四 YARN配置和HBase配置
文章目录
- 零 前置条件
- 一 YARN应用
- 操作一 配置yarn-site.xml和mapred-site.xml文件
- 操作二 将配置文件同步到其它节点,集群启动YARN;启动备用节点RM
- 操作三 Web查看YARN和测试YARN
- 注意:
- 二 HBase应用
- 操作一 官网下载 HBase压缩包
- 操作二 修改4个配置文件;拷贝HDFS的2个配置文件;创建HBase日志目录
- 操作三 hbase-1.2.0-cdh5.10.0 同步到其他节点,并创建软链接;集群启动hbase
- 操作四 web查看hbase
- 注意
零 前置条件
-
zookeeper已成功配置;hdfs已成功配置;FinalShell连接3个虚拟节点
-
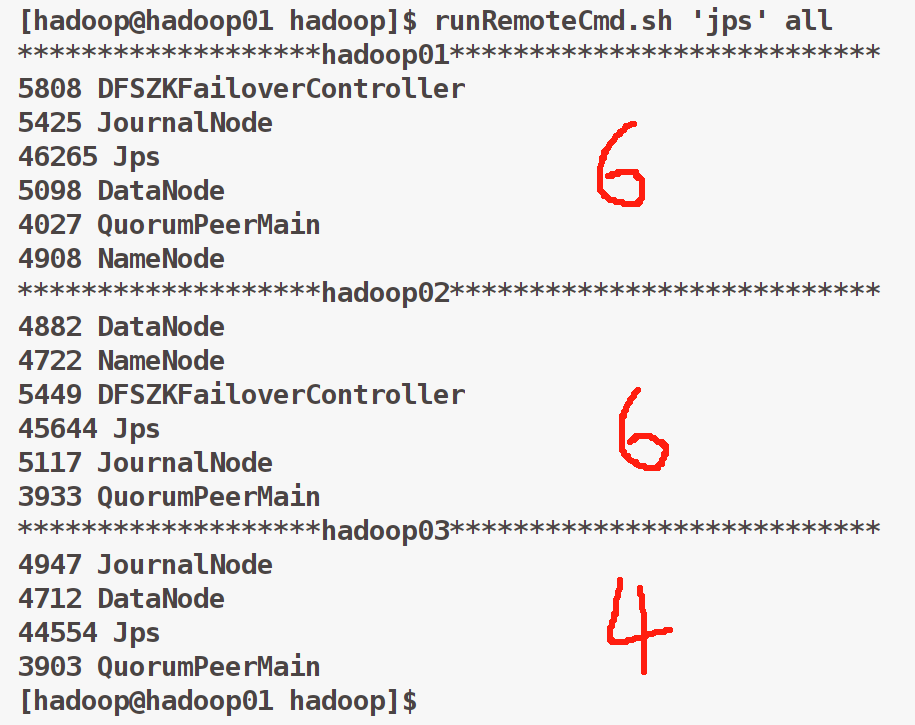
先开启zookeeper,后开启hdfs,jps查看当前集群的进程,如图所示
一 YARN应用
操作一 配置yarn-site.xml和mapred-site.xml文件
# yarn-site.xml
<configuration><property><name>yarn.resourcemanager.connect.retry-interval.ms</name><value>2000</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.ha.automatic-failover.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.ha.automatic-failover.embedded</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>yarn-rm-cluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop01</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop02</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.zk.state-store.address</name><value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value></property><property><name>yarn.resourcemanager.zk-address</name><value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value></property><property><name>yarn.resourcemanager.address.rm1</name><value>hadoop01:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>hadoop01:8034</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>hadoop01:8088</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>hadoop02:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>hadoop02:8034</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>hadoop02:8088</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
</configuration># mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>操作二 将配置文件同步到其它节点,集群启动YARN;启动备用节点RM
- 集群同步节点到其余节点,在目录[/home/hadoop/etc/hadoop]下执行
deploy.sh yarn-site.xml ~/app/hadoop/etc/hadoop slave
deploy.sh mapred-site.xml ~/app/hadoop/etc/hadoop slave
- 启动YARN和备用节点,在[/home/hadoop/app/hadoop]目录下执行
# hadoop01
sbin/start-yarn.sh # 如果HDFS未启动,可sbin/start-all.sh (包括HDFS和YARN)# 关闭yarn
sbin/stop-yarn.sh
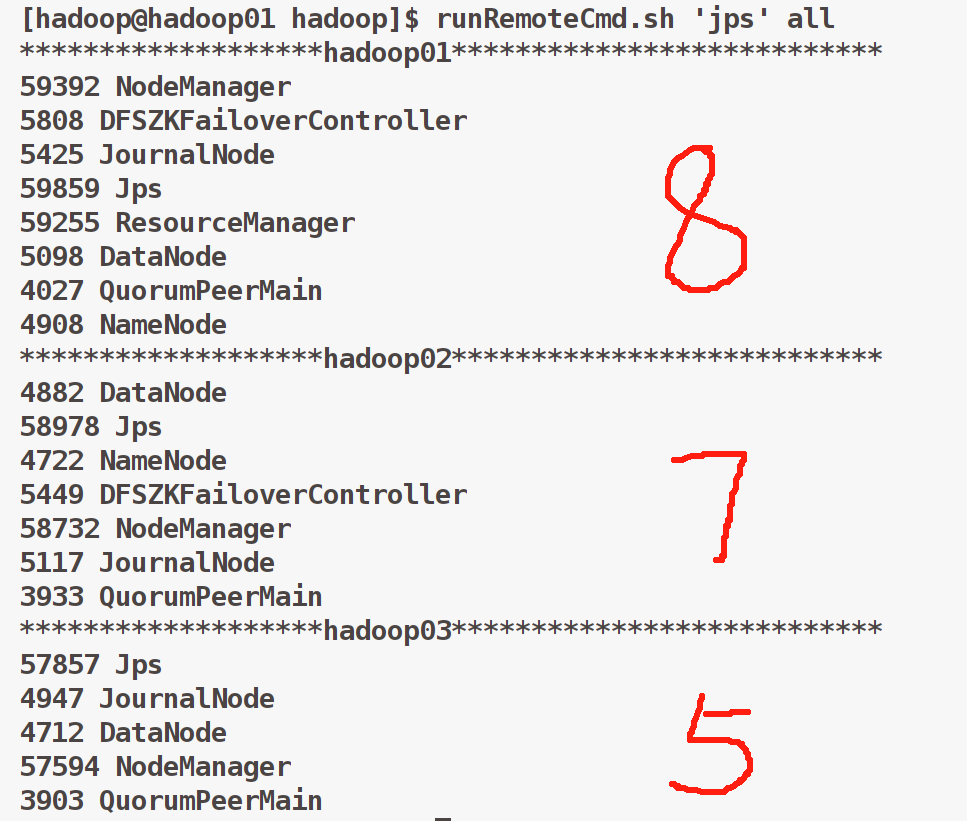
# hadoop02启动备用节点RM,在目录[/home/hadoop/app/hadoop]下执行
sbin/yarn-daemon.sh start resourcemanager# 关闭备用RM
sbin/yarn-daemon.sh stop resourcemanager

- 查看RM状态
bin/yarn rmadmin -getServiceState rm1
bin/yarn rmadmin -getServiceState rm2
操作三 Web查看YARN和测试YARN
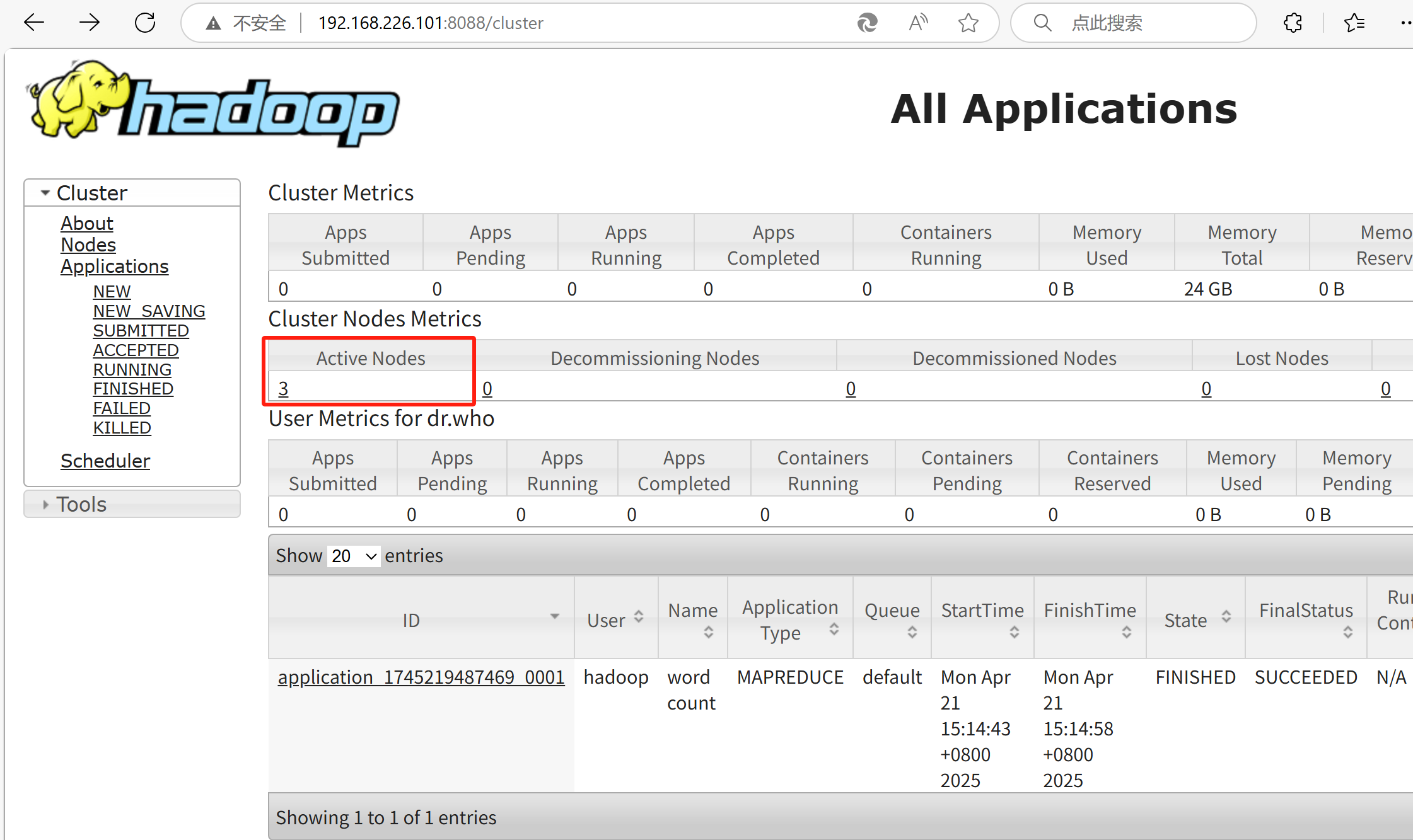
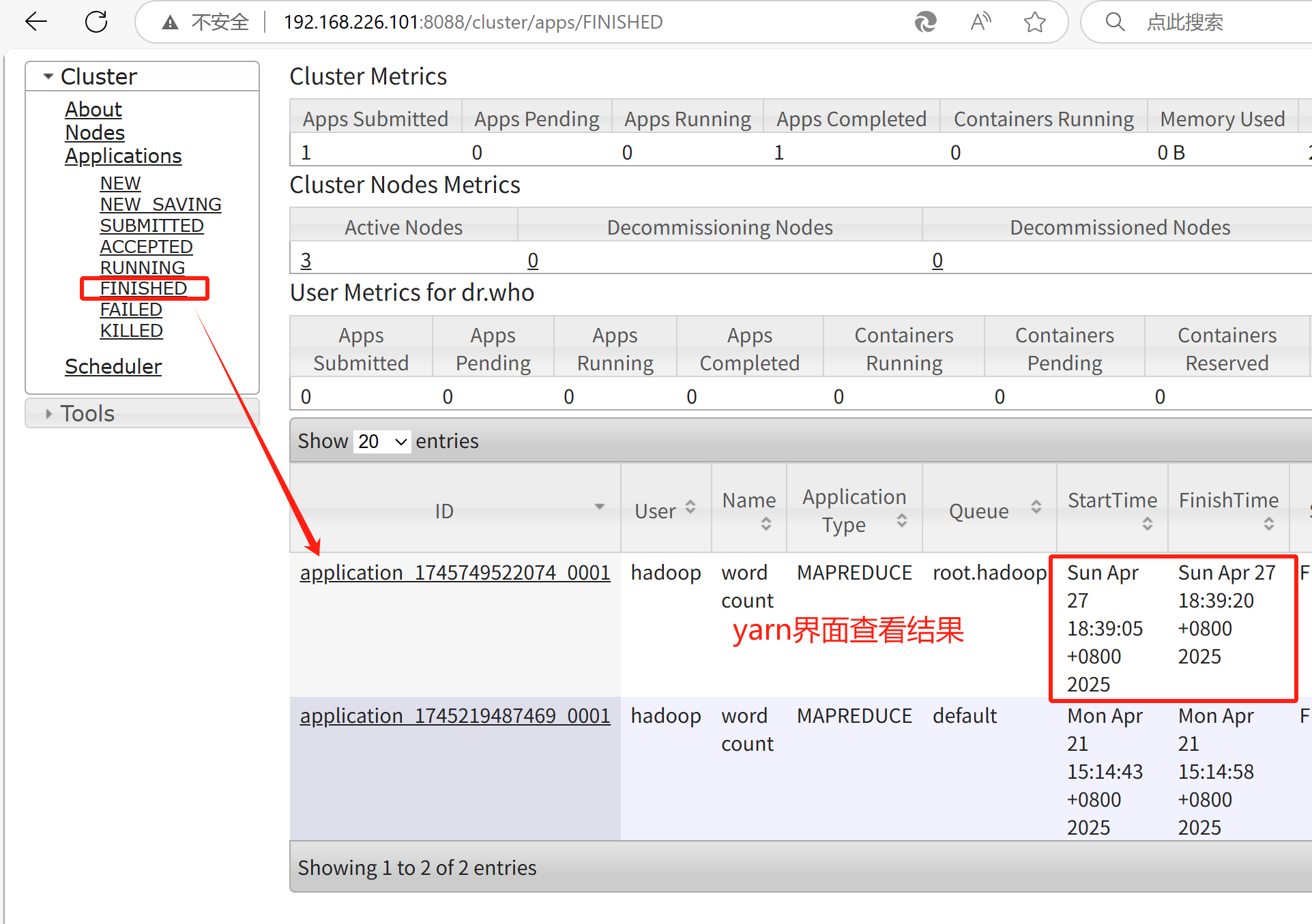
1.windows系统下输入网址192.168.226.101:8088,成功开启YARN之后界面如下
- yarn自带wordcount程序,测试yarn的功能
-
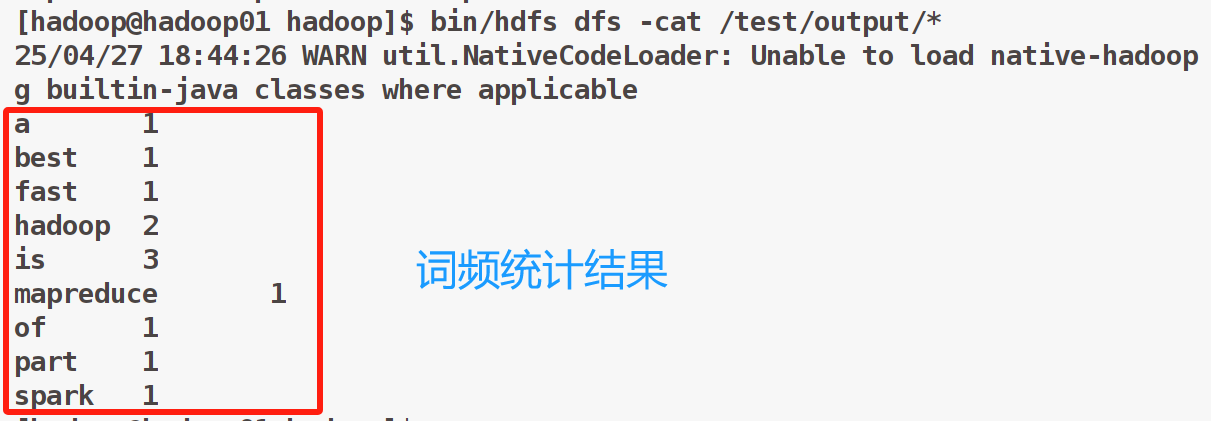
当前hdfs文件系统中/test目录下有文件1.txt,统计其中的字词数量
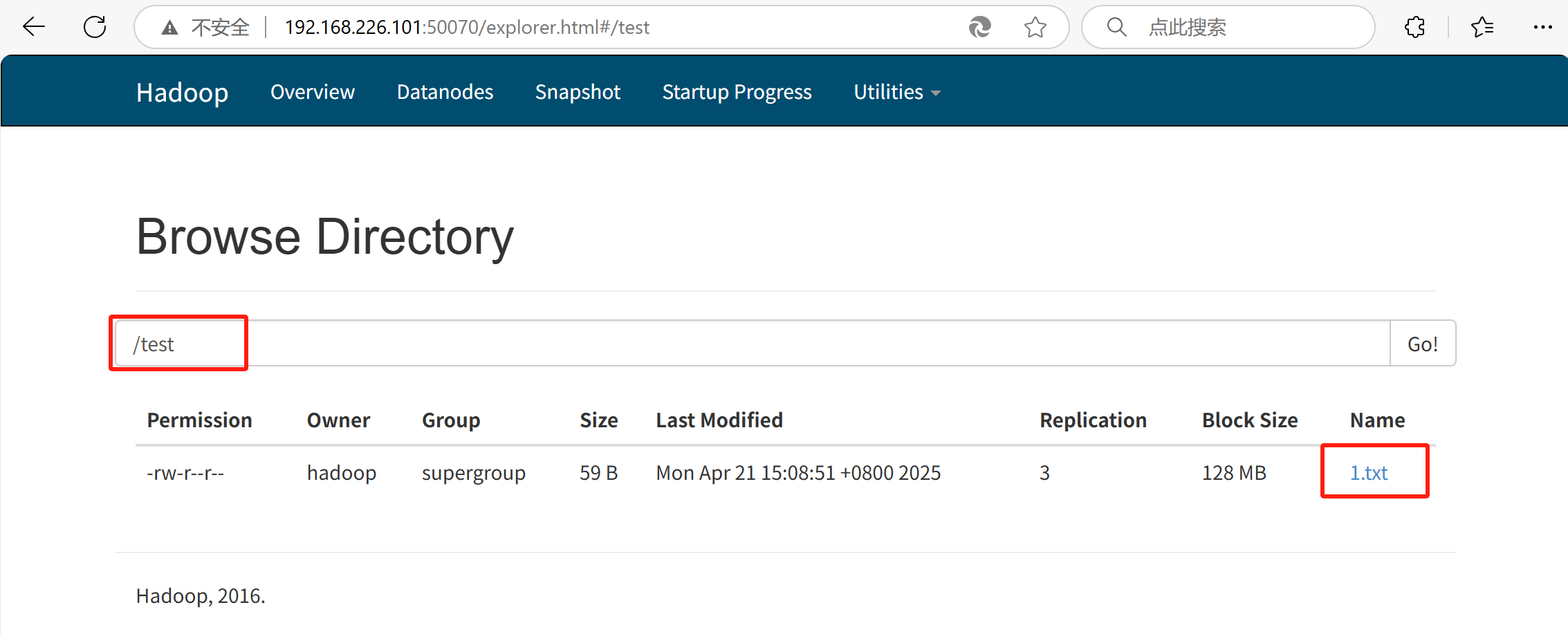

-
[home/hadoop/app/hadoop]目录下 , 执行如下命令
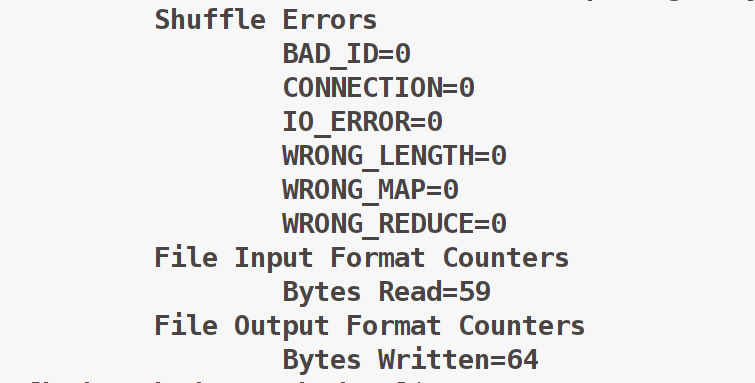
# 执行成功,如下图所示
bin/hadoop jar share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.10.0.jar wordcount /test/1.txt /test/output# 查看执行结果
bin/hdfs dfs -cat /test/output/*
注意:
-
wordcount程序统计词频之后会产生output文件,如果当前存在output文件,再次创建output会报错;可以删除之后,再次执行wordcount程序
-
yarn的配置文件存放在hadoop中的etc/hadoop文件下
二 HBase应用
操作一 官网下载 HBase压缩包
Apache 版本: http://archive.apache.org/dist/hbase/
CDH 版本: http://archive-primary.cloudera.com/cdh5/cdh/5/
这里选择下载 hbase-1.2.0-cdh5.10.0.tar.gz 版本的安装包,上传至主节点 app 目录。
操作二 修改4个配置文件;拷贝HDFS的2个配置文件;创建HBase日志目录
- 解压安装包并创建软链接
tar -zvxf hbase-1.2.0-cdh5.10.0.tar.gz
ln -s hbase-1.2.0-cdh5.10.0.tar.gz hbase
- 修改hbase-site.xml、hbase-en.sh、regionservers、backup-masters配置文件
# hbase-site.xml
<configuration><property><name>hbase.zookeeper.quorum</name><value>hadoop01,hadoop02,hadoop03</value><!--指定Zookeeper集群节点--></property><property><name>hbase.zookeeper.property.dataDir</name><value>/home/hadoop/data/zookeeper/zkdata</value><!--指定Zookeeper数据存储目录--></property><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value><!--指定Zookeeper端口号--></property><property><name>hbase.rootdir</name><value>hdfs://cluster1/hbase</value><!--指定HBase在HDFS上的根目录--></property><property><name>hbase.cluster.distributed</name><value>true</value><!--指定true为分布式集群部署--></property>
</configuration># hbase-en.sh # 含有如下环境变量
export JAVA_HOME=/home/hadoop/app/jdk
export HBASE_LOG_DIR=/home/hadoop/data/hbase/logs
export HBASE_PID_DIR=/home/hadoop/data/hbase/pids
export HBASE_MANAGES_ZK=false# regionservers
hadoop01
hadoop02
hadoop03# backup-masters # 配置备用节点
hadoop02
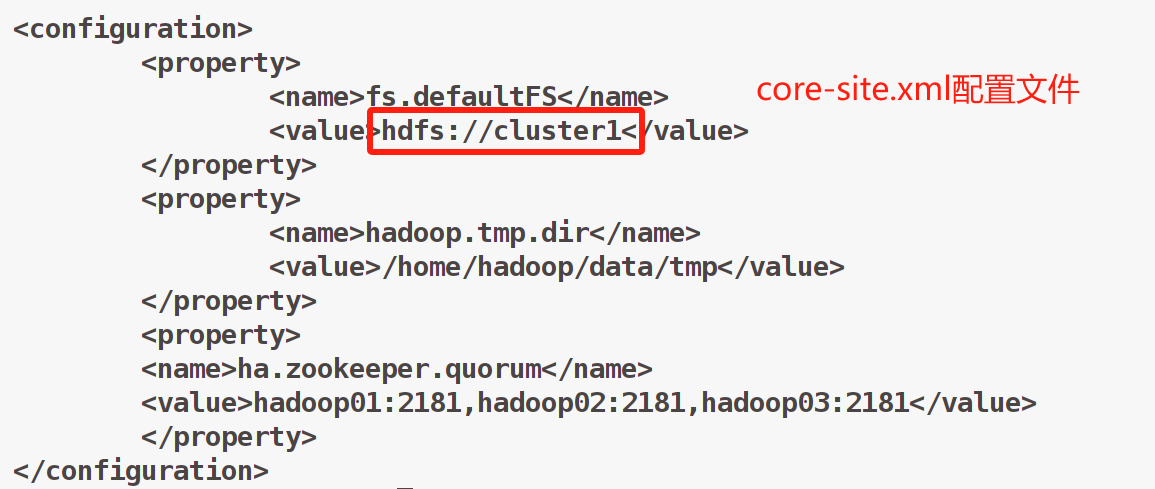
- 拷贝HDFS文件系统中的hdfs-site.xml 和core-site.xml文件,[/home/hadoop/app/hadoop/etc/hadoop]下执行
cp hdfs-site.xml ~/app/hbase/conf
cp core-site.xml ~/app/hbase/conf
- 创建HBase日志目录
runRemoteCmd.sh 'mkdir -p ~/data/hbase/logs' all
注意:hdfs-site.xml和core-site.xml文件中的这部分保持一致

操作三 hbase-1.2.0-cdh5.10.0 同步到其他节点,并创建软链接;集群启动hbase
- hbase同步到其他节点
deploy.sh hbase-1.2.0-cdh5.10.0 ~/app slave
ln -s hbase-1.2.0-cdh5.10.0 hbase
- 启动hbase,在[/home/hadoop/app/hbase]目录下执行。注意,HDFS已启动
# 在哪个节点启动HBase,哪个节点就是HBase Master
bin/start-hbase.sh #关闭HBase
bin/stop-hbase.sh
这里在hadoop01节点启动的HBase
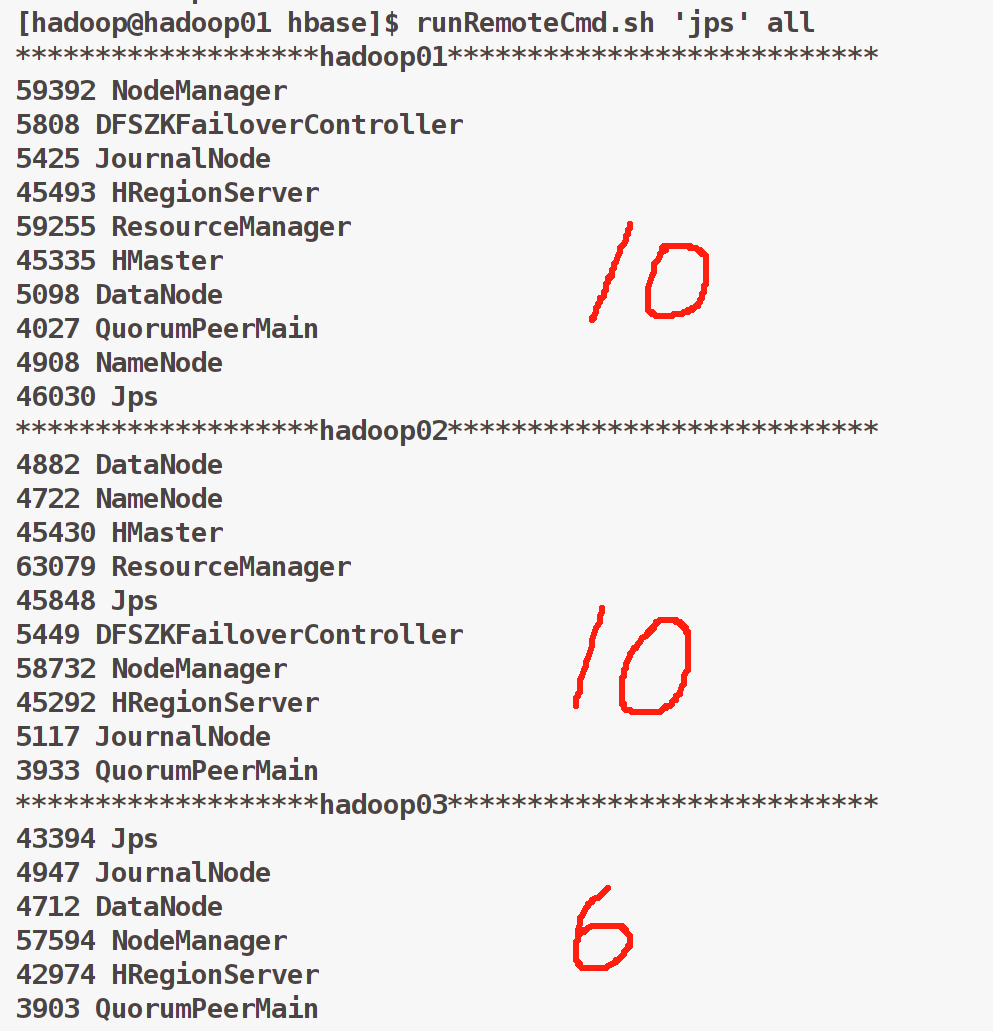
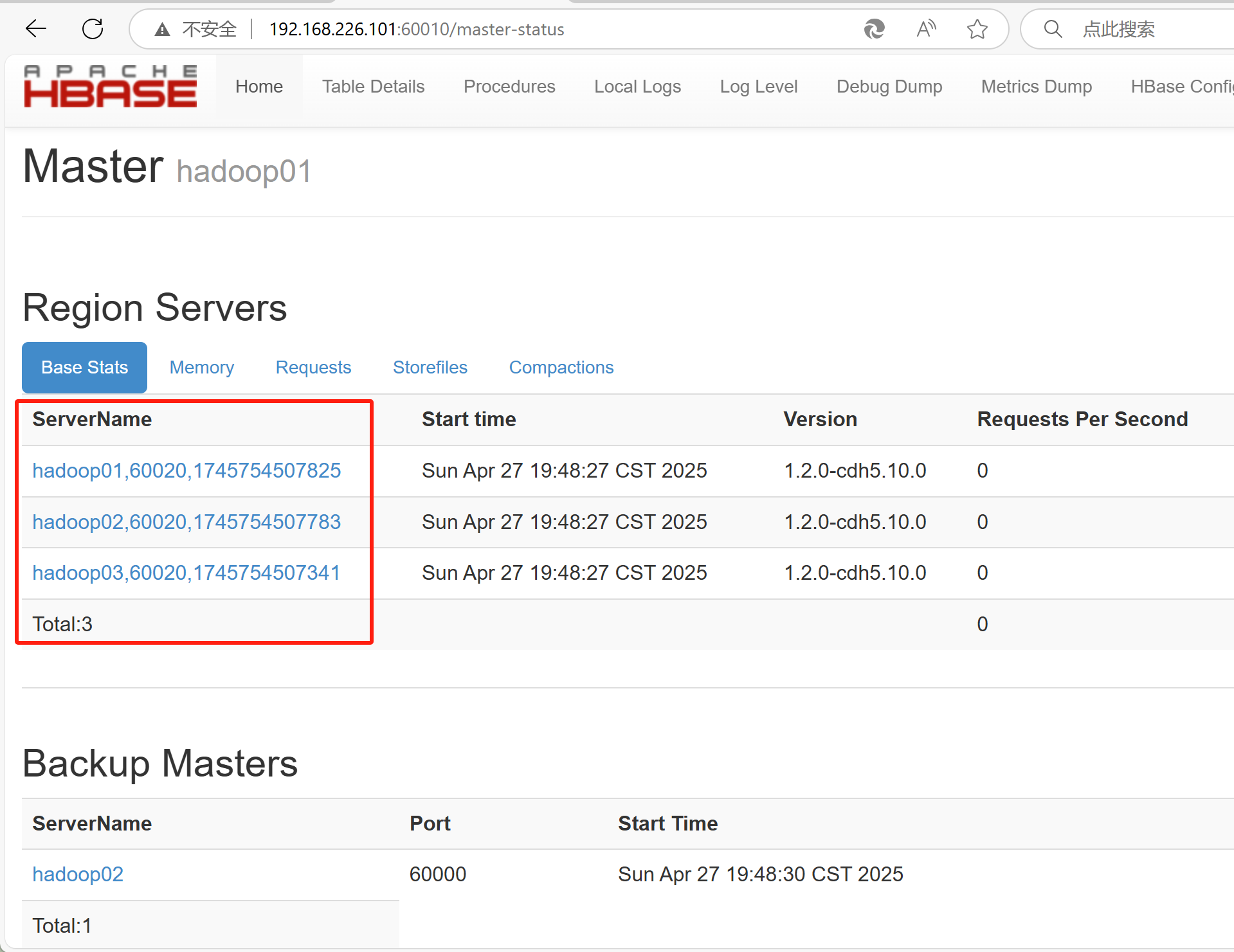
操作四 web查看hbase
Windows系统下访问地址http://master:60010
注意
-
开机先开zk,再开dfs,再开hbase; 关机先关hbase,再关dfs,再关zk
-
在Hadoop集群中,在哪个节点上启动HBase,那个节点就会成为HBase Master,成为Master候选,而在多Master配置下,最终活跃Master由ZooKeeper选举决定;单Master配置下则没有选举过程