机器学习分类模型性能评估:应对类别不平衡的策略与指标
在机器学习的世界里,模型们就像一群努力破案的侦探,而数据就是它们的“犯罪现场”。今天,咱们的主角——一个自命不凡的分类模型,接到了一个看似简单的任务:揪出那些患有罕见疾病的患者。这听起来是不是很容易?毕竟,只要随便猜猜,就能蒙对大部分结果,轻松拿下高得吓人的准确率。
可别急,事情没那么简单!这个任务背后藏着一个巨大的陷阱,那就是数据的“偏见”——患病的人太少啦!这就像是在一个全是好人的人群里找坏蛋,要是随便抓几个好人当嫌疑人,那可就太冤枉人家了。我们的模型侦探们必须使出浑身解数,用各种聪明的指标来衡量自己的表现,才能真正找到那些隐藏在人群中的“坏蛋”。
接下来,就让我们一起看看,这些模型侦探们是怎么一步步解开这个谜团的吧!
用性能指标评估分类模型
亲爱的机器学习小伙伴们,快来看看这个有趣的情景吧:
假设你被安排去构建一个机器学习模型,用来检测医学患者是否感染了一种罕见疾病。这种疾病实在是太罕见了,患者感染的概率只有1%。你的上司希望你构建的模型能达到最高的准确率。这将是一个二分类器,以患者的信息作为输入,然后告诉你患者是否患有该疾病,我们可以将输出分别编码为1(患病)或0(未患病)。
接下来的几天,你充分发挥自己的机器学习技能,构建了一个准确率达到85%的模型。干得漂亮!
然而,你的快乐并没有持续太久,因为你的上司告诉你,团队里的另一个成员只花了大约10分钟就构建了一个更简单的模型,轻松实现了99%的准确率。
啥?!这是咋回事呢?难道那个团队成员是个超级天才,还是公司给的指令有问题,或者我不是自己想象中的那么厉害的机器学习从业者?
让我们来一探究竟吧!
性能指标
在机器学习的任何领域,我们都应该从最基本的定义和原理出发。
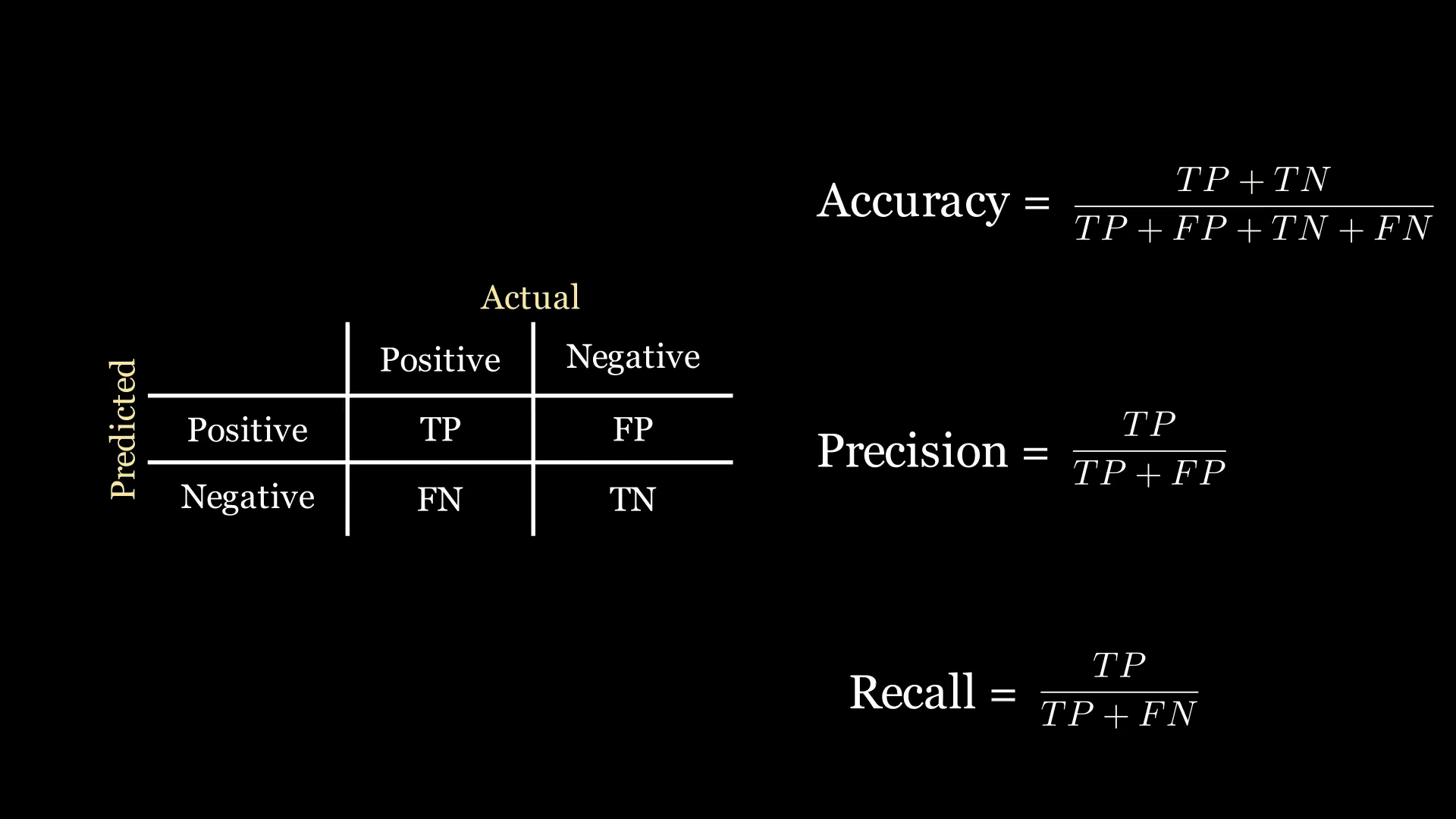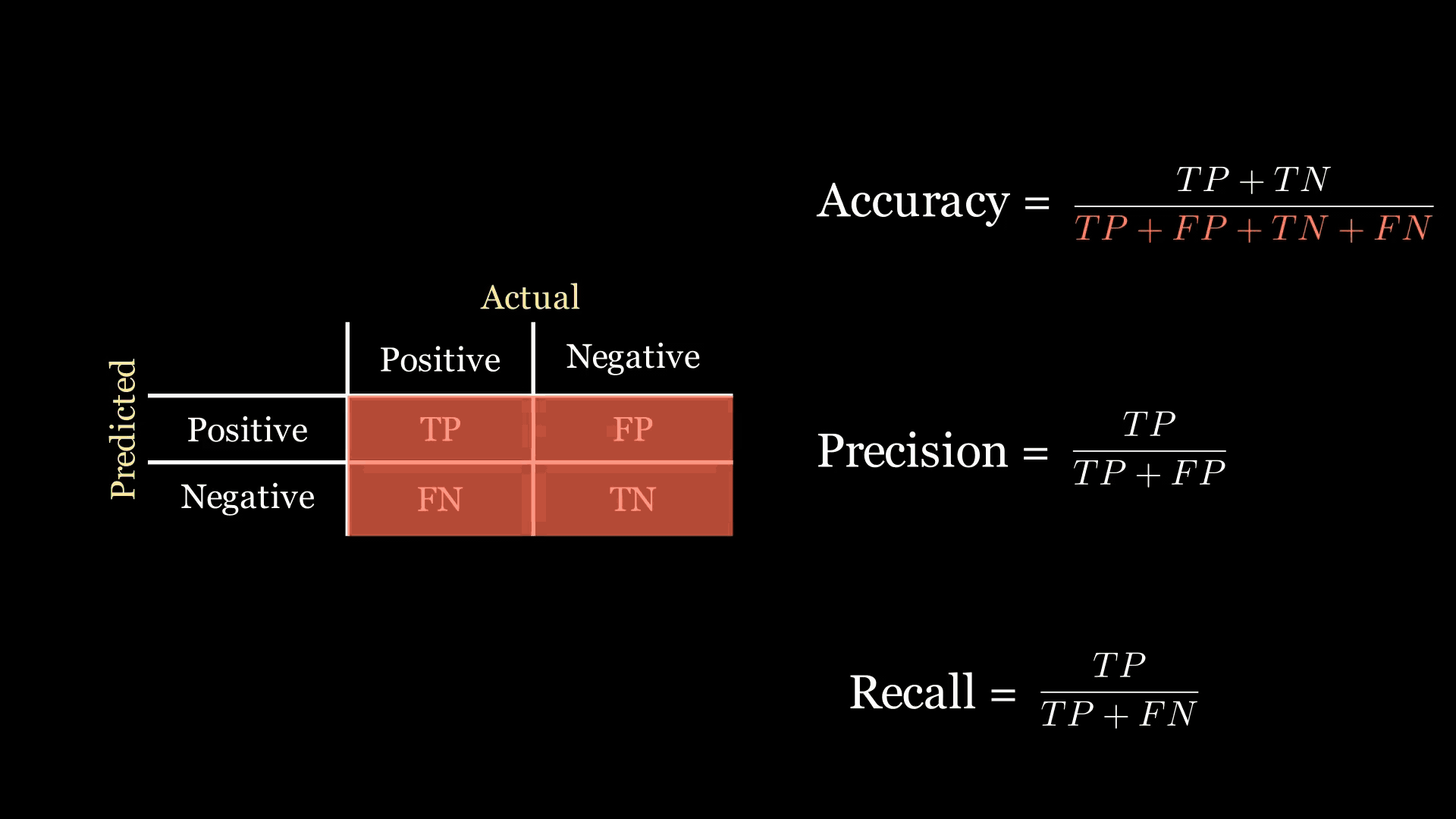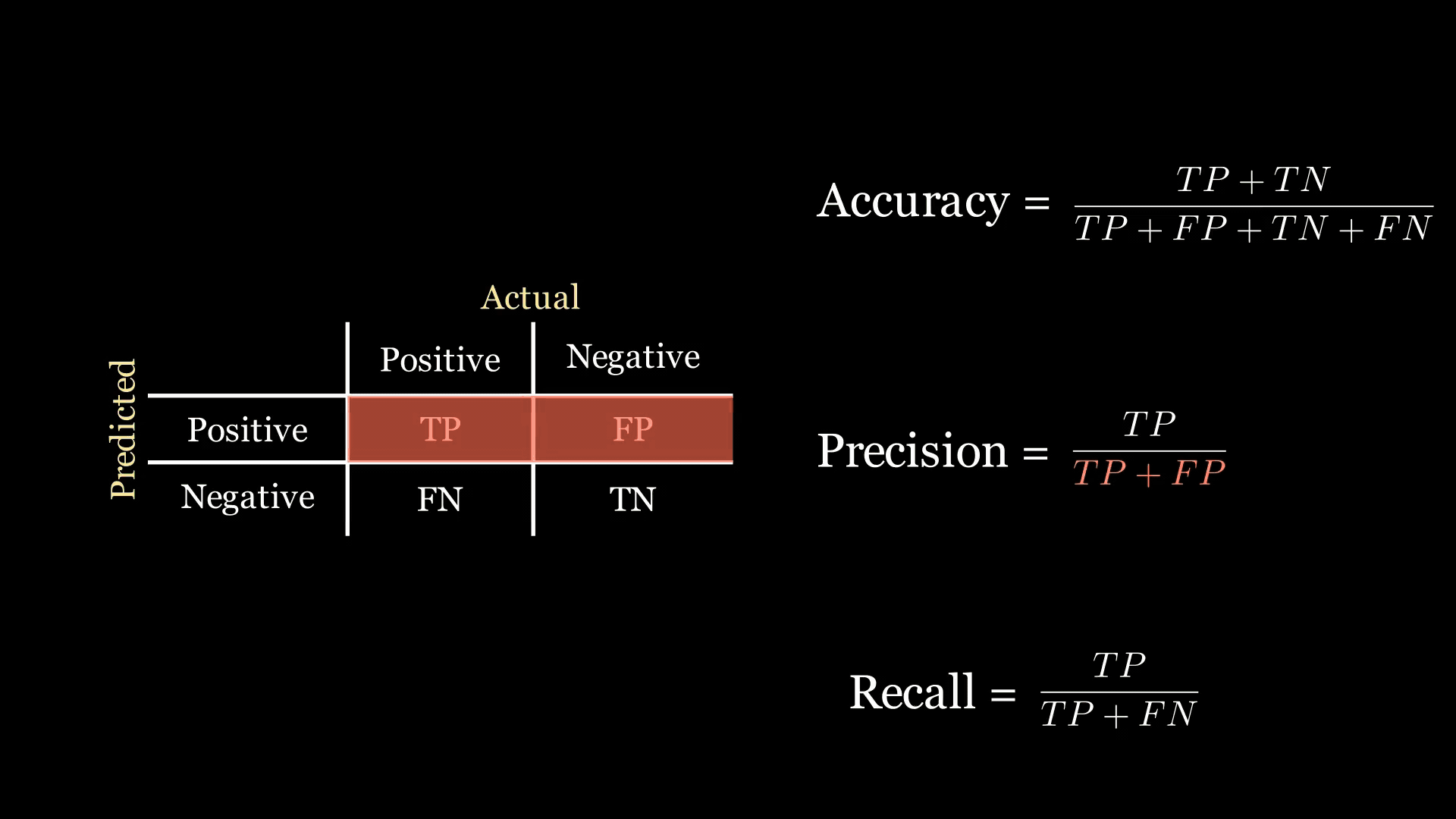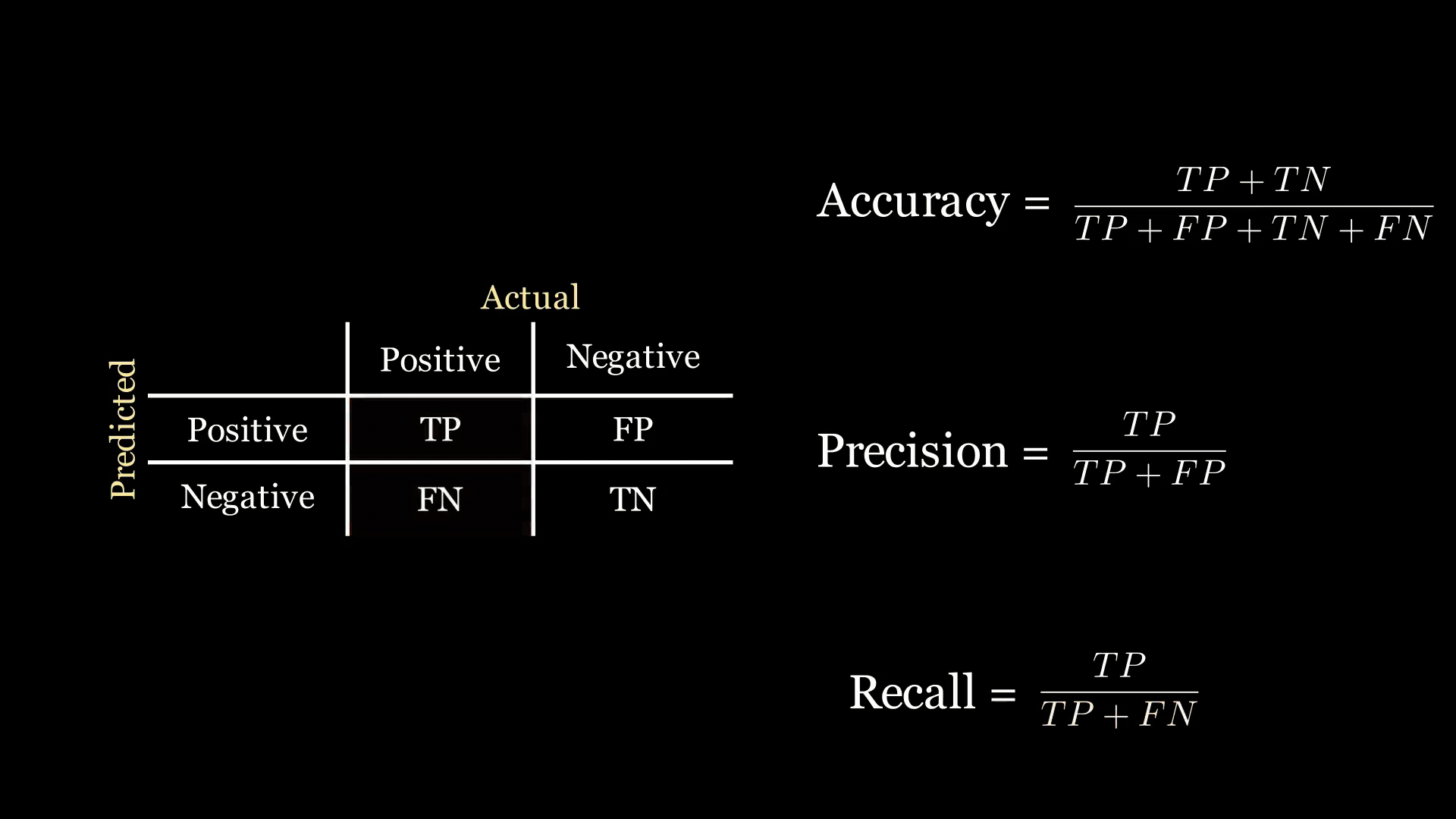
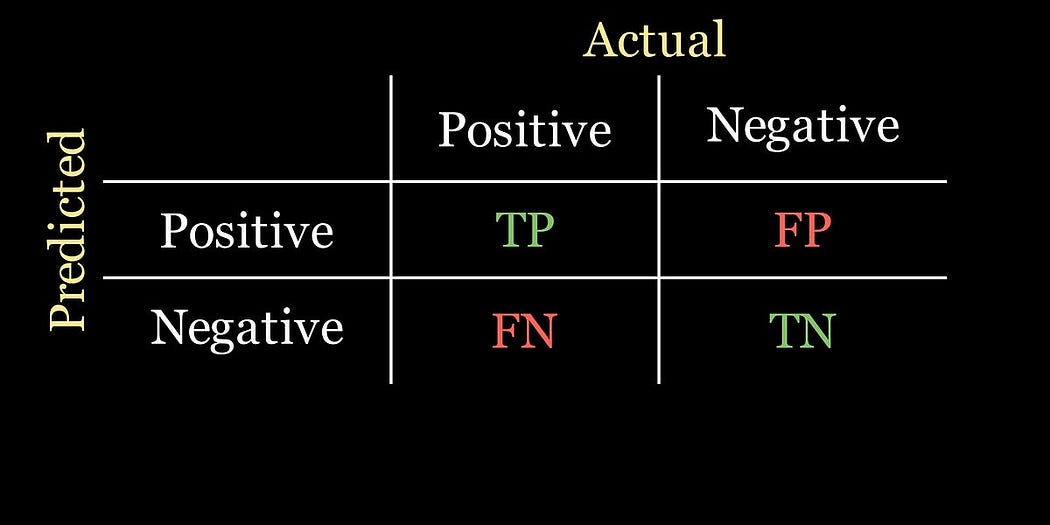
我们先从混淆矩阵说起,它展示了我们的模型预测得好不好。对于我们的二分类问题,它看起来像一个2×2的网格:第一列给出了实际患有疾病患者的数量,第二列给出了实际未患病患者的数量;行则对应模型做出的预测。举个例子:
从现在开始,我们将疾病检测称为“阳性”结果,没有检测到疾病为“阴性”结果。也就是说,当模型认为检测到疾病实例时,就会发出阳性信号。
混淆矩阵中的每个单元格代表一定的数量:
- 真阳性(TP):模型预测患者患有疾病,且患者实际确实患有疾病的人数。
- 假阳性(FP):模型预测患者患有疾病,但患者实际并没有患病的人数。
- 假阴性(FN):模型预测患者没有患病,但患者实际患有疾病的人数。
- 真阴性(TN):模型预测患者没有患病,且患者实际确实没有患病的人数。
以下是混淆矩阵的示意图:
回想一下,公司让你构建一个优化准确率的模型。分类器的准确率是正确分类点的比例:
准确率 = TP + TN TP + FP + FN + TN \text{准确率} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{FP} + \text{FN} + \text{TN}} 准确率=TP+FP+FN+TNTP+TN
由于这是一个比例,准确率的值将在0到1之间,我们也可以将其转换为百分比。
医学奇迹
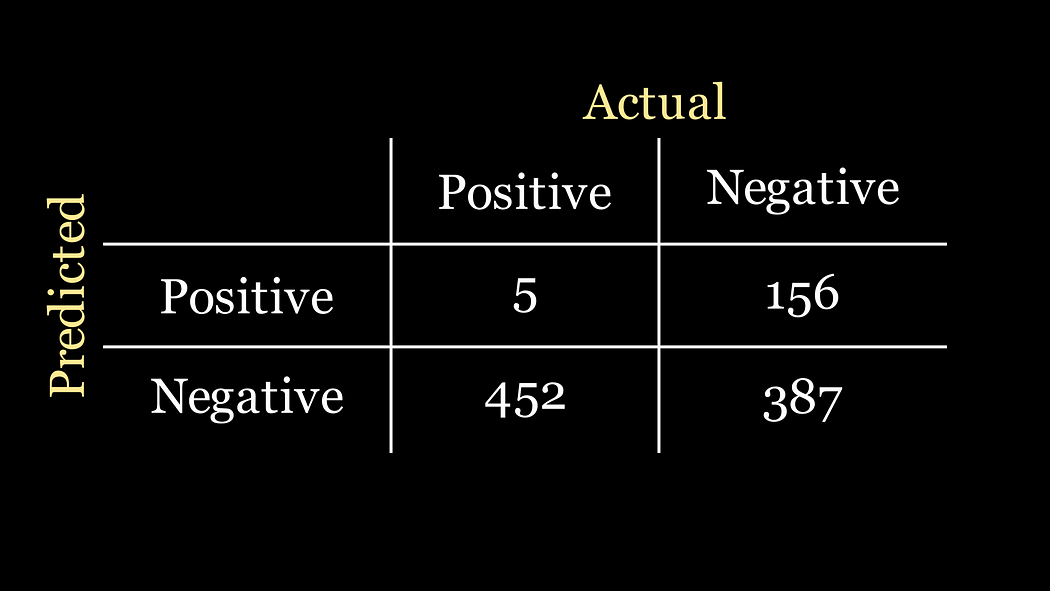
让我们暂停一下,思考一下公司给我们的分类任务。我们知道,我们数据中只有1%的患者实际上患有这种疾病。因此,如果我们的数据集中有1000名患者,那么只有10人真正患有这种疾病。对于这个问题,分类器的最佳混淆矩阵场景如下:
事实上,对于任何混淆矩阵,最优分类器是其混淆矩阵仅在主对角线上有值的那个。
按照上面给出的公式,这个分类器的准确率是
准确率 = 10 + 990 10 + 0 + 0 + 990 = 1 \text{准确率} = \frac{10 + 990}{10 + 0 + 0 + 990} = 1 准确率=10+0+0+99010+990=1
🤔 你能看出我们如何构建一个准确率达到99%的超简单分类器吗?
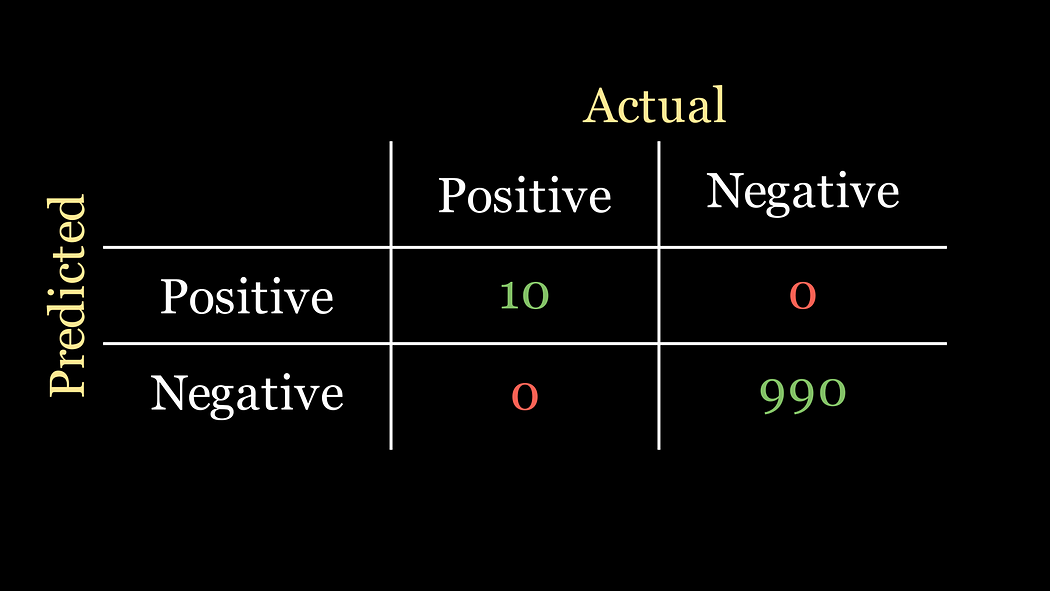
💡 我们只需预测每个患者都没有患病即可。这被称为天真分类器,其混淆矩阵如下:
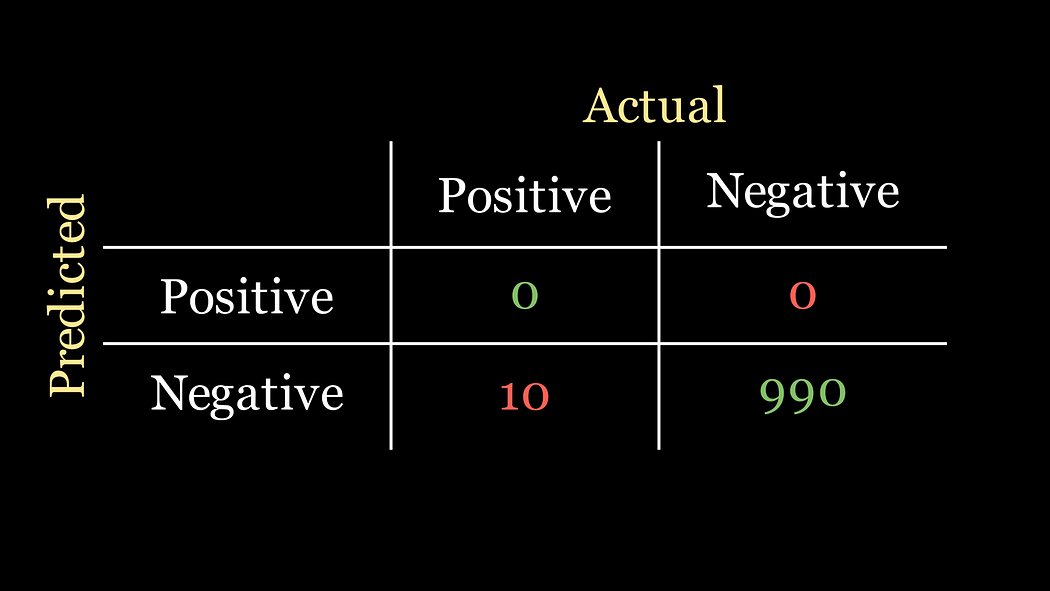
对应的准确率现在是
准确率 = 0 + 990 0 + 0 + 10 + 990 = 0.99 \text{准确率} = \frac{0 + 990}{0 + 0 + 10 + 990} = 0.99 准确率=0+0+10+9900+990=0.99
瞧!毫不费力就实现了99%的准确率。现在我们知道同事是怎么轻松实现这么高准确率的了……
但更重要的问题是,我们同事的分类器是不是一个好的分类器呢?尽管准确率很高,但它的设计并没有真正检测出任何疾病的实例!它只是默认说任何数据实例都没有疾病。
主要问题是:准确率指标并不适合像我们正在讨论的这种存在严重类别不平衡的数据集。
所以,使用准确率作为模型的性能指标并不总是明智的。那我们该怎么办呢?
召回率
鉴于疾病诊断的背景,我们希望一个优先检测疾病的分类器。我们可以使用的一个指标是召回率:
召回率 = TP TP + FN \text{召回率} = \frac{\text{TP}}{\text{TP} + \text{FN}} 召回率=TP+FNTP
分类器的召回率告诉我们,被模型分类为患有疾病的实际患有疾病的患者比例。
另一种说法是:在所有模型预测患有疾病的患者中,实际患有疾病的百分比是多少?
对于医疗诊断来说,这个指标比准确率更适合,因为我们不希望模型遗漏任何疾病的实例。我们不太关心模型输出了多少假阳性(即模型预测患者患病,但实际上患者并没有患病)。相反,我们需要尽可能降低假阴性值,否则就会有患有罕见疾病的患者却不知道自己患病。
尽管假阳性很不方便,但假阴性是有害的。
让我们看看天真分类器的召回率是什么样的:
召回率 = 0 0 + 10 = 0 \text{召回率} = \frac{0}{0 + 10} = 0 召回率=0+100=0
哦,这下就对了。
精确率
召回率性能指标适用于我们不想出现太多假阴性的情况。但如果在某些情境下,标记假阳性太不方便而不能忽视呢?
精确率是另一个性能指标,它衡量实际为正的正分类的比例:
精确率 = TP TP + FP \text{精确率} = \frac{\text{TP}}{\text{TP} + \text{FP}} 精确率=TP+FPTP
当希望向模型强调不要不必要地标记假阳性时,这个指标很有用。例如,在电子邮件垃圾邮件检测的情境中,过多的假阳性可能意味着重要邮件最终会出现在你的垃圾邮件文件夹中!这当然不太理想。
F1 分数
你的问题背景可能需要结合精确率和召回率的一些特点。F1 分数在精确率和召回率之间提供了平衡:
F1 分数 = 2 × 精确率 × 召回率 精确率 + 召回率 \text{F1 分数} = 2 \times \frac{\text{精确率} \times \text{召回率}}{\text{精确率} + \text{召回率}} F1 分数=2×精确率+召回率精确率×召回率
也就是说,F1 分数是精确率和召回率的调和平均值。我们也可以用 TP、FP 和 FN 来表示 F1 分数公式:
F1 分数 = 2 × TP 2 × TP + FP + FN \text{F1 分数} = \frac{2 \times \text{TP}}{2 \times \text{TP} + \text{FP} + \text{FN}} F1 分数=2×TP+FP+FN2×TP
我们可以看到,当 FP 和 FN 的算术平均值较高时,F1 分数会受到影响。特别是,仅最小化 FP 或 FN 中的一个是不够的。
总的来说,F1 分数是在处理不平衡数据集时的一个有用指标。
小小的注意事项
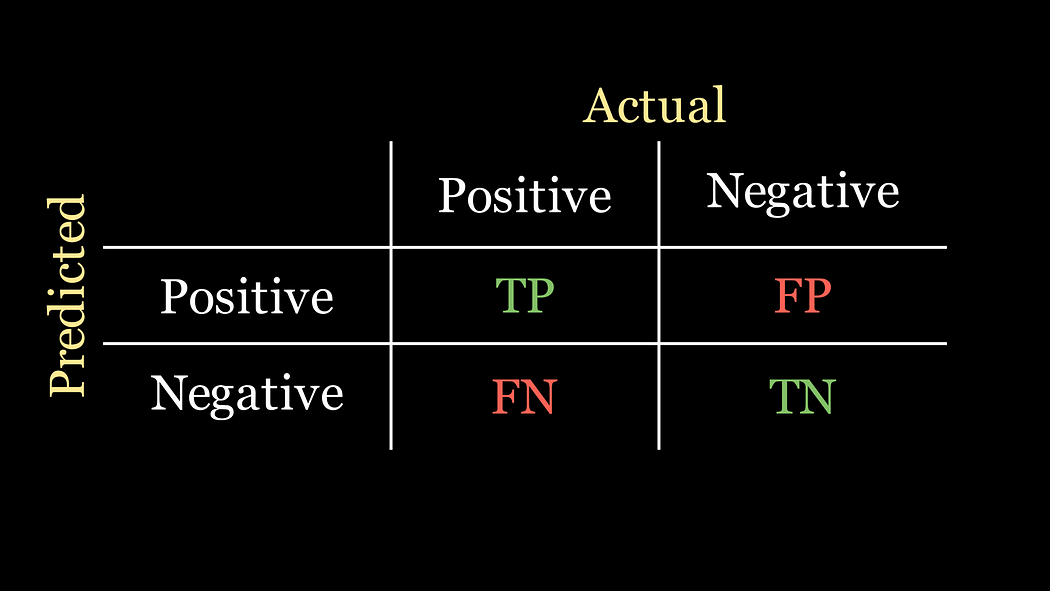
似乎对于混淆矩阵中预测值和实际值应该如何显示,并没有全球统一的共识。在本文中,我将预测值放在行上,实际值放在列上。总之,当查看在线资源时要小心,因为有些可能使用的是我所描述的转置版本。
总结一下
性能指标对于评估模型性能至关重要,有助于以符合预测目标的方式进行评估。希望这篇文章能帮你理解模型评估时需要考虑的细微差别。现在,像往常一样,简单总结一下:
- 准确率:告诉你模型正确分类的数据点比例。这个指标并不适合包含类别不平衡的数据集。
- 召回率:表示实际为正的数据点中被预测为正的比例。当你希望尽量减少模型漏掉的阳性结果时,这个指标很理想。召回率关注混淆矩阵的第一列。
- 精确率:表示被预测为正的数据点中实际为正的比例。当你希望尽量减少模型做出的错误阳性预测时,这个指标很理想。精确率关注混淆矩阵的第一行。
下面的动画中,绿色和红色的高亮显示帮助我记住召回率和精确率在混淆矩阵中的位置: