【Spark入门】Spark RDD基础:转换与动作操作深度解析
目录
1 RDD编程模型概述
1.1 RDD操作分类
2 常用转换操作详解
2.1 基本转换操作
2.2 键值对转换操作
2.3 复杂转换操作
3 动作操作触发机制
3.1 常见动作操作
3.2 动作操作性能对比
4 RDD执行机制深度解析
4.1 惰性求值原理
4.2 任务生成过程
5 性能优化实践
5.1 转换操作优化建议
5.2 动作操作优化建议
6 总结
深入理解RDD的转换和动作操作是掌握Spark编程的基础。
1 RDD编程模型概述
RDD(Resilient Distributed Dataset,弹性分布式数据集)是Spark的核心数据抽象,代表一个不可变、可分区的元素集合,可以并行操作。理解RDD的转换(Transformation)和动作(Action)操作是掌握Spark编程的基础。
1.1 RDD操作分类
- 转换操作(Transformation):从现有RDD创建新RDD的惰性操作(如map、filter)
- 动作操作(Action):触发实际计算并返回结果到Driver或存储系统的操作(如count、collect)
- 惰性求值(Lazy Evaluation):转换操作不会立即执行,只有遇到动作操作时才触发计算
2 常用转换操作详解
2.1 基本转换操作
- map操作:元素级转换
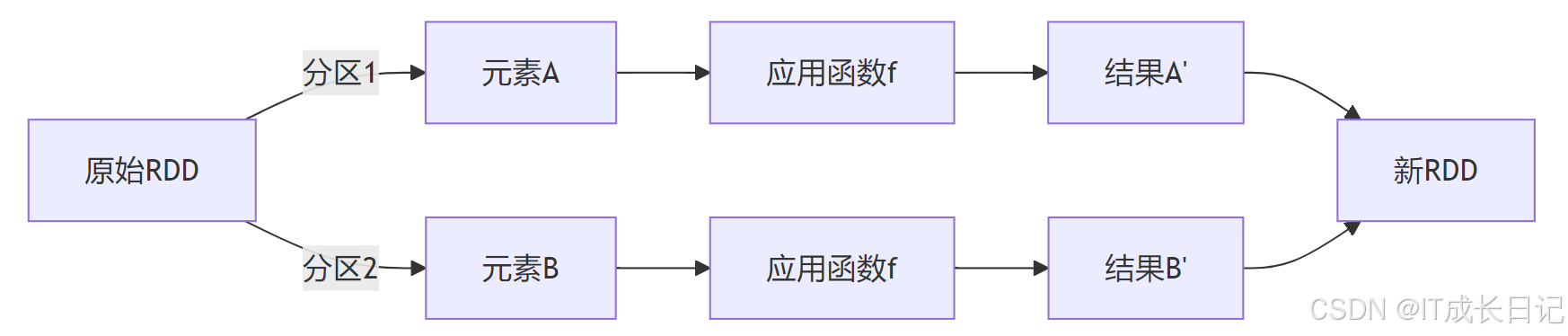
特点:
- 一对一转换:每个输入元素生成一个输出元素
- 保持分区数不变
- 示例:
rdd = sc.parallelize([1, 2, 3, 4])
squared = rdd.map(lambda x: x*x) # [1, 4, 9, 16]- filter操作:数据过滤
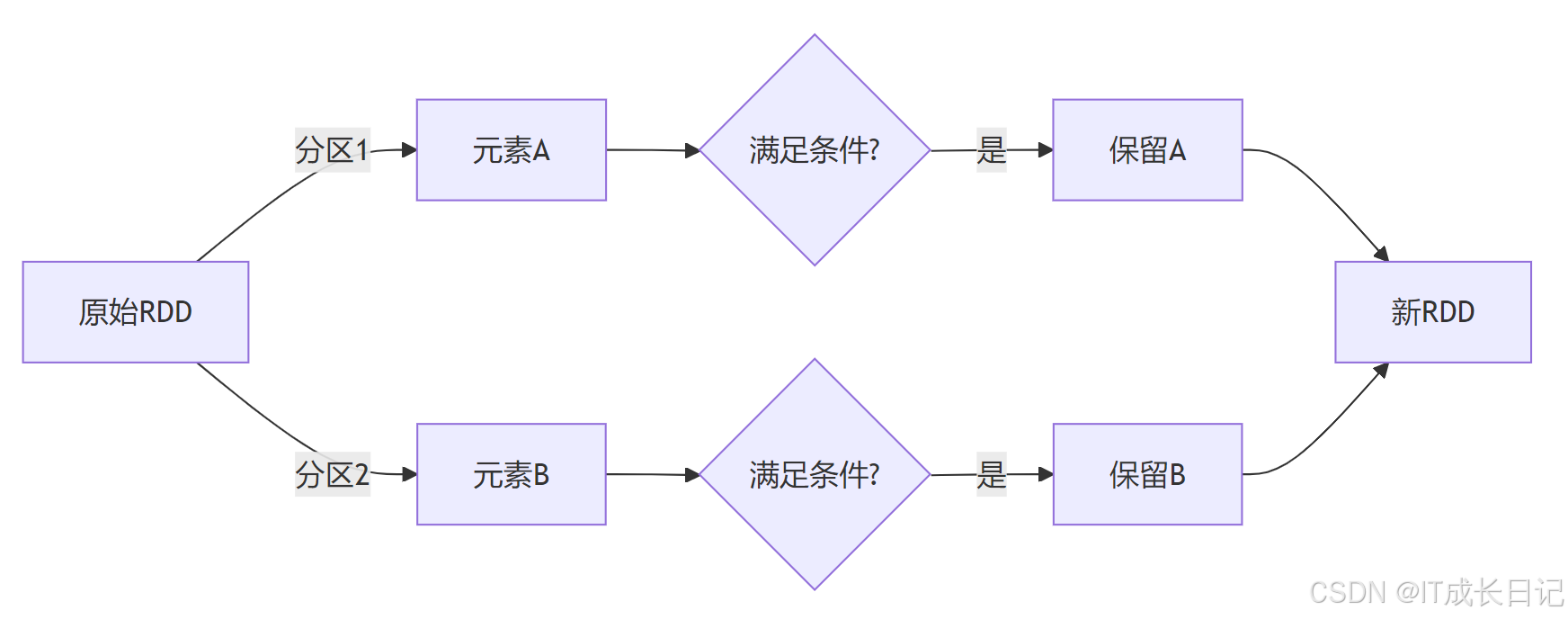
特点:可能减少数据量(分区数不变,但每个分区元素可能减少)
- 示例:
rdd = sc.parallelize([1, 2, 3, 4])
filtered = rdd.filter(lambda x: x > 2) # [3, 4]2.2 键值对转换操作
- reduceByKey操作:按键聚合
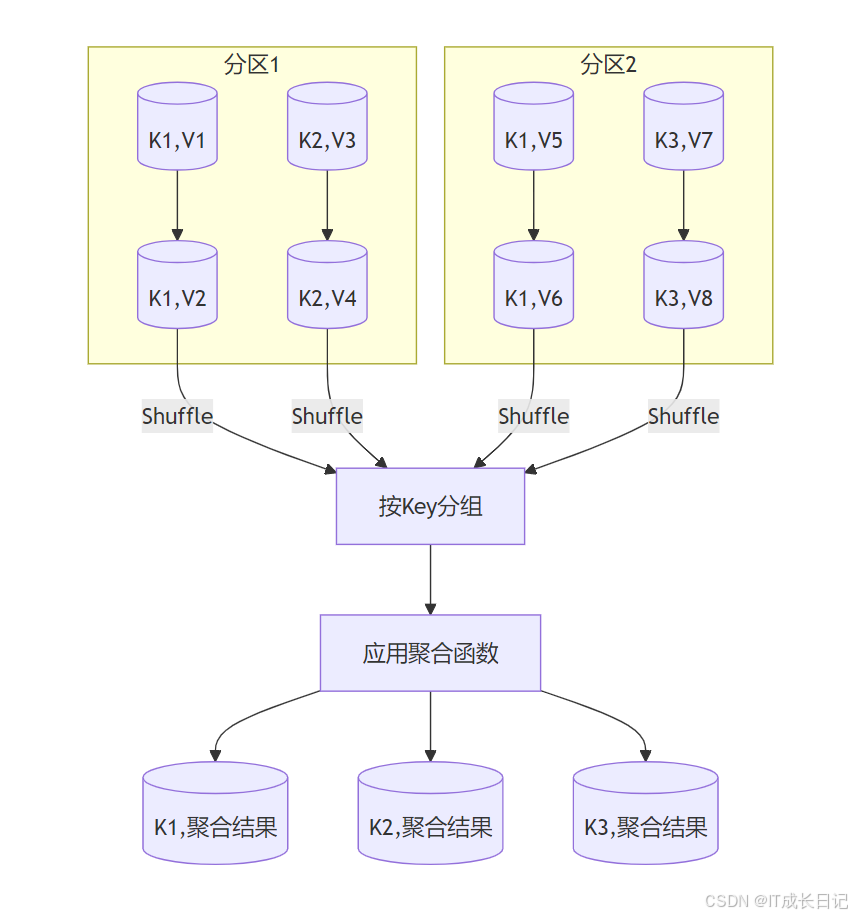
特点:
- 触发Shuffle操作
- 需要提供聚合函数(满足结合律和交换律)
- 示例:
rdd = sc.parallelize([("a", 1), ("b", 2), ("a", 3)])
reduced = rdd.reduceByKey(lambda x, y: x + y) # [("a", 4), ("b", 2)]- groupByKey操作:按键分组
| 特性 | reduceByKey | groupByKey |
| 网络传输 | 先本地聚合再Shuffle | 直接Shuffle所有数据 |
| 内存使用 | 更高效 | 可能OOM |
| 适用场景 | 聚合统计 | 需要原始分组数据 |
2.3 复杂转换操作
- join操作:数据集连接
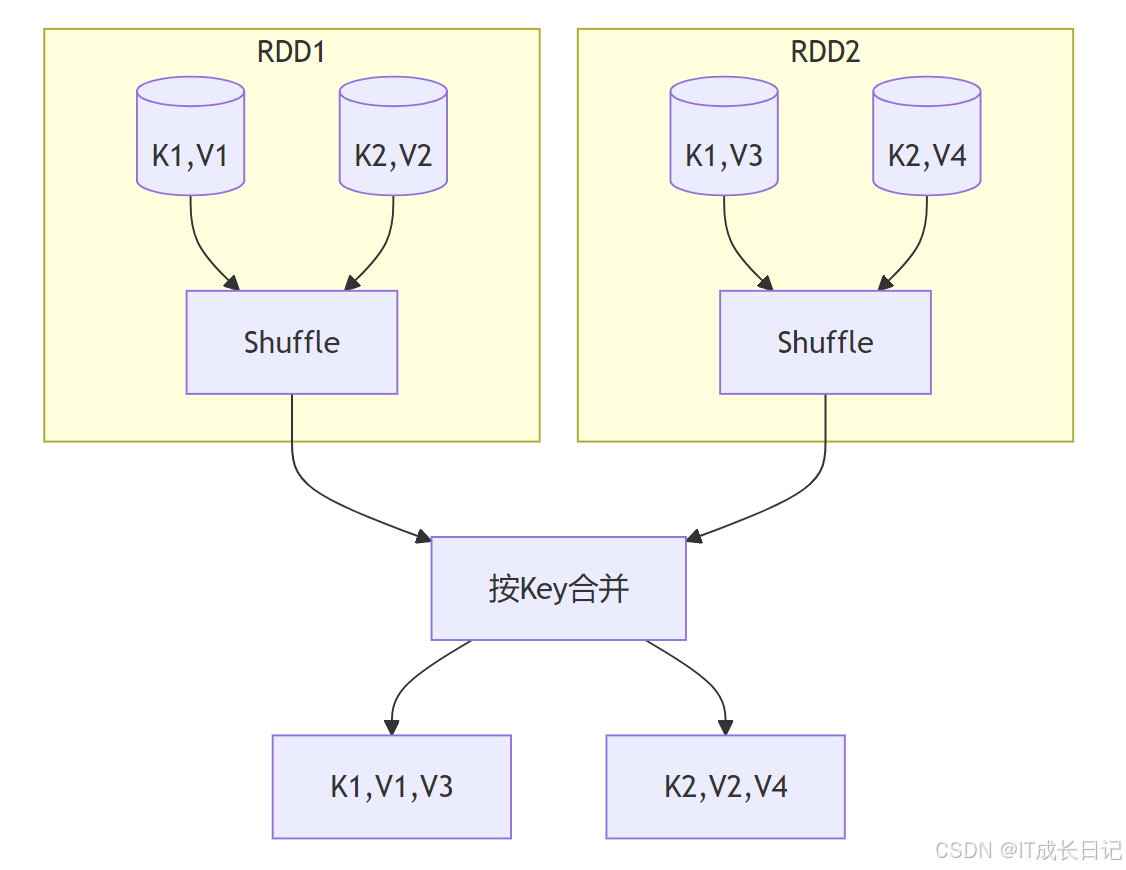
特点:
- 宽依赖操作,性能开销大
- 支持内连接、左外连接、右外连接等
- 示例:
rdd1 = sc.parallelize([(1, "A"), (2, "B")])
rdd2 = sc.parallelize([(1, "X"), (2, "Y")])
joined = rdd1.join(rdd2) # [(1, ("A", "X")), (2, ("B", "Y"))]3 动作操作触发机制
3.1 常见动作操作
- count操作:计数

特点:触发所有分区的计算
- 示例:
rdd = sc.parallelize([1, 2, 3, 4])
cnt = rdd.count() # 4- collect操作:数据收集

注意事项:所有数据会加载到Driver内存,大数据集慎用
- saveAsTextFile操作:数据保存

特点:每个分区生成一个输出文件
- 示例:
rdd = sc.parallelize([1, 2, 3, 4])
rdd.saveAsTextFile("hdfs://path/output")3.2 动作操作性能对比
| 动作操作 | 网络传输量 | Driver内存压力 | 适用场景 |
| count | 极小 | 低 | 统计记录数 |
| collect | 极大 | 高 | 小数据集收集 |
| take(n) | 中等 | 中 | 查看样本数据 |
| saveAsTextFile | 无 | 低 | 持久化大数据集 |
| foreach | 无 | 低 | 分布式处理无需返回结果 |
4 RDD执行机制深度解析
4.1 惰性求值原理
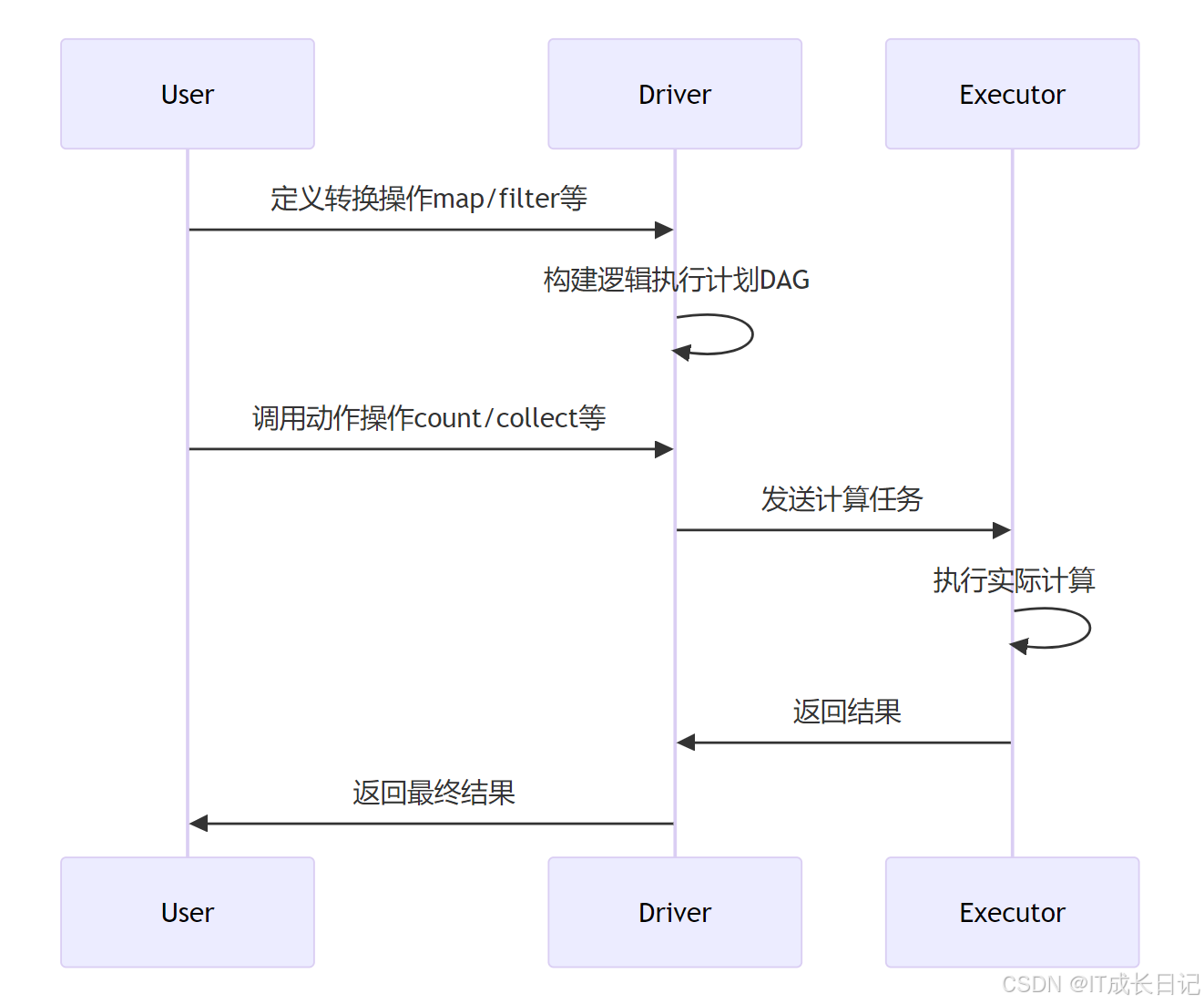
优势:
- 优化机会:Spark可以查看完整的DAG进行优化
- 减少IO:避免中间结果的磁盘写入
- 资源节省:按需计算,避免不必要的计算
4.2 任务生成过程
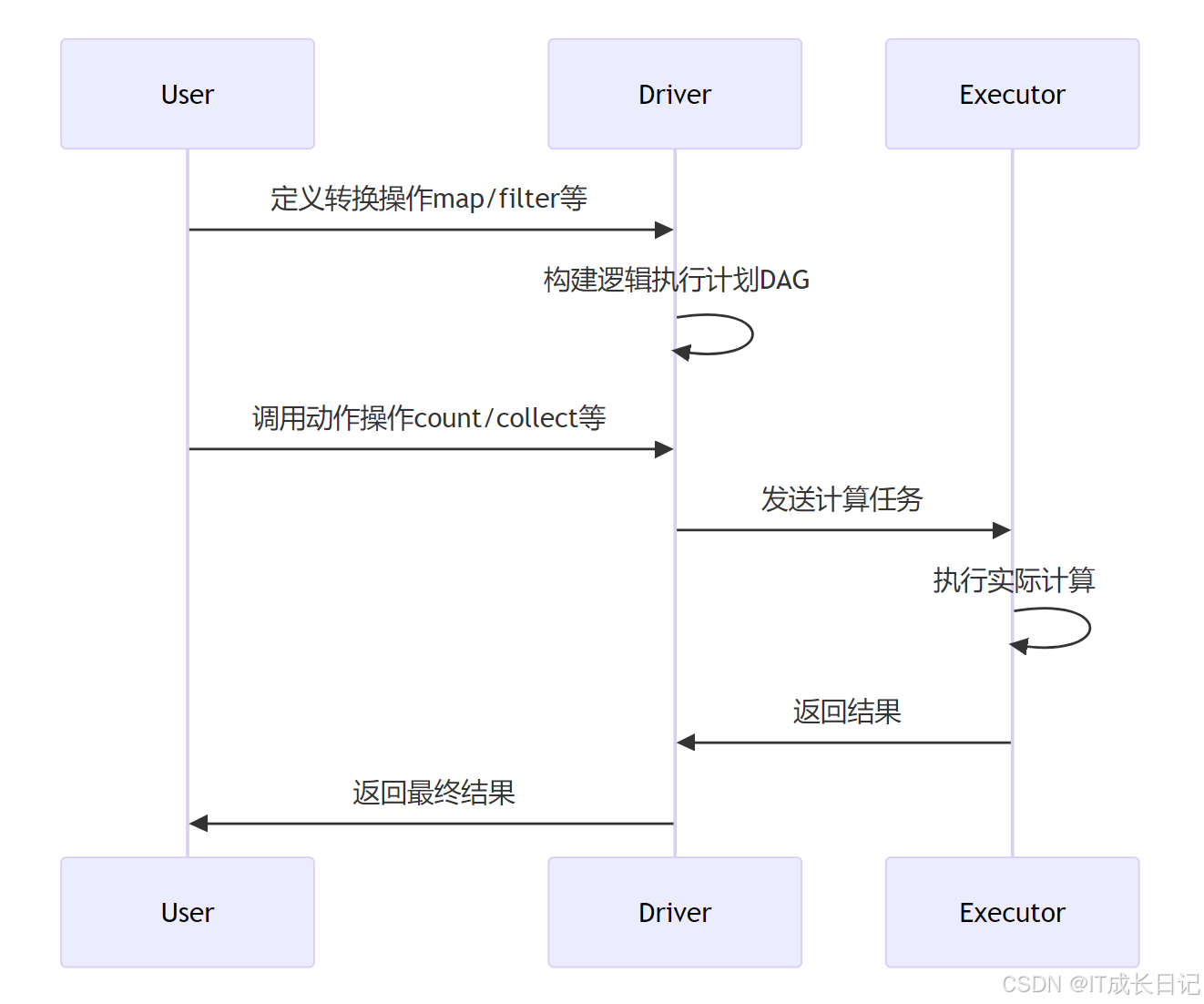
- Stage划分规则:
窄依赖:父RDD的每个分区最多被子RDD的一个分区使用
- map、filter、union等操作产生窄依赖
宽依赖:父RDD的每个分区被子RDD的多个分区使用
- reduceByKey、join、groupByKey等操作产生宽依赖
5 性能优化实践
5.1 转换操作优化建议
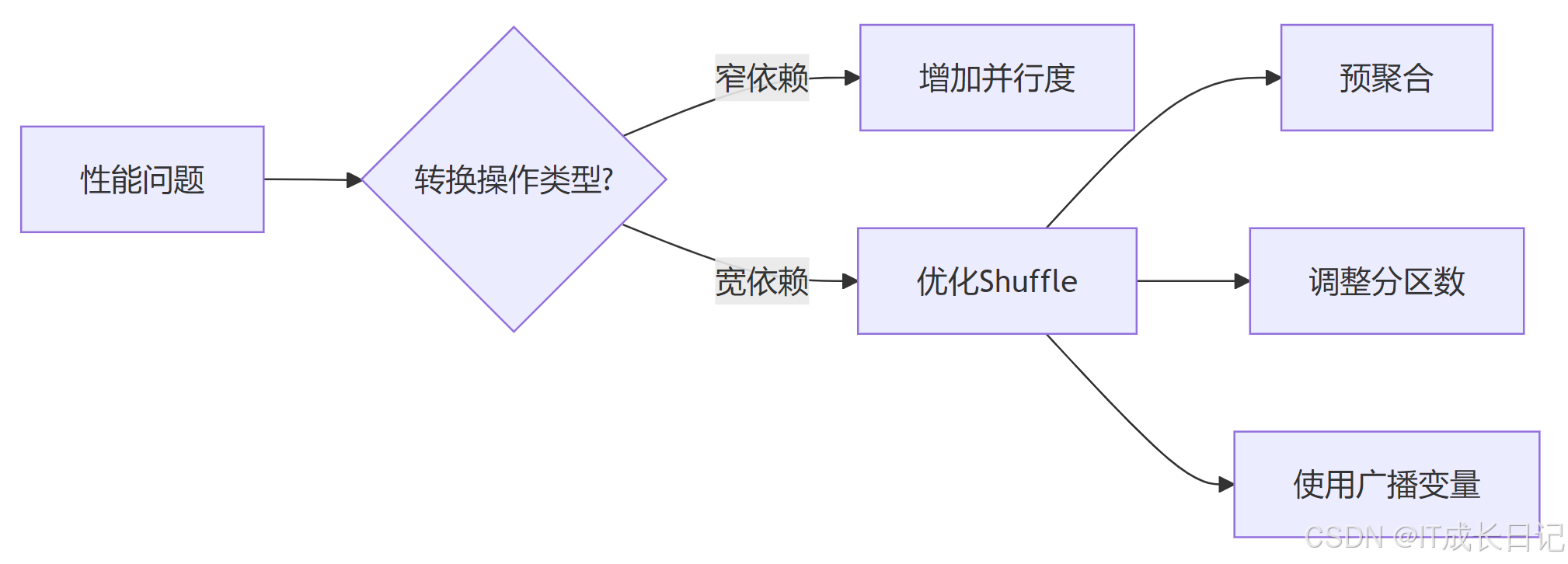
- 具体优化策略:
mapPartitions替代map:减少函数调用开销
# 低效方式
rdd.map(lambda x: func(x))# 高效方式
def process_partition(iterator):return [func(x) for x in iterator]
rdd.mapPartitions(process_partition)减少Shuffle:
- 使用reduceByKey替代groupByKey+map
- 使用broadcast join替代常规join(小表广播)
合理设置分区数:
# 设置合适的分区数
rdd = rdd.repartition(100)
# 根据集群核数调整5.2 动作操作优化建议
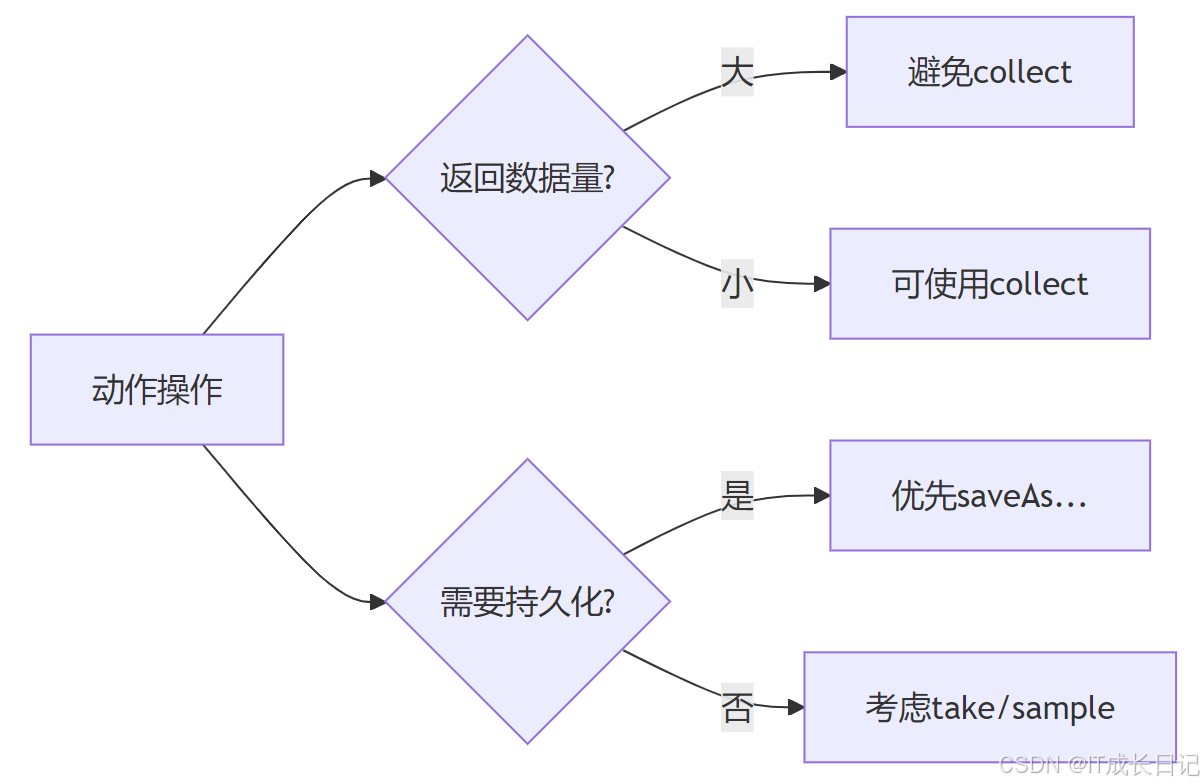
- 替代collect的方案:
# 危险操作(大数据集)
data = rdd.collect() # 安全替代方案
data = rdd.take(100) # 取前100条
data = rdd.sample(False, 0.1).collect() # 采样10%- 检查点优化:
# 对长血统RDD设置检查点
rdd.checkpoint() rdd.count()
# 触发实际检查点操作6 总结
深入理解RDD的转换和动作操作是掌握Spark编程的基础。