transformer-实现单层encoder_layer
Encoder Layer
-
论文地址
https://arxiv.org/pdf/1706.03762
Encoder层介绍
-
Encoder层是Transformer编码器的核心组件,由多头自注意力和前馈神经网络两个子层构成。每个子层都包含残差连接(Residual Connection)和层归一化(Layer Normalization),有效缓解梯度消失问题并加速训练。
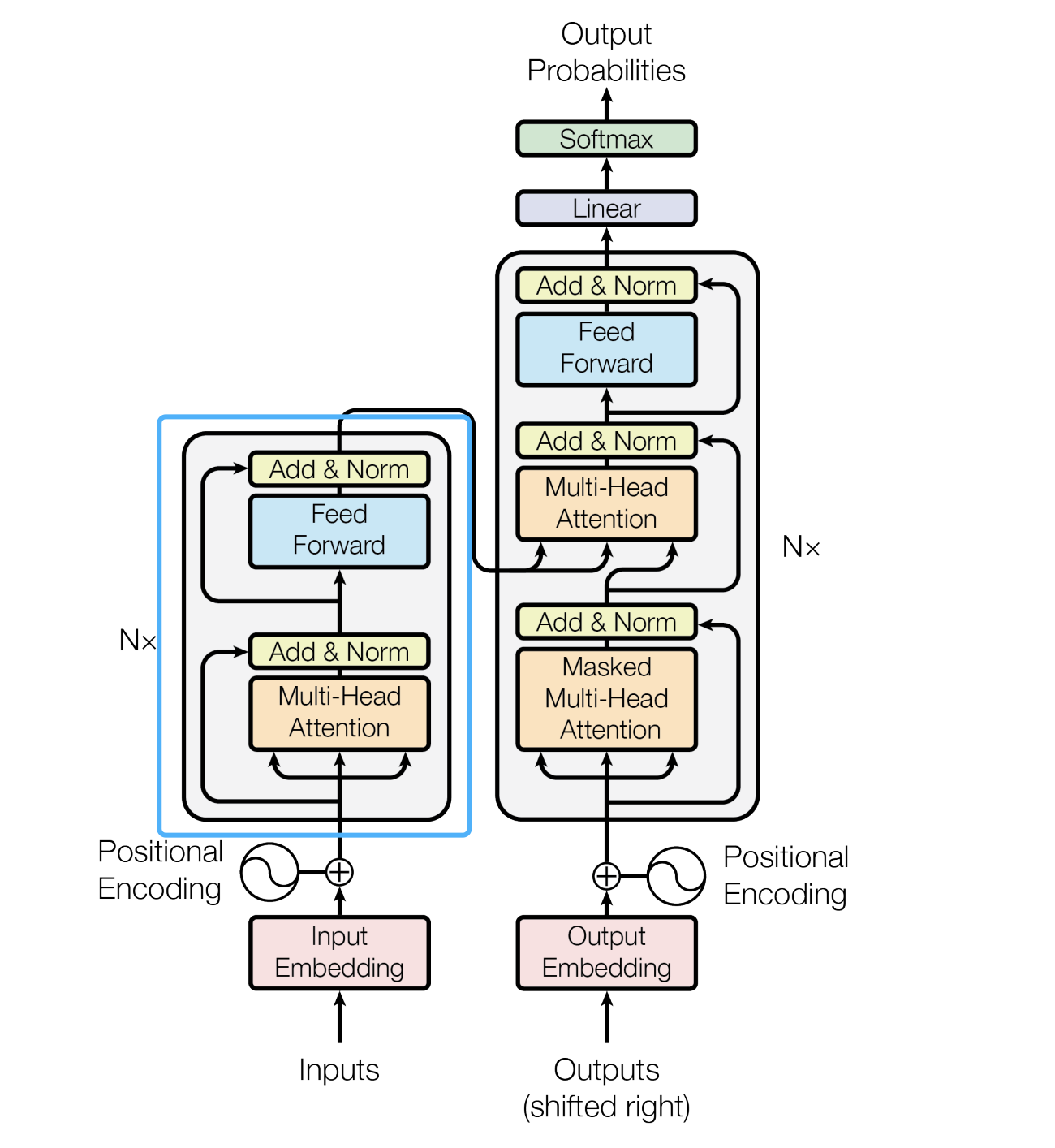
今天这里实现的是上图中蓝色框中的单层EncoderLayer,不包含 embedding和位置编码
主要处理流程:
- 多头自注意力机制:建立序列内部元素之间的依赖关系
- 前馈神经网络:进行非线性特征变换
- 残差连接 + 层归一化:在两个子层后各执行一次
- Dropout:最终输出前进行随机失活
数学表达
-
子层处理流程公式化表示:
LayerOutput = LayerNorm ( x + Sublayer ( x ) ) \text{LayerOutput} = \text{LayerNorm}(x + \text{Sublayer}(x)) LayerOutput=LayerNorm(x+Sublayer(x))对于Encoder层具体展开:
z = LayerNorm ( x + MultiHeadAttention ( x ) ) o u t = LayerNorm ( z + FeedForward ( z ) ) \begin{aligned} z &= \text{LayerNorm}(x + \text{MultiHeadAttention}(x)) \\ out &= \text{LayerNorm}(z + \text{FeedForward}(z)) \end{aligned} zout=LayerNorm(x+MultiHeadAttention(x))=LayerNorm(z+FeedForward(z))
代码实现
-
其他层的实现
层名 链接 PositionEncoding https://blog.csdn.net/hbkybkzw/article/details/147431820 calculate_attention https://blog.csdn.net/hbkybkzw/article/details/147462845 MultiHeadAttention https://blog.csdn.net/hbkybkzw/article/details/147490387 FeedForward https://blog.csdn.net/hbkybkzw/article/details/147515883 LayerNorm https://blog.csdn.net/hbkybkzw/article/details/147516529 下面统一在before.py中导入
-
实现单层的encoder层
import torch from torch import nnfrom before import PositionEncoding,calculate_attention,MultiHeadAttention,FeedForward,LayerNormclass EncoderLayer(nn.Module):"""Transformer编码器层"""def __init__(self, n_heads, d_model, d_ff, dropout_prob=0.1):super(EncoderLayer, self).__init__()self.self_multi_head_att = MultiHeadAttention(n_heads, d_model, dropout_prob)self.ffn = FeedForward(d_model, d_ff, dropout_prob)self.norm1 = LayerNorm(d_model)self.norm2 = LayerNorm(d_model)self.dropout = nn.Dropout(dropout_prob)def forward(self, x, mask=None):# 自注意力子层_x = x # 原始输入保存用于残差连接att_out = self.self_multi_head_att(x, x, x, mask)att_out += _x # 残差连接att_out = self.norm1(att_out) # 层归一化# 前馈子层_x = att_outffn_out = self.ffn(att_out) ffn_out += _x # 残差连接ffn_out = self.norm2(ffn_out) # 层归一化return self.dropout(ffn_out) # 最终输出 -
维度变化
处理阶段 张量形状示例 输入数据 [batch_size, seq_len, d_model] 自注意力输出(不改变维度) [batch_size, seq_len, d_model] 残差连接+层归一化 [batch_size, seq_len, d_model] 前馈网络输出(不改变维度) [batch_size, seq_len, d_model] 最终输出 [batch_size, seq_len, d_model]
使用示例
-
测试用例
if __name__ == "__main__":# 模拟输入:batch_size=4, 序列长度100, 维度512x = torch.randn(4, 100, 512)# 实例化编码器层:8头注意力,512维,前馈层2048维,10% dropoutencoder_layer = EncoderLayer(n_heads=8, d_model=512, d_ff=2048, dropout_prob=0.1)# 前向传播out = encoder_layer(x, mask=None)print("Input shape:", x.shape) # torch.Size([4, 100, 512])print("Output shape:", out.shape) # torch.Size([4, 100, 512])