阿里开源图生动画模型AnimateAnyone2
项目背景

近年来,基于扩散模型(diffusion models)的人物图像动画化方法取得了显著进展,例如 Animate Anyone 在生成一致性和泛化性方面表现优异。然而,这些方法在处理人物与环境之间的空间关系和人-物体交互(human-object interaction)时存在局限性,生成的动画往往无法自然融入环境上下文。例如,人物动作可能与环境不协调,缺乏合理的互动性。
Animate Anyone 2 的目标是解决这一问题,通过引入环境表征(environment affordance)作为条件输入,生成能够与环境协调一致的人物动画。具体而言,该模型将环境定义为视频中排除人物的区域,并通过生成符合环境上下文的人物来实现这一目标。这一创新旨在提升动画的真实感和实用性,尤其适用于需要复杂场景互动的应用程序,如虚拟现实(VR)、游戏开发和电影特效。
技术架构
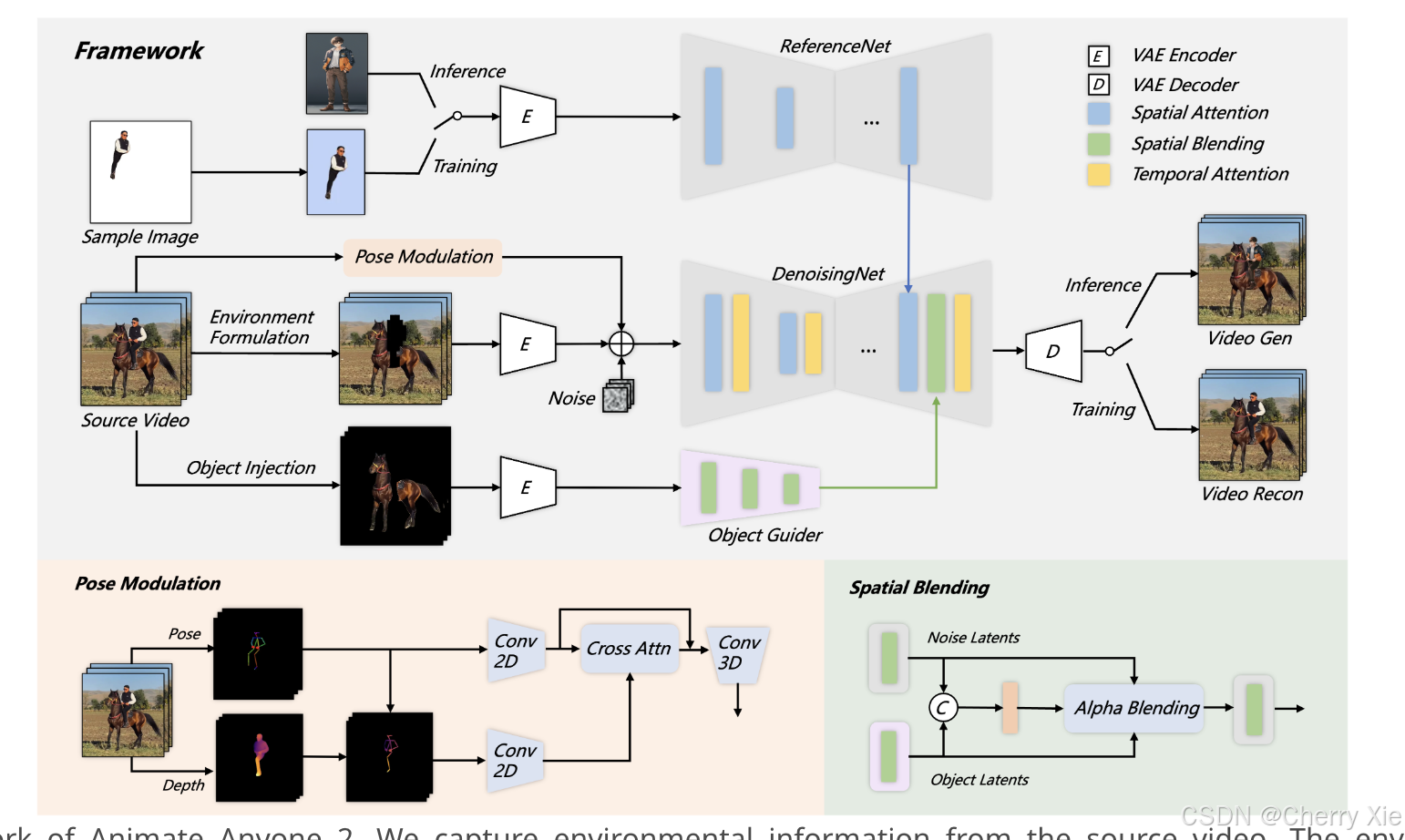
Animate Anyone 2 的技术架构基于扩散模型框架,特别是潜在扩散模型(Latent Diffusion Models, LDM),其核心是通过预训练的变分自编码器(Variational Autoencoder, VAE)将图像转换为潜在空间(latent space),以减少计算复杂度并提升生成质量。
扩散模型框架
-
基础架构: 模型扩展了 2D UNet 为 3D UNet,结合了 AnimateDiff 的时间层(temporal layers),以处理视频序列的生成。
-
训练目标: 训练目标是最小化预测噪声与实际噪声之间的均方误差。
-
实现细节: 训练使用 8 个 NVIDIA A100 GPU,训练 100,000 步,批量大小为 8,视频长度为 16 帧。中心裁剪确保角色包含在帧内,参考图像随机采样,并与随机背景合成。
条件生成机制
-
外观特征提取: 使用 ReferenceNet 从参考图像中提取外观特征,通过空间注意力机制(spatial attention)在 midblock 和 upblock 中与扩散模型融合。
-
条件嵌入: 条件嵌入包括环境序列、动作序列和物体序列,分别通过 VAE 编码器、姿态调制和物体引导器处理。这些条件输入确保生成的动画与驱动视频的上下文一致。
物体注入与空间融合
-
物体引导器(Object Guider): 采用轻量级的全卷积架构(fully convolutional architecture),从物体潜在表示中提取多尺度特征,通过 3x3 Conv2D 下采样四次,与 DenoisingNet 的 midblock 和 upblock 对齐。
-
物体提取: 使用视觉语言模型(VLM)进行定位,或手动标注,随后通过 SAM2 提取掩码。

姿态调制与时间建模
- 深度姿态调制: 使用 Sapien 工具提取骨骼和深度信息,通过 Conv2D 处理后,通过交叉注意力(cross-attention)将深度信息融入骨骼特征。
- 时间建模: 使用 Conv3D 进行时间建模,处理多样化的动作模式,确保动画的流畅性和一致性。
推理与长视频处理
推理时,长视频被分割为多个片段,每个片段使用前一个片段的最后一帧作为时间参考,确保过渡平滑。例如,生成的动画片段在 TikTok 数据集上的表现显示出优异的流体性和动态性,尤其在处理复杂动作(如 Joaquin Phoenix 的 Joker 流动作)时表现突出。
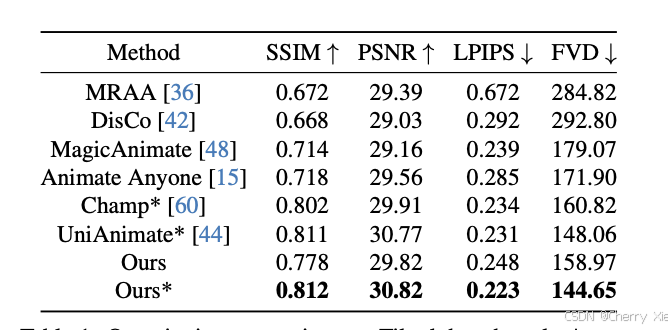
性能对比
详见技术报告

看看效果
相关文献
官方地址:https://humanaigc.github.io/animate-anyone-2/
技术报告:https://arxiv.org/pdf/2502.06145