JVM模型、GC、OOM定位
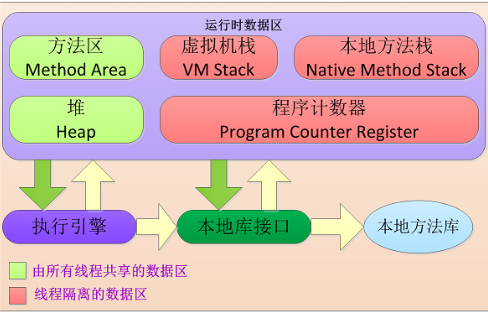
JVM模型
程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完。
另外,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
作用
记录当前线程执行的字节码指令地址(行号),在多线程切换时恢复执行位置。
特性
线程私有,生命周期与线程绑定
唯一不会发生OutOfMemoryError的区域
异常
无
Java虚拟机栈(Java Virtual Machine Stack)
与程序计数器一样,Java虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型。
Java 内存可以粗糙的区分为堆内存(Heap)和栈内存(Stack)其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。 (实际上,Java虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有局部变量表、操作数栈、动态链接、方法出口信息)
局部变量表主要存放了编译器可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
作用
存储方法调用的栈帧(Frame),包括局部变量表、操作数栈、动态链接和方法返回地址。
特性
线程私有,每个方法调用对应一个栈帧
通过 -Xss 参数设置栈大小(如 -Xss1m)
异常
StackOverflowError:栈深度超过限制(如无限递归)
OutOfMemoryError:栈动态扩展时无法申请足够内存(较少见)
本地方法栈(Native Method Stack)
和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
作用
为JVM调用本地(Native)方法(如C/C++代码)服务。
特性
与Java虚拟机栈类似,但服务于Native方法。
异常
同虚拟机栈(StackOverflowError、OutOfMemoryError)。
Java堆(Java Heap)
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
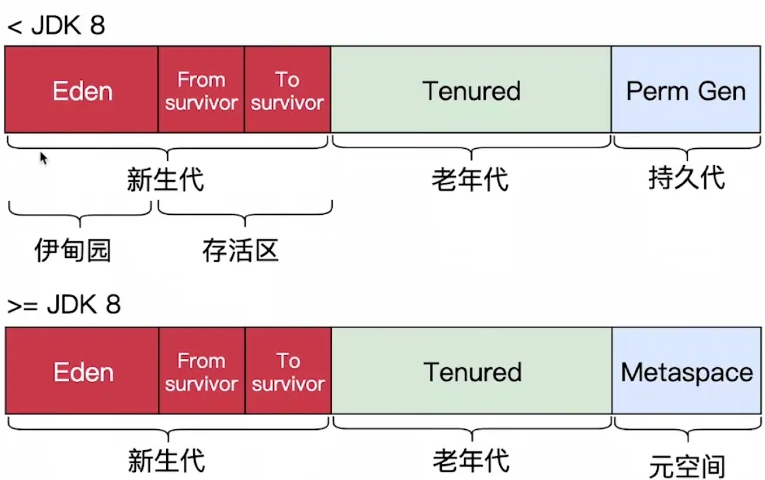
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC堆(Garbage Collected Heap).从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以Java堆还可以细分为:新生代和老年代:再细致一点有:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
作用
存放对象实例和数组,是垃圾回收(GC)的主要区域。
特性
线程共享,生命周期与JVM进程一致。
通过 -Xms(初始堆大小)和 -Xmx(最大堆大小)调整(如 -Xms256m -Xmx1024m)。
新生代分为 Eden 区 和两个 Survivor 区(From 和 To),默认比例(可通过参数调整):
Eden : Survivor = 8:1:1(如 -XX:SurvivorRatio=8)
Java 8后,字符串常量池(String Table)从方法区移至堆中。
异常
OutOfMemoryError: Java heap space:对象过多或内存泄漏导致堆空间不足。
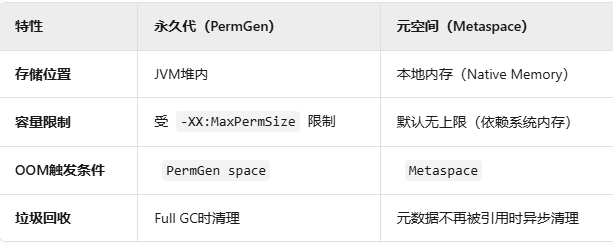
永久代与元空间的区别:
方法区(Method Area)
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
作用
存储类元数据(Class Metadata)、常量池(Constant Pool)、静态变量(JDK 8+移至堆中)等。
实现演进
JDK 7及之前:称为“永久代(PermGen)”,通过 -XX:PermSize 和 -XX:MaxPermSize 调整。
JDK 8+:改为元空间(Metaspace),使用本地内存(Native Memory),通过 -XX:MetaspaceSize 和 -XX:MaxMetaspaceSize 控制。
异常
OutOfMemoryError: Metaspace(JDK 8+)或 PermGen space(JDK 7):加载过多类或动态生成类(如反射、CGLib)。
直接内存(Direct Memory)
定位:
直接内存是JVM外部的本地内存(Native Memory),不属于JVM运行时数据区,但可通过Java代码间接访问(如ByteBuffer.allocateDirect())。
特点:
绕过堆内存:避免Java堆与Native堆之间的数据复制,提升I/O性能(常用于NIO的DirectBuffer)。
手动管理:不依赖JVM垃圾回收,需显式调用System.gc()或依赖Cleaner机制释放(但不可控)。
容量限制:受操作系统物理内存和进程地址空间限制(32位系统单进程通常≤2GB)。
配置参数
-XX:MaxDirectMemorySize:设置直接内存最大容量(默认与堆最大值-Xmx相同)
# 示例:限制直接内存为512MB
-XX:MaxDirectMemorySize=512m
常见问题
OutOfMemoryError: Direct buffer memory:
原因:
直接内存分配超出MaxDirectMemorySize限制,或未及时释放。
排查:
检查代码中DirectBuffer的使用(如Netty、文件读写)。
监控直接内存占用(jcmd VM.native_memory或NMT工具)。
确保-XX:MaxDirectMemorySize配置合理。
GC
垃圾收集器详解
JVM 提供了多种垃圾收集器(Garbage Collectors, GC),每种收集器针对不同的应用场景和性能需求设计。以下是主要收集器的分类、特点及适用场景:
经典分代收集器
(1) Serial 收集器
模式:单线程、Stop-The-World (STW)。
适用场景:客户端应用、资源受限的嵌入式系统。
参数:-XX:+UseSerialGC
新生代算法:复制(Copying)。
老年代算法:标记-整理(Mark-Compact)。
(2) Parallel Scavenge(吞吐量优先收集器)
模式:多线程并行、STW。
目标:最大化 吞吐量(总运行时间中 GC 时间占比最低)。
参数:-XX:+UseParallelGC(JDK 8 默认)
新生代算法:复制。
老年代算法:标记-整理(Parallel Old)。
(3) ParNew 收集器
模式:Parallel Scavenge 的改进版,专为配合 CMS 设计。
参数:-XX:+UseParNewGC
特点:与 CMS 配合时,用于新生代收集。
(4) CMS(Concurrent Mark-Sweep)
模式:并发标记、STW 清除。
目标:最小化 停顿时间(低延迟)。
参数:-XX:+UseConcMarkSweepGC
老年代算法:标记-清除(Mark-Sweep),需定期 Full GC 整理碎片。
缺点:内存碎片、CPU 敏感。
新一代收集器
(1) G1(Garbage-First)
模式:并发与并行、分 Region 管理。
目标:平衡 吞吐量 和 延迟(JDK 9+ 默认收集器)。
参数:-XX:+UseG1GC
内存布局:将堆划分为多个 Region(默认 2048 个),避免全堆回收。
阶段:
Young GC:回收 Eden 和 Survivor 区。
Mixed GC:同时回收新生代和部分老年代 Region。
适用场景:大内存(>4GB)、低延迟要求(数百毫秒级)。
(2) ZGC(Z Garbage Collector)
模式:全并发、低停顿(STW < 10ms)。
目标:超大堆(TB 级)下的极低延迟。
参数:-XX:+UseZGC
关键技术:
染色指针(Colored Pointers):在指针中存储元数据,避免内存屏障。
内存映射:支持动态堆大小调整。
适用场景:云计算、实时系统(JDK 15+ 生产可用)。
(3) Shenandoah
模式:全并发、与 ZGC 竞争。
参数:-XX:+UseShenandoahGC
特点:
与 ZGC 类似,但通过 读屏障 而非染色指针实现并发。
在 JDK 12+ 中提供,适合中等规模堆(数百 GB)。
优势:低延迟且兼容性更广(支持较早 JDK)。
特殊场景收集器
(1) Epsilon(No-Op GC)
模式:不执行回收,仅供测试。
参数:-XX:+UseEpsilonGC
用途:性能测试、短生命周期应用(如 CI 任务)。
(2) Serial GC 的变种
Serial Old:Serial 的老年代版本(标记-整理)。
Serial CMS:CMS 的单线程模式(极少使用)。
JDK 17+ 支持的收集器
| 收集器 | 启动参数 | 适用场景 | 特点 | 推荐 JDK 版本 |
|---|---|---|---|---|
| G1 (Garbage-First) | -XX:+UseG1GC | 通用场景(默认) | 平衡吞吐量和延迟,支持大堆内存 | JDK 9+ (默认) |
| ZGC | -XX:+UseZGC | 超大堆、超低延迟 | STW < 1ms,支持 TB 级堆 | JDK 15+ |
| Shenandoah | -XX:+UseShenandoahGC | 低延迟、兼容性要求高 | 全并发,STW < 10ms | JDK 12+ |
| Parallel (吞吐量优先) | -XX:+UseParallelGC | 批处理、计算密集型任务 | 多线程并行,最大化吞吐量 | JDK 8+ |
| Serial | -XX:+UseSerialGC | 客户端/嵌入式系统 | 单线程,资源占用低 | 全版本 |
| Epsilon (无操作) | -XX:+UseEpsilonGC | 测试/极短生命周期应用 | 不回收内存,仅分配 | JDK 11+ |
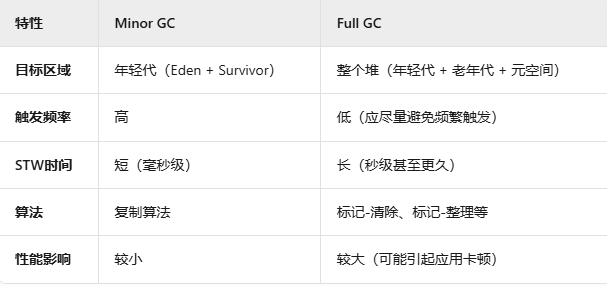
Minor GC(Young GC)
目标
回收年轻代(Young Generation)的垃圾对象。
触发条件
Eden 区空间不足:当程序尝试在 Eden 区分配对象时,若空间不足则触发。
主动触发:某些垃圾收集器(如 G1)可能周期性触发。
核心流程
(1) 根枚举(Root Scanning)
目标:确定所有 GC Roots(存活对象的起点)。
GC Roots 类型:
栈帧中的局部变量(线程栈)
静态变量(方法区)
JNI 引用(Native 方法)
(2) 标记存活对象(Marking)
可达性分析:从 GC Roots 出发,遍历所有引用链,标记存活对象。
三色标记法:通过白、灰、黑三色跟踪对象状态(具体算法因收集器而异)。
(3) 复制存活对象(Copying)
复制目标:
Survivor To 区:将 Eden 和 Survivor From 区的存活对象复制到 Survivor To 区。
老年代:若对象年龄超过阈值(默认 15,-XX:MaxTenuringThreshold)或 To 区空间不足,则直接晋升到老年代。
对象年龄计数器:每经历一次 Minor GC,存活对象的年龄 +1。
(4) 清空原区域(Sweeping)
回收 Eden 和 From 区:所有未被复制的对象(即垃圾)被回收,空间被释放。
指针碰撞(Bump the Pointer):内存整理后,Eden 区重新从起始地址分配对象。
(5) 交换 Survivor 区(Swap)
From ↔ To 角色互换:确保下一次 Minor GC 时,Survivor To 区为空。
核心算法
复制算法(Copying):通过复制存活对象到Survivor区,避免内存碎片。
Stop-The-World(STW):Minor GC会暂停所有应用线程,但时间通常较短。
Full GC
目标
回收整个堆(包括老年代、年轻代)以及元空间(Metaspace)或永久代(PermGen,Java 8之前)
触发条件
1.老年代空间不足(如对象晋升失败)。
2,元空间/永久代空间不足。
3.显式调用System.gc()(依赖JVM参数-XX:+DisableExplicitGC配置)。
4.垃圾回收器策略触发(如CMS的并发模式失败、G1的疏散失败等)。
核心流程
(1)标记所有存活对象:
从GC Roots出发,标记整个堆(年轻代+老年代)和元空间的存活对象。
(2)回收垃圾对象:
年轻代:执行类似Minor GC的复制算法。
老年代:根据垃圾回收器类型不同,可能使用以下算法:
标记-清除-整理(Mark-Sweep-Compact):CMS、Serial Old等。
分代收集(Generational):G1、ZGC等。
元空间/永久代:回收不再使用的类元数据。
(3)内存整理(可选):
部分回收器(如Serial Old)会对老年代进行内存整理,减少碎片。
(4)完成回收:
释放未使用的内存,恢复应用线程。
核心算法
标记-清除(Mark-Sweep)或标记-整理(Mark-Compact):适用于老年代。
Stop-The-World(STW):Full GC的STW时间通常较长,对性能影响显著。
GC关键对比
OOM定位
常见OOM类型
| 错误类型 | 触发区域 | 典型原因 |
|---|---|---|
| java.lang.OutOfMemoryError: Java heap space | 堆内存 | 对象数量过多、内存泄漏、缓存未清理 |
| java.lang.OutOfMemoryError: Metaspace | 元空间(方法区 | 动态生成类过多(如反射、CGLIB)、未限制元空间大小 |
| java.lang.OutOfMemoryError: Direct buffer memory | 直接内存 | 未释放 ByteBuffer、Netty 或 NIO 使用不当 |
| java.lang.OutOfMemoryError: Unable to create new native thread | 栈/线程资源 | 线程数过多、操作系统限制(ulimit -u) |
| java.lang.OutOfMemoryError: Requested array size exceeds VM limit | 堆内存 | 尝试分配超大数组(如 new int[Integer.MAX_VALUE]) |
分析堆转储文件
工具选择:
Eclipse MAT:分析对象引用链,查找内存泄漏。
VisualVM:快速查看对象分布。
JProfiler:商业工具,功能全面。
MAT 分析步骤:
打开 heapdump.hprof。
查看 Histogram,按对象数量或内存占用排序。
使用 Dominator Tree 找到占用内存最大的对象。
通过 Path to GC Roots 查看对象引用链,定位未释放的引用。
发生OOM时自动生成堆转储文件Heap Dump)
1.在 Dockerfile 中直接指定 JVM 参数
FROM openjdk:11-jdk # 基础镜像(需确保有写入权限的目录)
COPY your-app.jar /app.jar# 创建堆转储目录并设置权限
RUN mkdir -p /dumps && chmod 777 /dumps# 添加 JVM 参数
ENV JAVA_OPTS="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/dumps"
CMD ["sh", "-c", "java $JAVA_OPTS -jar /app.jar"]
2. 通过 docker run 命令动态传递参数
docker run -d \-v /host/dumps:/dumps \ # 挂载宿主机目录到容器内的转储路径-e JAVA_OPTS="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/dumps" \your-java-image
3.导出.hprof文件使用MAT工具分析
使用jmap命令
确保容器内安装 JDK(而非仅 JRE)
基础镜像应包含完整的 JDK,例如:
FROM openjdk:11-jdk # 使用 JDK 镜像(包含 jps/jmap 工具)
如果使用 JRE 镜像(如 openjdk:11-jre),需手动安装 JDK 工具:
apt-get update && apt-get install -y openjdk-11-jdk-headless
启动容器时保留调试权限
添加 --cap-add=SYS_PTRACE 避免权限问题:
docker run -d --cap-add=SYS_PTRACE --name my_container my_image
查看java进程PID
进入容器执行命令
docker exec -it <container_id> /bin/bash
jps -l # 查看容器内 Java 进程 PID 和主类名
直接执行命令(不进入容器)
docker exec <container_id> jps -l
使用 jmap 生成堆转储
生成堆转储文件
# 进入容器后执行
jmap -dump:format=b,file=/tmp/heapdump.hprof <pid># 或直接执行
docker exec <container_id> jmap -dump:format=b,file=/tmp/heapdump.hprof <pid>
将堆转储文件从容器复制到宿主机
docker cp <container_id>:/tmp/heapdump.hprof /path/on/host