分布式一致性算法起源思考与应用
目录
一、分布式一致性算法的应用
1.1 kafka
1.2 flink
1.3 redis(Redis Sentinel模式)
1.4 mysql(MGR模式)
二、分布式一致性算法的作用
三、自己设计一个分布式一致性算法
3.1 选主策略
3.2 原子广播
四、总结
一、分布式一致性算法的应用
工作中碰到的越来越多的分布式系统,到处都存在着分布式一致性算法,举个例子:
1.1 kafka
-
Controller 是 Kafka 集群中的一个特殊 Broker,负责管理 Partition 的 Leader 选举、副本分配等元数据操作。
-
Controller 的选举:
-
依赖 ZooKeeper 的版本:通过 ZooKeeper 的临时节点(EPHEMERAL)实现,第一个成功创建
/controller节点的 Broker 成为 Controller。 -
Kafka KRaft 模式(去 ZooKeeper 化):使用 Raft 协议 选举 Controller,确保元数据的一致性。
-
1.2 flink
Flink 通过 High Availability (HA) 机制实现 JobManager 的故障恢复,选主过程依赖外部协调服务(如 ZooKeeper 或 Kubernetes):
-
依赖组件
-
ZooKeeper:用于领导者选举和元数据存储(推荐方案)。
-
Kubernetes:通过原生 API 实现高可用(如 Deployment + Service)。
-
-
选主流程
-
注册节点:多个 JobManager 启动时向 ZooKeeper 注册临时节点。
-
选举主节点:通过 ZooKeeper 的选举机制(如
LeaderLatch)确定唯一的主 JobManager。 -
状态持久化:主 JobManager 将作业元数据和检查点位置持久化到共享存储(如 HDFS、S3)。
-
故障检测:若主节点失联,ZooKeeper 触发重新选举,新主节点从共享存储恢复元数据并接管集群。
-
1.3 redis(Redis Sentinel模式)
故障检测与转移流程:
-
主观下线(SDOWN)
Sentinel 节点定期向主节点发送PING命令,若在down-after-milliseconds内未收到响应,标记主节点为 主观下线。 -
客观下线(ODOWN)
其他 Sentinel 节点也尝试与主节点通信。当超过quorum数量的 Sentinel 确认主节点不可达,标记为 客观下线。 -
领导者选举
Sentinel 集群通过 Raft 算法选举一个 领导者 Sentinel(需获得多数票)。 -
故障转移
-
领导者选择最优从节点(依据优先级、复制偏移量等)晋升为主节点。
-
向新主节点发送
SLAVEOF NO ONE,并等待其确认角色切换。 -
更新其他从节点配置,指向新主节点(
SLAVEOF <new-master>)。
-
-
客户端重定向
客户端通过 Sentinel 查询新主节点地址,自动切换连接。 -
原主节点恢复
若原主节点重新上线,Sentinel 会将其配置为从节点,同步新主数据。
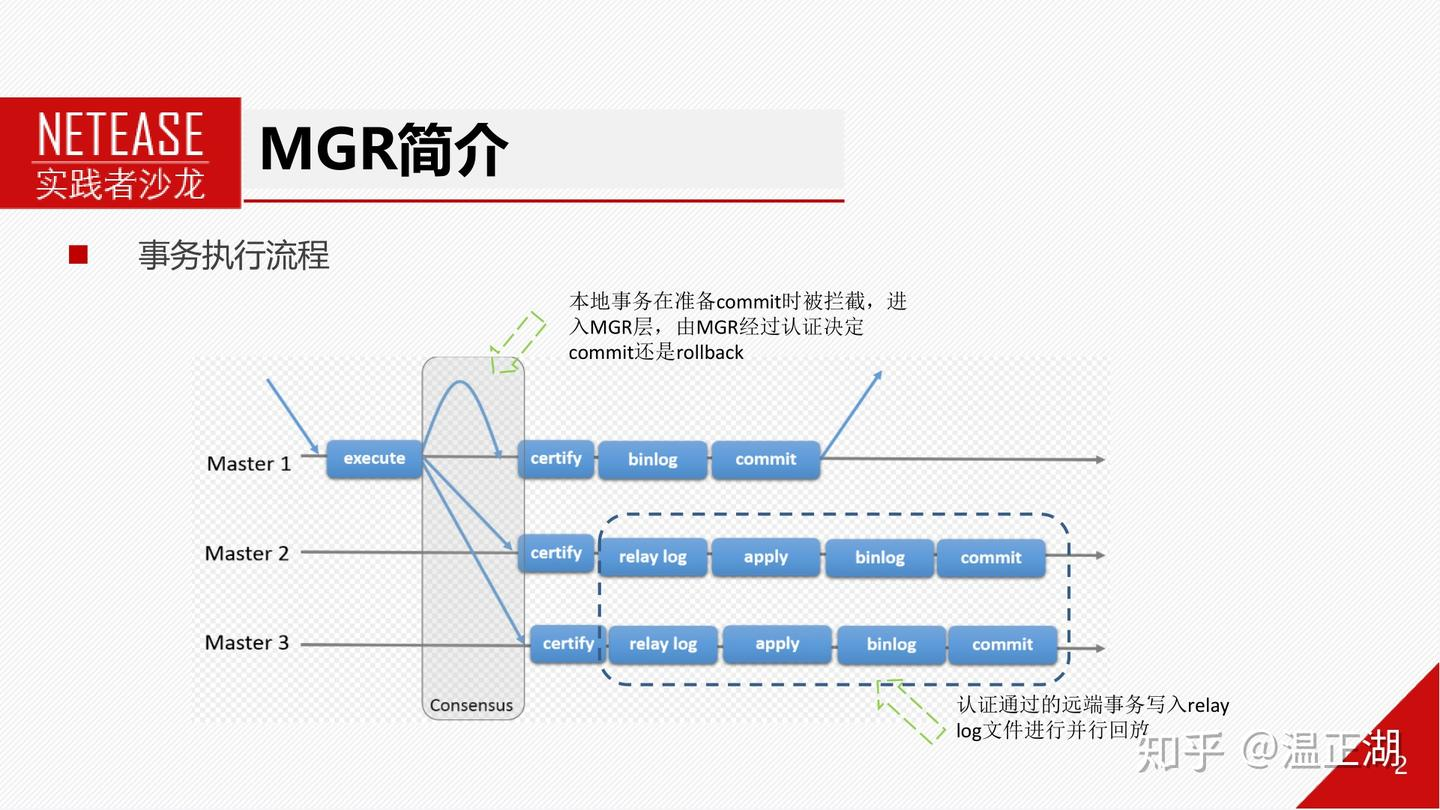
1.4 mysql(MGR模式)
MGR模式下,事务完成引擎层prepare,写Binlog之前会被MySQL的预埋钩子HOOK before_commit()拦截,进入到MGR层,将事务封装成消息通过Paxos一致性协议(consensus)进行全局排序后发送给MGR各个节点,在各节点上独自进行认证(certifiy)。
二、分布式一致性算法的作用
可以看到上面的系统中使用了paxos、raft等等算法,它们使用这些算法的原因,本质上是:
分布式系统中要达成一个共识
这个共识可以是哪台机器是master,亦或是某个log在系统间的同步
paxos、raft等等都是为了达成一个共识,所以它们也叫分布式共识算法
三、自己设计一个分布式一致性算法
网上很多教分布式一致性算法的博客,但我感觉先尝试自己设计一个,再去和通用的分布式算法作比较,思考自己的设计不足,理解的会更深刻
Q:假设我们有11台机器,如何达成共识?
我们让一台机器是leader,其它机器是follower,这样我们只要leader做出了决定,其它机器只是follower,自然可以达成共识,信息同步之类的可以通过2pc来解决
Q:所以问题就变成了,11台机器,如果选出一个leader?
如果我们有zookeeper之类的软件,可通过节点抢占选出leader
Q:那么问题来了,zookeeper如何实现的?
zookeeper也是典型的一主多从架构,需要从多个节点中选主,一个leader提供写服务,其它follower保持和leader同步
Q:所以问题又回来了,在没有zk的情况下,我们要设计实现一个多机器选主策略,且可以实现原子广播
3.1 选主策略
leader选举初始化:
每台机器启动时,都认为自己是leader,保存自己的id(myLeaderId)与成为leader的时间(myLeaderTime)
每个机器向其它机器,发送自己的myLeaderId和myLeaderTime,两台机器比较myLeaderTime大小,更早成leader的机器将成为另一台机器的leader,如果一台机器已经成为了follower,它将不会再参与比较,而是跟随自己的leader改变
每台机器在自己内部维护:
自己的leader是谁:myApproveLeaderId
自己的follower是谁:List[myFollowerid]
当有一台机器的follower超过了集群的一半机器,那么该机器成为该集群的master
可能发生的特殊情况是:
某个机器A虽然myLeaderTime大于机器B,但因为机器A同步速度更快,所以机器A率先成为了集群的leader,这时b会直接承认a为leader
有从节点挂掉:
少数挂掉无所谓,超过一半挂掉, leader退化成自由节点,系统拒绝服务
主节点挂掉:
从节点通过心跳和主节点连接,当发现主节点挂掉后,从节点删除自己的myApproveLeaderId,重新成为自由节点,参与到新的选主过程里,直到一个新的节点成为了master
产生分区:
假设产生分区的数量一多一少
原leader在多的那一边,无影响,因为少的那一边限于数量不可能选出来新的leader
原leader在少的那一边,leader退化成自由节点,多的一边重新选出来leader,这个过程可能发生脑裂,需要详细设置下时间参数
3.2 原子广播
选出leader以后,leader产出的消息要广播给follower
该消息要满足原子性、一致性、有序性
有序性的满足:leader给每条消息打上序列号,follower执行时,严格按照序号顺序执行,除非明确收到某个序号不执行的命令
原子性与一致性:leader收到消息后,将消息传给follower预处理,只要有一半的follower表示预处理成功,leader就给这些follower发送commit消息,让它们持久化消息,都持久化成功后,返回给客户端成功
有几种异常可能:
1. leader收到消息后,将消息传给follower预处理,没收到超过一半的ack就挂了,或者收到了超过一半的ack,但是没发任何一个commit就挂了
这种情况不会给客户端发送处理成功,消息也没持久化,客户端可以继续发
2. leader发送commit后崩溃,导致部分follower没有收到commit消息
这种leader重新选主时,会选有最新事务的follower作为leader,被commit后的follower即作为了leader,这样消息会被持久化成功,即执行成功,但因为中途崩溃了,所以客户端并不知情,客户端再提交可能导致一条消息被执行两次,可能需要客户端提交时,比如维护一个唯一的序列号,当失败了之后再提交时,服务端根据这个唯一的序列号判断是否执行过,来直接返回结果
四、总结
粗略看起来设计一个分布式一致性算法不是太复杂,可能之前已了解过不少该类算法特性,后面会研究一下raft、zab、paxos,在它们之间作比较,同时也和我上边的设计的算法简单对比,看看各种算法的应用场景与优劣