【机器学习】人工智能在电力电子领域的应用

摘要:
本文概述了电力电子系统的人工智能 (AI) 应用。设计、控制和维护这三个独特的生命周期阶段与人工智能要解决的一项或多项任务相关,包括优化、分类、回归和数据结构探索。讨论了专家系统、模糊逻辑、元启发法和机器学习四类人工智能的应用。我们对 500 多篇出版物进行了审查,以确定人工智能在电力电子应用中的共同理解、实际实施挑战和研究机会。本文附有一个 Excel 文件,其中列出了统计分析的相关出版物。
I、前言
如今人工智能(AI)正在迅速发展,是过去几十年来最突出的研究领域之一[1],[2]。人工智能的目标是促进具有人类学习和推理能力的智能系统。它具有巨大的优势,已成功应用于图像分类、语音识别、自动驾驶、计算机视觉等众多工业领域。电力电子受益于人工智能的发展,潜力巨大。有多种应用,包括功率模块散热器的设计优化[3]、多色发光二极管(LED)的智能控制器[4]、风能转换系统的最大功率点跟踪(MPPT)控制[5]、[6] ]、逆变器异常检测[7]、超级电容器剩余使用寿命(RUL)预测[8]等。通过人工智能的应用,电力电子系统具有自我意识和自适应能力,因此系统自主权可以提高。
同时,数据科学的快速发展,包括传感器技术、物联网(IoT)、边缘计算、数字孪生[9]和大数据分析[10]、[11],为电力电子系统贯穿其生命周期的不同阶段。不断增加的数据量带来了巨大的机遇,为电力电子领域的人工智能奠定了坚实的基础。人工智能能够利用数据,通过全局设计优化、智能控制、系统健康状态估计等来提高产品竞争力。因此,电力电子的研究可以从数据驱动的角度进行,这尤其有利于复杂的电力电子技术的研究。和具有挑战性的案件。
由于电力电子系统的特殊挑战和特点,例如控制调谐速度高、老化检测的状态监测灵敏度高等,人工智能在电力电子领域的实施有其不同于其他工程领域的特点。 ,例如图像分类。因此,迫切需要对电力电子领域的人工智能进行概述,以加快协同研究和跨学科应用。基于文献综述,本文将人工智能在电力电子领域的应用分为设计、控制和维护三个方面。
图1显示了自1990年以来电力电子人工智能相关的每年出版物数量。统计数据基于从IEEE Transactions on Power Electronics、IEEE Journal of Emerging and Selected Topics in Power Electronics、IEEE Transactions等期刊搜索IEEE Xplore工业电子学、IEEE 工业信息学汇刊和 IEEE 工业应用汇刊。 2020年的数据截至2020年5月。总共识别出444篇相关期刊论文,可以在补充Excel文件中找到。可以看出,人工智能的实施在过去几年中急剧增加,并经历了惊人的活力。控制方面的出版物数量不断增加,是最活跃的研究领域。 2007年以来,设计和维护应用有所增加,近两年这种趋势更加明显。
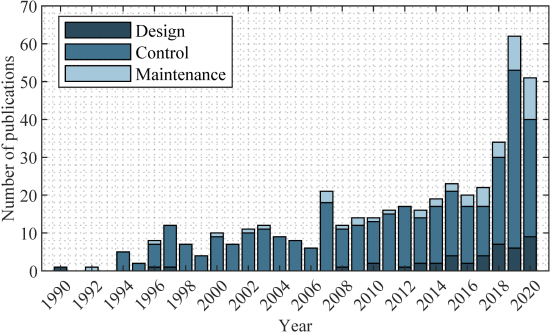
图1 自1990年以来电力电子领域人工智能的年度出版物数量。
发现文献中已有的几篇评论与该主题相关。在[12]中,回顾了用于电能质量和波形、电路设计和控制调谐的随机优化的元启发式方法。它仅关注优化任务。 [13]详细介绍了神经网络(NN)在工业应用中的网络结构设计、训练方法和应用注意事项。它涵盖了电力电子之外的广泛工程应用。文献[14]对神经网络在电力电子领域的应用进行了全面的综述。详细介绍了控制和系统识别的几个具体示例。然而,其他人工智能技术,如模糊逻辑、元启发式方法等,尚未被讨论。尽管[15]进一步讨论了这些技术,但它强调说明性示例,而没有提供对人工智能算法的深入分析。在[16]中,对光伏(PV)系统中MPPT的元启发式方法进行了深入讨论。在[17]中,回顾了应用于光伏系统的人工智能技术,仅关注特定的光伏应用。
电力电子中的维护[18]是一个包括可靠性、状态监测、RUL预测等的主题。过去十年的几篇综述论文可以在[19] - [22]中找到。在[19]中,提出了电力电子设备状态监测和故障检测的最新分析。然而,它只包括非常有限的基于人工智能的故障检测方法。在[20]中,对电力电子转换器中电容器的状态监测技术进行了回顾。它仅包括基于人工智能的参数识别方法。在[21]中,总结了信息和电子丰富系统的预测和健康管理(PHM)方法。本文仅讨论PHM领域的AI算法类别,没有算法细节或对比分析。文献[22]总结了应用于能源系统可靠性管理的机器学习方法。它仅关注机器学习方法和维护任务。关于“电力电子领域的人工智能应用”的教程 [23] 在 2019 年 IEEE 能源转换大会暨博览会上发布。它作为介绍性的演示。然而,人工智能算法的理想细节及其比较尚不可用。
因此,缺乏对电力电子领域人工智能算法和应用的全面回顾。本文旨在从生命周期的角度填补这一空白,全面回顾已发表的利用人工智能技术的电力电子研究,需要进行系统的整理。本文的贡献包括以下内容。
- 从生命周期的角度对电力电子中的人工智能算法进行系统研究,确定相关人工智能算法之间的关系、其基本功能和相关应用。
- 提供了时间线图来说明人工智能算法和电力电子应用的里程碑。此外,它还提供了方法使用百分比和应用趋势的定量信息。
- 全面研究人工智能算法的优点和局限性。为人工智能在每个生命周期阶段提供了示例性应用,讨论了挑战和未来的研究方向。
本文的其余部分组织如下。第二部分介绍了人工智能在电力电子领域的功能、方法和里程碑。人工智能在设计、控制和维护方面的应用分别在第三节-第五节中讨论。第六节提出了人工智能在电力电子领域应用的展望。最后,第七节总结了本文。
II、电力电子系统人工智能的功能和方法
图2总结了人工智能在电力电子领域的方法、功能和应用。可见,人工智能已广泛应用于电力电子系统的设计、控制和维护三个独特的生命周期阶段。
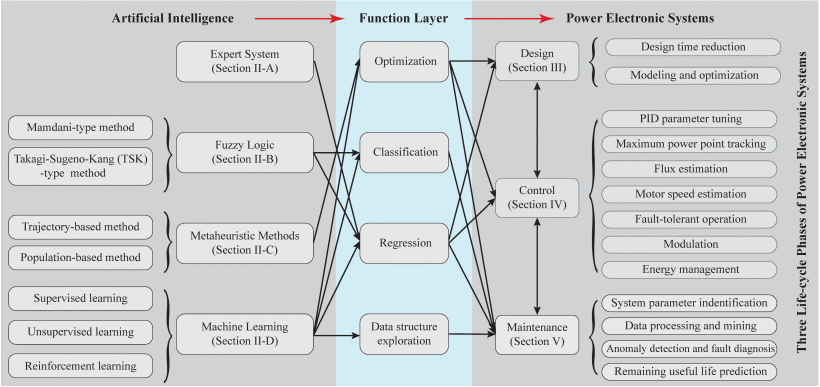
图2 人工智能在电力电子系统全生命周期中的应用第 II-A 节意味着相关讨论将在第 II 节的 A 部分中进行。
作为人工智能和电力电子应用之间的功能层,人工智能的基本功能分为优化、分类、回归和数据结构探索。
1)优化:它是指在给定解决方案必须满足的约束、等式或不等式的情况下,从一组可用替代方案中找到最大化或最小化目标函数的最佳解决方案。例如,在设计任务中,优化可作为探索一组最佳参数的工具,这些参数可在设计约束下最大化或最小化设计目标。
2)分类:它处理分配输入信息或数据,并带有指示 k 离散类之一的标签。具体来说,维护中的异常检测和故障诊断是利用状态监测信息确定故障标签的典型分类任务。
3)回归:通过识别输入变量和目标变量之间的关系,回归的目标是预测给定输入变量的一个或多个连续目标变量的值。例如,可以通过输入电信号和输出控制变量之间的回归模型来促进智能控制器。
4)数据结构探索:它包括发现数据集中相似数据组的数据聚类、确定输入空间内数据分布的密度估计以及将高维数据投影到低维数据以减少特征的数据压缩。例如,在维护中,退化状态聚类属于数据结构探索范畴。
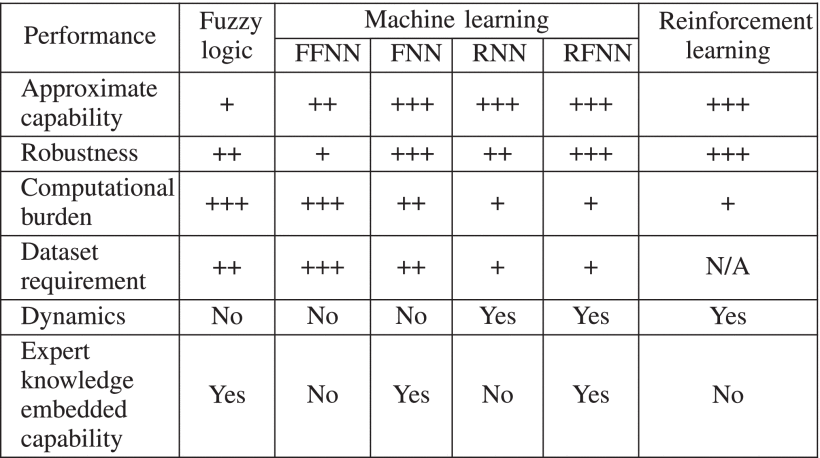
根据对444篇相关期刊论文的调查,图3展示了人工智能方法在电力电子系统生命周期中的应用使用统计桑基图。其中,设计、控制、维护等环节人工智能应用比例分别为9.8%、77.8%、12.4%。从功能来看,优化、分类、回归和数据结构探索的比例分别为33.3%、6.6%、58.4%和1.7%。这表明电力电子领域人工智能的大部分任务本质上都是回归和优化。人工智能方法一般可分为专家系统、模糊逻辑、元启发式方法和机器学习。他们的申请比例分别为0.9%、21.3%、32.0%和45.8%。这表明电力电子领域人工智能的最大部分是机器学习。这些方法将在后面详细介绍。请注意,我们进行了全面但仍不彻底的调查。仅考虑广泛应用于电力电子领域的相关AI方法。
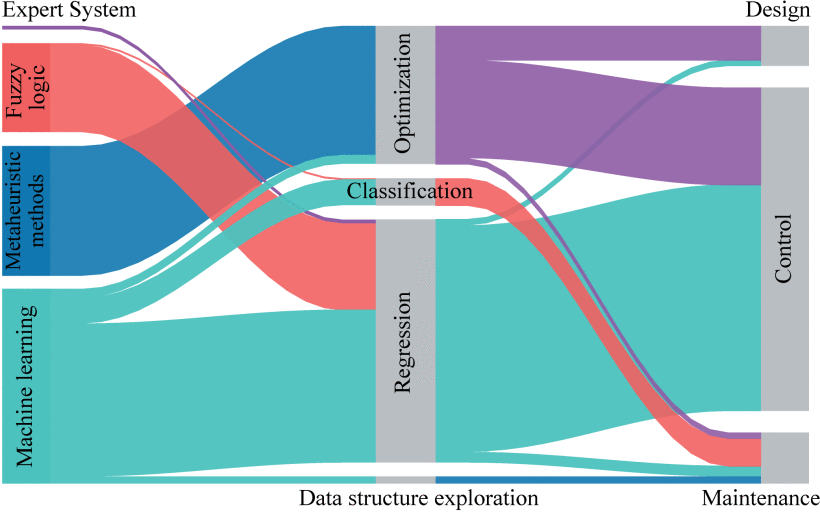
图3 人工智能方法及其在电力电子系统生命周期各个阶段的应用桑基图。统计用途和百分比基于图1中的数据。
- 专家系统
专家系统是人工智能中最早在工业应用中得到有效实施的方法[17]。专家系统[24]-[27]本质上是一个将专家知识集成到布尔逻辑目录中的数据库,并在此基础上模拟人脑推理中的IF-THEN规则。它是一个模拟推理过程的智能系统,可以根据数据库回答“为什么”和“如何”的查询。该数据库来自现场专家经验或模拟数据、事实和陈述。它可以不断更新。专家系统的技术细节在[17]中给出,几个示例性应用可以在[15]和[28]中找到。
值得一提的是,根据图3的使用情况统计,专家系统的应用率低至0.9%。这是因为专家系统一般基于系统原理和规则,与系统利益相关性强,缺乏通用性。它仅适用于具有可靠专家规则的明确定义的领域。此外,由于计算平台的快速发展,专家系统的功能可以被其他具有卓越推理和逼近能力的先进人工智能方法(例如模糊逻辑和机器学习)所取代。
- 模糊逻辑
与专家系统类似,模糊逻辑也是一种基于规则的方法,同时它将布尔逻辑扩展到多值情况。模糊逻辑是解决系统不确定性和噪声测量的理想工具[29] –[31]。不是直接使用精确的输入清晰值,而是首先使用由多个 0-1 范围内的隶属函数组成的模糊集进行模糊化。然后在推理步骤中将模糊输入信号与模糊规则聚合。随后通过考虑实现程度对推理结果进行去模糊化并输出清晰的值。从而在模糊空间中操纵清晰值,通过精心设计的原理完成输入和输出之间的非线性映射。
在大多数应用中,模糊逻辑方法主要由四个部分组成[30]:模糊化、规则推理、知识库和去模糊化。首先,对具有隶属函数的语言变量的输入进行模糊化,包括三角形、梯形、高斯形、钟形、单形和其他定制形状。其次,推理模块根据专家经验得出的知识库中的 IF-THEN 模糊规则将信号集成在一起。第三,对信号进行去模糊化输出。模糊规则的一个例子是
前提:如果 X 是中并且 Y 是零,
结果:那么 Z 是正数。
对于前因和后因,履行的程度由隶属函数决定。模糊推理方案的类型分为 Mamdani 型 [30] 、 [32] – [35] 和 Takagi–Sugeno–Kang 型(TSK 型) [31] 、 [36] – [38] 。对于 Mamdani 型模糊推理方案,前件和后件的隶属函数是基于形状的函数,例如三角形。对于TSK型模糊推理方案,前件部分的隶属函数与Mamdani型相同,而后件部分的隶属函数在几个常数值处是单例的。通常,对于相同的任务,与 TSK 型方案相比,Mamdani 型方案需要更多的模糊集。与Mamdani型格式中的模糊项相比,TSK型格式中的隶属函数可以是线性或常数的函数类型,在非线性逼近方面更加强大和准确。模糊逻辑的更多理论细节在[15]、[39]中讨论。
请注意,专家经验在隶属函数和模糊规则的设计中起着至关重要的作用,并且这种方法在大多数情况下仅适用于专家。从这个角度来看,先验信息和专家经验可以用模糊逻辑来处理,然后与其他人工智能技术结合作为混合方法。
- 元启发法
一旦制定了特定应用的优化任务,就可以通过确定性编程方法(例如线性或二次规划)或非确定性编程方法(即元启发式方法)获得最优解。确定性编程方法需要计算梯度和Hessian矩阵[40],由于其复杂性,这对于电力电子中的大多数优化任务来说都是具有挑战性的。元启发式方法作为一种通用的端到端工具,需要较少的专家经验,并且对于各种优化任务来说是高效且可扩展的。
元启发式方法[12]通常是受到生物进化的启发而发展起来的,例如通过自然选择过程的遗传算法(GA)[41],通过模拟蚂蚁寻找有效路径的蚁群优化(ACO)算法[42]。食物。对最优解决方案的探索是由试错过程驱动的。元启发式方法可分为基于轨迹的方法(禁忌搜索法[43]、模拟退火法[44]等)和基于群体的方法[GA、粒子群优化(PSO)[45]、ACO、微分法等。进化[46]、免疫算法(IA)[47]等]。对于基于轨迹的方法,每个探索阶段仅包含一个候选解,并且根据一定的规则演变成另一个解。该方法的性能主要取决于规则的质量和效率。因此,基于轨迹的方法的收敛速度通常很慢,并且对于非凸优化任务,最终的解决方案倾向于局部而不是全局解决方案。对于基于群体的方法,随机生成多个候选解。在每次迭代探索中,这些候选解决方案都会多样化(例如,遗传算法中的交叉)或合并并替换为新的候选解决方案,以提高当前一代的群体质量。从而迭代提高种群的适应性以逼近最优解。与基于轨迹的方法相比,它们在收敛速度、全局搜索能力方面具有优越性,尤其适用于大规模优化任务。然而,基于群体的方法的计算负担更加密集。 对于效率和速度最为重要的在线应用案例,需要考虑这一挑战。表一总结了电力电子领域的元启发式方法及其优点和局限性。这些元启发式方法在几个关键特征方面进行了定性比较,包括实现简单性、全局收敛性、收敛速度和并行能力。
表 I 元启发式方法在电力电子领域的应用
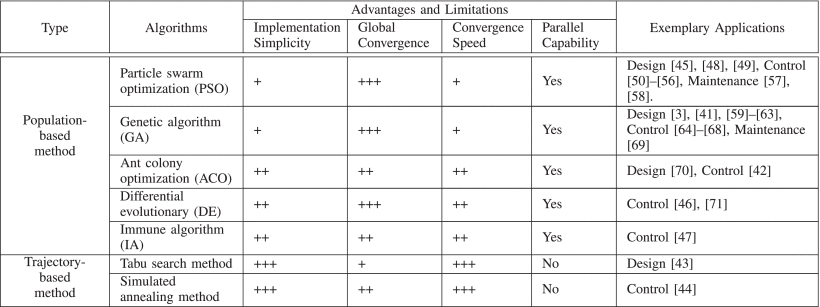
由于巨大的优势,电力电子领域的大多数优化任务都是通过基于群体的方法来解决的。从表一可以看出,电力电子领域的优化任务有多种基于群体的方法和改进的变体。它们是根据不同的生物学灵感而开发和改进的。除了早期广泛应用的元启发式方法外,其他几种新兴方法也已在有限范围内得到应用,例如基于生物地理学的优化[72]、乌鸦搜索算法[73]、灰狼优化[74]、萤火虫优化算法[ 16]、蜜蜂算法[75]、殖民竞争算法[76]、基于教学的优化[77]等。值得一提的是,最佳方法的选择并不是一个简单的任务,它取决于应用程序[12] .遗传算法和粒子群算法是电力电子领域最流行的两种元启发式方法,如图 4 所示。它们分别是进化算法和群体智能算法的基础和代表,并在此基础上开发了各种变体。实践者可以根据表一考虑其优越性来选择该方法。
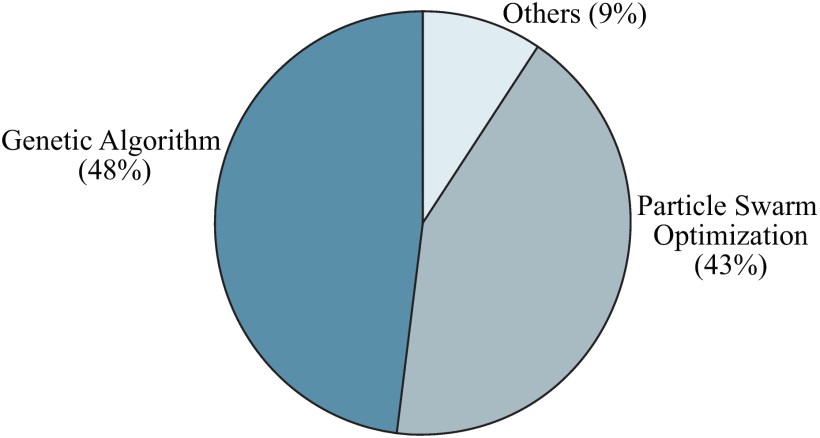
图4 基于群体的元启发式方法在电力电子优化中的使用统计。根据图1的数据得到统计结果。
请注意,不能保证元启发式方法的全局最优,但该解决方案对于大多数实际应用来说通常是令人满意和可接受的。有关元启发式方法的更多理论细节,读者可以参考[16]和[78]。
- 机器学习
机器学习旨在根据收集的数据或通过试错进行交互的经验自动发现原理和规律。对于电力电子应用,它分为监督学习、无监督学习和强化学习(RL)。
1)监督学习
利用由输入和输出对组成的训练数据集,监督学习的目的是隐式地建立输入和输出之间的映射和函数关系。此功能对于电力电子中系统模型难以制定的情况特别有用。一般来说,监督学习的任务包括分类和回归。对于分类,其训练数据集中的输入和输出对的输出处理要标记的有限数量的离散类别。例如,多电平逆变器的故障诊断[94]是一个典型的分类任务,需要在给定输入故障信息的情况下识别离散故障标签。对于回归任务,输入和输出对的输出由一个或多个连续变量组成。回归的一个例子是 IGBT 的 RUL 预测 [114],其中输出(即剩余使用寿命)是一个连续变量。一旦模型经过训练,就可以评估与训练数据集不同的新数据点。模型处理新数据点(即测试数据集中的数据点)的能力称为泛化。由于在大多数情况下训练数据集仅包含有限数量的可能的输入和输出对,因此其对新输入的泛化是监督学习方法最关键的性能因素之一。
一般来说,监督学习方法可以分为基于联结主义的方法(即NN方法)、概率图方法和基于记忆的方法(即核方法)。对于神经网络方法,从训练数据集中学习的知识被促进并传输为网络的连接权重和结构。许多研究致力于提高神经网络方法的性能。这些改进来自于电力电子应用的两个方面。第一个方面涉及启用神经网络处理噪声信号的不确定性能力,以提高方法的鲁棒性。通过将模糊逻辑集成到神经网络中作为模糊神经网络(FNN)或其变体(例如,自适应神经模糊推理系统(ANFIS)[101])来促进此功能。第二个方面是改进神经网络的动态性能,以处理时间序列数据集的情况,例如智能控制器、RUL 预测。与网络权重独立的传统神经网络相比,通过在不同层和网络单元之间共享权重来促进瞬态性能。权重共享可以在具有卷积结构的浅层中实现(例如,一维卷积神经网络(CNN)、延时神经网络(TDNN)[114]),也可以通过使用循环单元在全深度规模中实现作为循环神经网络[105]。一般来说,循环单元实现的建模能力优于卷积结构的建模能力。 NN 方法的更多理论细节在 [1,Ch.1] 中讨论。 5]、[13]和[14]。
概率图形方法通过使用输入和输出对的图形表示从数据中获取知识。图解表示暗示了决策变量之间的条件依赖关系。模型中的基本关系是在贝叶斯框架 [1] 中表述的,并且可以通过概率方式推断。因此,与神经网络方法相比,该模型的可解释性要好得多。此外,概率图模型在处理不确定性和不完全知识方面具有优越性。典型的概率图方法之一是贝叶斯网络[117]。概率图解方法的更多理论细节在[1,Ch.8]中给出。
概率图形方法通过使用输入和输出对的图形表示从数据中获取知识。图解表示暗示了决策变量之间的条件依赖关系。模型中的基本关系是在贝叶斯框架 [1] 中表述的,并且可以通过概率方式推断。因此,与神经网络方法相比,该模型的可解释性要好得多。此外,概率图模型在处理不确定性和不完全知识方面具有优越性。典型的概率图方法之一是贝叶斯网络[117]。概率图解方法的更多理论细节在[1,Ch.1]中给出。 8]。
因此,表二总结了电力电子领域的监督学习方法及其变体的优点、局限性和示例性应用。
表二 监督学习方法及其在电力电子领域的应用
2)无监督学习
与数据集为输入输出对的监督学习相比,无监督学习在学习过程中没有学习目标的输出数据。一般来说,电力电子应用中的无监督学习任务可以分为数据聚类和数据压缩。
与数据集为输入输出对的监督学习相比,无监督学习在学习过程中没有学习目标的输出数据。一般来说,电力电子应用中的无监督学习任务可以分为数据聚类和数据压缩。
一般来说,这些无监督学习算法在进行后续分析(例如故障诊断)之前充当数据预处理的角色。虽然此步骤是可选的,但有利于减少计算负担并提高分析准确性。表 III 总结了电力电子应用的典型无监督学习方法。更多无监督学习方法和理论细节可以在[137]中找到。
表 III 无监督学习方法及其在电力电子领域的应用
3)强化学习
与监督学习和无监督学习相比,强化学习不需要训练数据集。相反,它的目标是找到一个合适的行动策略来最大化特定任务的奖励,这本质上是一个动态编程或优化任务。这种以目标为导向的策略是通过试错过程与系统或模拟模型的交互来制定的[138]。通过这种方式,它逐步积累经验并学习最大化预定目标的特定策略。理论上,强化学习是一个马尔可夫决策过程[139]。 RL 的训练旨在开发一个关于动作选择策略的 Q 表,它可以最大化未来的总预期奖励。 Q 表是一个信息丰富的策略矩阵,记录了给定特定条件变量时要采取的最佳操作。更多 RL 的理论细节可以在 [139] 中找到。一个应用示例是 MPPT [5]、[6]、[140]。请注意,强化学习从系统之间的交互而不是现有数据集中获取经验。因此,它更适合系统知识较少或其模型难以制定的情况。
作为总结,图 5 展示了机器学习方法的使用统计数据。监督学习主要应用于电力电子领域。原因是监督学习是一种多功能工具,通常是电力电子系统中大多数机器学习相关应用的核心部分。
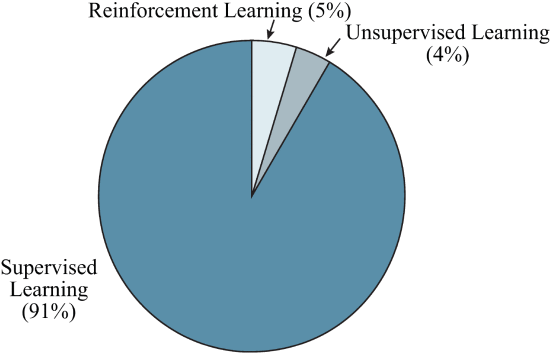
图5 电力电子系统中机器学习方法的使用统计。根据图1的数据得到统计结果。
- 电力电子相关人工智能方法和应用的时间表
图6总结了相关人工智能方法的里程碑及其在电力电子领域的应用。包括该算法首次提出的年份、首次在电力电子领域的应用、相关AI算法的里程碑以及每种方法的应用。应该指出的是,这些信息是作者所知的。此外,时间线并不长,无法涵盖所有现有的人工智能算法。相反,只包括那些在电力电子领域表现出巨大潜力的技术。根据图6,可以注意到以下内容。
- 图6总结了相关人工智能方法的里程碑及其在电力电子领域的应用。包括该算法首次提出的年份、首次在电力电子领域的应用、相关AI算法的里程碑以及每种方法的应用。应该指出的是,这些信息是作者所知的。此外,时间线并不长,无法涵盖所有现有的人工智能算法。相反,只包括那些在电力电子领域表现出巨大潜力的技术。根据图6,可以注意到以下内容。
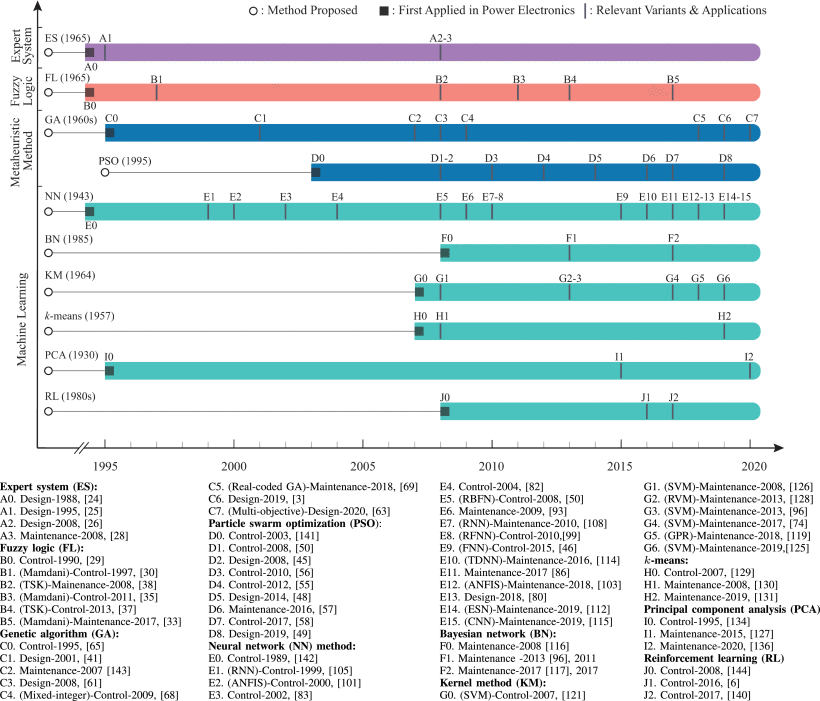
图6 相关人工智能方法及其在电力电子领域应用的时间表。考虑到重要的算法变体和相关应用,确定了里程碑。它的组织形式为(重要变体)-申请年份。特别指出了显着的变体。否则,它是标准算法。
- 相关人工智能方法及其在电力电子领域应用的时间表。考虑到重要的算法变体和相关应用,确定了里程碑。它的组织形式为(重要变体)-申请年份。特别指出了显着的变体。否则,它是标准算法。
- 相关人工智能方法及其在电力电子领域应用的时间表。考虑到重要的算法变体和相关应用,确定了里程碑。它的组织形式为(重要变体)-申请年份。特别指出了显着的变体。否则,它是标准算法。
- 核方法和概率图模型的应用呈增长趋势。这是因为这些方法大多数都是在贝叶斯框架内制定的,具有更好的泛化性和可解释性。此外,迄今为止的平台可以很好地解决它们的计算负担。
- 强化学习是应用于电力电子的机器学习方法的最新前沿,受到计算硬件快速发展的推动。
从图1和2中可以注意到以下内容。图2、图3和图6关于不同AI方法的比较。
- 元启发式方法和机器学习都可以应用于优化任务。具体来说,基于机器学习的优化(即 RL)侧重于与决策相关的动态优化(例如 MPPT)。元启发式方法通常应用于静态优化(例如散热器设计)。
- 模糊逻辑和机器学习都可以用于分类任务。一般来说,机器学习比模糊逻辑更准确、更灵活。
- 回归任务可以通过专家系统、模糊逻辑和机器学习来实现。与模糊逻辑和机器学习相比,专家系统的实现很简单,但功能较弱。模糊逻辑的实现需要专家的经验。机器学习是最流行的方法,并且已经开发了各种算法变体。它可以与模糊逻辑结合以提高性能。
- 只有机器学习才能应用于数据结构探索的任务。
以下三个部分分别讨论前面介绍的人工智能方法在电力电子系统设计、控制和维护阶段的应用。
III、设计
电力电子设计包括拓扑选择、组件尺寸、电路综合、可靠性考虑等,本质上是一项优化任务[145]。电力电子系统设计的典型过程包括以下四个步骤。
1) 目标制定:目标函数是需要最大化或最小化的理想设计目标。一般来说,电力电子器件的设计目标包括元件参数[41]、重量[146]、体积[147]、成本[146]、散热器图案[3]、面积[148]、功率损耗[62]等。对于将所需或期望的设计要求制定为几个显式数学表达式作为单个目标(如 (1) 中给出的)或多个目标(如 (2) [12] 、 [145] 中给出的)至关重要:
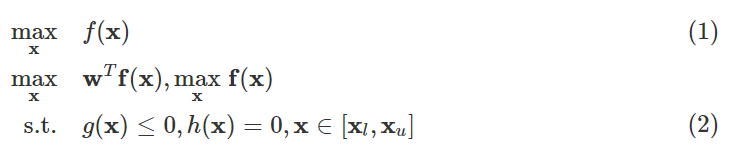
其中 g(x) 和 h(x) 分别是不平等和平等。 xl 和 xu 分别是决策变量 x 的下限和上限。这里,最大化是目标,可以简单地应用于最小化情况。请注意,对于 (2) 中的多个目标,可以通过将多个目标加权在一起来最大化标量函数 wTf(x) 来解决,也可以通过直接优化目标向量 f(x) 来解决,其中帕累托前沿[62 ]可用于确定最优解,例如[60]中用于功率模块多目标设计优化的非支配排序GA方法。
2)约束空间:约束空间定义了目标函数所受到的可行空间、边界、关系和限制。这些约束包括线性或非线性等式和不等式。它们源自实际设计要求,例如几何形状、体积、寿命特性、成本等。
3)约束空间:约束空间定义了目标函数所受到的可行空间、边界、关系和限制。这些约束包括线性或非线性等式和不等式。它们源自实际设计要求,例如几何形状、体积、寿命特性、成本等。
4)性能评估:可以通过仿真、硬件在环测试、原型实验等针对预定义目标对候选解决方案进行测试。结果可以返回到之前的步骤,以进一步进行性能改进和优化。
设计任务不是一个连续的过程,而是一个迭代的试错过程。基于每个步骤的评估,可以重新制定任务,例如调整目标、修改约束空间、重新配置编程方法等。对于电力电子领域的传统设计来说,这非常耗时并且需要多个迭代步骤。例如,组件对齐和模型选择依赖于专家经验和直觉,没有足够的定量参考。这样,设计性能就会慢慢收敛到要求的标准。这个缺点可以通过人工智能方法来缓解。它们可应用于 1) 减少设计时间的目标制定,以及 3) 建模和优化的解决方案探索。
A. 减少设计时间
作为可靠性设计(DfR)的应用,在[80]中,两个前馈神经网络(FFNN)被应用于电力电子系统的自动化可靠性设计。第一个 FFNN 作为模拟功率转换器热特性的代理模型,通过该模型可以将设计参数映射到结温变化信息。随后,应用第二个 FFNN 将年度任务概况(例如年度太阳辐射和环境温度)映射到年度寿命消耗。通过这种方式,定量表征了设计参数与年寿命消耗之间的非线性关系,可以加速迭代设计过程。
[109] 中给出了电力电子系统 DfR 人工智能的另一个例子。具有处理时间序列数据的卓越能力,具有外源输入的非线性自回归网络(NARX)被应用于考虑热交叉耦合效应的电力电子系统的热建模。所提出的基于 NARX 的热模型可以在大约 109 秒内完成,与传统模型的 1005 秒相比,这是一个显着的效率提升。基于 NARX 的热模型估算的温度与实际测量之间的误差小于 1 ∘C 。实验结果表明,基于 NARX 的热模型可以取代传统模型,测试工作量更少,计算负担也更少。
在[79]中,考虑到电热相互作用,应用FFNN来构建MOSFET的组件行为模型,而无需对器件结构有任何深入的了解。在静态下,变量之间存在复杂的非线性和温度相关特性,包括漏源电压 VDS 、栅源电压 VGS 、结温 Tj和输出电流 ID 是通过使用神经网络建立的。这种紧凑的模型可以以相当的精度极大地加速设计仿真过程。
B. 建模和优化
电力电子系统的建模和优化是指指定电路拓扑、元件模型、元件参数等,使系统尺寸、重量、工作频率等得到最佳特性(例如功率损耗、功率密度)给定设计约束[12]。具体来说,优化方法应用于解决方案探索,以提供整体最优配置,其中可以利用人工智能中的元启发式方法。如前所述,合适的元启发式方法的选择取决于具体应用。下面给出几个示例性应用。
在[3]中,遗传算法与有限元分析相结合,用于 50 kW 三相逆变器的自动散热器设计。如图7所示,应用遗传算法优化九种定制图案的组合,以制定散热器的复杂单元图案。目标是最大限度地降低功率半导体器件的结温。与具有规则单元图案的传统设计相比,所提出的方法制定的散热器解决方案的尺寸减小了27%,结温降低了6%。
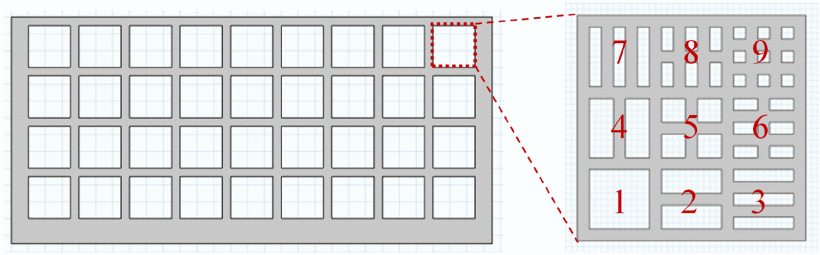
图7 每个空白单元格有九种不同的单元格模式 [3]。应用遗传算法来确定散热器设计的不同单元图案的最佳组合,以最大限度地降低结温。
在[62]中,基于500千瓦太阳能的微电网系统的设计被表述为多目标优化任务,它最大化平均功率分布并同时最小化系统重量。它探索了四个微电网参数的最佳值,包括电池电压、光伏最大功率、光伏最大功率点电压和每串电池板数量。将遗传算法与Pareto前沿相结合来解决多目标优化任务。此外,针对多目标优化任务,还有一种专门改进的 GA 变体,即非支配排序 GA II (NSGA-II) [63]。
在[45]中,PSO被应用于电力电子电路的电路综合,其中探索元件的最佳值以实现更好的静态和动态性能的设计目标。对于这种特定情况,模拟表明,与 GA 相比,PSO 可以用更少的计算工作量产生更好的解决方案。
在[70]中,ACO被用来确定电力电子电路中的最佳元件值,其中传统的ACO被扩展以促进连续元件值的优化并加速优化过程。此外,将元件公差纳入优化中,这使得所提出的方法更有利于实际应用。
IV、控制
本质上,人工智能方法在电力电子系统中的控制应用可以分为优化和回归。与设计阶段的优化类似,控制应用中与优化相关的任务也在处理元启发式方法。前面给出了几个有代表性的应用。
在[64]中,遗传算法被应用于编程逻辑控制器的PID调节,其中优化目标是最小化理想阶跃响应和斜坡响应与使用比例项 Kp 初始化的响应之间的误差,积分术语 KI 和衍生术语 KD 由 GA 找到。实验分析表明,优化控制器的输出性能非常接近理想的阶跃和斜坡响应。
在[64]中,遗传算法被应用于编程逻辑控制器的PID调节,其中优化目标是最小化理想阶跃响应和斜坡响应与使用比例项 Kp 初始化的响应之间的误差,积分术语 KI 和衍生术语 KD 由 GA 找到。实验分析表明,优化控制器的输出性能非常接近理想的阶跃和斜坡响应。
在[42]中,为了克服光伏系统在部分阴影情况下多个最大功率点的挑战,提出了一种基于ACO的MPPT方法。与恒压跟踪、扰动观察、粒子群算法等传统方法进行了比较。实验结果表明,基于ACO的MPPT方法在全局收敛性和对各种着色模式的鲁棒性方面具有优越性。
在[47]中,在单相全桥逆变器中,应用IA来寻找四个开关的最佳正弦脉宽调制(PWM)控制序列,从而最小化输出波形的总谐波失真(THD)。实验表明,采用IA方案的THD为0.79%,优于传统滞环电流PWM控制方法的1.23%和GA方案的0.99%。此外,IA在收敛速度上优于GA。与优化相关的控制应用的更多示例可以在[12]中找到。
控制应用中与回归相关的任务是以静态或动态方式处理系统输入和输出的非线性映射。具体来说,它涉及调节系统以确保系统原则的预期性能输出。传统方法的一些局限性已被确定,如下所示。
- 控制应用中与回归相关的任务是以静态或动态方式处理系统输入和输出的非线性映射。具体来说,它涉及调节系统以确保系统原则的预期性能输出。传统方法的一些局限性已被确定,如下所示。
- 一旦控制器安装完毕,它就会以静态方式运行,适应性有限,这表明它只适用于时不变系统。然而,当环境和操作条件发生变化时,控制器对系统参数变化的鲁棒性较差,控制性能可能会恶化。
- 从有效控制的角度来看,理想的控制器必须能够以快速瞬态响应来应对参数容差,以保持系统稳定性。然而,这种期望的特征并不能很好地实现。
这些限制可以通过人工智能方法来缓解。对于控制应用中与回归相关的任务,它是按照模糊逻辑、神经网络和强化学习来组织的。
A. 基于模糊逻辑的控制器
基于模糊逻辑的方法已广泛应用于电力电子系统的控制,例如速度控制[30]、MPPT[35]、能量管理[149]等。
在[30]中,为变速风力发电系统开发了具有三个模糊逻辑控制器的控制策略。发电机速度编程控制器的结构如图8所示。控制变量包括输出功率的增量 ΔPo 和速度的最后变化 LΔw∗r 。控制器输出速度变化 Δw∗r 来调节发电机速度以获得最大风力输出。应用 Mamdani 型模糊逻辑并根据规则矩阵表聚合信息,例如“IF ΔPo 是 PS AND LΔw∗r 是 ZE,那么 Δw∗r 是下午。”通过系统仿真和实验迭代调整隶属函数。类似的用于风电场一次频率调节的 Mamdani 型模糊逻辑控制器可以在[34]中找到。
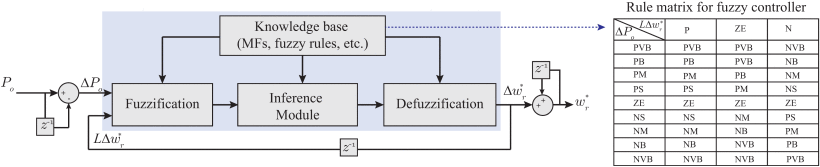
图8 用于变速风力发电系统的基于模糊逻辑的控制器[30]。 MF:会员功能。规则矩阵表中: P:正; V:非常;非常; B:大; M:中等; ZE:零;N:负。
在[36]中,提出了一种模糊逻辑控制器,用于通过逼近理想控制律来调节基于TSK模糊逻辑的开关磁阻电机的速度。利用李亚普诺夫稳定性定理对参数进行整定,保证系统稳定性。实验分析表明,所开发的自适应TSK型控制器优于传统的模糊逻辑控制器和PI控制器。类似的 TSK 型控制器可以在 [31] 中找到,用于逼近集成 LED 驱动器的典型滑模控制曲线。它计算效率高,并且在低成本平台上实现。
尽管模糊逻辑控制器可以处理系统的不确定性,但与PID等传统方法类似,没有内部更新机制,因此适应性有限[50]。同时可以看出,隶属函数和模糊规则的设计需要专家经验,这极大地限制了方法的实用性。因此,这种方法在大多数情况下仅适用于专家。然而,从这个角度来看,专家经验可以用模糊逻辑来应对,然后与其他人工智能技术作为混合方法结合起来,如下文所述。
B. 基于神经网络的控制器
作为一种黑盒技术,神经网络可以以任意精度逼近各种非线性函数。基于神经网络的控制器对系统知识要求低,具有鲁棒性、无模型、动态、自适应、万能逼近等优点。
1)传统神经网络
电力电子中使用最广泛的神经网络是具有前馈多层和反向传播拓扑的 FFNN(或反向传播神经网络)[14]。各自的应用本质上利用了 FFNN 静态非线性映射的特性。
在[82]中,FFNN被应用于波形处理和无延迟滤波。通过变频率和变幅度两种情况,表明FFNN可以将任意形状的 m 相波形转换为具有各种幅度和频率特征的 n 相波形。基于FFNN的波形处理方法简化了硬件实现。此外,由于结构灵活性,可以轻松嵌入附加的单一处理功能。
在[83]中,三电平电压馈送逆变器的空间矢量PWM(SVPWM)是用FFNN实现的。神经网络的输入是采样的命令相电压,输出是 SVPWM 的脉宽模式。训练数据是通过 SVPWM 算法模拟生成的。通过与传统的基于数字信号处理器(DSP)的SVPWM解决方案进行比较,验证了基于FFNN的SVPWM的性能,并且可以在专用IC芯片上灵活地实现。
除了FFNN之外,另一种传统的神经网络结构是径向基函数网络(RBFN)。在FFNN中,输入到隐藏和隐藏到输出的权重是同时确定的。对于 RBFN,输入层直接且完全连接到隐藏层,没有权重。隐藏层通过权重 Wj 连接到输出层,这是训练中唯一需要确定的权重参数,如图 9 所示。通常,RBFN 的泛化能力比 FFNN 更好,并且训练速度和执行速度更快。 RBFN 在三相感应发电机中调节直流母线电压和交流线路电压的示例性应用可以在[50]中找到。
关于神经元的数量,确定最佳数量的原则很少。通用的方法是从相对较少数量的神经元开始,然后根据训练误差逐渐增加。对于隐藏层的激活函数,有多种选择,包括 sigmoid [4] 、 [51] 、 [52] 、 [83] 、径向基函数 [50] 、 [150] 、双曲正切函数 [106] 、 [151]、小波[46]、[53]、[84]、[152]等。值得一提的是,小波激活函数具有优越的收敛速度和泛化能力。
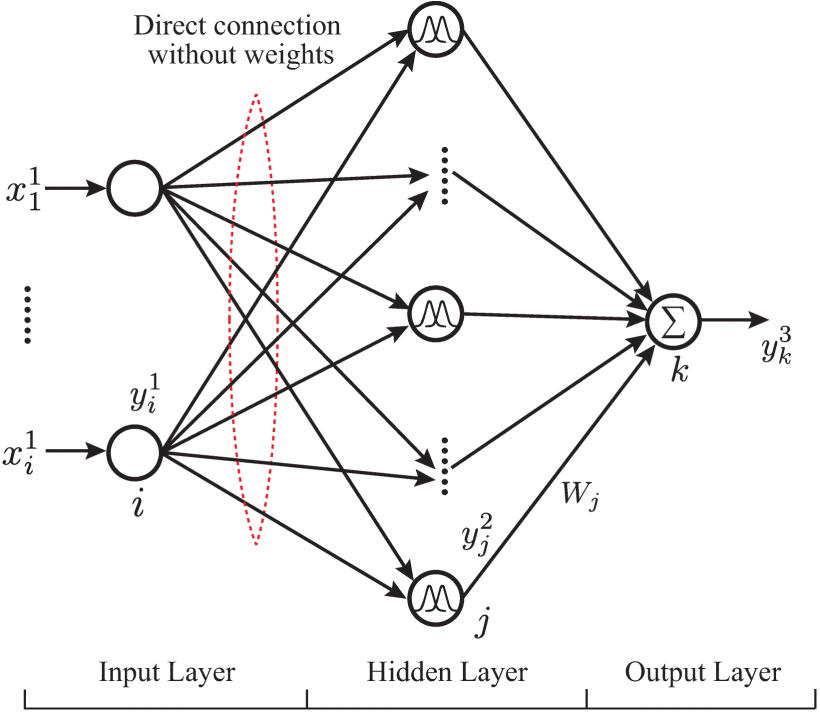
图9 三层 RBFN 的结构 [50]。 x1i 是输入层节点 i 的输入, y1i 是其输出。 y2j 是隐藏层节点 j 的输出。 y3k 是输出层节点 k 的输出。输入层和隐藏层完全直接连接,没有权重。
尽管模糊逻辑控制器可以处理系统的不确定性,但与PID等传统方法类似,没有内部更新机制,因此适应性有限[50]。同时可以看出,隶属函数和模糊规则的设计需要专家经验,这极大地限制了方法的实用性。因此,这种方法在大多数情况下仅适用于专家。然而,从这个角度来看,专家经验可以用模糊逻辑来应对,然后与其他人工智能技术作为混合方法结合起来,如下文所述。
2) 模糊逻辑神经网络
在控制应用中,为了系统的稳定性和鲁棒性,应充分考虑参数的不确定性和外部干扰。因此,提出了神经网络的改进变体,即 FNN 或神经模糊系统,它是神经网络和模糊逻辑的混合。 FNN具有两方面的优点[100],即融合了专家知识和认知不确定性的模糊逻辑的类人IF-THEN推理规则,以及神经网络对任何非线性系统的强大逼近和泛化能力。 FNN 的更多理论细节可以在[39]中找到。
在[100]中,应用FNN来模拟升压转换器的滑模控制,以减轻抖振现象。控制器框图如图10(a)所示,四层FNN结构如图10(b)所示。 FNN 的输入包括滑动表面 S(t) 及其微分 S˙(t) ,它们是基于跟踪平均输出电压 ev 和电感器电流 的误差而获得的 ei ,给定参考电压 Vref 和电流 iref 。输出控制信号为PWM的占空比 u 。模糊推理由规则层实现为 lk=∏ni=1wkjiμji(xi) 。网络输出为 u=f(∑Nyk=1wklk) 。对于电压控制,电压跟踪性能通过输出电压的均方误差(MSE)来评估

其中 T 是采样时刻。网络调整的目的是尽可能降低MSE,以输出准确稳定的电压。如果隶属函数设计得当,FNN 的性能可以得到显着提高。例如,在[46]中,将不对称隶属函数应用于六相永磁同步电机的控制器。这表明与传统的隶属函数(例如高斯函数[71]、[99]、[100]相比)可以提高学习速度并且可以简化网络结构。
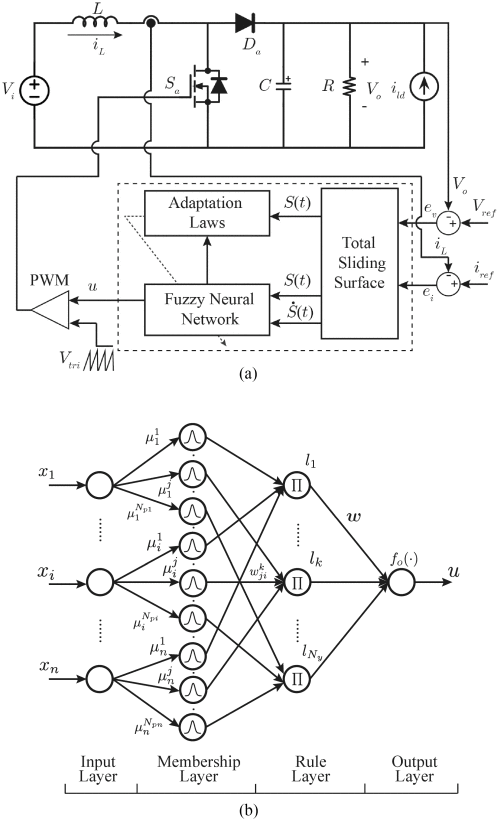
图10 用于升压转换器的基于 FNN 的控制器 [100]。 x1 是滑动面 S(x) 和 x2 是它的微分, n=2 。 μji 是输入 xi 的 jth 隶属函数。 w 是层与层之间的权重。 (a) 用于升压转换器的基于 FNN 的控制器的框图。 (b) 四层结构的 FNN。
FNN 的挑战之一是模糊规则的设计,通常需要丰富的专家经验[100]。为了克服这一挑战,另一个典型且有效的结合模糊逻辑和神经网络的框架是ANFIS,它可以从图10中的四层结构扩展为五层拓扑[101],如图11所示。在ANFIS中,需要专家参与的IF-THEN模糊规则可以在训练中自动生成。例如,在[101]中,针对基于ANFIS的PWM逆变器馈电感应电机驱动器开发了直接扭矩神经模糊控制方案。如图11所示,基于ANFIS的控制器的输入包括磁通误差 εm 和扭矩误差 εΨ 。第 1 层是成员资格层,输入权重为 wm 和 wΨ 。第 2 层从输入中选择最小值。归一化在第 3 层中执行。在第 4 层中,输出 oi 与网络输入 ud=(εm,εΨ) 线性组合。第 5 层是极坐标 Vc 和 φVc 中的定子电压命令向量的网络输出。 Δγi 是增量角度, γs 是定子磁通矢量的实际角度。与传统的训练方案相比,ANFIS 的参数调整是通过反向传播算法(对于隶属函数)和最小二乘法(对于 fourth 层中的参数)交互完成的。 ANFIS 训练方法的更多理论细节可以在[153]中找到。
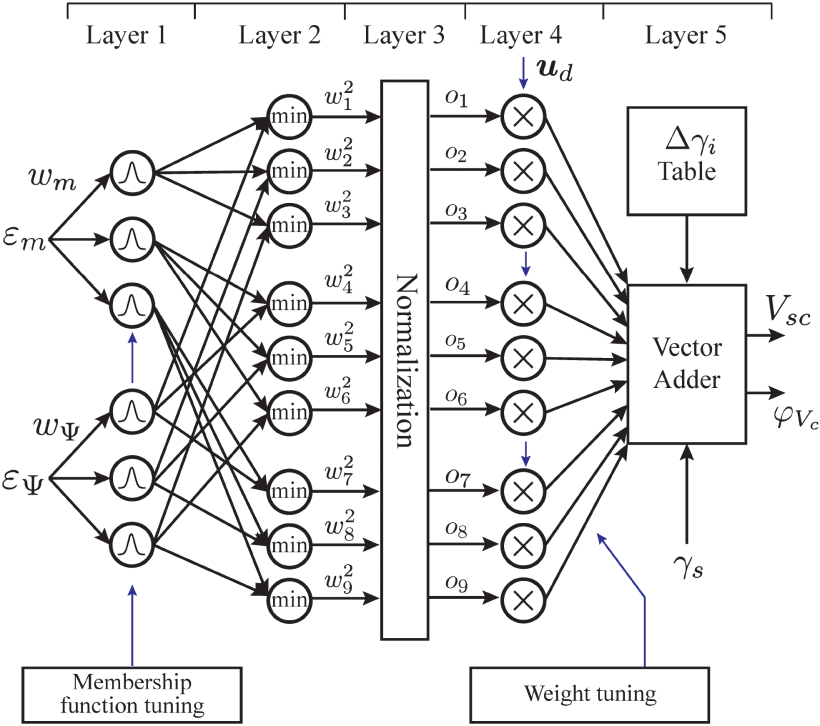
图11 用于 PWM 逆变器馈电感应电机驱动的基于 ANFIS 的控制器 [101]。它是一个五层网络结构,具有自动识别模糊规则的能力。
3)具有循环单元的神经网络
然而,第 IV-B1 节中的 NN 结构和第 IV-B2 节中的 FNN 结构仅适用于静态关系映射和行为表征。控制器的动态性能对于瞬态响应至关重要。为了实现神经网络控制器的动态能力,通常插入时滞反馈连接 Z−1 的存储单元来制定循环神经网络(RNN)[107],如图12所示。网络的输出不仅取决于当前的输入,还取决于之前的输入。因此,该网络结构可以处理时间序列数据,从而有利于更好地表现动态性和灵敏度。
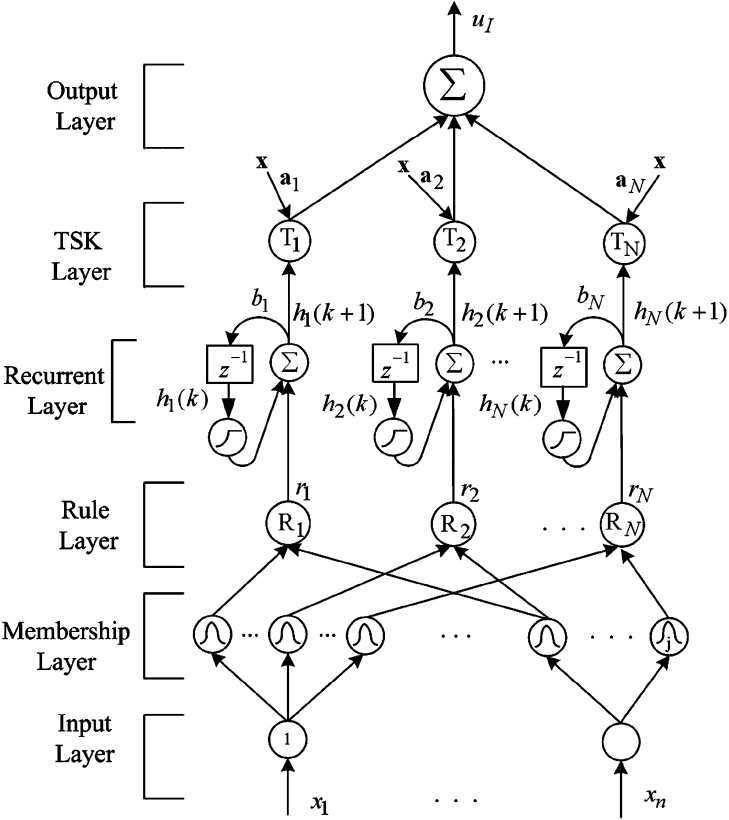
图12 RFNN控制器用于线性微步进电机驱动器的高精度轨迹跟踪控制[99]。添加延时反馈连接 Z−1 的存储单元,以实现神经网络控制器的动态能力。
在[106]中,针对单相并网变流器提出了一种基于RNN的鲁棒控制器,以便在系统参数变化的情况下获得更好的控制性能。 RNN的训练是通过Levenberg-Marquardt(LM)方法完成的[13],[82],[106]。通过使用所提出的基于 RNN 的控制器可以显着减少谐波,并且可以减轻对传统控制方法的高采样和开关频率以及阻尼策略的要求。类似的 RNN 结构,也称为 Elman NN (ENN),可以在 [52] 中找到。
除了动力学性能外,RNN中还融入了模糊逻辑,以提高鲁棒性的性能。例如,在[99]中,提出了一种基于TSK型自组织循环FNN(RFNN)的控制器,用于线性微步进电机驱动器的高精度轨迹跟踪控制。网络结构如图12所示。 TSK 型自组织 RFNN 用于对驾驶员的逆动态进行建模。与图 10(b) 中的 FNN 相比,RFNN 的关键是插入循环层,其中延迟神经元输出 hi(k) 作为神经元输入返回,以促进网络动态。采用自组织方法调整网络图和大小,并采用递归最小二乘法调整各网络参数。因此,可以同时优化网络图及其参数。
4)神经网络的训练方法
本质上,神经网络的训练是一项优化任务。当然,也可以用传统的优化方法来完成,例如PSO[51]、递归最小二乘法[99]、卡尔曼滤波器[105]等。考虑到神经网络中的大量参数,这些传统的优化方法一般是效率低下。因此,开发了一种精心设计的训练方案,即反向传播算法 [4] 、 [50] 、 [52] 、 [53] 、 [71] 、 [83] 、 [84] 、 [150] 。反向传播算法的更多理论细节可以在 [1,Ch. 5]。
反向传播算法基于最速梯度下降的思想。反向传播算法的关键步骤之一是权重更新的迭代

其中 wk 是当前权重, gk 是当前梯度, ηk 是学习率, wk+1 是下一次迭代的权重。为了有效地计算梯度 gk 并找到梯度下降的最陡方向,人们提出了反向传播算法的各种改进变体,例如LM方法[13],[82],[106],弹性反向传播算法、共轭梯度算法、一步割线算法等。请注意,为特定任务确定最合适的训练算法是具有挑战性的。它取决于多种因素,包括问题复杂性、数据集大小、参数数量、分类或回归的任务类型等。有用的参考可以在 MATLAB Manual of Neural Network Toolbox [40] 中找到,其中理论细节、优点、局限性以及这些训练算法的比较通过几个基准示例进行了彻底分析。值得一提的是,LM方法是电力电子领域应用最广泛的方法之一,具有收敛速度快、精度高等特点。
考虑到训练数据集是批量形式还是顺序形式,神经网络的训练方案可以通过批量学习(也称为离线学习)或顺序学习(也称为在线学习)来完成或增量学习。
考虑到训练数据集是批量形式还是顺序形式,神经网络的训练方案可以通过批量学习(也称为离线学习)或顺序学习(也称为在线学习)来完成或增量学习。
对于顺序学习,(4) 中的梯度 gk 是基于每个新可用的数据点或形成小批量的几个新可用的数据点来计算的。因此,学习过程是逐步完成的。该功能对于现场应用中只能顺序获取训练数据的情况特别有用。智能控制器[53]是顺序训练方案的典型案例,因为神经网络的输入数据只能通过与控制命令和系统的输出交互来顺序获得。借助这种自适应功能,可以对神经网络进行重新参数化和重新配置,以跟踪系统参数变化。顺序学习的关键步骤之一是确定(4)中合适的学习率 ηk ,因为较大的 ηk 会导致系统不稳定,较小的 ηk 会导致系统不稳定。导致收敛缓慢。最佳学习率 ηk 可以通过在训练中使用元启发式方法来确定,例如[50]、[52]和[53]中的PSO以及[46]中的差分进化(DE)。因此,顺序学习过程可以稳定且快速收敛。
C. 基于 RL 的控制器
通过强化学习,控制器通过与物理系统或其仿真模型交互来学习面向目标的控制策略[138]。它逐步积累经验并学习最大化预定义目标的特定控制策略。
基于 RL 的控制器的相关应用之一是可再生能源系统中的 MPPT [5],如图 13 所示。具体而言,针对风能转换系统提出了一种使用 RL 的实时智能 MPPT 算法。利用强化学习与环境交互的在线学习能力,在 Q 表中制定最优控制策略。 Q 表由状态转换概率 q(st,at) 的元素组成,在给定当前系统状态st(包括当前电输出功率Pe和发电机转子转速wr)的情况下,如果在预期发电机转子转速w * r处进行动作,则可以促进最大功率输出(或奖励)。一个亮点是,不需要风力涡轮机参数和风速。本文通过将 NN 集成到 RL 的 Q 学习中来进一步扩展 [6]。这样,就避免了确定状态空间的挑战。一旦学习到的最佳关系被系统老化行为破坏,就可以重新激活在线学习过程。显着提高了风能转换系统的自主能力。类似的例子可以在[140]中找到,其中RL应用于光伏阵列降压转换器的MPPT控制。
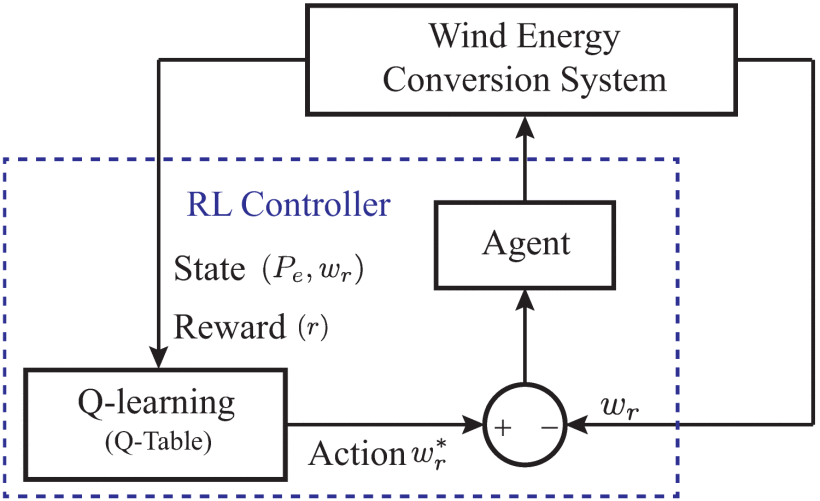
图13 风能转换系统MPPT控制器中的RL框架[5],[138]。 Q 表的制定是为了保存在给定当前系统状态 st 的情况下要执行的最佳发电机转子速度 w∗r ,包括当前电力输出功率 Pe 和发电机转子速度 wr 。
风能转换系统MPPT控制器中的RL框架[5],[138]。 Q 表的制定是为了保存在给定当前系统状态 st 的情况下要执行的最佳发电机转子速度 w∗r ,包括当前电力输出功率 Pe 和发电机转子速度 wr 。
D、讨论
表 IV 总结了人工智能算法在控制应用中的优点和局限性。值得一提的是,AI算法的动态性能、鲁棒性、泛化性和收敛速度在控制应用中至关重要。算法复杂性和计算负担是主要挑战。因此,高性能DSP或现场可编程门阵列对于实际实现是必要的。
表 IV 人工智能算法在控制应用中的优点和局限性
V、维护
尽管在设计和控制中充分考虑了可靠性特性,但电力电子系统仍然由于复杂和恶劣的工作环境而承受各种风险甚至灾难性故障[18],[154],[155]。电力电子元件、转换器和系统的可靠性和安全性对于现场应用非常重要。在维护中,预防性活动,包括状态监测、异常检测、故障诊断、RUL预测等,是确保预期功能正确执行的有效方法。这些活动与电子系统 PHM 的 IEEE 标准框架保持一致 [156]。图 14 展示了电力电子系统维护活动的系统流程图。一般由以下三部分组成。
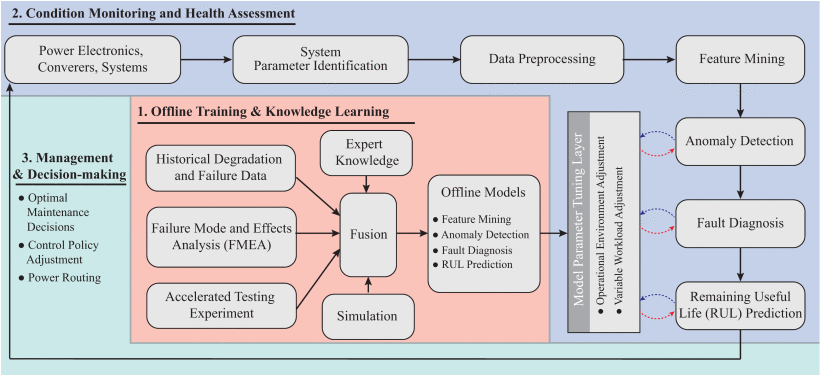
图14 电力电子系统维护流程图。
1)离线培训和知识学习:集成了历史监测数据、仿真数据、加速老化测试实验、失效模式和影响分析等各方面的知识。此外,这部分通常采用集成方法或融合技术来提高性能。因此,物理系统动力学和行为(例如退化行为)可以根据单位总体的信息准确地表征为离线模型。
2)状态监测和健康评估:这部分涉及现场应用中在线状态监测的在用设备的健康评估。离线模型通过模型参数调整层,通过适应现场操作环境和工作量,针对使用中的单元进行定制和个性化。功能包括无创参数识别、数据预处理(例如数据清洗)、特征挖掘、异常检测、故障诊断和RUL预测。通过这种方式,可以从连续的状态监测信息中提取有洞察力的决策知识。
3)管理与决策:在这一部分中,返回健康评估的支持知识以做出最佳决策。通过此反馈,可以调整控制策略(例如电源路由),以在给定实时健康状态的情况下最大限度地提高系统性能。此外,可以制定经济的维护策略,以促进基于状态和预测的维护。
随后,从这三个部分详细讨论了人工智能在维护中的相关应用。
A. 状态监测
电力电子中的状态监测[20]、[157]、[158]包括系统参数识别、数据预处理和特征挖掘。状态监测信息用于发现隐藏的、信息丰富的见解,作为后续 PHM 应用的基础。
1)系统参数识别
系统参数识别[159]处理关键组件的信息获取。然而,由于电力电子系统的特点,例如功率模块中的空间非常狭小、开关频率非常快,开发用于参数识别的特定硬件(例如 IGBT 的温度敏感电气参数[158])是一项相当具有挑战性的任务。 ,相对不显着的参数变化在老化方面[157]等。有前途的解决方案之一是无创方法,无需任何额外的硬件实现,其中可以从可用的物理信号间接推断或估计感兴趣的信息。因此,可以通过无传感器且经济高效的解决方案来实现状态监测,这对工业从业者来说是有利的。一般来说,考虑是否需要系统动力学和模型,系统参数识别可以分为无模型方法和基于模型的方法。
对于无模型方法,不需要系统动力学的先验知识。本质上,它涉及人工智能算法的回归能力,以构建输入和输出之间的关系。例如,在三相前端二极管桥电机驱动中, a 相中的电流 ia,out 和直流母线纹波电压 Δvdc 被视为输入,电容 C 用作 FFNN [86] – [88] 训练的输出。这样,就建立了输入信号与电容之间的关系,从而可以间接推断出电容。类似地,证明了可以通过由直流母线电压纹波的频域信息构建的FFNN来估计电容。 FFNN 在电容估计中的潜力在硬件原型中得到了说明 [88]。
文献[108]考虑到RNN的动态能力,提出了一种基于RNN的阻抗识别方法,以实现电力电子系统在宽频率范围内的稳定性分析。 RNN 用于构建一个模型,该模型可以在给定相同输入的情况下产生与物理系统相同的输出。 RNN 的输入包括三相电压 va,vb,vc 。输出是 a 相电流 ia 。因此,基于 RNN 的模型具有与物理模型相同的频率特性。可以在不中断系统运行的情况下进行阻抗识别。
在[103]中,应用改进的ANFIS来估计超级电容器的电容和等效串联电阻(ESR)。在监控时间 t ,ANFIS的输入包括电源电压 Vt ,超级电容器温度 θt ,以及由前五个组成的时间序列 ESRt−400:100:t ESR 数据点。 AFIS 的输出是未来 p 步骤中的 ESR 估计。实验分析表明,在2600 h的状态监测时间下,可以准确估计超级电容器的ESR,且ESR估计的归一化均方根误差小至0.025。
图 15 给出了无模型参数识别方法的框架摘要。可以看出,AI 方法充当了可用输入信号和要监控的参数之间的回归工具 f(⋅) 。
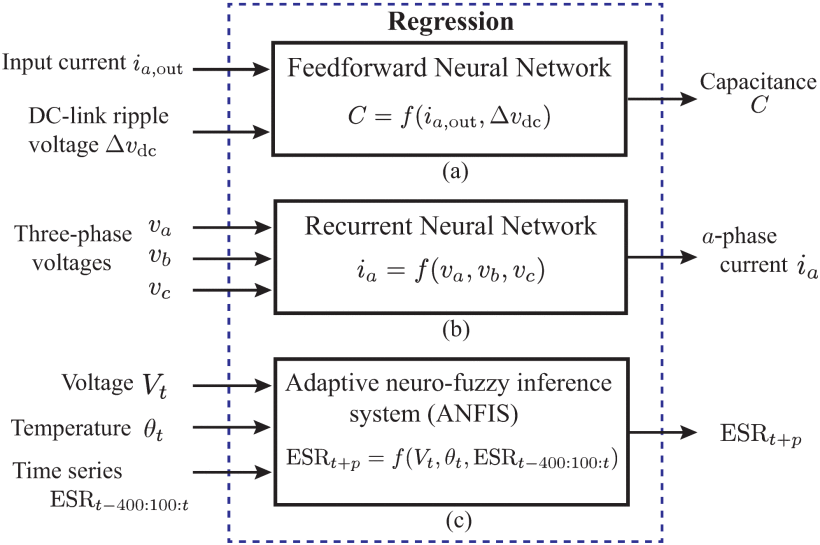
图15 利用人工智能进行系统参数识别的无模型方法示例。 (a) 直流母线电容器的电容识别[88]。 (b) a -用于计算电力电子系统阻抗测量的相电流估计[108]。 (c) 超级电容器未来 p 步骤的 ESR 估计 [103] 。
利用人工智能进行系统参数识别的无模型方法示例。 (a) 直流母线电容器的电容识别[88]。 (b) a -用于计算电力电子系统阻抗测量的相电流估计[108]。 (c) 超级电容器未来 p 步骤的 ESR 估计 [103] 。
系统参数识别的另一类是基于模型的方法。顾名思义,对于基于模型的方法,系统物理和模型是预先部分已知的,并且识别模型是用未知的模型参数制定的。这样,系统辨识任务就相当于模型最优参数的探索,本质上是一个优化任务。在这种情况下,人工智能,尤其是元启发式方法,被用作优化器来寻找最佳解决方案。可以利用许多方法,例如 PSO [57]、乌鸦搜索算法 [73]、GA [69] 等或其改进的变体。
在[69]中,开发了一种用于光伏电池板健康诊断的参数识别方法。光伏电池板的等效电路如图 16 所示,其系统模型明确导出为
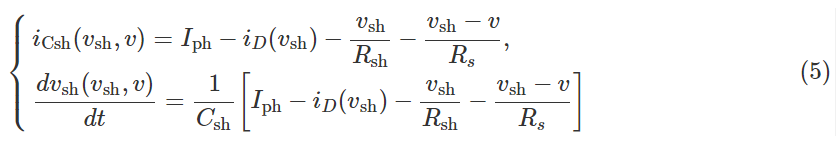
其中 Iph 是输入电流, Io 是输出电流, vsh 是两端的电压电容 Csh 、 Rsh 是电阻, Csh 是p-n结电容。因此,参数识别相当于找到一个参数集 G={Iph,Io,vsh,Rsh,Csh,Rs} ,保证与物理系统的输出相同。通过在测试阶段向电池板电压注入大信号干扰,对电流-电压特性的动态响应进行采样,计算出目标函数为
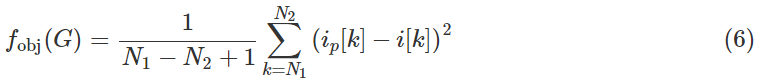
其中 ip[k] 和 i[k] 是模型的当前输出和物理系统, N1 和 N2 分别是采样的开始索引和结束索引。随后,使用改进的遗传算法来探索最小化(6)中 fobj(G) 的最优解。 类似的研究可以在[57]中找到,其中将改进的PSO算法应用于光伏电池板的内部参数识别。
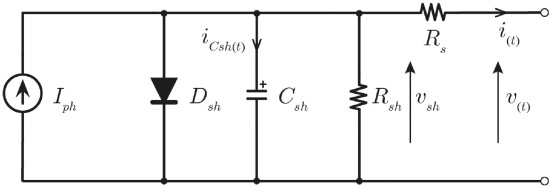
图16 使用基于模型的方法进行参数识别的光伏电池板动态模型[69]。系统参数包括输入电流 Iph 、输出电流 Io ( i(t) )、电容 Csh 两端电压 vsh 、电阻 Rsh ,p-n结电容 Csh ,和电阻 Rs 。
使用基于模型的方法进行参数识别的光伏电池板动态模型[69]。系统参数包括输入电流 Iph 、输出电流 Io ( i(t) )、电容 Csh 两端电压 vsh 、电阻 Rsh ,p-n结电容 Csh ,和电阻 Rs 。
电力电子中的参数识别方法需要考虑复杂环境下的准确性和鲁棒性。例如,对于[131]中功率MOSFET的状态监测,如果漏源通态电阻RDS(on)的退化指标增加0.08 Ω ,则该器件被视为失效 。如此微小的增量很难观察到。因此,需要更多的研究工作来提高基于人工智能的参数识别方法的灵敏度。此外,值得一提的是,现场应用应考虑计算负担和嵌入式功能。
2)数据预处理和特征挖掘
数据预处理和特征挖掘涉及提炼原始数据以更好地服务于应用程序,例如故障诊断。通过探索数据集结构,它包括用于减少噪声的数据清理、用于发现相似数据点组的数据聚类、用于识别数据分布的密度估计、用于将高维数据投影到低维数据以减少数据数量的数据压缩。通常,如果数据预处理和特征挖掘得当,可以显着提高后续PHM应用的性能,例如诊断准确性。
文献[131]提出了一种基于连续时间马尔可夫链的功率MOSFET可靠性评估方法。为了在不破坏固有单调性的情况下离散化功率 MOSFET 的连续退化路径,采用 k -means 方法将漏极至源极通态电阻 RDS(ON) 的演变划分为 11 个离散值状态,如图17所示。
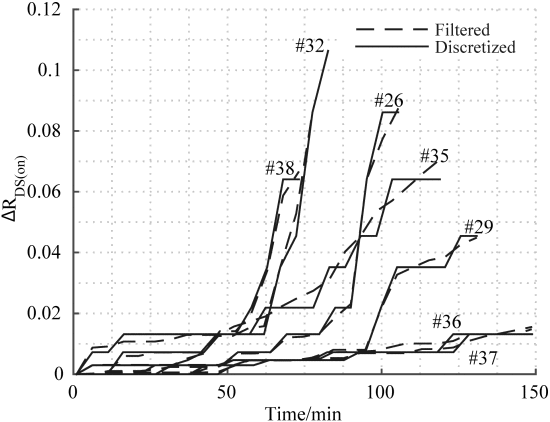
图17 k - 表示不同功率MOSFET器件#26、#29、#32、#35的漏源通态电阻 ΔRDS(on) 增量的过滤退化路径离散化的聚类方法,#36,#37,#38 [131]。
文献[133]提出了一种基于自组织映射(SOM)的IGBT健康状态识别方法。它本质上是一个聚类任务。考虑到输入测量之间的距离(包括集电极电流 Ic 、集电极-发射极电压 Vce,和外壳温度 T )以及经过训练的 SOM 的最佳匹配单元,设备的状态分为健康状态、部分退化状态、严重退化状态和故障状态。
在[160]中,利用遗传编程的数据融合技术(遗传编程的一种变体)开发了 SiC MOSFET 的复合失效前兆。它以非线性方式集成功率半导体器件的多个退化信号。由于复合材料失效前兆直接根据RUL预测模型进行优化,预测精度提高了35.3%,预测不确定性降低了16.3%。它表明状态监测中的数据融合可能很有用,特别是对于存在多个物理退化信号的系统级应用(例如转换器)。
MATLAB[161]中提供了用于特征识别的集成工具箱“诊断特征设计器”,它可以作为自动工具应用于数据预处理和特征挖掘。
B. 异常检测和故障诊断
异常检测采用二元决策,重点关注异常行为识别。当额定系统特性或标称参数超出预定义的安全范围时,它会提供指示。一旦异常行为发生,故障诊断[19]随后识别并定位详细的故障模式。本质上,异常检测和故障诊断是分类、回归或聚类任务。根据训练阶段学到的关系,当新的故障签名可用时,它确定故障标签。需要注意的是,基于人工智能的异常检测和故障诊断的可行性基于两个假设[33]:首先,任何组件的故障发生都会对故障特征产生影响;其次,对这些特征的影响因不同的故障模式和故障位置而异。异常检测和故障诊断的方法可以分为监督学习方法和无监督学习方法。
1)监督学习方法
在[93]中,应用FFNN来建立全桥二极管整流器的输入和输出的非线性关系。 FFNN的训练是在整流器的正常工作模式下完成的,如图18所示。这样就得到了输入的原理和映射关系,包括输入电压 vi(t) ,输入电流 ii(t) ,输出电流 io(t) ,以及输出电压vo(t)的输出信号 具有特征,被认为是指示整流器正常工作模式的数字仿真器。该数字仿真器和物理整流器同时运行,并实时比较它们的输出。一旦监测到的物理整流器的输出电压与FFNN的输出显着偏离,则表明整流器进入异常模式,有利于异常检测。在这种情况下,FFNN 本质上充当回归工具。
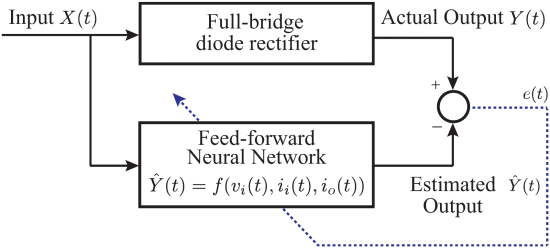
图18 用于全桥二极管整流器异常检测的 FFNN。神经网络的输入包括输入电压 vi(t) 、输入电流 ii(t) 和输出电流 io(t) ;神经网络的输出是输出电压 vo(t) [93] 。
在[90]中,提出了一种针对变化负载条件下的微电网系统中的逆变器的开路故障诊断算法。提出了一种信号处理方法来减少故障表示所需的信息量并抑制负载变化的影响。 FFNN 用作诊断分类器。所提出方法的计算负担可以减少到现有算法的10%。在这种情况下,FFNN 充当分类工具。类似的故障诊断思想包括 AFIS 来确定直流链路滤波器中电容器的严重程度 [102]。
文献[112]提出了一种电压源逆变器多开关故障诊断算法。回声状态网络 (ESN) 用作给定小低频数据的诊断分类器。请注意,ESN 是 RNN 的改进变体,可避免训练中的梯度爆炸和消失。在这项工作中,ESN 的诊断性能与 FFNN、具有小波激活函数的 FFNN 和 RBFN 进行了比较。这表明ESN在灵敏度、设计过程和训练速度方面均具有优越性。
在[115]中,一维CNN被应用于模块化多电平转换器的故障诊断。一维CNN的优点之一是可以将特征提取和诊断分类集成在一起,从而可以直接对原始数据进行故障诊断。这样就可以避免通常需要大量经验的特征提取。实验结果表明,该方法可靠性高,100 ms内检测准确率达98.9%,故障诊断准确率达99.7%。
除了之前基于神经网络的方法外,包括SVM和RVM在内的核方法也被应用于异常检测和故障诊断。核方法的优点之一是数据集大小要求相对低于基于神经网络的方法。
文献[7]基于时域故障特征,提出了一种基于SVM的逆变器IGBT早期渐进故障诊断方法。 SVM的训练可以通过元启发式方法(例如PSO、GA等)来完成。对于总共 41 个故障类别,它的平均准确度达到 94.82%,对负载变化和电机参数变化都具有鲁棒性。
在[127]中,RVM应用于级联H桥多电平逆变器的故障诊断。应用PCA提取故障信号特征。实验分析表明,RVM 优于 FFNN 和 SVM,在该特定案例研究中诊断准确率达到 100%。与以直接故障标签作为输出的SVM相比,RVM是在贝叶斯框架下制定的。它使故障信息概率化输出,具有良好的理论指导作用,有利于诊断结果的不确定性分析。一般来说,对于相同的任务,RVM 比 SVM 更稀疏,这表明现场应用的速度更快。但RVM的训练时间普遍比SVM长。
2)无监督学习方法
在[136]中,PCA被应用于SiC MOSFET的异常检测。多种统计特征,包括峰度、偏度等,被视为PCA算法的输入。输出很紧凑,具有较少的特征和变换矩阵。对于现场应用,新的可用数据被应用到变换矩阵以计算异常指数。当异常指数超过预定义阈值时,会通知异常行为。通过处理器在环实验验证了该方法。这种检测机制类似于[93]中的检测机制。异常检测和故障诊断中的其他无监督学习方法,包括 k -means和SOM,可以在[118]中找到。
3)讨论
表 V 总结了典型人工智能算法的特征及其用于异常检测和故障诊断的变体。可以看出,每种人工智能算法都有优点和局限性。为了充分发挥每种算法的优势,将多种算法结合起来进行决策级融合,可以有效提高诊断的准确性和鲁棒性。用于 IGBT 故障诊断的决策级融合的示例可以在[96]中找到。更多结合多种算法的集成方法可以在 [1,第 1 章] 中找到。 14]。从人工智能的角度来看,电力电子和其他工程领域(例如机电应用)在异常检测和故障诊断任务方面的差异可以忽略不计。关于人工智能方法在异常检测和故障诊断方面的两篇综述可以在[162]和[163]中找到。
表V 电力电子系统异常检测和故障诊断算法比较
请注意,各种人工智能方法及其变体已成功应用于异常检测和故障诊断。不同应用中数据的采集方式和可用数据类型存在差异,这是人工智能实际应用的一个重要方面。 MATLAB [164] 提供了一个集成平台“预测维护工具箱”,其中包括各种异常检测和诊断算法。这有利于方法开发和基准分析。从人工智能的角度来看,大多数方法可以互换应用,在评估精度方面表现相当。虽然可以通过先进算法(例如深度学习方法)进一步提高准确率,但与其他实际问题相比,高分(例如 90%)后的准确率提升相对不那么显着。应该更多地考虑理论算法和实际实现之间的差距,其中实际考虑因素包括以下内容。
1)除单个部件故障外,还应考虑多个部件同时失效的故障模式。部件故障之间的依赖性和耦合效应应纳入诊断算法中。
2)考虑到电力电子系统数据采集的挑战,实际应用的训练数据集通常是有限的。对于故障标签不平衡的数据集,即正常运行情况下的数据充足,而由于灾难性故障而导致故障标签的数据稀缺,这种情况更糟。因此,在数据集大小有限和数据质量差的情况下,应该研究算法的适用性。
3)还应综合考虑实用性,包括计算负担、自适应能力、鲁棒性、算法设计和调试的难度[112]、实现成本等。
C. RUL 预测
设计阶段的寿命预测是为了支持DfR,它指的是单元群体的特征。作为 PHM [165] 的关键方面之一,RUL 预测并不是预测一组单元的寿命。它根据状态监测信息预测正在使用的单个单元的剩余寿命。寿命预测存在相关的不确定性,包括模型校准误差、制造公差、运行环境和工作负载的变化等。这些不确定性导致现场运行中特定单元的可靠性估计不准确[166]。 RUL 预测作为附加工具来应用,以减少可靠性关键、安全关键或可用性关键应用的不确定性。
RUL预测的流程图和过程如图19所示。可以根据历史数据建立回归模型。可以根据回归模型估计任意特定条件监测时间的退化水平的概率密度函数(pdf)。 RUL 的 pdf 可以从退化水平的 pdf 导出。鉴于系统在状态监测时间 t 正常运行,其RUL l 被定义为退化过程 D(t) 超过故障阈值w时的剩余寿命 ,即
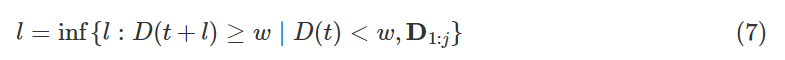
其中 D1:j 是截至时间 t 的累积CM信息。请注意,RUL l 是随机变量。除了预期值之外,具有下置信区间和上置信区间 (llo,lup) 的不确定性指标也非常重要。 RUL 预测中的 AI 方法通常基于训练数据集处理退化信息与相应 RUL 之间的非线性回归[167]。通过这种方式,可以表征退化模式。一旦了解了退化模式,就可以根据回归模型直接进行预测,以方便未来的退化水平预测。结果,可以估计RUL。
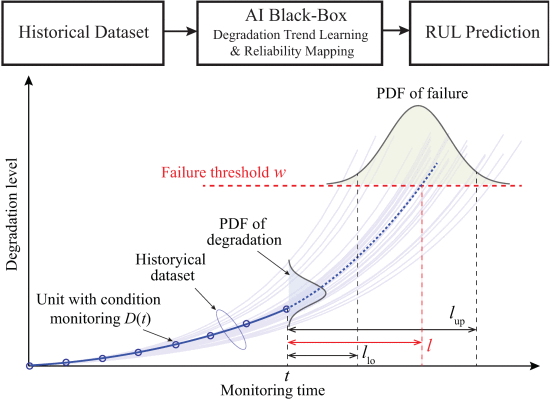
图19 用于电力电子系统 RUL 预测的 AI 方法的流程图和程序,其中 pdf:概率密度函数。
在[111]中,ESN被应用于功率MOSFET的RUL预测,如图20所示。 ESN 的输入退化指标是 k−1 和 k时的漏源通态电阻 RDS,(on) ,输出是时间 k+1时的 RDS,(on) 。为了促进ESN的适应,当现场设备的新状态监测数据可用时,利用粒子滤波器递归地更新输出权重。通过这种方式,退化模型可以适应不同的外部环境和运行模式。另一种涉及 TDNN 的 IGBT RUL 预测的神经网络方法可以在 [114] 中找到。
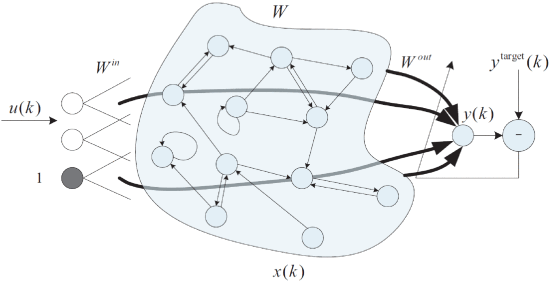
图20 基于ESN的功率MOSFET的RUL预测[111]。对于网络训练,输入权重 Win 和循环权重 W 是随机生成的。输出权重 Wout 通过最小二乘法估计。
在[119]中,高斯过程回归被应用于IGBT的RUL预测。对于退化建模,通态集电极-发射极电压 ΔVce,on 的减量与状态监测时间之间的非线性关系是通过高斯过程回归建立的。由于高斯过程是用贝叶斯框架制定的,因此它能够本质上预测变化 ΔVce,on 的不确定性。从图21可以看出, ΔVce,on 演化的误差条是明确导出的,可以进一步用于RUL置信区间的计算。用于 RUL 预测的核方法的另一个示例可以在 [74] 中找到,其中 SVM 应用于降压转换器的退化建模。
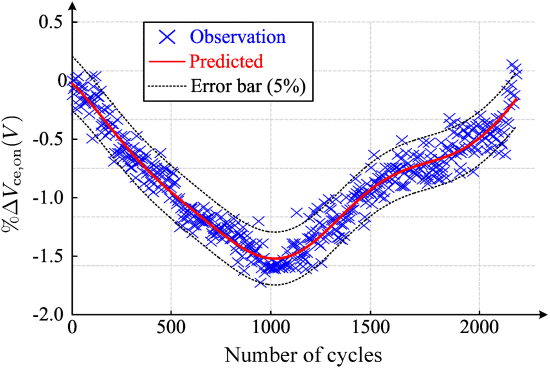
图21 用于 IGBT 的 RUL 预测的高斯过程回归 [119]。
为了使基于人工智能的RUL预测方法更加实用,应在以下方面做出更多努力。
为了使基于人工智能的RUL预测方法更加实用,应在以下方面做出更多努力。
1)不确定性量化:与其他回归相关任务(例如控制应用)相比,不确定性量化的能力对于 RUL 预测更为关键。如图19所示,RUL是一个随机变量,因此,置信区间的量化对于最优决策至关重要。这些不确定性来自群体异质性、测量噪声、不同的操作设置等,实际解决方案应综合考虑这些不确定性。考虑到黑盒特征,人工智能方法对于预测结果的不确定性量化相当具有挑战性。几种可行的方法包括蒙特卡罗方法[114]、在神经网络中结合粒子滤波器[111]和基于贝叶斯的人工智能方法(例如高斯过程、RVM)。另一个有前途的方向是随机数据驱动方法 [154]、[160]、[168],它们本质上可以提供用于计算置信区间的 RUL 的 pdf。
2)自适应能力:涉及图14中的模型参数调整层,用于连接离线模型和在线模型,这是实际应用的关键步骤。如果某种特定的人工智能方法缺乏自适应能力,那么它的应用就会受到限制,因为一个前提是训练数据和测试数据应该在相似的情况下(例如外部环境和操作模式)生成并具有高度相似性[95] ]。这对于电力电子来说是一个挑战,因为原位系统的操作设置(即测试数据)与训练数据集的操作设置有很大不同,训练数据集通常是通过加速测试实验获得的。大多数研究[74]、[114]、[119]假设原位系统的操作设置与训练数据集相同(例如加速老化实验),但在现场应用中可能并非如此。因此,基于人工智能的 RUL 预测方法的自适应能力对于连接学术研究和工业应用至关重要。模型参数调整的其他有希望的方向包括各种操作设置(温度、电压、湿度等)下退化特性的显式映射关系推导[169]和迁移学习[170]、[171]。然而,这可能意味着对系统模型的深入研究。
VI、电力电子系统人工智能展望
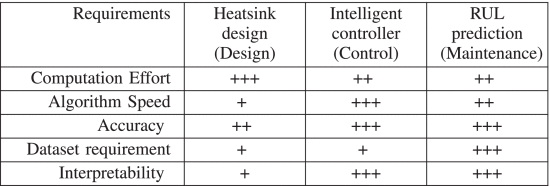
从算法的角度来看,有必要研究人工智能应用于不同生命周期阶段时的特点。通过使用功率变换器系统,应用三个具体示例来说明人工智能方法对每个生命周期阶段的要求。
对于转换器系统的散热器设计,需要确定大量决策变量,例如重量、体积、图案,这本质上是一项优化任务。元启发式方法应用于涉及迭代试错过程的优化。尽管计算工作量很大,但设计任务通常是离线执行的。这种情况下对算法速度的要求较低。尽管基于元启发式方法的优化不能确保全局解决方案,但次优散热器设计在大多数情况下仍然是优越且令人满意的。因此,算法的准确性也并不重要。不需要训练数据集和优化过程的可解释性。
对于变流器系统的智能控制器来说,需要将电压误差、电流误差等实时控制误差返回给控制器进行在线自适应更新。因此,算法速度和精度的要求最为关键。此外,控制器的稳定性需要在理论上得到保证,因此可解释性至关重要。智能控制器一般是在线调优的,不需要准备模型训练的数据集。
对于变流器系统中开关器件的RUL预测,由于器件退化较慢并且可以接受较长的决策时间跨度,因此对算法速度的要求适中。 RUL 预测的退化模型可以在离线模式下准备并在在线模式下有效调整,并且该应用中的计算工作量适中。由于模型精度高度依赖于数据集,因此数据集要求,例如数据集质量、数据集大小、标签平衡(例如训练数据集中限制异常数据)等是最关键的。此外,具有不确定性的 RUL 预测结果的可解释性也至关重要。因此,表六提供了电力电子系统生命周期各个阶段的人工智能算法的比较。
表六 人工智能在设计、控制和维护方面的示例性应用的要求
结论是人工智能在电力电子系统中具有巨大的潜力。许多机会和问题有待探讨如下。
- 人工智能应用于电力电子系统的动机和理由:尽管自 20 世纪 90 年代以来,文献中有大量关于电力电子系统人工智能的研究,但工业中的实际实施仍然有限,这与声称的人工智能潜力形成鲜明对比。有必要对人工智能本质上优于传统方法的任务进行更深入的研究。应通过从工业角度与传统方法进行比较来清楚地确定基于人工智能的解决方案的合理性,例如实现复杂性、算法准确性和鲁棒性、算法责任、额外硬件成本、计算能耗、嵌入式能力等。
- 通过生命周期阶段交织的人工智能实施:在设计、控制和维护的每个生命周期阶段实施人工智能将促进灵活的功能交互。该功能有利于整体性能优化和流程简化。它还使系统能够管理电气和其他学科(例如机械领域)之间的数据流[13]。例如,通过基于人工智能的系统参数识别获得的老化信息可以灵活地纳入基于人工智能的控制器中,以提高可靠性。因此,应更加关注人工智能驱动下的交织互动。
- 多级信息融合:稳健性对于安全关键型电力电子系统至关重要。在大多数情况下,对于电力电子系统的特定应用,可以使用多个信息源和模型。如果同时利用这些信息源和模型,就可以减轻可能的偏差,从而提高稳健性。多级信息融合可以在数据级[160]、[172]、特征级、决策级[96]及其组合上进行,以便利用每个信息源的洞察力。例如,电力转换器系统的完善微分方程可以与人工智能集成,作为状态监测的混合解决方案。因此,可以获得模型驱动方和数据驱动方的优势,以获得更好的准确性和鲁棒性。
- 计算-轻AI:与其他工业领域(例如图像识别)相比,电力电子系统的关键特征之一是没有强大的计算单元。而控制等实时应用对算法速度提出了严格的要求。尽管复杂的深度学习技术[170]可以提供卓越的性能,但它对于电力电子系统来说是计算密集型的。一个前瞻性的方向是轻计算人工智能算法,它可以在具有成本效益的单元上实现,但提供与深度学习算法相当的性能。
- Data-Light AI:电力电子系统上人工智能实施的瓶颈之一是数据集。例如,基于人工智能的 RUL 预测解决方案要求数据集具有足够的通用性,以便进行准确的退化行为学习。然而,由于降解实验非常消耗资源,因此数据集大小通常很小。对于安全关键的情况,这种情况更糟。因此,开发数据集要求较低的人工智能算法,即在数据集较差的情况下能够提供可接受的性能的轻数据人工智能解决方案是一个未来的方向。
- 可解释的人工智能:电力电子领域的大多数人工智能算法都存在“黑匣子”功能。例如,大多数基于人工智能的 RUL 预测解决方案只能提供点估计,而没有敏感性分析和不确定性量化。它使得基于人工智能的解决方案变得不透明,并且对于从业者在行业应用中实施的说服力较差,尤其是对于安全关键的情况。迫切需要提高算法透明度,以实现具有更好可解释性的可解释人工智能。了解模型如何做出决策对于模型简化和安全性至关重要,这样可以放心地实施人工智能解决方案。
- 数据集隐私:数据隐私受到越来越多的关注,例如欧盟的《通用数据保护条例》[173]。由于这些严格的规定,标准人工智能算法的训练具有挑战性,因为集中式数据收集在未来可能不可行。因此,对于电力电子应用,有希望为人工智能算法开发一种协作学习方案,而无需集体聚合来自不同位置的数据,例如联邦学习[174]。这非常符合人工智能解决方案实施的数据隐私法规趋势。
- 电力电子数据库:由于电力电子系统动力学的复杂性,模型训练需要大量数据集,特别是维护应用。而数据收集的实验测试通常既耗时又昂贵。人们迫切需要建立通用电力电子数据和知识库。这些开源数据集对于基准算法性能和加速应用程序开发至关重要。它将有利于学术界和工业界的全球电力电子社区。
VII、结论
本文全面回顾了电力电子系统中现有的人工智能方法。新发现如下,
- 从应用角度来看,人工智能方法在电力电子系统中的应用可分为设计、控制和维护。讨论了人工智能在各个生命周期阶段的使用比例、应用趋势、特征和需求。
- 从方法角度来看,应用于电力电子系统的人工智能方法可分为专家系统、模糊逻辑、元启发式方法和机器学习。综合比较各类别相关AI算法的使用比例、优势和局限性。
- 从功能上看,AI相关应用本质上是优化、分类、回归、数据结构探索等。
- 相关算法变体和应用程序的里程碑被识别并组织为时间线图。
- 对于每个生命周期阶段,都讨论了说明性示例,并确定了挑战和未来的研究机会。