机器学习第十四课--神经网络
总结起来,对于深度学习的发展跟以下几点是离不开的:
- 大量的数据(大数据)
- 计算资源(如GPU)
- 训练方法(如预训练)
很多时候,我们也可以认为真正让深度学习爆发起来的是数据和算力,这并不是没道理的。
由于神经网络是深度学习的基础,学习神经网络本身是非常必要的。神经网络中所涉及到的前向传播、反向传播等技术以及梯度消失等现象都会出现在其他深度学习模型如深度神经网络、卷积神经网络、RNN、LSTM中。我们强烈先学好神经网络再去接触深度学习相关的技术,这样会事半功倍。
神经网络,首先是线性变换,然后通过激活函数非线性化
一.线性激活函数
线性激活函数实际上是没作用的,即便加了也等于什么都没加,因为它对信号不会做任何的处理。这有点类似于管道,来了信号之后原封不动地输出出去。之所以提出线性激活函数,其主要目的是为了完整性。那什么会用到线性激活函数呢?通常在,深度模型中的最后一层会用到。另外,如果我们没有叠加任何的激活函数到神经元,默认可以认为是加了线性激活函数。
二.非线性激活函数
2.1Sigmoid激活函数
定义域 :负无穷到正无穷
值域:0到1
特点:
1.值域映射到0-1
2.有边界
3.递增

2.2二分类问题
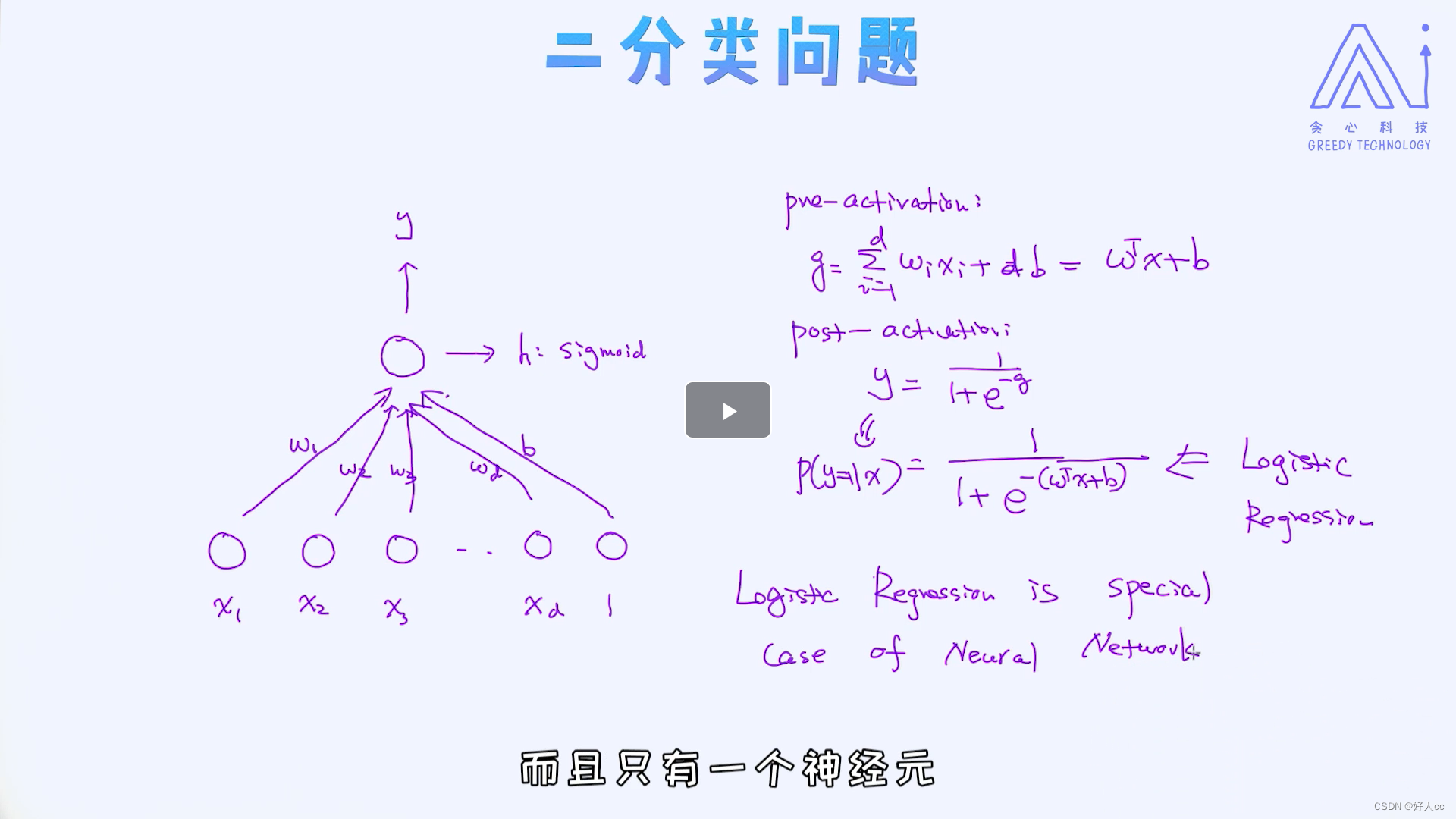
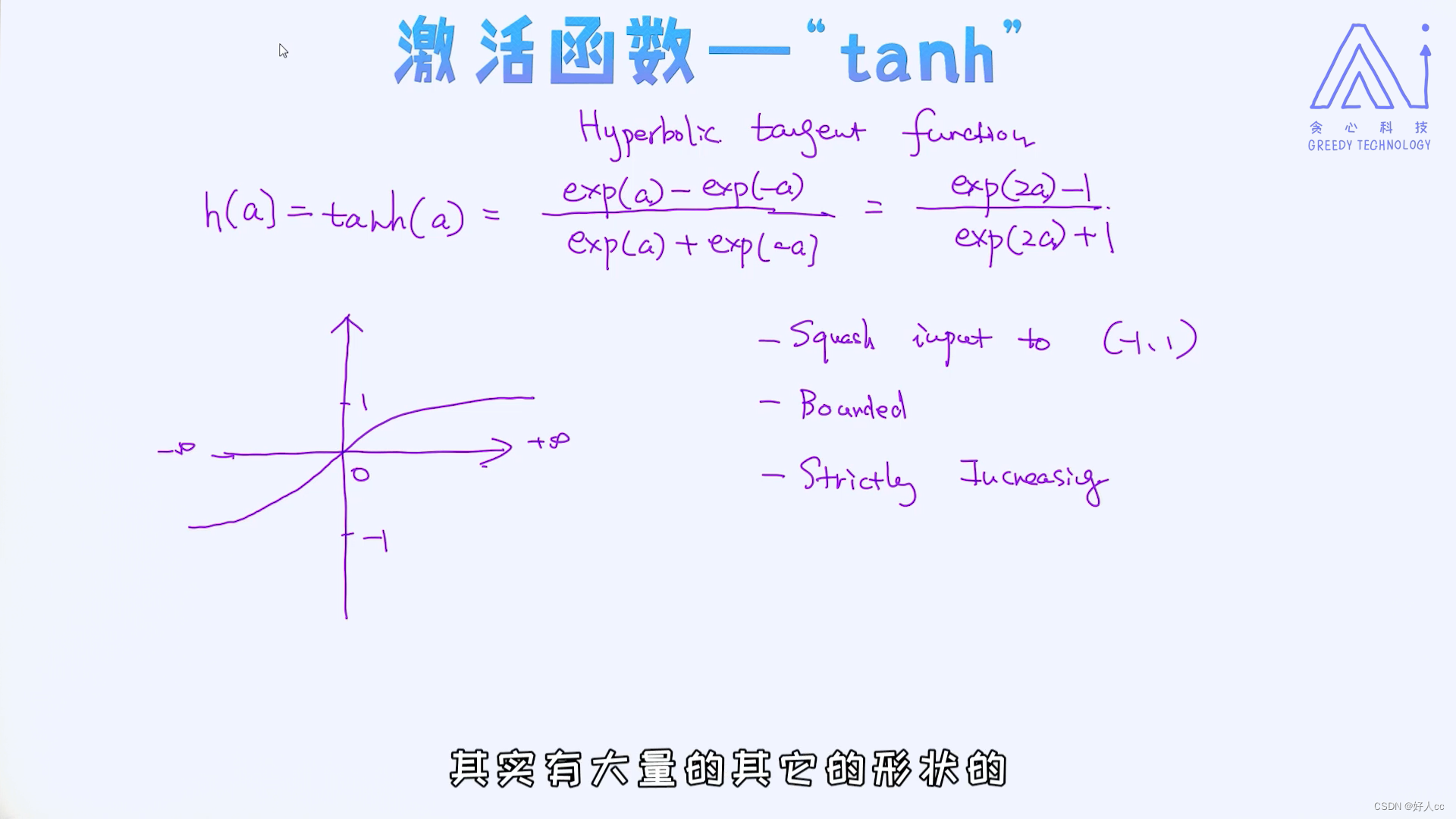
2.3tanh激活函数
三.拥有一层隐含层的神经网络
单个输出
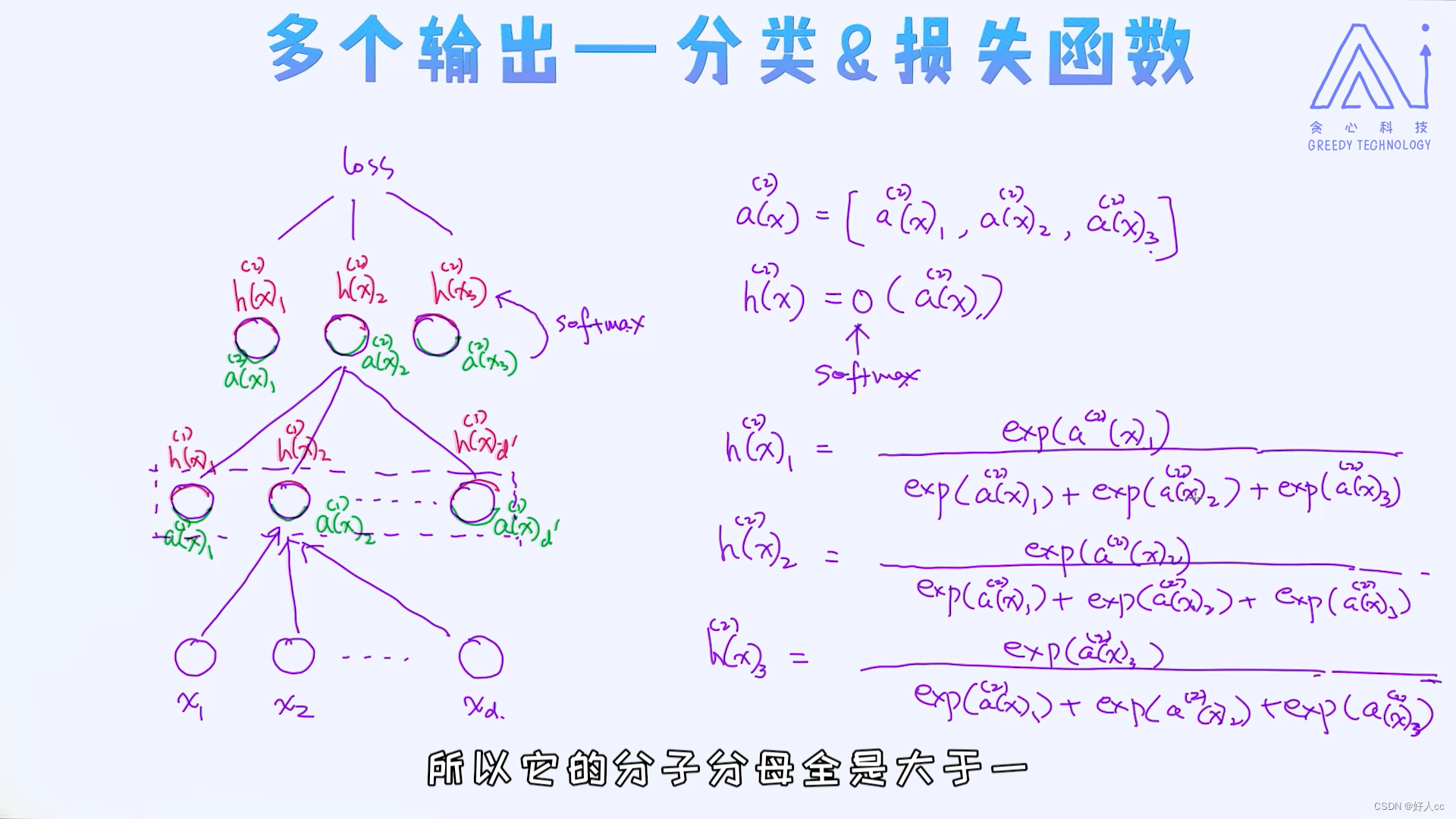
 多个输出---softmax激活函数
多个输出---softmax激活函数
四.多层神经网络
当我们增加额外的隐含层时就可以得到多层神经网络。至于隐含层的个数是没有限制的,我们可以随意搭建很多层的神经网络。为什么要增加隐含层呢?道理很简单,增加隐含层可直接导致模型的复杂度变高,随之带来的就是可以学出x到y的更复杂的映射关系。
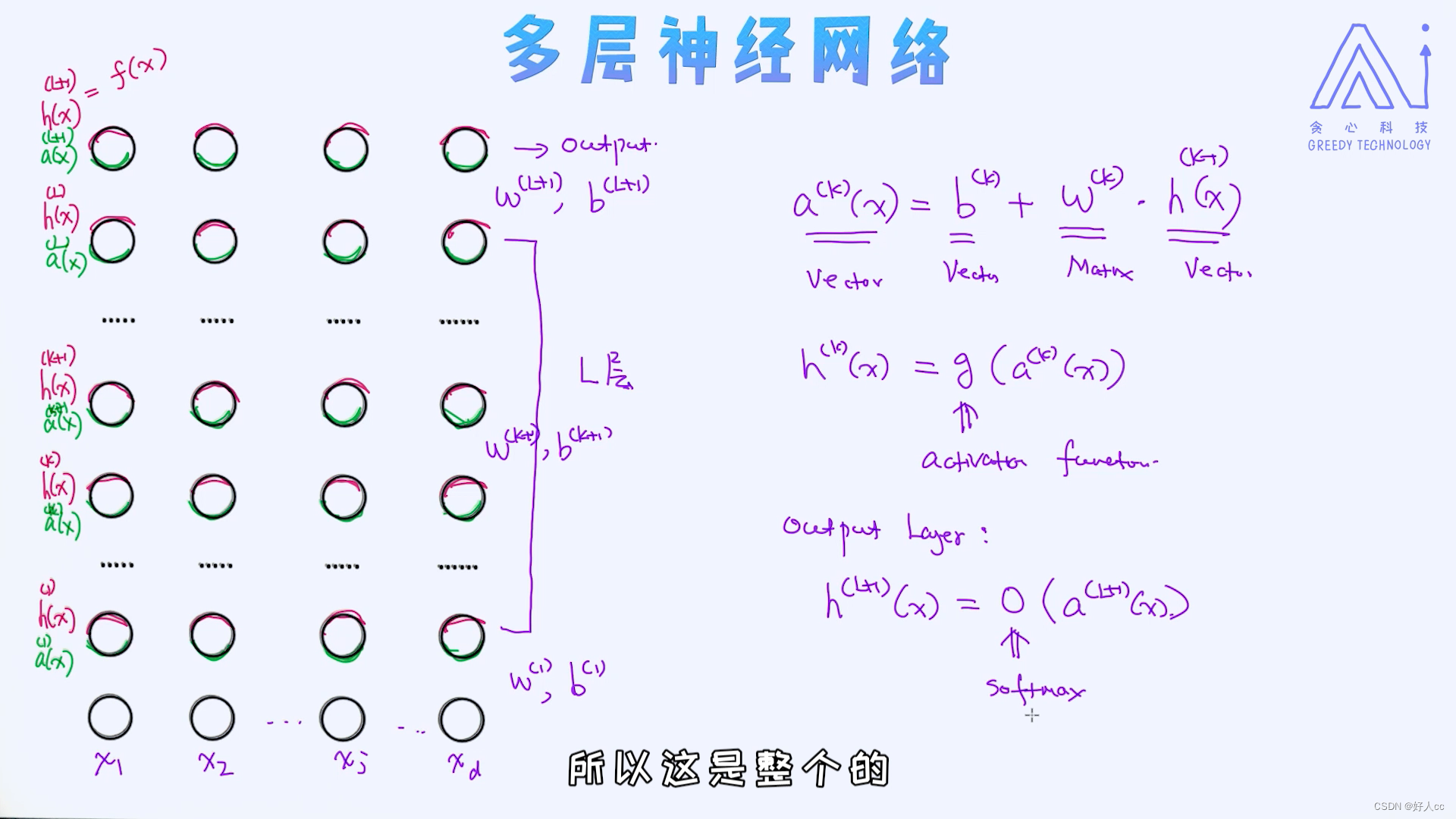
首先 这里的参数只有w和b 根据x1-xd输入 输出f(x) 然后会有一个loss 然后反向传播(梯度下降法)求w和b
注:对于分类问题,最后一层的激活函数是softmax
五.深度神经网络的损失函数
任何模型训练的第一步是明确损失函数。模型训练过程无非就是在优化损失函数,从而找到让损失函数最小的模型的参数。在这一节我们主要以深度神经网络为例来讲解反向传播算法,自然而然的,第一步就是要定义出损失函数。在这里先假定任务是分类任务,所以损失部分需要使用交叉熵损失(cross-entropy loss)。