《Learning Langchain》阅读笔记10-RAG(6)索引优化:MultiVectorRetriever方法
Indexing Optimization:索引优化
基础的 RAG 索引阶段通常涉及对给定文档进行简单的文本切分并对各段落进行嵌入(embedding)。
然而,这种基础方式会导致检索结果不稳定,并且在数据源包含图像或表格的情况下,幻觉现象(hallucinations)发生频率较高。
[!NOTE] 为什么基础的 RAG 索引方式会导致效果差、幻觉多?
- “朴素切分”割裂了语义完整性
基础做法通常是固定长度切分(如每 500 字一段),不考虑语义边界
它可能会把一段完整逻辑的文本切成两段或多段
导致检索时返回的片段上下文不全、含义模糊
举例:如果你将一个介绍“图神经网络”的段落从中间切断,你只检索到“图结构”或“反向传播”,模型会“脑补”错误内容。
2. 文本嵌入不适合非文本结构(如图表、图片)
图像、表格、代码等非自然语言内容对文本嵌入模型来说是盲区
嵌入结果会很混乱,语义空间不准确
检索时很容易引发幻觉(hallucinations)
RAG 的本质是语义匹配 —— 如果 embedding 是错误的,检索回来就是“看起来相似但实则无关”的文本,模型可能误导生成。
3. 没有多视角表达(Multi-vector)
每个 chunk 只生成一个向量,模型无法知道这个段落有哪些“子语义”
检索时容易漏掉“局部重要信息”
所以才有了后续优化技术:如 MultiVectorRetriever(一个 chunk 多个视角嵌入),更好地覆盖含义。
4. RAG 模型生成太依赖“检索内容质量”
Garbage in, garbage out.
如果索引阶段的内容就不准、被切乱、嵌入错了,那么即使你的大模型再强,它也没法给出正确答案。
为了提升索引阶段的准确性和性能,有多种优化策略可供选择。
在接下来的章节中,我们将介绍三种方法:
- MultiVectorRetriever
- RAPTOR
- ColBERT
MultiVectorRetriever
如果一个文档同时包含文本和表格内容,就不能简单地按文本进行切分并作为上下文嵌入(embedding),因为整个表格很容易在过程中丢失。
为了解决这个问题,我们可以将用于答案生成(answer synthesis)的文档,与用于检索(retriever)的参考信息进行解耦。
图 2-5 展示了具体的方法。
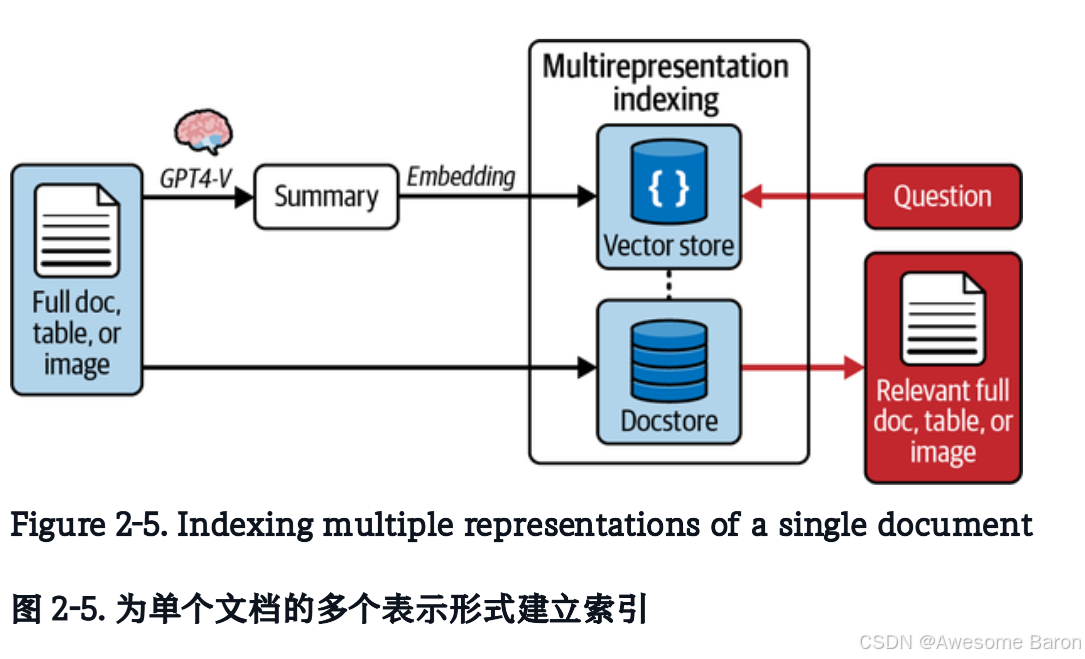
简单来说,例如,对于包含表格的文档,我们可以首先生成一个“表格内容的摘要 summary”(简短概括),把这个摘要生成向量并存入到vector store。
但是我们要确保每个摘要中包含一个指向完整原始表格的 ID 引用。summary里藏着:“我对应的是 Table-123”,到时候真要用的时候,可以根据 ID 找回原表格!
接下来,我们将这些原始表格单独存储在一个独立的docstore中。
最后,当用户查询检索到某个表格摘要时,我们会将完整的原始表格作为上下文传递给 LLM,用于最终的答案生成(answer synthesis)。
这种方法使我们能够为模型提供回答问题所需的完整信息上下文。
对应图2-5我们来梳理梳理流程,首先表格元素将会生成summary存放到vector store中,每个summary中包含一个指向完整原始表格的 ID 引用。但同时我们也会将这些原始表格单独存储在一个独立的docstore中。当用户查询到某个表格摘要时,我们就去docstore中找到完整的原始表格作为上下文传递给LLM,用于最终的答案生成。
MultiVectorRetriever例子
import os
import requestsos.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'r = requests.get("https://www.google.com")
print(r.status_code) # 能返回 200 就说明代理成功了
200
import getpass
import osif "GOOGLE_API_KEY" not in os.environ:os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter your Google AI API key: ")
Enter your Google AI API key: ········
from langchain_google_genai import ChatGoogleGenerativeAIllm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-001", # 或其他可用模型
)print(llm.invoke("你好呀!你现在通了吗?").content)
你好!我一直都在线并准备好为你提供帮助。所以,是的,我可以说是“通了”。有什么我可以为你做的吗?
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.documents import Document
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from tqdm import tqdm
import uuidconnection = 'postgresql+psycopg2://langchain:langchain@localhost:6024/langchain'
collection_name = "summaries"# embed each chunk and insert it into the vector store
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': False}embeddings_model = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)# Load the document
loader = TextLoader("./test.txt", encoding="utf-8")
docs = loader.load()print("length of loaded docs: ", len(docs[0].page_content))# Split the document
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = splitter.split_documents(docs)# The rest of your code remains the same, starting from:
prompt_text = "Summarize the following document:\n\n{doc}"prompt = ChatPromptTemplate.from_template(prompt_text)llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-001", # 或其他可用模型temperature=0,
)# 定义了一个处理链 summarize_chain:
# 取出 chunk 的文本内容 page_content
# 套入 Prompt 模板
# 交给 Gemini LLM生成
# 最后用 StrOutputParser() 把返回结果提取成字符串
summarize_chain = {"doc": lambda x: x.page_content} | prompt | llm | StrOutputParser()# ⭐ 用循环方式,带 tqdm
summaries = []
for chunk in tqdm(chunks, desc="Summarizing chunks"):try:summary = summarize_chain.invoke(chunk)summaries.append(summary)except Exception as e:print(f"遇到错误,跳过一个chunk: {e}")summaries.append("Summary Failed")# 全部完成后
print("\n完成,总结如下:")
for i, s in enumerate(summaries):print(f"第 {i+1} 个总结:{s}")
length of loaded docs: 6604Summarizing chunks: 100%|██████████████████████████████████████████████████████████████| 8/8 [00:12<00:00, 1.61s/it]完成,总结如下:
第 1 个总结:This document introduces the problem of LLMs having limited knowledge due to private data and knowledge cutoffs. While LLMs are trained on vast amounts of public data, they lack access to private information and current events beyond their training date. This can lead to inaccurate or hallucinated responses. Simply adjusting prompts is insufficient to overcome this limitation. The core challenge is how to provide LLMs with relevant context from a large corpus of information without exceeding token limits. The document sets the stage for exploring techniques to select the most relevant information from a large dataset to answer user questions, which is a crucial step in building effective LLM applications. The following chapters will address this challenge in two steps.
第 2 个总结:The document discusses the challenge of providing large amounts of data to Large Language Models (LLMs) when the data exceeds the LLM's token limit. The core problem is how to select the most relevant information from a large text corpus to answer user questions. The solution presented is **Retrieval Augmented Generation (RAG)**, a technique that involves two key steps:1. **Indexing:** Pre-processing documents to make them easily searchable for relevant information.
2. **Retrieval:** Retrieving relevant external data from the index and using it as context for the LLM to generate accurate outputs.The document focuses on the first step, indexing, and uses the example of analyzing Tesla's 2022 annual report. The indexing process, also referred to as "ingestion," involves:* Extracting text from the document.
* Splitting the text into manageable chunks.
* Converting the text into numerical representations (embeddings).
* Storing these numerical representations in a vector store for efficient retrieval.The document highlights that embeddings are numerical representations of text and vector stores are specialized databases for storing these embeddings.
第 3 个总结:This document explains the concept of embeddings and vector stores. Embeddings are numerical representations of text, allowing computers to understand relationships between words. This is a lossy process, meaning the original text cannot be recovered from the embedding alone. The document uses the example of "lion," "pet," and "dog" to illustrate how embeddings can represent semantic similarity. Words with closer meanings, like "pet" and "dog," will have closer vectors in a multi-dimensional space. The document introduces cosine similarity as a method to calculate the similarity between vectors, where a higher value indicates greater similarity. Finally, it mentions that a database specifically designed to store these numerical representations is called a vector store.
第 4 个总结:This document explains how to convert documents into text for preprocessing using LangChain. It introduces LangChain's document loaders, which handle parsing and extracting content from various data sources into a `Document` object (containing text and metadata). The document then provides a practical example using `TextLoader` to load a `.txt` file. It highlights a common error encountered due to the modular structure of recent LangChain versions (requiring separate installation of `langchain-community`) and provides the `pip install -U langchain-community` command to resolve it. Finally, it shows the corrected code with `encoding="utf-8"` to load the text file properly.
第 5 个总结:This document explains how to load text documents using LangChain's `TextLoader`. It provides a code snippet demonstrating how to load a `test.txt` file using the `TextLoader` and highlights the general pattern for using LangChain document loaders: choosing a loader based on the document type, instantiating the loader with relevant parameters (like file path), and calling the `load()` method to retrieve a list of `Document` objects. The document also mentions that LangChain supports various file types (CSV, JSON, Markdown) and integrations (Slack, Notion) and provides an example of using `WebBaseLoader` to load and parse HTML content from a webpage, requiring the `beautifulsoup4` package. Finally, it provides a link to the official LangChain documentation for more information on document loaders.
第 6 个总结:This document demonstrates how to load data into LangChain using two different document loaders: `WebBaseLoader` and `PyPDFLoader`.* **WebBaseLoader:** It shows how to load and parse HTML content from a webpage using `WebBaseLoader`. It requires the `beautifulsoup4` package to be installed. The example loads the LangChain website and extracts its content, including metadata like the source URL, title, description, and language.
* **PyPDFLoader:** It shows how to load text from a PDF document using `PyPDFLoader`. It requires the `pypdf` package to be installed. The example loads a PDF file named "untitled.pdf" and extracts its content.
第 7 个总结:This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
第 8 个总结:The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.
可以看到8个 chunk 生成了8条总结。
lambda x: x.page_content 是一个匿名函数(lambda函数):
-
输入是一个 x
-
x 通常就是一个 Document 对象(LangChain里的文档标准结构)
-
x.page_content 就是这个文档的正文内容(纯字符串)
"doc": lambda x: x.page_content 意思是:
-
创建一个键名叫 “doc”(和你 prompt 模板的 {doc} 对应)
-
键值是一个函数,取出 page_content 作为输入内容
超时特别久,排查原因发现,连接Gemini一定要加上:
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
连接Gemini服务器超时后,我添加了tdqm实时显示进度,方便查看进度。
基本不到一分钟就可以处理6000多个字符的文档了!
现在Gemini可以帮我们总结文献了!芜湖!
接下来,让我们定义vector store和docstore来存储原始摘要和它们的embeddings:
# 初始化子文档(summary)向量存储器,连接到 PGVector 数据库
vectorstore = PGVector(embedding_function=embeddings_model,collection_name=collection_name,connection_string=connection,use_jsonb=True,
)# 初始化父文档(原文)存储器,存储在内存中
store = InMemoryStore()
id_key = "doc_id" # 用于关联父文档和子文档的唯一标识字段# 创建 MultiVectorRetriever,将子文档存入 vectorstore,父文档存入 docstore
retriever = MultiVectorRetriever(vectorstore=vectorstore,docstore=store,id_key=id_key,
)# 为每个文本块(chunk)生成一个唯一的 doc_id
doc_ids = [str(uuid.uuid4()) for _ in chunks]# 根据总结内容(summaries)构造新的文档对象,每个文档带有对应的 doc_id 元数据
summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]})for i, s in enumerate(summaries)
]# 将所有 summary 文档批量插入到向量数据库,用于后续相似度检索
retriever.vectorstore.add_documents(summary_docs)# 将原始 chunks 以 (doc_id, chunk内容) 的形式批量存入内存数据库(docstore)
retriever.docstore.mset(list(zip(doc_ids, chunks)))# 测试:根据用户输入语句检索最相似的 summary 文档(返回 K=2条)
sub_docs = retriever.vectorstore.similarity_search("大模型知识截止", k=2
)print("\n=== 检索到的 Summary 文档 ===")
for idx, doc in enumerate(sub_docs):print(f"\n第 {idx+1} 条检索结果:")print(f"内容 (page_content):\n{doc.page_content}")print(f"元数据 (metadata):\n{doc.metadata}")=== 检索到的 Summary 文档 ===第 1 条检索结果:
内容 (page_content):
The document discusses the challenge of providing large amounts of data to Large Language Models (LLMs) when the data exceeds the LLM's token limit. The core problem is how to select the most relevant information from a large text corpus to answer user questions. The solution presented is **Retrieval Augmented Generation (RAG)**, a technique that involves two key steps:1. **Indexing:** Pre-processing documents to make them easily searchable for relevant information.
2. **Retrieval:** Retrieving relevant external data from the index and using it as context for the LLM to generate accurate outputs.The document focuses on the first step, indexing, and uses the example of analyzing Tesla's 2022 annual report. The indexing process, also referred to as "ingestion," involves:* Extracting text from the document.
* Splitting the text into manageable chunks.
* Converting the text into numerical representations (embeddings).
* Storing these numerical representations in a vector store for efficient retrieval.The document highlights that embeddings are numerical representations of text and vector stores are specialized databases for storing these embeddings.
元数据 (metadata):
{'doc_id': 'a5a22dee-7e14-4822-b53d-9acb49ac9590'}第 2 条检索结果:
内容 (page_content):
The document discusses the challenge of providing large amounts of data to Large Language Models (LLMs) when the data exceeds the LLM's token limit. The core problem is how to select the most relevant information from a large text corpus to answer user questions. The solution presented is **Retrieval Augmented Generation (RAG)**, a technique that involves two key steps:1. **Indexing:** Pre-processing documents to make them easily searchable for relevant information.
2. **Retrieval:** Retrieving relevant external data from the index and using it as context for the LLM to generate accurate outputs.The document focuses on the first step, indexing, and uses the example of analyzing Tesla's 2022 annual report. The indexing process, also referred to as "ingestion," involves:* Extracting text from the document.
* Splitting the text into manageable chunks.
* Converting the text into numerical representations (embeddings).
* Storing these numerical representations in a vector store for efficient retrieval.The document highlights that embeddings are numerical representations of text and vector stores are specialized databases for storing these embeddings.
元数据 (metadata):
{'doc_id': '2fd5985d-664e-45dc-b3af-9543705b63cb'}
出现了报错:
LangChainPendingDeprecationWarning: This class is pending deprecation and may be removed in a future version. You can swap to using the `PGVector` implementation in `langchain_postgres`. Please read the guidelines in the doc-string of this class to follow prior to migrating as there are some differences between the implementations. See <https://github.com/langchain-ai/langchain-postgres> for details about the new implementation.vectorstore = PGVector(
原因:LangChain 团队单独把 PGVector 支持抽到新的独立项目 langchain-postgres 中了,然而我改成from langchain.vectorstores.pgvector import PGVector这个写法是因为之前 psycopg 无法正确加载 libpq 库(PostgreSQL 的底层通信库),所以在导入 PGVector 时报错。新版的 psycopg(也叫 psycopg3),它和旧版 psycopg2 不一样,需要本地系统有 PostgreSQL 的 C 库支持(libpq)。我们的PostgreSQL运行在docker上。所以忽略这个警告,沿用老版写法。
这里出现了一件好笑的事情,我选取k=2,希望返回两条结果最相近的内容,但仔细一看,两条内容的摘要是一样的哈哈哈哈哈。
让我们回到和之前的章节中一样的问题,查看结果是否会不同:
# 测试:根据用户输入语句检索最相似的 summary 文档(返回 K=2条)
sub_docs_2 = retriever.vectorstore.similarity_search("为什么会有“上下文窗口”(context window)", k=2
)print("\n=== 检索到的 Summary 文档 ===")
for idx, doc in enumerate(sub_docs_2):print(f"\n第 {idx+1} 条检索结果:")print(f"内容 (page_content):\n{doc.page_content}")print(f"元数据 (metadata):\n{doc.metadata}")=== 检索到的 Summary 文档 ===第 1 条检索结果:
内容 (page_content):
This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
元数据 (metadata):
{'doc_id': 'fbd86e86-fb05-4f0b-8fde-2c839261f6e4'}第 2 条检索结果:
内容 (page_content):
This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
元数据 (metadata):
{'doc_id': 'bda4368e-7f81-40b4-af61-0842ed9e22b2'}
它返回的摘要依然是相同的两条摘要,但是我们注意到同样的摘要,但是doc_id却不一样:
检索到的 2 条结果,page_content(摘要内容)是一样的,
但是 metadata["doc_id"](文档ID)却不一样,比如:
| 内容 | doc_id |
|---|---|
| 同一段 summary | fbd86e86-fb05-4f0b-8fde-2c839261f6e4 |
| 同一段 summary | bda4368e-7f81-40b4-af61-0842ed9e22b2 |
这是为什么呢?
-
首先每个 chunk(小块文本)生成了一个新的 doc_id。不管 summary 内容是不是重复的,系统都会给每个 chunk 单独生成一个 uuid。
-
doc_id = str(uuid.uuid4())是 每个 chunk 随机分配的,不会检查内容重复。
而 doc_id 是用来建立子文档(summary)和父文档(原文 chunk)之间的一一对应关系的桥梁。它唯一标识每一个原始 chunk,summary 与原文 chunk 通过 doc_id 关联,检索后能精准找回原文,支持多视角检索——同一个原文可以挂多个子向量(summary、keyword等),但都通过同一个 doc_id挂回去。
而我们这里为什么会对应同样的summary,不同的doc_id呢?
答案就是:我运行了**两次插入(add_documents 或 index)**的代码,
所以即使 summary 内容相同,系统还是重新生成了新的 doc_id,并插入了新的记录。
排查原因是通过去数据库可视化界面pgAdmin查询SQL语句发现的:
你可以输入
SELECT cmetadata->>'doc_id', document
FROM langchain_pg_embedding;
查看doc_id以及对应的document。cmeta是一个json类型的数据。
-
cmetadata->>'doc_id'代表提取 cmetadata 这个 JSON 字段里的 doc_id 字符串 -
document 是对应的 summary 内容
最后,让我们根据query查询检索相关的完整上下文文档:
# Whereas the retriever will return the larger source document chunks:
retrieved_docs = retriever.invoke("为什么会有“上下文窗口”(context window)")print("=== 检索到的文档 ===\n")for i, doc in enumerate(retrieved_docs, 1):print(f"第 {i} 条结果:")print(f"内容 (page_content):\n{doc.page_content}\n")print(f"元数据 (metadata):\n{doc.metadata}\n")print("=" * 50) # 分割线
=== 检索到的文档 ===第 1 条结果:
内容 (page_content):
```python
from langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("./untitled.pdf")
pages = loader.load()# 只打印每页的纯文本内容
for i, page in enumerate(pages):print(f"--- Page {i + 1} ---")print(page.page_content)
```
输出为:--- Page 1 ---u n t i t l e d 11111111111111111111111111222222222222222222222223333333333333333我们的简单示例中,文本已经从 PDF 文档中提取出来并保存在 Document 类中。但是,有一个问题。假如加载的文档长度超过 100,000 个字符,不适合大多数 LLM 或嵌入模型的上下文窗口。为了克服这一限制,我们需要将 Document 拆分为可管理的文本块,以便稍后将其转换为嵌入并进行语义搜索,从而进入第二步(retrieving检索)。> **注意:**
> 大语言模型(LLMs)和嵌入模型在输入和输出的token数量上都存在严格的限制。这个限制通常被称为 上下文窗口(context window),它通常适用于输入和输出的总和。
>
>也就是说,如果上下文窗口大小为 100(我们稍后会解释单位),而你的输入占用了 90 个 token,那么输出最多只能为 10 个 token。
>
>上下文窗口通常以 token 数量来衡量,例如 8192 个 token。
>
>Token(如前言中提到的)是文本的数值表示,每个 token 通常对应 3 到 4 个英文字符。元数据 (metadata):
{'source': './test.txt'}==================================================
# Whereas the retriever will return the larger source document chunks:
retrieved_docs = retriever.invoke("context window")print("=== 检索到的文档 ===\n")for i, doc in enumerate(retrieved_docs, 1):print(f"第 {i} 条结果:")print(f"内容 (page_content):\n{doc.page_content}\n")print(f"元数据 (metadata):\n{doc.metadata}\n")print("=" * 50) # 分割线
=== 检索到的文档 ===第 1 条结果:
内容 (page_content):
> [!NOTE] **为什么会有“上下文窗口”(context window)这个限制?**
>
>1. 资源限制:计算成本高> 每次你和大语言模型对话,它其实是在处理一个非常复杂的数学计算过程,背后是巨大的矩阵运算。 > 输入越长,占用的 显存(GPU memory) 和 计算时间 就越多。
>输入+输出的长度太长,会让显卡扛不住,或者处理速度变得非常慢。
>所以模型必须设置一个“上限”——这就是 context window,也叫“上下文窗口”。>
>
>2. 模型设计:Transformer 架构的限制> 大语言模型(如 GPT)基于 Transformer 架构。> Transformer 是靠“注意力机制”处理每一个 token 的。> 每加一个 token,就要考虑它和之前所有 token 的关系,所以计算量是平方级别增长的(O(n²))。> 这意味着:> 上下文越长,注意力机制越慢,成本越高,效果也可能下降。
>3. 训练方式决定了这个限制> 模型训练时,是在固定长度的上下文窗口中学习的,比如 2048、4096 或 8192 个 token。> 如果你测试时突然给它一个比训练时长得多的输入,模型可能根本不知道怎么处理。> 所以训练时设置了窗口,使用时就要遵守这个规则。
>
> ---------------------
>一个简单类比:
>
>想象你在读一本书,但你只能记住最近的一页内容(上下文窗口),太久以前的内容就记不清了。
>
>模型也是这样,它记得的“最近内容”数量是有限的。元数据 (metadata):
{'source': './test.txt'}==================================================
又发现了一个问题对不对,当我输入中文“为什么会有“上下文窗口”(context window)”返回的检索是错误的,但当我只输入英文“context window”返回的检索却是对的。
# 测试:根据用户输入语句检索最相似的 summary 文档(返回 K=2条)
sub_docs_3 = retriever.vectorstore.similarity_search("context window", k=2
)print("\n=== 检索到的 Summary 文档 ===")
for idx, doc in enumerate(sub_docs_3):print(f"\n第 {idx+1} 条检索结果:")print(f"内容 (page_content):\n{doc.page_content}")print(f"元数据 (metadata):\n{doc.metadata}")=== 检索到的 Summary 文档 ===第 1 条检索结果:
内容 (page_content):
The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.
元数据 (metadata):
{'doc_id': 'dec3d223-0243-4ab2-b43e-c120ff0264d4'}第 2 条检索结果:
内容 (page_content):
The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.
元数据 (metadata):
{'doc_id': '2a39827f-0ed9-4a3d-a445-c30e779f9625'}
我理解了这个问题,输入中文“为什么会有“上下文窗口”(context window)”返回的检索是错误的,但当只输入英文“context window”返回的检索却是对的,其实这里并不分对错。我们可以看看chunk 7 的英文总结,其实这里也包含了context window的内容(加粗内容):
第 7 个总结:This Python code snippet uses the
langchainlibrary to load a PDF document named “untitled.pdf” and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
那么我们来分析一下什么出现中英文查询命中不同 summary :
[!NOTE] 为什么出现中英文查询命中不同 summary 的现象?
出现中英文查询命中不同 summary 的原因,主要有以下几点:
Embedding 模型的语言偏好
你用的是 sentence-transformers/all-mpnet-base-v2,这是一个以英语为主训练的模型,虽然它对多语言也有一定支持,但对中文的理解和表达能力远不及对英文的精细度。当你直接把中文(甚至是中英文混合)查询送入模型时,模型对“为什么”这样的中文词语,或者中英文混合的输入,往往只能做“粗略”或“零散”的编码。对于 “为什么会有“上下文窗口”(context window)” 这样的混合查询,模型会把你的“为什么”“上下文窗口”这些中文,以及括号里的英文“context window”都尽量编码进向量里,但这种向量往往更倾向于匹配那些对“上下文窗口”概念做了概括性、定义性描述的文本(你的 chunk7 摘要正好是在解释什么是 context window、为什么要分片等)。
而对纯英文 “context window”,模型会给出一个更“纯净”的英文向量,更容易和那些深入讨论“context window 限制原因”细节的文档(你的 chunk8)匹配上。
摘要内容的语言一致性
你的所有 summary_docs 均为英文摘要,因此如果用纯英文查询,自然会命中更“纯粹”的英文解释(chunk8);而中英文混合查询里带有大量中文信号,模型就会偏好那些也更偏向概念、背景介绍的摘要(chunk7)。
Embedding 正规化
你把 encode_kwargs={‘normalize_embeddings’: False} 关掉了归一化。关闭归一化后,不同语言、不同长度的向量在向量空间里的“距离”计算(一般是点积或余弦)会更受输入长度、词汇分布等因素影响,进一步放大了跨语言查询与英文文档之间的差异。
如何让中英文查询更一致地命中相同文档呢?
[!NOTE] 如何让中英文查询更一致地命中相同文档?
1.使用多语言或中文专用的 embedding 模型
换成多语言模型,例如 sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2;
或者中文专用模型,比如 shibing624/text2vec-large-chinese。
这样对中英文查询都有更一致的向量表示。
2.对中文查询做翻译预处理
在送入向量数据库前,把中文查询用 LLM 或其他翻译服务先转成英文,再做检索。
3.保持 embedding 归一化
把 normalize_embeddings 打开,确保所有向量都投影到同一单位球面上,用余弦相似度比较时对长短、语言分布的敏感度会更低。
4.为 chunk 生成中英文双语 summary
在生成摘要时,同时输出中英文版本,或者用中文再生成一次摘要,这样中文查询能直接匹配中文摘要。
我们来验证一下 把 normalize_embeddings 打开,确保所有向量都投影到同一单位球面上,用余弦相似度比较:
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain_core.documents import Document
import uuid# 假设你已经准备好了 summary_docs 列表:
# summary_docs = [
# Document(page_content=s, metadata={"doc_id": id})
# for s, id in zip(summaries, doc_ids)
# ]# 1. 新的 collection 名称,避免覆盖旧库
new_collection = "summaries_normalized"# 2. 初始化 embedding 模型,开启 L2 归一化
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings_model = HuggingFaceEmbeddings(model_name=model_name,model_kwargs={"device": "cuda"},encode_kwargs={"normalize_embeddings": True}, # 打开归一化
)# 3. 初始化 PGVector,使用 cosine 距离策略
normalized_vectorstore = PGVector(connection_string="postgresql+psycopg2://langchain:langchain@localhost:6024/langchain",collection_name=new_collection,embedding_function=embeddings_model,use_jsonb=True,distance_strategy="cosine", # 指定余弦相似度
)# 4. 批量写入新的向量库
normalized_vectorstore.add_documents(summary_docs)# 5. 对比测试:两条不同查询
queries = [("中英混合查询", "为什么会有“上下文窗口”(context window)"),("纯英文查询", "context window"),
]for label, q in queries:results = normalized_vectorstore.similarity_search(q, k=2)print(f"\n=== {label}: '{q}' ===")for i, doc in enumerate(results, start=1):print(f"第 {i} 条结果:")print(doc.page_content)=== 中英混合查询: '为什么会有“上下文窗口”(context window)' ===
第 1 条结果:
This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
第 2 条结果:
The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.=== 纯英文查询: 'context window' ===
第 1 条结果:
The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.
第 2 条结果:
This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
很惊人的发现:这次检索出的两条查询是不一样的,并且新建了新的 collection解决了之前我对同一个collection两次插入add_documents的问题。
这里我们仅仅改动部分代码保持 embedding 归一化,把 normalize_embeddings 打开,用余弦相似度比较。
验证了——模型对中英混合输入的query和英文输入的query返回的结果是不一样的。
下面我们再来验证一下embedding模型的影响:
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain_core.documents import Document
import uuid# 1. 新的 collection 名称,避免覆盖旧库
new_collection = "summaries_normalized_embeddingmodel_new"# 2. 初始化 embedding 模型,开启 L2 归一化
# 并且更换embedding模型为sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2,以支持多语言
model_name = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
embeddings_model = HuggingFaceEmbeddings(model_name=model_name,model_kwargs={"device": "cuda"},encode_kwargs={"normalize_embeddings": True}, # 打开归一化
)# 3. 初始化 PGVector,使用 cosine 距离策略
normalized_vectorstore = PGVector(connection_string="postgresql+psycopg2://langchain:langchain@localhost:6024/langchain",collection_name=new_collection,embedding_function=embeddings_model,use_jsonb=True,distance_strategy="cosine", # 指定余弦相似度
)# 4. 批量写入新的向量库
normalized_vectorstore.add_documents(summary_docs)# 5. 对比测试:两条不同查询
queries = [("中英混合查询", "为什么会有“上下文窗口”(context window)"),("纯英文查询", "context window"),
]for label, q in queries:results = normalized_vectorstore.similarity_search(q, k=2)print(f"\n=== {label}: '{q}' ===")for i, doc in enumerate(results, start=1):print(f"第 {i} 条结果:")print(doc.page_content)=== 中英混合查询: '为什么会有“上下文窗口”(context window)' ===
第 1 条结果:
The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.
第 2 条结果:
This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.=== 纯英文查询: 'context window' ===
第 1 条结果:
The "context window" limitation in large language models (LLMs) exists due to three main reasons:1. **Resource Constraints (High Computational Cost):** Processing longer inputs requires more GPU memory and computation time due to complex matrix operations. Exceeding the context window can overwhelm the hardware or significantly slow down processing.2. **Transformer Architecture Limitations:** LLMs are based on the Transformer architecture, which uses an "attention mechanism." The computational cost of this mechanism increases quadratically (O(n²)) with the length of the context, making longer contexts slower, more expensive, and potentially less effective.3. **Training Methodology:** LLMs are trained on fixed-length context windows. Providing an input longer than the training window during testing can lead to unpredictable behavior because the model hasn't been trained to handle such lengths.In essence, the context window is a limit imposed by hardware capabilities, architectural design, and training data constraints. It's like reading a book and only being able to remember the most recent page.
第 2 条结果:
This Python code snippet uses the `langchain` library to load a PDF document named "untitled.pdf" and then prints the text content of each page. The code then discusses the problem of large documents exceeding the context window limitations of Large Language Models (LLMs) and embedding models. It highlights the need to split the document into smaller, manageable chunks for embedding and semantic search. The text also explains the concept of a context window, its limitations on input and output token counts, and the meaning of tokens in the context of LLMs.
到这里,我们的疑问已经解开,两条查询返回了一样的结果,在我们更换embeding模型为sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2后。
换用 paraphrase-multilingual-MiniLM-L12-v2 + L2 归一化后,模型具备了更强的跨语言对齐能力,并且检索只看向量方向不看幅度,致使中英文含义相同的查询映射到了几乎同一个点,自然得到了完全相同的检索结果。
当你在 HuggingFaceEmbeddings 里设置 normalize_embeddings=True,它就会自动帮你把每个文本 embedding 除以自身的 L2 范数,变成单位向量。
在 PGVector 里指定 distance_strategy=“cosine” 后,底层检索实际就是在这些已归一化的向量间计算点积——等价于计算余弦相似度。
好处:不管原始文本多长、多短,或含有多少词,只要语义相近,方向就会靠得更近,检索结果就更聚焦于“语义相似度”本身,而不会被向量长度(信息量多少)左右。