【蒸馏(5)】DistillBEV代码分析
架构图
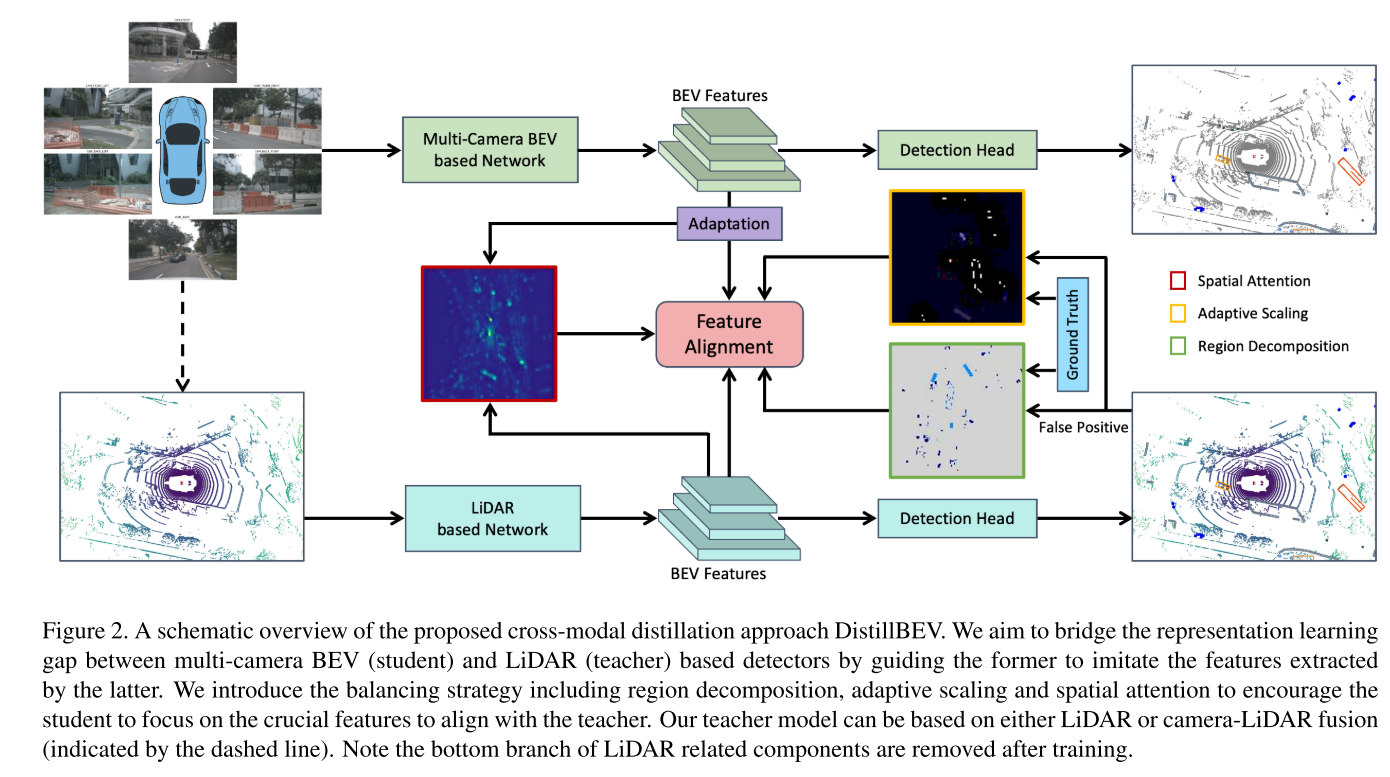
区域分解decompostion
在二维物体检测中,前景(目标物体)和背景区域之间的样本数量存在严重不平衡(例如背景像素/锚框数量远多于前景),这种不平衡会导致以下问题:
-
特征对齐的局限性
直接对齐教师模型(Teacher)和学生模型(Student)的特征(如通过L2损失或注意力机制)时,背景区域的简单负样本会主导对齐过程。由于背景样本数量庞大且易于分类,其特征差异较小,对齐操作会过度优化背景部分,而忽视对前景关键特征的传递。
数学表达:若损失函数为 L a l i g n = ∑ i ( F T ( i ) − F S ( i ) ) 2 L_{align} = \sum_{i}(F_{T}^{(i)} - F_{S}^{(i)})^2 Lalign=∑i(FT(i)−FS(i))2,其中背景样本 i i i占比极高,导致梯度更新被背景支配。 -
已有研究的共识
文献[7][13][40][43]指出,单纯的特征对齐无法缓解前景-背景不平衡问题,原因包括:- 前景特征稀疏性:前景样本的局部特征(如边缘、纹理)在整体特征图中占比低,对齐时易被背景淹没。
- 任务差异:分类任务依赖全局特征,而检测需兼顾局部定位,对齐可能破坏空间敏感性。
-
更有效的解决方案
当前主流方法通过以下方式改进:- 硬/软采样:如Focal Loss降低简单背景样本权重,OHEM筛选难样本。
- 任务特异性对齐:仅在前景区域或关键点(如中心点)对齐特征。
- 动态权重:根据样本难度调整对齐强度,如IoU-guided损失。
总结:特征对齐在检测中需结合类别平衡策略,直接应用会因背景主导而失效,这一结论已被大量实验验证。
这种现象在三维物体检测中更加严重,因为绝大多数三维空间都是空的。我们对BEV特征图的统计发现,平均不到30%的像素是非空的,其中只有一小部分包含我们感兴趣的物体。为了进行有效的知识转移,我们引入了区域分解来引导学生关注关键区域,而不是平等对待所有区域。具体来说,我们将特征图分为四种类型:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。据此,我们定义一个区域分解掩码M:
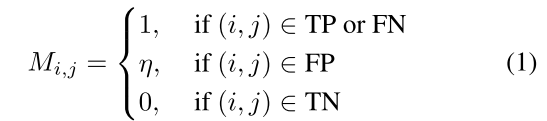
在知识蒸馏(特别是跨模态蒸馏,如LiDAR-to-Camera的3D目标检测任务中),教师模型在某些区域的高激活可能包含对几何学习有益的隐含信息,即使这些区域是误检(False Positive, FP)。 FP区域的潜在价值
- 几何线索的隐含性:教师模型(如基于LiDAR的检测器)的FP激活(如将电线杆误检为行人)通常源于对局部几何特征(如垂直线、高度信息)的敏感响应。这些特征虽未正确分类,但可能包含场景的3D结构信息(如深度、形状)。
- 跨模态对齐:在跨模态蒸馏中,相机模态的学生模型缺乏LiDAR的直接深度测量能力。模仿教师的高激活区域(包括FP)可间接学习到几何先验(如物体高度与深度的关联性)。
FP区域的筛选方法
- 热图阈值化:通过对比教师模型的置信度热图( H teacher H_{\text{teacher}} Hteacher)和地面实况标签热图( H gt H_{\text{gt}} Hgt),FP区域可定义为:
FP = { p ∣ H teacher ( p ) > τ , H gt ( p ) < τ } \text{FP} = \{p \mid H_{\text{teacher}}(p) > \tau, H_{\text{gt}}(p) < \tau\} FP={p∣Hteacher(p)>τ,Hgt(p)<τ}
其中 τ \tau τ为阈值,筛选出教师高置信但实际无目标的区域。 - 动态权重分配:DistillBEV等框架通过区域分解掩模(如 η ⋅ I FP \eta \cdot \mathbb{I}_{\text{FP}} η⋅IFP)为FP区域分配自适应权重,平衡其对损失的贡献。
对3D几何学习的益处
- 特征多样性增强:FP区域常位于物体边缘或复杂背景(如电线杆、植被),模仿这些特征可提升学生对遮挡、形变等挑战性场景的鲁棒性。
- 模态差距缓解:LiDAR教师对几何信息的敏感响应(即使误分类)能弥补相机学生缺乏的几何感知能力,例如通过FP区域学习到“垂直结构通常对应高深度梯度”的规律。
鼓励学生模仿教师FP区域的特征响应,本质是通过误检中的几何线索(如结构、深度)增强学生的3D表示能力。这种方法需结合热图阈值化和动态权重设计,以区分有益FP与纯噪声。
2热力图
真值热力图的生成方法基于高斯核的生成(目标检测场景)
在目标检测(如CenterNet)中,真值热力图通过高斯核函数将关键点(如物体中心)扩散为概率分布:
H g t ( x , y ) = exp ( − ( x − p x ) 2 + ( y − p y ) 2 2 σ 2 ) H_{gt}(x,y) = \exp\left(-\frac{(x-p_x)^2 + (y-p_y)^2}{2\sigma^2}\right) Hgt(x,y)=exp(−2σ2(x−px)2+(y−py)2)
其中 ( p x , p y ) (p_x, p_y) (px,py) 是目标中心坐标, σ \sigma σ 控制扩散范围。热力图中越接近中心点值越接近1,远离则趋近0。
特点:
- 每个类别独立生成一张热力图(如80类目标生成80张图)。
- 多目标时,不同实例的热力图叠加但保持峰值独立。
3注意力
理解 Spatial Attention 机制
在 DistillBEV 方法中,Spatial Attention(空间注意力) 是一种关键设计,用于引导学生模型(多摄像头 BEV 检测器)从教师模型(LiDAR 检测器)中学习更重要的特征区域。以下是逐步解析:
空间注意力的作用
- 核心目标:通过注意力机制,让学生模型模仿教师模型的特征激活模式,从而专注于对检测任务更重要的空间区域(如物体边界、几何结构等)。
- 解决的问题:直接对齐教师和学生的所有特征可能无效,因为不同模态(LiDAR 和摄像头)的特征分布差异大,且背景区域(如天空、地面)可能干扰知识迁移。
空间注意力图的构建
给定一个特征图 ( F ∈ R C × H × W F \in \mathbb{R}^{C \times H \times W} F∈RC×H×W )(通道 × 高度 × 宽度):
-
通道维度平均池化:
- 计算 ( P ( F ) ∈ R H × W P(F) \in \mathbb{R}^{H \times W} P(F)∈RH×W ),即沿通道维度对 ( F ) 的绝对值取平均:
P ( F ) i , j = 1 C ∑ c = 1 C ∣ F c , i , j ∣ P(F)_{i,j} = \frac{1}{C} \sum_{c=1}^{C} |F_{c,i,j}| P(F)i,j=C1c=1∑C∣Fc,i,j∣ - 这一步将多通道特征压缩为单通道的“能量图”,反映每个空间位置的重要性。
- 计算 ( P ( F ) ∈ R H × W P(F) \in \mathbb{R}^{H \times W} P(F)∈RH×W ),即沿通道维度对 ( F ) 的绝对值取平均:
-
Softmax 归一化:
- 对 ( P(F) ) 应用 softmax 归一化,得到注意力权重 ( N ( F ) ∈ R H × W N(F) \in \mathbb{R}^{H \times W} N(F)∈RH×W ):
N ( F ) i , j = e P ( F ) i , j / τ ∑ k , l e P ( F ) k , l / τ N(F)_{i,j} = \frac{e^{P(F)_{i,j}/\tau}}{\sum_{k,l} e^{P(F)_{k,l}/\tau}} N(F)i,j=∑k,leP(F)k,l/τeP(F)i,j/τ - 温度参数 ( \tau ):控制注意力分布的尖锐程度(( τ → 0 \tau \to 0 τ→0 ) 时趋向 one-hot,( τ → ∞ \tau \to \infty τ→∞ ) 时趋向均匀分布)。
- 对 ( P(F) ) 应用 softmax 归一化,得到注意力权重 ( N ( F ) ∈ R H × W N(F) \in \mathbb{R}^{H \times W} N(F)∈RH×W ):
教师与学生的注意力对齐
-
教师注意力 ( A_t ):从教师特征 ( F t F_t Ft ) 生成 ( A t = N ( F t ) A_t = N(F_t) At=N(Ft) )。
-
学生注意力 ( A_s ):学生特征 ( F s F_s Fs ) 需通过自适应模块 ( G ) 调整尺寸后生成 ( A s = N ( G ( F s ) ) A_s = N(G(F_s)) As=N(G(Fs)) )。
- 自适应模块 ( G ):由于教师和学生的特征图尺寸可能不同(如教师是学生的 2 倍),( G ) 通常包含上采样层和卷积层,将 ( F s F_s Fs ) 映射到与 ( F t F_t Ft ) 相同的尺寸 ( F ~ s \tilde{F}_s F~s )。
-
最终注意力图:通过结合教师和学生的注意力,引导学生关注教师认为重要的区域:
A = A t ⋅ A s A = \sqrt{A_t \cdot A_s} A=At⋅As
这里使用几何平均(而非简单乘积)平衡两者的贡献。
为什么需要空间注意力?
- 模态差距补偿:LiDAR 特征对几何结构(如深度、形状)更敏感,而摄像头特征更依赖纹理。注意力机制帮助学生聚焦于几何相关的区域。
- 抑制噪声:忽略背景或无意义的激活(如天空的均匀区域),提升知识迁移效率。
与蒸馏损失的结合
空间注意力图 ( A ) 会加权蒸馏损失(如特征模仿损失 ( L_{feat} )),使得学生模型在重要区域的特征对齐更严格:
L f e a t = ∑ i , j A i , j ⋅ ∥ F ~ s ( n ) ( i , j ) − F t ( n ) ( i , j ) ∥ 2 L_{feat} = \sum_{i,j} A_{i,j} \cdot \| \tilde{F}_s^{(n)}(i,j) - F_t^{(n)}(i,j) \|^2 Lfeat=i,j∑Ai,j⋅∥F~s(n)(i,j)−Ft(n)(i,j)∥2
总结
- Spatial Attention 通过教师和学生的特征激活模式生成注意力权重,指导学生模型“学什么”和“学哪里”。
- 关键设计:通道池化 + softmax 归一化 + 自适应尺寸调整,确保跨模态特征的可比性。
- 效果:在 BEV 检测中,这种机制显著提升了学生对 3D 几何信息的建模能力,缩小了与 LiDAR 教师的性能差距。
4 G函数
这段描述的核心是解决知识蒸馏中教师(Teacher)与学生(Student)模型因架构差异导致的多尺度特征对齐问题,尤其在BEV(鸟瞰图)感知任务中。
背景与挑战
- 多尺度特征蒸馏:知识蒸馏中,教师模型通常更复杂(如参数量大、特征图分辨率高),而学生模型需要轻量化(如分辨率低)。直接对齐不同尺度的特征会导致信息不匹配。
- 架构差异:教师和学生的BEV特征图分辨率可能相差2倍或4倍(例如教师为 H × W H \times W H×W,学生为 H 2 × W 2 \frac{H}{2} \times \frac{W}{2} 2H×2W),导致空间和语义抽象级别不一致。
传统方法的局限性
- 简单对齐的缺陷:若直接对相同分辨率的特征计算损失(如MSE),会因抽象层级不同引入噪声,例如教师的细节特征可能干扰学生的粗粒度学习。
解决方案:自适应模块G
- 模块设计:轻量级模块G由上采样层(提升学生特征分辨率)和投影层(调整通道/空间语义)组成,将学生特征映射到与教师相似的抽象级别。
- 作用:
- 分辨率匹配:上采样使学生特征尺寸与教师一致(如从 H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W到 H × W H \times W H×W)。
- 语义对齐:投影层(如1×1卷积或MLP)调整学生特征的分布,使其与教师特征在语义空间中对齐。
5 总损失
n 个蒸馏层的特征模仿损失:
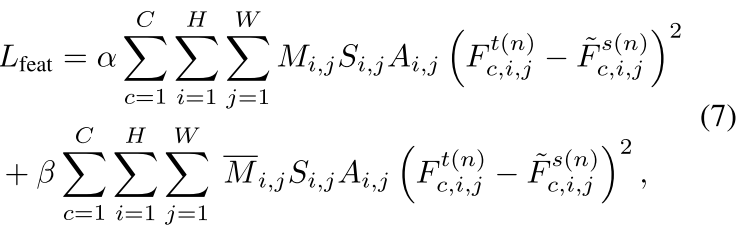
注意力模仿损失
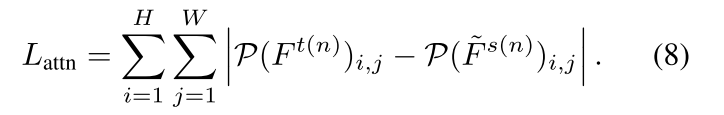
综上所述,
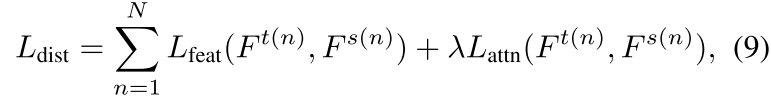
其中 N 是执行蒸馏的选定层数,λ 控制两个损失函数之间的相对重要性。
二、代码分析
基于BEVDepth4DDistill 是基于两阶段MVXTwoStageDetector检测器的centerpoint进行的。
MVX最基础的class的
class MVXTwoStageDetector(Base3DDetector):
"""Base class of Multi-modality VoxelNet."""
这个类是基于MVX-Net: Multimodal VoxelNet for 3D Object Detection mvxnet论文进行mmdet3d实现mvxnet
centerpoint在MVX修改了extract_pts_feat,只在BEV特征进行目标回归。修改forward_pts_train返回损失。
def extract_pts_feat(s..."""Extract features of points."""def forward_pts_train(..."""Forward function for point cloud branch.Args:pts_feats (list[torch.Tensor]): Features of point cloud branchgt_bboxes_3d (list[:obj:`BaseInstance3DBoxes`]): Ground truthboxes for each sample.gt_labels_3d (list[torch.Tensor]): Ground truth labels forboxes of each sampoleimg_metas (list[dict]): Meta information of samples.gt_bboxes_ignore (list[torch.Tensor], optional): Ground truthboxes to be ignored. Defaults to None.Returns:dict: Losses of each branch."""
BEVDet基于centerpoint父类,基于图片特征img_feats生成的BEV特征会传入forward_pts_train()点云的处理函数,因此修改了
BEVDetDistill基于BEVDet父类。
需要传入参数
teacher_config, teacher_ckpt, distill_type, distill_params:teacher_config='configs/centerpoint/centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus.py',teacher_ckpt='output/centerpoint/centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus/epoch_20.pth',distill_type='fgd',distill_params=dict(
...
然后会初始化教师模型:
self.teacher_model = build_detector(teacher_config['model'])load_checkpoint(self.teacher_model, teacher_ckpt, map_location='cpu')
会在forward_train()调用forward_distill()会使用
teacher_neck_feat, canvas_feat, teacher_backbone_feats = self.teacher_model.extract_pts_feat(...
teacher_preds = self.teacher_model.pts_bbox_head(teacher_neck_feat)
losses_distill = self.distill_loss(teacher_feat=teacher_feat, student_feat=student_feat,teacher_preds=teacher_preds, student_preds=preds,heatmaps=heatmaps, anno_boxes=None, inds=None, masks=None,gt_bboxes_3d=gt_bboxes_3d, gt_labels_3d=gt_labels_3d,canvas_feat=canvas_feat.detach(), index=index)
进行蒸馏模式选择
assert distill_type in ['all', 'foreground_background', 'linfengzhang', 's2m2_ssd_heatmap', 's2m2_ssd_feature','gauss_focal_heatmap', 'non_local', 'affinity', 'fgd']assert 'heatmap' not in distill_type, 'to add heatmap distill support in the future!'
根据提供的代码片段,
distill_type的可选值及其分布如下:
all:表示使用所有可用的蒸馏方法。foreground_background:可能涉及前景和背景分离的蒸馏方法,适用于目标检测或分割任务。linfengzhang:可能指某种特定的蒸馏技术。s2m2_ssd_heatmap和s2m2_ssd_feature:
s2m2_ssd_heatmap:与热图(heatmap)相关的蒸馏方法,但当前代码中明确禁止使用(断言'heatmap' not in distill_type)。s2m2_ssd_feature:可能指基于特征模仿的蒸馏方法(如学生模型学习教师模型的中间特征表示)。
gauss_focal_heatmap:结合高斯分布和焦点机制的蒸馏方法,可能与热图相关,但同样被当前代码禁用。non_local:可能指基于非局部注意力机制的蒸馏方法,用于捕捉长程依赖关系。affinity:可能涉及特征或样本间的相似性(affinity)蒸馏,例如通过关系矩阵传递知识。fgd:可能指 Feature Guided Distillation(特征引导蒸馏)。
代码中明确排除了包含 'heatmap' 的蒸馏类型(如 s2m2_ssd_heatmap 和 gauss_focal_heatmap),提示未来可能支持热图蒸馏,但当前版本未实现。部分选项(如 linfengzhang、fgd)可能是特定论文或内部实现的命名。
distill_loss 会选择一种模式进行蒸馏损失计算。
channel_wise_adaptations()建立 学生-老师 映射层。
channel_wise_adaptations = nn.ModuleList([nn.Linear(student_channel, teacher_channel)for student_channel, teacher_channel in zip(student_channels, teacher_channels)])
这段代码使用 nn.ModuleList 创建了一个动态的线性层列表,用于将学生模型(Student)的通道数(student_channels)与教师模型(Teacher)的通道数(teacher_channels)对齐。 目的:在知识蒸馏(Knowledge Distillation)中,学生模型和教师模型的中间特征图可能具有不同的通道数(如学生模型为64通道,教师模型为256通道)。这段代码通过一组线性变换层(nn.Linear)将学生模型的通道空间映射到教师模型的通道空间,便于后续的特征匹配或损失计算。 数学表示:对每一对学生和教师的通道数 ( s _ c h , t _ c h ) (s\_ch, t\_ch) (s_ch,t_ch),生成一个线性变换层 W ∈ R t _ c h × s _ c h W \in \mathbb{R}^{t\_ch \times s\_ch} W∈Rt_ch×s_ch,将学生特征 x _ s ∈ R s _ c h x\_s \in \mathbb{R}^{s\_ch} x_s∈Rs_ch 转换为 x _ s ′ = W x _ s ∈ R t _ c h x\_s' = Wx\_s \in \mathbb{R}^{t\_ch} x_s′=Wx_s∈Rt_ch。 zip(student_channels, teacher_channels): 将学生和教师的通道数列表逐对组合(例如 student_channels=[64, 128],teacher_channels=[256, 512] → 生成对 (64, 256) 和 (128, 512))。 列表推导式: 为每对通道数创建一个 nn.Linear 层,输入维度为 student_channel,输出维度为 teacher_channel。 nn.ModuleList: 将生成的线性层组织为一个模块列表,确保这些层的参数能被PyTorch自动追踪和优化。
class DistillModel(nn.Module):def __init__(self, student_channels, teacher_channels):super().__init__()self.channel_adapters = nn.ModuleList([nn.Linear(s_ch, t_ch)for s_ch, t_ch in zip(student_channels, teacher_channels)])def forward(self, student_feats, teacher_feats):losses = []for adapter, s_feat, t_feat in zip(self.channel_adapters, student_feats, teacher_feats):adapted_feat = adapter(s_feat) # 学生特征通道对齐loss = F.mse_loss(adapted_feat, t_feat) # 计算蒸馏损失losses.append(loss)return losses
fgd选项:FGD(Focal and Global Distillation)
distill_type='fgd'student_channels=[256,],teacher_channels=[384,],adaptation_type='1x1conv',student_adaptation_params=dict(kernel_size=1, stride=1, upsample_factor=4), # for TwoLayer adaptation in fgdteacher_adaptation_type='identity',teacher_adaptation_params=dict(kernel_size=4, stride=4), # for TwoLayer adaptation in fgdspatial_attentions=['teacher',],配置基本要素
student_channels, teacher_channels = distill_params['student_channels'], distill_params['teacher_channels']
# student_channels = [256,](1层通道数),则代码将 adaptation_type='1x1conv',扩展为 [1x1conv'],确保每层学生网络有独立的适配类型配置。
distill_params['adaptation_type'] = [distill_params['adaptation_type'] for _ in student_channels]
distill_params['teacher_adaptation_type'] = [distill_params['teacher_adaptation_type'] for _ in student_channels]
self.channel_wise_adaptations = []
self.teacher_adaptations = []
for index, (adaptation_type, teacher_adaptation_type, student_channel, teacher_channel) in \enumerate(zip(distill_params['adaptation_type'],\distill_params['teacher_adaptation_type'],\student_channels, teacher_channels)):if adaptation_type == '1x1conv':self.channel_wise_adaptations.append(nn.Conv2d(student_channel, teacher_channel,kernel_size=1, stride=1, padding=0))if teacher_adaptation_type == 'identity':self.teacher_adaptations.append(nn.Identity())self.teacher_adaptations[index].stride = _pair(1)self.channel_wise_adaptations = nn.ModuleList(self.channel_wise_adaptations)self.teacher_adaptations = nn.ModuleList(self.teacher_adaptations)if distill_params['spatial_mask']:self.spatial_wise_adaptations = nn.ModuleList([nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=1)for student_channel, teacher_channel in zip(student_channels, teacher_channels)])
主要是得到
self.channel_wise_adaptations–> 1x1convself.teacher_adaptations--> identity【恒等映射(identity mapping),即输入什么就输出什么,不做任何修改。以】self.spatial_wise_adaptations--> 3x3conv
然后进行损失计算
spatial_t=0.5,spatial_student_ratio=1.0,channel_t=0.5,fg_feat_loss_weights=[1.5e-3,],bg_feat_loss_weights=[4e-2,],channel_loss_weights=[0.25,],spatial_loss_weights=[2.5e-3,],feat_criterion=dict(type='MSELoss', reduction='none'),spatial_criterion=dict(type='L1Loss', reduction='none'),channel_criterion=dict(type='L1Loss', reduction='none'),transpose_mask=False,foreground_mask='gt',background_mask='logical_not',scale_mask='combine_gt',spatial_mask=True,channel_mask=True,student_feat_pos=['head',],teacher_feat_pos=['head',],two_stage_epoch=-1,affinity_weights=[0, ],affinity_mode='none',affinity_criterion=dict(type='SmoothL1Loss'),affinity_split=1,non_empty_weight=0,output_threshold=1.0,groundtruth_threshold=None,fp_as_foreground='none',fp_weight=0,fp_epoch=0,multi_scale_epoch=-1,fp_scale_mode='dfs',gauss_fg_weight=-1e10,context_length=0,context_weight=0,),1、初始一些参数
S_T = self.distill_params['spatial_t'] # 0.5s_ratio = self.distill_params['spatial_student_ratio'] # 1.0# for channel attentionC_T = self.distill_params['channel_t'] # 0.5# loss weightkd_fg_feat_loss_weight =kd_bg_feat_loss_weight = kd_channel_loss_weight = kd_spatial_loss_weight =spatial_att =feat_criterion =spatial_criterion = channel_criterion = loss_dict = dict()feat_criterion = build_loss(feat_criterion)# 'MSELoss'spatial_criterion = build_loss(spatial_criterion)# L1Losschannel_criterion = build_loss(channel_criterion)# L1Loss2、对齐老师-学生的特征
############### maybe a non-linear combination of spatial and channel adaptation would be the bestteacher_feat = self.teacher_adaptations[index](teacher_feat)student_feat = self.channel_wise_adaptations[index](student_feat)3生成前景的缩放
根据3D检测框(gt_bboxes_3d)生成前景掩码(foreground_mask)和动态缩放掩码(fg_scale_mask和bg_scale_mask),用于在知识蒸馏中加权前景(物体区域)和背景的特征损失,其中前景权重与物体尺寸成反比,背景权重均匀分布。
foreground_scale_mask(...)
关键点:
- 前景掩码:标记哪些像素属于3D检测框内的前景区域。
- 动态缩放:
- 前景权重 =
1/(物体面积)(小物体权重更高,缓解尺寸不平衡) - 背景权重 =
1/(背景像素总数)(均匀分布)
- 前景权重 =
- 扩展背景:通过
bg_extend_length和bg_extend_weight扩展前景周围区域的权重,增强边界特征学习。 - 输出形状:
Nx1xHxW(N为batch大小,H/W为特征图分辨率)。
用途:在FGD等蒸馏方法中,优先对齐教师-学生模型的前景特征,同时控制背景贡献。
4 注意力掩膜计算
空间注意力掩码(t_attention_mask 和 s_attention_mask)和通道注意力掩码(c_t_attention_mask)。
4.1. 空间注意力掩码(Spatial Attention Mask)
生成一个空间维度的权重图,突出教师模型或学生模型中重要的空间区域(如物体所在区域)。
特征绝对值均值:
t_attention_mask = torch.mean(torch.abs(teacher_feat), [1], keepdim=True)
对教师特征 teacher_feat(形状为 [B, C, H, W])沿通道维度(dim=1)取绝对值均值,得到空间维度的激活强度(形状为 [B, 1, H, W])。
物理意义:每个空间位置(H, W)的通道均值反映了该位置的总体重要性。
展平并归一化:
t_attention_mask = t_attention_mask.view(B, -1)t_attention_mask = torch.softmax(t_attention_mask / S_T, dim=1) * teacher_H * teacher_W
将空间维度展平为 [B, H* W],便于后续 softmax 操作。使用 softmax 对展平后的特征归一化,得到空间权重分布(S_T 是温度系数,控制分布的尖锐程度)。 乘以 H*W 是为了恢复原始空间尺寸的权重范围。
恢复形状:
t_attention_mask = t_attention_mask.view(B, 1, teacher_H, teacher_W)
将权重重新调整为 [B, 1, H, W],作为空间注意力掩码。
4.2. 通道注意力掩码(Channel Attention Mask)
生成一个通道维度的权重向量,突出教师模型中重要的通道(如与任务相关的特征通道)。
特征绝对值均值:
c_t_attention_mask = torch.mean(torch.abs(teacher_feat), [2, 3], keepdim=True) # B x C x 1 x1
对教师特征 teacher_feat 沿空间维度(H, W)取绝对值均值,得到通道维度的激活强度(形状为 [B, C, 1, 1])。
物理意义:每个通道(C)的空间均值反映了该通道的总体重要性。
展平并归一化:
c_t_attention_mask = c_t_attention_mask.view(B, -1) # B x Cc_t_attention_mask = torch.softmax(c_t_attention_mask / C_T, dim=1) * teacher_C
将通道维度展平为 [B, C],便于后续 softmax 操作。使用 softmax 对展平后的特征归一化,得到通道权重分布(C_T 是温度系数)。 乘以 C 是为了恢复原始通道数的权重范围。
恢复形状:
c_t_attention_mask = c_t_attention_mask.view(B, teacher_C, 1, 1) # B x C x 1 x1
将权重重新调整为 [B, C, 1, 1],作为通道注意力掩码。
- 空间注意力:关注“哪里重要”(如物体位置)。
- 通道注意力:关注“什么特征重要”(如颜色、纹理等通道)。
4.3. 背景和前景注意力计算
# TODO: add two scale_maskif self.distill_params['spatial_mask']:fg_mask = fg_mask * sum_attention_maskbg_mask = bg_mask * sum_attention_maskif self.distill_params['channel_mask']:fg_mask = fg_mask * c_sum_attention_maskbg_mask = bg_mask * c_sum_attention_mask
掩码处理(Spatial and Channel Masks)
空间注意力掩码:sum_attention_mask 的形状为 [B, 1, H, W]。
- 这是一个单通道的空间权重图,表示每个空间位置(H, W)的重要性。
通道注意力掩码:c_sum_attention_mask 的形状为 [B, C, 1, 1]。
- 这是一个通道维度的权重向量,表示每个通道(C)的重要性。
目的:通过注意力掩码(sum_attention_mask 和 c_sum_attention_mask)对前景(fg_mask)和背景(bg_mask)区域进行加权,突出重要区域或通道。
- 如果 fg_mask 是 [B, 1, H, W],sum_attention_mask 会直接按空间位置加权。
- 如果 fg_mask 是 [B, 1, H, W],c_sum_attention_mask 会广播到 [B, C, H, W],然后按通道加权。相乘后的输出形状:[B, C, H, W]。 每个空间位置(H, W)和每个通道(C)都会被加权。 输出是一个完整的特征图,包含空间和通道维度的加权信息
spatial_mask:空间维度的掩码(如基于物体检测的ROI区域)。
channel_mask:通道维度的掩码(如重要通道的注意力权重)。
操作:掩码与原始特征相乘,实现特征的选择性蒸馏。
5 计算损失
kd_fg_feat_loss = (feat_criterion(student_feat, teacher_feat) * fg_mask).sum() \* kd_fg_feat_loss_weight / Bkd_bg_feat_loss = (feat_criterion(student_feat, teacher_feat) * bg_mask).sum() \* kd_bg_feat_loss_weight / Bkd_channel_loss = channel_criterion(torch.mean(teacher_feat, [2, 3]),torch.mean(student_feat, [2, 3])).sum() \* kd_channel_loss_weight / Bt_spatial_pool = torch.mean(teacher_feat, [1], keepdim=True).view(teacher_B, 1, teacher_H, teacher_W)s_spatial_pool = torch.mean(student_feat, [1], keepdim=True).view(student_B, 1, student_H, student_W)kd_spatial_loss = spatial_criterion(t_spatial_pool,self.spatial_wise_adaptations[index](s_spatial_pool)).sum() * kd_spatial_loss_weight / B
- 特征蒸馏损失(Foreground/Background Feature Loss)
目的:分别计算学生模型和学生模型在前景和背景区域与教师模型的特征差异。
feat_criterion:特征差异的度量(如L1/L2损失)。
fg_mask/bg_mask:仅对目标区域(前景/背景)计算损失。
kd_fg_feat_loss_weight/kd_bg_feat_loss_weight:损失权重。
/B:归一化(B为batch size)。
-
通道蒸馏损失(Channel-wise Loss)
目的:蒸馏通道维度的全局信息。
对空间维度(H, W)取均值,得到通道维度的统计量。
channel_criterion:通道差异的度量(如MSE损失)。 -
空间蒸馏损失(Spatial-wise Loss)
目的:蒸馏空间维度的全局信息。
对通道维度(C)取均值,得到空间维度的统计量。
spatial_wise_adaptations[index]:可选的空间适配层(如1x1卷积),用于对齐学生和教师的特征空间。
spatial_criterion:空间差异的度量(如L1损失)。
整体逻辑
掩码加权:通过空间或通道掩码聚焦重要区域。
多维度蒸馏:
局部特征:前景/背景区域(kd_fg_feat_loss/kd_bg_feat_loss)。
全局通道:通道均值(kd_channel_loss)。
全局空间:空间均值(kd_spatial_loss)。
损失加权求和:最终损失可能是这些损失的加权组合(代码中未显示总和,但实际使用时可能将它们相加)。
X. 附录
linfengzhang选项
linfengzhang_distill_loss 是一个基于特征的知识蒸馏(Feature-based Knowledge Distillation)损失函数,用于目标检测任务。该方法的提出源自ICLR 2021论文《Improve Object Detection with Feature-based Knowledge Distillation: Towards Accurate and Efficient Detectors》。以下是关键点解析:
核心思想
该方法属于基于中间特征图激活的知识蒸馏,通过让学生模型(Student)模仿教师模型(Teacher)的中间特征表示(BCHW张量),传递目标检测任务所需的语义和空间信息。与传统的基于输出概率(Logits)的蒸馏不同,特征蒸馏能更直接地保留教师模型对物体位置和类别的判别能力。
输入参数
teacher_feat: 教师模型的中间特征图,形状为BCHW(Batch, Channels, Height, Width)。student_feat: 学生模型的对应特征图,需与teacher_feat尺寸相同。index: 可能用于指定特征图的层级或任务相关的索引(如检测头中的特定层)。
实现原理
- 特征对齐:通过注意力机制或自适应层对齐师生特征的维度(若尺寸不一致)。
- 损失计算:通常采用以下一种或多种损失函数:
- MSE(均方误差):最小化特征图的逐像素差异,即 L = 1 B C H W ∑ ∥ t e a c h e r _ f e a t − s t u d e n t _ f e a t ∥ 2 L = \frac{1}{BCHW} \sum \|teacher\_feat - student\_feat\|^2 L=BCHW1∑∥teacher_feat−student_feat∥2。
- 注意力转移(Attention Transfer):对特征图进行空间或通道维度的注意力掩码加权。
- 实例感知蒸馏:如论文所述,可能利用物体标注(如边界框)生成实例条件注意力掩模,聚焦前景区域蒸馏。
与其他蒸馏方法的对比
- 与传统KD(Hinton, 2015):传统方法仅蒸馏输出概率,而特征蒸馏能传递更丰富的中间表示。
- 与FitNet:FitNet直接匹配师生特征图,而
linfengzhang_distill_loss可能通过实例条件机制更高效地利用标注信息。 - 与FGD(Focal and Global Distillation):FGD结合前景和背景分离的蒸馏,而该方法可能更强调实例级别的特征匹配。
应用场景
适用于目标检测模型的压缩,例如:
- 将大型检测器(如Faster R-CNN)的知识蒸馏到轻量级模型(如YOLO)。
- 提升学生模型对小物体或密集场景的检测能力。
all选项
def all_distill_loss(self, teacher_feat, student_feat, index):p = self.distill_params['p'] # 2kd_feat_loss_weight = self.distill_params['feat_loss_weights'][index]loss_dict = dict()if p == 1:loss = F.l1_loss(self.adaptation_layers[index](student_feat), teacher_feat) * kd_feat_loss_weightelif p == 2:loss = F.mse_loss(self.adaptation_layers[index](student_feat), teacher_feat) * kd_feat_loss_weightelse:raise NotImplementedErrorloss_dict['kd_feat_loss'] = lossreturn loss_dictall_distill_loss 和 fgd_distill_loss 是两种不同的知识蒸馏(Knowledge Distillation, KD)损失函数,它们在目标检测任务中的应用方式和优化目标有显著区别。
功能与设计目标
-
all_distill_loss- 功能:通用的特征模仿损失,通过最小化学生模型与教师模型特征之间的差异(L1或MSE损失)实现知识迁移。
- 特点:
- 仅依赖特征图的逐像素对齐(通过
adaptation_layers调整学生特征的通道数以匹配教师特征)。 - 适用于简单的特征蒸馏场景,不区分前景/背景或空间注意力。
- 超参数
p控制损失类型(L1或MSE),kd_feat_loss_weight动态调整不同层的重要性。
- 仅依赖特征图的逐像素对齐(通过
-
all_distill_loss- 输入:仅需教师和学生的特征图(
teacher_feat,student_feat)及索引index。 - 计算:轻量级,仅需线性变换和逐像素损失计算。
- 输入:仅需教师和学生的特征图(
-
all_distill_loss- 适用于轻量级蒸馏或任务无关的特征模仿(如分类、简单检测任务)。
- 示例:在DETR等Transformer检测器中直接对齐编码器特征。
-
all_distill_loss- 损失公式:
L = { ∥ adapt ( x s ) − x t ∥ 1 if p = 1 , ∥ adapt ( x s ) − x t ∥ 2 2 if p = 2. L = \begin{cases} \| \text{adapt}(x_s) - x_t \|_1 & \text{if } p=1, \\ \| \text{adapt}(x_s) - x_t \|_2^2 & \text{if } p=2. \end{cases} L={∥adapt(xs)−xt∥1∥adapt(xs)−xt∥22if p=1,if p=2. - 其中
adapt为通道对齐层。
- 损失公式:
fgd_distill_loss 选项
-
fgd_distill_loss- 功能:基于论文《Focal and Global Knowledge Distillation for Detectors》(FGD)的蒸馏方法,专门针对目标检测任务设计。
- 特点:
- 前景-背景分离:通过
gt_bboxes_3d和gt_labels_3d生成掩码,区分前景(目标区域)和背景,分别计算损失以解决类别不平衡问题。 - 注意力机制:引入空间注意力(Spatial Attention)和通道注意力(Channel Attention)损失,让学生模型模仿教师模型的关键区域激活模式。
- 全局关系建模:通过
canvas_feat或类似模块捕获特征图的全局依赖关系(如非局部交互),补充局部蒸馏的不足。
- 前景-背景分离:通过
-
fgd_distill_loss- 输入:额外需要标注信息(
gt_bboxes_3d,gt_labels_3d)、热力图(heatmaps)、预测结果(teacher_preds,student_preds)等。 - 计算:复杂,涉及注意力掩码生成、多尺度特征对齐、全局关系建模等,计算开销较大。
- 输入:额外需要标注信息(
-
fgd_distill_loss- 专为目标检测优化,尤其适合小目标检测或密集场景(如COCO数据集)。
- 实验表明,FGD在RetinaNet、Faster R-CNN等模型上可提升AP 2-3%。
-
fgd_distill_loss- 损失公式(简化版):
L = α L focal + β L global + γ L attention , L = \alpha L_{\text{focal}} + \beta L_{\text{global}} + \gamma L_{\text{attention}}, L=αLfocal+βLglobal+γLattention,
包含前景/背景加权损失、全局关系损失和注意力对齐损失。
- 损失公式(简化版):
| 维度 | all_distill_loss | fgd_distill_loss |
|---|---|---|
| 核心目标 | 特征对齐 | 前景-背景分离 + 注意力模仿 + 全局关系 |
| 输入复杂度 | 低(仅特征图) | 高(需标注、热力图等) |
| 计算开销 | 低 | 高 |
| 适用任务 | 通用蒸馏 | 目标检测专用 |
| 性能增益 | 基础提升 | 显著(如 +2-3% AP) |