【Hive入门】Hive基础操作与SQL语法:DML操作全面解析
目录
1 Hive DML操作概述
2 数据加载操作
2.1 LOAD DATA语句
2.2 INSERT语句
3 数据导出操作
3.1 INSERT OVERWRITE DIRECTORY
3.2 使用HDFS命令导出
4 数据更新与删除
4.1 UPDATE语句
4.2 DELETE语句
5 MERGE操作(Hive 2.2+)
6 性能优化建议
7 常见问题与解决方案
8 总结
1 Hive DML操作概述
Hive(Hadoop数据仓库工具)的DML(Data Manipulation Language,数据操作语言)是Hive SQL中用于数据操作的核心部分,主要包括数据的加载、插入、更新、删除等操作。与传统的RDBMS相比,Hive的DML操作有其特殊性,主要因为Hive构建在Hadoop之上,遵循"一次写入,多次读取"的原则。
- 核心概念解析
外部表与内部表:
- 内部表(Managed Table):Hive拥有表数据,删除表时数据也会被删除
- 外部表(External Table):Hive只管理元数据,删除表不会影响实际数据
分区与分桶:
- 分区(Partition):按照某个字段的值将数据分散存储,提高查询效率
- 分桶(Bucket):在分区基础上进一步将数据分散,用于数据采样和JOIN优化
数据存储格式:
- TextFile:默认格式,文本文件
- SequenceFile:二进制键值对格式
- ORC/Parquet:列式存储格式,高效压缩
2 数据加载操作
2.1 LOAD DATA语句
-- 基本语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)];
步骤说明:
- 判断是否为本地文件(LOCAL关键字)
- 如果是本地文件,将其上传到HDFS
- 将文件移动到Hive表对应的HDFS目录
- 更新Hive元数据,使数据对查询可见
- 示例
-- 加载本地数据到内部表
LOAD DATA LOCAL INPATH '/opt/data/employee.txt' INTO TABLE employee;-- 加载HDFS数据到分区表
LOAD DATA INPATH '/user/hive/data/employee_partitioned'
INTO TABLE employee_partitioned PARTITION (dept='IT');2.2 INSERT语句
Hive提供多种INSERT操作方式,比LOAD更灵活:
-- 基本语法
INSERT INTO TABLE tablename [PARTITION (partcol1=val1, ...)]
select *from statement;- 多表插入(高效方式):
FROM source_table
INSERT INTO TABLE target1 SELECT col1, col2 WHERE condition1
INSERT INTO TABLE target2 SELECT col1, col3 WHERE condition2;- 动态分区插入:
-- 启用动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;INSERT INTO TABLE employee_partitioned
PARTITION (dept, country)
SELECT id, name, salary, dept, country FROM employee_staging;3 数据导出操作
3.1 INSERT OVERWRITE DIRECTORY
-- 基本语法
INSERT OVERWRITE [LOCAL] DIRECTORY 'directory'
[ROW FORMAT row_format] [STORED AS file_format]
select_statement;- 示例:
-- 导出到HDFS
INSERT OVERWRITE DIRECTORY '/user/output/employee_data'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT * FROM employee;-- 导出到本地
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/employee_data'
STORED AS TEXTFILE
SELECT * FROM employee WHERE dept='IT';3.2 使用HDFS命令导出
# 直接从HDFS复制表数据文件
hadoop fs -get /user/hive/warehouse/employee /local/path4 数据更新与删除
4.1 UPDATE语句
-- 基本语法
UPDATE tablename SET column = value [, column = value ...]
[WHERE expression];注意事项:
- 需要表支持ACID(Hive 0.14+)
- 需要设置事务支持:
SET hive.support.concurrency=true;
SET hive.enforce.bucketing=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;4.2 DELETE语句
-- 基本语法
DELETE FROM tablename [WHERE expression];- 示例:
-- 删除特定记录
DELETE FROM employee WHERE id = 100;-- 删除分区数据(更高效的方式)
ALTER TABLE employee_partitioned DROP PARTITION (dept='HR');5 MERGE操作(Hive 2.2+)
-- 基本语法
MERGE INTO target_table
USING source_table
ON merge_condition
WHEN MATCHED [AND condition] THEN UPDATE SET col1=val1[, col2=val2...]
WHEN MATCHED [AND condition] THEN DELETE
WHEN NOT MATCHED [AND condition] THEN INSERT VALUES (col1[, col2...]);- 操作流程图:
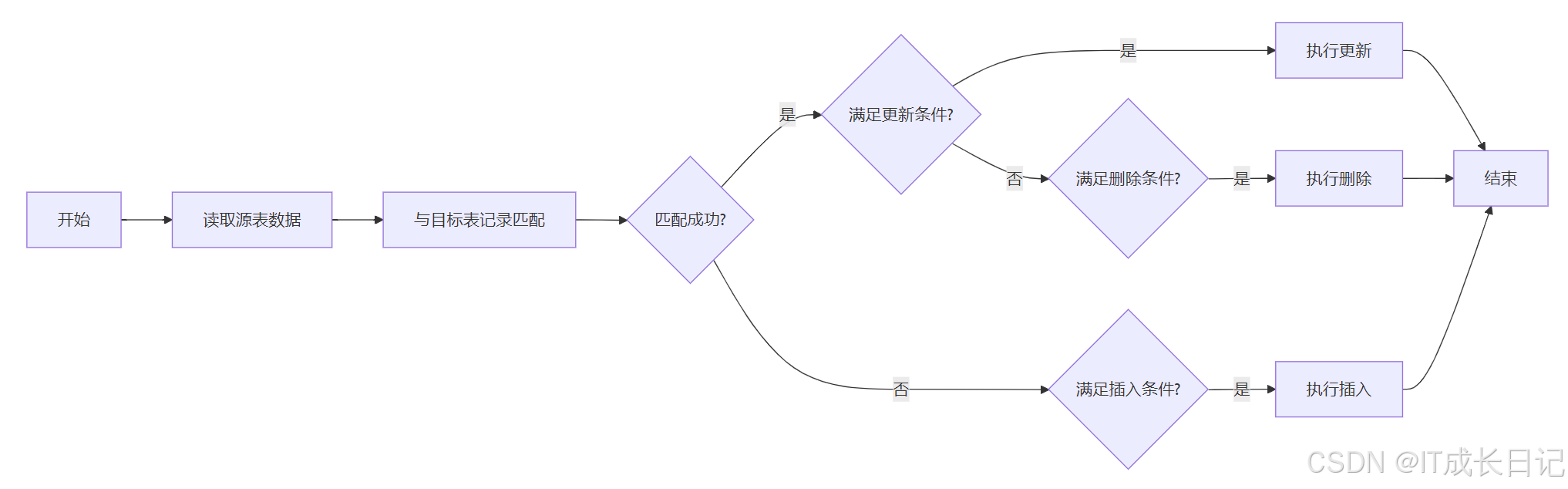
- 示例:
MERGE INTO employee_target t
USING employee_source s
ON t.id = s.id
WHEN MATCHED AND s.dept = 'Obsolete' THEN DELETE
WHEN MATCHED THEN UPDATE SET name=s.name, dept=s.dept, salary=s.salary
WHEN NOT MATCHED THEN INSERT VALUES (s.id, s.name, s.dept, s.salary);6 性能优化建议
- 分区裁剪:WHERE条件中指定分区字段
- 使用合适文件格式:ORC/Parquet格式+压缩
- 避免小文件:合并小文件或使用HAR
- 合理使用分桶:对JOIN字段分桶
- 并行执行:SET hive.exec.parallel=true;
7 常见问题与解决方案
数据倾斜问题:
- 现象:某些reduce任务处理时间远长于其他任务
- 解决方案:使用DISTRIBUTE BY或SKEW JOIN优化
动态分区过多:
- 现象:创建大量小分区
- 解决方案:限制最大动态分区数hive.exec.max.dynamic.partitions
ACID操作失败:
- 检查表是否配置为事务表(TBLPROPERTIES ('transactional'='true'))
- 确认Hive版本支持事务
8 总结
Hive DML操作是数据仓库ETL流程的核心部分,理解各种数据操作方式及其适用场景对于构建高效的数据处理流程至关重要。随着Hive版本的更新,越来越多的传统数据库特性(如ACID)被引入,使得Hive在大数据环境下的数据操作更加灵活和强大。