【lammps】后处理 log.lammps
【lammps】后处理 log.lammps
直接运行命令查看输出(不重定向):
egrep '^[[:space:]]+(Step|Temp|Press|Pxx|Pyy|Pzz|Lx|Ly|Lz|Atoms|[0-9])' log.lammps
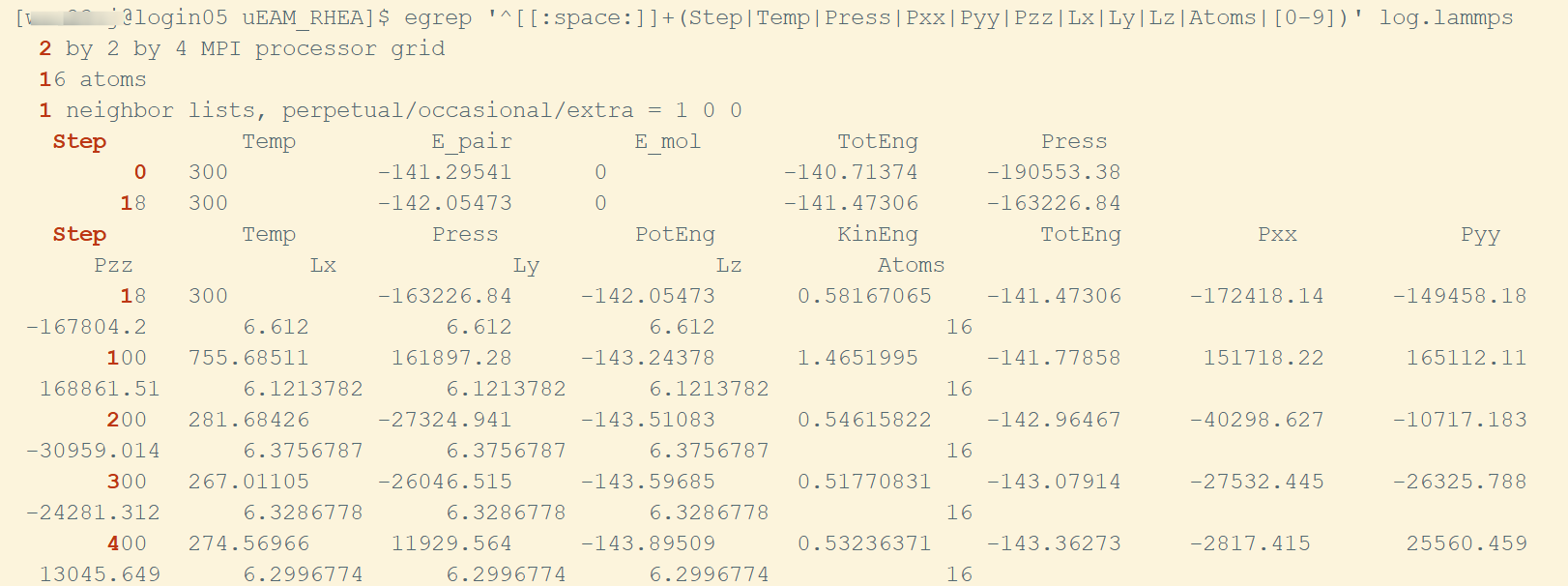
将上述内容重定向到新的文件中:
egrep '^[[:space:]]+(Step|Temp|Press|Pxx|Pyy|Pzz|Lx|Ly|Lz|Atoms|[0-9])' log.lammps > thermo_data.txt

提取完整表格
提取 标题行 + 所有数据行(排除其他无关内容),可以使用更精确的正则表达式:
# 匹配标题行(包含完整列名)
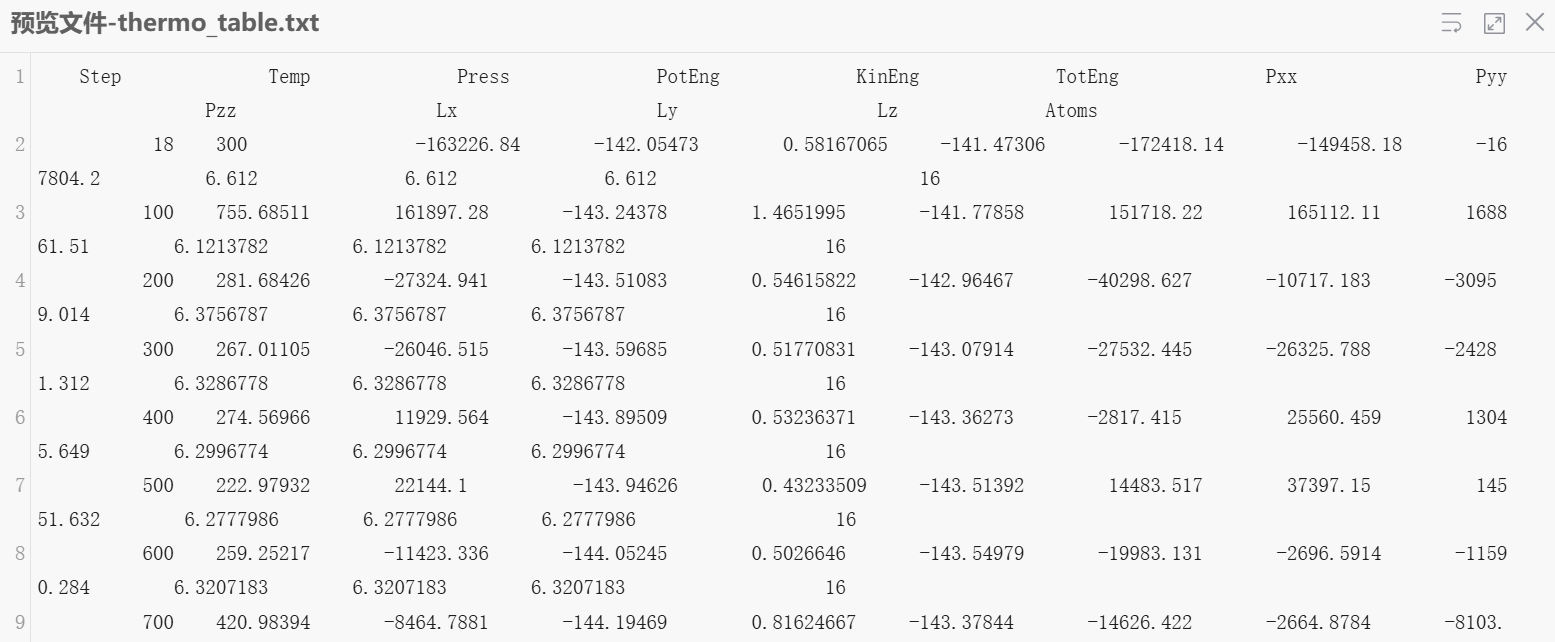
egrep '^[[:space:]]+Step[[:space:]]+Temp[[:space:]]+Press' log.lammps -A 100 > thermo_table.txt
-A 100:匹配标题行后,附带接下来的 100 行数据(根据实际数据量调整)。
解析:
egrep 等同于 grep -E,使用扩展正则表达式(无需对 |、+ 等符号加反斜杠转义)。
正则表达式核心符号
^:行首锚点(匹配行的开头)。
[[:space:]]:匹配任意空白字符(空格、制表符 \t 等),等价于 [ \t\r\n\f]。
+:前一个字符 / 组出现至少一次(即 [[:space:]]+ 表示一个或多个空白)。
(...):分组,用于将多个选项合并(如 (Step|Temp) 表示匹配 Step 或 Temp)。
|:或运算符(多选一)。
[0-9]:匹配任意数字(等价于 \d,但更通用)。
-A 100:-A 是 --after-context 的缩写,表示匹配后显示后续 100 行。
两者之间的区别:
egrep '^[[:space:]]+(Step|Temp|Press|Pxx|Pyy|Pzz|Lx|Ly|Lz|Atoms|[0-9])' log.lammps标题关键词或数字开头的行
egrep '^[[:space:]]+Step[[:space:]]+Temp[[:space:]]+Press' log.lammps -A 100 > thermo_table.txt
严格包含 Step Temp Press 的标题行