KAG:通过知识增强生成提升专业领域的大型语言模型(二)
目录
摘要
Abstract
1 实验
1.1 实验设置
1.2 总体结果
1.3 消融研究
1.3.1 知识图谱索引消融
1.3.2 推理与检索消融
1.3.3 实验结果与讨论
2 KAG服务部署
2.1 安装Docker
2.2 安装Doker Compose
2.3 启动服务
2.4 查看状态
2.5 产品访问
3 KAG 0.6使用(可视化界面)
3.1 全局配置
3.2 创建知识库
3.3 导入文档
3.4 查看结果
3.4 推理问答
4 KAG 0.6使用(开发者模式)
4.1 环境配置
4.2 代码克隆
4.3 代码结构
4.4 示例
4.5 配置文件解读
4.5.1 项目配置
4.5.2 kag-builder配置
4.5.3 kag-solver配置
总结
摘要
本周继续学习KAG的实验结果部分、完成对KAG的安装部署,还有对KAG代码框架的理解。首先,介绍了KAG框架在知识密集型问答任务中的应用和性能评估。KAG通过多步检索、知识对齐和逻辑形式求解等策略,提升了问答系统在多跳问答数据集上的表现。消融研究进一步探讨了知识图谱索引和推理与检索策略对性能的影响,证明了知识对齐和逻辑形式求解器的有效性。然后,完成了包括KAG可视化界面和KAG开发者模式的安装部署,有Docker部署服务、构建和管理私域知识库以及进行推理问答的步骤。详细了解了KAG代码框架和实现过程。
Abstract
This week, we will continue to study the experimental results of KAG, complete the installation and deployment of KAG, and understand the KAG code framework. Firstly, the application and performance evaluation of KAG framework in knowledge-intensive Q&A tasks are introduced. KAG improves the performance of the Q&A system on multi-hop Q&A datasets through strategies such as multi-step retrieval, knowledge alignment, and logical form solving. The ablation study further explores the impact of knowledge graph indexing and inference and retrieval strategies on performance, and proves the effectiveness of knowledge alignment and logical form solvers. Then, the installation and deployment of KAG visual interface and KAG developer mode were completed, including Docker deployment service, building and managing private domain knowledge base, and inference Q&A. Learn more about the KAG code framework and implementation process.
1 实验
1.1 实验设置
为了评估KAG在知识密集型问答任务中的有效性,在3 广泛使用的多跳问答数据集上进行了实验,包括HotpotQA、2WikiMultiHopQA和MuSiQue。为了进行公平的比较,遵循IRCoT和HippoRAG,使用每个验证集的1,000个问题,并使用与所选问 题相关的检索语料库。
在评估问答性能时,使用两个指标:精确匹配(EM)和F1分数。为了评估检索性能,根据Top 2/5检索结果计算命中率,表示为Recall@2和Recall@5。
将KAG与几种稳健且常用的检索RAG方法进行对比:
- NativeRAG使用ColBERTv2作为检索器并直接根据所有检索到的文档生成答案;
- HippoRAG是一个受人类长期记忆启发的RAG框架,它使LLMs能够持续地将知识整合到外部文档中。
在本文中,KAG也使用ColBERTv2作为其检索器。IRCoT将思维链(CoT)生成和知识检索步骤交织在一起,以 便通过CoT引导检索,反之亦然。这种交织允许检索到更多与后续推理步骤相关的信息,这是实现现有RAG框架中多步检索的关键技术。
1.2 总体结果
在利用ChatGPT-3.5作为骨干模型的RAG框架中,HippoRAG相较于NativeRAG表现出更优越的性能。HippoRAG采用人类长期记忆策略,有助于将外部文档中的知识持续集成到LLMs中,从而显著提升问答能力。然而,考虑到使用ChatGPT-3.5带来的巨大经济成本,KAG选择了DeepSeek-V2 API作为可行的替代方案。平均而言,使用DeepSeek-V2 API的IRCoT + HippoRAG配置的性能略高于ChatGPT-3.5。如下表所示,KAG与IRCoT+HippoRAG相比,性能显著提升,在HotpotQA、2WikiMultiHopQA和MuSiQue上的EM分别提高了11.5%、19.8%和10.5%,F1分别提高了12.5%、19.1%和 12.2%。这些端到端性能的提升主要归功于KAG框架中更有效的索引、知识对齐和混合求解库的开发。
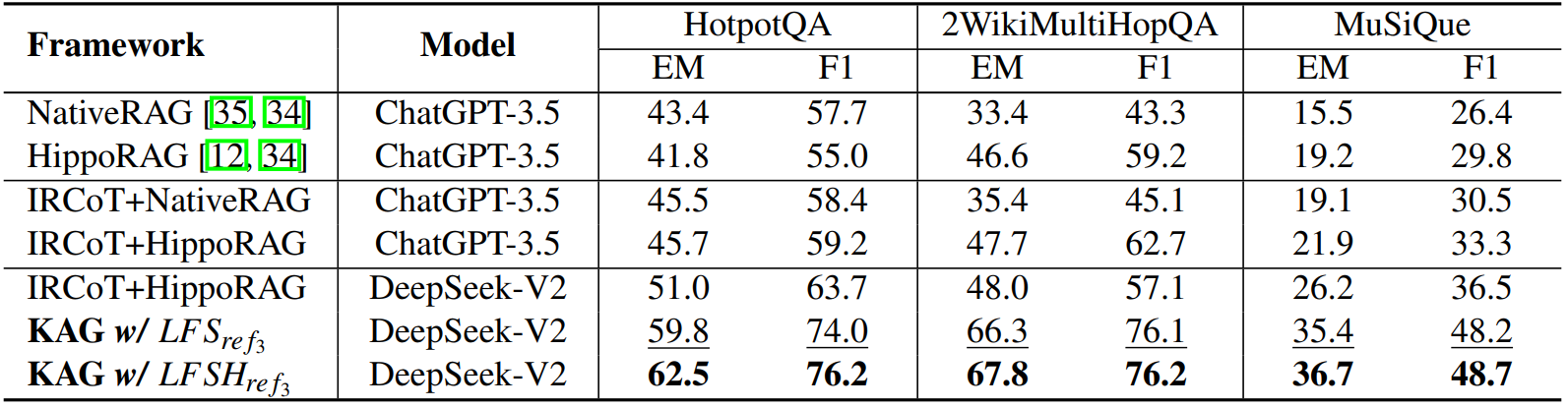
还评估了单步检索器和多步检索器的有效性,检索性能如下表所示:
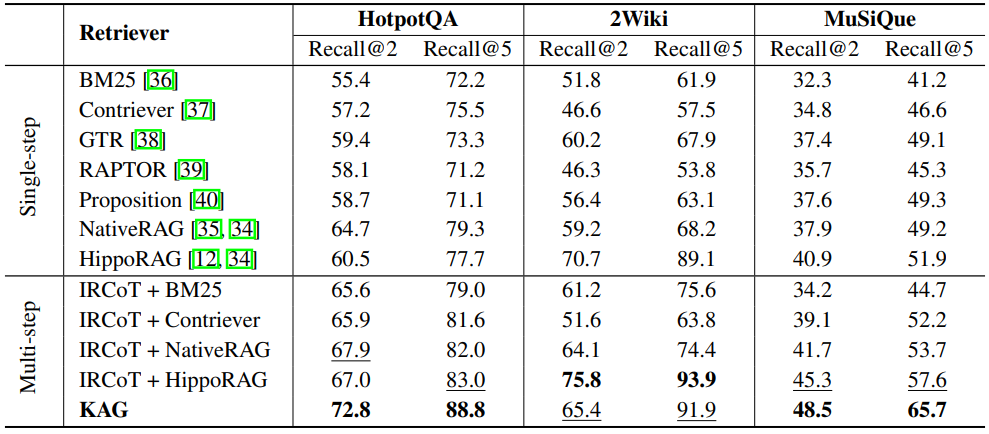
从实验结果来看,多步检索器通常优于单步检索器。
分析表明,单步检索器检索到的内容具有非常高的相似性,导致无法使用单步检索结果推导出某些需要推理的数据的答案,多步检索器缓解了这一问题。KAG 框架直接使用多步检索器,并通过互索引、逻辑形式求解和知识对齐等策略显著提高了检索性能。
1.3 消融研究
本实验的目的是深入探究知识对齐和逻辑形式求解器对最终结果的影响,通过对每个模块进行消融实验,替换不同的方法并分析结果的变化。
1.3.1 知识图谱索引消融
在图索引阶段,提出了以下两种替换方法:
- 互索引方法(M_Indexing):作为 KAG 的基线方法,使用信息抽取方法(如OpenIE)从文档块中提取短语和三元组,并形成图结构和文本之间的互索引。根据LLMFriSPG的层次表示将块进行索引,然后将它们写入知识图谱存储;
- 知识对齐增强(K_Alignment):该方法利用知识对齐来增强知识图谱的互索引和逻辑形式引导的推理与检索。它主要完成实例和概念的分类、概念的上下位词预测、概念间语义关系的补全、实体消歧和融合等任务,增强了知识的语义区分度和实例之间的连通性,为后续逻辑形式引导的推理与检索奠定了坚实基础。
1.3.2 推理与检索消融
KAG采用了ReSP中的多轮反思机制来评估逻辑形式求解器是否已完全回答问题。如果没有,将生成补充问题进行迭代求解,直到全局内存中的信息足够。本文分析了最大迭代次数 对结果的影响,记为
。如果
,则表示未启用反思机制。
在推理和检索阶段,设计了以下三种替换方法:
- 块检索器:以HippoRAG的检索能力为参考,定义了KAG的基线检索策略,旨在召回支持回答当前问题的前
个块。块得分通过加权向量相似度和个性化得分来计算。称此方法为
,用
轮反思表示
;
- 逻辑形式求解器(启用图检索):接下来,使用逻辑形式求解器进行推理。该方法使用预定义的逻辑形式来解析和回答问题:
- 首先,它探索
和
空间中
结构的推理能力,重点关注推理的准确性和严谨性;
- 然后,当推理步骤没有结果时,它使用
中的 supporting_chunks 来补充检索;
- 称此方法为
,参数
- 首先,它探索
- 逻辑形式求解器(启用混合检索)。为了充分利用
。
通过设计这项消融研究,旨在全面深入地了解不同图索引和推理方法对最终结果的影响,为后续的优化和改进提供强有力的支持。
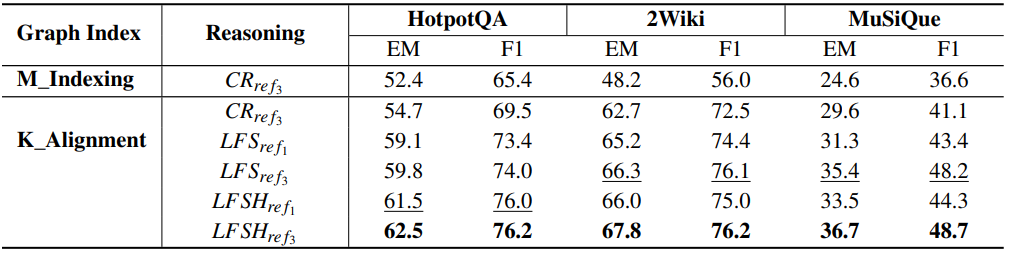
1.3.3 实验结果与讨论
下表为三个多跳问答数据集上不同模型方法的端到端生成性能。骨干模型为DeepSeek-V2 API。 表示最多3轮反射,而
表示最多1轮,这意味着不引入反射:
下表为展示了三种数据集上不同方法的召回性能。 方法中一些子问题的答案使用
推理而不召回支持块,这在召回率方面与其他方法不可比。骨干模型是 DeepSeek-V2 API:
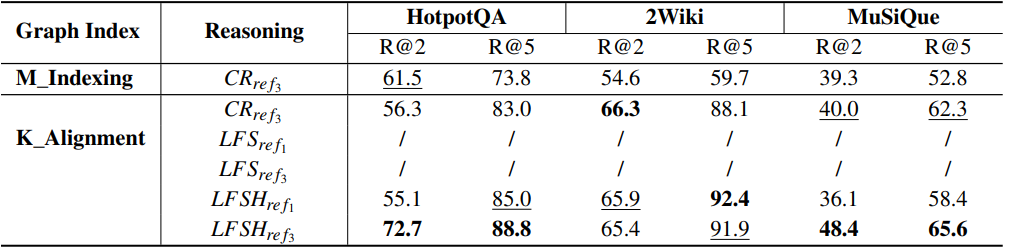
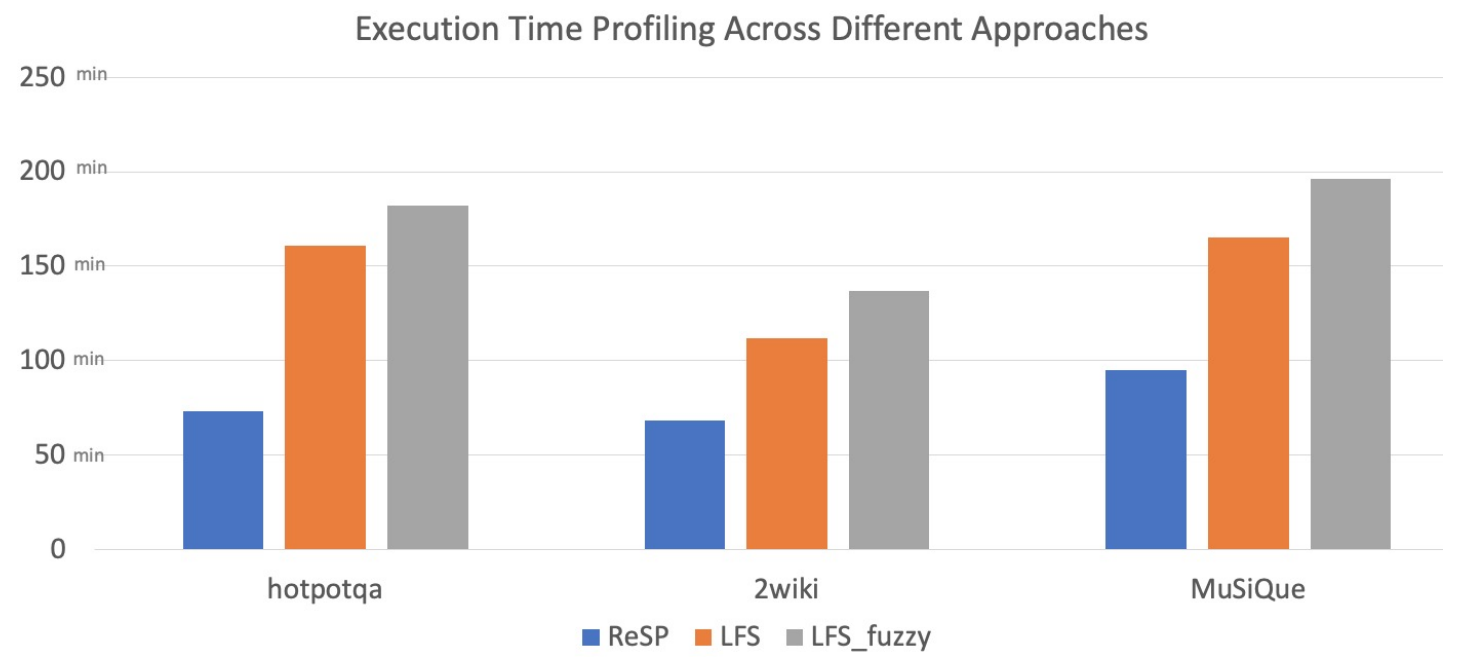
三个测试数据集各包含1000个测试问题,20个任务并发处理,最大迭代次数 为 3。
方法执行速度最快,而
方法最慢。具体来说,
方法在三个数据集上分别比
方法高出149%、101%和134%。相比之下,在相同的数据集上,
方法分别比
方法高出13%、22%和18%,F1相对损失分别为2.6%、0.1%和 1.0%:
如下图,应用K_Alignment后,图的连通性表现出明显的右移,展示了1跳、2跳和3跳邻居的分布变化:
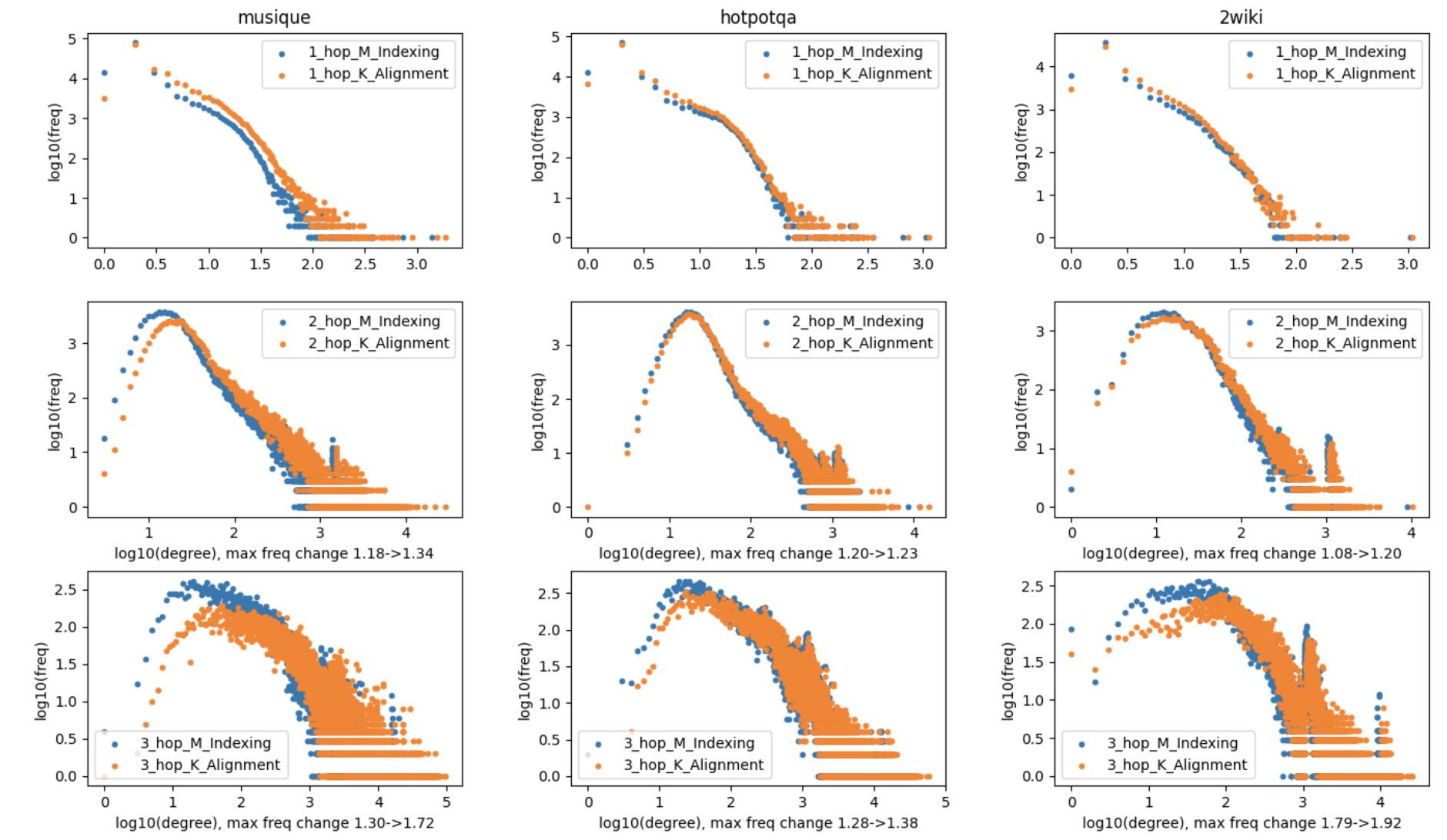
可以从以下两个角度对实验结果进行分析:
- 知识图谱索引:在将知识对齐融入
的 top-5 召回率分别提高了9.2%、28.4%和9.5%,平均提高了15.7%;在增强知识对齐后,关系密度显著增加,频率-出度图整体向右移动;这表明新添加的语义关系有效地增强了图连通性,从而提高了文档召回率;
- 图推理分析:在召回率方面,与相同的图索引相比,
在
消耗的时间是
2 KAG服务部署
KAG用户手册:用户手册v0.6 · OpenSPG
以下KAG部署和使用均使用的Windows系统。
2.1 安装Docker
进入Docker官网,选择Windows版本下载安装:
全部勾选,点击OK完成安装。
在控制台输入docker -v,查看版本号,出现即表示Docker可以使用:
然后启动docker,确保docker处于开启状态,再进行下面步骤
2.2 安装Doker Compose
首先,下载Docker Compose.exe,并移入Docker所在的目录(C:\Program Files\Docker)
在地址栏中输入cmd并回车:
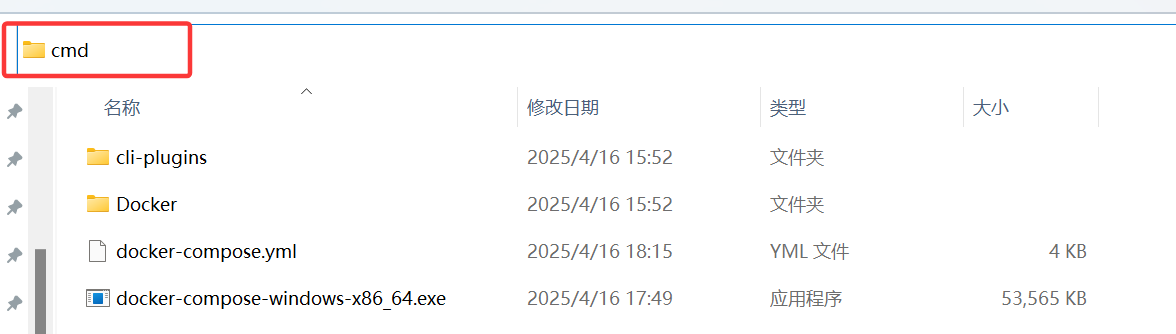
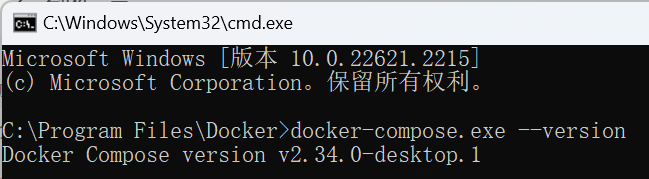
输入docker-compose.exe --version 查看版本号,出现即表示安装成功:
2.3 启动服务
在D盘中新建一个KAG目录,并在KAG目录创建一个docker-compose.yml的文件,将下面内容复制docker-compose.yml文件中,并保存:
version: "3.7"
services:server:restart: alwaysimage: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latestcontainer_name: release-openspg-serverports:- "8887:8887"depends_on:- mysql- neo4j- miniovolumes:- /etc/localtime:/etc/localtime:roenvironment:TZ: Asia/ShanghaiLANG: C.UTF-8command: ["java","-Dfile.encoding=UTF-8","-Xms2048m","-Xmx8192m","-jar","arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",'--server.repository.impl.jdbc.host=mysql','--server.repository.impl.jdbc.password=openspg','--builder.model.execute.num=20','--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j','--cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j']mysql:restart: alwaysimage: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latestcontainer_name: release-openspg-mysqlvolumes:- /etc/localtime:/etc/localtime:roenvironment:TZ: Asia/ShanghaiLANG: C.UTF-8MYSQL_ROOT_PASSWORD: openspgMYSQL_DATABASE: openspgports:- "3306:3306"command: ['--character-set-server=utf8mb4','--collation-server=utf8mb4_general_ci']neo4j:restart: alwaysimage: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latestcontainer_name: release-openspg-neo4jports:- "7474:7474"- "7687:7687"environment:- TZ=Asia/Shanghai- NEO4J_AUTH=neo4j/neo4j@openspg- NEO4J_PLUGINS=["apoc"]- NEO4J_server_memory_heap_initial__size=1G- NEO4J_server_memory_heap_max__size=4G- NEO4J_server_memory_pagecache_size=1G- NEO4J_apoc_export_file_enabled=true- NEO4J_apoc_import_file_enabled=true- NEO4J_dbms_security_procedures_unrestricted=*- NEO4J_dbms_security_procedures_allowlist=*volumes:- /etc/localtime:/etc/localtime:ro- $HOME/dozerdb/logs:/logsminio:image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latestcontainer_name: release-openspg-miniocommand: server --console-address ":9001" /datarestart: alwaysenvironment:MINIO_ACCESS_KEY: minioMINIO_SECRET_KEY: minio@openspgTZ: Asia/Shanghaiports:- 9000:9000- 9001:9001volumes:- /etc/localtime:/etc/localtime:ro同样,在D:\KAG的地址栏中输入cmd并回车:
然后,输入如下命令,设置HOME环境变量:
set HOME=%USERPROFILE%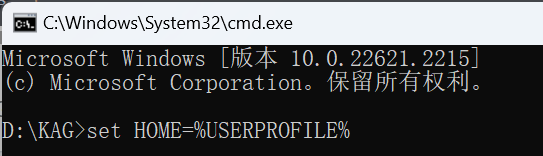
然后输入如下命令,启动服务:
docker compose -f docker-compose.yml up -d
等待neo4j、mysql、minio、openspg-server安装完成即可。
2.4 查看状态
# 查看服务启动时间
docker ps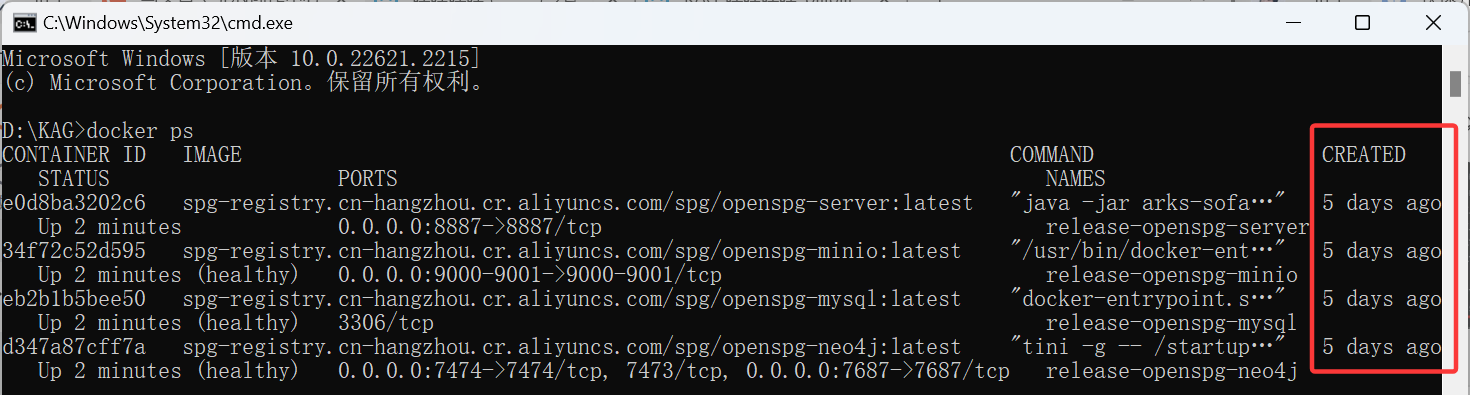
docker logs -f release-openspg-server如下日志显示的是 openspg 服务端启动成功的标识:
2.5 产品访问
在浏览器输入地址http://127.0.0.1:8887, 可访问openspg-kag产品界面,默认登录信息如下:
用户名:openspg
默认密码:openspg@kag
# 默认密码必须修改后才能使用,如忘记密码,可以在db里重新初始化
UPDATE kg_user SET `gmt_create` = now(),`gmt_modified` = now(),`dw_access_key` ='efea9c06f9a581fe392bab2ee9a0508b2878f958c1f422f8080999e7dc024b83' where user_no = 'openspg' limit 1;
3 KAG 0.6使用(可视化界面)
OpenSPG-KAG可视化界面支持用户在页面上进行私域知识库的构建、问答及管理。同时能够直观的查看建模结果。
3.1 全局配置
在创建知识库之前,需要进行全局配置,包括通用配置和模型配置。
点击右上角的全局配置。
首先,进行通用配置,通用配置包括图存储配置、向量模型配置和提示词中英文配置:
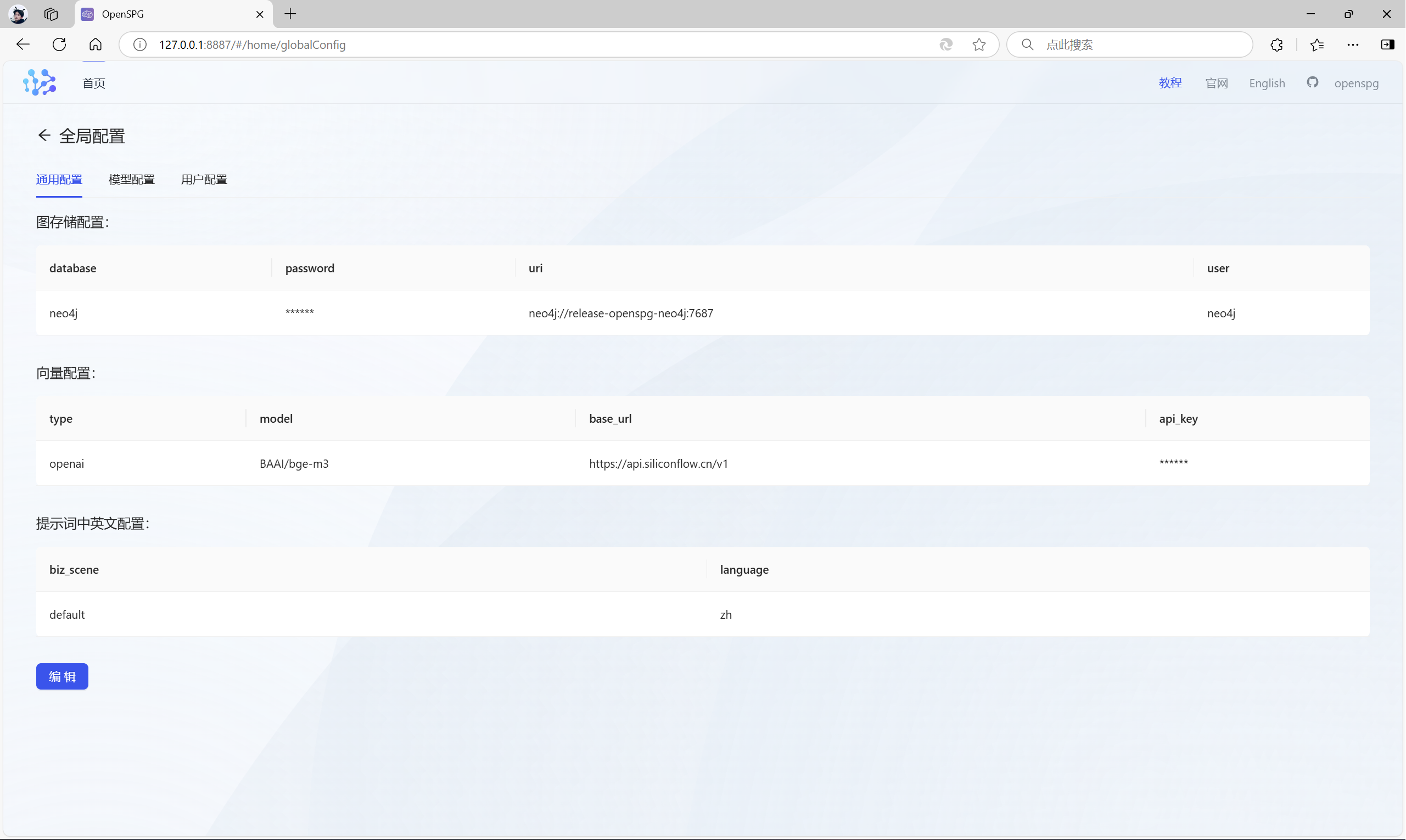
图存储配置:
{"database":"neo4j", # 图存储的数据库名称,固定和知识库英文名称保持一致,且不可修改"uri":"neo4j://release-openspg-neo4j:7687", # 自带的openspg-neo4j默认值为:neo4j://release-openspg-neo4j:7687"user":"neo4j", # 自带的openspg-neo4j默认值为:neo4j"password":"neo4j@openspg", # 自带的openspg-neo4j默认值为:neo4j@openspg
}向量配置:
提供向量生成服务,支持 bge、openai-embedding。建议英文使用bge-m3,中文使用bge-base-zh。
配置硅基流动等商业表示模型服务的示例:
{"type": "openai","model": "BAAI/bge-m3","base_url": "https://api.siliconflow.cn/v1","api_key": "YOUR_API_KEY",# 去硅基流动获取"vector_dimensions": "1024"
}提示词中英文配置:
用于模型调用时判断是否使用中文(zh)或英文(en)。
{"biz_scene":"default","language":"zh"
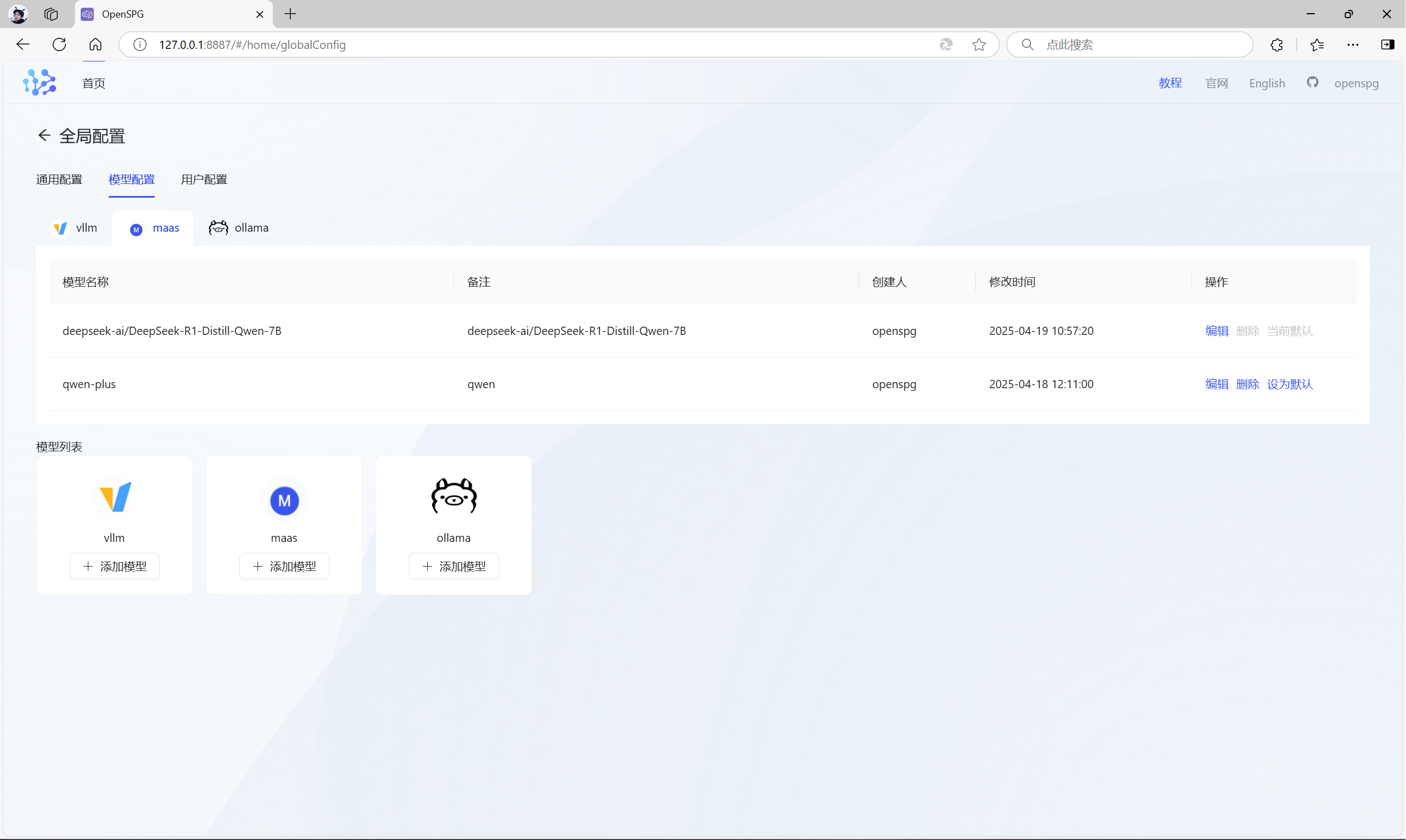
}然后切换到模型配置,配置模型用于构建及问答时的模型调用。支持open-ai 兼容的api(chatgpt3.5、deepseek、qwen2等),提供maas、vllm、ollama等模式。
{"type": "maas","base_url": "https://api.deepseek.com", # 地址"api_key": "deepseek api key", # api_key"model": "deepseek-chat" # 模型名称
}
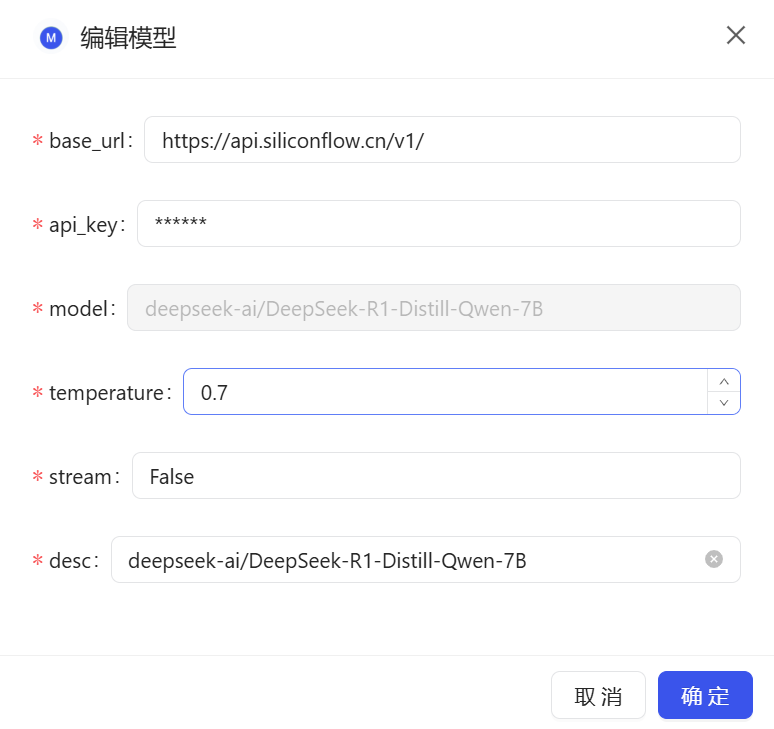
3.2 创建知识库
配置完成后,回到首页,点击“创建知识库”:
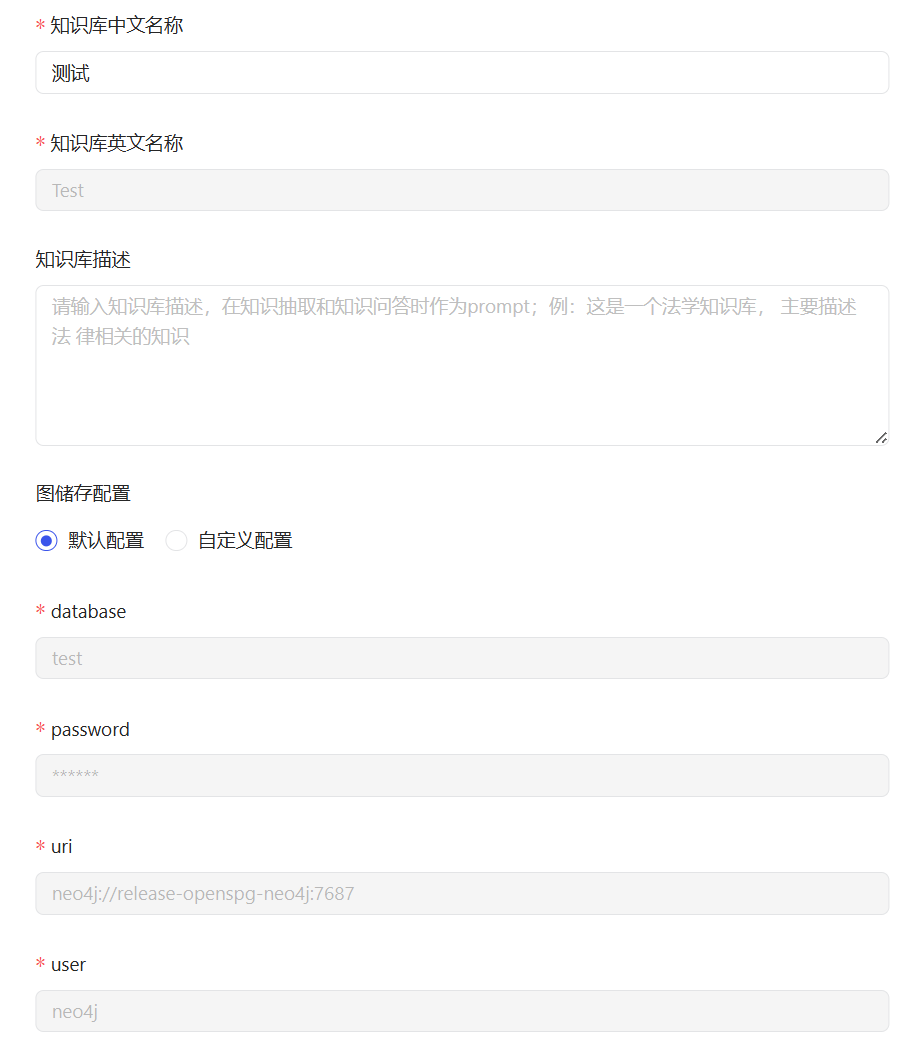
知识库中文名称:
必填项。知识库的中文名称,用于页面展示。
知识库英文名称:
必填项。知识库的英文名称,必须以大写字母开头,且仅支持字母和数字组合,3个字符以上。用于Schema的前缀及图存数据隔离。
3.3 导入文档
创建好知识库后,点击“知识库构建”,再点击右上角“创建任务”:
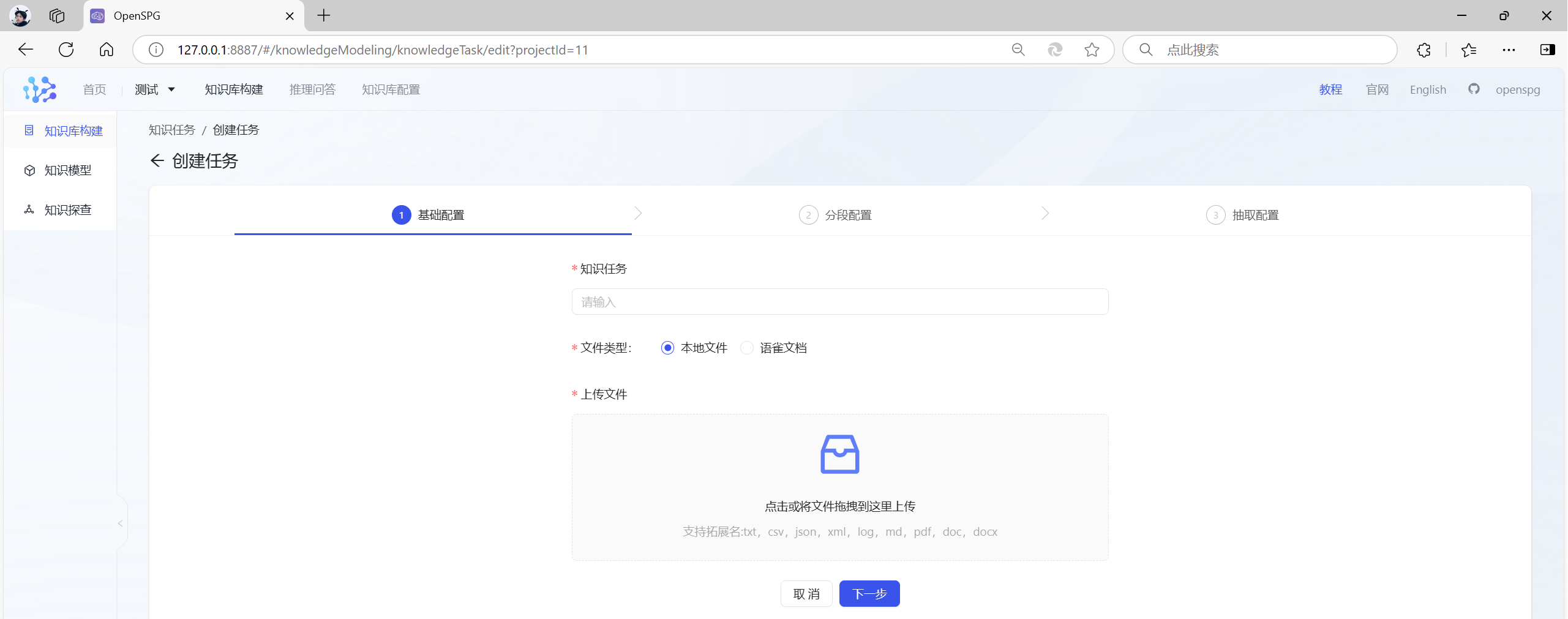
- 支持的文档类型:本地文件和语雀文档
- 支持拓展名:txt,csv,json,xml,log,md,pdf,doc,docx
- 支持的切分方式:语义切分和长度切分。
- 支持的抽取方式:
- 抽取模型:使用创建项目时的默认配置
- 是否支持增量schema:默认选中,不可修改
- 抽取后直接导入:默认选中,不可修改
- 抽取配置的提示词:可用于提示文件为什么类型的文档等。
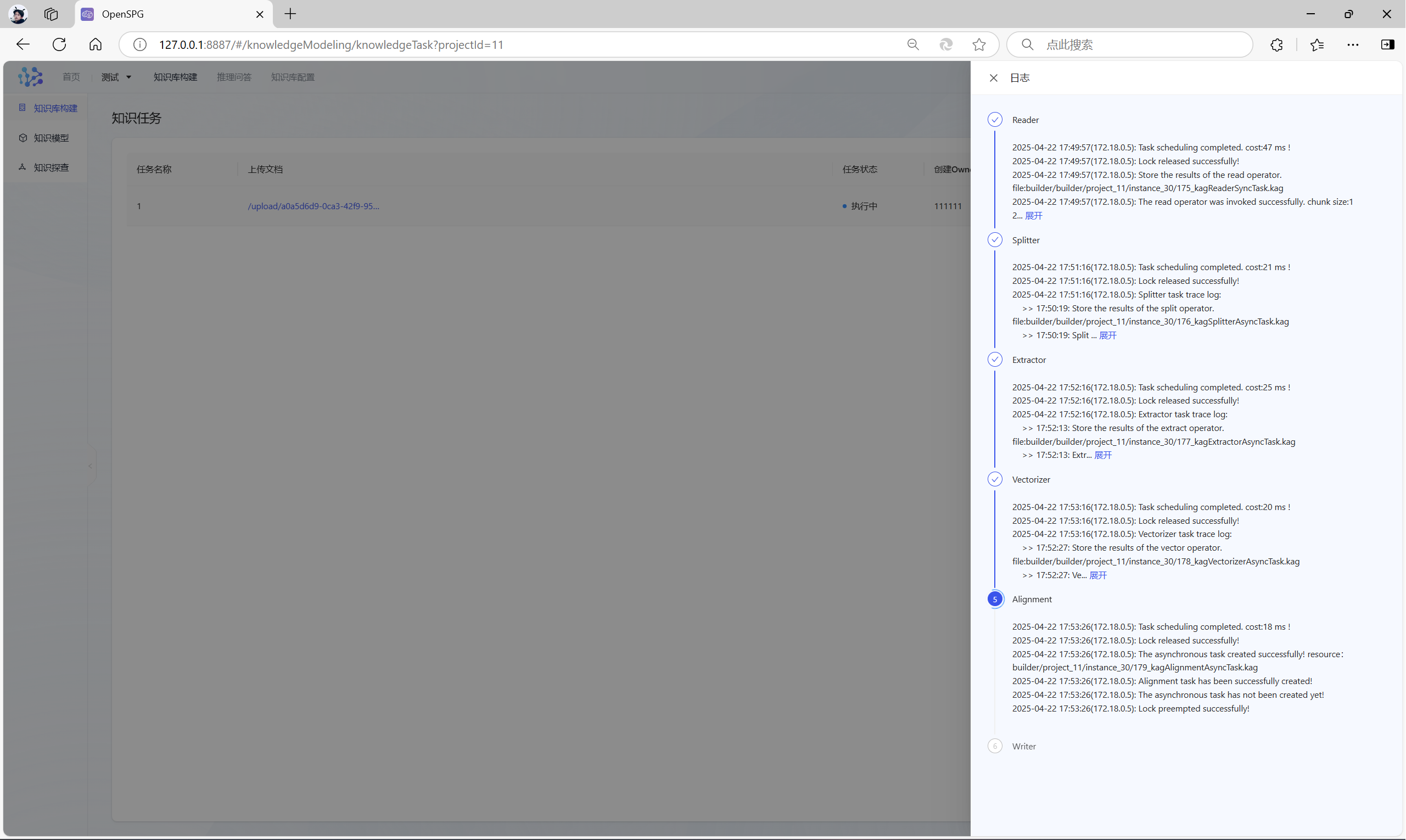
设置好后,点击“完成”,KAG开始解析文件,构建知识库了,主要分为六个步骤:
- reader:读取不同类型的数据源;
- splitter:对读取到的文本数据进行切分处理,将长文本分割成更适合后续处理的片段;
- extractor:从切分后的文本中提取实体、关系等知识图谱的核心元素;
- vectorizer:将提取出的实体、关系等知识元素转化为向量表示;
- aligner:对齐和合并多个子图;
- writer:将构建好的知识图谱数据写入到指定的存储介质中;
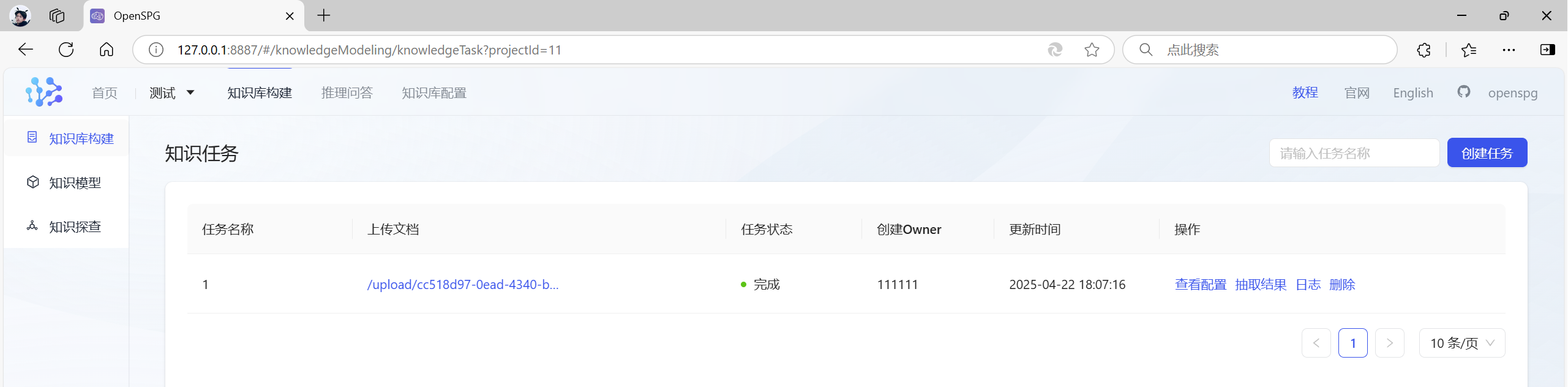
等到任务状态变成“完成”,就代表知识库构建成功:
3.4 查看结果
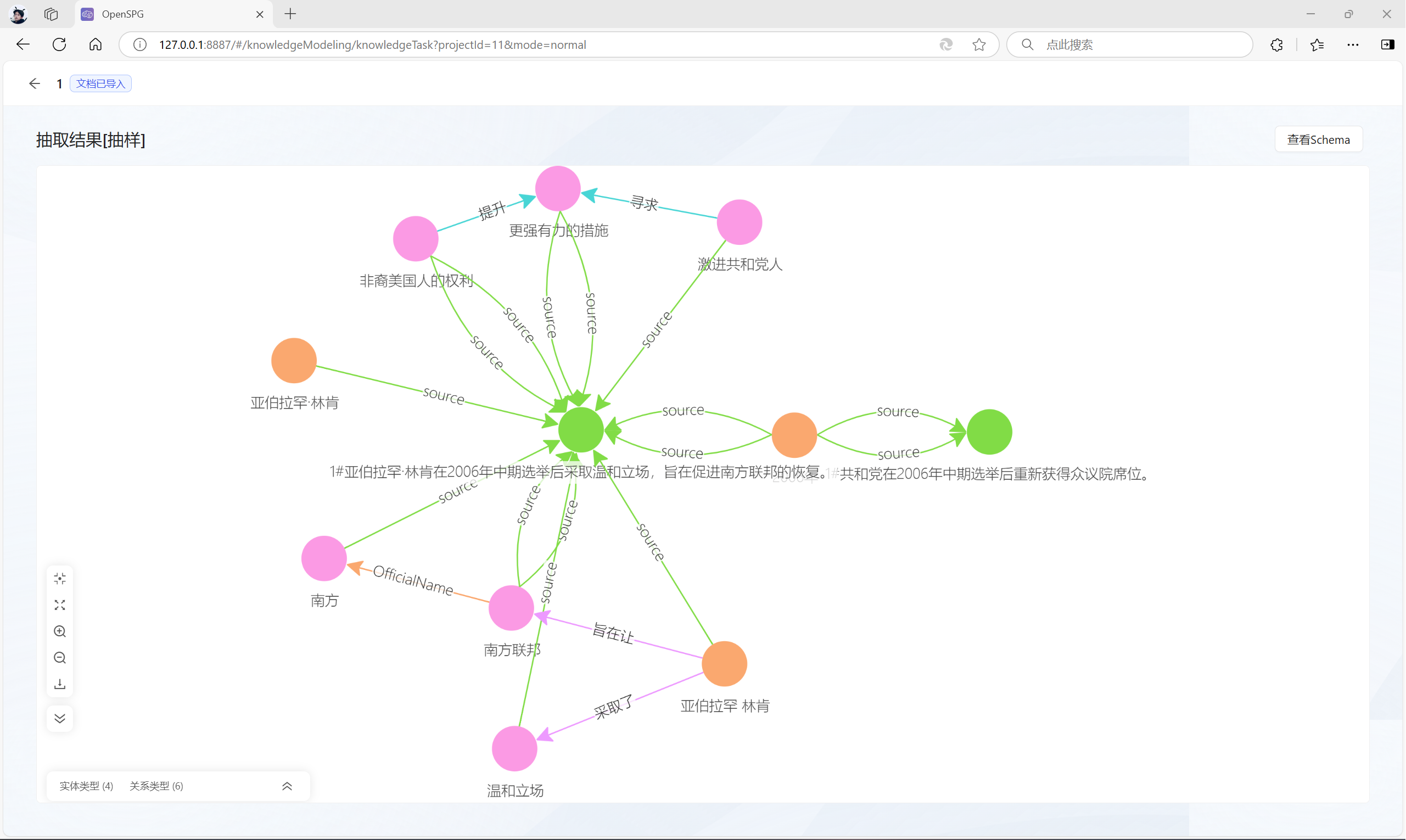
点击“抽取结果”,可以查看构建的知识图谱:
或者,点击左上角的“知识探查”菜单,然后输入“知识名称”,勾选“知识列表”,点击“画布探查”,可对图谱数据进行查看:
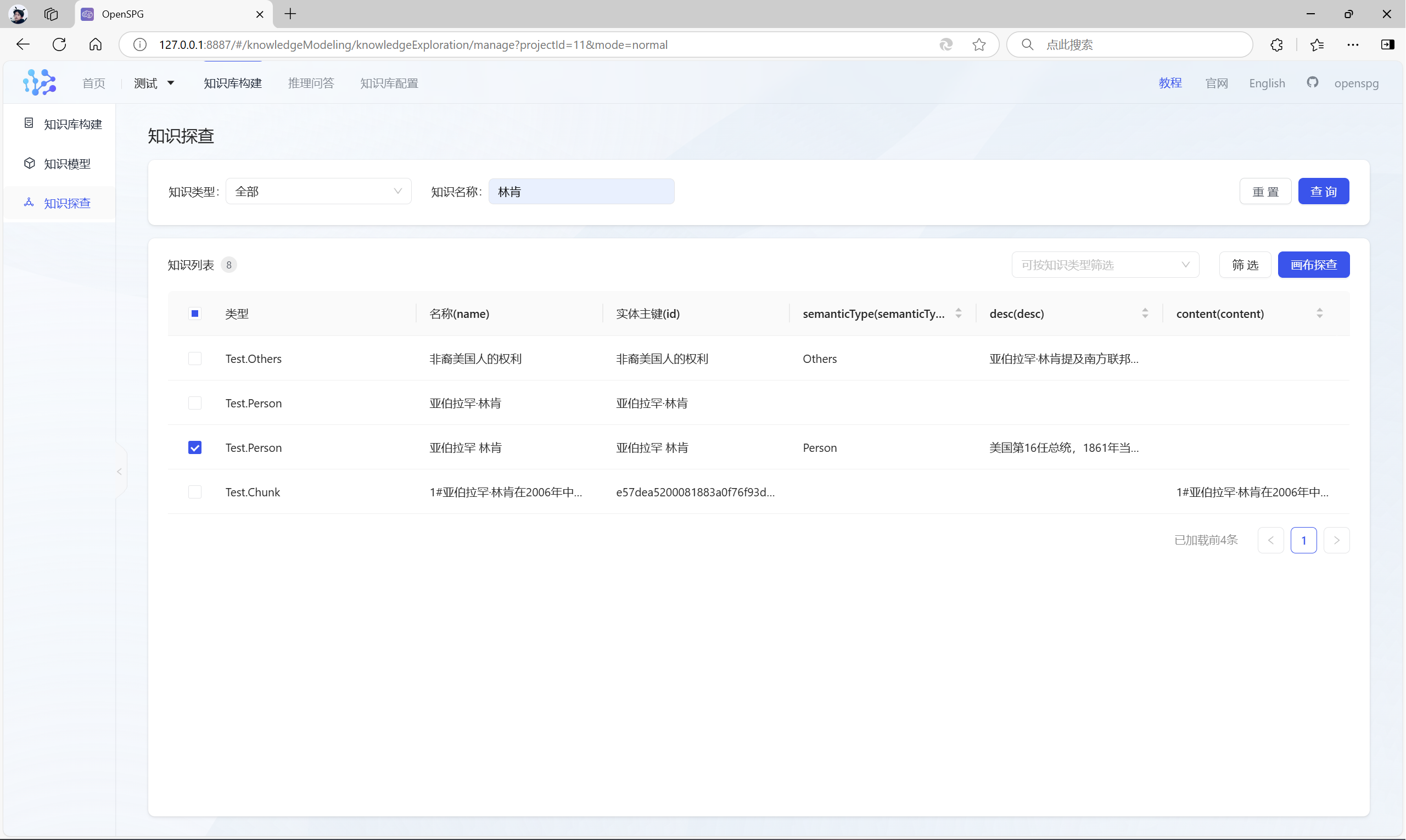
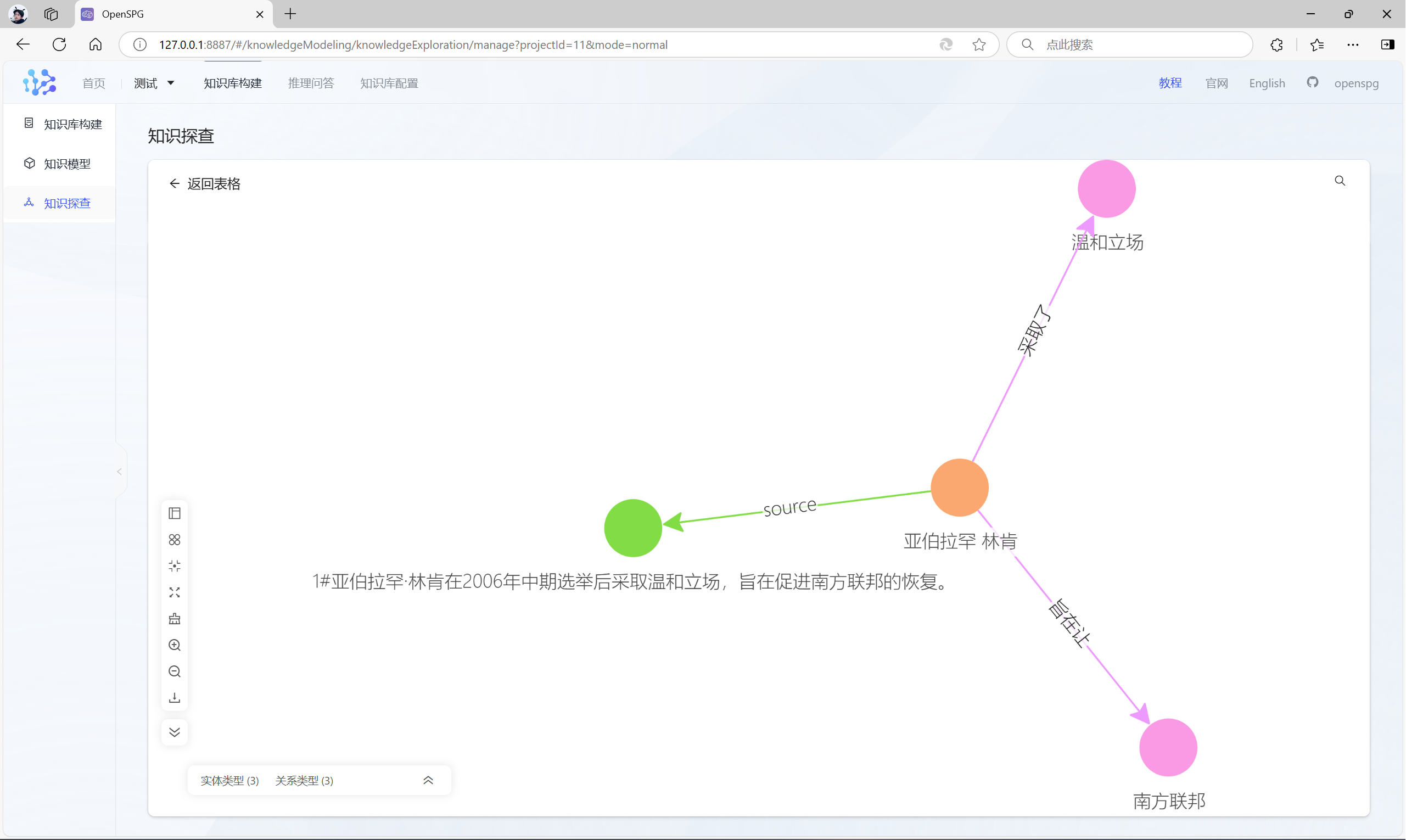
3.4 推理问答
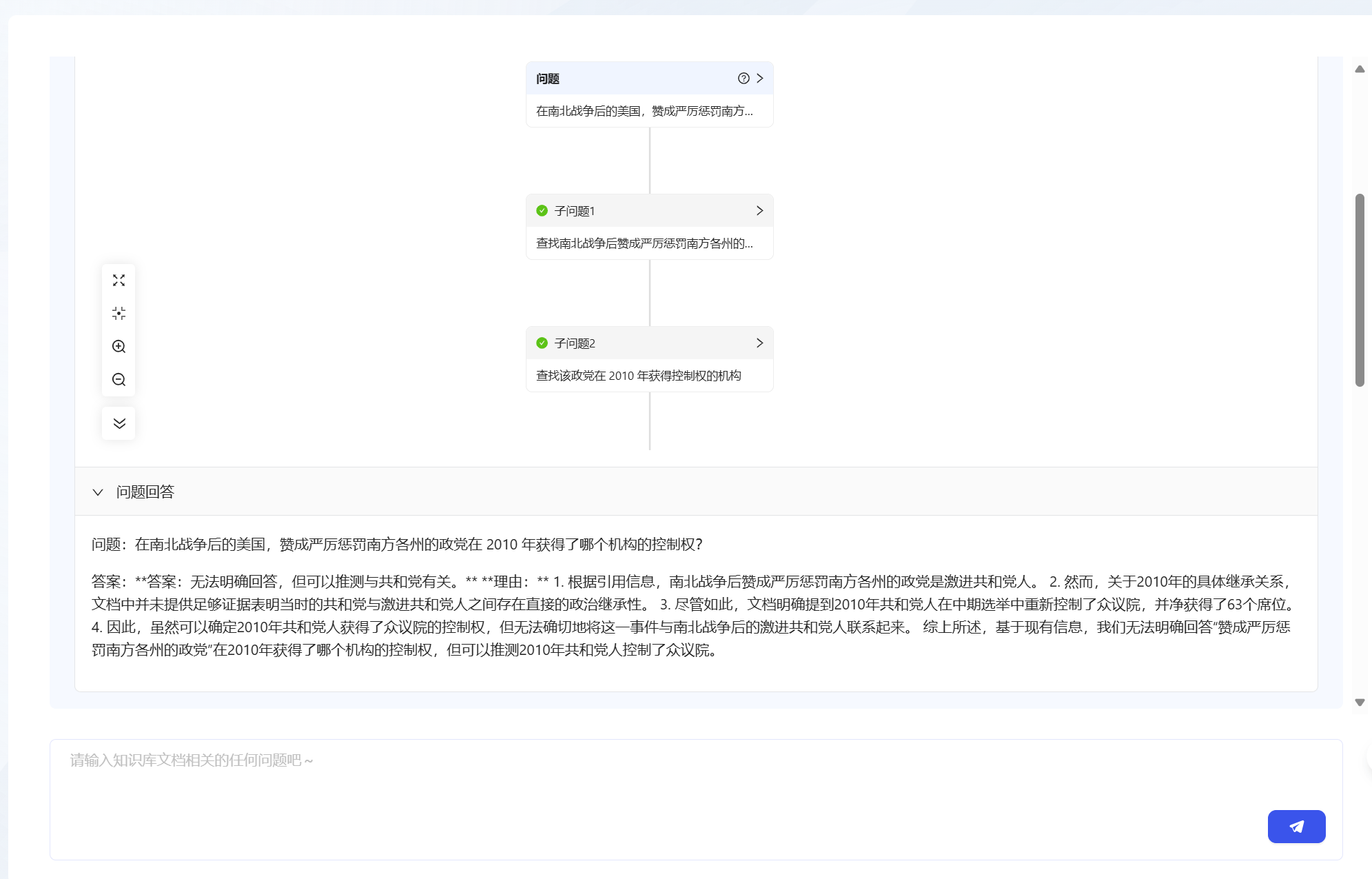
点击知识库的“推理问答”:

不同知识库间的数据是隔离的,只能查询当前知识库中的内容。
然后,输入问题,等待结果返回:
4 KAG 0.6使用(开发者模式)
kag开发者模式通过自定义schema设计、知识抽取prompt、表示模型的选取、问题规划prompt、图谱召回算法、答案生成prompt等,可以实现私域知识库场景,图谱构建和推理问答的效果优化。
4.1 环境配置
KAG依赖于OpenSPG-Server进行元数据管理及图存服务,所以首先要完成服务端的部署,参考第2节。
然后完成虚拟环境的安装:
# 安装conda
# conda安装文档参考:https://docs.anaconda.com/miniconda/# 安装python 虚拟环境:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda create -n kag-demo python=3.10 && conda activate kag-demo# 设置pip 源镜像
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple4.2 代码克隆
代码地址如下:https://github.com/OpenSPG/KAG
或使用如下命令:
git clone https://github.com/OpenSPG/KAG.git然后,进入项目根目录即./KAG,进行KAG安装:
验证是否安装成功:
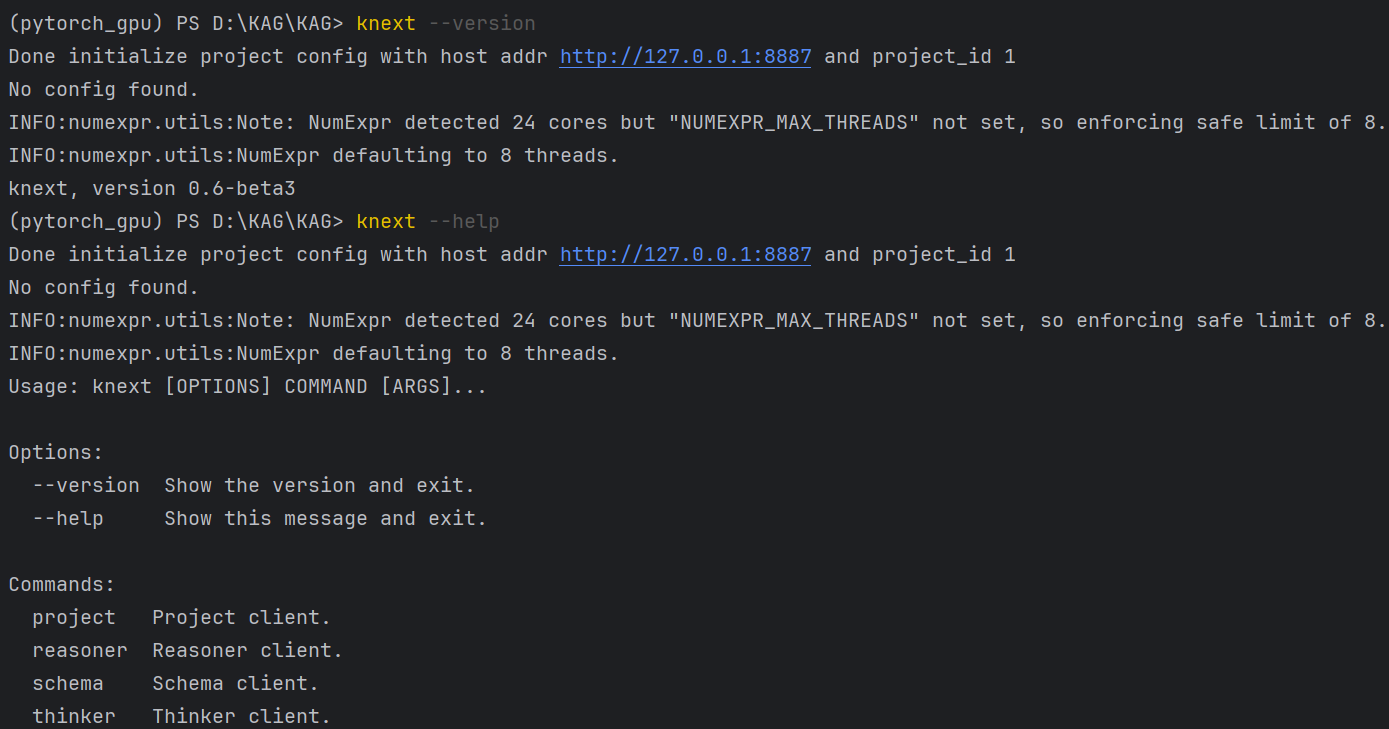
4.3 代码结构
kag的整体代码结构如下:
├──kag├──builder:知识图谱构建├──component:包含各种组件├──1.reader:读取不同类型的数据源├──2.splitter:对读取到的文本数据进行切分处理,将长文本分割成更适合后续处理的片段├──3.extractor:从切分后的文本中提取实体、关系等知识图谱的核心元素├──4.vectorizer:将提取出的实体、关系等知识元素转化为向量表示├──5.aligner:对齐和合并多个子图├──6.writer:将构建好的知识图谱数据写入到指定的存储介质中├──mapping:实现不同数据源、不同格式之间的映射和转换├──scanner:对数据进行快速扫描和预处理,识别数据中的关键信息和结构├──external_graph:用于与外部知识图谱进行交互和融合,可以导入或导出知识图谱数据└──postprocessor:对构建好的知识图谱进行后处理,如数据清洗、格式转换、质量评估等├──model:定义了一些数据模型├──chunk.py:用于表示文本数据的片段├──spg_record.py:用于表示结构化的知识图谱记录└──sub_graph.py:用于表示知识图谱的子图结构├──operator:操作符相关模块├──prompt:提示词模块├──default_chain.py:默认的处理链逻辑└──runner.py:作为KAG项目的运行入口,负责初始化和启动整个知识图谱构建流程├──solver:问题解决和推理├──common:通用模块└──base.py:基础通用模块├──execute:执行模块├──op_executor:具体的操作执行器实现├──default_lf_executor.py:默认的逻辑形式执行器,负责执行逻辑形式的推理和查询├──default_sub_query_merger.py:默认的子查询合并器,用于将多个子查询的结果合并为一个综合的结果└──sub_query_generator.py:子查询生成器,用于将复杂的查询分解为多个子查询├──implementation:实现模块├──default_reasoner.py:默认的推理器,负责基于知识图谱进行逻辑推理├──default_generator.py:默认的生成器,用于生成解决问题所需的逻辑形式或自然语言响应├──default_reflector.py:默认的反思器,用于验证和评估求解过程的正确性└──default_memory.py:默认的反思器,用于验证和评估求解过程的正确性├──logic:逻辑模块├──core_modules:逻辑推理的核心组件和功能,提供了逻辑推理的基本构建块和操作└──solver_pipeline.py:求解器的流水线逻辑,将多个逻辑组件串联起来,形成完整的推理流程├──plan:规划模块└──default_lf_planner.py:默认的规划器,用于生成逻辑形式的求解计划├──prompt:提示词模块├──tools:工具模块├──retriever:检索器模块├──base:基础检索器模块└──kg_retriever.py:定义了知识图谱检索器的基类和接口├──impl:具体检索器模块├──default_chunk_retriever.py:默认的文本片段检索器,用于从知识图谱中检索与问题相关的文本片段├──default_exact_kg_retriever.py:默认的精确知识图谱检索器,用于精确匹配知识图谱中的实体和关系。└──default_fuzzy_kg_retriever.py:默认的模糊知识图谱检索器,用于在知识图谱中进行模糊匹配,适用于查询条件不完全明确的情况。├──chunk_retriever.py:文本片段检索器├──exact_kg_retriever.py:精确知识图谱检索器└──fuzzy_kg_retriever.py:模糊知识图谱检索器├──main_solver.py:主解决器入口文件└──utils.py:工具函数├──common:通用的工具类、函数和配置├──examples:使用实例├──interface:主要组件的接口和抽象基类└──templates:项目中使用的模板文件其中:
- builder:用于知识图谱的构建,分为读取器、切分器、提取器、向量器、对齐器和写入器;
- solver:逻辑形式求解器,用于问题的规划、推理和检索;
- examples:一些使用示例。
4.4 示例
进入项目kag/examples目录.里面有很多的演示示例,参考每个示例里的README.md逐步操作即可:
以2wiki为例:
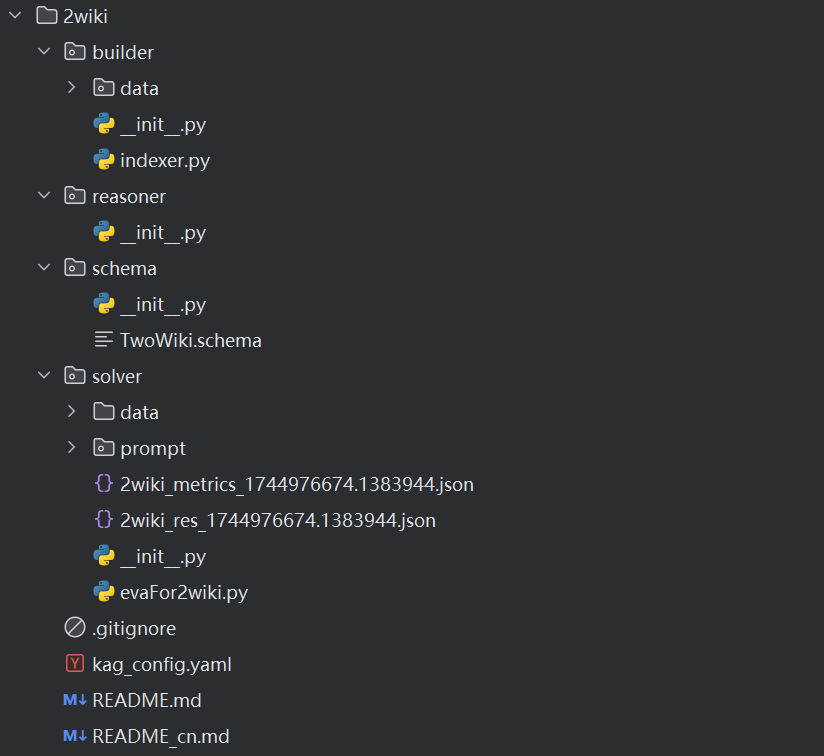
- builder:构建器,用于知识图谱构建:
- data:数据存放,构建过程中使用的数据;
- indexer.py:构建索引脚本,用于创建和管理知识图谱的索引。
- reasoner:推理器,用于知识推理;
- schema:模式,用于提取知识时需参照的模式和规则,例如实体关系;
- solver:求解器,用于进行问题的规划、检索和推理:
- data:数据存放,求解过程中使用的数据;
- prompt:提示,用于引导求解过程的提示信息;
- evaFor2wiki(eval).py:求解器脚本,用于提问和问题的规划、检索、推理。
- kag_config.yaml:配置文件,整个项目的配置信息。
4.5 配置文件解读
下面对示例配置文件进行解读,配置文件总体分为三部分:项目配置、kag-builder配置和kag-solver配置。
4.5.1 项目配置
项目配置代码如下:
openie_llm:api_key: keybase_url: https://api.deepseek.commodel: deepseek-chattype: maaschat_llm: &chat_llmapi_key: keybase_url: https://api.deepseek.commodel: deepseek-chattype: maasvectorize_model: &vectorize_modelapi_key: keybase_url: https://api.siliconflow.cn/v1/model: BAAI/bge-m3type: openaivector_dimensions: 1024
vectorizer: *vectorize_modellog:level: INFOproject:biz_scene: defaulthost_addr: http://127.0.0.1:8887id: '12'language: zhnamespace: SupplyChaincheckpoint_path: ./extract-runner-ckpt其中,需要配置如下:
- openie大模型
- chat大模型
- 向量模型
- 日志级别
- 项目信息
4.5.2 kag-builder配置
定义知识抽取的索引通道,包括字典知识抽取、结构化数据知识抽取、非结构化数据知识抽取。
下面为一个默认的非结构化数据知识抽取示例,有抽取类型、抽取提示词、读取器类型、后处理器类型、切分器类型、向量器类型等:
kag_builder_pipeline:chain:type: unstructured_builder_chain # kag.builder.default_chain.DefaultUnstructuredBuilderChainextractor:type: schema_free_extractor # kag.builder.component.extractor.schema_free_extractor.SchemaFreeExtractorllm: *openie_llmner_prompt:type: default_ner # kag.builder.prompt.default.ner.OpenIENERPromptstd_prompt:type: default_std # kag.builder.prompt.default.std.OpenIEEntitystandardizationdPrompttriple_prompt:type: default_triple # kag.builder.prompt.default.triple.OpenIETriplePromptreader:type: dict_reader # kag.builder.component.reader.dict_reader.DictReaderpost_processor:type: kag_post_processor # kag.builder.component.postprocessor.kag_postprocessor.KAGPostProcessorsplitter:type: length_splitter # kag.builder.component.splitter.length_splitter.LengthSplittersplit_length: 100000window_length: 0vectorizer:type: batch_vectorizer # kag.builder.component.vectorizer.batch_vectorizer.BatchVectorizervectorize_model: *vectorize_modelwriter:type: kg_writer # kag.builder.component.writer.kg_writer.KGWriternum_threads_per_chain: 1num_chains: 16scanner:type: 2wiki_dataset_scanner # kag.builder.component.scanner.dataset_scanner.MusiqueCorpusScanner4.5.3 kag-solver配置
定义了数据检索与知识图谱接口、精确与模糊检索器、文本片段检索器、求解器流水线,用于问题的规划、检索和生成:
search_api: &search_apitype: openspg_search_api #kag.solver.tools.search_api.impl.openspg_search_api.OpenSPGSearchAPIgraph_api: &graph_apitype: openspg_graph_api #kag.solver.tools.graph_api.impl.openspg_graph_api.OpenSPGGraphApiexact_kg_retriever: &exact_kg_retrievertype: default_exact_kg_retriever # kag.solver.retriever.impl.default_exact_kg_retriever.DefaultExactKgRetrieverel_num: 5llm_client: *chat_llmsearch_api: *search_apigraph_api: *graph_apifuzzy_kg_retriever: &fuzzy_kg_retrievertype: default_fuzzy_kg_retriever # kag.solver.retriever.impl.default_fuzzy_kg_retriever.DefaultFuzzyKgRetrieverel_num: 5vectorize_model: *vectorize_modelllm_client: *chat_llmsearch_api: *search_apigraph_api: *graph_apichunk_retriever: &chunk_retrievertype: default_chunk_retriever # kag.solver.retriever.impl.default_fuzzy_kg_retriever.DefaultFuzzyKgRetrieverllm_client: *chat_llmrecall_num: 10rerank_topk: 10kag_solver_pipeline:memory:type: default_memory # kag.solver.implementation.default_memory.DefaultMemoryllm_client: *chat_llmmax_iterations: 3reasoner:type: default_reasoner # kag.solver.implementation.default_reasoner.DefaultReasonerllm_client: *chat_llmlf_planner:type: default_lf_planner # kag.solver.plan.default_lf_planner.DefaultLFPlannerllm_client: *chat_llmvectorize_model: *vectorize_modellf_executor:type: default_lf_executor # kag.solver.execute.default_lf_executor.DefaultLFExecutorllm_client: *chat_llmforce_chunk_retriever: trueexact_kg_retriever: *exact_kg_retrieverfuzzy_kg_retriever: *fuzzy_kg_retrieverchunk_retriever: *chunk_retrievermerger:type: default_lf_sub_query_res_merger # kag.solver.execute.default_sub_query_merger.DefaultLFSubQueryResMergervectorize_model: *vectorize_modelchunk_retriever: *chunk_retrievergenerator:type: default_generator # kag.solver.implementation.default_generator.DefaultGeneratorllm_client: *chat_llmgenerate_prompt:type: default_resp_generator # kag.solver.prompt.default.resp_generator.RespGeneratorreflector:type: default_reflector # kag.solver.implementation.default_reflector.DefaultReflectorllm_client: *chat_llm总结
KAG框架针对知识密集型问答任务提出了一种结合知识对齐和逻辑形式求解的创新方法。通过在多个权威数据集上的实验验证,KAG相较于传统RAG方法展现了显著的性能优势,特别是在多跳推理和知识检索方面。其核心优势在于多步检索策略能够有效避免单步检索的局限性,而知识对齐和逻辑形式求解器则进一步增强了知识图谱的连通性和推理能力。此外,KAG提供了详细的部署和使用文档,支持用户在私域知识库场景下快速构建和应用问答系统。无论是通过可视化界面还是开发者模式,用户均可灵活定制知识抽取、存储和推理过程,以适应不同领域的专业问答需求。总体而言,KAG为知识密集型问答任务提供了一种高效、灵活且易于扩展的解决方案。