使用KNN预测图像
题目:使用KNN算法实现机器学习 给我一个水果的图片 我能预测出这个是什么水果
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, accuracy_score# 数据集路径和水果标签
dataset_path = './fruits' # 你的数据集在这个文件夹里
fruit_labels = ['apple', 'banana', 'grape', 'orange', 'pear'] # 定义水果标签
fruit_dict = {fruit: idx for idx, fruit in enumerate(fruit_labels)} # 构建标签字典(字符串到数字的映射)# 特征提取函数:读取图像,调整大小并展平
def extract_features(image_path):# 读取图像img = cv2.imread(image_path)if img is None:print(f"Warning: Could not read image at {image_path}")return None # 如果图像读取失败,返回 None# 将图像调整为统一的大小(100x100)img = cv2.resize(img, (100, 100))# 展平图像为一维数组,方便用于训练img = img.flatten()return img# 加载数据集:遍历数据集目录,提取每张图像的特征并保存标签
def load_data(dataset_path):data = [] # 存储所有图像的特征labels = [] # 存储每张图像对应的标签for fruit in fruit_labels: # 遍历每个水果类别fruit_folder = os.path.join(dataset_path, fruit) # 获取每个类别的文件夹路径for image_name in os.listdir(fruit_folder): # 遍历文件夹中的每张图片image_path = os.path.join(fruit_folder, image_name) # 获取图像的完整路径features = extract_features(image_path) # 提取图像的特征if features is not None:data.append(features) # 添加特征到数据列表labels.append(fruit_dict[fruit]) # 添加对应的标签(数字标签)到标签列表return np.array(data), np.array(labels) # 返回特征和标签的 numpy 数组# 加载数据并进行训练集和测试集划分
data, labels = load_data(dataset_path) # 加载数据和标签
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42) # 按 80% 训练、20% 测试划分数据集# 使用 KNN 分类器进行训练
knn = KNeighborsClassifier(n_neighbors=3) # 初始化 KNN 分类器,选择 k=3
knn.fit(X_train, y_train) # 使用训练集进行模型训练# 模型评估:预测测试集,并输出评估结果
y_pred = knn.predict(X_test) # 对测试集进行预测
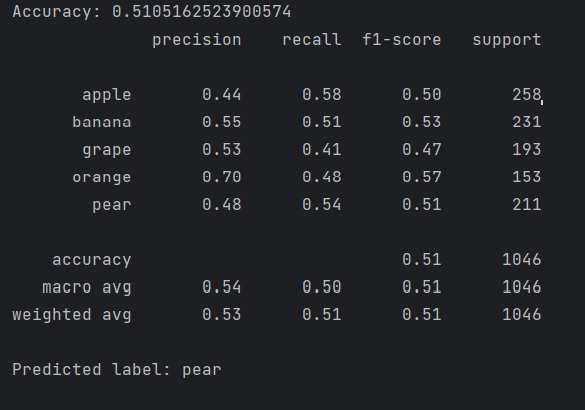
print(f"Accuracy: {accuracy_score(y_test, y_pred)}") # 输出模型准确度
print(classification_report(y_test, y_pred, target_names=fruit_labels)) # 输出分类报告,包括精度、召回率、F1 分数等# 现在进行对传入图片的预测
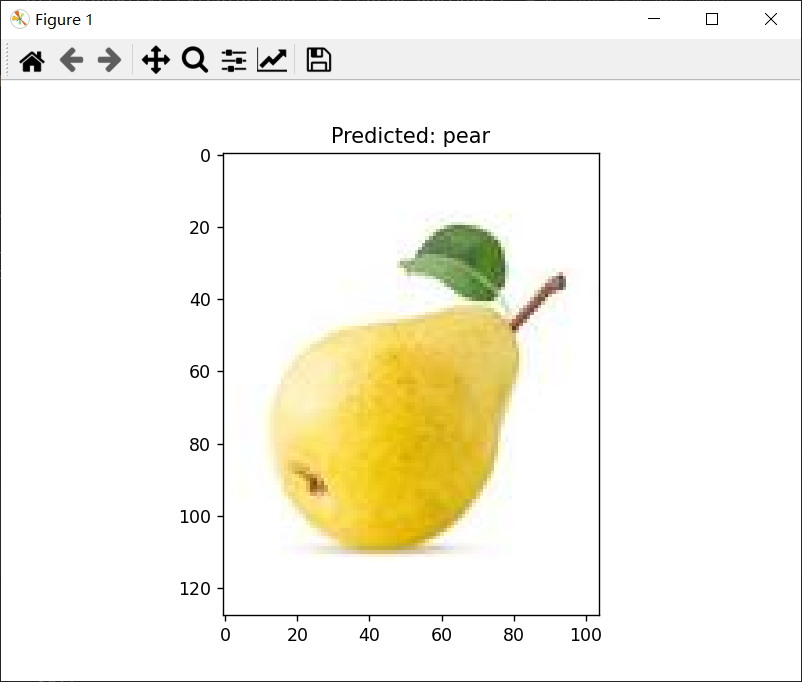
def predict_image(image_path):# 读取输入图片img = cv2.imread(image_path)if img is not None:# 提取输入图像的特征img_resized = cv2.resize(img, (100, 100)) # 将图像调整为统一的大小img_flattened = img_resized.flatten() # 将图像展平为一维特征向量# 使用训练好的 KNN 模型进行预测prediction = knn.predict([img_flattened]) # 注意这里是 [img_flattened],KNN 需要二维数组# 输出预测结果predicted_label = fruit_labels[prediction[0]] # 将预测的数字标签转换为水果标签print(f"Predicted label: {predicted_label}") # 打印预测标签# 可视化输入图片并显示预测结果plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 将图像从 BGR 转为 RGB 并显示plt.title(f"Predicted: {predicted_label}") # 显示标题(预测结果)plt.show() # 显示图像else:print(f"Error: Image at {image_path} could not be read.") # 如果无法读取图片,输出错误信息# 调用 predict_image 函数来预测一个新的图片
# 传入你希望预测的图片路径
image_path = './fruits/pear/1.jpg' # 替换为你的图像路径,确保图像路径正确
predict_image(image_path) # 进行预测并显示结果
运行结果:
结果分析:
1. 准确度(Accuracy):
准确度 = 0.51:这意味着模型在所有预测中正确预测了 51% 的样本。考虑到有多个类别(苹果、香蕉、葡萄、橙子、梨),这个准确度并不算特别高。一般来说,准确度应该在 70% 以上才算是一个比较好的模型。
2. 分类报告分析:
每个类别的评估指标:
(1)Apple(苹果):
精度(Precision) = 0.44:模型预测为苹果的样本中,只有 44% 是正确的。说明虽然模型预测苹果较多,但也有较多的错误预测。
召回率(Recall) = 0.58:真实标签为苹果的样本中,58% 被模型正确预测。召回率较低,意味着有 42% 的苹果未被正确识别。
F1 分数(F1-Score) = 0.50:这是精度和召回率的调和平均数,综合考虑了精度和召回率。F1 分数为 0.50,说明模型在预测苹果时存在一定的平衡问题。
(2)Banana(香蕉):
精度 = 0.55,召回率 = 0.51,F1 分数 = 0.53:香蕉的表现比苹果稍好,但精度和召回率依然较低,F1 分数也仅为 0.53,表明模型对香蕉的识别能力有限。
(3)Grape(葡萄):
精度 = 0.53,召回率 = 0.41,F1 分数 = 0.47:葡萄类别的召回率较低,意味着很多葡萄的图片被错误分类,F1 分数也较低,表明该类别模型性能不佳。
(4)Orange(橙子):
精度 = 0.70,召回率 = 0.48,F1 分数 = 0.57:橙子的精度较高,但召回率较低,F1 分数也相对较高,表示橙子的识别能力相对较强。
(5)Pear(梨):
精度 = 0.48,召回率 = 0.54,F1 分数 = 0.51:梨的精度和召回率相对接近,F1 分数接近 0.5,整体表现中等。
(6)宏观平均(Macro Average):
精度 = 0.54,召回率 = 0.50,F1 分数 = 0.51:宏观平均是对所有类别指标的平均值。由于各类别的精度和召回率较低,宏观平均也表现一般。
(7)加权平均(Weighted Average):
精度 = 0.53,召回率 = 0.51,F1 分数 = 0.51:加权平均考虑了每个类别的样本数量,因此它受类别分布的影响。如果某些类别样本较多,权重就会较大。这里加权平均与宏观平均非常接近,表明每个类别对最终评分的贡献差不多。
改进建议:
(1)数据预处理:
可能需要进一步改进图像预处理步骤。例如,使用更复杂的特征提取方法(如使用卷积神经网络(CNN)或改进的传统特征如 HOG)。
如果图像分辨率不一致,进一步进行数据增强(例如旋转、缩放、翻转等),可以帮助模型更好地泛化。
(2)模型改进:
KNN 模型在高维度的图像数据上可能并不十分适用,可以尝试其他更强的机器学习算法,例如随机森林、支持向量机(SVM)或者卷积神经网络(CNN)。
适当调整 KNN 中的参数(如 K 的值)可能会带来更好的性能。
(3)类别不平衡问题:
如果某些类别的样本数量较少,可以考虑进行样本重采样(过采样或欠采样),或者尝试类别加权,以解决类别不平衡问题。
(4)特征选择或提取:
可以进一步优化特征提取方法。比如,使用深度学习模型(如 CNN)来提取更有代表性的特征,可能会显著提高分类效果。
如果可能,使用数据增强方法来增加样本多样性,尤其是对于较小的类别(如葡萄和橙子)。