Kubernetes(k8s)学习笔记(三)--部署 Kubernetes Master
前文已经使用docker安装了kubeadm,因此本文使用kubeadm部署master节点。
一.先拉取必要的镜像库到本地。
在拉取之前,先配下镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://hub-mirror.c.163.com","https://mirror.ccs.tencentyun.com","https://docker.mirrors.ustc.edu.cn"]
}
EOF然后重启 Docker 生效
sudo systemctl daemon-reload
sudo systemctl restart docker拉取必要的镜像,可执行下面的shell脚本来实现:
#!/bin/bashimages=(kube-apiserver:v1.17.3kube-proxy:v1.17.3kube-controller-manager:v1.17.3kube-scheduler:v1.17.3coredns:1.6.5etcd:3.4.3-0pause:3.1
)for imageName in ${images[@]} ; dodocker pull registry.aliyuncs.com/google_containers/$imageNamedocker tag registry.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
done注意:registry.cn-hangzhou.aliyuncs.com镜像库已不再维护,请切换到上文的registry.aliyuncs.com镜像库。
二.使用kubeadm init完成master节点的初始化
通过执行下面的命令来实现
kubeadm init \
--apiserver-advertise-address=10.0.2.15 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5这一步非常关键,也是在耗费较多时间的这一步,执行了几次都失败,后面看到网友提到,
kubernetes-version v1.17.3是比较老的版本,需要用18.09.9的dock版本才能初始化成功,于是赶紧用docker --version命令查看服务器中的docker版本,这一看是26.1.4(当前最新版本)。于是卸载了该版本的docker,安装上18.09.9的docker,重新执行下面的命令,又遇到下面的错误
[preflight] Some fatal errors occurred: [ERROR Port-6443]: Port 6443 is in use [ERROR Port-10259]: Port 10259 is in use [ERROR Port-10257]: Port 10257 is in use [ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists [ERROR Port-10250]: Port 10250 is in use [ERROR Port-2379]: Port 2379 is in use [ERROR Port-2380]: Port 2380 is in use [ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
因为之前初始化失败过,系统上已经存在一个 Kubernetes 集群的残留文件或进程,导致端口和文件冲突。要解决这个问题,需要彻底清理旧的 Kubernetes 环境,然后再重新初始化。以下是具体步骤:
1. 重置 Kubernetes 环境
(1) 使用 kubeadm reset 清理
sudo kubeadm reset --force 这将会删除下面的文件:
Kubernetes 管理的容器(kubelet 创建的 Pod)
/etc/kubernetes/ 下的配置文件
网络插件相关的 CNI 配置
(2) 手动清理残留文件
sudo rm -rf /etc/kubernetes/ # 删除残留的 Kubernetes 配置文件
sudo rm -rf /var/lib/etcd/ # 删除 etcd 数据目录
sudo rm -rf $HOME/.kube # 删除 kubectl 配置文件(3) 清理占用端口的进程
检查哪些进程占用了 Kubernetes 相关端口(6443、10250、2379 等):
sudo netstat -tulnp | grep -E '6443|10259|10257|10250|2379|2380'发现占用进程(如旧 kube-apiserver、etcd),使用下面的命令手动终止:
sudo kill -9 <PID> # 替换 <PID> 为实际进程 ID执行完上面命令后,重新执行kubdadm ini命令,如果出现类似下面的说明,则表明成功啦
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.0.2.15:6443 --token ddxbg6.tjzfs3d7iyni1iun \ --discovery-token-ca-cert-hash sha256:f4913e091bdf5cc614771810c294e4a4cb258f769b307ad83fe9519356d4ba57
注意:上面的命令先不要着急clear掉,先把它拷贝到本地,稍候子节点加入master节点的时候需要用到。
三.配置 kubectl 访问权限
使用下面的命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config然后获取所有节点
kubectl get nodes四.安装 Pod 网络插件(CNI)
方法一:可以将下面的代码复制到本地并创建一个名为kube-flannel.yml文件
然后执行kubectl apply -f kube-flannel.yml命令来完成网络应用搭建,
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:name: psp.flannel.unprivilegedannotations:seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/defaultseccomp.security.alpha.kubernetes.io/defaultProfileName: docker/defaultapparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/defaultapparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:privileged: falsevolumes:- configMap- secret- emptyDir- hostPathallowedHostPaths:- pathPrefix: "/etc/cni/net.d"- pathPrefix: "/etc/kube-flannel"- pathPrefix: "/run/flannel"readOnlyRootFilesystem: false# Users and groupsrunAsUser:rule: RunAsAnysupplementalGroups:rule: RunAsAnyfsGroup:rule: RunAsAny# Privilege EscalationallowPrivilegeEscalation: falsedefaultAllowPrivilegeEscalation: false# CapabilitiesallowedCapabilities: ['NET_ADMIN']defaultAddCapabilities: []requiredDropCapabilities: []# Host namespaceshostPID: falsehostIPC: falsehostNetwork: truehostPorts:- min: 0max: 65535# SELinuxseLinux:# SELinux is unused in CaaSPrule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:name: flannel
rules:- apiGroups: ['extensions']resources: ['podsecuritypolicies']verbs: ['use']resourceNames: ['psp.flannel.unprivileged']- apiGroups:- ""resources:- podsverbs:- get- apiGroups:- ""resources:- nodesverbs:- list- watch- apiGroups:- ""resources:- nodes/statusverbs:- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:name: flannel
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: flannel
subjects:
- kind: ServiceAccountname: flannelnamespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:name: flannelnamespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:name: kube-flannel-cfgnamespace: kube-systemlabels:tier: nodeapp: flannel
data:cni-conf.json: |{"name": "cbr0","cniVersion": "0.3.1","plugins": [{"type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]}net-conf.json: |{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: kube-flannel-ds-amd64namespace: kube-systemlabels:tier: nodeapp: flannel
spec:selector:matchLabels:app: flanneltemplate:metadata:labels:tier: nodeapp: flannelspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: beta.kubernetes.io/osoperator: Invalues:- linux- key: beta.kubernetes.io/archoperator: Invalues:- amd64hostNetwork: truetolerations:- operator: Existseffect: NoScheduleserviceAccountName: flannelinitContainers:- name: install-cniimage: quay.io/coreos/flannel:v0.11.0-amd64command:- cpargs:- -f- /etc/kube-flannel/cni-conf.json- /etc/cni/net.d/10-flannel.conflistvolumeMounts:- name: cnimountPath: /etc/cni/net.d- name: flannel-cfgmountPath: /etc/kube-flannel/containers:- name: kube-flannelimage: quay.io/coreos/flannel:v0.11.0-amd64command:- /opt/bin/flanneldargs:- --ip-masq- --kube-subnet-mgrresources:requests:cpu: "100m"memory: "50Mi"limits:cpu: "100m"memory: "50Mi"securityContext:privileged: falsecapabilities:add: ["NET_ADMIN"]env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespacevolumeMounts:- name: runmountPath: /run/flannel- name: flannel-cfgmountPath: /etc/kube-flannel/volumes:- name: runhostPath:path: /run/flannel- name: cnihostPath:path: /etc/cni/net.d- name: flannel-cfgconfigMap:name: kube-flannel-cfg
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: kube-flannel-ds-arm64namespace: kube-systemlabels:tier: nodeapp: flannel
spec:selector:matchLabels:app: flanneltemplate:metadata:labels:tier: nodeapp: flannelspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: beta.kubernetes.io/osoperator: Invalues:- linux- key: beta.kubernetes.io/archoperator: Invalues:- arm64hostNetwork: truetolerations:- operator: Existseffect: NoScheduleserviceAccountName: flannelinitContainers:- name: install-cniimage: quay.io/coreos/flannel:v0.11.0-arm64command:- cpargs:- -f- /etc/kube-flannel/cni-conf.json- /etc/cni/net.d/10-flannel.conflistvolumeMounts:- name: cnimountPath: /etc/cni/net.d- name: flannel-cfgmountPath: /etc/kube-flannel/containers:- name: kube-flannelimage: quay.io/coreos/flannel:v0.11.0-arm64command:- /opt/bin/flanneldargs:- --ip-masq- --kube-subnet-mgrresources:requests:cpu: "100m"memory: "50Mi"limits:cpu: "100m"memory: "50Mi"securityContext:privileged: falsecapabilities:add: ["NET_ADMIN"]env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespacevolumeMounts:- name: runmountPath: /run/flannel- name: flannel-cfgmountPath: /etc/kube-flannel/volumes:- name: runhostPath:path: /run/flannel- name: cnihostPath:path: /etc/cni/net.d- name: flannel-cfgconfigMap:name: kube-flannel-cfg
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: kube-flannel-ds-armnamespace: kube-systemlabels:tier: nodeapp: flannel
spec:selector:matchLabels:app: flanneltemplate:metadata:labels:tier: nodeapp: flannelspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: beta.kubernetes.io/osoperator: Invalues:- linux- key: beta.kubernetes.io/archoperator: Invalues:- armhostNetwork: truetolerations:- operator: Existseffect: NoScheduleserviceAccountName: flannelinitContainers:- name: install-cniimage: quay.io/coreos/flannel:v0.11.0-armcommand:- cpargs:- -f- /etc/kube-flannel/cni-conf.json- /etc/cni/net.d/10-flannel.conflistvolumeMounts:- name: cnimountPath: /etc/cni/net.d- name: flannel-cfgmountPath: /etc/kube-flannel/containers:- name: kube-flannelimage: quay.io/coreos/flannel:v0.11.0-armcommand:- /opt/bin/flanneldargs:- --ip-masq- --kube-subnet-mgrresources:requests:cpu: "100m"memory: "50Mi"limits:cpu: "100m"memory: "50Mi"securityContext:privileged: falsecapabilities:add: ["NET_ADMIN"]env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespacevolumeMounts:- name: runmountPath: /run/flannel- name: flannel-cfgmountPath: /etc/kube-flannel/volumes:- name: runhostPath:path: /run/flannel- name: cnihostPath:path: /etc/cni/net.d- name: flannel-cfgconfigMap:name: kube-flannel-cfg
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: kube-flannel-ds-ppc64lenamespace: kube-systemlabels:tier: nodeapp: flannel
spec:selector:matchLabels:app: flanneltemplate:metadata:labels:tier: nodeapp: flannelspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: beta.kubernetes.io/osoperator: Invalues:- linux- key: beta.kubernetes.io/archoperator: Invalues:- ppc64lehostNetwork: truetolerations:- operator: Existseffect: NoScheduleserviceAccountName: flannelinitContainers:- name: install-cniimage: quay.io/coreos/flannel:v0.11.0-ppc64lecommand:- cpargs:- -f- /etc/kube-flannel/cni-conf.json- /etc/cni/net.d/10-flannel.conflistvolumeMounts:- name: cnimountPath: /etc/cni/net.d- name: flannel-cfgmountPath: /etc/kube-flannel/containers:- name: kube-flannelimage: quay.io/coreos/flannel:v0.11.0-ppc64lecommand:- /opt/bin/flanneldargs:- --ip-masq- --kube-subnet-mgrresources:requests:cpu: "100m"memory: "50Mi"limits:cpu: "100m"memory: "50Mi"securityContext:privileged: falsecapabilities:add: ["NET_ADMIN"]env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespacevolumeMounts:- name: runmountPath: /run/flannel- name: flannel-cfgmountPath: /etc/kube-flannel/volumes:- name: runhostPath:path: /run/flannel- name: cnihostPath:path: /etc/cni/net.d- name: flannel-cfgconfigMap:name: kube-flannel-cfg
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: kube-flannel-ds-s390xnamespace: kube-systemlabels:tier: nodeapp: flannel
spec:selector:matchLabels:app: flanneltemplate:metadata:labels:tier: nodeapp: flannelspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: beta.kubernetes.io/osoperator: Invalues:- linux- key: beta.kubernetes.io/archoperator: Invalues:- s390xhostNetwork: truetolerations:- operator: Existseffect: NoScheduleserviceAccountName: flannelinitContainers:- name: install-cniimage: quay.io/coreos/flannel:v0.11.0-s390xcommand:- cpargs:- -f- /etc/kube-flannel/cni-conf.json- /etc/cni/net.d/10-flannel.conflistvolumeMounts:- name: cnimountPath: /etc/cni/net.d- name: flannel-cfgmountPath: /etc/kube-flannel/containers:- name: kube-flannelimage: quay.io/coreos/flannel:v0.11.0-s390xcommand:- /opt/bin/flanneldargs:- --ip-masq- --kube-subnet-mgrresources:requests:cpu: "100m"memory: "50Mi"limits:cpu: "100m"memory: "50Mi"securityContext:privileged: falsecapabilities:add: ["NET_ADMIN"]env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespacevolumeMounts:- name: runmountPath: /run/flannel- name: flannel-cfgmountPath: /etc/kube-flannel/volumes:- name: runhostPath:path: /run/flannel- name: cnihostPath:path: /etc/cni/net.d- name: flannel-cfgconfigMap:name: kube-flannel-cfg方法二:kubectl apply -f \ https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
该地址可能被墙。
执行上面的命令等待大约 3 分钟,直到出现下面的提示
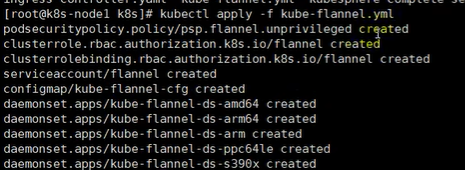
然后执行下面的命令查看指定名称空间的 pods
kubectl get pods -n kube-system 查看所有名称空间的 pods
kubectl get pods –all-namespace在执行上面这个命令的时候,又出现了一个问题
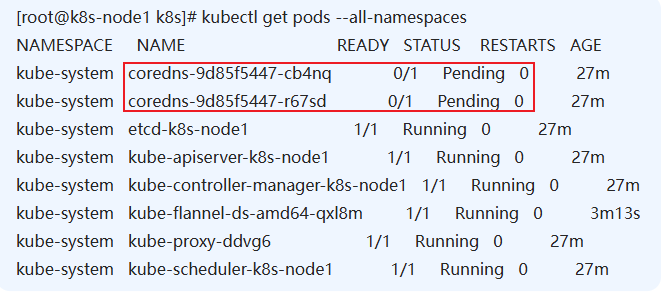
从中可以看到大部分节点已处于Running状态,但有2个节点是Pending状态。这样子是不行的,必须确保所有节点都处于Running状态才行。好吧,接下来就是想办法让corddns这2个跑起来。
coredns Pending 的常见原因是:
Node taint 导致无法调度
没有可用的 Pod 网络(Flannel 刚启动8分钟,有可能网络还没完全通)
资源不足(CPU/内存资源配额问题)
CNI 网络插件异常
下面一步步检查:
第一步:检查 Node Ready 状态
确认node 是不是已经 Ready。
执行下面的命令检查:
kubectl get nodes
如果 STATUS 显示 NotReady,那就肯定是 taint 的问题,Pod 调度不下去。
如果 STATUS 是 Ready,那么继续看调度详情。
第二步:查看 coredns 调度失败原因
执行下面的命令检查:
kubectl describe pod -n kube-system coredns-9d85f5447-cb4nq
看Events这一段,里面会清楚告诉为什么 Pending(比如是 taints、不满足资源请求、还是网络问题)
执行完上面的命令后,Events部分显示:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 5m28s (x37 over 56m) default-scheduler 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate.
这句话意思就是:
-
只有一个节点(k8s-node1)
-
这个节点有 taint(就是
node.kubernetes.io/not-ready:NoSchedule) -
coredns Pod 没有加 Toleration 来容忍这个 taint
-
所以调度失败了,Pending
从中可以看出node 已经基本正常了(否则 coredns不会一直排队调度),只是 taint 没去掉而已。
解决办法:
直接执行
kubectl taint nodes k8s-node1 node.kubernetes.io/not-ready:NoSchedule-注意最后有一个 短横线(-),表示要把 taint 移除。
执行完这个命令,再次执行kubectl get pods –all-namespace命令,此时又出现另一种情况:
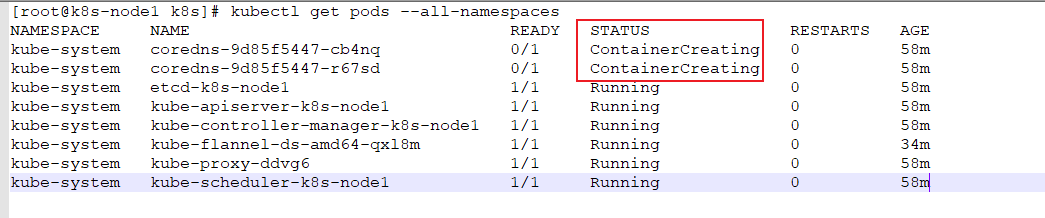
coredns从Pending变成ContainerCreating,本以为等一会就好,没想到再次执行上面的命令还是ContainerCreating状态,一直卡在 ContainerCreating。
继续使用下面的命令确认一下 coredns 的具体状态:
kubectl describe pod -n kube-system coredns-9d85f5447-cb4nq在 Events 里提示
Warning FailedScheduling 3m54s (x41 over 60m) default-scheduler 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate.
Warning NetworkNotReady 2m3s (x25 over 2m50s) kubelet, k8s-node1 network is not ready: runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitializ
从中可以看出coredns Pod 现在卡在 ContainerCreating,原因是节点的网络还没准备好
总结一下问题:
-
Flannel Pod虽然是
Running,但是 节点上(kubelet)并没有正确初始化 CNI网络插件配置。 -
所以 kubelet 现在处于
NetworkNotReady状态。 -
coredns 启动依赖网络,没网络分配 IP,就卡在
ContainerCreating
这个问题出现的典型原因有几种:
-
Flannel的CNI配置文件没有正确下发到
/etc/cni/net.d/ -
CNI插件二进制(比如
/opt/cni/bin/)目录缺东西 -
/etc/cni/net.d/ 目录为空,或者配置错了
根据上面的推断,一步步排查,先执行以下命令看看:
① 看一下 /etc/cni/net.d/ 目录
在 k8s-node1 节点上执行:
ls /etc/cni/net.d/ 正常来说,应该有一个类似 10-flannel.conflist 或 10-flannel.conf 的文件。
如果目录是空的,就说明 CNI配置还没生成成功!我的里边是有 10-flannel.conflist 文件的,接着往下排查
② 看一下 CNI插件二进制是否存在
执行:
ls /opt/cni/bin/提示:ls: cannot access /opt/cni/bin/: No such file or directory
结论:
-
Flannel部署的时候已经下发了CNI配置文件(
10-flannel.conflist),所以 kubelet能找到配置。 -
但是,CNI二进制插件(就是
/opt/cni/bin/下的一堆执行程序)根本没有。 -
没有二进制,kubelet就算有配置也用不了,所以提示
NetworkPluginNotReady。
这就是coredns卡住ContainerCreating的直接原因。
原因找到了,那么解决办法就是补充CNI插件!
只需要下载官方的 CNI 插件包,解压到 /opt/cni/bin/ 目录。
1.创建目录:
mkdir -p /opt/cni/bin下载 CNI 插件(注意选跟你的 Kubernetes 版本兼容的,比如 v1.25 对应 CNI 0.8.x 或 1.0.x)我的是17.3版本,需要下载CNI v0.8.7,这个版本兼容性好,也比较稳定。
cd /opt/cni/bin
curl -LO https://github.com/containernetworking/plugins/releases/download/v0.8.7/cni-plugins-linux-amd64-v0.8.7.tgz
tar -xzvf cni-plugins-linux-amd64-v0.8.7.tgz
这个是github的地址,国内下载可能较慢,途中因等待时间有点久,将上面的命令停止后使用阿里云的镜像
curl -LO https://kubernetes-release.pek3b.qingstor.com/cni-plugins/v0.8.7/cni-plugins-linux-amd64-v0.8.7.tgz
结果下载完解压时提示:
[root@k8s-node1 bin]# tar -xzvf cni-plugins-linux-amd64-v0.8.7.tgz gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
这说明的问题是:
-
下载的那个
cni-plugins-linux-amd64-v0.8.7.tgz文件 根本就不是正确的 gzip 压缩包。 -
要么是下载失败了(比如网页404,实际上下载下来是个 HTML 错误页)
-
要么是被拦截成了别的内容。
可以简单看下文件大小:
ls -lh cni-plugins-linux-amd64-v0.8.7.tgz或者直接 cat 看看:
cat cni-plugins-linux-amd64-v0.8.7.tgz | head -n 10
结果提示:
{"status":404,"code":"object_not_exists","message":"The object you are accessing does not exist."...
说明:
-
这个下载链接 404了,文件压根不存在了!
重新用上面的github地址下载,下载完一定要先检查一下文件大小
ls -lh cni-plugins-linux-amd64-v0.8.7.tgz正常是 38M 左右。如果文件大小无误,则进行解压:
tar -xzvf cni-plugins-linux-amd64-v0.8.7.tgz然后重启 kubelet:
systemctl restart kubelet再次用kubectl get pods –all-namespace文件检查:
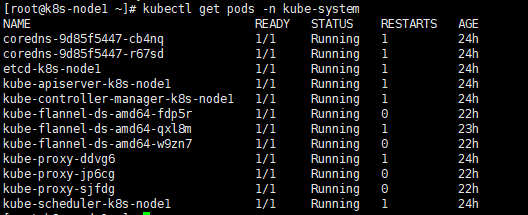
终于成功了。
如果以后换版本(比如升级 Kubernetes),记得也要同步更新对应的 CNI 插件版本
(一般大版本跨度大了,比如 1.17 ➔ 1.25,就要用新版CNI了)
将子节点加入 Kubernetes master节点,使用上面kubdadm init命令,上面提到拷贝到本地的命令
在子节点上去执行,在子节点上执行,不是在master节点
kubeadm join 10.0.2.15:6443 --token ddxbg6.tjzfs3d7iyni1iun \
--discovery-token-ca-cert-hash sha256:f4913e091bdf5cc614771810c294e4a4cb258f769b307ad83fe9519356d4ba57
上面的token只有2小时的时效,如果token过期了,可以通过下面的命令重新生成:
kubeadm token create --print-join-command
kubeadm token create --ttl 0 --print-join-command
kubeadm join --token y1eyw5.ylg568kvohfdsfco --discovery-token-ca-cert-hashsha256: 6c35e4f73f72afd89bf1c8c303ee55677d2cdb1342d67bb23c852aba2efc7c73执行 watch kubectl get pod -n kube-system -o wide 监控 pod 进度等 3-10 分钟,完全都是 running 以后使用 kubectl get nodes 检查状态
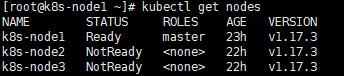
可以看到2个子节点已经加入到集群中了,但处于NotReady状态,是因为还没有像主节点那样进行网络配置,参照上文提到的flannel网络配置,对2个子节点进行配置网络即可。