关系数据的可视化
目录
【实验目的】
【实验原理】
【实验环境】
【实验步骤】
一、安装Python所需要的第三方模块
二、实验
【实验总结】
【实验目的】
1.掌握关系数据在大数据中的应用
2.掌握关系数据可视化方法
3. python 程序实现图表
【实验原理】
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠或者是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?
就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集程1度,是数据分布范围的描述,与茎叶图类似,但是不会具体到某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点图将序列显示为一组点。值由点在图表中的位置表示。散点图通常用于比较跨类别的聚合数据。
【实验环境】
OS:Windows
python:v3.6
【实验步骤】
数据源:

一、安装Python所需要的第三方模块
pip install seaborn二、实验
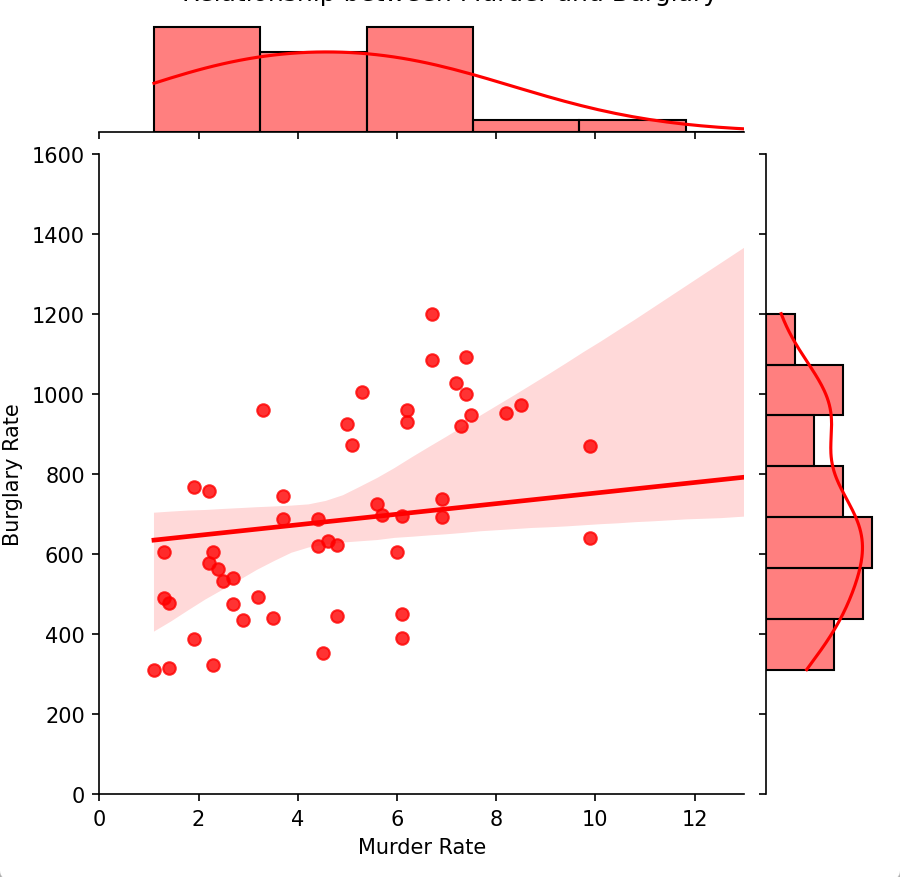
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt# 读取数据
df = pd.read_csv(r"crimeRatesByState2005.csv")# 使用jointplot绘制图表并设置颜色
g = sns.jointplot(data=df, x='murder', y='burglary', kind='reg', color='red')# 设置图表标题和轴标签
g.fig.suptitle('Relationship between Murder and Burglary', y=1.02)
g.set_axis_labels('Murder Rate', 'Burglary Rate')# 设置横坐标和纵坐标的最大值
g.ax_joint.set_xlim(0, 13)
g.ax_joint.set_ylim(0, 1600)# 显示图表
plt.show()
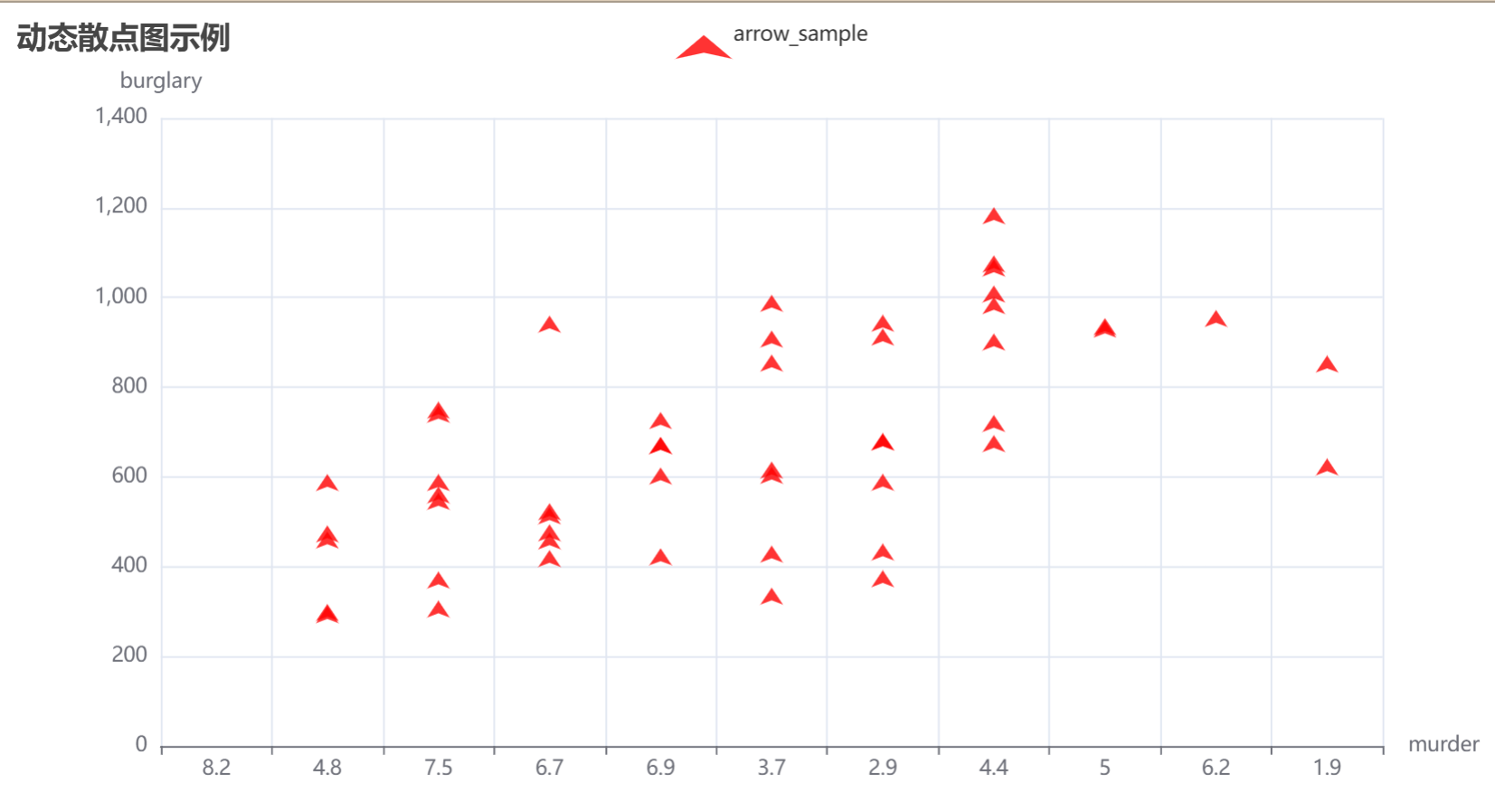
2.动态散点图
from pyecharts import options as opts
from pyecharts.charts import Scatter
import pandas as pd# 数据加载和预处理函数
def load_and_process_data(file_path):# 读取数据crime = pd.read_csv(file_path)# 筛选数据,去除 "United States" 和 "District of Columbia"crime_filtered = crime[(crime.state != "United States") & (crime.state != "District of Columbia")]return crime_filtered# 创建 Scatter 图表函数
def create_scatter_plot(data):# 创建 Scatter 图表scatter = (Scatter().add_xaxis(data['murder'].tolist()) # 使用 "murder" 列作为 x 轴.add_yaxis("arrow_sample",data['burglary'].tolist(), # 使用 "burglary" 列作为 y 轴symbol="arrow", # 设置为箭头形状label_opts=opts.LabelOpts(is_show=False), # 不显示标签itemstyle_opts=opts.ItemStyleOpts(color="red") # 设置散点颜色为红色).set_global_opts(title_opts=opts.TitleOpts(title="动态散点图示例"),xaxis_opts=opts.AxisOpts(name="murder", min_=0, max_=10), # 设置 x 轴范围yaxis_opts=opts.AxisOpts(name="burglary") # 设置 y 轴名称))return scatter# 主程序入口
def main():# 加载和处理数据file_path = "crimeRatesByState2005.csv" # 文件路径crime_data = load_and_process_data(file_path)# 创建散点图并渲染scatter_plot = create_scatter_plot(crime_data)scatter_plot.render("scatter_effect.html") # 渲染并保存为 HTML 文件# 执行主程序
if __name__ == "__main__":main()
3、请使用矩阵图表示数据集中七种犯罪类型之间的相关关系(提示:请剔除 United States 和 District of Columbia 两行表示均值和异常的数据),效果如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 修改文件地址
df = pd.read_csv(r"crimeRatesByState2005.csv")# 剔除 United States 和 District of Columbia 两行数据
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 选择七种犯罪类型的数据
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']
df_crime = df[crime_types]# 设置中文字体为黑体(解决中文显示问题,需确保系统已安装黑体字体)
plt.rcParams['font.sans-serif'] = ['SimHei']# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False# 设置图形大小
plt.figure(figsize=(12, 12))# 创建散点图矩阵,去掉 corner 参数以显示对角线以上的散点图,并设置颜色为紫色
g = sns.pairplot(df_crime, plot_kws={'color': 'red'})# 设置图形标题
g.fig.suptitle('七种犯罪类型之间的相关关系', y=1.02)# 调整子图布局
plt.tight_layout()# 显示图形
plt.show()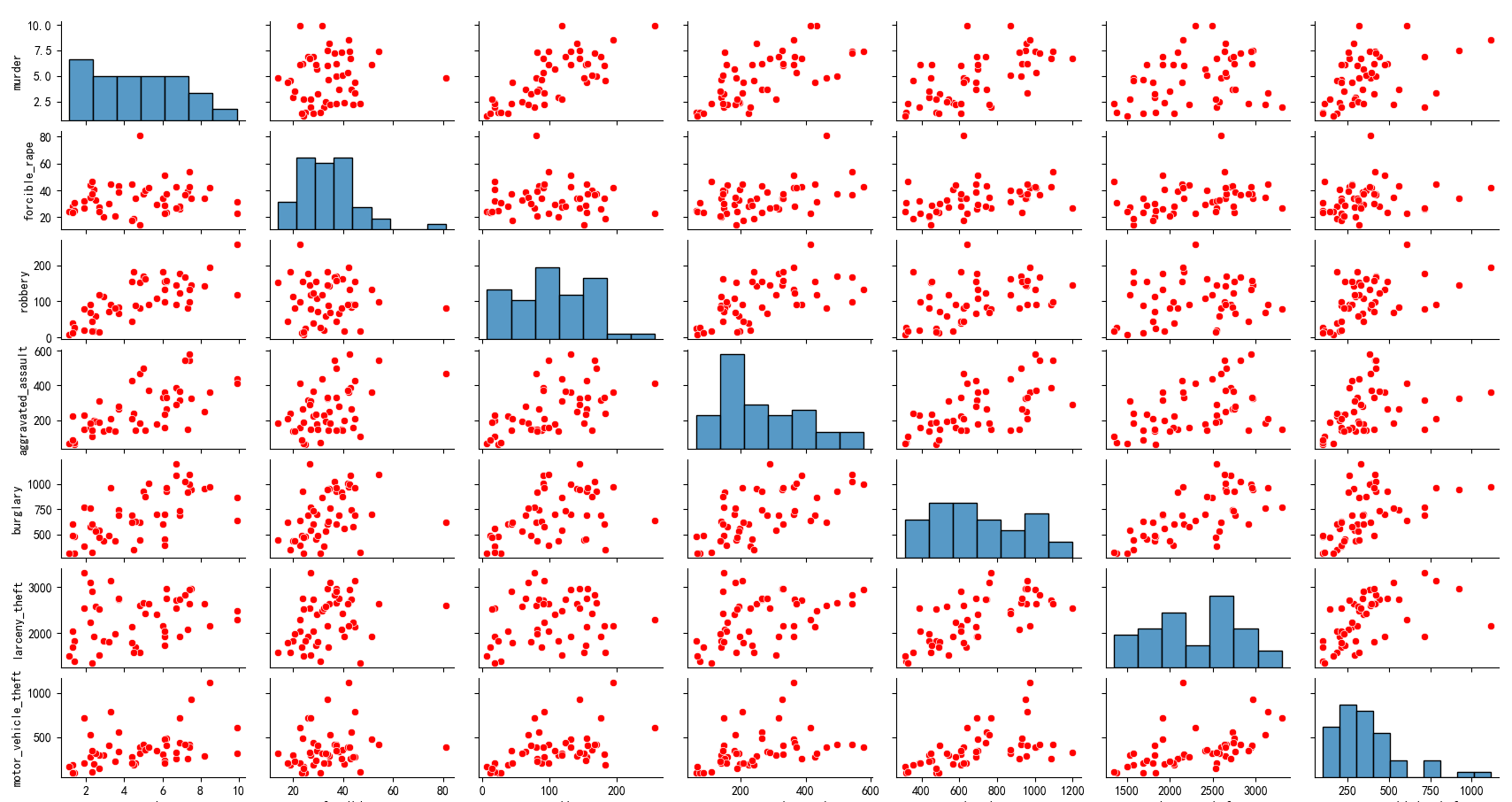
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA# 读取数据
df = pd.read_csv('crimeRatesByState2005.csv')# 剔除 United States 和 District of Columbia 两行数据
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 提取犯罪类型数据列
crime_cols = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']
crime_data = df[crime_cols]# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(crime_data)# 进行主成分分析
pca = PCA(n_components=2)
principal_components = pca.fit_transform(scaled_data)# 绘制双标图
fig, ax = plt.subplots(figsize=(10, 8))# 绘制样本点
ax.scatter(principal_components[:, 0], principal_components[:, 1], alpha=0.5)# 绘制变量箭头
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
for i, feature in enumerate(crime_cols):ax.arrow(0, 0, loadings[i, 0], loadings[i, 1], color='r', alpha=0.5, head_width=0.1)ax.text(loadings[i, 0] * 1.15, loadings[i, 1] * 1.15, feature, color='g', ha='center', va='center')# 设置标题和坐标轴标签
ax.set_title('Biplot of Seven Crime Types')
ax.set_xlabel('Principal Component 1')
ax.set_ylabel('Principal Component 2')# 显示图形
plt.show()
代码解释:
- 数据读取与预处理:使用
pandas的read_csv函数读取 CSV 文件,并通过布尔索引过滤掉United States和District of Columbia两行数据。 - 提取犯罪类型数据:从数据集中选取七种犯罪类型对应的列。
- 数据标准化:使用
StandardScaler对数据进行标准化处理,消除量纲影响。 - 主成分分析:使用
PCA进行主成分分析,将数据降维到二维(n_components=2)。 - 绘制双标图
- 绘制样本点:将样本投影到前两个主成分上并绘制散点图。
- 绘制变量箭头:根据主成分的载荷绘制变量箭头,箭头的方向和长度表示变量在主成分上的贡献,箭头之间的夹角反映变量之间的相关性。
- 设置标题和坐标轴标签:为图形添加标题和坐标轴标签,增强可读性。
- 显示图形:使用
plt.show()显示绘制好的图形。
运行结果:
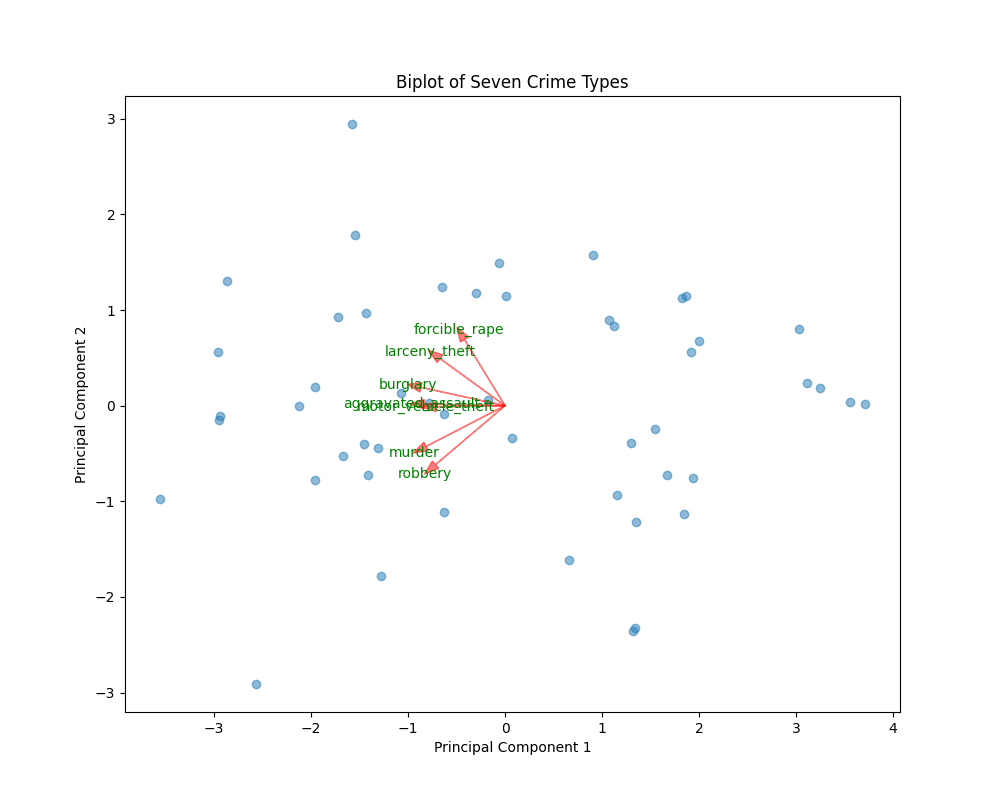
运行代码后,会弹出一个图形窗口,展示七种犯罪类型的双标图。图中包含样本点和变量箭头。样本点的分布展示了不同样本在主成分上的分布情况;变量箭头的方向和长度反映了变量对主成分的贡献,箭头之间的夹角越小,说明变量之间的相关性越强。通过观察双标图,可以直观地探究七种犯罪类型之间的相关关系。
(2)雷达图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 读取数据
df = pd.read_csv('crimeRatesByState2005.csv')# 剔除 United States 和 District of Columbia 两行数据
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 提取犯罪类型数据列
crime_cols = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']
crime_data = df[crime_cols]# 计算各犯罪类型的均值
mean_values = crime_data.mean().values# 犯罪类型数量
num_vars = len(crime_cols)# 角度
angles = np.linspace(0, 2 * np.pi, num_vars, endpoint=False).tolist()
angles += angles[:1]# 均值数据添加最后一个值以闭合图形
mean_values = np.concatenate((mean_values, [mean_values[0]]))# 创建画布
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))# 绘制雷达图
ax.plot(angles, mean_values, color='b', linewidth=1)
ax.fill(angles, mean_values, color='b', alpha=0.25)# 设置坐标轴标签
ax.set_xticks(angles[:-1])
ax.set_xticklabels(crime_cols)# 设置标题
ax.set_title('Radar Chart of Seven Crime Types', y=1.1)# 显示图形
plt.show()代码解释:
-
数据读取与预处理:借助
pandas的read_csv函数读取 CSV 文件,并且通过布尔索引把United States和District of Columbia两行数据过滤掉。 -
提取犯罪类型数据:从数据集中选取七种犯罪类型对应的列。
-
计算均值:计算每种犯罪类型的均值,从而在雷达图里展示整体的情况。
-
确定角度:为了在雷达图上合理分布各个犯罪类型,计算每个犯罪类型对应的角度。
-
绘制雷达图:使用
matplotlib的plot函数绘制折线,使用fill函数对图形进行填充。 -
设置坐标轴标签和标题:为雷达图添加坐标轴标签和标题,增强可读性。
-
显示图形:使用
plt.show()显示绘制好的图形。
运行结果:
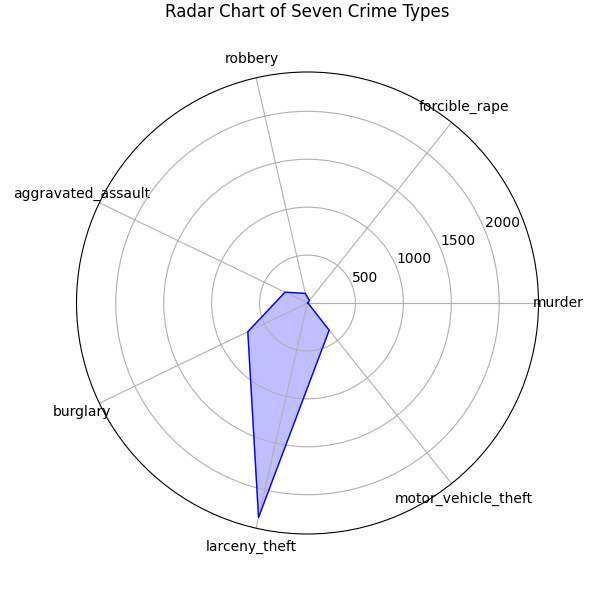
运行代码之后,会弹出一个图形窗口,展示七种犯罪类型的雷达图。在雷达图中,每个坐标轴代表一种犯罪类型,而多边形的顶点则表示该犯罪类型的均值。通过观察多边形的形状和各个顶点的位置,能够直观地对比不同犯罪类型之间的数值大小和相对关系。
(3)热力图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from scipy.stats import pearsonr
from matplotlib.colors import LinearSegmentedColormapdef create_correlation_matrix():# 读取数据df = pd.read_csv('crimeRatesByState2005.csv')# 剔除 United States 和 District of Columbia 两行数据df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 提取犯罪类型数据列crime_cols = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']crime_data = df[crime_cols]# 数据标准化scaler = StandardScaler()scaled_data = scaler.fit_transform(crime_data)# 计算相关系数矩阵corr_matrix = np.zeros((len(crime_cols), len(crime_cols)))for i in range(len(crime_cols)):for j in range(len(crime_cols)):corr, _ = pearsonr(scaled_data[:, i], scaled_data[:, j])corr_matrix[i, j] = corr# 生成自定义颜色映射,从蓝色到白色再到红色cmap = LinearSegmentedColormap.from_list('custom_cmap', ['blue', 'white','red'])# 绘制矩阵图plt.figure(figsize=(10, 8))plt.imshow(corr_matrix, cmap=cmap, vmin=-1, vmax=1)plt.xticks(range(len(crime_cols)), crime_cols, rotation=45, ha='right')plt.yticks(range(len(crime_cols)), crime_cols)plt.colorbar(label='Correlation Coefficient')plt.title('Correlation Matrix of Crime Types')# 在矩阵图中添加相关系数数值for i in range(len(crime_cols)):for j in range(len(crime_cols)):plt.text(j, i, f'{corr_matrix[i, j]:.2f}', ha='center', va='center', color='black' if abs(corr_matrix[i, j]) < 0.7 else 'white')plt.tight_layout()plt.show()if __name__ == "__main__":create_correlation_matrix()
代码解释:
-
数据读取与预处理:使用
pandas的read_csv函数读取 CSV 文件,然后通过布尔索引过滤掉United States和District of Columbia两行数据。 -
提取犯罪类型数据:从数据集中选取七种犯罪类型对应的列。
-
绘制散点图矩阵:使用
seaborn的pairplot函数绘制散点图矩阵,该矩阵会展示每两种犯罪类型之间的散点图,同时在对角线上显示各犯罪类型的单变量分布(通常是直方图)。 -
设置标题:为整个散点图矩阵添加标题。
-
显示图形:使用
plt.show()显示绘制好的图形。
运行结果:

运行代码后,会弹出一个图形窗口,展示七种犯罪类型之间的散点图矩阵。通过观察散点图的分布,可以直观地了解不同犯罪类型之间的关系。如果散点呈现出某种线性趋势,说明这两种犯罪类型可能存在一定的相关性;如果散点比较分散,则说明相关性较弱。对角线上的直方图可以展示每种犯罪类型的分布情况。
【实验总结】
本次实验围绕关系数据在大数据中的应用及可视化展开,通过多种Python程序实现的图表,深入探究了犯罪类型数据之间的关系。 在实验过程中,首先利用seaborn模块的jointplot方法,将散点图、密度分布图和直方图结合,对谋杀(murder)和入室盗窃(burglary)两种犯罪类型的关系进行探究。这种可视化方式从多个角度展示了数据的分布和相关性,直观呈现出两种犯罪类型在不同维度下的特征,为进一步分析提供了基础。 接着,运用pyecharts创建动态散点图,不仅展示了谋杀和入室盗窃数据的分布,还通过箭头形状和交互功能,使数据可视化更具动态性和趣味性,增强了对数据的理解和探索性。 针对七种犯罪类型之间的关系,分别使用散点图矩阵、主成分分析双标图、雷达图和热力图进行可视化。散点图矩阵展示了各犯罪类型两两之间的散点分布,帮助观察变量之间的潜在关系。主成分分析双标图通过降维,将高维数据在二维平面上展示,样本点和变量箭头的结合,直观反映了变量对主成分的贡献以及变量之间的相关性。雷达图则以独特的方式,将七种犯罪类型的均值在同一图表中呈现,方便对比不同犯罪类型的数值大小和相对关系。 通过这些实验,掌握了多种关系数据可视化方法,深入理解了不同图表在展示数据关系时的特点和优势。同时,也学会了运用Python中的pandas、seaborn、sklearn、matplotlib和pyecharts等库进行数据处理和图表绘制,提升了数据处理和可视化的实践能力。