学成在线。。。
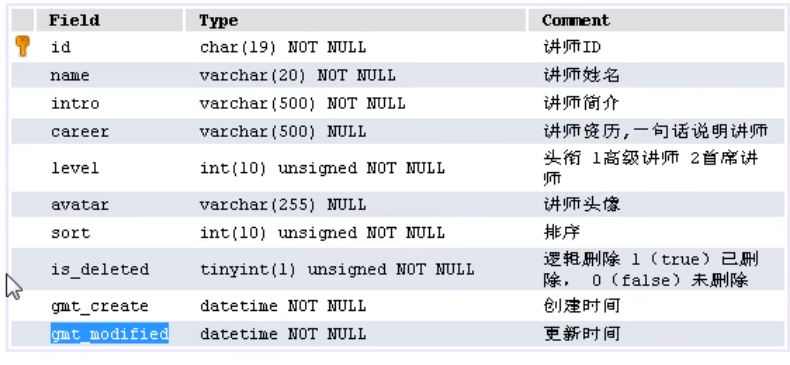
一:讲师管理
介绍:可以实现对讲师的分页展示,多条件组合分页查询,对讲师的添加,修改,删除操作。
针对于添加来说,使用requestBody注解,搭配postmapping接收数据,使用service层的对象,调用mapper方法,向数据库中保存数据。
修改:
先根据讲师id,查询出讲师,再去修改
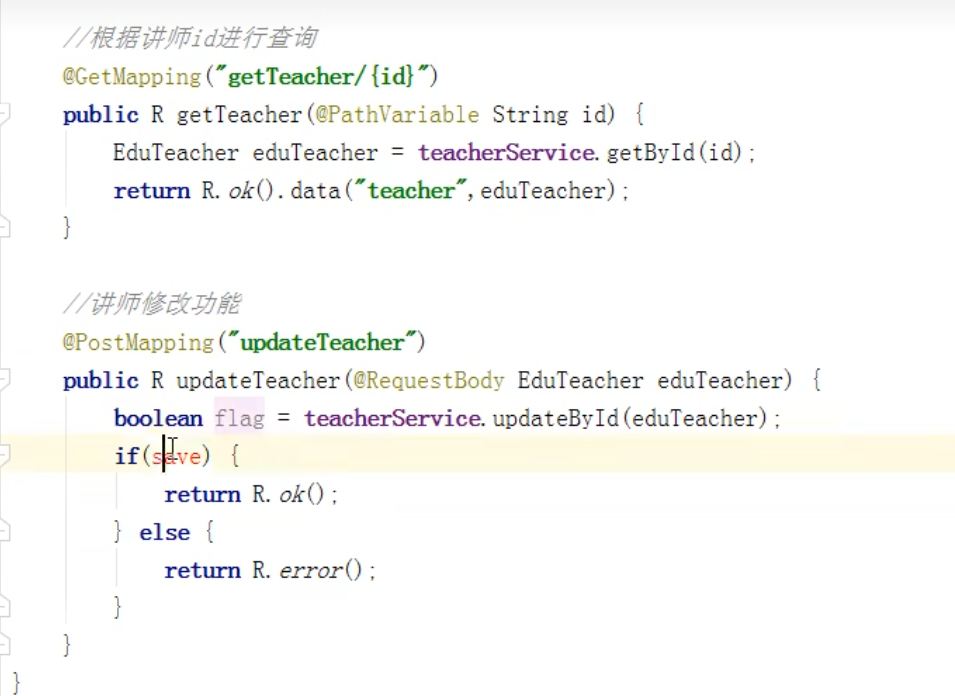
创建时间和更新时间在实体类中使用TabledField注解,实现自动填充。
对讲师分页展示;支持多条件组合查询教师;
分页展示:
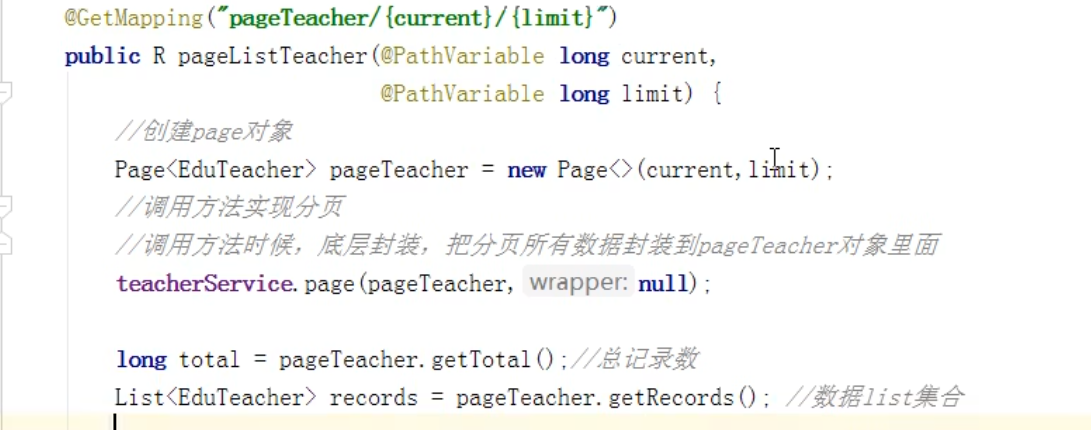
使用mp的分页插件,在接口中,通过路径,接收当前页和每页记录数,接着创建page对象,接收两个参数,一个是当前页码,一个是当前页的记录数。调用方法,把page对象传进去,会将分页所有数据封装到这个page对象当中,通过page对象,返回所有数据的一个list集合。
多条件组合带分页的查询:
用户选择不同的条件,可以查出不同的教师。
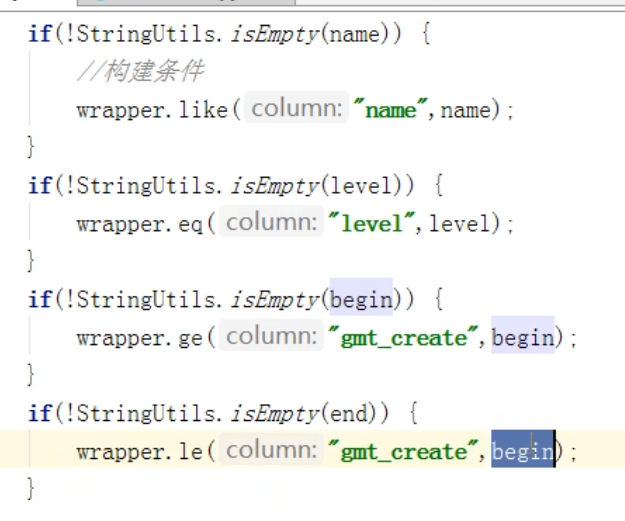
首先要把条件值封装到vo当中,把vo再传给接口。(vo中包括讲师名称,级别,开始和结束时间)。
然后会对传来的条件值进行判空,如果不为空,就拼接条件,使用page方法根据条件,查询出符合的数据,最后返回数据。

常用注解:
requestBody:前端用json传递数据,把数据封装到对应的对象当中。
需要搭配psot提交;
还要注意传来的数据是否可以为空,如果可以为空,就要设置required为false
reponseBody:用于返回json数据。
PathVariable:将url中的变量绑定到方法中的参数上。
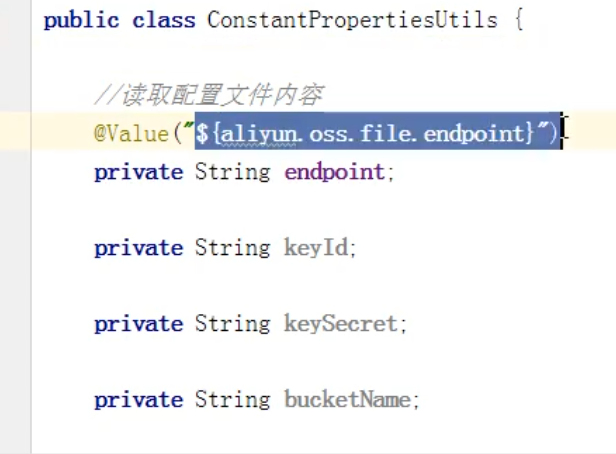
Value:用来读取配置文件中的数据,保存到变量中。
上传讲师头像:
将id和密钥保存到配置文件当中,使用常量类,读取配置文件中的内容。
在相关接口中,接收文件变量,使用阿里云的相关方法,先创建出一个oss实例
再获取一个文件输入流
调用oss实例中的put方法,实现上传,返回保存的文件路径
文件路径需要手动拼接出来:由桶的名称+站点名称+文件名称
方法的参数有:bucket名称,输入流,文件名


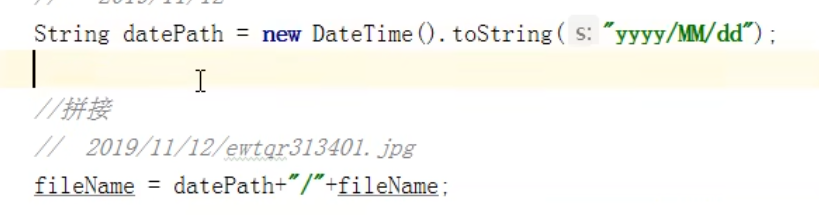 使用datetime获取当前时间,再把当前时间拼接到文件名称里面,这样在进行上传的时候,就可以在阿里云中根据时间,建立相应的文件夹,来对文件进行分类。
使用datetime获取当前时间,再把当前时间拼接到文件名称里面,这样在进行上传的时候,就可以在阿里云中根据时间,建立相应的文件夹,来对文件进行分类。
问题:
1:如何使用oss服务
在使用oss服务之前,需要在阿里云中创建出bucket,也就相当于一个文件夹,用来存储相关文件
再得到id和密钥,只有有了这个,才有相关权限去操作。
再去Java工程中引入相关依赖,就可以操作相关方法,上传相关文件。
2:多次上传文件,如果文件名相同会被覆盖,如何解决
通过使用uuid的random方法,给文件名称添加唯一的随机值。
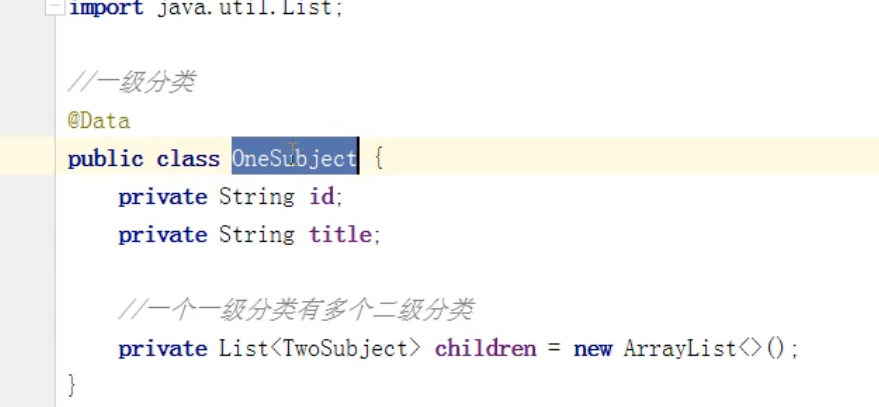
二:课程分类管理
课程分类管理是我负责开发的,负责展示相关课程,进行二级分类展示。
树形分类展示:
1:首先需要将数据存入到数据库中
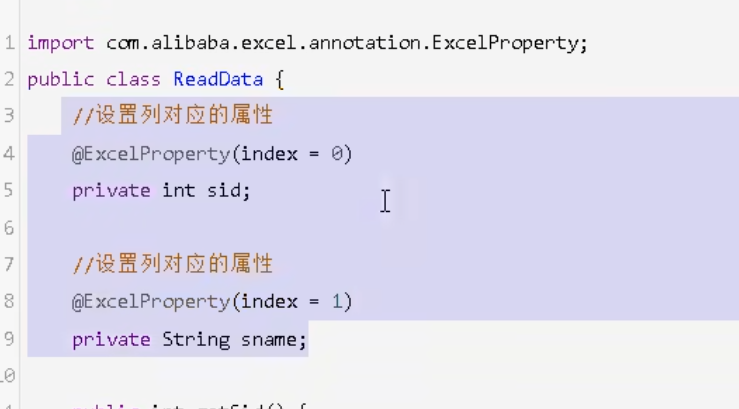
使用的easyexcel,读取数据是从磁盘中一行一行读取,而不是将文件一次性读到内存当中
根据excel的列表头创建对应的实体类
在接口中获取文件输入流
获取到文件之后,调用easyexcel的read方法进行读取,参数有输入流,实体类,监听器对象
接下来需要实现监听器这个类:
它是进行一行一行的读取数据的
监听器这个类,交给不了spring管理,那么在这个监听器中,就注入不了其他对象,所以就将其他对象传给监听器的构造方法,实现将其他对象注入到这个监听器类中。
这个类中有两个方法,一个是invoke方法,用来读取excel数据。
由于有每一行中第一个数据是一级分类,第二个数据是二级分类
所以就先读第一个数据,读取到数据库中,再读第二个数据,读取到数据库中
在进行读取时,要进行判断数据是否重复
是根据名称和parentid值进行判断,一级分类的parentid值都是0,二级分类的parentid值是它对应的一节分类的parentid值
2:存入之后,需要给前端返回数据,构建出前端需要的类型的数据
分析:最外层是一个json类型的数组,数组里面又有多个对象,每个对象中,有一级分类,又有一个数组,数组当中又有多个对象,对象中是二级分类。
其实就是最后返回一个list集合,这个集合里面存储一级分类的对象,在这个对象当中又有一个集合,用来存储二级分类对象。简单就是集合里面存对象,对象里面又存集合,
第一步:根据返回数据,建立对应的实体类
第二步: 在两个实体类之间表示关系:一个一级分类有多个二级分类。
第三步:在services层中编写业务:先查询出各自的一级分类和二级分类,返回的都是list类型的集合,因为包含多条记录,再依次进行封装。
根据parentid = 0,查询出一级分类,不等于0,查询出二级分类。
然后需要弄出一个桶,来存储封装数据。
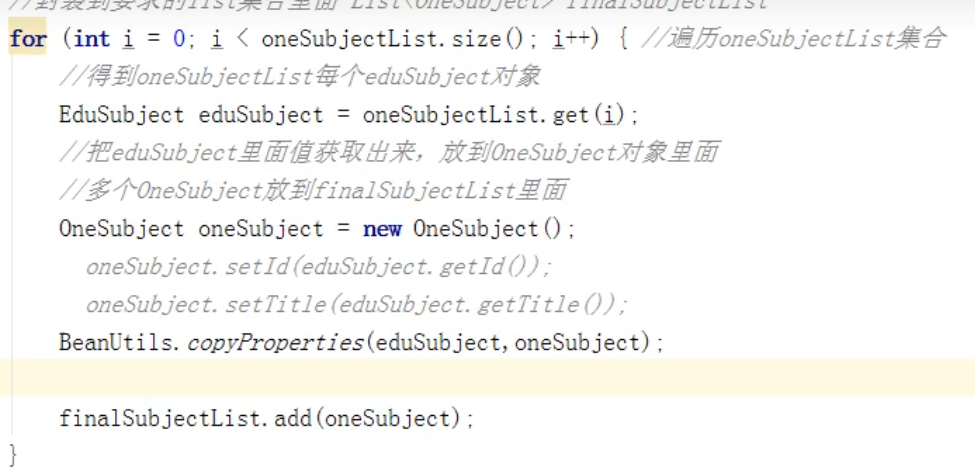
但是桶(list)里面存储的对象类型与查询出来的类型不一致,所以就需要遍历,再取值放入。取值取的是id和title。对象类型不同,但是里面要存储的值是相同的,外壳(类型)不同,但心是相同的,(即使有不同的,但是会选择相同的)我选择使用beanUtils里面的copy方法,放完之后,再把新对象添加到list(桶)当中
接着在这个循环里面,加一个循环,用来封装二级分类(就是在大桶里面,有对象(一级分类),在这个对象里面有个小桶,用来放二级分类对象)。
上面是把二级分类封装到list之中,但最后还有一步,是把list添加到children中!
list中有一节分类对象,一级分类对象里面有个list类型的children对象,这个children对象中存放list类型对象,这个list中保存了当前一节分类对象下的所有二级对象。


三:课程管理
表关系:
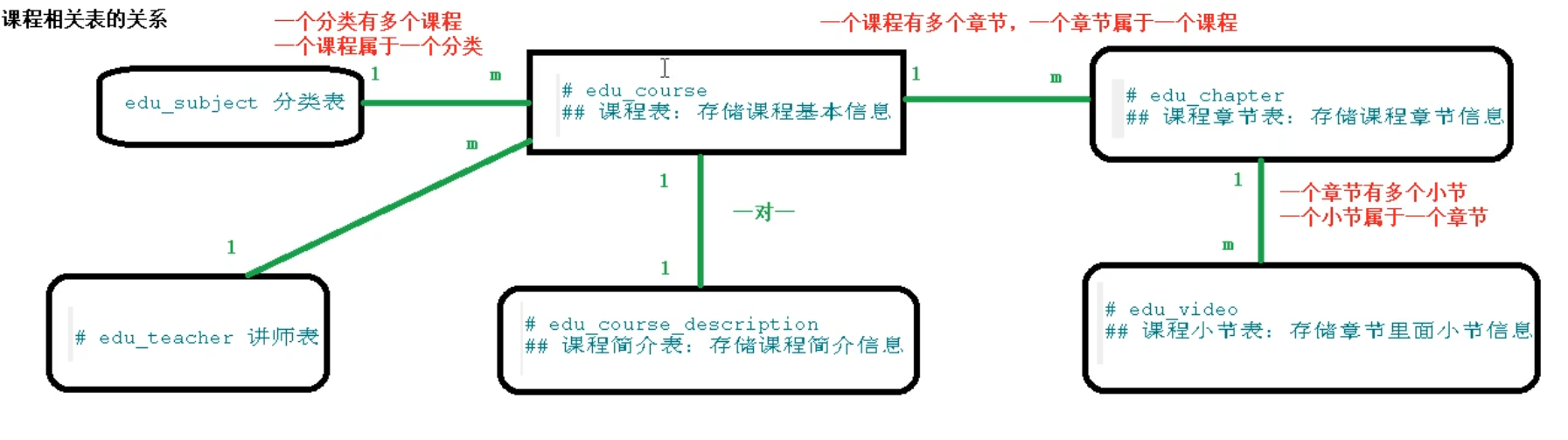
课程管理是我负责开发的,功能是可以发布课程,并对课程列表进行管理,针对于某个课程,可以对课程的基本信息进行修改,也可以对课程的大纲进行修改。
发布课程:
发布课程是分为三步:首先填写课程的基本信息,再去创建这一门课程的大纲,最后选择发布课程。
1: 在这个课程的基本信息(课程名称,讲师,简介)
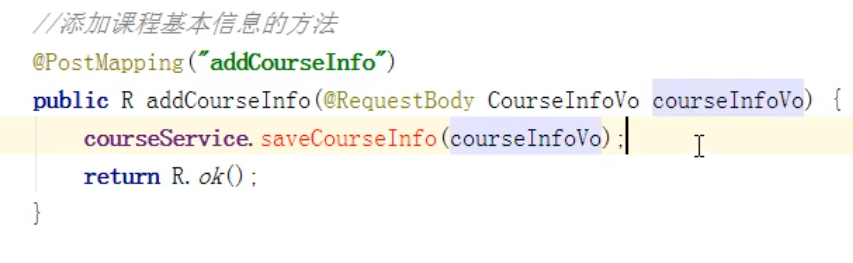
创建vo类,用来接收前端表单传来的数据,使用postmapping搭配requestbody。
向两张表传数据,课程基本信息表和课程简介表
在传数据之前,要把vo对象转变为课程对应实体类对象:使用的是beanutils的copy方法
2:大纲
由章节和小节组成,分为章节和小节,小节属于章节,先添加章节,再添加小节
1:展示章节和小节:
先根据课程id查询出对应的章节和小节,再进行封装
在查询之前,要创建两个vo类,用来传输数据;
在进行封装的时候,之前查询到的小节是当前课程的所有小节,所以在封装小节到章节里面时,要进行判断,只有这个小节对象的charperId和当前章节的id一致,才可以封装。
先在大循环中封装章节到大list中,每次封装完一个之后,就开启一个小循环,在当前章节里面封装小节,当前章节的所有小节,封装到小list之后,在小循环外面,把小list添加到children中

2:在大纲处可以选择上一步:进行修改课程基本信息
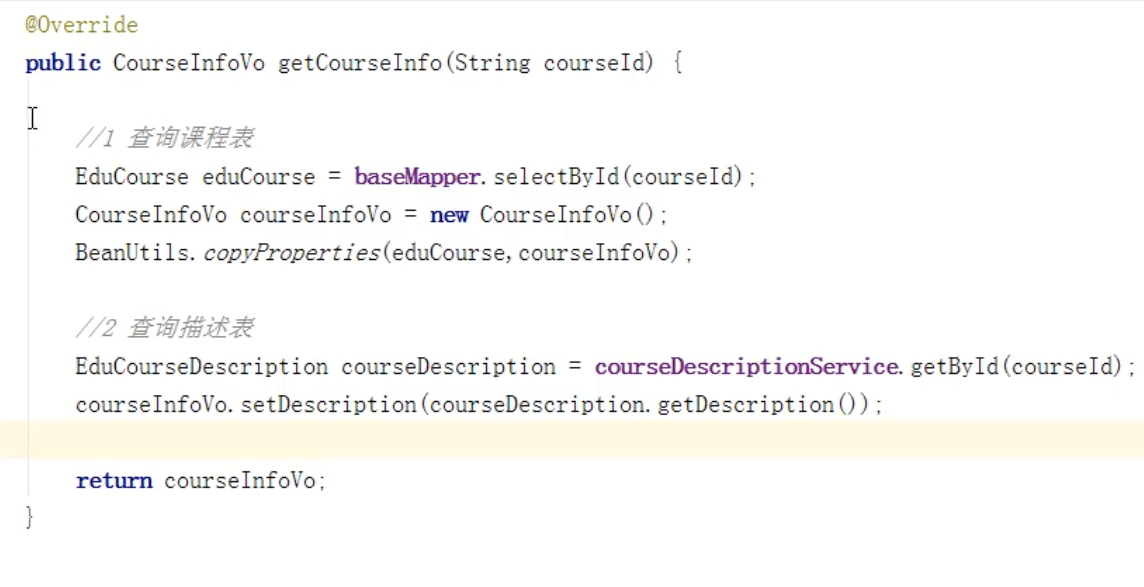
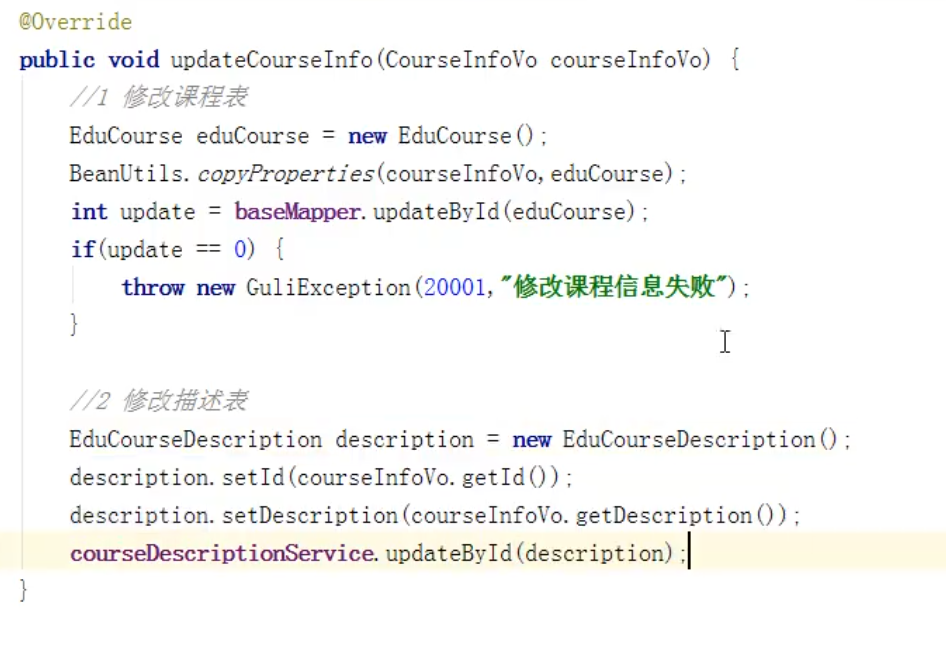
所以需要先查询出课程基本信息,在进行修改:
3:对章节的添加,查看,修改,删除操作。(很简单)
通过id,实体类接收数据,进行处理。
对于删除操作:
根据章节id,去判断这个章节下,是否有小节,如果有小节,就不能删除,如果没有,就可以进行删除操作。(判断条件是,使用count函数,对行记录进行判断,不为0,就代表有小节)
4:在小节中可以上传视频
使用阿里云的视频点播服务,能够将视频上传到云端,并且能够保证视频的安全;
最后返回视频id;
具体:在接口中把文件的输入流,文件名称等一些信息,传给阿里云提供的上传方法,通过response对象,获取对应视频的id,进行返回即可。
注意:上传文件时,可以对文件大小进行限制;(在配置文件中进行配置即可)
4:在上传页面,上传视频之后,可以点击叉号,删除视频,这里删除视频,删除的是云端的视频
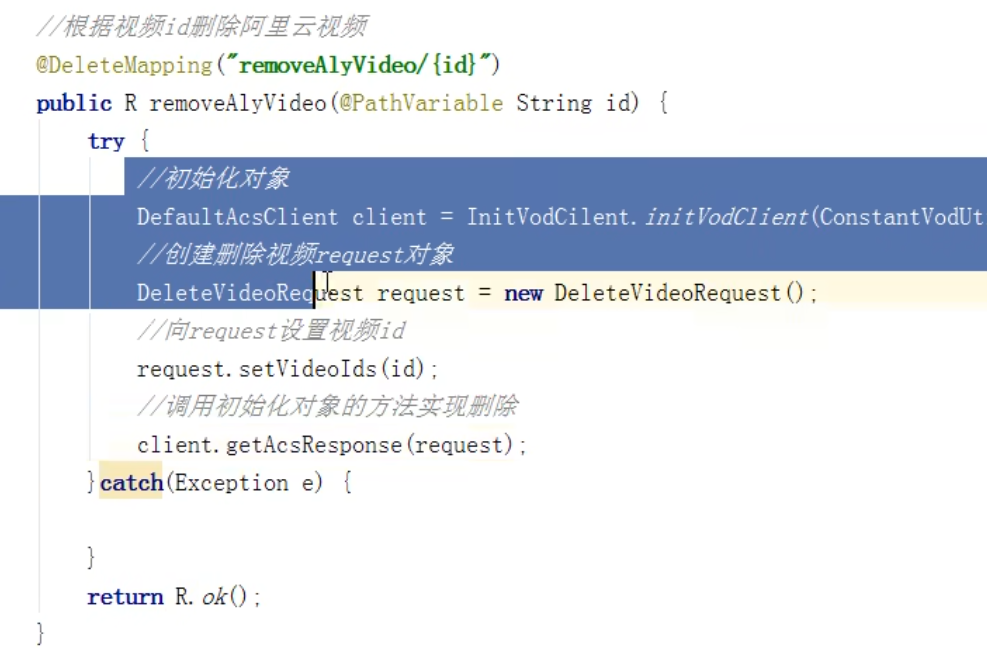
使用阿里云提供的相关方法,初始化client对象,创建删除对象,给这个删除对象传入视频id,把这个删除对象传给client对象的一个方法实现删除。
通过阿里云提供的一个文档,可以快速写出
3:最终发布
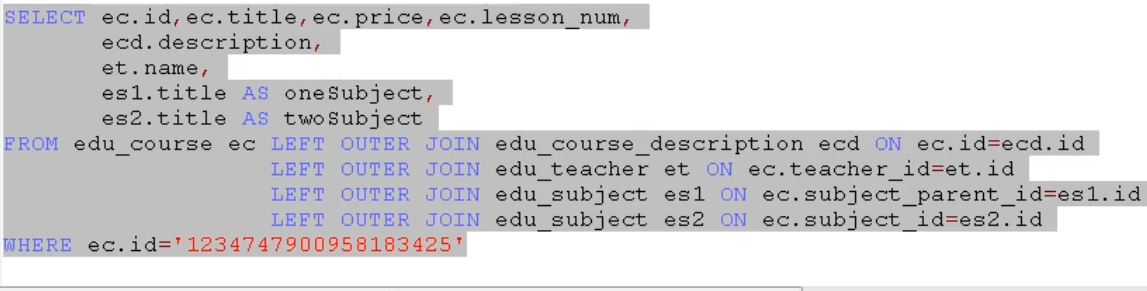
显示要发布的课程的基本信息 名称+分类+讲师+简介
多表查询
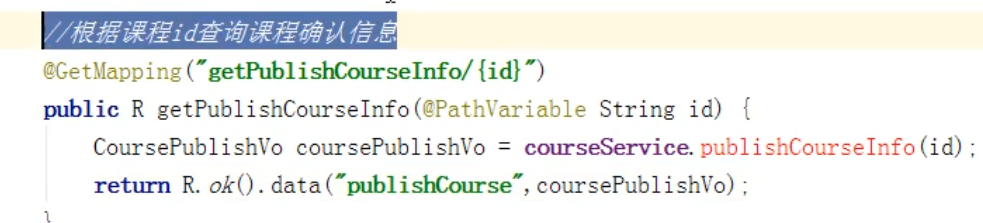
创建好实体类vo,用于返回数据,因为在确认之前,要把数据显示到页面上。
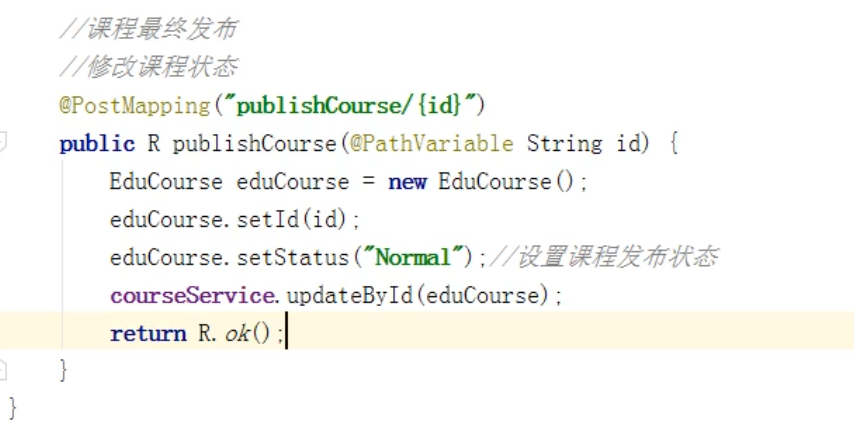
修改课程的状态,只有课程的状态是normal,用户才可以看到
课程列表
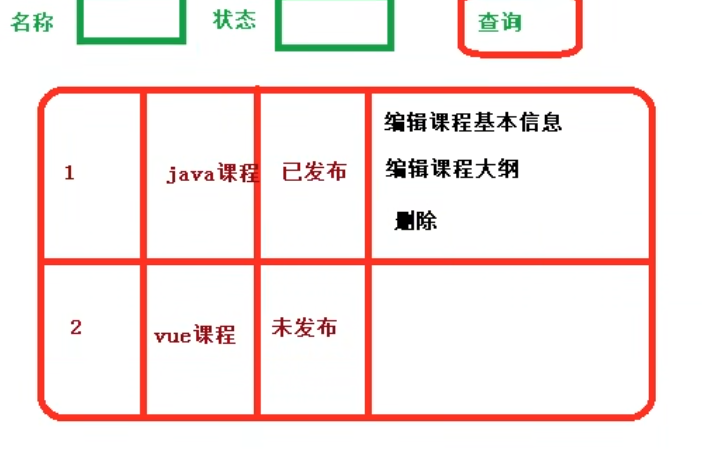
1:展示所有课程
向数据库中查询所有数据,返回list
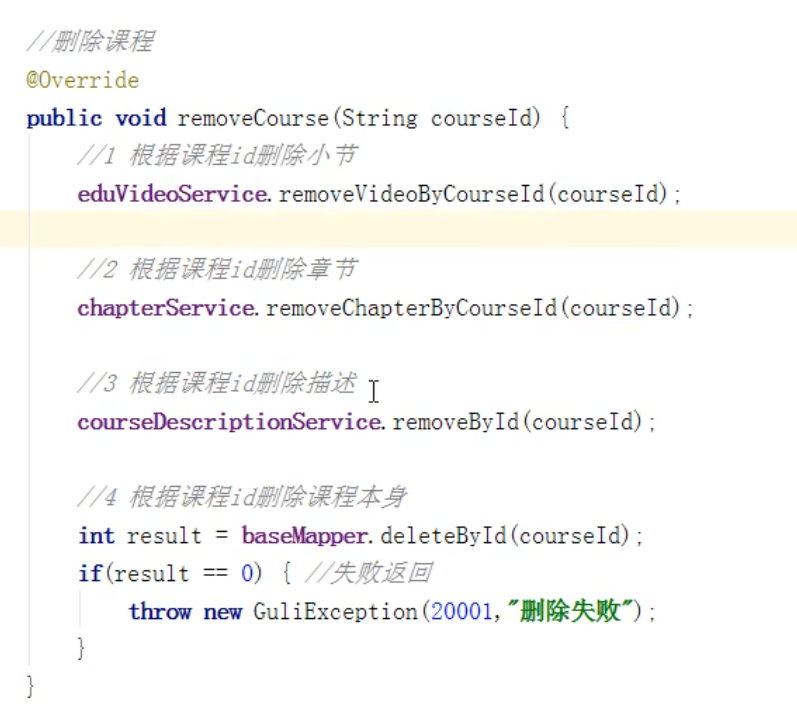
2:删除课程
在数据库中要删除这个课程包含的视频,小节,章节,课程描述和课程本身。
删除课程的controller层:
services层:

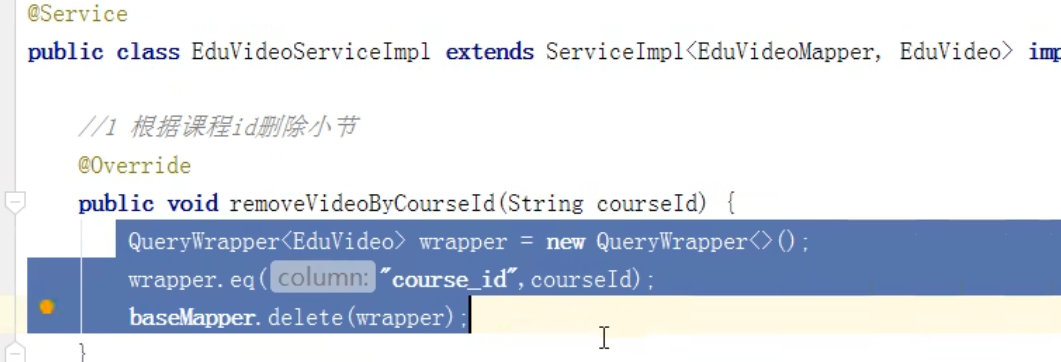
删除小节:
存储到阿里云如何保证视频安全的?
视频文件被保存在阿里云的一个私有文件夹中,外界是访问不到的;
同时,在进行上传时,需要获得阿里云的id和密钥,才能有上传的资格;
上传文件使用的https加密传输
在章节中可以
上传视频,删除视频,上传视频使用的是阿里云的视频点播服务,将上传的视频保存到阿里云当中;
也可以删除小节中的视频,或者是这个小节也可以删除
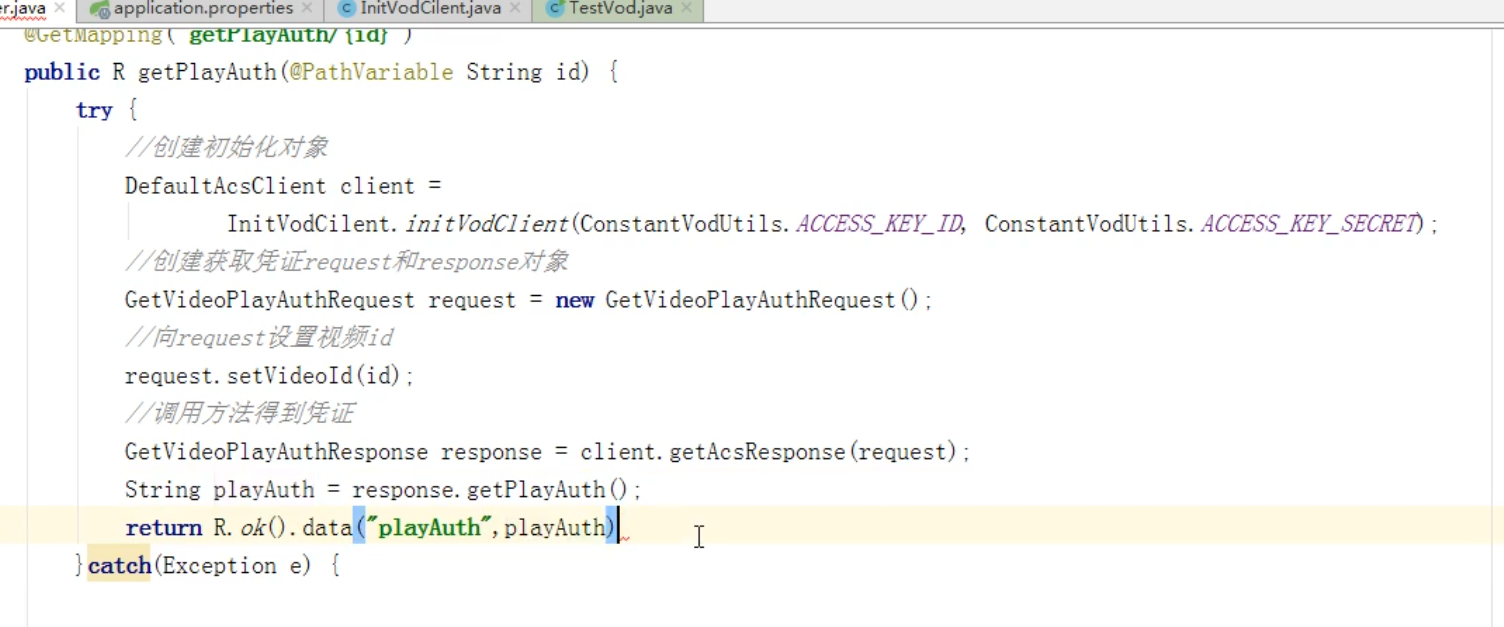
3:在小节中查看视频
点击小节,可以查看上传的视频,使用阿里云提供相应的方法,根据视频id,获取该视频的播放凭证,并返回。
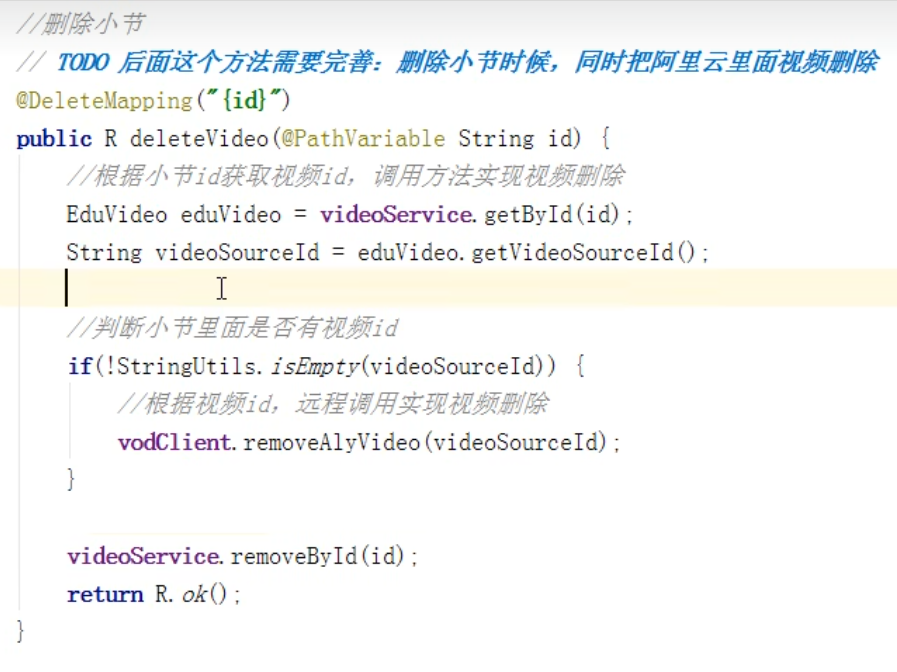
4:删除某个小节
根据小节id,获取视频id,再判断这个小节中是否有视频,使用StringUtils里面的方法进行判断,只有有视频,才进行删除,最后再删除这个小节。
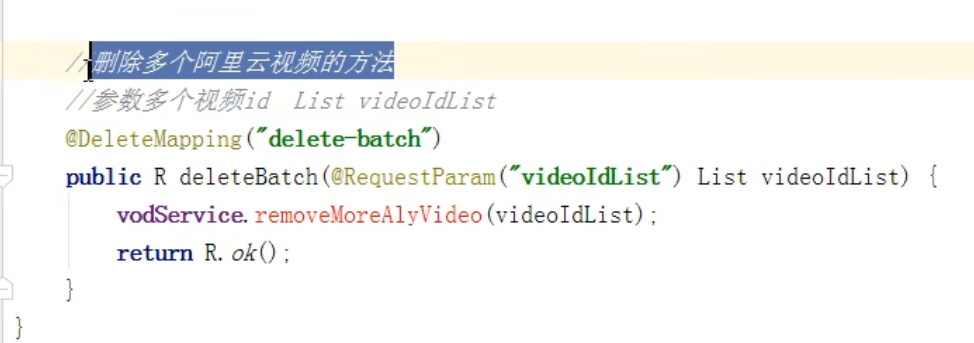
这是删除多个视频,就需要有多个视频id,使用list集合来存储id。
5:删除课程
(依次删除小节(视频),章节,描述,基本信息)
首先需要删除这个课程里面的所有视频
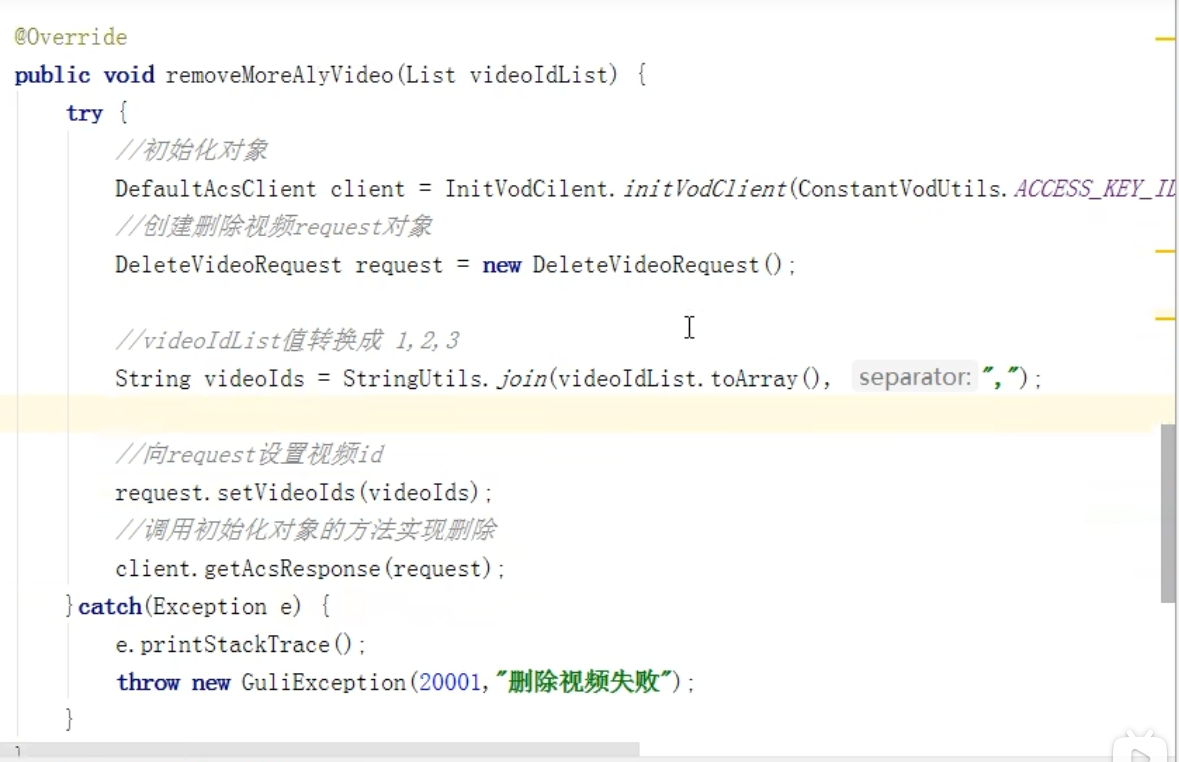
使用list集合获取多个视频的id,随后将多个id,以字符串的形式传给负责删除视频的request对象进行删除。(如何转化成字符串呢?可以遍历这个集合中的每个值,再给每个值拼接逗号,传过去,也可以;也可以使用stringutils的join方法,(是阿帕奇里面的方法)将list集合中的值,以逗号进行分割,返回值是string类型)
这个是删除多个视频的方法
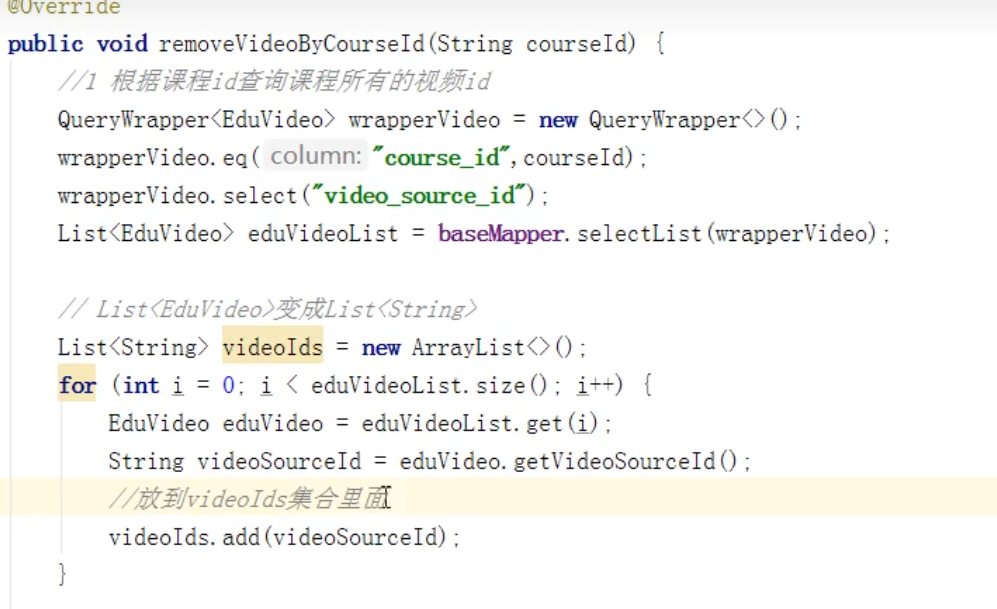
这个是根据课程id,删除某个小节的方法
会调用上个方法,删除视频,但是再调用之前,要准备数据,什么数据?多个视频的id,通过课程id获得,返回一个list集合类型的对象,但是这个集合中要存放的值的类型是string,所以要转换一下,new出一个新的list集合,这个集合的值的类型要求是string,所以遍历原集合,获取视频id,放到新的集合当中
在这个方法中,首先要根据课程id,查询出所有视频,获取到的集合,里面存储的是其他对象类型的,但是删除视频的接口中,集合中要存储string类型的值,所以只能通过遍历,将原集合中的每个对象中的视频id得到,赋值给string类型的变量,再将变量值放到新的集合当中。
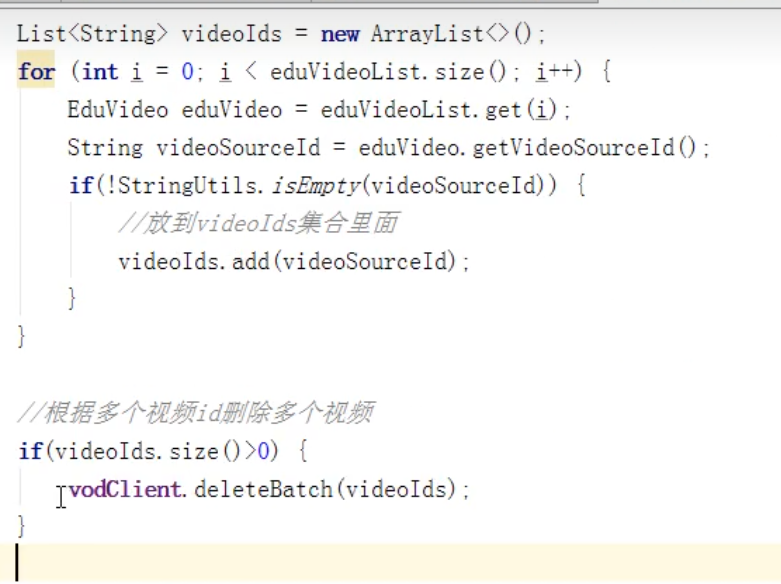
这个是上个方法的优化:
其中获取到的eduVideo对象中可能会没有视频id,因为某个小节中可能会没有视频,所以再进行放之前,通过get获取id之后,看看这个video里面有没有值,最后这个循环遍历完之后,也就是放完之后,可能这个课程里面全都没有视频,也就是新的这个集合中可能没有东西,所以再调用删除视频的方法时,要加个if条件,使用size方法,只有当大于0的时候,才去调用。
四:直播管理
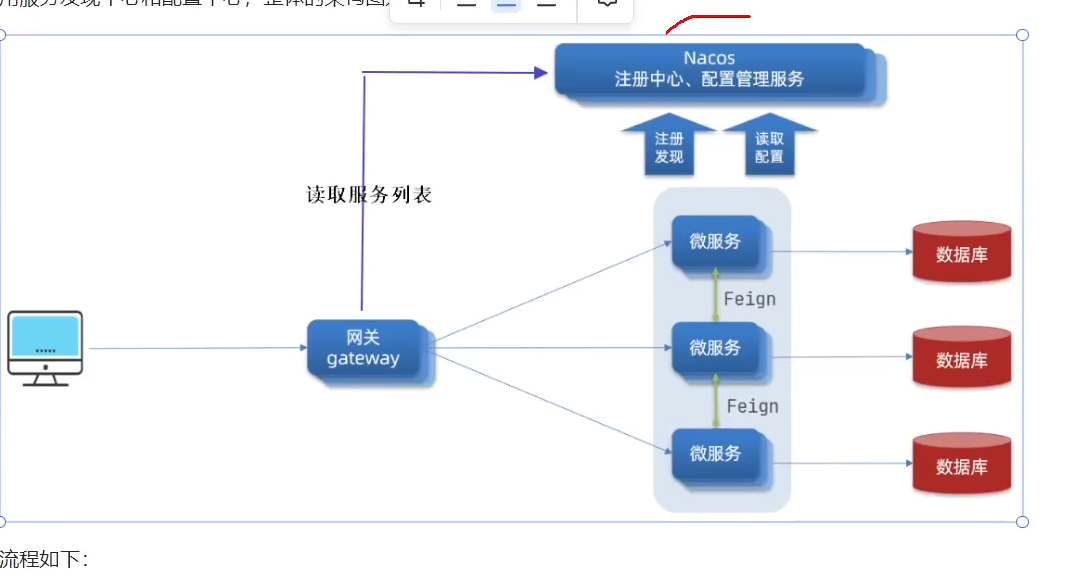
五:媒资管理
使用minio这样的一个分布式文件系统,进行上传图片,视频等一些重要文件。
minio是用来存储文件的,能够保证数据安全。
1)媒资管理服务是干啥的?
对文件进行统一管理的.比方说:文件上传,文件的校验等等.
2)为什么要使用minio这个系统呢?
因为他开源,使用简单,功能强大
3)如何校验文件的完整性?
比较原始文件和下载的文件的md5,如果不相等,就代表不完整.
4)输入流是什么?
类似于水流吧,只能单向流动,按照顺序处理数据;
并且是逐步处理数据,不用把全部数据一次性加载到内存中
5)为什么要把所有服务的配置文件交给nacos统一管理?
在进行更改的时候,修改的效率很高
6)nacos是什么?
nacos是注册中心也是配置中心
每个微服务需要把相关信息提交给nacos,进行注册
7)为什么要使用minio呢?存到本地不就可以了吗?
本地存储不够大,并且不能很好保证数据安全;
minio拥有巨大的存储空间,并且能够保证数据安全。
8)如何保证的数据安全?
拥有多副本机制
即使某一块文件丢失了,它还有副本。
9)你是如何使用的minio?
再使用之前,需要在程序中添加他的依赖;并且它还提供了示例方法,用来上传文件,删除文件,下载文件,在程序中就是使用他提供的方法的核心逻辑,进行改造,实现我们想要的功能。
上传方法:使用之前,需要初始化一个minio对象,接着再创建一个bucket,用来存放上传的文件
调用minio对象的upload方法,进行上传文件。
在上传之前,需要给这个方法准备一些参数信息:桶名称,文件的本地路径,上传之后的文件名
删除方法:调用remove方法即可,给方法传入相关要删除的文件的参数:名称,桶名称等
下载方法:调用get方法,返回的数据用输入流接收,指定一个输出流,使用beanutils的copy方法拷贝到输出流。同时还要校验下载下来的文件是否完整。如何做到的?
对原文件和下载下来的文件进行md5,如果文件相同,会得到相同的字符串,对得到的一串字符串进行比较,如果相等,就代表完整。


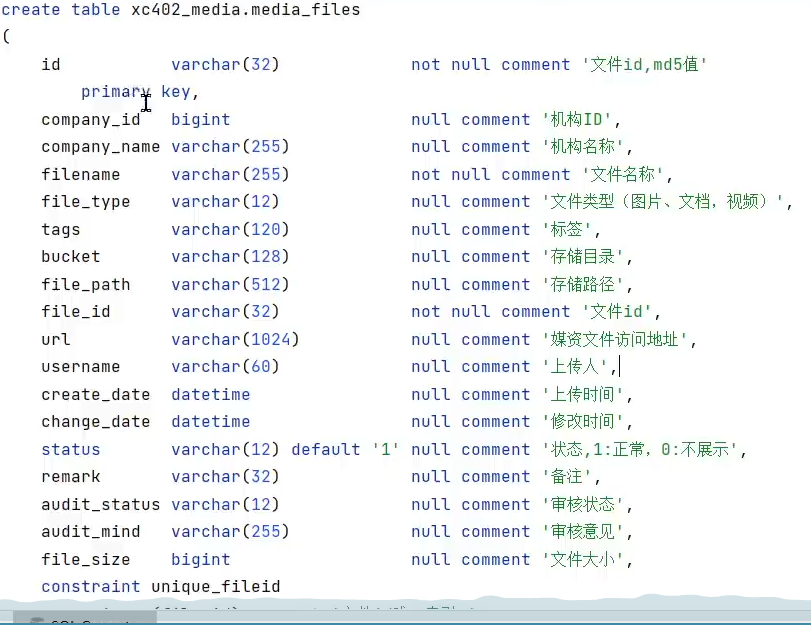
前端点击保存时,会将课程的相关信息和图片地址保存到内容服务中的数据库中的课程表

1:上传图片
前端选择上传文件,请求发到后端,把文件相关信息传给后端,调用媒资服务,将图片保存到minio系统中,并将图片相关信息保存到媒资服务的文件表中,给前端返回相关信息,前端点击完成上传后,会将图片地址和课程的相关信息保存到内容服务的课程表中。
用到的表有媒资服务的文件表,和内容服务的课程表。
1)图片如何保存到minio系统中的?
接收前端传来的文件对象,在接口中调用minio的sdk的相关方法,传递相关参数,把图片上传到minio系统中的桶当中。
2)参数有哪些?
文件的本地路径,保存到系统中的文件名字,桶的名字。
3)会不会上传失败呢?
会的,上传方法完成后,会返回一个布尔值,对布尔值进行判断,如果为false,就抛出相关异常。
4)那你是如何将文件信息保存到数据库中的?
先去判断这个文件之前是否已经存在过了; 如何判断的?拿文件的md5值在数据库中查询
如果返回的对象为空,就代表不存在,再继续后面操作;
使用beanutils的copy方法,将对象拷贝一下,再设置文件的MD5,桶的名字,等一些信息,插入到数据库中。
5)有没有可能插入失败?
有,判断insert方法返回的值是否为0,就知道是否插入失败了,失败后,你要干什么呢?
打个日志
6)那给前端返回的什么信息,就是刚刚插入到数据库的信息,只不过使用beanutils的copy方法,换了一下对象类型。
7) 前端给后端传了什么值?
文件路径,名称,类型,大小,等等
8)对数据库进行操作,有没有对数据进行保护呢?
有,在方法上加了transactional注解,当发生异常后,会进行事务回滚,保护数据安全。
9)什么是分布式文件系统?
它是一个将文件存储和管理吧,分布在多个计算机上的系统
10)requestPart是什么意思?
用来接收前端传来的文件,将文件绑定到方法中的参数中。
视频上传与处理
通过媒资服务将视频上传到minio中后,将相关信息记录在文件表中;
然后使用分布式任务调度去处理视频,调度中心发送请求,执行器接收请求,用来处理视频
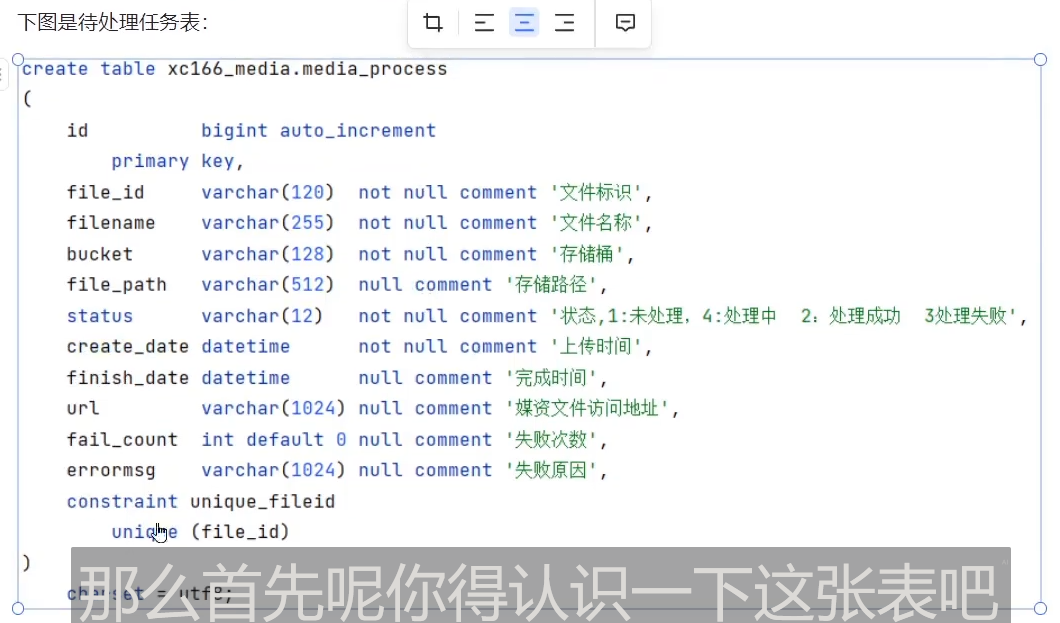
在待处理任务表中读取相关信息,去处理相应的任务。
用任务编号除以执行器的数量,余数等于几,就由序号是几的执行器去处理。处理完之后,将处理结果更新到历史任务处理表中。
通过文件id,就可以在文件表中找到对应的文件,通过状态,来实现任务的幂等性,处理成功之后,设置状态值为2,随后,删除这条记录,移入历史任务处理表中,还有失败次数,还会把url更新到文件表中
-----具体做法:
当将信息记录在文件表中后,继续将信息记录在待处理任务表中
判断文件类型,符合文件类型的,才会加入到这张表中。
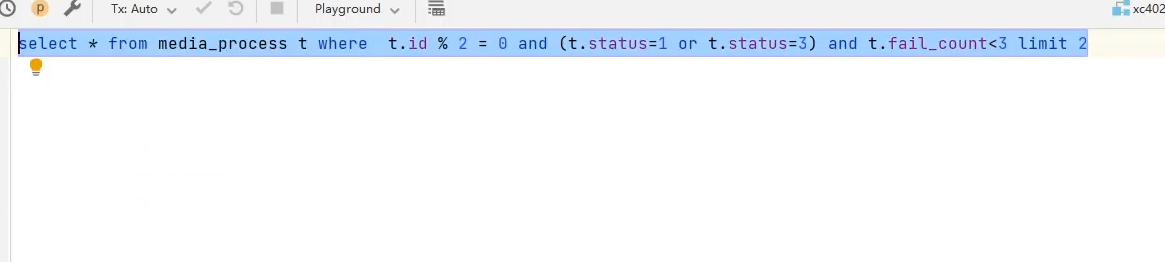
接着执行器去查询待处理任务
这个是mapper接口:

现在有一个问题,需要解决,就是执行器是分布式部署,无法保证同一个视频只有一个执行器去处理,所以就使用分布式锁去处理这个问题,让多个执行器同时去争抢一把锁,谁抢到了谁就执行。
syn锁只适用一个虚拟机内部使用,现在是多个虚拟机去抢同一把锁,所以可以选择用数据库实现分布式锁
使用的是乐观锁来实现分布式锁,什么是乐观锁,在执行之前,不加锁,认为没有人和我竞争,直接去执行,执行失败,就重试,直到达到最大失败次数,或者执行成功。
具体是如何实现的呢?
我设置的是给状态这个字段添加一个值,是处理中,只要执行时,就更新这个字段为处理中,谁执行成功了,谁就相当于拿到锁了,再去处理接下来的操作,这样其他线程就无法执行了,它就会重试了
下面是代码:谁可以执行,谁就有资格了!!
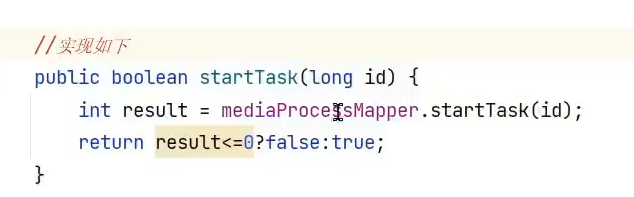
一个更新的接口(最后的操作) 参数有:任务id,任务状态,任务url,失败信息
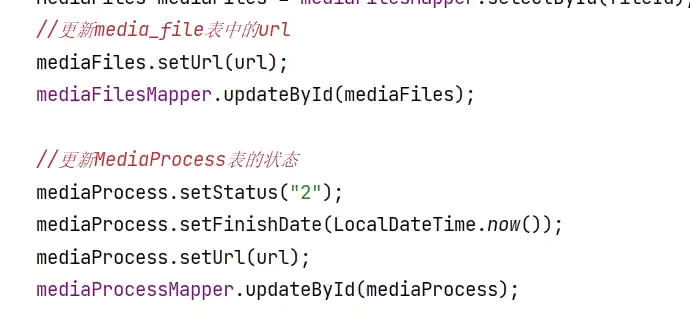
对任务处理结束后,需要去更新表记录,如果执行成功,在文件表中,添加视频的url地址,在待处理任务表中更新任务状态,url和完成时间将此条记录复制到历史任务处理表中,把待处理任务表中的这条记录删掉,如果执行失败,在待处理任务表中设置失败次数 ,添加失败原因
具体:在更新之前,需要先查询,拿出这条记录,设置相关的值,再把这条记录更新到这张表中;
如何复制记录呢?
先准备出数据,new一个待处理任务对象,使用beanutils的copy方法,进行赋值,再调用insert方法插入这条记录。
最后根据任务id,删除掉这个任务在待处理任务表中

现在写出一个任务处理类,在这个类中会去完成视频处理的任务
2:断点续传
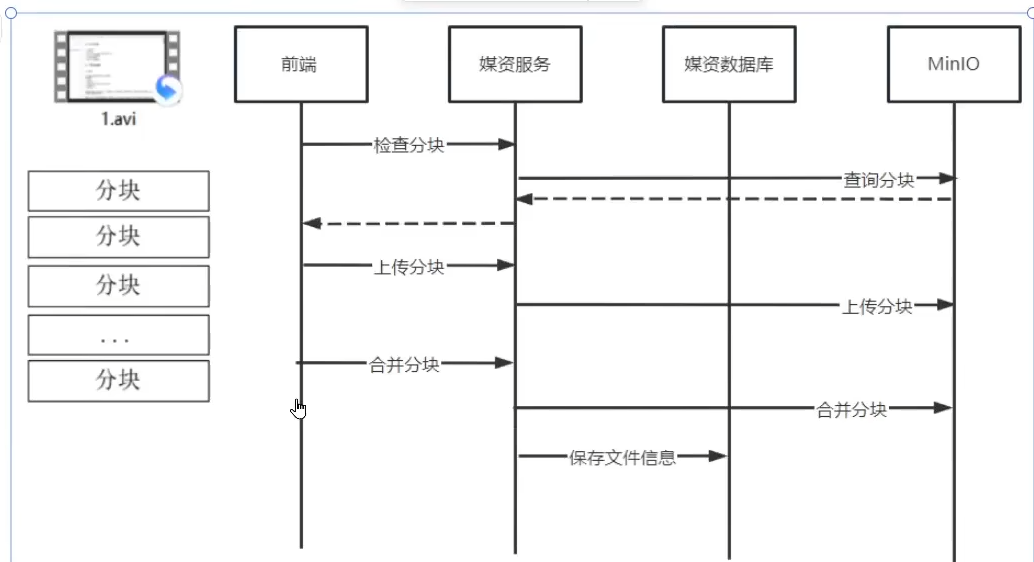
当用户进行上传比较大的文件时,发生网络断开后,停止上传了,当网络恢复后,用户可以继续上传,不用重新上传。
步骤:
先根据md5,校验文件是否存在,如果存在就不用上传了
不存在,前端就会把文件分成块,在上传前,后端会进行校验,该分块是否存在,如果存在,前端就不在上传,继续进行下一块。
待上传完毕后,服务会将分块按照顺序合并
合并完之后,会根据文件的md5值进行判断,文件是否上传完整,如果上传失败,需要重新进行上传。
1)如何校验分块文件是否存在?
前端给服务传来当前文件的md5值和分块的序号就可以知道分块文件是否存在于minio中
因为在minio中分块文件是根据md5的前两位作为子目录 ,序号作为分块的名字
通过这两个数据就可以去minio中查询
2)校验文件,是校验哪的文件?如何校验
存储在数据库中的文件的id,是用文件的md5赋值的,
校验数据库和minio中的。因为可能数据库中有,minio中没有,这种情况也是需要进行存储的。
先检查数据库中是否有,如果有,再检查minio中是否有,通过get方法得到后,通过输入流接收,判断输入流是否为空即可
3)如何校验文件是否存在?
先去数据库中查,如果数据库存在,再查询minio;
如果数据库中没有,就选择上传
4)分块文件是如何上传的?
获取分块文件的MD5值和序号,取MD5的前两位作为目录,序号为名字 ,将这些信息传给uoload方法即可上传
5)如何合并的?
找到分块文件,使用minio中的方法合并;
合并后,将原文件与合成文件通过md5进行校验

3:视频编码
当视频成功上传之后,需要对视频进行编码。
4:分布式任务调度
在多台计算机上,以固定的时间间隔,去执行固定的任务
我使用的是xxl-job,实现任务调度
它是由两部分组成,调度中心和执行器
调度中心是负责调度的,发出调度请求,执行器负责接收请求,并去执行任务。
1:写一个任务类,在类中写任务方法
2:在调度中心里面的任务管理去设置这个任务的调度策略
1)那你这个是如何防止数据被重复执行的呢?
1:调度中心会告诉每个执行器,总共有多少个执行器,当前这个执行器是第几个 。
这样我们就可以自定义一个分配逻辑进行分配,保证不会重复执行。
2:还会设置调度过期策略和阻塞处理策略
阻塞处理策略:当执行器执行任务时,调度中心又发起请求了 ,此时可以选择丢弃,覆盖,我们一般是选择丢弃,下一轮再执行,如果选择覆盖,可能会导致任务被重复执行。
同时针对于调度过期策略,我们设置的是忽略
意思是调度中心如果在该调度的时候没有调度,然后再去选择调度,可能我们的执行器还在执行任务,这时可能会导致重复执行,所以让执行器选择忽略本次调度,重新计算触发时间
3:同时还要保证任务的幂等性
就是无论做多少次重复操作,都只向数据库插入一条数据。
4:如何保证的?
通过乐观锁,在更新数据时,根据乐观锁状态去更新;
给任务一个标识,只有做完了的任务,才会去更新标识