MCP 模型上下文协议配置MCP Server开发实践
MCP (Model Context Protocol)模型上下文协议
文章目录
- MCP (Model Context Protocol)模型上下文协议
- 什么是 MCP?
- 为什么需要 MCP?
- MCP Architecture 解构
- 原理:模型是如何确定工具的选用的?
- 模型如何智能选择工具?
- 工具执行与结果反馈机制
- 总结
- Appendix A:MCP Server 开发实践
本篇引用了以下两个连接中的内容
https://zhuanlan.zhihu.com/p/29001189476
https://zhuanlan.zhihu.com/p/17395202545
- 什么是 MCP?
- 为什么需要 MCP?
- 作为用户,我们如何使用/开发 MCP?
什么是 MCP?
官方语言:
MCP 是一个开放协议,它为应用程序向 LLM 提供上下文的方式进行了标准化。你可以将 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 为设备连接各种外设和配件提供了标准化的方式一样,MCP 为 AI 模型连接各种数据源和工具提供了标准化的接口。
mcp定义了应用程序和ai模型之间交换上下文的方式,开发者能够以一致的方式将各种数据源、工具和功能连接到AI模型(中间协议层),就像USB-C让不同的设备能够通过相同的接口连接,MCP也是创建一个通用标准,使AI应用程序的开发和集成变得更简单、统一。
以更标准的方式让 LLM Chat 使用不同工具
为什么需要 MCP?
它可能是prompt engineering发展的产物。更结构化的上下文信息对模型的performance提升是显著的**。在构造prompt时也是提供更specific的信息(本地文件、上下文、网络实时信息等)给模型,这样模型更容易理解真实场景的问题**。
这些信息都是通过@文件、或者从数据库检索信息复制到上下文中,手动粘贴这些prompt,这些手工prompt很有局限性,需要克服它
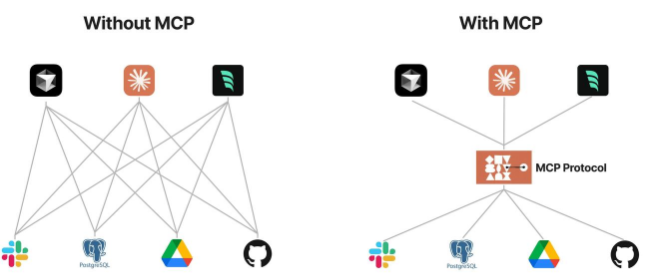
目前很多LLM平台(Open AI、Google)引入function call功能,允许模型在需要时调用预定义的函数获取数据或执行操作,::显著提升了自动化水平。
这个function call,各个LLM平台的API差异也较大,调用都不兼容,增加适配成本、安全性、交互性等问题
而这个MCP就是AI模型的“万能转接头”,让LLM能轻松的获取数据或调用工具
MCP 的优势在于:
- 生态 - MCP 提供很多现成的插件,你的 AI 可以直接使用。
- 统一性 - 不限制于特定的 AI 模型,任何支持 MCP 的模型都可以灵活切换。
- 数据安全 - 你的敏感数据留在自己的电脑上,不必全部上传。(因为我们可以自行设计接口确定传输哪些数据)
MCP Architecture 解构
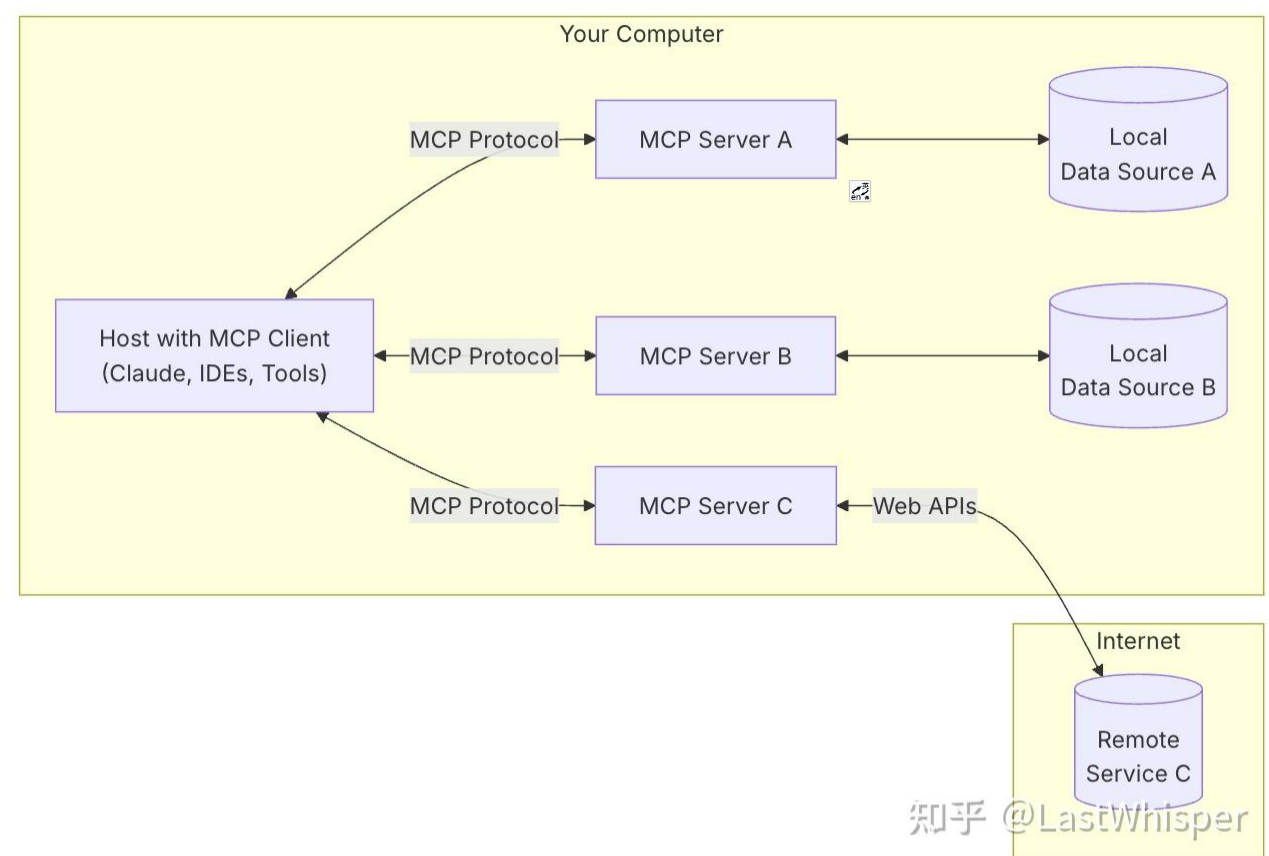
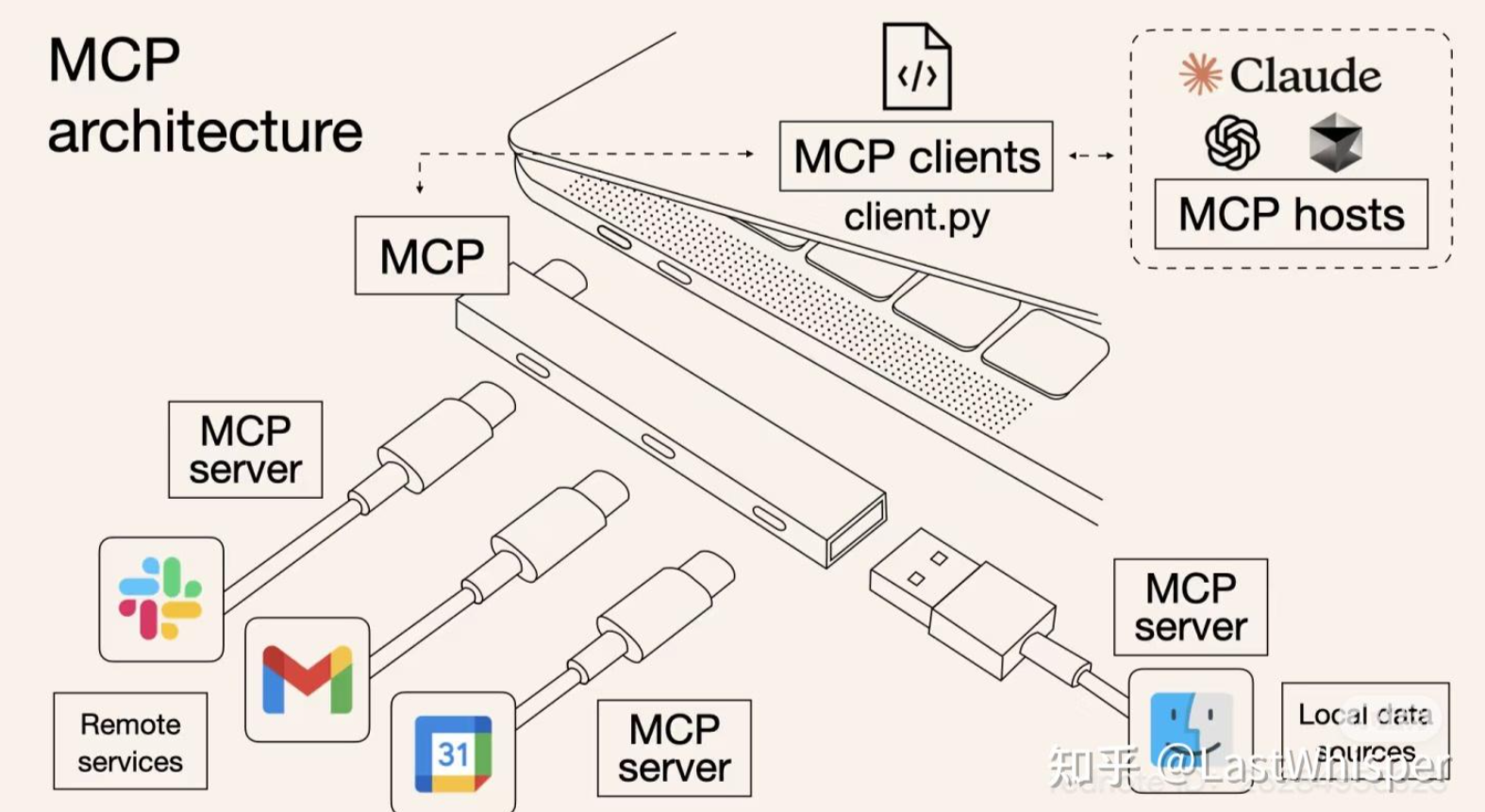
MCP由Host、Client、Server组成,
假设你正在使用 Claude Desktop (Host) 询问:“我桌面上有哪些文档?”
- Host:Claude Desktop 作为 Host,负责接收你的提问并与 Claude 模型交互。
- Client:当 Claude 模型决定需要访问你的文件系统时,Host 中内置的 MCP Client 会被激活。这个 Client 负责与适当的 MCP Server 建立连接。
- Server:在这个例子中,文件系统 MCP Server 会被调用。它负责执行实际的文件扫描操作,访问你的桌面目录,并返回找到的文档列表。
原理:模型是如何确定工具的选用的?
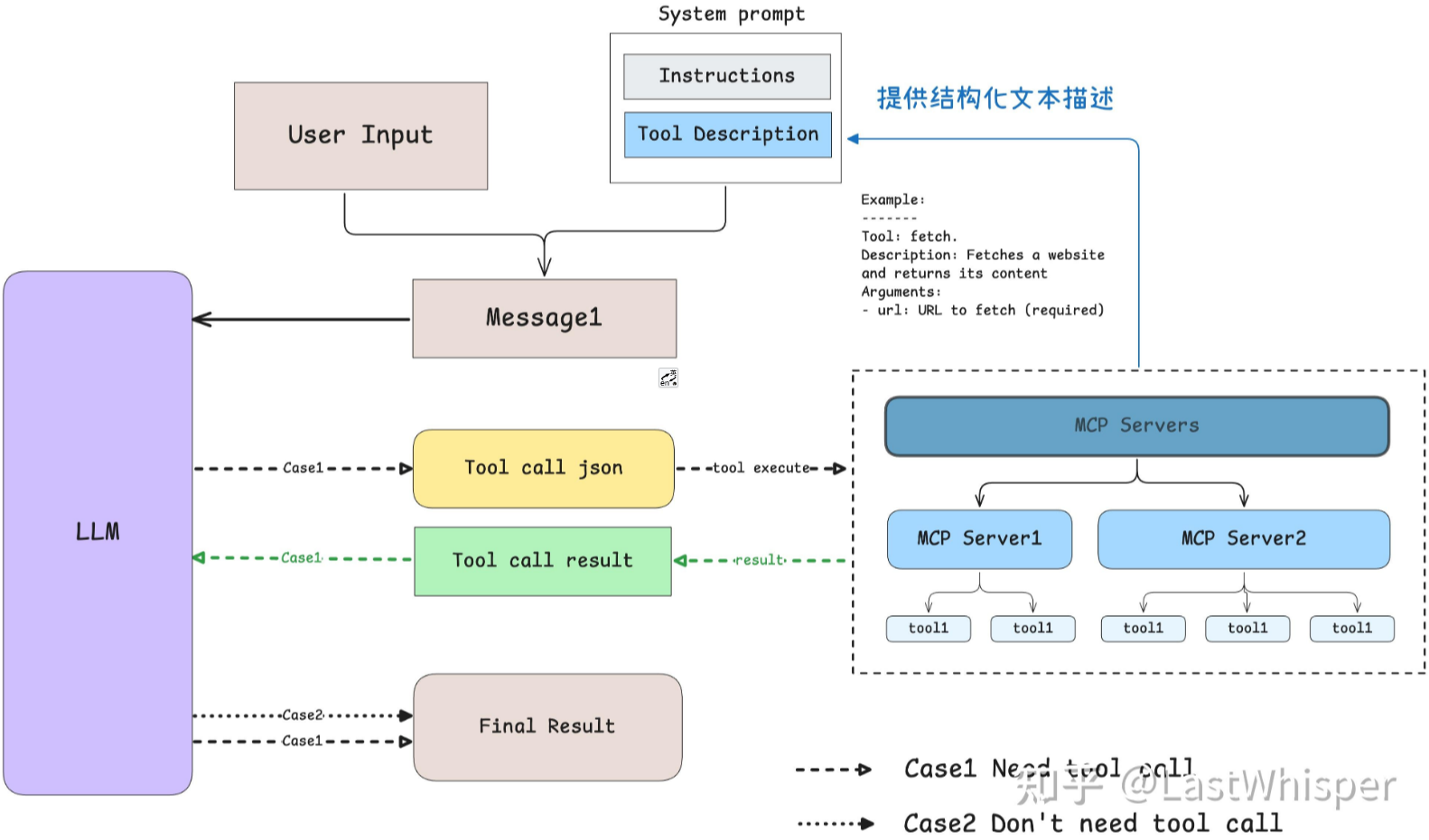
Claude(LLM模型)是在什么时候确定使用哪些工具的呢?
当用户提出一个问题时:
- 客户端(Claude Desktop / Cursor)将你的问题发送给 Claude。
- Claude 分析可用的工具,并决定使用哪一个(或多个)。
- 客户端通过 MCP Server 执行所选的工具。
- 工具的执行结果被送回给 Claude。
- Claude 结合执行结果构造最终的 prompt 并生成自然语言的回应。
- 回应最终展示给用户!
MCP Server 是由 Claude 主动选择并调用的。有意思的是 Claude 具体是如何确定该使用哪些工具呢?以及是否会使用一些不存在的工具呢(幻觉)?
调用过程分两个步骤
- 由 LLM(Claude)确定使用哪些 MCP Server。
- 执行对应的 MCP Server 并对执行结果进行重新处理。
模型如何智能选择工具?
模型是通过 prompt 来确定当前有哪些工具。我们通过将工具的具体使用描述以文本的形式传递给模型,供模型了解有哪些工具以及结合实时情况进行选择。
以下是底层代码
... # 省略了无关的代码async def start(self):# 初始化所有的 mcp serverfor server in self.servers:await server.initialize()# 获取所有的 tools 命名为 all_toolsall_tools = []for server in self.servers:tools = await server.list_tools()all_tools.extend(tools)# 将所有的 tools 的功能描述格式化成字符串供 LLM 使用# tool.format_for_llm() 我放到了这段代码最后,方便阅读。tools_description = "\n".join([tool.format_for_llm() for tool in all_tools])# 这里就不简化了,以供参考,实际上就是基于 prompt 和当前所有工具的信息# 询问 LLM(Claude) 应该使用哪些工具。system_message = ("You are a helpful assistant with access to these tools:\n\n"f"{tools_description}\n""Choose the appropriate tool based on the user's question. ""If no tool is needed, reply directly.\n\n""IMPORTANT: When you need to use a tool, you must ONLY respond with ""the exact JSON object format below, nothing else:\n""{\n"' "tool": "tool-name",\n'' "arguments": {\n'' "argument-name": "value"\n'" }\n""}\n\n""After receiving a tool's response:\n""1. Transform the raw data into a natural, conversational response\n""2. Keep responses concise but informative\n""3. Focus on the most relevant information\n""4. Use appropriate context from the user's question\n""5. Avoid simply repeating the raw data\n\n""Please use only the tools that are explicitly defined above.")messages = [{"role": "system", "content": system_message}]while True:# Final... 假设这里已经处理了用户消息输入.messages.append({"role": "user", "content": user_input})# 将 system_message 和用户消息输入一起发送给 LLMllm_response = self.llm_client.get_response(messages)... # 后面和确定使用哪些工具无关class Tool:"""Represents a tool with its properties and formatting."""def __init__(self, name: str, description: str, input_schema: dict[str, Any]) -> None:self.name: str = nameself.description: str = descriptionself.input_schema: dict[str, Any] = input_schema# 把工具的名字 / 工具的用途(description)和工具所需要的参数(args_desc)转化为文本def format_for_llm(self) -> str:"""Format tool information for LLM.Returns:A formatted string describing the tool."""args_desc = []if "properties" in self.input_schema:for param_name, param_info in self.input_schema["properties"].items():arg_desc = (f"- {param_name}: {param_info.get('description', 'No description')}")if param_name in self.input_schema.get("required", []):arg_desc += " (required)"args_desc.append(arg_desc)return f"""Tool: {self.name}Description: {self.description}Arguments:{chr(10).join(args_desc)}"""
那 tool 的描述和代码中的 input_schema 是从哪里来的呢?通过进一步分析 MCP 的 Python SDK 源代码可以发现:大部分情况下,当使用装饰器 @mcp.tool() 来装饰函数时,对应的 name 和 description 等其实直接源自用户定义函数的函数名以及函数的 docstring 等。
总结:模型是通过 prompt engineering,即提供所有工具的结构化描述和 few-shot 的 example 来确定该使用哪些工具。另一方面,Anthropic 肯定对 Claude 做了专门的训练(毕竟是自家协议,Claude 更能理解工具的 prompt 以及输出结构化的 tool call json 代码)
工具执行与结果反馈机制
工具的执行就比较简单和直接了。承接上一步,我们把 system prompt(指令与工具调用描述)和用户消息一起发送给模型,然后接收模型的回复。当模型分析用户请求后,它会决定是否需要调用工具:
- 无需工具时:模型直接生成自然语言回复。
- 需要工具时:模型输出结构化 JSON 格式的工具调用请求。(cursor把用户的输入按照需要的工具,转换成对应的json格式调用请求)
如果回复中包含结构化 JSON 格式的工具调用请求,则客户端会根据这个 json 代码执行对应的工具。具体的实现逻辑都在 process_llm_response 中,代码,逻辑非常简单。(客户端即数据库等,然后把json中的请求内容执行工具,然后这个返回的叫result)
如果模型执行了 tool call,则工具执行的结果 result 会和 system prompt 和用户消息一起重新发送给模型,请求模型(host)生成最终回复。
如果 tool call 的 json 代码存在问题或者模型产生了幻觉怎么办呢?
通过阅读代码 发现,我们会 skip 掉无效的调用请求。(即server工具不认识的请求就不干活)
... # 省略无关的代码async def start(self):... # 上面已经介绍过了,模型如何选择工具while True:# 假设这里已经处理了用户消息输入.messages.append({"role": "user", "content": user_input})# 获取 LLM 的输出llm_response = self.llm_client.get_response(messages)# 处理 LLM 的输出(如果有 tool call 则执行对应的工具)result = await self.process_llm_response(llm_response)# 如果 result 与 llm_response 不同,说明执行了 tool call (有额外信息了)# 则将 tool call 的结果重新发送给 LLM 进行处理。if result != llm_response:messages.append({"role": "assistant", "content": llm_response})messages.append({"role": "system", "content": result})final_response = self.llm_client.get_response(messages)logging.info("\nFinal response: %s", final_response)messages.append({"role": "assistant", "content": final_response})# 否则代表没有执行 tool call,则直接将 LLM 的输出返回给用户。else:messages.append({"role": "assistant", "content": llm_response})
- 工具文档至关重要 - 模型通过工具描述文本来理解和选择工具,因此精心编写工具的名称、docstring 和参数说明至关重要。
- 由于 MCP 的选择是基于 prompt 的,所以任何模型其实都适配 MCP,只要你能提供对应的工具描述。但是当你使用非 Claude 模型时,MCP 使用的效果和体验难以保证(没有做专门的训练)。
总结
MCP (Model Context Protocol) 代表了 AI 与外部工具和数据交互的标准建立。通过本文,我们可以了解到:
- MCP 的本质:它是一个统一的协议标准,使 AI 模型能够以一致的方式连接各种数据源和工具,类似于 AI 世界的"USB-C"接口。
- MCP 的价值:它解决了传统 function call 的平台依赖问题,提供了更统一、开放、安全、灵活的工具调用机制,让用户和开发者都能从中受益。
- 使用与开发:对于普通用户,MCP 提供了丰富的现成工具,用户可以在不了解任何技术细节的情况下使用;对于开发者,MCP 提供了清晰的架构和 SDK,使工具开发变得相对简单。
Appendix A:MCP Server 开发实践
对绝大部分 AI 开发者来说,我们只需要关心 Server 的实现。因此,我这里准备通过一个最简单的示例来介绍如何实现一个 MCP Server。
MCP servers 可以提供三种主要类型的功能:
- Resources(资源):类似文件的数据,可以被客户端读取(如 API 响应或文件内容)
- Tools(工具):可以被 LLM 调用的函数(需要用户批准)
- Prompts(提示):预先编写的模板,帮助用户完成特定任务
本教程将主要关注工具(Tools)。
在trae(一种集成ai的开发工具,也可以用cursor)中可以快速简单的构建mcp server
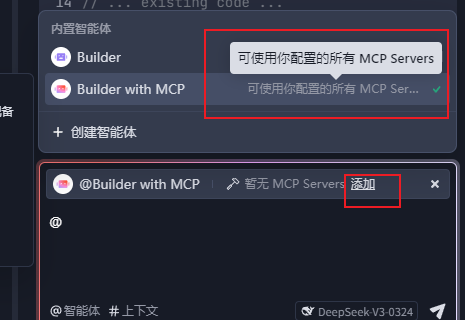
https://deepseek.apifox.cn/ 文档为例,说一下怎么手动配置 Apifox MCP Server。
另外https://docs.apifox.com/6327888m0中教学怎么配置自己的apifox文档接口,需要去自己的api文档上拉取个人令牌token以及项目id,通过这段json手动配置mcp即可,之后可以直接调用这个智能体了
{"mcpServers": {"API 文档": {"command": "cmd","args": ["/c","npx","-y","apifox-mcp-server@latest","--project=<project-id>"],"env": {"APIFOX_ACCESS_TOKEN": "<access-token>"}}}
}
当你将这段mcp配置写好之后,将token值也写好自己的了,可以直接复制粘贴到你的mcp server的目的地,点击错误没有报错,说连接成功,那就是配置好了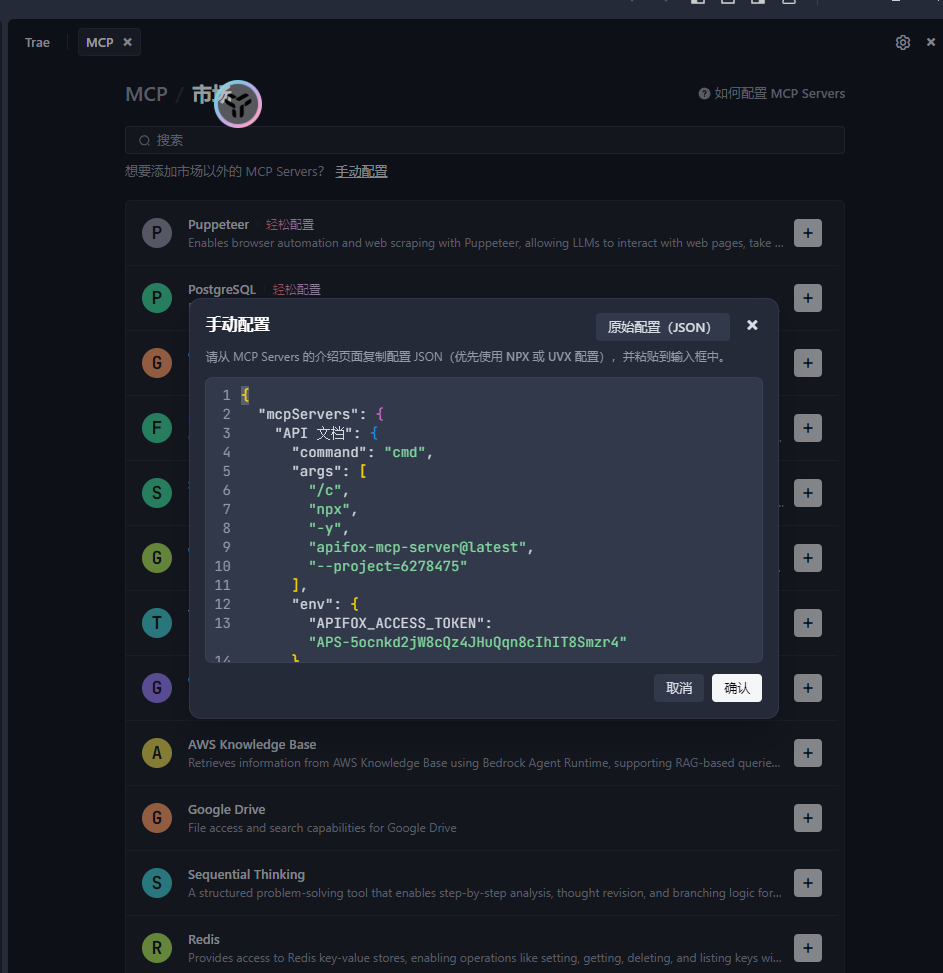
注意:这个智能体还是有点笨的,如果内部绑定了多个智能体,有时候它是不能够只能的分析要用哪个api文档,或者说不知道要调用哪个mcp server了。需要在问问题的时候进行提示,以及这个绑定了apifox文档时,是本地缓存,所以如果你的apifox文档进行了更新,需要手动的告诉智能体,让他刷新毕业设计项目的OpenAPI Spec文件内容以获取最新状态。
我在学习mcp的时候首先安装了一个 Claude for Desktop,根据官网的文档看的做自己电脑上的mcp服务配置,能够操作自己电脑的文件,通过下载了@modelcontextprotocol/server-filesystem的server,它是Anthropic 维护的官方库,通过在开发者选项编辑配置
{"mcpServers": {"filesystem": {"command": "npx","args": ["-y","@modelcontextprotocol/server-filesystem","C:\\Users\\朱宗宁\\Desktop","C:\\Users\\朱宗宁\\Downloads"]}}
}
给予它两个权限,后续它就可以实现操纵我的电脑,比如说写一首诗然后保存到我的电脑上。
Claude 会在执行操作前征求您的许可:然后就让它允许本次聊天权限就可。
但是他说我们国家不支持。(需要开代理),实现之后我是在我的cursor上安装了一个apifox的server,在这之后就可以通过智能体扫描apifox里面的项目文档数据了,在之后我做毕业设计开发的时候是直接配合这个接口进行开发。
type "%APPDATA%\Claude\logs\mcp*.log" 查看日志
其中 type 意思是显示文本文件内容的内置命令。
-
%APPDATA%
是 Windows 的环境变量,指向当前用户的应用程序数据文件夹(路径通常为C:\Users\[你的用户名]\AppData\Roaming)。 -
\Claude\logs\mcp\*.log
表示在 Claude 的日志文件夹中,查找所有以mcp开头、.log结尾的日志文件(例如mcp-server.log)。
这个Claude3.5系列也有不同的模型


使用cusor配置mysql的mcp
https://cloud.tencent.com/developer/article/2512737
这种没有的官方支持的mcp,也可以通过gpt生成python代码生成一个自己的mcp server,之后在cusor配置的时候其中arg字段直接改成.py文件的地址