Milvus(8):密集向量、二进制向量、稀疏向量
1 密集向量
密集向量是广泛应用于机器学习和数据分析的数值数据表示法。它们由包含实数的数组组成,其中大部分或所有元素都不为零。与稀疏向量相比,密集向量在同一维度上包含更多信息,因为每个维度都持有有意义的值。这种表示方法能有效捕捉复杂的模式和关系,使数据在高维空间中更容易分析和处理。密集向量通常有固定的维数,从几十到几百甚至上千不等,具体取决于具体的应用和要求。
密集向量主要用于需要理解数据语义的场景,如语义搜索和推荐系统。在语义搜索中,密集向量有助于捕捉查询和文档之间的潜在联系,提高搜索结果的相关性。在推荐系统中,密集矢量有助于识别用户和项目之间的相似性,从而提供更加个性化的建议。
1.1 相关概述
密集向量通常表示为具有固定长度的浮点数数组,如[0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5] 。这些向量的维度通常从数百到数千不等,如 128、256、768 或 1024。每个维度都能捕捉对象的特定语义特征,通过相似性计算使其适用于各种场景。
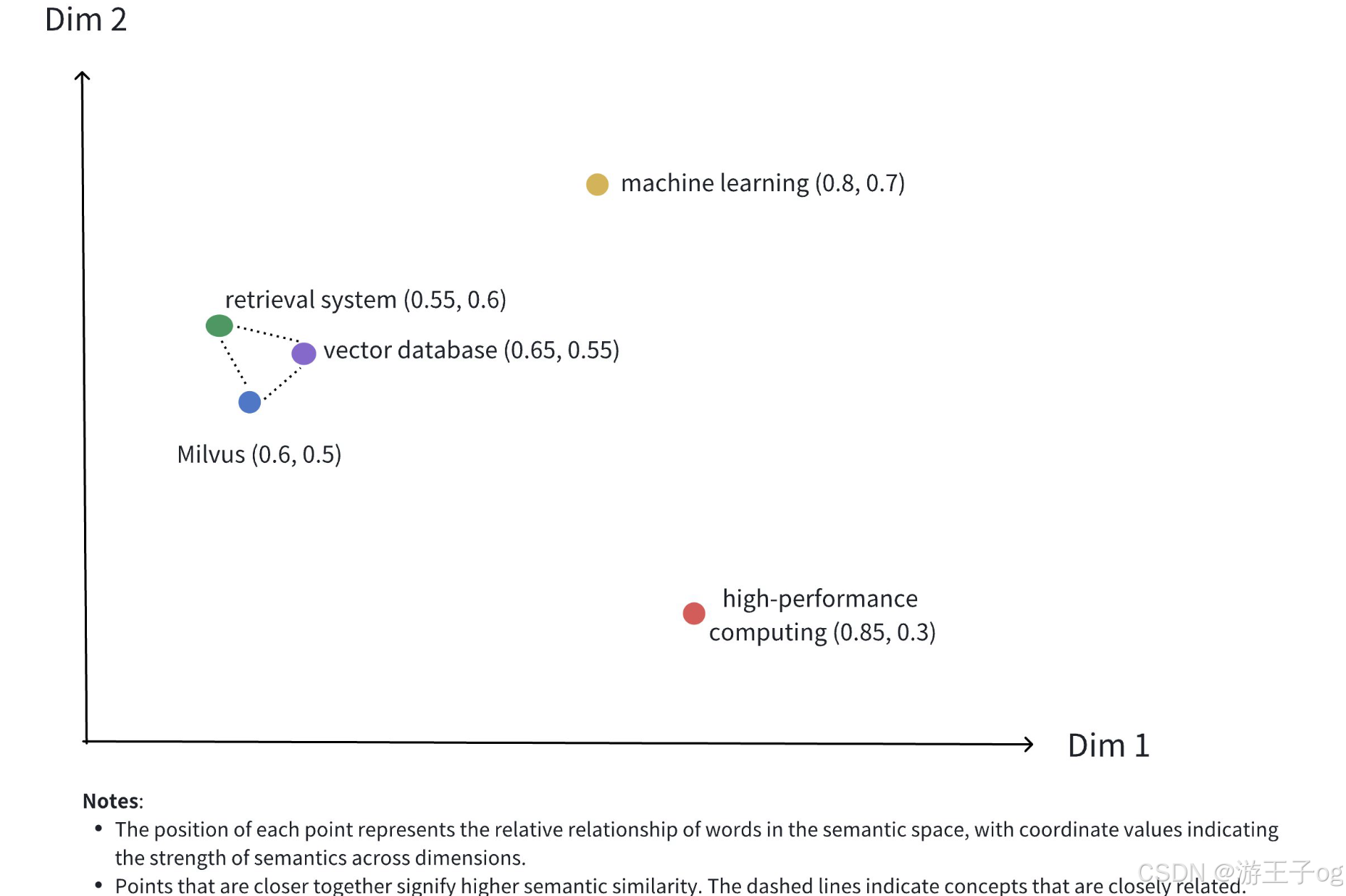
上图展示了密集向量在二维空间中的表现形式。虽然实际应用中的密集向量通常具有更高的维度,但这种二维插图有效地传达了几个关键概念:
- 多维表示:每个点代表一个概念对象(如Milvus、向量数据库、检索系统等),其位置由其维度值决定。
- 语义关系:点之间的距离反映了概念之间的语义相似性。距离较近的点表示语义关联度较高的概念。
- 聚类效应:相关概念(如Milvus、向量数据库和检索系统)在空间中的位置相互靠近,形成语义聚类。
下面是一个代表文本"Milvus is an efficient vector database" 的真实稠密向量示例:
[-0.013052909,0.020387933,-0.007869,-0.11111383,-0.030188112,-0.0053388323,0.0010654867,0.072027855,// ... more dimensions
]稠密向量可使用各种嵌入模型生成,如用于图像的 CNN 模型(如ResNet、VGG)和用于文本的语言模型(如BERT、Word2Vec)。这些模型将原始数据转化为高维空间中的点,捕捉数据的语义特征。此外,Milvus 还提供便捷的方法,帮助用户生成和处理密集向量,一旦数据被向量化,就可以存储在 Milvus 中进行管理和向量检索。下图显示了基本流程。
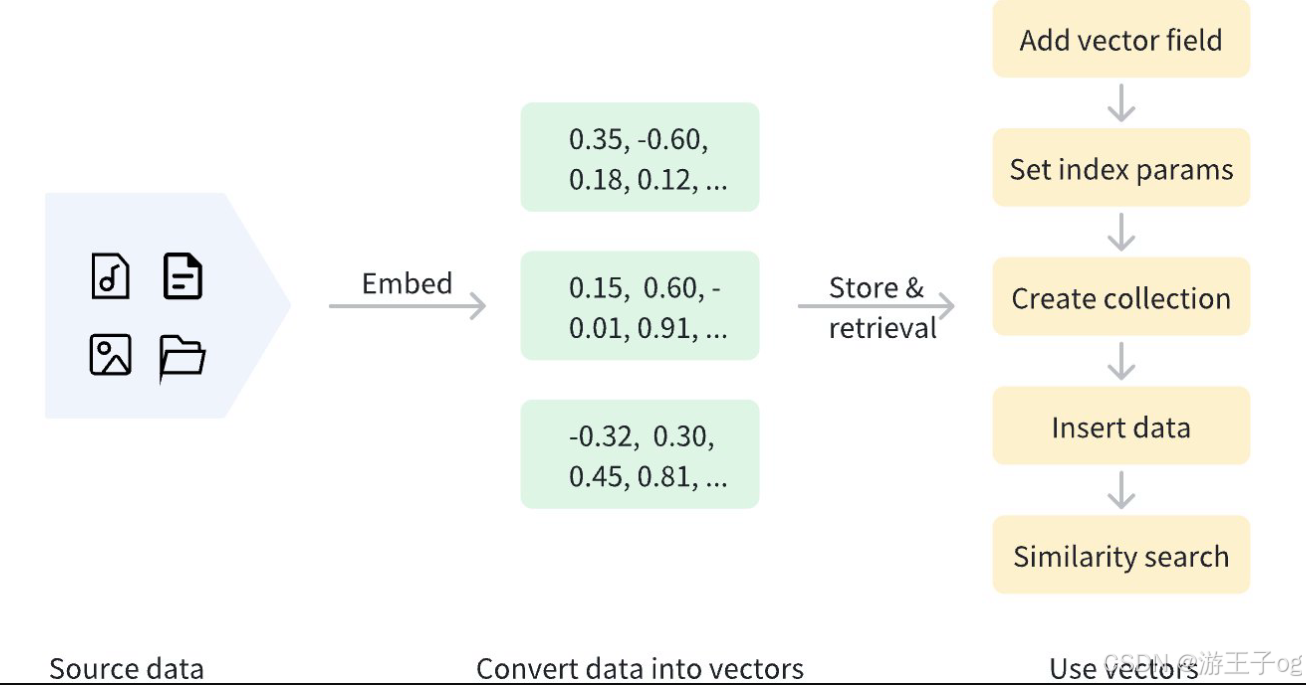
1.2 使用密集向量
1.2.1 添加向量场
要在 Milvus 中使用密集向量,首先要在创建 Collections 时定义一个用于存储密集向量的向量场。这一过程包括
- 将
datatype设置为支持的密集向量数据类型。 - 使用
dim参数指定密集向量的维数。
在下面的示例中,我们添加了一个名为dense_vector 的向量字段来存储密集向量。字段的数据类型为FLOAT_VECTOR ,维数为4 。
from pymilvus import MilvusClient, DataTypeclient = MilvusClient(uri="http://localhost:19530")schema = client.create_schema(auto_id=True,enable_dynamic_fields=True,
)schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="dense_vector", datatype=DataType.FLOAT_VECTOR, dim=4)
支持的密集向量字段数据类型:
| 数据类型 | 描述 |
|---|---|
|
| 存储 32 位浮点数,常用于表示科学计算和机器学习中的实数。非常适合需要高精度的场景,例如区分相似向量。 |
|
| 存储 16 位半精度浮点数,用于深度学习和 GPU 计算。在精度要求不高的情况下,如推荐系统的低精度召回阶段,它可以节省存储空间。 |
|
| 存储 16 位脑浮点(bfloat16)数,提供与 Float32 相同的指数范围,但精度有所降低。适用于需要快速处理大量向量的场景,如大规模图像检索。 |
1.2.2 为向量场设置索引参数
为了加速语义搜索,必须为向量场创建索引。索引可以大大提高大规模向量数据的检索效率。
index_params = client.prepare_index_params()index_params.add_index(field_name="dense_vector",index_name="dense_vector_index",index_type="AUTOINDEX",metric_type="IP"
)
在上面的示例中,使用AUTOINDEX 索引类型为dense_vector 字段创建了名为dense_vector_index 的索引。metric_type 设置为IP ,表示将使用内积作为距离度量。
Milvus 提供多种索引类型,以获得更好的向量搜索体验。AUTOINDEX 是一种特殊的索引类型,旨在平滑向量搜索的学习曲线。
1.2.3 创建 Collections
完成密集向量和索引参数设置后,就可以创建包含密集向量的 Collections。下面的示例使用create_collection 方法创建了一个名为my_collection 的集合。
client.create_collection(collection_name="my_collection",schema=schema,index_params=index_params
)1.2.4 插入数据
创建集合后,使用insert 方法添加包含密集向量的数据。确保插入的密集向量的维度与添加密集向量字段时定义的dim 值相匹配。
data = [{"dense_vector": [0.1, 0.2, 0.3, 0.7]},{"dense_vector": [0.2, 0.3, 0.4, 0.8]},
]client.insert(collection_name="my_collection",data=data
)1.2.5 执行相似性搜索
基于密集向量的语义搜索是 Milvus 的核心功能之一,可以根据向量之间的距离快速找到与查询向量最相似的数据。要执行相似性搜索,请准备好查询向量和搜索参数,然后调用search 方法。
search_params = {"params": {"nprobe": 10}
}query_vector = [0.1, 0.2, 0.3, 0.7]res = client.search(collection_name="my_collection",data=[query_vector],anns_field="dense_vector",search_params=search_params,limit=5,output_fields=["pk"]
)print(res)# Output
# data: ["[{'id': '453718927992172271', 'distance': 0.7599999904632568, 'entity': {'pk': '453718927992172271'}}, {'id': '453718927992172270', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172270'}}]"]2 二进制向量
二进制向量是一种特殊的数据表示形式,它将传统的高维浮点向量转换成只包含 0 和 1 的二进制向量。这种转换不仅压缩了向量的大小,还降低了存储和计算成本,同时保留了语义信息。当对非关键特征的精度要求不高时,二进制向量可以有效保持原始浮点向量的大部分完整性和实用性。
二进制向量有着广泛的应用,尤其是在计算效率和存储优化至关重要的情况下。在搜索引擎或推荐系统等大规模人工智能系统中,实时处理海量数据是关键所在。通过减小向量的大小,二进制向量有助于降低延迟和计算成本,而不会明显牺牲准确性。此外,二进制向量在移动设备和嵌入式系统等资源受限的环境中也很有用,因为在这些环境中,内存和处理能力都很有限。通过使用二进制向量,可以在这些受限环境中实现复杂的人工智能功能,同时保持高性能。
2.1 二进制向量概述
二进制向量是一种将复杂对象(如图像、文本或音频)编码为固定长度二进制值的方法。在 Milvus 中,二进制向量通常表示为比特数组或字节数组。例如,一个 8 维二进制向量可以表示为[1, 0, 1, 1, 0, 0, 1, 0] 。
下图显示了二进制向量如何表示文本内容中关键词的存在。在这个例子中,用一个 10 维二进制向量来表示两个不同的文本(文本 1和文本 2),其中每个维度对应词汇表中的一个词:1 表示文本中存在该词,0 表示文本中没有该词。
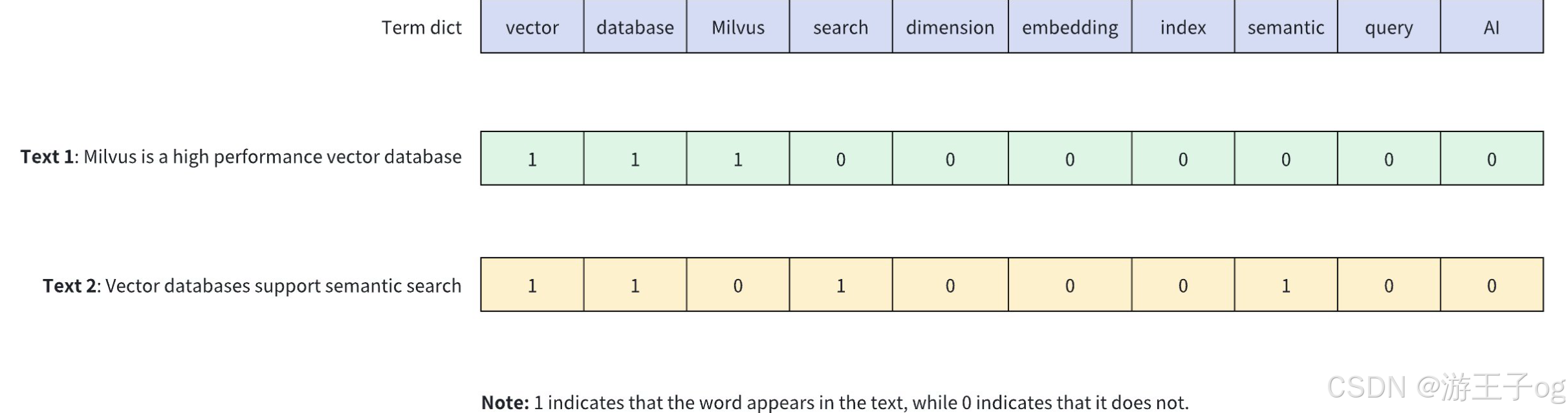
二进制向量具有以下特点:
- 高效存储:每个维度只需 1 位存储空间,大大减少了存储空间。
- 快速计算:使用 XOR 等位运算可以快速计算向量间的相似性。
- 固定长度:无论原始文本的长度如何,向量的长度保持不变,从而使索引和检索更加容易。
- 简单直观:直接反映关键词的存在,适合某些专业检索任务。
二进制向量可以通过各种方法生成。在文本处理中,可以使用预定义的词汇表,根据词的存在设置相应的位。在图像处理中,感知哈希算法(如pHash)可以生成图像的二进制特征。在机器学习应用中,可对模型输出进行二进制化,以获得二进制向量表示。二进制向量化后,数据可以存储在 Milvus 中,以便进行管理和向量检索。下图显示了基本流程。
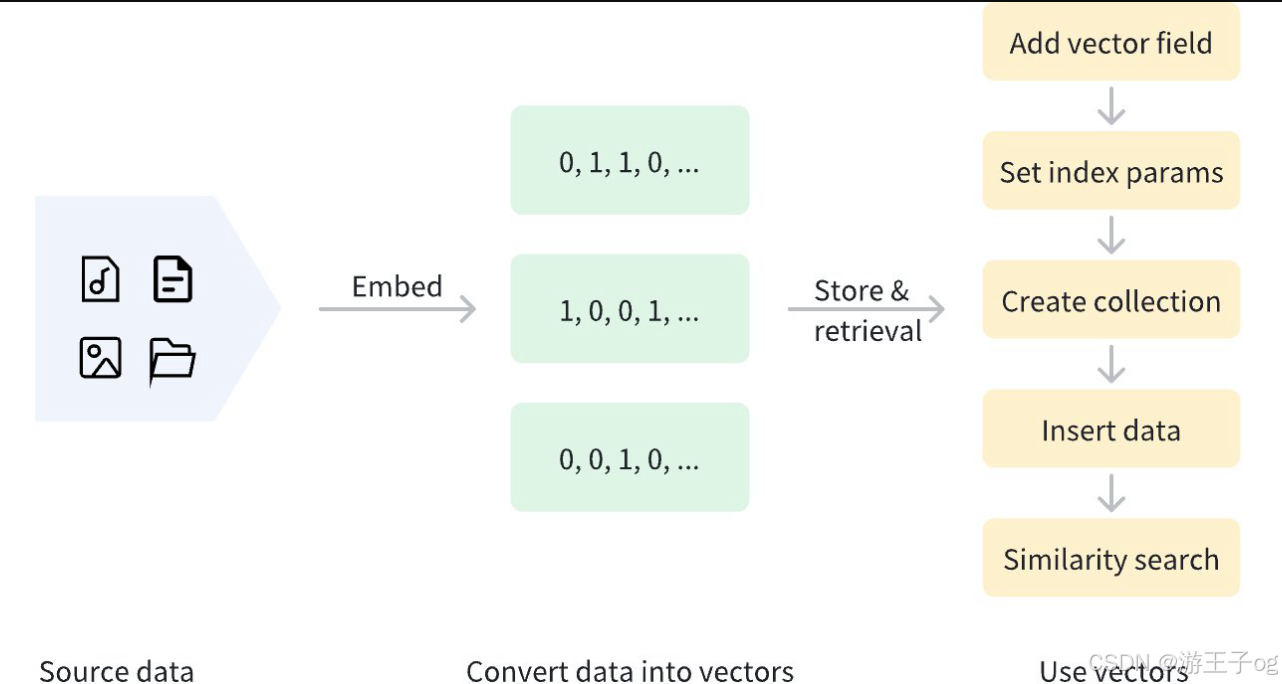
虽然二进制向量在特定场景中表现出色,但其表达能力存在局限性,难以捕捉复杂的语义关系。因此,在实际应用场景中,二进制向量通常与其他向量类型一起使用,以平衡效率和表达能力。
2.2 使用二进制向量
2.2.1 添加向量场
要在 Milvus 中使用二进制向量,首先要在创建 Collections 时定义一个用于存储二进制向量的向量场。这一过程包括
- 将
datatype设置为支持的二进制向量数据类型,即BINARY_VECTOR。 - 使用
dim参数指定向量的维数。请注意,dim必须是 8 的倍数,因为二进制向量在插入时必须转换成字节数组。每 8 个布尔值(0 或 1)将打包成 1 个字节。例如,如果dim=128,插入时需要一个 16 字节数组。
from pymilvus import MilvusClient, DataTypeclient = MilvusClient(uri="http://localhost:19530")schema = client.create_schema(auto_id=True,enable_dynamic_fields=True,
)schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="binary_vector", datatype=DataType.BINARY_VECTOR, dim=128) 在此示例中,添加了一个名为binary_vector 的向量字段,用于存储二进制向量。该字段的数据类型为BINARY_VECTOR ,维数为 128。
2.2.2 为向量字段设置索引参数
为了加快搜索速度,必须为二进制向量字段创建索引。索引可以大大提高大规模向量数据的检索效率。
index_params = client.prepare_index_params()index_params.add_index(field_name="binary_vector",index_name="binary_vector_index",index_type="AUTOINDEX",metric_type="HAMMING"
)
在上面的示例中,使用AUTOINDEX 索引类型为binary_vector 字段创建了名为binary_vector_index 的索引。metric_type 设置为HAMMING ,表示使用汉明距离进行相似性测量。Milvus 提供多种索引类型,以获得更好的向量搜索体验。AUTOINDEX 是一种特殊的索引类型,旨在平滑向量搜索的学习曲线。此外,Milvus 还支持二进制向量的其他相似度度量。
2.2.3 创建 Collections
二进制向量和索引设置完成后,创建一个包含二进制向量的 Collections。下面的示例使用create_collection 方法创建了一个名为my_collection 的 Collection。
client.create_collection(collection_name="my_collection",schema=schema,index_params=index_params
)2.2.4 插入数据
创建集合后,使用insert 方法添加包含二进制向量的数据。请注意,二进制向量应以字节数组的形式提供,其中每个字节代表 8 个布尔值。例如,对于 128 维的二进制向量,需要一个 16 字节的数组(因为 128 位 ÷ 8 位/字节 = 16 字节)。下面是插入数据的示例代码:
def convert_bool_list_to_bytes(bool_list):if len(bool_list) % 8 != 0:raise ValueError("The length of a boolean list must be a multiple of 8")byte_array = bytearray(len(bool_list) // 8)for i, bit in enumerate(bool_list):if bit == 1:index = i // 8shift = i % 8byte_array[index] |= (1 << shift)return bytes(byte_array)bool_vectors = [[1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112,[0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1] + [0] * 112,
]data = [{"binary_vector": convert_bool_list_to_bytes(bool_vector) for bool_vector in bool_vectors}]client.insert(collection_name="my_collection",data=data
)2.2.5 执行相似性搜索
相似性搜索是 Milvus 的核心功能之一,可以根据向量间的距离快速找到与查询向量最相似的数据。要使用二进制向量执行相似性搜索,请准备好查询向量和搜索参数,然后调用search 方法。
在搜索操作过程中,还必须以字节数组的形式提供二进制向量。确保查询向量的维度与定义dim 时指定的维度相匹配,并且每 8 个布尔值转换为 1 个字节。
search_params = {"params": {"nprobe": 10}
}query_bool_list = [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112
query_vector = convert_bool_list_to_bytes(query_bool_list)res = client.search(collection_name="my_collection",data=[query_vector],anns_field="binary_vector",search_params=search_params,limit=5,output_fields=["pk"]
)print(res)# Output
# data: ["[{'id': '453718927992172268', 'distance': 10.0, 'entity': {'pk': '453718927992172268'}}]"] 3 稀疏向量
稀疏向量是信息检索和自然语言处理中一种重要的数据表示方法。虽然密集向量因其出色的语义理解能力而广受欢迎,但在涉及需要精确匹配关键词或短语的应用时,稀疏向量往往能提供更精确的结果。
3.1 稀疏向量概述
稀疏向量是高维向量的一种特殊表示形式,其中大部分元素为零,只有少数维度具有非零值。这一特性使得稀疏向量在处理大规模、高维但稀疏的数据时特别有效。常见的应用包括
- 文本分析:将文档表示为词袋向量,其中每个维度对应一个单词,只有在文档中出现的单词才有非零值。
- 推荐系统:用户-物品交互矩阵,其中每个维度代表用户对特定物品的评分,大多数用户只与少数物品交互。
- 图像处理:局部特征表示,只关注图像中的关键点,从而产生高维稀疏向量。
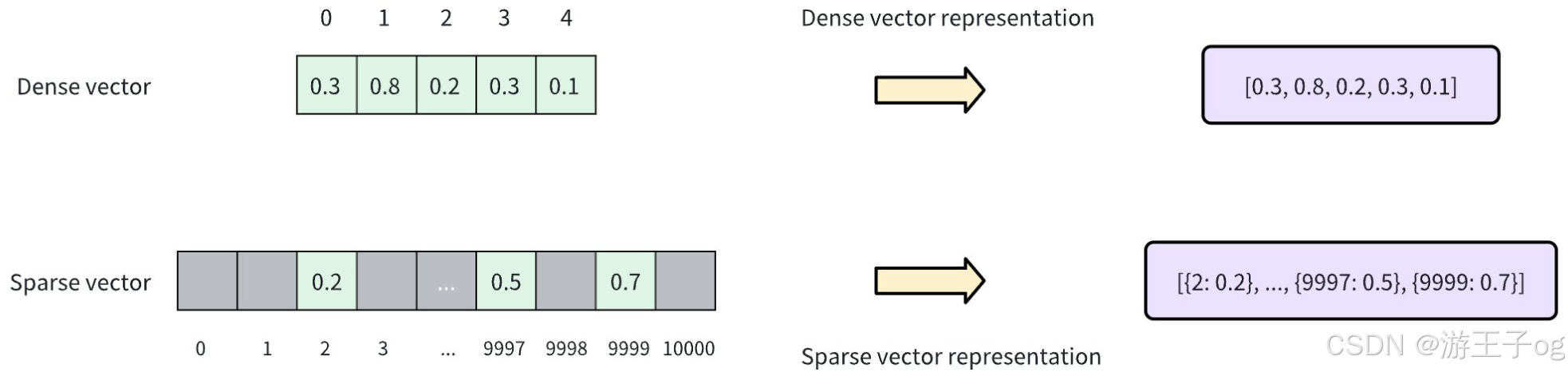
如下图所示,密集向量通常表示为连续数组,其中每个位置都有一个值(如[0.3, 0.8, 0.2, 0.3, 0.1] )。相比之下,稀疏向量只存储非零元素及其索引,通常表示为键值对(如[{2: 0.2}, ..., {9997: 0.5}, {9999: 0.7}] )。这种表示方法大大减少了存储空间,提高了计算效率,尤其是在处理极高维数据(如 10,000 维)时。
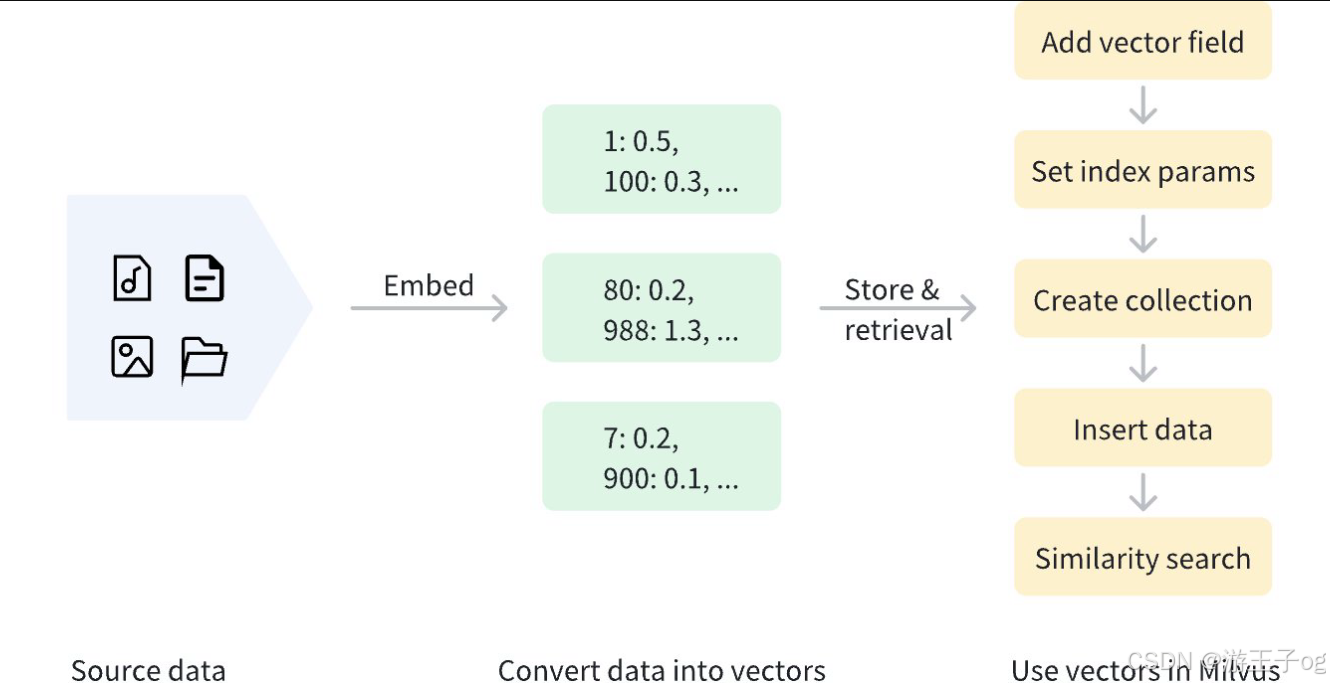
稀疏向量可以使用多种方法生成,例如文本处理中的TF-IDF(词频-反向文档频率)和BM25。此外,Milvus 还提供了帮助生成和处理稀疏向量的便捷方法。对于文本数据,Milvus 还提供全文搜索功能,可以直接在原始文本数据上执行向量搜索,而无需使用外部嵌入模型来生成稀疏向量。矢量化后,数据可存储在 Milvus 中进行管理和矢量检索。下图说明了基本流程。
3.2 使用稀疏向量
Milvus 支持以下列任何一种格式表示稀疏向量:
稀疏矩阵(使用scipy.sparse 类)
from scipy.sparse import csr_matrix# 创建一个稀疏矩阵
row = [0, 0, 1, 2, 2, 2]
col = [0, 2, 2, 0, 1, 2]
data = [1, 2, 3, 4, 5, 6]
sparse_matrix = csr_matrix((data, (row, col)), shape=(3, 3))# 用稀疏矩阵表示稀疏向量
sparse_vector = sparse_matrix.getrow(0) 字典列表(格式为{dimension_index: value, ...})
# 使用字典表示稀疏向量
sparse_vector = [{1: 0.5, 100: 0.3, 500: 0.8, 1024: 0.2, 5000: 0.6}] 元组迭代器列表(格式如[(dimension_index, value)])
# 使用元组列表表示稀疏向量
sparse_vector = [[(1, 0.5), (100, 0.3), (500, 0.8), (1024, 0.2), (5000, 0.6)]]3.2.1 添加向量场
要在 Milvus 中使用稀疏向量,请在创建 Collections 时定义一个用于存储稀疏向量的字段。这个过程包括
- 将
datatype设置为支持的稀疏向量数据类型,即SPARSE_FLOAT_VECTOR。 - 无需指定维度。
from pymilvus import MilvusClient, DataTypeclient = MilvusClient(uri="http://localhost:19530")schema = client.create_schema(auto_id=True,enable_dynamic_fields=True,
)schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR) 在此示例中,添加了一个名为sparse_vector 的向量字段,用于存储稀疏向量。该字段的数据类型为SPARSE_FLOAT_VECTOR 。
3.2.2 为向量字段设置索引参数
为稀疏向量创建索引的过程与为密集向量创建索引的过程类似,但在指定的索引类型 (index_type)、距离度量 (metric_type) 和索引参数 (params) 上有所不同。
index_params = client.prepare_index_params()index_params.add_index(field_name="sparse_vector",index_name="sparse_inverted_index",index_type="SPARSE_INVERTED_INDEX",metric_type="IP",params={"inverted_index_algo": "DAAT_MAXSCORE"}, # or "DAAT_WAND" or "TAAT_NAIVE"
)
在上面的示例中
index_type:为稀疏向量场创建的索引类型。SPARSE_INVERTED_INDEX:稀疏向量的通用反转索引。metric_type:用于计算稀疏向量之间相似性的度量。有效值:IP(内积):使用点积来衡量相似性。BM25:通常用于全文搜索,侧重于文本相似性。params.inverted_index_algo:用于建立和查询索引的算法。有效值:"DAAT_MAXSCORE"(默认):使用 MaxScore 算法进行优化的 Document-at-a-Time (DAAT) 查询处理。MaxScore 通过跳过可能影响最小的术语和文档,为高k值或包含大量术语的查询提供更好的性能。为此,它根据最大影响分值将术语划分为基本组和非基本组,并将重点放在对前 k 结果有贡献的术语上。"DAAT_WAND":使用 WAND 算法优化 DAAT 查询处理。WAND 算法利用最大影响分数跳过非竞争性文档,从而评估较少的命中文档,但每次命中的开销较高。这使得 WAND 对于k值较小的查询或较短的查询更有效,因为在这些情况下跳过更可行。"TAAT_NAIVE":基本术语一次查询处理(TAAT)。虽然与DAAT_MAXSCORE和DAAT_WAND相比速度较慢,但TAAT_NAIVE具有独特的优势。DAAT 算法使用的是缓存的最大影响分数,无论全局 Collections 参数(avgdl)如何变化,这些分数都保持静态,而TAAT_NAIVE不同,它能动态地适应这种变化。
3.2.3 创建 Collections
完成稀疏向量和索引设置后,就可以创建包含稀疏向量的 Collections。下面的示例使用create_collection 方法创建了一个名为my_collection 的集合。
client.create_collection(collection_name="my_collection",schema=schema,index_params=index_params
)3.2.4 插入数据
创建集合后,插入包含稀疏向量的数据。
sparse_vectors = [{"sparse_vector": {1: 0.5, 100: 0.3, 500: 0.8}},{"sparse_vector": {10: 0.1, 200: 0.7, 1000: 0.9}},
]client.insert(collection_name="my_collection",data=sparse_vectors
)3.2.5 执行相似性搜索
要使用稀疏向量执行相似性搜索,请准备好查询向量和搜索参数。
#准备搜索参数
search_params = {"params": {"drop_ratio_search": 0.2}, # 一个可调的跌落比参数,有效范围在0到1之间
}# 准备查询向量
query_vector = [{1: 0.2, 50: 0.4, 1000: 0.7}] 在本例中,drop_ratio_search 是专门针对稀疏向量的可选参数,允许在搜索过程中对查询向量中的小值进行微调。例如,使用{"drop_ratio_search": 0.2} ,查询向量中最小的 20% 值将在搜索过程中被忽略。然后,使用search 方法执行相似性搜索:
res = client.search(collection_name="my_collection",data=query_vector,limit=3,output_fields=["pk"],search_params=search_params,
)print(res)# Output
# data: ["[{'id': '453718927992172266', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172266'}}, {'id': '453718927992172265', 'distance': 0.10000000149011612, 'entity': {'pk': '453718927992172265'}}]"]