给视频自动打字幕:从Humanoid-X、UH-1到首个人形VLA Humanoid-VLA:迈向整合第一人称视角的通用人形控制
前言
本博客内,之前写了比较多的大脑相关的,或者上肢操作,而解读运动控制、规划的虽也有,但相对少
故近期 准备多写写双足人形的运动控制相关
- 一方面,我司「七月在线」有些客户订单涉及这块
- 二方面,想让双足人形干好活,运动控制、sim2real 都还存在一些问题
故,本文来了
第一部分 从海量人类视频中学习以实现通用人形姿态控制
1.1 提出背景与相关工作
1.1.1 提出背景
扩展性在深度学习中至关重要
- 最近在计算机视觉领域的进展表明,扩展训练数据可以带来更强大的视觉识别[26,41,44]和生成[3,51]基础模型
- 在机器人领域,研究人员采用类似的范式,通过收集大量的机器人演示来构建用于机器人操作的基础模型[4,5,24,40]。然而,与丰富且易于获取的图像和视频相比,收集大规模的机器人演示既昂贵又耗时,这限制了当前机器人学习方法的扩展性
这引发了一个问题:是否可以将视频用作演示,以提高机器人学习的扩展性?为了解决这一挑战,人们做出了许多努力,例如从自然视频中学习可供性[2,15,28]、流[67,69]和世界模型[68],这些方法使机器人操作更具普遍性
然而,当它涉及人形机器人时,从视频中学习这种动作表示仍然是一个开放的问题。与机械臂不同,人形机器人具有独特的运动学结构和更多的自由度(DoFs),使得它们更难控制
- 现有工作[8,9,16,17,30,47,48]利用大规模强化学习来学习鲁棒的类人控制策略,但它们只专注于有限的机器人技能,例如运动或跳跃,使其在处理日常任务时的泛化能力较差
- 其他工作[13,19,20,53]通过远程操作控制人形机器人,但它们需要人工收集机器人数据,因此可扩展性较差
与这些先前的工作相比,从大量视频中学习通用的动作表示将极大地提高人形机器人学习的可扩展性,并实现更具泛化能力的类人姿态控制
为了弥合人形机器人学习的这一差距,作者引入了Humanoid-X——其项目网站为:usc-gvl.github.io/UH-1,这是一个从大规模多样化视频集合中策划的大型数据集,用于通用人形姿态控制
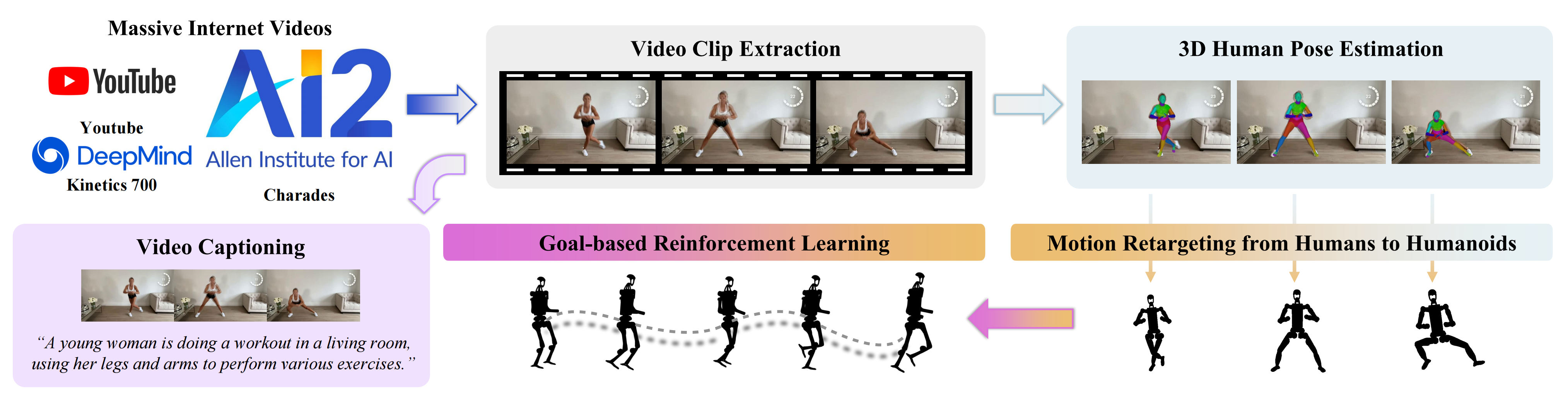
- Humanoid-X利用自然语言作为连接人类命令与人形机器人动作的接口,使人类可以通过与人形机器人对话来控制其动作。自然语言表示通过字幕工具从视频中提取,并用于描述人形机器人的动作
对于动作表示,Humanoid-X结合了用于高级控制的机器人关键点和用于直接位置控制的机器人目标自由度(DoF)位置 - 为了从人类视频中提取人形动作
首先从视频中重建3D人类及其动作
最终,作者从学术数据集和互联网收集了超过16万个人类为中心的视频,涵盖多样的动作类别,且在进一步将这些视频转化为文本-动作对,生成超过两千万个人形动作及其对应的文本描述
再进一步,基于Humanoid-X数据集,作者还研究了如何利用大规模文本-动作对来学习通用的人形姿态控制模型——引入了Universal Humanoid-1(UH-1),这是一个用于通用语言条件下的人形姿态控制的大型人形模型

UH-1利用Transformer架构的可扩展性来高效处理海量数据
- 首先将2000万个人形动作离散化为动作token,创建了一个运动原语的词汇表
- 然后,给定一个文本指令作为输入,Transformer模型以自回归方式解码出这些tokenized的人形机器人动作序列
对于涉及机器人关键点的动作表示,作者使用额外的动作解码器将其转换为机器人自由度位置 - 最后,利用比例 - 微分(PD)控制器将自由度位置转换为电机扭矩,从而能够控制类人机器人并在现实世界中部署它们
1.1.2 相关工作
第一,对于从互联网数据中学习机器人
- 许多尝试已经致力于从非机器人数据,尤其是互联网视频中,学习可扩展的机器人学习策略。关键思想是从海量视觉数据中学习有价值的表示,并将其迁移到机器人任务中
- 学习表示包括从视频中预训练的视觉特征[36,39,46,65]以及可迁移的动作表示,例如可供性[1,2]和以对象为中心的流[67,69]
- 其他工作[12,38,68]尝试从互联网视频中学习世界模型。然而,大多数这些工作集中在机器人操作上。由于机器人手臂的运动学结构与人形机器人完全不同,用于机器人操作的视觉和动作表示无法迁移到人形机器人控制
相比之下,作者研究如何从海量视频中学习人形机器人的通用姿态控制
第二,对于人形机器人的训练/学习
大量工作致力于学习能够实现人形机器人稳健控制的策略
- 一些工作集中于使用大规模强化学习[8,16,17,30,48]或模仿学习[49,57]进行人形机器人运动。其他工作通过模仿学习[29,71]学习人形机器人操作
- 值得注意的是,一些工作[9,13,19–21]通过将动作从3D人类转移到人形机器人来学习人形机器人远程操作
然而,这些工作依赖于校准良好的动作捕捉数据,这限制了它们对未见过的动作的泛化能力 - 相比之下,作者的方法作为一个完全自主的代理运行,它从海量的互联网视频中学习,并能够基于任意文本指令进行通用的人形姿态控制
In contrast, our method operates as a fully autonomous agent that learns from massive Internet videosand performs generalizable humanoid pose control based onarbitrary text commands
第三,对于3D人类动作生成
- 许多研究尝试通过Transformers [22,72] 或扩散模型[31,54,60,66,74] 生成多样化的3D人类动作
此外,一些研究 [14,34,35,42,43,58,64,70]试图生成逼真的动作来为基于物理的虚拟角色赋予生命 - 然而,人形机器人在许多方面与数字人类本质上不同:
1) 它们具有不同的关节结构和自由度;
2) 人形机器人无法访问像线速度这样的特权信息,而这些信息在控制虚拟人类时是随手可得的;
3) 人形机器人具有诸如电机扭矩限制的物理约束,而3D虚拟人类没有这些限制 - 一个可替代的解决方案是首先生成3D人类动作,然后将它们重新定向到人形机器人 [19,23]
与这些方法相比,作者的UH-1模型通过直接将文本指令映射到可执行的人形动作而无需中间步骤,提供了更简化的解决方案。此外,与依赖昂贵动作捕捉数据训练的人类动作生成模型不同,从大量视频中学习显著增强了他们方法的泛化能力
1.2 2000 万帧、总计约240 小时的Humanoid-X数据集
为了利用大量人类视频扩展人形机器人学习,他们引入了Humanoid-X,这是迄今为止最大的人形机器人数据集,由广泛且多样化的视频集合编制而成,用于通用人形机器人姿态控制
Humanoid-X包含163,800个动作样本,涵盖了全面的动作类别。数据集中的每个动作样本包含5种数据模态:
- 一个原始视频片段
- 视频中动作的文本描述
- 从视频中估计出的基于SMPL [33] 的人体姿势序列
- 用于高层机器人控制的人形关键点序列
- 以及表示低层机器人位置控制目标自由度位置的人形动作序列
Humanoid-X 包含超过2000 万帧,总计约240 小时的数据。除了其跨多种数据模态的广泛规模(对于可扩展的人形策略训练至关重要)之外,Humanoid-X 还具有一个大且多样的基于文本的动作词汇,如下图图3 (c) 所示
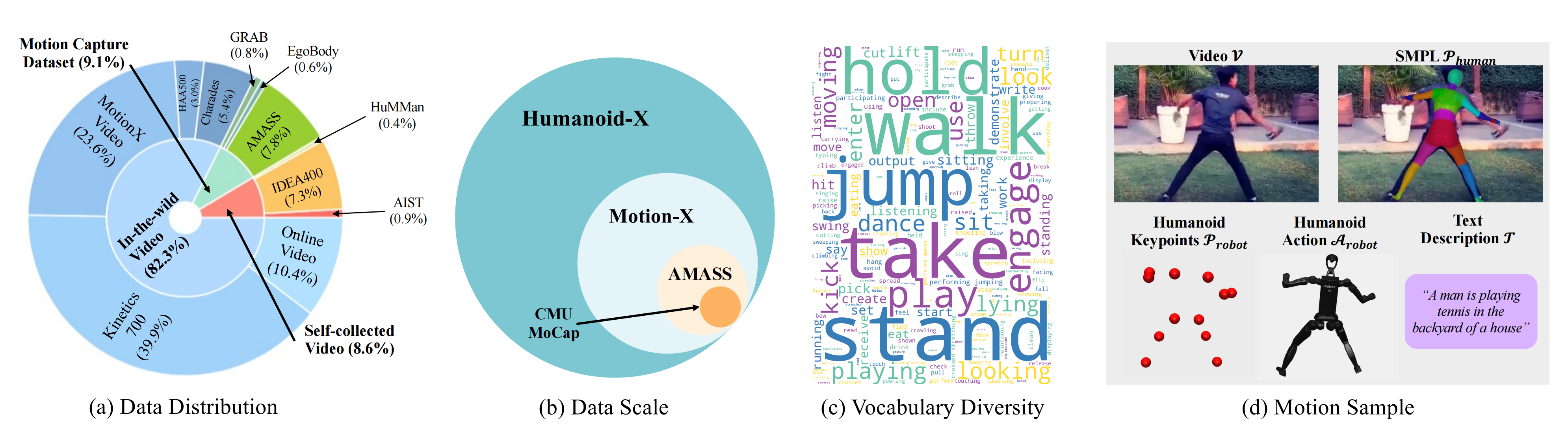
在下一节中,将讨论如何从海量视频中获取这些运动样本⟨,
,
,
,
⟩
1.2.1 从海量视频中学习:提取视频特征、生成字幕、3D姿态估计、重定向、RL训练
为了处理大规模、自然环境中的原始视频数据,作者开发了一套完全自动化的数据标注流水线,包括五个模块,如下图图2 所示
该流水线包括:
- 一个视频处理模块,用于从嘈杂的互联网视频中挖掘并提取视频片段
- 一个视频字幕生成模型,用于生成人类动作的文本描述
;
- 一个人体姿态检测模块,用于从视频片段中估计参数化的3D 人体姿态
a human pose detection module that estimate sparametric 3D human poses Phuman from video clips - 一个运动重定向模块,通过将人类的动作转移到人形机器人上生成人形机器人的关节点
amotion retargeting module to generate humanoid robotickeypoints Probot by transferring motions from humans to humanoid robots - 以及一个目标条件强化学习策略-Goal-conditioned reinforcement learning,通过模仿人形关键点来学习可以物理部署的人形动作
a goal-conditioned reinforcementlearning policy to learn physically-deployable humanoidactions Arobot by imitating humanoid keypoints
第一,收集视频并提取视频片段
为了收集大量以人为中心的视频——这些视频涵盖了各种各样的动作类型,为此,作者们从三个来源挖掘了大量信息丰富的视频片段:
- 用于数字人研究的学术数据集[6,11,18,32,56,61,75]
- 用于视频动作理解的数据集 [7,55]
- 以及来自 YouTube 的互联网视频
且计了超过400个独特的搜索词,涵盖从日常任务到专业体育的一系列人类活动,然后利用Google Cloud API*检索了每个指定搜索词的前20个视频
原始视频通常包含噪声,包括没有人、多个人或静止个体的片段,这使得它们不适合用于人形控制
- 为了获得有意义的视频剪辑,首先将每个视频降采样到标准化的每秒20帧(FPS),以确保数据集的一致性
- 接下来,使用一个对象检测器[50]进行单人检测,选择仅包含一个可见人的帧。在检测之后,通过计算连续帧之间的逐像素灰度差异来应用运动检测,从而保留显示显著运动的帧
- 然后,将满足上述单人运动标准的至少连续64帧的序列编译成视频剪辑,总共生成了163,800个视频剪辑
第二,给视频生成字幕
- 语言连接了人类指令和人形动作。为了将人形动作与语义意义关联起来并实现基于语言的人形控制,使用一个视频字幕生成模型[10]从视频中生成细粒度的动作描述
其中是视频字幕生成模型
- 为了避免无关的文本描述,作者精心设计了提示词来引导模型描述人类行为而非物理外观,从而生成以动作为中心的文本描述
第三,三维人体姿态估计(3D Human Pose Estimation)
机器人本质上与人类共享相似的骨架结构,这使得可以基于人类运动数据学习类人机器人的控制策略
- 为此,首先需要从视频中提取人体姿态。为了准确地跟踪和估计视频片段中的人体姿态,作者采用了一种基于视频的3D人体参数模型估计器[27],该模型能够为每一帧估计基于SMPL[33]的人体和相机参数
- 之后,进一步利用估计出的相机参数提取全局人体运动,即根部平移
该过程可以表述为
其中是人体姿态估计模型
- 最终,获得每帧的3D 人体姿态:
其中
控制人体形状
控制关节旋转
控制全局根部平移
第四,对于从人类到类人机器人的运动重定向
由于人类和类人机器人具有相似的骨骼结构,故可以跟踪人类关节在不同帧中的位置,并将其映射到人形机器人的相应关节,从而生成用于高层次控制的人形关节点
特别是,作者选择了在人类和人形机器人中都存在的12 个关节:左右髋关节、膝关节、踝关节、肩关节、肘关节和腕关节
人体关节位置可以通过正向运动学
获得
由于人类的形状与人形机器人不同,按照[20],首先优化人体形状参数,以确保调整后的人体形状与人形机器人非常相似
- 具体而言,首先在标准
形姿势下获取人形机器人的关节位置:
- 然后,在相同的T 形姿势下,优化
与对应的人形机器人关节位置
相同
其中表示标准
- 对于每一帧人体姿势,用
中的最优
替换原始
可以获得调整后的关节位置
- 最后,直接将人形机器人的关键点设置为调整后的人体关节位置
且为了有效控制人形机器人,还通过逆运动学提取人形机器人中的电机自由度位置
此外,他们还使用 Adam 优化器 [25] 来解决逆运动学问题——在优化中添加了一个平滑项,以正则化
第五,目标条件的人形控制策略
- 重新定位的人形关节点
和自由度位置
能够准确反映人形动作,但它们无法直接部署到真实机器人上
这是因为它们缺乏有效处理现实世界中的变化和约束所需的必要安全保障和鲁棒性 - 为了解决这个问题,作者开发了一种目标条件控制策略π,该策略在确保物理机器人安全可靠部署的同时适应这些动作
策略π 的输入包括两部分:目标空间和观测空间
包含机器人本体感知信息,例如根部方向、角速度以及当前电机自由度位置。输出动作空间
是用于控制人形机器人的各关节目标自由度位置,这些位置可以通过比例-微分(PD)控制器进一步转换为电机力矩信号
作者使用大规模强化学习(PPO [52])对控制策略π进行优化
奖励函数包括多个项:
- 运动奖励以鼓励模仿重新定向的人形关键点
- 根跟踪奖励以跟随目标根方向和从
- 以及稳定性奖励以帮助机器人在运动中保持平衡并防止跌倒
最终的策略π和机器人动作Arobot使人形机器人能够在物理世界中安全操作,同时保持所需的运动
最后,作者们从大量视频中收集了大量运动样本⟨,
,
,
,
⟩。在下一节中,我们将研究如何使用大量运动样本训练一个通用的人形姿态控制策略
1.2.2
// 待更
第二部分 Humanoid-VLA
2.1 提出背景与相关工作
2.1.1 提出背景:兼顾动作与语义的对齐、及整合第一人称视角
此前的一些研究「比如Cheng 等人2024-Expressive whole-body control for humanoid robots 即Exbody;Ji 等人2024-Exbody2: Advanced expressive humanoid whole-body control」开发了将基本人体运动学序列转化为人形机器人运动的全身控制器
- 此领域自此进步到集成多模态感知,使人形机器人能够实时模仿人类演示「He 等人2024b-H2O:Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation 」
并流畅地响应自然语言指令「Mao 等人2024- Learning from massive human videos for universal humanoid pose control」 - 然,尽管这些方法在实现人形机器人高保真运动控制方面表现出色,但它们主要通过反应机制运行,动态调整运动以响应外部输入
即它们无法自主感知并推断其周围环境中的潜在交互目标,这种局限性极大地阻碍了它们在需要物体操作或在复杂环境中进行自适应探索的场景中的部署
为此,本文旨在研究带有以自我中心视觉集成的通用人形机器人控制
然而,开发这样的系统面临一个显著的瓶颈:数据稀缺
- 现有的动作捕捉数据集缺乏同步的第一人称视觉信息,这使得直接转移到以自我为中心的任务变得不可能
- 此外,尽管远程操作为收集视觉运动数据提供了理论上的途径,但其高昂的成本严重限制了大规模获取。这些限制导致了训练数据集在数量和多样性上的不足,从而阻碍了结合第一人称视觉整合的类人控制基础模型的发展
针对数据稀缺的挑战,Humanoid-VLA的作者们提出了一种可行且具有成本效益的范式。具体而言
首先,通过使用与文本描述配对的非自我中心的人体运动数据集,建立一种语言-运动的预对齐。这使得模型能够从多样化的第三人称观察中学习通用的运动模式和动作语义,从而获得一种不依赖于自我中心视觉输入的鲁棒且具有泛化能力的运动表示
- 毕竟,仅依靠现有的训练范式不足以确保模型性能的最优,主要原因在于运动与语言之间的对齐存在局限性,而框架的有效性依赖于运动与语言表示的预对齐
- 受到MLLMs(Liu等2023-Visual instruction tuning;Zhang等2023a-Video-llama: An instructiontuned audio-visual language model for video understanding)成功的启发——其中强大的大语言模型(LLMs)作为基础组件
然而,实现这种对齐在很大程度上取决于大规模和高质量数据的可用性
但不幸的是,当前的运动数据集在规模上不足以满足这一需求。尽管视频资源提供了大量的人类数据,但由于缺乏运动描述注释,其在模型训练中的实用性受到限制 - 为了解决这一限制,Humanoid-VLA提出了一个自监督数据增强框架,该框架通过自动化的运动分析生成伪注释
其具体的解决方案包含一个自动注释管道,该管道通过精心设计的自监督任务直接从运动序列中提取语义含义。一个典型的实现是在运动序列中暂时遮掩特定的身体关节,然后训练模型重建被遮挡的运动
representative implementation in-volves temporarily masking specific body joints with in mo-tion sequences and training the model to reconstruct the oc-cluded movements.
且为这类任务自动生成指令提示,例如“缺失的左臂<遮挡>运动数据。请完成该运动”,并配以相应的地面实况运动作为目标输出
We automatically generate instructional prompts for such tasks as "missing left arm <Occlusion>motion data. Please complete the motion"
这一自动化过程系统地将原始运动数据转化为有意义的问题-答案对。通过整合这些自监督学习目标,该方法避免了对人工标注文本描述的需求,同时有效地利用了从视频库中提取的大规模未标注运动数据
总之,Humanoid-VLA的框架实质上降低了对以自我为中心的数据集的依赖,使得将语言理解、以自我为中心的场景感知与运动控制相结合成为可能
Our framework essentially reduces the dependence on ego-centric datasets, making combining language understandingand egocentric scene perception with motion control feasi-bl
接下来,通过一个参数高效的交叉注意力模块整合以自我为中心的视觉上下文。这种自适应机制在保持预训练模型完整性的同时,允许动态融合第一人称视觉特征,从而实现上下文感知的运动生成
2.1.2 相关工作:人形机器人控制、人形数据集
第一,对于人形机器人控制
- 传统的人形控制方法(Li等人,2023;Kuindersma等人,2016;Elobaid等人,2023;Dantec等人,2021;Dai等人,2014)如MPC提供了精确性和稳定性,但缺乏适应性
- 而基于学习的方法提供了灵活性,但由于人形数据集的有限性,依赖于人类运动数据,诸如
Exbody(Cheng等人,2024)
Exbody2(Ji等人,2024)
HARMON(Jiang等人,2024),详见此文《基于人类视频的模仿学习与VLM推理规划:从DexMV、MimicPlay、SeeDo到人形OKAMI、Harmon(含R3M的详解)》的第六部分 HARMON:从语言描述生成人形机器人的全身运动
和mobile-television(Lu等人,2024)等工作
使用SMPL模型(Loper等人,2023)和根速度跟踪实现了人形机器人上半身的运动重定向,以及下半身的运动 - 为了实现灵活且复杂的动作,方法如PHC(Luo等人,2023)、H2O(He等人,2024b)和OmniH2O(He等人,2024a)使用SMPL模型将运动重定向扩展到全身控制
此外,像OmniH2O(He等人,2024a)、HARMON(Jiang等人,2024)和UH-1(Mao等人,2024)这样的方法实现了语言引导的动作生成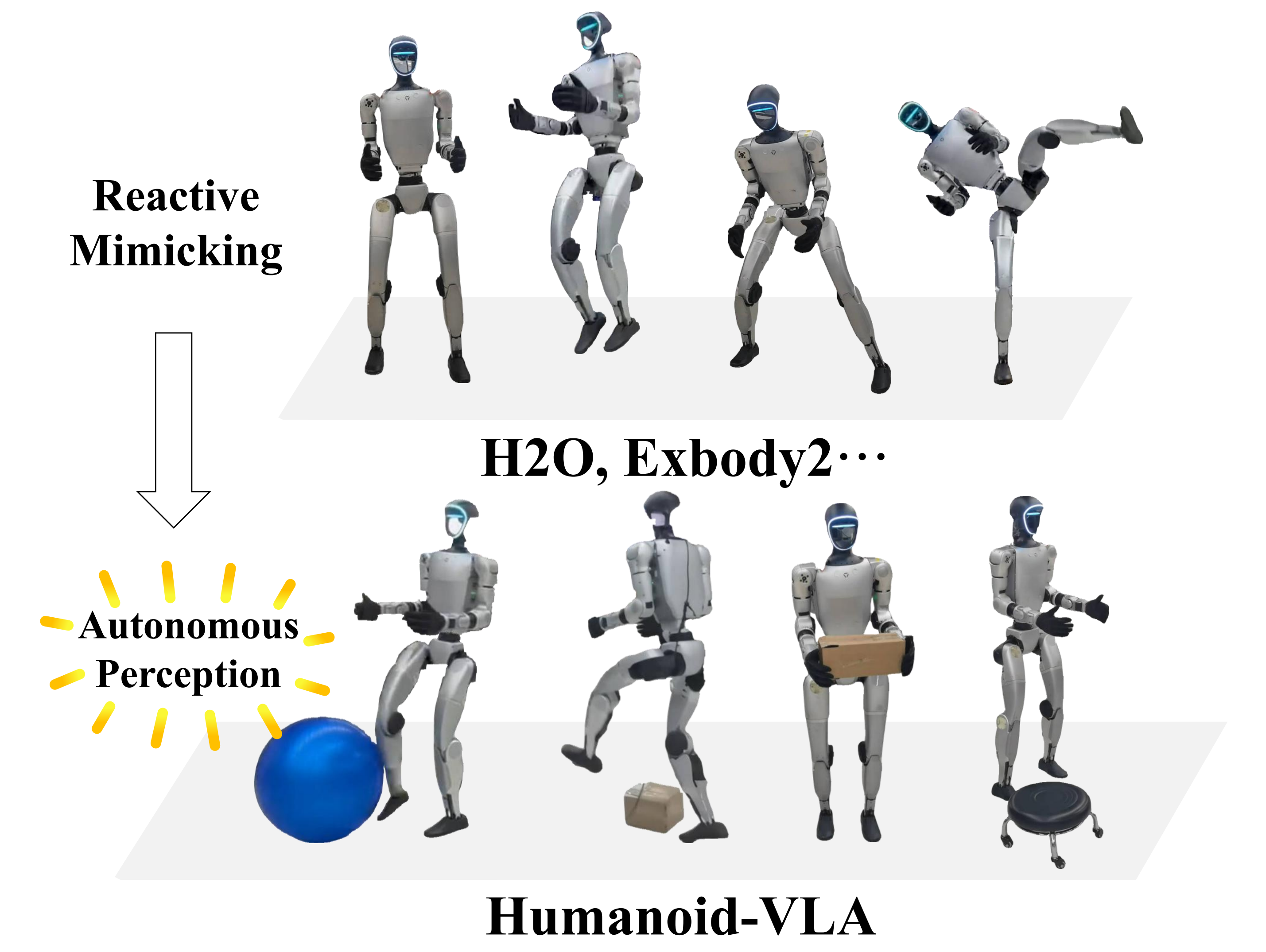
然而,这些方法是被动的,意味着模型基于文本或关键点被动生成各种动作。为了在动态且复杂的环境中自主执行更高级的任务,第一视角的视觉信息是不可或缺的
第二,对于人形数据集
除了第一人称的视觉信息外,将动作与语义相关的文本信息对齐对于构建基础类人机器人模型至关重要
- 先前的人类数据集,例如AMASS(Mahmood等人,2019年)、HumanML3D(Guo等人,2022年a)、Motion-X (Lin等人,2023年)以及Human3.6M(Ionescu等人,2014年;CatalinIonescu,2011年)提供了大规模的人类动作数据
尽管一些工作使用人类动作重定向来开发类人机器人数据集(He等人,2024年a;b;程等人,2024年;季等人,2024年),这些数据集通常存在稀疏的文本注释和有限的规模,限制了它们在训练基础模型中的使用
即使某些方法可以缓解这个问题,它们通常也面临高成本(毛等人,2024年)和缺乏精确性(Tevet等人,2023年)的困境 - 相比之下,Humanoid-VLA提出了一种自监督的数据增强方法,该方法避免了对人工注释文本描述的需求,同时有效利用了从视频库中提取的大规模未标注运动数据,用于机器人基础模型的训练
第三,对于用于机器人学习的VLA
近年来,VLA 模型通过整合视觉、语言和动作,在机器人学习方面取得了进展,特别是在机械臂和四足机器人领域,从而增强了任务和环境的泛化能力
- 对于机械臂,诸如RT-2 (Brohan et al., 2023)、OpenVLA (Kimet al., 2024)、GR-2 (Cheang et al., 2024)、RoboMamba(Liu et al., 2024a) 和RDT-1B (Liu et al., 2024b) 等模型利用视觉和语言输入实现高效的任务执行
- 对于四足机器人,诸如QUAR-VLA (Ding et al., 2025) 和QUART-Online (Tong et al., 2024) 等模型在动态环境中提升了泛化能力和适应性,而π0 (Black et al., 2024)使多体机器人能够执行多样化的任务
- 尽管取得了这些进展,由于缺乏结合第一视角视觉信息、文本运动描述和全身运动数据的人形机器人数据集,VLA 模型尚未应用于人形机器人。本文迈出了构建Humanoid-VLA模型的第一步,以使人形机器人能够自主执行行走-操作任务
2.1.3 初步内容:人形控制的定义、及其限制
随着图形学领域中人类数据的日益丰富,近期的人形机器人控制越来越多地采用从人类数据中学习的方法。具体来说,给定来自物理遥操作(例如动作捕捉系统)的目标身体姿态以及人形机器人的本体感觉,全身控制器 生成关节扭矩以控制人形机器人
从形式上讲,这可以表示为
其中
表示目标身体姿态
人形机器人的本体感受
在时间t ∈N+ 时的关节力矩
然而,开发一个通用机器人需要有目的的学习,这涉及从人类数据中提取有意义的意图,并将先前的经验适应于新的任务或环境
- 目前的数据获取方法主要集中在人体关节姿态上,缺乏与第一人称视觉的整合。因此,它们只能教机器人执行的动作,而无法传递其背后的意图或上下文
因此,由于环境差异,基于姿态的模仿在普适性上本质上受到限制 - 所以,作者们提出了Humanoid-VLA,这是第一个针对人形机器人设计的VLA模型,它将语言理解、场景感知和运动控制无缝集成到一个统一的系统中,以解决人形机器人控制的先前局限性
接下来,从两个主要部分演示该框架:语言-运动预对齐和视觉条件下的微调
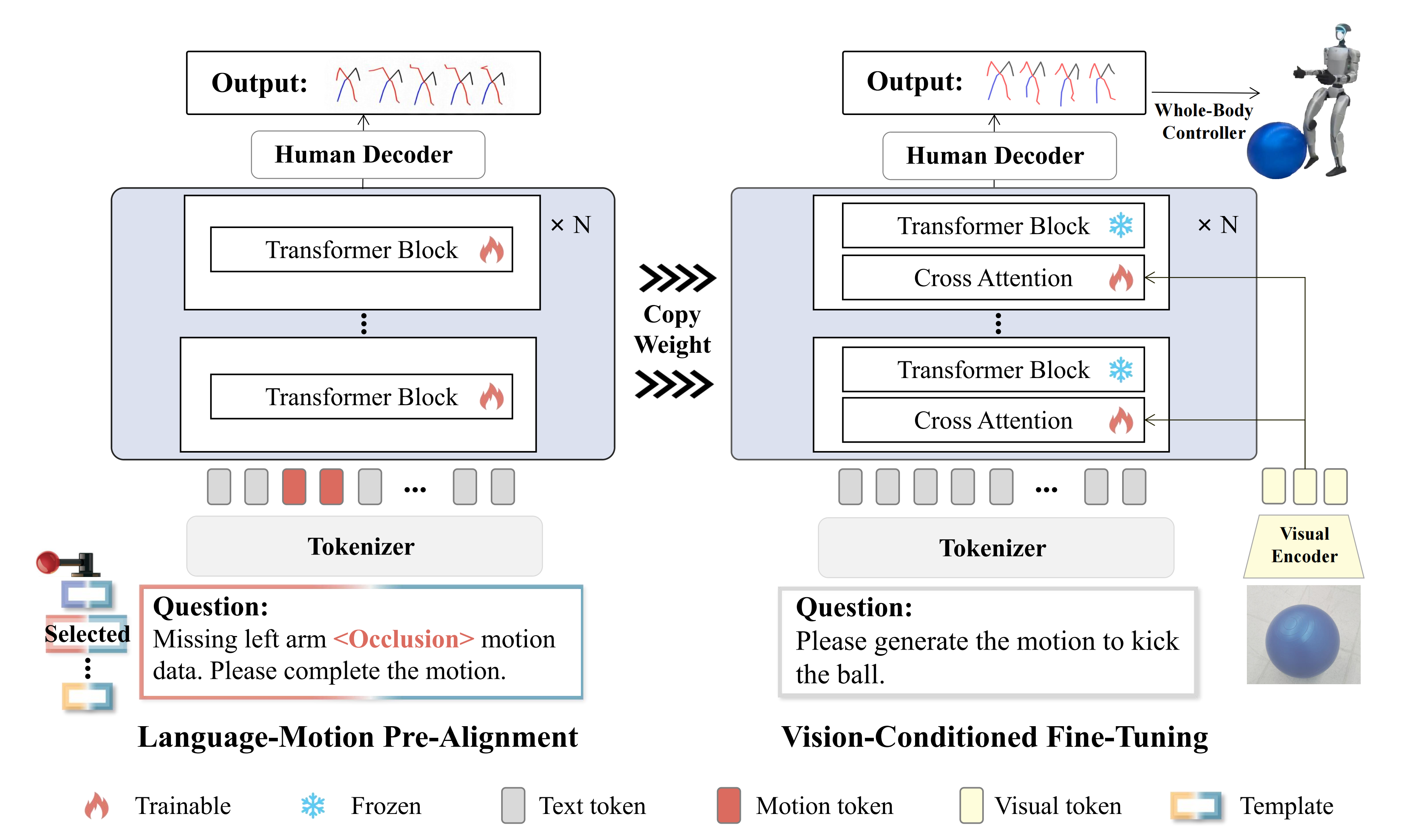
2.2 Humanoid-VLA的语言-动作预对齐
接下来,将非自我中心的人体动作数据与语言描述进行对齐。这种对齐使得模型能够从非自我中心的数据源中学习动作模式和动作语义,为无需自我中心视觉输入的动作生成奠定了坚实的基础
2.2.1 组合运动量化和自动数据增强
但之前数据采集存在较大的局限性
- 先前的研究主要利用精心整理的数据集,这些数据集将运动轨迹与语言描述配对,用于训练基于文本条件的运动生成模型。尽管这些数据集能够有效训练模型,但其数量和多样性有限,这限制了其实现更好对齐的能力
- 相比之下,大规模的在线视频数据集(如表1所示)提供了丰富且多样化的运动数据
然而,缺乏相应的语言标注显著限制了它们在此任务中的适用性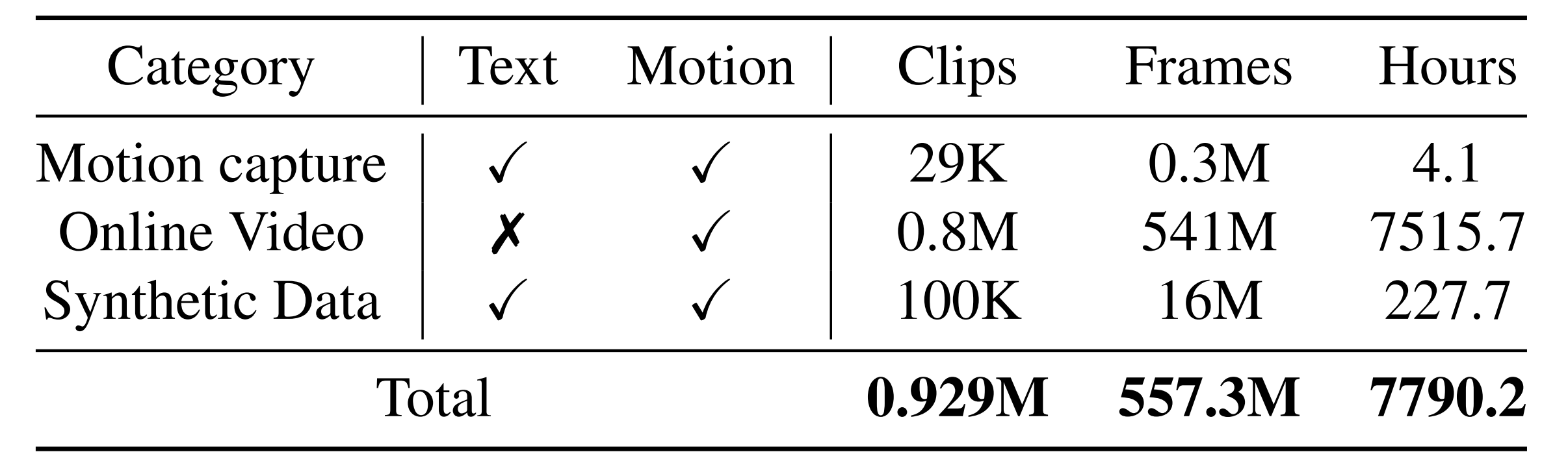
- 最近,为解决这一瓶颈,研究人员集中在手动标注大规模视频数据集或使用视频大语言模型(VLLMs)(Zhang等,2023a)上。然而,手动标注成本极高,而VLLMs由于无法捕捉细微的运动细节或描述复杂的动作,通常会产生噪声、不完整或不精确的标注。这些限制削弱了生成的数据集在语言和运动对齐方面的有效性
- 自监督数据增强
作者们提出了一种经济高效的标注方法,即不依赖于明确的动作描述,而是通过设计各种直接源自动作数据的自监督任务来实现
例如,一种具有代表性的方法是在动作序列中暂时遮蔽特定的身体关节,并训练模型来重建被遮挡的动作
可以为这些任务生成诸如“左臂 <遮挡/Occlusion> 动作数据缺失,请完成动作”之类的指导提示,并将其与相应的动作真实值作为目标输出配对
这种自动方法消除了对明确标注的需求,并且比为来自视频源的动作数据添加额外标注更准确
接下来,将解释如何通过两个关键模块实现这一点:组合运动量化和自动数据增强
首先是组成运动量化
- 他们提出了一种用于身体姿态表示的分解压缩方法。具体来说,我们将每个身体姿态分解为五个基于身体的标记,分别对应五个不同的部分:左腿、右腿、躯干、左臂和右臂
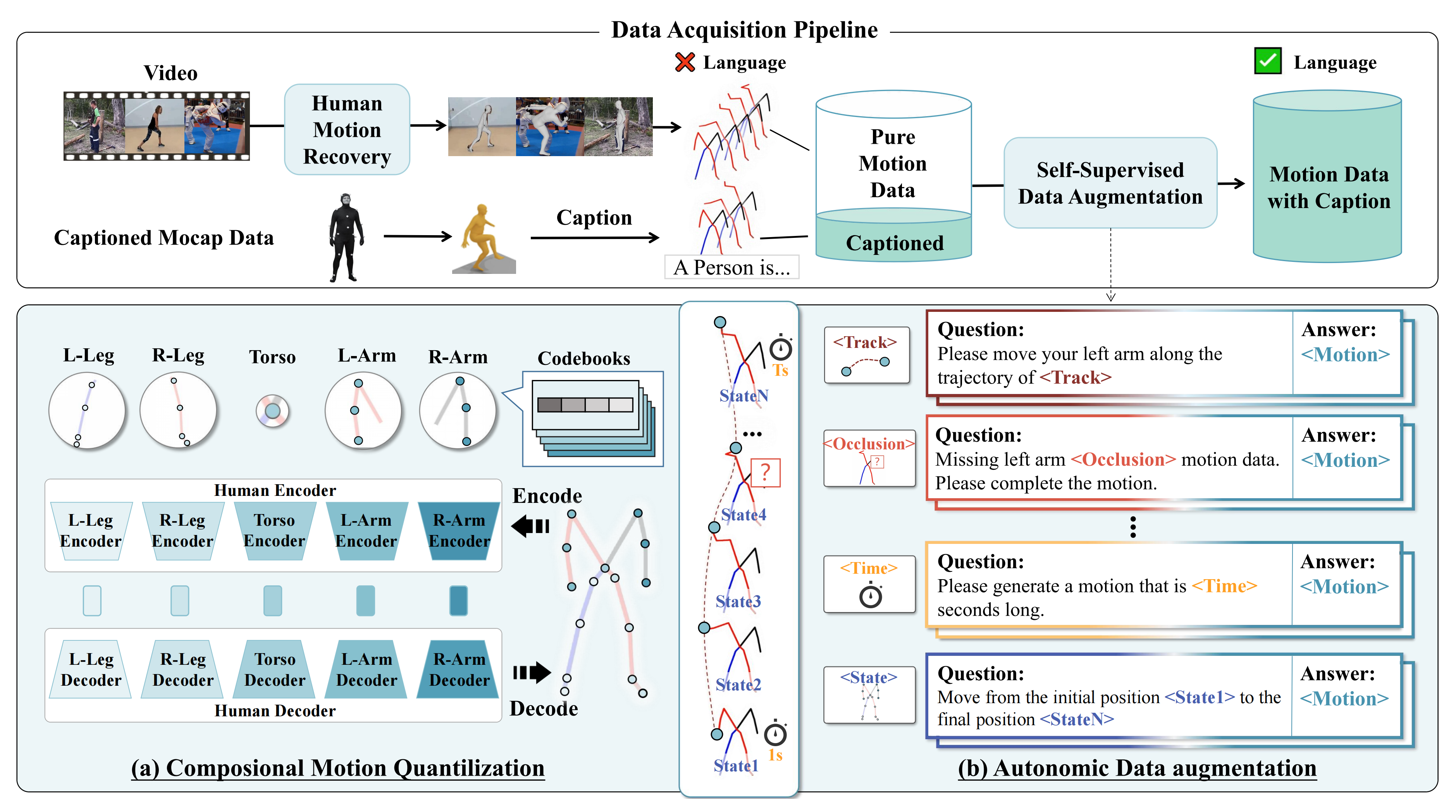
- 为每个身体部分独立训练每个编码器
及其对应的codebook
,以在时间
将身体部分数据
压缩为量化表示
形式上,他们将运动编码器定义为,它将
压缩为
其中,从
中获得的离散向量集合,它们是与词汇
中
的量化最相似的元素
类似于编码器,他们使用运动解码器将潜在变量投射回动作空间
优化目标可以表示为:重构损失
、嵌入损失
和承诺损失
的组合
这种组合编码方法非常重要,它允许对运动序列进行灵活的编辑。将身体姿态分解为多个部分并分别编码的优势在于,使得可以在token级别对运动序列进行灵活操作
例如,可以替换、扰动或重新排列与特定身体部位对应的token以生成新的运动模式
其次是自动数据增强
如下图图3所示「该方法将视频中丰富的纯运动数据转换为带有注释的运动数据。该框架由两个关键模块组成:一种组合运动量化方法和一种自主数据增强方法,这两者共同实现了数据集的可扩展扩展」
- 他们引入了四种类型的增强——<轨迹/Track>、<遮挡/Occlusion>、<时间/Time>和<状态/State>——以从原始运动数据中提取多样化的特征。例如,在<轨迹>增强中,将特定关节(例如根关节)的时间轨迹隔离出来,并将其编码为相应的运动token
- 为了创建有意义的问答对,将此运动特征与一个指令提示配对,例如“请沿着<轨迹>的轨迹移动你的中心位置”,同时使用完整的运动序列作为答案
这种方法有效地增强了最初缺乏语言标注的数据集,使其能够用于需要文本与运动对齐的任务
该方法具有几个关键优势
- 它具有高度的灵活性和可扩展性:可以将之类的增强类型与其他条件(例如)结合起来创建更复杂的任务,同时可以通过像GPT-4(Achiam等,2023)这样的工具对相同的指令进行重述来进一步丰富语言多样性
- 该框架利用了运动数据固有的时间和空间动态特性,使模型能够学习更丰富和更稳健的运动-语言关系
- 最后,交错数据集的使用通过在输入和输出中同时纳入动作和文本,增强了跨模态对齐。正如先前的工作(如 VILA,Lin 等人,2024 年)所展示的那样,这种训练范式使模型能够更好地捕捉动作和语言之间的相互作用,同时又不会影响其在原始任务上的性能
通过这种增强方法,他们收集了迄今为止最大的动作 - 语言交错数据集,其规模是先前工作的 25 倍(Mao 等人,2024 年)——有效地解决了训练基础人类动作模型时的数据稀缺问题
2.2.2 训练
对于训练过程
当获得足够的带有语言注释的数据时,仍然需要考虑来自视频源的原始运动数据的质量。因此,我们将整个训练过程分为两个阶段
- 首先,利用低质量数据建立运动和语言之间的初步对齐。即使它们不够精确,大规模数据也可以奠定基础
- 之后,继续使用来自Mocap的小规模但高质量数据集训练模型,以确保其符合正确的人体运动学
为了利用大型语言模型(LLMs)将输入条件映射为生成运动序列的方式。他们的数据增强方法和组合运动编码使LLMs能够无缝地将运动条件嵌入到输入描述中
例如,用于生成动作的指令 可以这样构建:“在 <Time> 秒内规划一系列动作,以 <State> 结束。”
- 这里,<State> 对应于从动作序列中第
- 而 <Time> 则指定了动作的持续时间
- 通过将动作codebook
和语言codebook
统一到一个共享词汇表
中
- 且可以将指令
与动作表示
和时间表示
一起编码为语言token
,其中
,
表示输入描述的长度
we can encode the instruction lt alongside the motion repre-sentations zt and temporal representations dt as language tokens Xd = {xid}Ni=1, where xd ∈V and N represents thelength of the input description
这种转换使得组合的动作和时间数据与 LLMs 兼容,从而实现精确且灵活的输入编码
对于损失函数
运动生成因此可以被框定为一个自回归过程,该过程预测下一个动作token的字典索引,最终生成最终的运动输出,其中
且
表示输出序列长度
训练目标被定义为最大化数据分布的对数似然:
最后,预测的离散运动序列可以通过词汇映射从LLM 的输出序列
中得出。然后,该序列可以用于重建最终预测的运动
,其中
表示运动序列的长度
2.3 Humanoid-VLA的基于视觉条件的微调
视觉信息为人形机器人提供了详细的对象感知洞察,帮助它们不仅了解如何行动,还能决定采取何种行动
- 尽管此前的研究已通过大量人类动作数据集对类人机器人进行了训练,但由于缺乏以自我为中心的视觉数据,限制了它们基于自主感知做出反应的能力
- 为了解决这个问题,作者们收集了与第一人称视角视觉图像相匹配的真实世界动作捕捉数据,从而能够将所学的动作知识转移到真实世界中基于视觉的情境中
To addressthis, we collect real-world motion capture data paired with egocentric visuals, enabling the transfer of learned motionknowledge to real-world, visually grounded scenarios.
具体而言,他们复制并冻结了语言-动作预对齐阶段的Transformer层,以将视觉信息与语言描述相结合
此外,他们引入了一个视觉编码器,并利用交叉注意力层将视觉特征与语言特征
融合成一个统一的嵌入
具体来说,解码器由层组成,其中第
层包括一个复制的Transformer解码器层和一个交叉注意力层
在交叉注意力层中
- tokenized的语言token
被用作查询——query/Q
- 而编码的视觉token
同时作为键和值——K V
从而有
其中表示隐藏维度大小,
表示语言token的线性变换矩阵,而
表示视觉token的变换
至于损失函数,则以与先前语言-动作预对齐阶段相同的方式优化模型
一旦完成了两个训练阶段,该模型就可以与一个全身控制器集成,以实现对人形机器人的控制
- 全身控制器本质上是一个目标条件的强化学习(RL)策略,它将人类动作映射到人形机器人关节
上
- 作者定义了一个奖励策略
,该策略以观察值
并使用近端策略优化(PPO)(Schulman等,2017)来最大化累积奖励
// 待更