MLLM之Bench:LEGO-Puzzles的简介、安装和使用方法、案例应用之详细攻略
MLLM之Bench:LEGO-Puzzles的简介、安装和使用方法、案例应用之详细攻略
目录
LEGO-Puzzles的简介
1、LEGO-Puzzles的特点
LEGO-Puzzles的安装和使用方法
1、安装
步骤 0:安装 VLMEvalKit
步骤 1:设置 API 密钥(可选)
步骤 2:在 LEGO-Puzzles 上运行评估
推理 + 评估:
仅推理:
多 GPU 加速(可选):
LEGO-Puzzles的案例应用
LEGO-Puzzles的简介
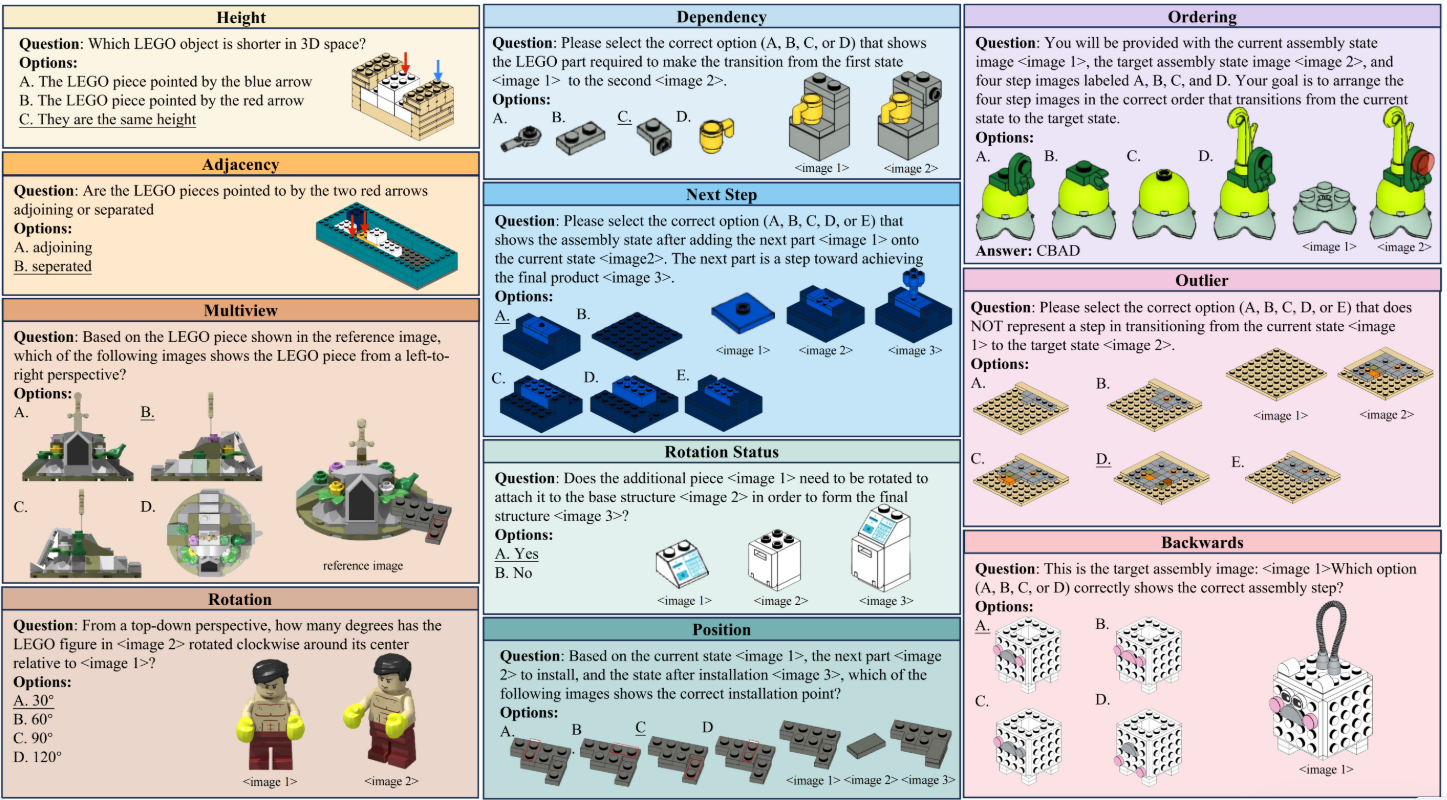
2025年4月,LEGO-Puzzles是一个用于评估多模态大型语言模型 (MLLM) 多步空间推理能力的基准测试。
LEGO-Puzzles 基准测试旨在系统地评估多模态大型语言模型 (MLLM) 的多步空间推理能力。它以乐高积木搭建为灵感,将空间理解定义为一系列乐高积木组装任务,这些任务需要模型同时具备视觉感知和顺序推理能力。 该基准测试包含三种核心任务类型:空间理解、单步顺序推理和多步顺序推理。 除了传统的视觉问答 (VQA) 任务外,LEGO-Puzzles 还包含图像生成任务,评估 MLLM 是否能够模拟结构转换并预测未来的组装状态。为了方便人类与模型进行比较,LEGO-Puzzles 还提供了一个精简的子集 LEGO-Puzzles-Lite,以及一个名为 Next-k-Step 的细粒度评估套件,用于测试在日益复杂的条件下推理的可扩展性。
总而言之,LEGO-Puzzles 提供了一个基于乐高积木的基准测试,用于评估 MLLM 的多步空间推理能力,其结果表明当前的 MLLM 在此方面仍有很大的提升空间。 该基准测试易于使用,并与 VLMEvalKit 框架集成,方便研究者进行模型评估。
GitHub地址:https://github.com/Tangkexian/LEGO-Puzzles
1、LEGO-Puzzles的特点
● 基于乐高积木:使用乐高积木搭建场景作为测试对象,直观易懂,便于理解和解释结果。
● 多任务类型:包含空间理解、单步顺序推理和多步顺序推理三种核心任务类型,以及图像生成任务,全面评估空间推理能力。
● 可扩展性:通过 Next-k-Step 评估套件,可以测试模型在不同步数下的推理能力。
● 可解释性:任务设计清晰,结果易于解释,方便分析模型的优缺点。
● 包含图像生成任务:不仅评估问答能力,还评估模型生成图像的能力,更全面地考察空间推理能力。
● 提供精简数据集:LEGO-Puzzles-Lite 方便进行人机性能比较。
LEGO-Puzzles的安装和使用方法
LEGO-Puzzles 已完全集成到 VLMEvalKit 框架中。
1、安装
安装和使用方法如下:
步骤 0:安装 VLMEvalKit
git clone https://github.com/open-compass/VLMEvalKit.gitcd VLMEvalKitpip install -e .
步骤 1:设置 API 密钥(可选)
如果要评估基于 API 的模型(例如 GPT-4o、Gemini-Pro-V 等)或使用 LLM 作为评判模型,需要在 .env 文件中配置必要的密钥,或者将其导出为环境变量:
# Example .env (place it in VLMEvalKit root directory)OPENAI_API_KEY=your-openai-keyGOOGLE_API_KEY=your-google-api-key# ...other optional keys
如果没有提供密钥,VLMEvalKit 将默认使用精确匹配评分(仅适用于 Yes/No 或多项选择任务)。
步骤 2:在 LEGO-Puzzles 上运行评估
将数据集名称设置为 LEGO 即可运行 LEGO-Puzzles:
推理 + 评估:
python run.py --data LEGO --model <your_model_name> --verbose# Example:# python run.py --data LEGO --model idefics_80b_instruct --verbose
仅推理:
python run.py --data LEGO --model <your_model_name> --verbose --mode infer# Example:# python run.py --data LEGO --model idefics_80b_instruct --verbose --mode infer
多 GPU 加速(可选):
torchrun --nproc-per-node=4 run.py --data LEGO --model <your_model_name> --verbose# Example:# torchrun --nproc-per-node=4 run.py --data LEGO --model idefics_80b_instruct --verbose
LEGO-Puzzles的案例应用
论文评估了 20 个最先进的 MLLM,包括开源和专有模型。结果表明,尽管 GPT-4o 和 Gemini-2.0-Flash 的整体性能领先,但在需要 3D 空间对齐、旋转处理和多步组装跟踪的任务中,它们的性能仍然远低于人类注释者。 在 LEGO-Puzzles-Lite (220 个样本) 上的人类与模型性能比较中,人类始终以较大优势胜出,再次证实了当前 AI 系统在空间推理方面面临的挑战。 在 5 个基于乐高的图像生成任务中,只有 Gemini-2.0-Flash 和 GPT-4o 表现出部分成功,开源模型通常无法生成结构有效或与指令对齐的图像。 Next-k-Step 评估结果表明,思维链 (CoT) 提示并不能有效地增强多步空间推理能力。