DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例
DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例
作者:CyPaul Space
原文地址:https://zhuanlan.zhihu.com/p/30289363967
全文阅读约3分钟~
背景
今天看到
论文:Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
论文地址:https://arxiv.org/pdf/2503.09516
这篇论文,发现其想法和前段时间自己的一个小实验不谋而合;
当然,特别指出,我只是测试基座模型(具体是QwQ-32B)的工具调用能力(不涉及微调训练),人家还专门针对工具调用和反思推理进行了再训练(具体是强化学习,但是我个人觉得SFT应该也会有差不多的效果); 所以也把自己的简单实践分享出来,具体如下:
引言
阿里最近新发布的
QwQ-32B:https://qwenlm.github.io/zh/blog/qwq-32b/
在推理模型中集成了与 Agent 相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。
特别地,我们可以在模型文件夹中的added_tokens.json文档中看到特别增加的工具调用和工具响应的特殊token
{"</think>": 151668,"</tool_call>": 151658,"</tool_response>": 151666,"<think>": 151667,"<tool_call>": 151657,"<tool_response>": 151665
}
所以,我们可以以Agentic RAG作为一个具体的场景,测试其端到端的检索增强的生成式问答的效果;
作为对比,我们特别强调下Agentic RAG和当前普遍的RAG实践的范式区别:
-
RAG:当前的绝大部分RAG项目实践本质上还是工作流:即"通过预定义的代码路径编排 LLM 和工具的系统"(人为事先定义的“写死的”工作流),由许多相互关联但脆弱的工作流组成:路由、分块、重排序、查询解释、查询扩展、源上下文化和搜索工程等;关于RAG的更多介绍可以参看本人之前的一个分享:高阶RAG(检索增强的生成式问答)雕花实践万字分享
评价:人为编排的工作流corner case太多,跟自动驾驶场景类似,你没办法一般化所有的场景,最后往往发现编排“工作流”上限有限;特别是在需要多轮检索等复杂场景下,效果更受限;
-
Agentic RAG:端到端,做减法,我只需要给模型配一个联网检索的api工具(本次案例中,具体是基于tavily的联网api,有一定的免费额度),剩下的全部由模型自己搞定(Less structure, more intelligence, Less is More),包括但不限于:
-
意图理解(联网判断)
-
问题改写或拆分
-
接口调用
-
流程编排(含是否多步检索,如何多步检索)
-
引用溯源
-
...
-
一个补充:Anthropic 关于Agent 模型定义: 类似于Deep Search,Agent必须在内部执行目标任务:它们"动态指导自己的过程和工具使用,控制完成任务的方式"
整体流程框架图
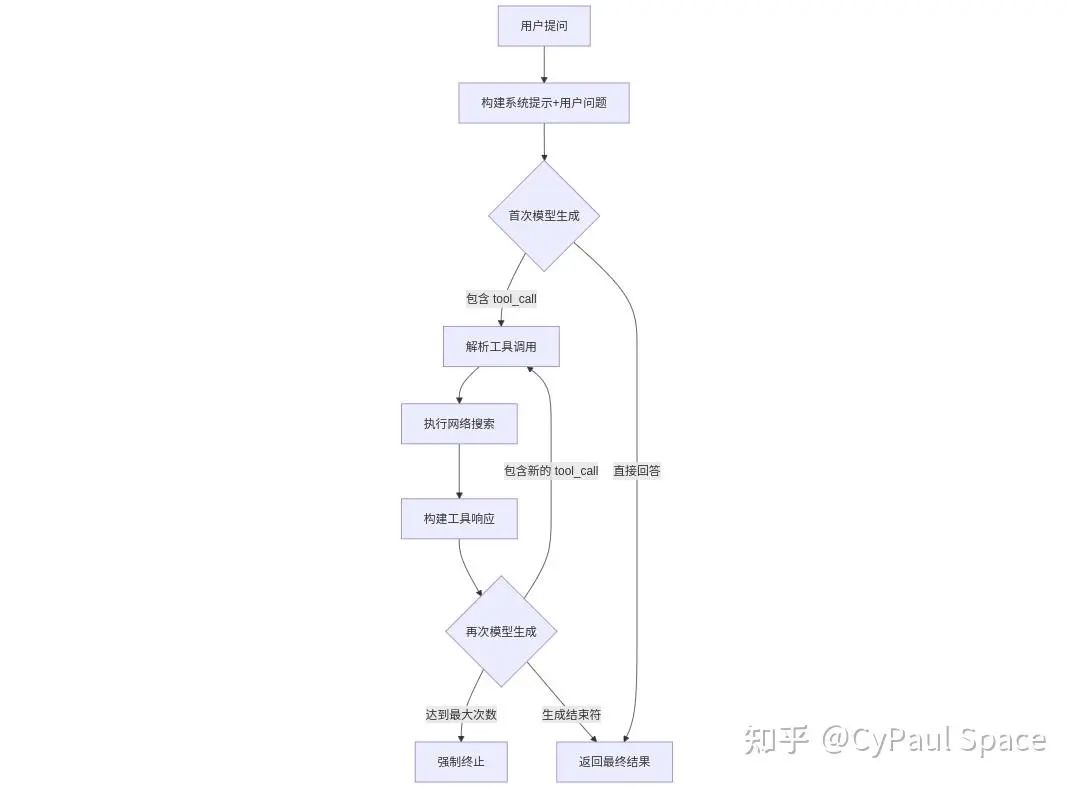
整体逻辑:
-
将用户问题适配到提示词模版 -> 调用模型generate新tokens,若生成中未出现<tool_call>...</tool_call>, 则直接输出返回
-
若出现<tool_call>...</tool_call>, 则表明模型推理过程中发起了一个工具调用申请,解析它,执行web_search,并将接口调用结果返回包装成<tool_response>...</tool_response>的格式续拼在大模型上下文中,再次请求大模型generate
-
重复执行,直到没有更多<tool_call>(或达到请求上限)或出现<|im_end|>
整体逻辑其实和Search-R1论文中的流程(如下所示)基本一致:

Search-R1推理流程.png
关键点说明
1、提示词框架模版:
user_question = input('请输入你的问题:')
max_search_times = 5prompt = f"""You are Qwen QwQ, a curious AI built for retrival augmented generation.
You are at 2025 and current date is {date.today()}.
You have access to the web_search tool to retrival relevant information to help answer user questions.
You can use web_search tool up to {max_search_times} times to answer a user's question, but try to be efficient and use as few as possible.
Below are some guidelines:
- Use web_search for general internet queries, like finding current events or factual information.
- Always provide a final answer in a clear and concise manner, with citations for any information obtained from the internet.
- If you think you need to use a tool, format your response as a tool call with the `action` and `action_input` within <tool_call>...</tool_call>, like this:\n<tool_call>\n{{ "action": "web_search", "action_input": {{ "query": "current stock price of Tesla" }} }}\n</tool_call>.
- After using a tool, continue your reasoning based on the web_search result in <tool_response>...</tool_response>.
- Remember that if you need multi-turn web_search to find relevant information, make sure you conduct all search tasks before you provide a final answer.
---
User Question:{user_question}"""
2、新增(自定义的)停止符
当检测到模型在自回归生成过程中触发了<tool_call>(.?)</tool_call>\s$格式(正则匹配)后,停止生成:
from transformers import (AutoModelForCausalLM,AutoTokenizer,StoppingCriteria,StoppingCriteriaList
)tool_call_regex = r"<tool_call>(.*?)</tool_call>\s*$"
end_regex = r"<\|im_end\|\>\s*$"# 同时监测: <tool_call> 或 <|im_end|>
class RegexStoppingCriteria(StoppingCriteria):def __init__(self, tokenizer, patterns):self.patterns = patternsself.tokenizer = tokenizerdef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:decoded_text = self.tokenizer.decode(input_ids[0])for pattern in self.patterns:if re.search(pattern, decoded_text, re.DOTALL):return Truereturn Falsestopping_criteria = StoppingCriteriaList([RegexStoppingCriteria(tokenizer,patterns=[tool_call_regex, end_regex])
])model.generate(..., topping_criteria=stopping_criteria) # 加上停止符
3、网络搜索api
本次实践中设置的搜索api为tavily,有一定的免费额度,方便实验和复现
详细实践
其他废话不多说了,详细实践代码详见:
DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例.ipynb
原文地址:https://github.com/Paul33333/experimental-notebook/blob/main/DeepSearch复现篇:QwQ_32B_ToolCall功能初探,以Agentic_RAG为例.ipynb
测试案例效果
我们下面直接看测试的效果;
测试问题:请给我详细介绍下阿里最近开源发布的QwQ-32B模型的相关信息
生成结果截图展示如下(声明:截图不完整,完整生成详见notebook):

生成结果之思考+工具调用部分.png
评价:可见,由推理模型自身完成了意图理解(是否联网搜索)&搜索关键词生成(问题改写或拆分,搜什么),而且其还特别思考了潜在的多轮搜索的场景(如果第一次搜索结果不够详细,可能需要进一步细化搜索词...),最后其成功触发了一次web search,然后我们响应其接口调用,并在接口返回结果包在<tool_response>...</tool_response>格式后续拼在上下文中

生成结果之最后报告部分1.png
生成结果之最后报告部分2.png
评价:本案例中,推理模型完成了一次的搜索接口调用,并根据搜索结果的反馈,直接生成了最后的输出报告(并未真正触发多轮搜索),一方面可能是案例的问题,但也有可能是基座模型不足以触发多轮搜索(本人也尝试了其他测试问题,均未真正触发多轮搜索),所以针对基座推理模型做智能体,确实还是有必要像Search-R1一样去做后训练进行针对性微调!
后续展望
基于:
-
具备使用工具的推理基座模型 (模型)
-
精心设计的合成(或人工整理)的再训练数据 (数据)
-
细分场景下的再次强化训练或SFT (算法)
-
只需要再掩码掉工具接口响应返回的输出tokens对应的损失(loss)即可
-
的再训练(针对智能体的SFT或强化学习)路线,应该会成为2025年智能体开发和部署的主流路线;
即post training用于智能体的训练,然后直接将模型用于端到端的推理(模型即产品)
再训练预先考虑了各种行动和边缘情况,使部署变得更简单,不再需要人为编排设计工作流。
【推荐阅读】:model-is-the-product: https://vintagedata.org/blog/posts/model-is-the-product

