph Neural Networks, GNN) 正在被探索,通过考虑句子依赖关系和文本情感来学习隐式情感表示 ,旨在捕捉语境情感线索。显式情感表示可以通过参考音频上的语音情感识别 (Speech Emotion Recognition, SER) 任务来学习 ,使用 SER 作为辅助任务。文本的情感信息也可以用于增强表现力 ,Snippet 提到了情感编码器,突出了文本线索的作用。最近的方法使用情感自适应球形向量来建模情感风格和强度 ,允许对情感进行连续控制。
情感整合技术的演变反映了从显式、离散标签到更隐式、连续和上下文感知的表示的转变,旨在实现情感表达的更大灵活性和细微差别。从 one-hot 编码 到 GST ,再到更复杂的方法(如 GNN 和球形向量 ),展示了在更细致的方式下捕捉情感复杂性的进步,而不是仅仅将其分类为几个离散状态。这使得在合成语音中能够更丰富、更真实地描绘人类情感。利用语音情感识别和情感分析等辅助任务可以为指导 TTS 模型生成情感恰当的语音提供有价值的信息。通过训练 TTS 模型同时识别语音中的情感 或理解文本的情感 ,该模型可以学习输入和期望的情感输出之间更好的映射,从而产生更准确、更具表现力的合成。这种多任务学习方法可以提高模型对语言、语音和情感之间关系的理解。
韵律控制:音高和时长操作方法
早期的基于规则的系统根据情感规则直接操作音高和时长 ,其中特定规则规定了这些声学特征对于不同情感应如何变化。连接式 TTS 系统可以通过操作语音片段的音高、时长和幅度来修改韵律 ,从而实现一定程度的情感色彩。基于 HMM 的 TTS 等参数方法通过调整统计参数提供了更大的韵律控制灵活性 ,为影响韵律特征提供了一种更系统的方法。神经 TTS 模型从训练数据中隐式地学习预测韵律 ,其中深度学习模型可以捕获复杂的韵律模式。FastSpeech2 等模型中的变异适配器用于引入音高、时长和能量的变化 ,提供了一种控制这些关键韵律元素的方法。一些研究探索了对音高均值和显著性等韵律因素的显式控制 ,旨在更直接地操作韵律特征以表达情感。
虽然早期的方法依赖于对韵律特征的显式操作,但现代神经网络越来越能够从数据中隐式地学习和生成适合不同情感的韵律。从手动规则控制 到统计建模 ,最终到端到端神经网络 ,展示了一种趋势,即让模型直接从数据中学习情感和韵律之间复杂的关系,减少了手动特征工程的需求,并可能捕获更细微的韵律线索。除了情感之外,显式控制韵律特征的能力可以对合成语音的表现力提供更精细的控制。虽然隐式学习很强大,但在需要特定的韵律特征来传达某些情感细微差别或出于风格目的的情况下,提供对音高和时长等参数的显式控制 可能很有价值,从而允许对生成的语音进行更精确的艺术或功能控制。
强化学习的作用:融入用户反馈以增强情感表达
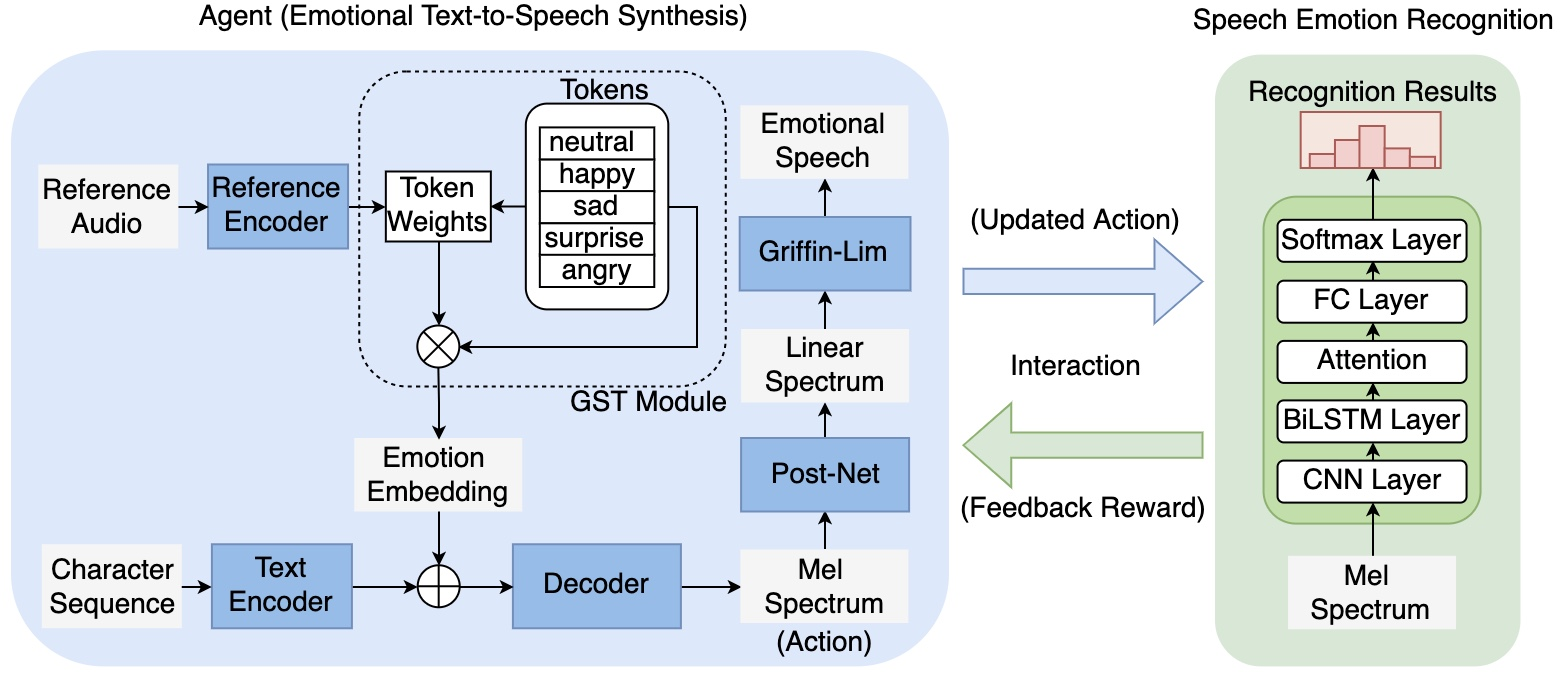
强化学习 (Reinforcement Learning, RL) 正被探索用于通过与语音情感识别 (SER) 模型交互来直接提高 TTS 中的情感可辨别性 。Snippet 详细介绍了 i-ETTS 框架,这是一项在情感 TTS 中使用 RL 的早期研究。这种方法旨在优化感知准确性。在 i-ETTS 中,TTS 模型充当代理,预测情感声学特征(动作),预训练的 SER 模型提供情感识别准确性的反馈(奖励)。Snippet 解释了这种交互式范式,其中奖励信号引导 TTS 模型生成更容易被 SER 模型分类的语音。策略梯度策略用于根据奖励优化 TTS 模型 。Snippet 提到了这种优化技术,允许平滑的反向传播和学习。人工智能反馈强化学习 (Reinforcement Learning with AI Feedback, RLAIF) 正在被研究,通过使用情感预测模型的反馈来使 TTS 模型与情感表达对齐 。Snippet 讨论了这种方法,利用 AI 模型提供可扩展的反馈来训练情感表达。不确定性感知优化 (Uncertainty-Aware Optimization, UNO) 是另一个受 RL 启发的框架,旨在基于人类反馈优化 TTS,而无需奖励模型或偏好数据 。Snippet 详细介绍了 UNO,它直接最大化语音生成的效用,同时考虑主观人类评估的不确定性。
强化学习为优化情感化 TTS 提供了一个有希望的途径,它通过直接结合对感知到的情感的反馈(来自 AI 模型或未来可能来自人类用户)来实现这一点。传统的 TTS 训练方法通常依赖于重构损失,这可能与人类感知合成语音中的情感的方式没有直接关联。RL 允许使用与期望结果(准确的情感表达)更一致的奖励信号,从而可能产生更具感知说服力的情感 TTS,因为它直接针对目标指标进行优化。在情感化 TTS 的背景下探索不同的 RL 技术(如策略梯度、RLAIF 和 UNO)表明,这是一个积极的研究领域,专注于利用反馈来提高性能。正在研究的各种 RL 方法 表明,研究人员正在探索不同的方式来有效地利用反馈指导情感化 TTS 模型的训练,认识到没有一种万能的解决方案,不同的 RL 范式可能更适合情感表达的不同方面。
幕后剖析:开源模型中的网络结构、损失函数和训练数据考量
许多开源情感化 TTS 模型建立在 Tacotron2 、FastSpeech2 和 VITS 等架构之上。这些都是在通用 TTS 领域表现良好的成熟架构。Transformer 是这些架构中用于序列建模的常见组件 ,它们在捕获语音中的长距离依赖关系方面非常有效。使用了各种损失函数,包括用于声学特征的均方误差 (Mean Squared Error, MSE) 以及可能用于情感识别的辅助损失 。Snippet 提到了 MSE 损失,这是一种用于回归任务(如预测声学特征)的标准损失函数。训练数据通常包括 ESD 、IEMOCAP 等情感语音数据集 。这些数据集的大小和质量对于模型学习不同的情感表达至关重要。Snippet 突出了某些常见情感语音数据集的特征。说话人嵌入通常用于捕获说话人身份 ,从而实现多说话人情感 TTS。HiFi-GAN 和 BigVGAN 等声码器用于从声学特征合成最终的语音波形,重点在于生成高保真音频。
在情感化 TTS 研究中依赖 Tacotron2 和 FastSpeech2 等成熟的 TTS 架构表明,这些模型为融入情感表现力提供了坚实的基础。Tacotron2 和 FastSpeech2 在通用 TTS 中的成功可能使其成为情感化 TTS 研究的有吸引力的起点,使研究人员能够专注于如何最好地将情感相关信息整合到这些已被充分理解的框架中,并利用其在文本到语音转换方面的现有优势。训练数据的选择显著影响合成语音的情感范围和自然度。情感语音数据集的可用性和可变性有限仍然是一个挑战。数据驱动模型的性能很大程度上取决于其训练所用的数据。高质量情感语音数据集()的稀缺性限制了模型学习完整的人类情感并很好地泛化到不同说话人和情况的能力。可用数据集的特征和局限性(Snippet )直接影响训练后模型的能力。
研究热点与潜在突破
迈向更细粒度的情感控制与表现力
研究正朝着比离散标签更精细地控制情感的方向发展,探索唤醒度、效价和支配度 (AVD) 等连续情感维度 。EmoSphere-TTS 等模型体现了这一趋势。开发能够捕捉和合成情感类别中细微变化的模型是关键的重点 ,旨在实现比平均情感风格更细致的情感控制。使用自然语言情感描述的基于提示的控制是一个新兴领域 ,为情感控制提供了更直观的用户界面。
情感化 TTS 的未来在于实现对情感更细致、更连续的控制,超越有限的预定义类别。使用 AVD 或自然语言提示 等连续维度控制情感,有望合成更广泛、更真实的情感表达,更好地反映人类情感的复杂性。
探索跨语言和个性化情感语音合成
将情感化 TTS 扩展到英语和普通话以外的更多语言是一个积极的研究领域 ,EmotiVoice 等项目已经支持多种语言。根据用户偏好或语境个性化合成语音的情感风格是未来的一个方向 ,旨在提供更定制化和更具吸引力的用户体验。跨语言情感迁移(在不同语言之间翻译语音时准确传达情感)正在被探索 ,这是全球交流的一个关键方面。
使情感化 TTS 能够跨不同语言使用并适应个人用户,将显著扩大其适用性和影响力。在一个日益全球化的世界中,以多种语言合成情感语音 对于接触不同的受众至关重要。此外,根据个人偏好定制情感表达 可以带来更具吸引力和以用户为中心的应用,增强人机交互的连接感和自然感。
语境理解在情感化语音合成中的融合
融入对周围语境的更深层次理解以生成情感恰当的语音仍然是一个挑战,也是一个关键的未来方向 。模型需要能够跟踪和整合正在进行的对话中的语境信息 ,当前的模型通常难以在不同轮次之间保持连贯性。语义理解对于生成语境恰当的情感语音至关重要 ,尤其是在理解讽刺等细微差别方面。
真正的情感智能化 TTS 需要对语音发生的语境有深刻的理解,使系统能够生成不仅准确而且适合情境的情感。人类的情感表达高度依赖于语境。为了使 TTS 听起来真正自然和富有同情心,它需要超越简单地识别文本中的情感标签,并理解更广泛的对话语境 ,以生成符合情境的情感反应,从而有助于连贯和有意义的交互。
该领域的新兴趋势与潜在突破
使用大型语言模型 (Large Language Models, LLM) 作为 TTS 的骨干网络在自然度和表现力方面显示出令人鼓舞的结果 ,Orpheus 等模型展示了人类水平的语音生成能力。扩散模型正越来越多地被探索用于高质量语音合成,包括情感化 TTS ,它们擅长生成逼真且多样的输出。具有情感迁移能力的零样本语音克隆是一个重要的进步 ,允许灵活和个性化的语音合成。开发更复杂的评估指标以更好地反映人类对合成语音中情感的感知至关重要 ,因为当前的指标可能无法完全捕捉情感的主观性。
大型语言模型、扩散模型和零样本学习的进步正在融合,有望在情感化 TTS 的质量、可控性和多功能性方面带来重大突破。LLM 提供强大的语言理解能力,扩散模型 实现高保真生成,零样本学习 允许以最少的数据适应新的声音和情感。结合这些强大的技术,情感化 TTS 有望达到新的逼真度和表现力水平。
表一:情感化语音合成未来研究方向
| 研究方向 | 潜在技术/方法 | 潜在影响/益处 |
|---|---|---|
| 更细粒度的情感控制 | 连续情感维度 (AVD) | 更逼真和细致的情感表达 |
| 跨语言合成 | 情感迁移学习 | 更广泛的适用性和可访问性 |
| 个性化情感风格 | 用户建模 | 定制化的用户体验 |
| 语境理解 | 语境编码机制 | 更自然和连贯的交互 |
| 与 LLM 和扩散模型集成 | 利用生成模型 | 更高质量和更多功能的合成 |