使用Open Compass进行模型评估,完成AI模型选择
OpenCompass 简单介绍
主要评测对象为语言大模型与多模态大模型
基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
OpenCompass 整体架构
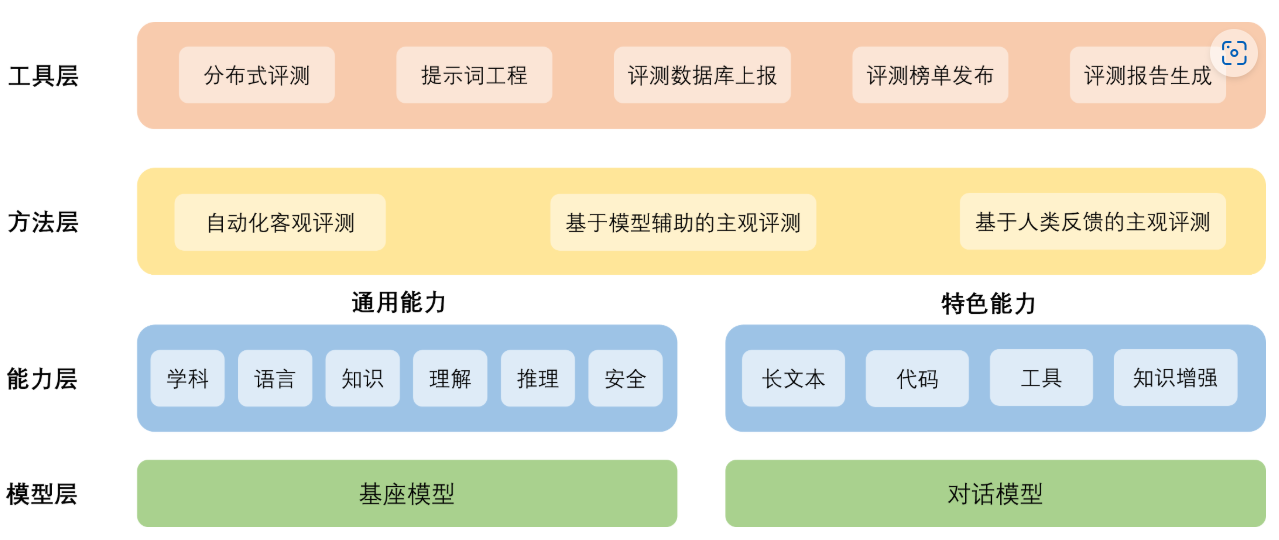
模型层:大模型评测所涉及的主要模型种类,OpenCompass以基座模型和对话模型作为重点评测对象。
能力层:OpenCompass从本方案从通用能力和特色能力两个方面来进行评测维度设计。在模型通用能力方面,从语言、知识、理解、推理、安全等多个能力维度进行评测。在特色能力方面,从长文本、代码、工具、知识增强等维度进行评测。
方法层:OpenCompass采用客观评测与主观评测两种评测方式。客观评测能便捷地评估模型在具有确定答案(如选择,填空,封闭式问答等)的任务上的能力,主观评测能评估用户对模型回复的真实满意度,OpenCompass采用基于模型辅助的主观评测和基于人类反馈的主观评测两种方式。
工具层:OpenCompass提供丰富的功能支持自动化地开展大语言模型的高效评测。包括分布式评测技术,提示词工程,对接评测数据库,评测榜单发布,评测报告生成等诸多功能。
openCompass 覆盖大模型的多样化需求;
OpenCompass 评估的核心指标:
1、准确度(Accurary):用于选择题或分类任务,通过比对生成结果与标准答案计算正确率。在0pencompass中通过metric=accuracy 配置;
2、困惑度(Perplexity PPL):衡量模型对候选答案的预测能力,适用于选择题评估。需使用ppl类型的数据集配置(如ceval_ppl)
3、生成质量(GEN):通过文本生成结果提取答案,需结合后处理脚本解析输出。使用gen类型的数据集(如ceval_gen),配置metric-gen并指定后处理规则;
4、ROUGE/LCS:用于文本生成任务的相似度评估,需安装rouge==1.0.1依赖,并在数据配置中设置metric=rouge
5、条件对数概率(CLP):结合上下文计算答案的条件概率,适用于复杂推理任务,需在模型配置中启用use_ogprob=True
OpenCompass 内置70多中验证数据集,覆盖五大能力维度;
常用数据集:
- 知识类:C-Eval(中文试题)、CLU(多语言知识问答)、MIU(英文多选)
- 推理类:GSMSK(数学推理)、BBH(复杂推理链)
- 语言类:CLUE(中文理解)、AFQMC(语义相似度)
- 代码类:HumanEval(代码生成)、MBPP(编程问题)
- 多模态类:MMBench(图像理解)、SEED-Bench(多模态问答)
评估范围差异:
- _gen后缀数据集:生成式评估,需后处理提取答案(如ceval_gen)
- _ppl后缀数据集:困惑度评估,直接比对选项率(如cevalpp1)
- c-Eval: 侧重中文STEM和社会科学知识,包含1.3万道选择题
- LaBench: 法律领域专项评估,需额外克隆仓库并配置路径
更多详细信息可以到OpenCompass 官网进行了解
OpenCompass使用
1、使用conda 构建虚拟环境
conda create --name opencompass python=3.10 -y
# conda create --name opencompass_lmdeploy python=3.10 -y
conda activate opencompas
安装:OpenCompass :
# 推荐使用 git 拉取源码;在做模型评估师需要修改到config 配置文件。
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .
2、数据准备
提前下载好评测数据
OpenCompass支持使用本地数据集进行评测,数据集的下载和解压可以通过以下命令完成:
# 下载完成数据,需要在opencompass 目录下下载,这样解压后后在opencompass 目录下生成data 文件目录
wget https://github.com/open-
compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-
20240207.zip
unzip OpenCompassData-core-20240207.zip
3、评测:
OpenCompass 支持通过命令行界面 (CLI) 或 Python 脚本来设置配置。对于简单的评估设置,我们推荐
使用 CLI;而对于更复杂的评估,则建议使用脚本方式。你可以在configs文件夹下找到更多脚本示例。
# 命令行界面 (CLI)
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
# Python 脚本
opencompass ./configs/eval_chat_demo.py
OpenCompass 预定义了许多模型和数据集的配置,你可以通过 工具 列出所有可用的模型和数据集配
置。
支持的模型
# 列出所有配置
python tools/list_configs.py
# 列出所有跟 hf_qwen 相关的配置
python tools/list_configs.py hf_qwen
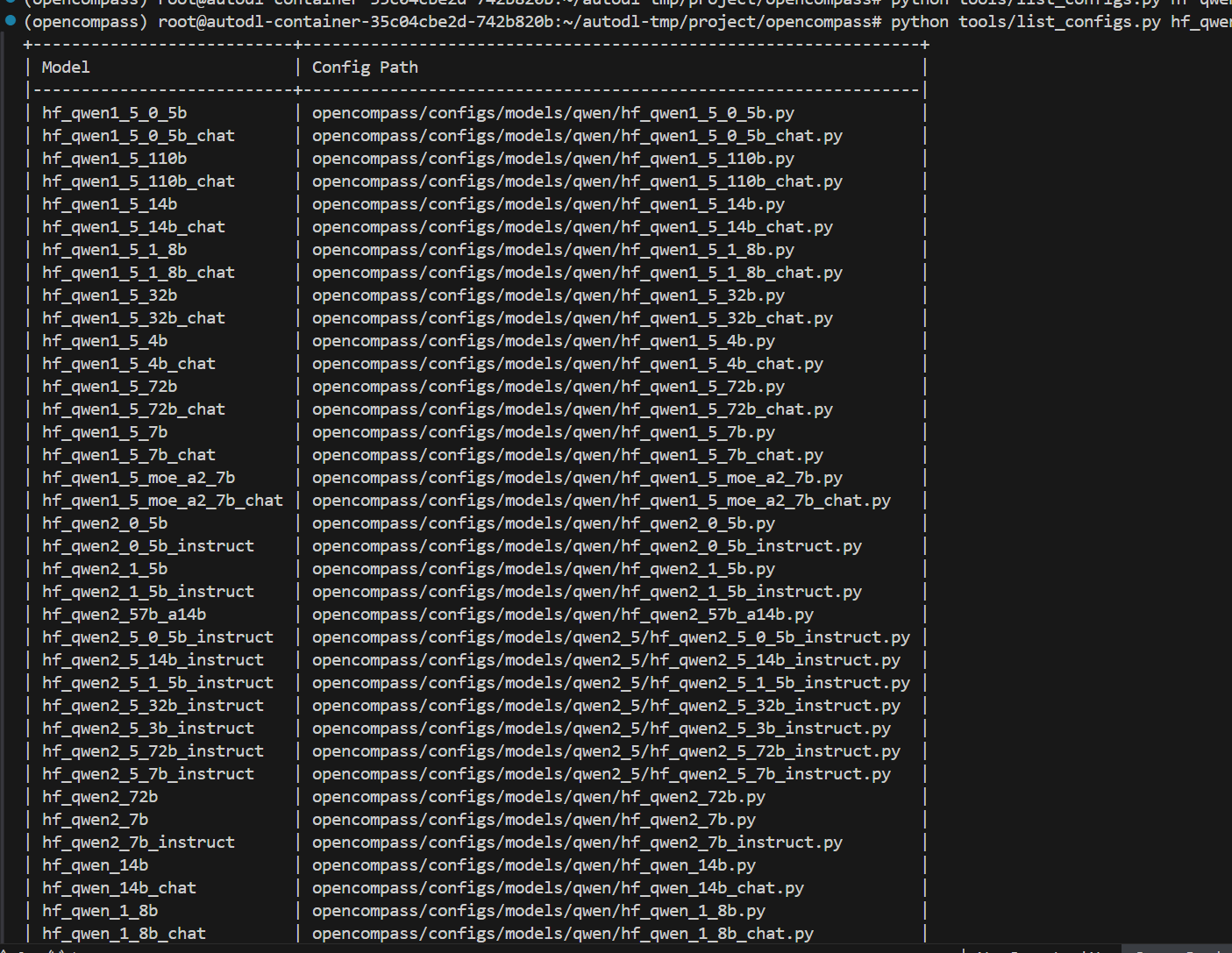
opencompass 会列举出hf_qwen 项目的模型;
python run.py \--models hf_qwen2_5_0_5b_instruct hf_qwen1_5_0_5b \ # 这里的模型名称就为上面输出的模型名称--datasets demo_gsm8k_base_gen demo_math_base_gen \--debug
如果模型不在列表中但支持 Huggingface AutoModel 类,仍然可以使用 OpenCompass 对其进行评估
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path
internlm/internlm2_5-1_8b-chat
如果你想在多块 GPU 上使用模型进行推理,您可以使用 --max-num-worker 参数。
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type
chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
4.自定义数据集评估
对于问答 ( qa ) 类型的数据,默认的字段如下:
- question : 表示问答题的题干
- answer : 表示问答题的正确答案。可缺失,表示该数据集无正确答案。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行
指定。
.jsonl 格式样例如下:
{"question": "752+361+181+933+235+986=", "answer": "3448"}
{"question": "712+165+223+711=", "answer": "1811"}
{"question": "921+975+888+539=", "answer": "3323"}
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
.csv 格式样例如下:
question,answer
123+147+874+850+915+163+291+604=,3967
149+646+241+898+822+386=,3142
332+424+582+962+735+798+653+214=,4700
649+215+412+495+220+738+989+452=,4170
4.1 命令行执行数据评测
自定义数据集可直接通过命令行来调用开始评测。
python run.py \
--models hf_llama2_7b \
--custom-dataset-path xxx/test_mcq.csv \
--custom-dataset-data-type mcq \
--custom-dataset-infer-method ppl
--debug
python run.py \
--models hf_llama2_7b \
--custom-dataset-path xxx/test_qa.jsonl \
--custom-dataset-data-type qa \
--custom-dataset-infer-method gen
在绝大多数情况下, --custom-dataset-data-type 和 --custom-dataset-infer-method 可以省略,
OpenCompass 会根据以下逻辑进行设置。
- 如果从数据集文件中可以解析出选项,如 A , B , C 等,则认定该数据集为 mcq ,否则认定为
qa 。 - 默认 infer_method 为 gen 。