黑马点评—短信登陆商户查询缓存
项目准备
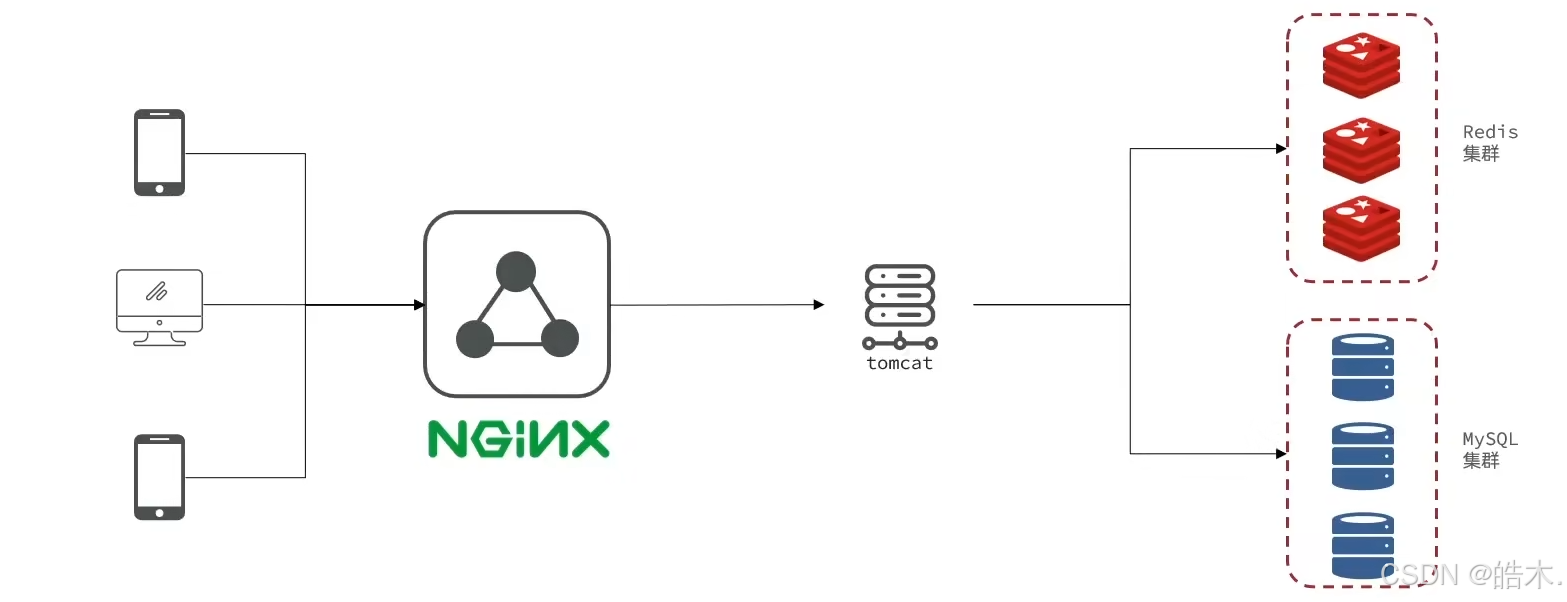
黑马点评项目是一个综合性的软件开发项目,主要实现了类似大众点评的功能,为用户和商家提供了一个互动的平台。
本项目采用前后端分离的方式,后端部署在tomcat上,前端则是Nginx。因为本项目主旨是学习Redis的用法,所以不涉及微服务,即spring cloud方面的知识。
找到下载的资料中的02-实战篇\资料\hm-dianping.zip,解压并将文件复制到自己的项目文件夹中,并使用idea打开。右键数据库,选择执行sql脚本,执行\redis学习\02-实战篇\资料\hmdp.sql文件用以生成相关数据。
然后将application.yaml文件中的配置信息:sql账号和密码、虚拟机ip、redis密码,端口号等信息修改为自己的。其余例如pom.xml中的版本信息请根据自身情况自行修改为对应版本。
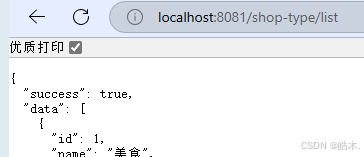
项目成功跑起来后可以访问http://localhost:8081/shop-type/list来测试是否能够访问到数据:
然后解压02-实战篇\资料\nginx-1.18.0.zip文件,将解压后的文件移动到纯英文目录,点击nginx.exe启动服务即可。
如果电脑事先已有nginx不想更换,可以将资料nginx中的html文件和conf\nginx.conf两文件替换自己nginx文件夹下的两文件,然后修改nginx.conf文件中有关端口的信息,再点击nginx.exe启动服务即可。
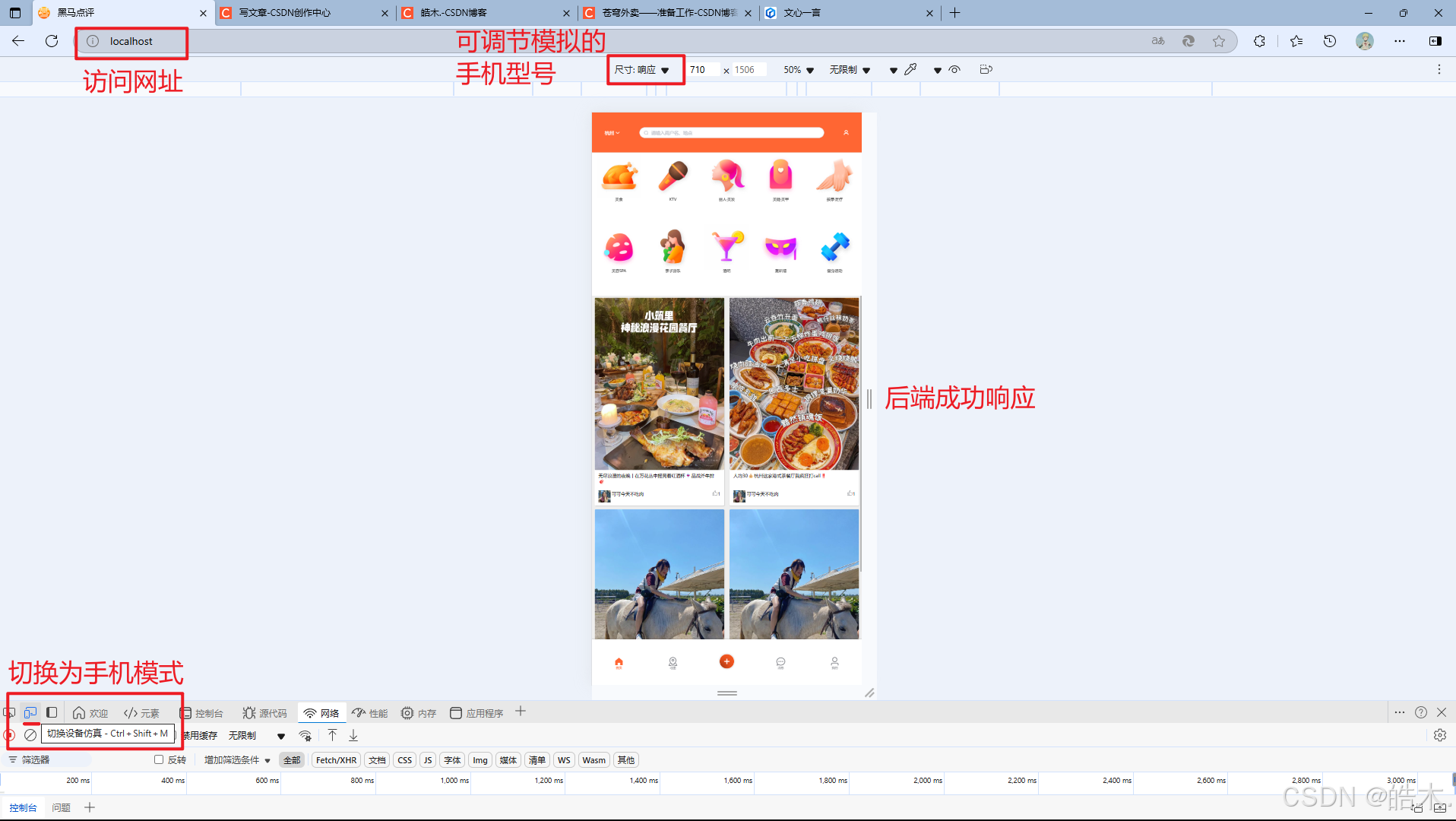
访问localhost网址(老师给的文件为localhost:8080),点击F12打开开发者模式(不同浏览器按键可能不同),点击左下角的切换设备仿真切换为手机浏览模式,即可测试前后端响应:
短信登陆
基于Session实现登录
共需要三步:
一、发送短信验证码:
验证手机号是否合法(不符合则要求重新输入)—生成验证码—将验证码保存在session中—发送验证码—结束。
二、短信验证码登录/注册
提交手机号及验证码—校验验证码(不一致则则要求重新输入)—根据手机号查询用户—判断用户是否存在(不存在则创建新用户,并保存用户到数据库)—保存用户到Session中—结束。
三、校验登录状态
发起请求并携带cookie—从session取出用户信息—判断用户是否存在(不存在则拦截,结束)—保存用户到ThreadLocal—放行—结束。
ThreadLocal是Java中用于创建线程本地变量的机制,它为每个线程提供了变量的独立副本,确保线程间数据隔离,适用于需要线程间隔离数据、减少参数传递或存储线程上下文信息的场景,但需注意在线程结束后及时清理以避免内存泄漏。
发送验证码
先来完成第一步:发送验证码。请求路径为/user/code,请求方法为Post,参数为phone电话号码,无返回值。
项目已在UserController中编写了sendCode()方法,我们只需完善该方法即可,在完成"发送验证码"这一步时,因为真正发送验证码较复杂,因此使用log.debug("验证码:{}发送成功",code);来模拟发送。
// Controller———————————————————
public class UserController {
......
@PostMapping("code")
public Result sendCode(@RequestParam("phone") String phone, HttpSession session) {
return userService.sendCode(phone,session);
}
......
}
// Service———————————————————————
public interface IUserService extends IService<User> {
Result sendCode(String phone, HttpSession session);
}
// ServiceImpl———————————————————
@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
@Override
public Result sendCode(String phone, HttpSession session) {
// 1、验证手机号
if (RegexUtils.isPhoneInvalid(phone)) {
// 不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 符合,生成验证码
String code = RandomUtil.randomNumbers(6);
// 2、保存验证码到session
session.setAttribute("code", code);
// 3、发送验证码
// 真实发送较麻烦,这里仅模拟发送
log.debug("验证码:{}发送成功",code);
return Result.ok();
}
}测试:


登录/注册
请求路径为/user/login,请求方法为Post,参数为phone电话号码、code验证码或者password密码,无返回值。
// UserController———————————————————
@PostMapping("/login")
public Result login(@RequestBody LoginFormDTO loginForm, HttpSession session){
return userService.login(loginForm,session);
}
// Service———————————————————————
Result login(LoginFormDTO loginForm, HttpSession session);
// ServiceImpl———————————————————
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1、校验手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
// 不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 2、校验验证码
Object cacheCode = session.getAttribute("code");
String code = loginForm.getCode();
if (cacheCode ==null || cacheCode.toString().equals(code)) {
// 不一致,报错
return Result.fail("验证码错误");
}
// 3、根据手机号查询用户
User user = query().eq("phone", phone).one();
// 4、判断用户是否存在
if(user==null){
// 不存在,创建新用户并保存
user = createUserByPhone(phone);
}
// 5、保存用户信息到session中
session.setAttribute("user", BeanUtil.copyProperties(user, UserDTO.class));
return null;
}
private User createUserByPhone(String phone) {
// 创建用户
User user = new User();
user.setPhone(phone);
user.setNickName(USER_NICK_NAME_PREFIX +RandomUtil.randomNumbers(6));
// 保存用户
save(user);
return user;
}登陆验证
设置拦截器来控制外界与Control层的交互。在util包下新建LoginCheckInterceptor实现HandlerInterceptor,并重写preHandle()方法和afterCompletion()方法,分别用于验证和销毁用户信息以免内存泄漏:
public class LoginCheckInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取session
HttpSession session = request.getSession();
// 2.获取session中的用户
User user = (User) session.getAttribute("user");
// 3.判断用户是否存在
if (user == null) {
//4.不存在,拦截,返回401状态码,意为未授权
response.setStatus(401);
return false;
}
//5.存在,保存用户信息到Threadlocal
UserHolder.saveUser((UserDTO)user);
//6.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//移除用户
UserHolder.removeUser();
}然后创建MvcConfig实现WebMvcConfigurer,来设置需要拦截的路径:
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginCheckInterceptor())
.excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
);
}
}集群的session共享问题
Session是一种在服务器端创建和管理的数据结构,用于存储和跟踪用户在网站上的会话信息。每个Session都与一个唯一的会话 ID(标识符) 相关联,该 ID 通常通过Cookie或URL重写的方式发送给客户端(如浏览器),并在客户端的后续请求中携带回服务器。在默认情况下,Session是依赖Cookie来实现身份标识的传递的。
当用户首次访问网站时,服务器会为用户创建一个新的Session对象,并为其分配一个唯一的Session ID,并将Session对象存储在服务器端(Cookie:JESSIONID=1)。在后续的请求中,客户端会将Session ID携带在请求头中发送给服务器。服务器会根据Session ID来查找对应的Session对象,从而获取或更新与该用户相关的状态信息。
其优点为存储在服务器端口,浏览器只存储ID,较安全,缺点为:服务器集群环境下无法直接使用Session(本次访问的服务器存储了Session,下次访问由另一个服务器响应但却无Session),后续tomcat服务器做水平扩展时,多台服务器之间信息不同步会导致用户体验较差。
因为基于Cookie实现,因此Cookie的移动端APP无法使用Cookie、不安全,用户可以自行禁用Cookie、Cookie不能跨域(同时发起的多个请求中协议、IP、端口任一不同即为跨域)等缺点他都有。
session的替代方案应该满足:1.数据共享。2.内存存储。3.key、value结构。 而Redis刚好满足以上要求。
基于Redis实现共享session登录
来改造之前的登陆功能,首先是保存验证码到redis中,value用来保存验证码,使用String类型即可。
在原本的架构中因为每个用户的session都不同,所以直接将验证码保存至session的code属性中即可,但在Redis中,如果仍使用"code"作为key,会导致所有用户共用一个验证码,引起数据覆盖等问题。但每个用户的手机号都不一样,使用手机号作为key即可。
然后是查询到用户后保存数据,之前是保存到session中了,但现在是保存到Redis中,有两种结构可供选择:String和Hash结构。
使用String结构时,value会以JSON字符串来保存,比较直观但每次修改时都需删除json数据重新添加,占用内存较多,数据量较少时推荐使用。
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD,并且内存占用更少,因此本项目采用Hash保存数据。
设计用户数据的key,key要具有唯一性,且方便存取。如果我们仍采用phone来当作key,虽然可行,但如果把这样的敏感数据存储到redis中并且从页面中带过来毕竟不太合适,所以我们在后台生成一个随机的token(随机字符串)作为key来存储。同时还需将该token返回给前端作为登陆凭证,以后每次登陆都需携带该token。

分析完操作来,我们来修改代码:
发送验证码
上文说过使用phone作为key,但这样不太规范,还不便于理解,我们选择为phone添加字符串前缀,同时该前缀不建议采用硬编码的方式写入,我们可以调用utils包RedisConstants类中的常量LOGIN_CODE_KEY来为key命名:
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public Result sendCode(String phone, HttpSession session) {
......
// 2、保存验证码到REDIS,并设置有效期为2分钟
stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY+phone,code,LOGIN_CODE_TTL, TimeUnit.MINUTES);
......
}登录/注册
首先是修改相关的登录方法login():
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1、校验手机号格式
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
// 手机号格式不正确,返回错误信息
return Result.fail("手机号格式错误!");
}
// 2、校验验证码
String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY+phone);
String code = loginForm.getCode(); // 获取用户输入的验证码
if (cacheCode == null || !cacheCode.equals(code)) {
// 验证码为空或与缓存验证码不一致,返回错误信息
return Result.fail("验证码错误");
}
// 3、根据手机号查询用户
User user = query().eq("phone", phone).one(); // 使用MyBatis-Plus查询用户
// 4、判断用户是否存在
if(user == null){
// 用户不存在,创建新用户并保存
user = createUserByPhone(phone);
}
// 5、保存用户信息到redis中
//随机生成token,作为登录令牌
String token = UUID.randomUUID().toString(true);
//将user对象转为HashMap存储
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO);
stringRedisTemplate.opsForHash().putAll(LOGIN_USER_KEY+token,userMap);
//设置token有效期
stringRedisTemplate.expire(LOGIN_USER_KEY+token,LOGIN_USER_TTL, TimeUnit.MINUTES);
// 返回token
return Result.ok(token);
}此时token在生成后的30分钟后就会过期,但这只适用于登录后就未进行任何操作的用户,如果用户持续在访问,我们需要不断刷新token的有效期以免用户再次需要登陆。拦截器正好可以进行这一操作:每次用户与后端交互都需经过拦截器,我们可以在拦截器中编写相关代码。
同时登陆验证也需拦截器来完成,我们将两者放在一起。
登录验证
因为LoginCheckInterceptor是我们自定义的一个类,其并未交给ioc容器来管理,所以我们想在其内部使用StringRedisTemplate,不能通过加@Autowired一类的注解来实现依赖注入,只能通过构造器注入的方式使用。
LoginCheckInterceptor不能加@Competent交给ioc容器管理,拦截器是一个非常轻量级的组件,只有在需要时才会被调用,并且不需要像控制器或服务一样在整个应用程序中可用。因此,将拦截器声明为一个Spring Bean可能会引导致性能下降。
public class LoginCheckInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public LoginCheckInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
// token不存在,拦截请求,返回401状态码,表示未授权
response.setStatus(401);
return false;
}
// 2.基于token获取Redis中的用户信息
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(LOGIN_USER_KEY + token);
// 3.判断用户信息是否存在
if (userMap.isEmpty()) {
// 用户信息不存在,拦截请求,返回401状态码,表示未授权
response.setStatus(401);
return false;
}
// 将查询到的HashMap数据转换为UserDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 保存用户信息到ThreadLocal,供后续请求使用
UserHolder.saveUser(userDTO);
// 刷新token的有效期
stringRedisTemplate.expire(LOGIN_USER_KEY + token, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 放行请求
return true;
}此时还有一问题:之前的拦截器我们设置为部分界面不进行拦截,如果用户一直访问这些页面那么token还是不会被刷新,为解决此问题我们决定再定义一个新拦截器:RefreshTokenInterceptor,当用户携带token时,刷新token,未携带token则直接放行,由LoginCheckInterceptor决定是否拦截。
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
// 构造函数注入StringRedisTemplate,用于操作Redis
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.从请求头中获取token
String token = request.getHeader("authorization");
// 如果token为空,直接放行
if (StrUtil.isBlank(token)) {
return true;
}
// 2.使用token从Redis中获取用户信息
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(LOGIN_USER_KEY + token);
// 如果用户信息为空,说明token无效或已过期,直接放行
if (userMap.isEmpty()) {
return true;
}
// 3.将用户信息Map转换为UserDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 4.将用户信息保存到ThreadLocal,以便在当前线程的后续处理中访问
UserHolder.saveUser(userDTO);
// 5.刷新token在Redis中的有效期
stringRedisTemplate.expire(LOGIN_USER_KEY + token, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 6.放行请求,继续执行后续的拦截器或处理器
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 请求处理完成后,从ThreadLocal中移除用户信息,避免内存泄漏
UserHolder.removeUser();
}
}public class LoginCheckInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.检查ThreadLocal中是否有用户信息
if(UserHolder.getUser() == null) {
// 2.如果没有用户信息,说明用户未登录或登录已过期
// 设置响应状态码为401(未授权),并拦截请求
response.setStatus(401);
return false;
}
// 3.如果有用户信息,放行请求
return true;
}
}同时,因为RefreshTokenInterceptor 类中定义了一个构造函数,该构造函数接受一个 StringRedisTemplate 参数。这意味着每当创建 RefreshTokenInterceptor 的实例时,都需要提供一个 StringRedisTemplate 的实例。
在 MvcConfig 类的 addInterceptors 方法中注册拦截器时使用 new RefreshTokenInterceptor() 时,也需手动注入 stringRedisTemplate 依赖。因为MvcConfig有着@Configuration注解,因此我们可以通过@Resource注入StringRedisTemplate。
同时我们需要确保RefreshTokenInterceptor拦截器先被执行,LoginCheckInterceptor拦截器后被执行。
默认情况下拦截器将按照被添加到InterceptorRegistry(拦截器注册表)的顺序来执行。这种情况下,代码中先添加的拦截器会先执行。
当然,我们也可以调用.order(int order)方法来指定拦截器的执行顺序。order的值越小,拦截器在拦截器链中的位置越靠前,越先执行。
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 添加刷新token的拦截器,确保所有请求都会经过该拦截器
// order(0)表示该拦截器在拦截器链中的执行顺序为第一个
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate))
.addPathPatterns("/**")
.order(0);
// 添加登录状态检查的拦截器,用于验证用户是否登录
// 排除了一些不需要登录即可访问的路径
// order(1)表示该拦截器在拦截器链中的执行顺序为第二个,即在刷新token拦截器之后执行
registry.addInterceptor(new LoginCheckInterceptor())
.excludePathPatterns(
"/shop/**", // 商店相关路径
"/voucher/**", // 优惠券相关路径
"/shop-type/**", // 商店类型相关路径
"/upload/**", // 文件上传相关路径
"/blog/hot", // 热门博客路径
"/user/code", // 用户验证码路径
"/user/login" // 用户登录路径
).order(1);
}
}
商户查询缓存
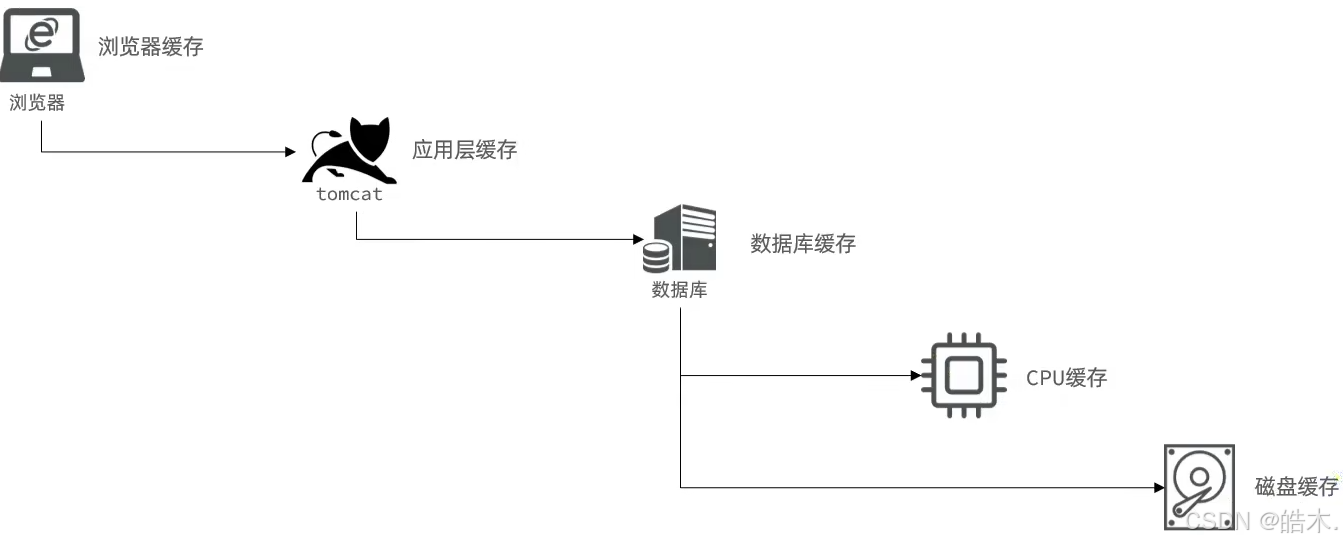
缓存就是数据交换的缓冲区,用于临时保存数据,以便快速访问,减少数据获取的时间,提高系统效率。
例如缓存可以解决CPU处理数据与内存读取数据之间读取速率差异过大的问题。不止有cpu缓存和磁盘缓存,还有浏览器缓存、服务器缓存、数据库缓存等:
缓存可以降低后端负载,提高响应速度。但会提高数据一致性成本,代码维护成本,运维成本等,也会引入缓存穿透击穿等问题。
添加Redis缓存
根据id查询商铺信息是由ShopController类中的queryShopById()方法完成的,该方法又调用了Mybatis-Plus提供的IService类中的getById()方法,用于根据id查询数据库。
未添加缓存之前,客户端会直接向数据库发起请求,数据库再返回对应信息。
添加缓存相当于在两者之间添加了一中间层,客户端的请求会优先到达我们的缓存。如果缓存中存在对应数据,缓存就会直接返回对应信息,不再与数据库交互。如果不存在对应数据,则与数据库交互,并在数据库返回数据时将其存入缓存中,以便下次缓存直接响应查询。
有两部分需要添加Redis缓存,分别是店铺详情和分类详情,我们依次来看。
店铺详情
原项目使用ShopController类的queryShopById()方法来接收,直接使用MyBatis-Plus来查询数据库,相关路径和jie
由于写入缓存的逻辑较复杂,所以我们将相关代码写在ShopServiceImpl类中:
// ShopController———————————————————
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryById(id);
}
// IShopService———————————————————————
Result queryById(Long id);
// ShopServiceImpl———————————————————
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
// 构建缓存键
String key = CACHE_SHOP_KEY + id;
// 尝试从Redis获取店铺数据
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 检查缓存中是否有数据
if (StrUtil.isNotBlank(shopJson)) {
// 缓存命中,直接反序列化并返回店铺对象
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 缓存未命中,从数据库查询店铺数据
Shop shop = this.getById(id);
// 检查数据库查询结果
if (Objects.isNull(shop)) {
// 数据库中无数据,返回错误信息
return Result.fail("店铺不存在");
}
// 数据库中有数据,序列化后存入Redis,并返回店铺对象
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
return Result.ok(shop);
}
}
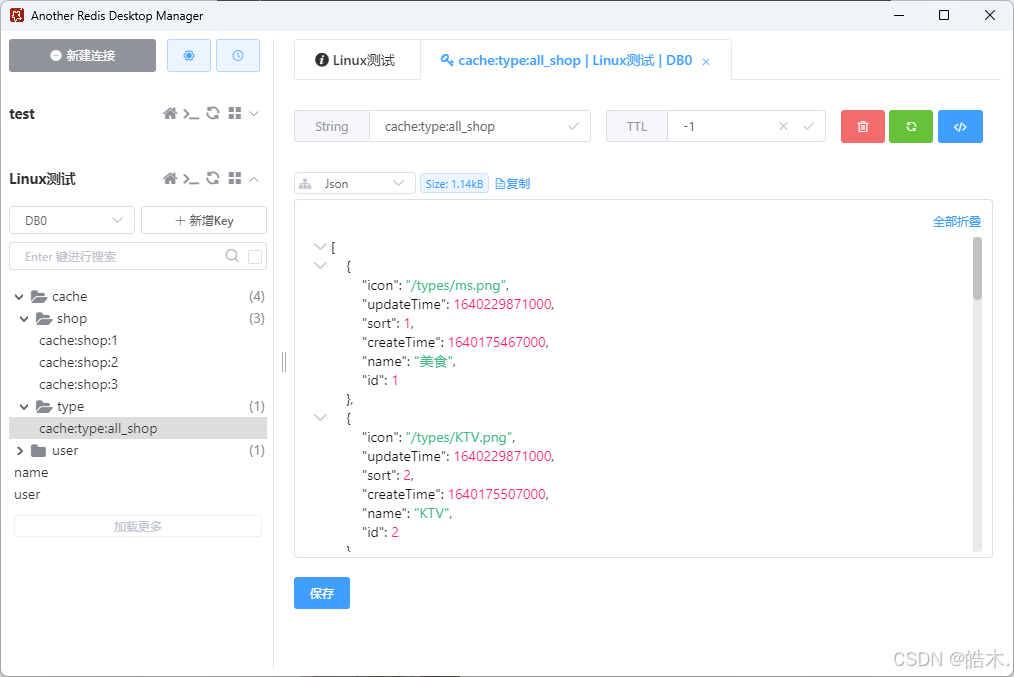
再次查询,相关数据就已存入到Redis中:
分类详情
吐槽:这里我踩了个大坑,因为之前写过苍穹外卖,惯性思维以为<该方法实现了"根据分类id查询店铺"功能,每个分类都需单独作为一个数据存入Redis中,而数据的key还是和上文的"店铺详情"部分相同:'固定字符串+id'>。但死活找不到这个id要从哪获取,看别人写的都是直接使用固定字符串作为key,而未拼接id,我还想着这样写那新查询的分类数据不就覆盖了老的分类数据了吗?
后面才发现该功能发起了两次请求, 分别是http://localhost/api/shop-type/list和http://localhost/api/shop/of/type?......,分别由ShopTypeController类中的queryTypeList()方法和ShopController类中的queryShopByType()方法来处理,两者分别实现了查询商铺类型和根据商铺类型查询商铺信息。
而老师只要求我们修改第一个路径的响应方法,也就是queryTypeList()方法。也就是说我们只需将query().orderByAsc("sort").list();的结果,即"商铺类型ID"这一份数据缓存即可,根据商铺类型查询商铺并不需要我们实现,因为只有一份数据,所以并不存在我担心的"新查询的分类数据覆盖老的分类数据"的情况,自然可以使用固定字符串作为key。
同理,我们从ShopTypeController类中的queryTypeList()方法开始修改:
// ShopTypeController———————————————————
@GetMapping("list")
public Result queryTypeList() {
return typeService.queryByType();
}
// IShopTypeService———————————————————————
Result queryByType();
// ShopTypeServiceImpl———————————————————
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryByType() {
String key = CACHE_TYPE_KEY;
//从redis中查询类型缓存
String typeJson = stringRedisTemplate.opsForValue().get(key);
//如果缓存不为空,直接返回
if (StrUtil.isNotBlank(typeJson)) {
return Result.ok(JSONUtil.toBean(value, ShopType.class));
}
//为空,查询
List<ShopType> shopTypeList = query().orderByAsc("sort").list();
//将数据库信息保存到缓存
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shopTypeList));
return Result.ok(shopTypeList);
}
}
//RedisConstants———————————————————————
public static final String CACHE_TYPE_KEY = "cache:type:all_shop";
缓存更新策略
上文介绍过,缓存虽然可以降低后端负载,提高响应速度。但会提高数据一致性成本,代码维护成本,运维成本等,也会引入缓存穿透击穿等问题。
先来看一致性,因为我们同时把数据保存在数据库和缓存中,当数据库中的数据发生变化时,缓存并未一起更新,此时用户来查询相关数据,会由缓存直接返回旧数据,与数据库中的新数据不一致。
为解决这些问题,我们需要对缓存进行更新。目前企业常见的缓存更新策略有内存淘汰、超时剔除、主动更新三种,三者各有优略:
- 一、内存淘汰:
- 定义:当缓存内存不足时,自动淘汰部分数据以腾出空间。
- 适用场景:业务不需要强一致性的场景。
- 一致性:较差,因为淘汰数据是基于内存使用情况的,而不是数据的一致性需求。
- 二、超时剔除
- 定义:为缓存数据设置生存时间(TTL),到期后自动删除。
- 一致性:中等,依赖于TTL的设置和数据的更新频率。
- 适用场景:作为兜底方案,与主动更新策略结合使用。
- 三、主动更新
- 编写业务逻辑,在修改数据库的同时,更新缓存。这种方法一致性较好,但也无法完全保持数据一致,我们需要编写大量代码,维护成本较高。
具体使用哪种方法要根据业务场景而定,低一致性需求使用内存淘汰机制。例如店铺类型的查询缓存。高一致性需求则主动更新,并以超时剔除作为兜底方案。
本项目中就采用主动更新。主动更新策略根据更新时机和方式的不同,可以分为以下几种:
- Cache Aside Pattern(旁路缓存模式)
- 原理:应用程序直接与数据库和缓存交互。查询时,先查缓存,未命中则查数据库并更新缓存;更新时,先更新数据库,再使缓存失效。
- 一致性:由应用程序保证,可以通过延迟双删等策略提高最终一致性。
- Read/Write Through Pattern(直写/直读模式)
- 原理:应用程序只与缓存交互,缓存负责与数据库的交互。查询时,如果缓存未命中,则缓存从数据库中加载数据并更新缓存;更新时,先更新缓存,再由缓存同步更新数据库(或先更新数据库,再同步更新缓存,具体取决于实现)。
- 一致性:由缓存组件保证,数据一致性较高。
- Write Behind Caching Pattern(写回缓存模式)
- 原理:应用程序只更新缓存,然后由异步任务或定时任务批量更新数据库。
- 一致性:较低,因为存在延迟更新数据库的情况。
我们一般使用旁路缓存模式,虽然需要编写大量代码,但好在更新的时间和数据可控。
使用这种模式时,通常选择删除缓存,而不是更新缓存以减少无效操作(更新缓存:每次更新数据库都更新缓存,无效写操作较多。删除缓存:更新数据库时让缓存失效,查询时再更新缓存)。
同时为确保数据库和缓存的操作同时成功或失败,在单体系统中我们需将数据库和缓存的操作放在同一个事务中。
为确保线程安全,避免在多线程中出现脏数据,我们需先操作数据库再操作缓存多线程。
先更新数据库,再删除缓存
先更新数据库可以确保数据在持久化存储中的一致性。在更新成功后,再删除缓存中的旧数据,可以确保后续读取操作能够从数据库中获取最新数据,并重新缓存。
由于先更新数据库,再删除缓存,因此在删除缓存之前,数据库中的数据已经是最新的。这减少了在缓存失效期间读取到旧数据并写入缓存的风险。在高并发环境下,这样可以减少因并发读写操作导致的数据不一致问题(但无法完全避免)。再为缓存加上过期时间,能有效减轻数据不一致带来的影响。
先删除缓存,再更新数据库
如果先删除缓存,再更新数据库,中间存在一个时间窗口。在这个时间窗口内,如果有读取请求到来,它会发现缓存已失效,于是去数据库中读取旧数据,并将其写入缓存。这会导致缓存中的数据与数据库中的数据不一致。
在高并发环境下,这样更容易导致竞态条件和数据不一致问题。例如,一个写操作刚删除缓存,另一个读操作就读取了旧数据并写入缓存;或者一个写操作在更新数据库时,另一个写操作已经删除了缓存并开始了自己的数据库更新过程。
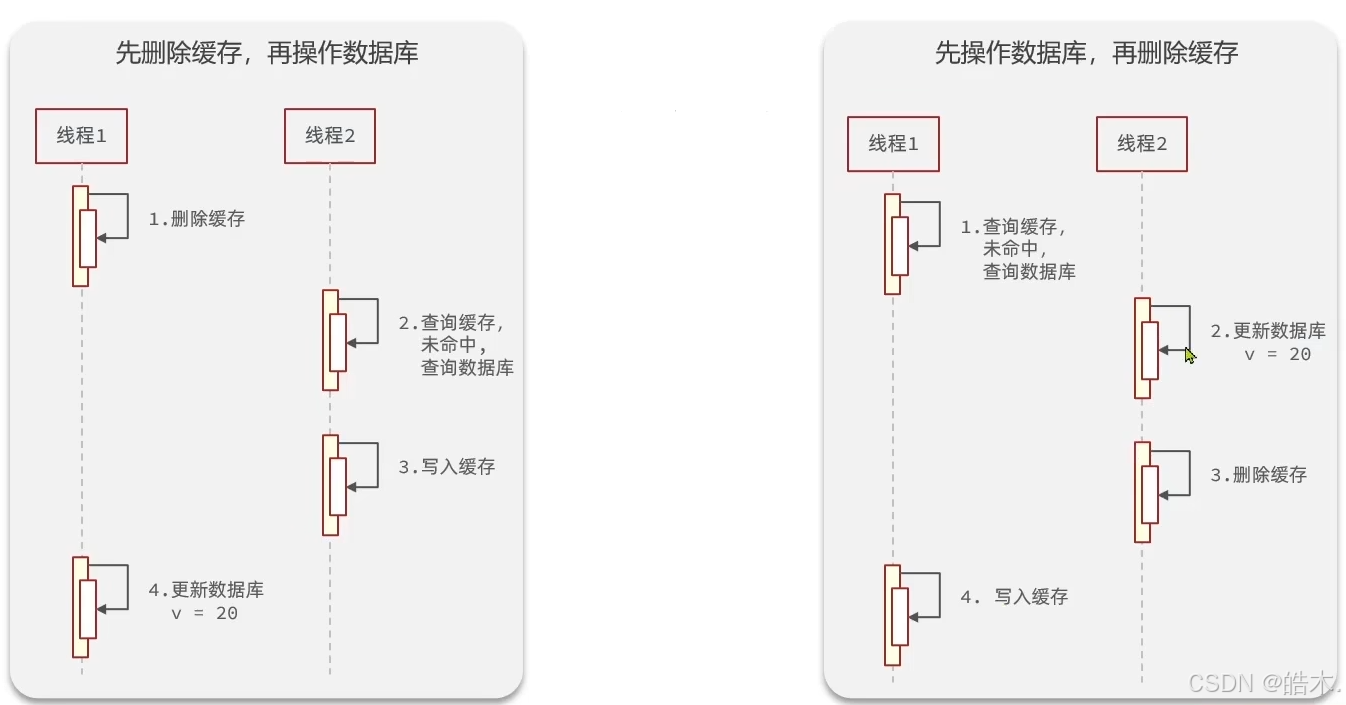
人话:缓存操作快,数据库操作慢。
如果先操作缓存后操作数据库,在缓存操作结束后等待数据库操作的一长段时间里,其它程序容易趁虚而入。
先操作数据库后操作缓存的话,数据库操作完成后缓存很快便会完成,其他程序很难夹杂在两操作中间。
两者都有极端情况,但因为数据库操作较慢,redis操作较快,因此后者的极端情况出现的概率较低:
修改项目
接下来为项目添加缓存更新策略,修改ShopController中的业务逻辑,满足下面的需求:
一、根据id查询店铺时,如果缓存未命中,则查询数据库,将查询结果写入缓存并设置超时时间
ShopServiceImpl————————————————————————————————————
public Result queryById(Long id) {
......
// 将查询到的数据序列化后存入Redis并设置过期时间
stringRedisTemplate.opsForValue()
.set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
}
}二、根据id修改店铺时,先修改数据库,再删除缓存
上文说过数据库和缓存操作放在同一个事务中,因此需添加@Transactional注解。同时需要先操作数据库再删除缓存。
// ShopController———————————————————
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
return shopService.update(shop);
}
// IShopService———————————————————————
Result update(Shop shop);
// ShopServiceImpl———————————————————
@Override
@Transactional
public Result update(Shop shop) {
// 更新数据库
updateById(shop);
// 删除缓存
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
System.out.println("1111");
return Result.ok();
}
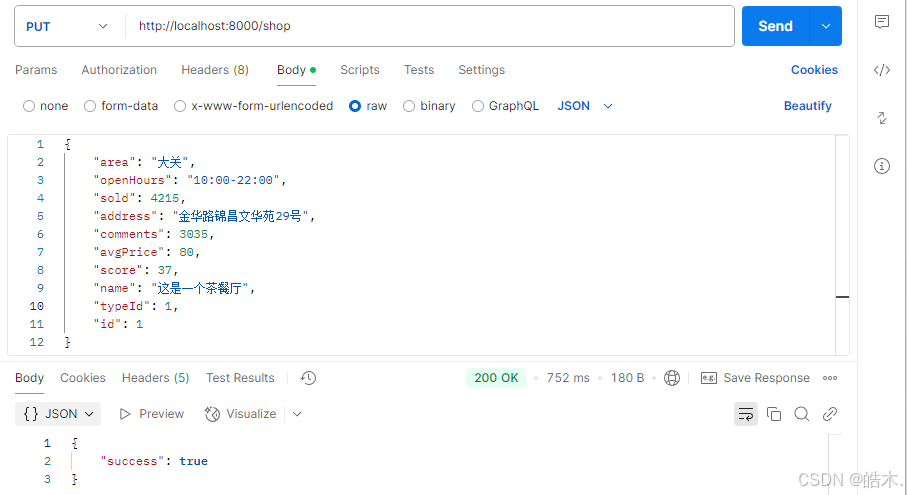
因为我们目前仍在使用用户端,其并无修改数据的功能,然后借助postman来完成数据更新(拦截器不会拦截该请求路径) :
执行完相关操作后数据库数据发生改变,缓存中相关数据被删除。
缓存穿透
接下来我们来看使用缓存时常见的难点问题,为面试做准备。
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远都不会生效,这些请求都会直接与数据库交互。即该请求都“穿透”了缓存系统,直接访问了底层的存储系统。
如果攻击者或者恶意用户发起大量这样的请求,会导致系统资源被占用甚至导致系统崩溃。
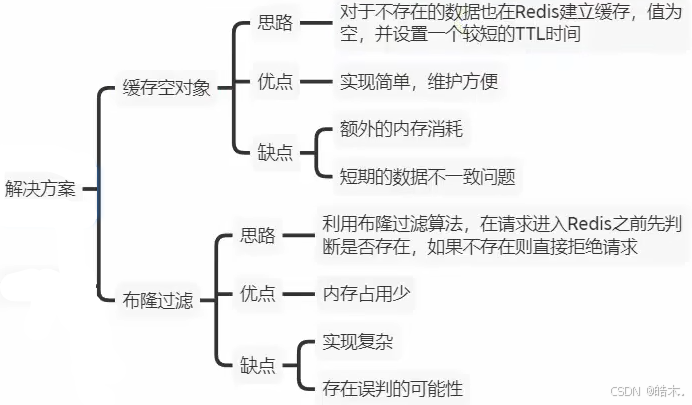
常见的解决方案有两种:缓存空对象和布隆过滤。
缓存空对象
缓存空值或错误标记是指对于不存在的数据或查询结果错误的数据,将其对应的键(key)和值(value)存储为特定标记(如null、空字符串或其他错误代码)并设置一个适当的过期时间,以便在后续查询只与缓存交互,而无需再次访问数据库。
但也有一定的缺点,例如增加了缓存的存储空间占用,因为需要存储不存在的数据或错误结果的标记,可以通过设置有效期来减轻压力,但如果标记的过期时间设置不当,可能会导致长时间存储无用的标记数据。
还可能造成短时间内的数据不一致,例如缓存中存储了id为1的空数据,但此时又向数据库插入id为1的数据,再发起请求查询id为1的数据时会查询到缓存中的空数据,而无法查询到数据库中的有效数据。该状况会一直持续到缓存中的数据失效。
布隆过滤
准确来讲他是一种算法,其在客户端和redis中间加入了布隆过滤器来拦截请求,如果布隆过滤器判断请求的目标存在则会允许通过,反之则禁止。后续与缓存和数据库的交互逻辑不变。
布隆过滤器由一个很长的二进制向量(位数组)和一系列随机映射函数(哈希函数)组成。这些哈希函数将集合中的元素映射到位数组的不同位置上,并将这些位置上的值设为1。因此,布隆过滤器并不直接存储集合中的元素,而是存储元素的哈希值的映射位置。
这样判断数据是否存在是一种概率上的判断,并不是100%准确,判断不存在则一定不存在,判断存在则不一定存在。因此其仍保留一定的数据穿透的风险。其优点是内存占用较少,没有多余key,缺点则是实现复杂,存在误判可能(有穿透的风险)。
修改项目
在本项目中我们采用缓存空对象的方式来应对缓存穿透。回到idea修改ShopServiceImpl类中的queryById()方法。
有一点需要注意,因为上文检查缓存中是否有数据时使用的是StrUtil.isNotBlank() ,该方法返回flase有四种情况:
- StrUtil.isNotBlank(null) // 返回 false
因为参数为 null,表示没有字符串,所以返回 false。 - StrUtil.isNotBlank("") // 返回 false
因为参数为空字符串,不包含任何字符,所以返回 false。 - StrUtil.isNotBlank("\t\n") // 返回 false
参数包含制表符和换行符,这些都是空白字符,不包含非空白字符,所以返回 false。 - StrUtil.isNotBlank("abc") // 返回 true
参数为非空字符串且包含字母(非空白字符),所以返回 true。
在本案例中存入缓存的空对象为"",也就是说当value为""时,系统会认为该value在缓存中不存在,也会与数据库交互,因此我们需再加一个判断语句,当value为""时直接返回结果。上文的四种情况中,如果value存在字符串时,原先的代码会直接返回结果,也就是说第四种情况不可能到达该判断语句。也就是说当value为null时才需到数据库中查找数据,因为我们直接反向判断,使用if(shopJson != null)将所有不需要到数据库的请求统统返回。
我这里为了和后文value为null时返回的数据做区分,当value为""时返回的字符串为"店铺不存在(防止缓存穿透)",和老师讲的略微有些区别。
个人感觉这里老师的思路好麻烦,我感觉可以将redis种的值(value)存储为特定的标记,例如字符串:CACHE_IS_NULL,判断当value为该值时直接返回,这样方便理解的多。可能老师是为了介绍StrUtil.isNotBlank()方法,所以刻意的与该方法相结合了,使用""作为value真的很不舒服。
ShopServiceImpl——————————————————————————
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 判断命中的是否是空值(缓存穿透的空标记)
if (shopJson != null) {
// 返回错误信息,表明店铺不存在
return Result.fail("店铺不存在(防止缓存穿透)");
}
// 缓存未命中,从数据库查询店铺数据
Shop shop = getById(id);
// 检查数据库查询结果,防止缓存穿透
if (Objects.isNull(shop)) {
// 将空值写入Redis,设置较短的过期时间
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 数据库中无数据,返回错误信息
return Result.fail("店铺不存在");
}
// 数据库中存在数据,序列化后存入Redis,并设置正常的过期时间
stringRedisTemplate.opsForValue()
.set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
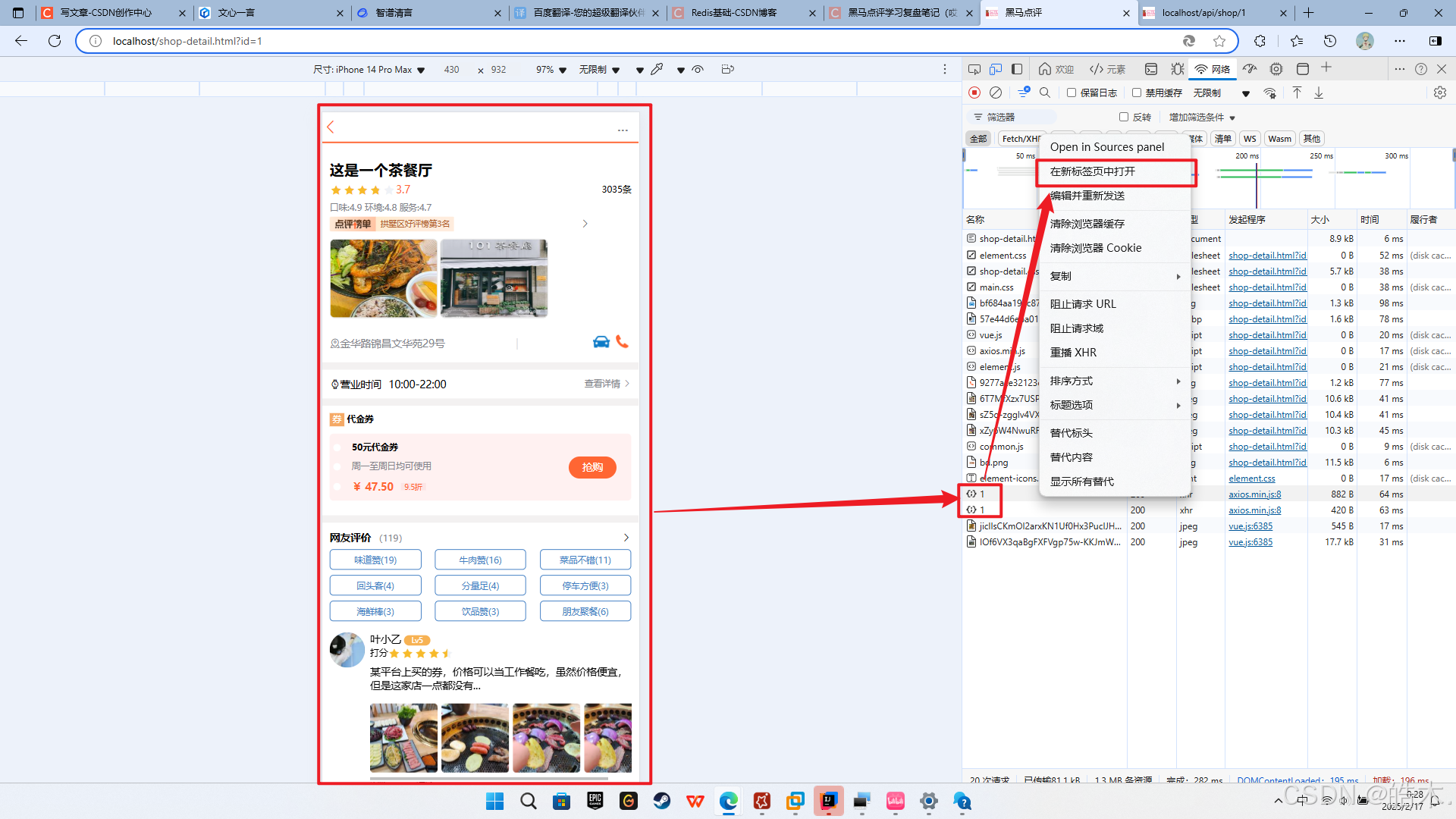
}测试:直接进入店铺详情页面,右键相关请求,选择在新标签页种打开
然后修改传入的参数为0,测试是否返回如下信息:
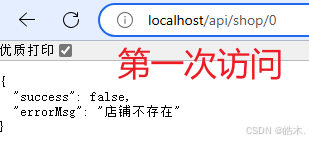
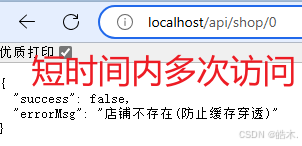
以上这些方式都是被动的解决缓存穿透方案,在编码过程中,我们也可以采用主动的方案预防缓存穿透,例如增强id的复杂性,避免被猜测id规律、做好数据的基础格式校验(防刁民)、加强用户权限校验(登录后才可查看详细信息)、做好热点参数的限流等。
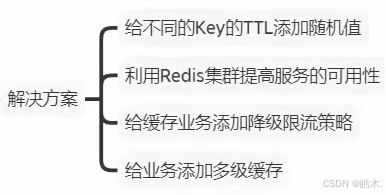
缓存雪崩
缓存雪崩是指当缓存服务器中的大量缓存数据同时过期,或者缓存服务器发生故障导致缓存数据无法访问时,大量的请求直接涌向数据库,导致数据库压力骤增,甚至可能引发数据库崩溃的现象。
解决方案有很多种:
- 随机过期时间:在设置缓存过期时间时,可以为不同数据添加随机偏差值,让缓存数据的失效时间更加均匀,避免在同一时刻大量缓存同时失效。
- 服务降级:在后端系统无法处理大量请求时进行服务降级,返回一些默认数据或提示信息,防止系统完全不可用。牺牲部分服务来保护数据库。
- 多级缓存架构:引入多级缓存架构,将缓存分布到多个层次,例如CDN缓存、本地缓存、分布式缓存(如Redis)等,使得缓存命中率最大化,减少后端压力。
- 请求限流:对请求进行限流,控制进入后端系统的请求数量,防止短时间内过多请求涌入数据库
还有些我们目前用不到的方法,了解即可:
双重缓存:设置两个缓存层,第一层用于保存实际的缓存数据,第二层则存储短期的缓存副本。当第一层缓存失效时,读取第二层副本,防止同时大量请求打到数据库,减缓后端压力。与此同时,后台可以异步更新第一层缓存的数据。
分布式锁:在缓存失效的情况下,引入分布式锁机制,让同一时间内只有一个请求能进行缓存的更新操作,其他请求等待锁释放,避免大量请求同时访问后端数据库。
缓存预热:在系统启动或大版本更新时,提前将常用或热点数据加载到缓存中,避免在高并发时突然失效产生大量请求。
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
有些数据因为比较复杂,缓存失效后从数据库查询数据并构建缓存所需时间较长,在这段时间里大量其他请求查找该缓存时也会查询数据库,造成大量请求与数据库交互。
常见的解决方案有两种:
互斥锁
指的是缓存失效后,第一个线程查询数据库之前需要先获取互斥锁,然后再查询数据库并重建缓存数据、写入缓存,最后再释放互斥锁。在此期间其他线程会因为获取互斥锁失败而无法访问数据库,其会休眠一段时间后再次查询缓存,如果再次无缓存且获取互斥锁失败,该线程会一直重试直至缓存命中。
互斥锁的优点是可以避免大量的并发请求直接落到数据库上,从而减少了并发压力,保证系统的稳定性。缺点是会增加单个请求的响应时间,因为只有一个线程能够读取缓存值,其他线程则需要等待。
逻辑过期
逻辑过期方案是指不直接设置缓存数据的过期时间(TTL),而是设置一个逻辑过期时间来告诉系统该缓存在该时间点后为过期值。
缓存失效后,第一个线程查询数据库之前同样需要先获取互斥锁,但之后查询数据库并重建缓存数据、写入缓存、释放互斥锁等工作交由其他线程完成。在此期间第一个线程会先返回过期数据,其他的线程在缓存未命中且获取互斥锁失败时,同样会返回过期数据。
逻辑过期的优点是可以减少缓存的更新次数,避免在没有必要的情况下过多地读取后端数据源。缺点是实现起来比较复杂,且在某些极端情况下可能出现数据不一致的问题。
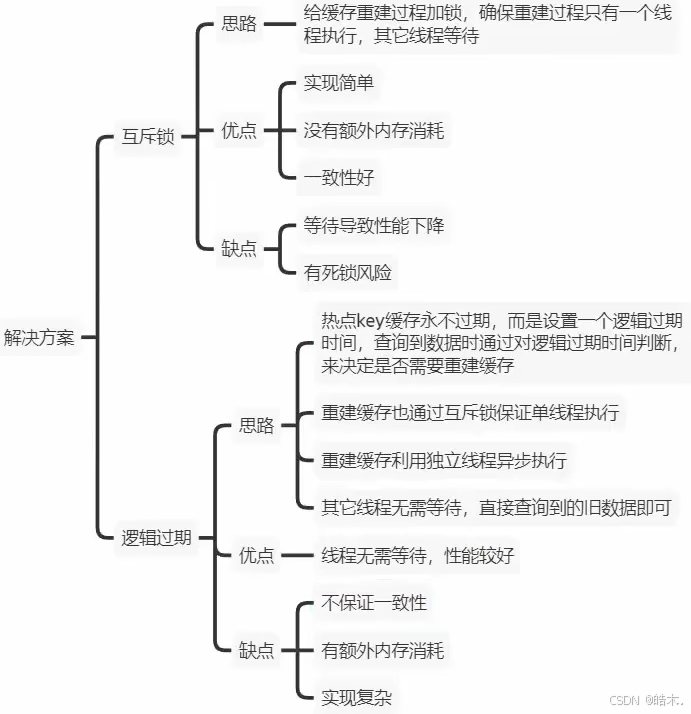
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的内存消耗 保证一致性 实现简单 | 线程需要等待,性能受影响 可能有死锁风险 |
| 逻辑过期 | 线程无需等待,性能较好 避免缓存失效时的数据库冲击 | 不保证一致性 有额外内存消耗 实现复杂 |
两者各有优略,在选择使用互斥锁还是逻辑过期时,需要根据具体的应用场景、性能要求和一致性需求来权衡。我们将依次使用两者来修改项目。
修改项目
我们先使用互斥锁解决缓存击穿问题:修改根据id查询商铺的业务,基于互斥锁方式来解决缓存击穿问题。
之前是缓存未命中则直接查询数据库,现在需要尝试获取互斥锁—失败则休眠一段时间后重试—成功则根据id查询数据库—将数据写入Redis—释放互斥锁—返回数据。
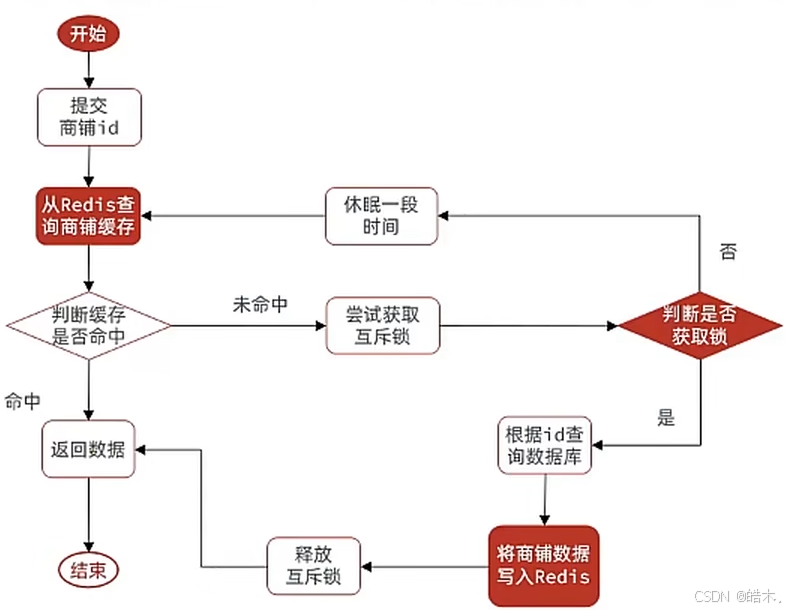
之前在操作Redis的String类型数据时有一个SETNX key value命令,只有在key不存在时设置key的值。我们可以用该语句来实现简单的互斥锁,在idea种将set()替换为setIfAbsent()即为调用SETNX。
当第一个线程调用该命令时,程序正常创建数据(获取互斥锁),但其他线程调用时却因为该数据已存在而创建失败(获取互斥锁失败),等到相关操作执行完毕后再删除该数据(释放互斥锁)。
为避免极端情况:互斥锁释放未能成功执行,导致互斥锁一直存在,各线程均无法获取新数据,我们还会为该数据设置过期时间,一段时间后该互斥锁会自动释放。
这便是实现互斥锁的基本思路,这距离真正的互斥锁仍有一定差距。
接下来修改代码,先在ShopServiceImpl类中定义两方法用于获取和释放互斥锁。
获取互斥锁需要返回boolean类型用于判断是否获取成功,但是注意不能直接返回setIfAbsent()的结果,我们应该使用BooleanUtil.isTrue()方法,并将setIfAbsent()的结果作为参数传入再返回。
释放互斥锁则不需要返回值,直接调用delete()方法即可。
为什么不能直接返回setIfAbsent()的结果
Boolean类型的变量flag可能包含三个值:true、false或null。当使用setIfAbsent方法时,如果键不存在且设置成功,它会返回true;如果键已存在且设置失败,它会返回false。但是,如果由于某种原因setIfAbsent方法没有正常执行(例如Redis服务不可用),它可能会返回null。
直接返回flag可能会让调用者无法区分false和null的情况,这两种情况在逻辑上可能需要不同的处理。使用BooleanUtil.isTrue(flag)可以确保只有当flag为true时才返回true,否则(即flag为false或null)都返回false。
为什么释放互斥锁则不需要返回值
Redis中,delete 操作通常是原子性的,并且成功执行时不会返回任何值,失败时则抛出异常。因此,stringRedisTemplate.delete(key) 在成功删除键时不会返回一个明确的成功标志。
ShopServiceImpl——————————————————————————
//获取互斥锁
private boolean lockMutex(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
//释放互斥锁
private void unlockMutex(String key) {
stringRedisTemplate.delete(key);
}然后来修改queryById()方法,我们不直接对原方法进行修改,而是将其逻辑封装在新方法queryWithMutex()中。
然后来修改返回值,queryWithMutex()方法的返回类型应为Shop,成功时返回Shop对象,失败则直接返回null。在缓存未命中—获取互斥锁之后,我们仍需再次尝试访问缓存,以避免在获取互斥锁期间其他线程创建了缓存。最后,为避免程序出错,互斥锁未能成功释放,我们应该使用try-catch-finally包裹创建互斥锁后的所有代码,无论代码成功与否都执行finally块,即释放互斥锁。
@Override
public Result queryById(Long id) throws Exception {
// 互斥锁解决缓存击穿+缓存空对象解决缓存穿透
Shop shop = queryWithMutex(id);
if(shop == null){
return Result.fail("店铺不存在!");
}
// 返回查询到的店铺对象
return Result.ok(shop);
}
// 互斥锁解决缓存击穿+缓存空对象解决缓存穿透
public Shop queryWithMutex(Long id) throws Exception {
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
// 判断命中的是否是空值(缓存穿透的空标记)
if (shopJson != null) {
return null;
}
// 缓存未命中,实现缓存重建
// 获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
Shop shop;
try {
boolean isLock = lockMutex(lockKey);
// 判断是否获取成功
if (!isLock) {
// 失败,休眠并重试
Thread.sleep(50);
return queryWithMutex(id);
}
// 再次查询缓存是否已由其他线程创建,做双重保险
shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
if (shopJson != null) {
return null;
}
// 成功,从数据库查询店铺数据
shop = getById(id);
// 模拟重建缓存的延时
Thread.sleep(200);
if (Objects.isNull(shop)) {
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
stringRedisTemplate.opsForValue()
.set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (Exception e) {
throw new Exception("缓存重建失败",e);
} finally {
//释放互斥锁
unlockMutex(lockKey);
}
return shop;
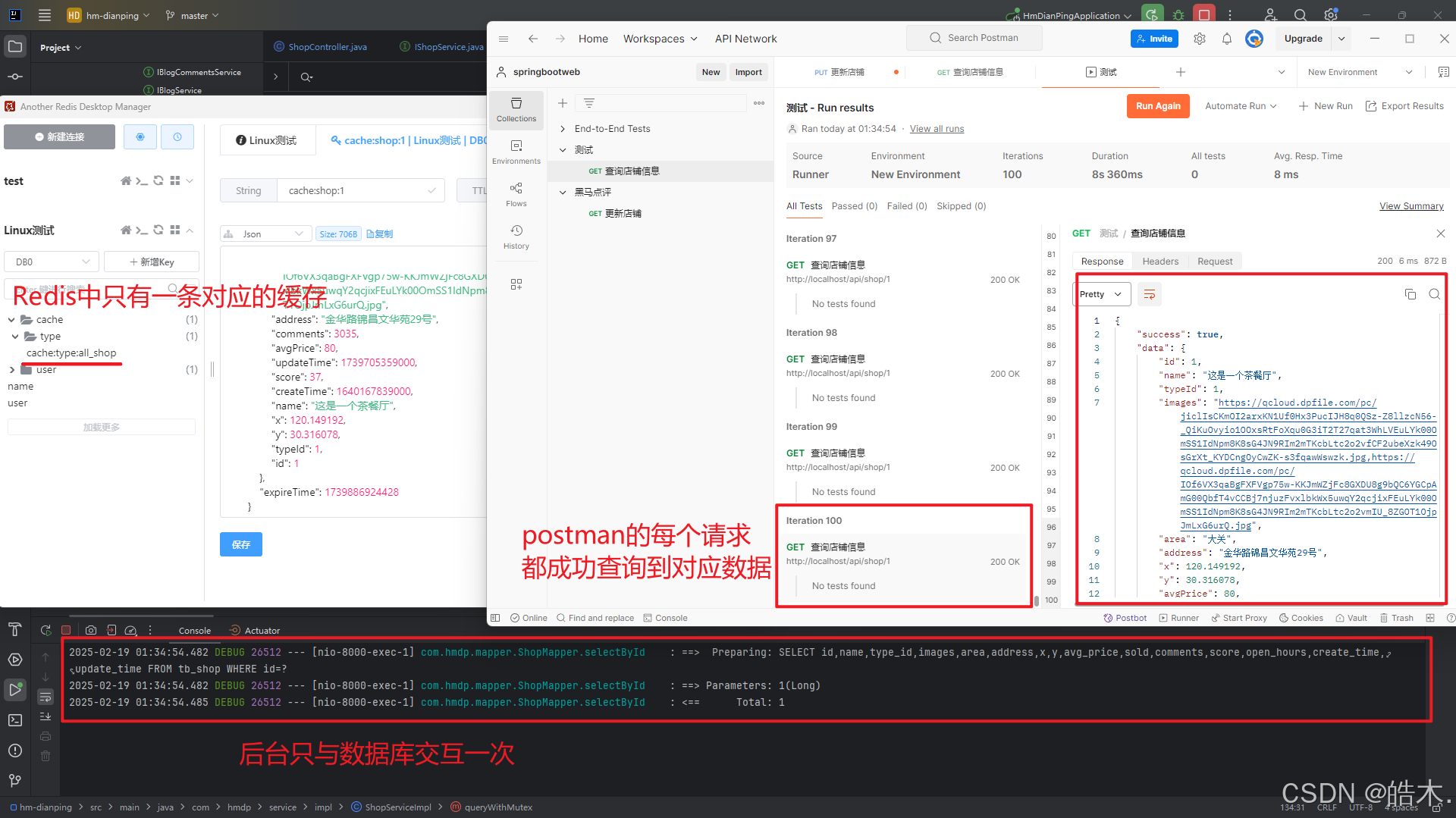
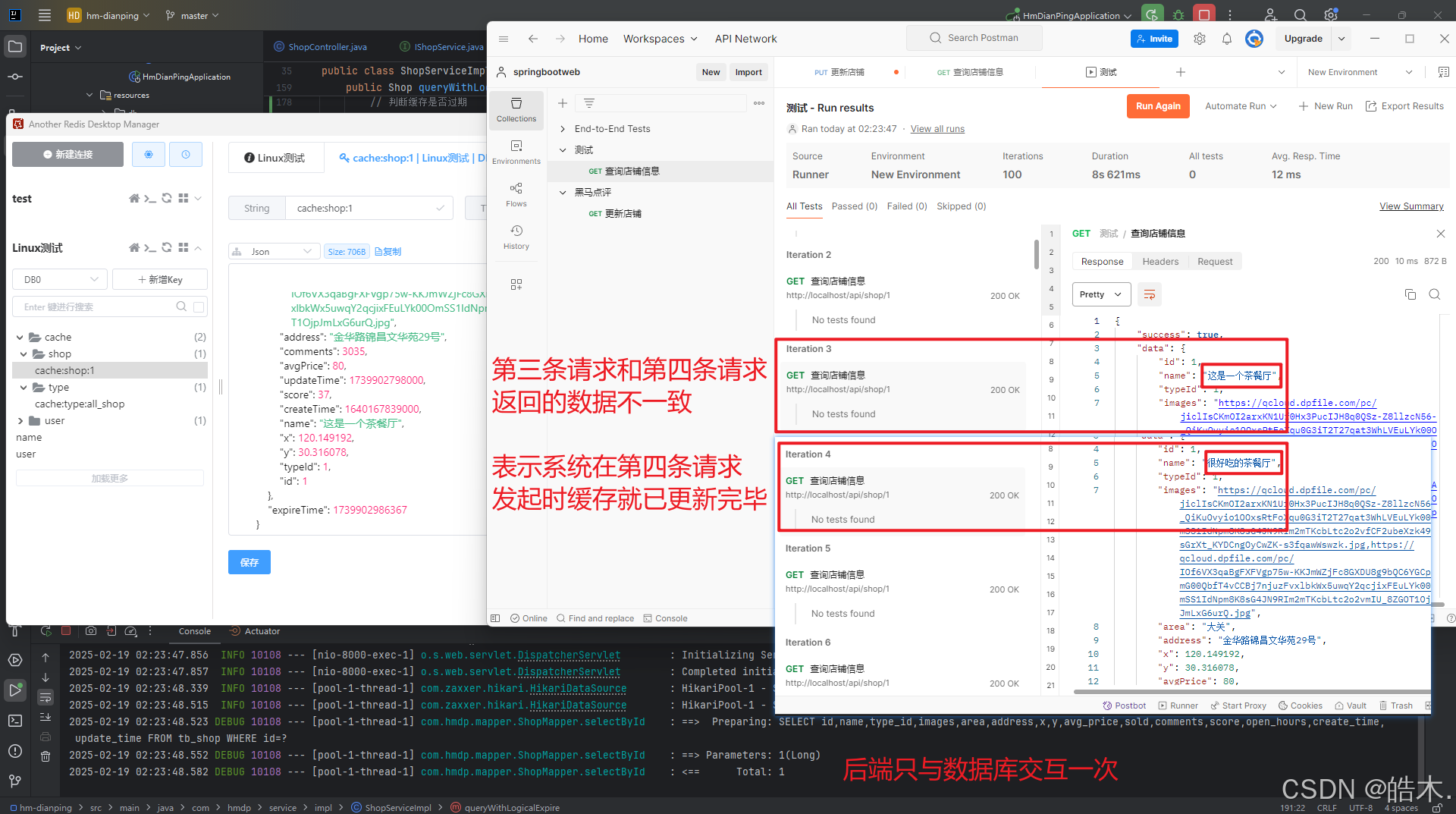
}我们可使用postman做测试,短时间内对http://localhost/api/shop/1发起大量请求,每个请求都成功获取到对应的数据,idea控制台只输出一次查询语句,即只与数据库交互一次:
然后是逻辑过期,同样是修改根据id查询商铺的业务,但是要基于逻辑过期方式来解决缓存击穿问题。
一般这种缓存用于存储限时对外开发的热点Key,一般会提前加入缓存,这种Key除非管理员删除,否则会一直存在,因此不会存在缓存未命中的问题,所以在未查询到key时,直接返回即可。
获取缓存后,需要先判断缓存是否过期,未过期的话仍直接返回数据即可,如果过期就需要尝试获取互斥锁—失败则返回已过期的信息—成功则根据开启独立线程再返回已过期的信息。新线程则会执行id查询数据库—将数据写入Redis—释放互斥锁一系列操作。
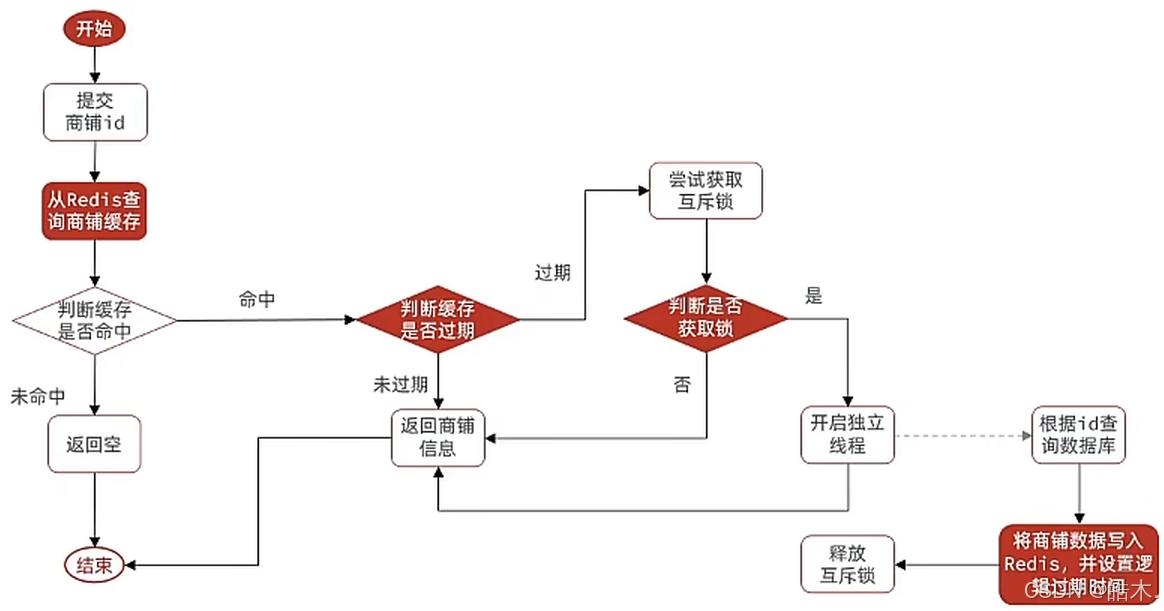
首先是逻辑过期字段,原本返回的Shop对象没有多余字段来逻辑过期时间,如果直接在Shop类中添加新的属性用于记录逻辑过期时间,虽然也能执行,但对原代码的侵入性较强。我们推荐其他两种方法:
一、Shop继承自新建类
可以新建一个RedisData类,包含逻辑过期字段,Shop类直接继承自该类即可。但该方法仍对代码有一定的侵入性。
二、新建类包含Shop类
同样新建一个RedisData类,包含逻辑过期字段,但还有一个Object字段,Shop对象可装在该Object中。但该方法不会对原先的代码做任何修改。
我们采用第二种方式来修改代码,RedisData类已存在于utils包中,无需再创建。
// 根据id查询数据、添加逻辑过期时间、写入Redis———————————————————
private void saveShop2Redis(Long id, Long expireSeconds) {
//查询店铺数据
Shop shop = getById(id);
//封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
//写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}有两点需要注意,因为Shop类的对象装进了RedisData的名为data的Object属性中,再转为Json格式存入Redis中,所以从Redis中取出的data实际上为JSONObject,我们需要强转。
在开辟新线程时,我们应使用线程池,而不是单独写一个线程,这样经常创建并销毁线程,会导致性能不佳。在使用新线程时,我们选择使用lambda表达式作为ExecutorService的submit方法的参数,其中之一就是它们不能抛出检查异常(checked exceptions)例如IOException、SQLException等,而运行时异常(RuntimeException)和错误(Error)是不受此限制的,因为它们是未检查异常(unchecked exceptions)。
老师提示在获取锁之后还需再检查一遍Redis中的缓存的逻辑日期是否过期,防止在获取锁时其他线程更新了缓存(),具体做法就是把"获取缓存—检查缓存逻辑时间是否过期"的代码复制一遍,我嫌麻烦就没有弄,大家感兴趣可以自行复制。
@Override
public Result queryById(Long id) throws Exception {
// // 缓存空对象解决缓存穿透
// Shop shop = queryWithPassThrough(id);
// // 互斥锁解决缓存击穿+缓存空对象解决缓存穿透
// Shop shop = queryWithMutex(id);
//逻辑过期解决缓存击穿+...
Shop shop = queryWithLogicalExpire(id);
if (shop == null) {
return Result.fail("店铺不存在!");
}
// 返回查询到的店铺对象
return Result.ok(shop);
}
//逻辑过期解决缓存穿透——————————————————————————
// 创建一个固定大小的线程池,用于异步执行缓存重建任务
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
/**
* 根据店铺ID查询店铺信息,同时处理逻辑过期和缓存穿透问题
* @param id 店铺ID
* @return 店铺信息,如果缓存未命中或发生异常则返回null
*/
public Shop queryWithLogicalExpire(Long id) {
// 构建缓存键
String key = CACHE_SHOP_KEY + id;
// 尝试从Redis获取店铺数据
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 检查缓存中是否有数据
if (StrUtil.isBlank(shopJson)) {
// 缓存未命中,直接返回null
return null;
}
// 缓存命中,将json反序列化为RedisData对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
// 进一步将RedisData中的数据部分反序列化为Shop对象
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
// 获取缓存的过期时间
LocalDateTime expireTime = redisData.getExpireTime();
// 判断缓存是否过期
if (expireTime.isAfter(LocalDateTime.now())) {
// 缓存未过期,直接返回店铺信息
return shop;
}
// 缓存已过期,需要重建缓存
// 构建互斥锁的键
String lockKey = LOCK_SHOP_KEY + id;
// 尝试获取互斥锁
boolean isLock = lockMutex(lockKey);
// 判断是否成功获取互斥锁
if (isLock) {
// 成功获取锁,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 重建缓存,设置新的过期时间
saveShop2Redis(id, 20L);
// 模拟重建缓存的延时
Thread.sleep(200);
} catch (RuntimeException | InterruptedException e) {
// 处理运行时异常,可以记录日志或者进行其他异常处理
throw new RuntimeException(e);
} finally {
// 释放互斥锁
unlockMutex(lockKey);
}
});
}
// 获取锁失败或发生异常,返回查询到的过期店铺对象
return shop;
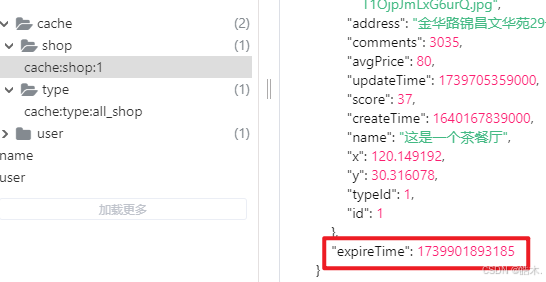
}因为原本的Redis缓存中的数据没有逻辑过期时间,我们可以先删除原数据,然后在测试中添加一条新的带有逻辑时间的缓存,即缓存预热:
ShopServiceImpl——————————————————————————————————————————————
private void saveShop2Redis(Long id, Long expireSeconds) {
//查询店铺数据
Shop shop = getById(id);
//封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
//写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}
public void aaa(long l, long l1) {
saveShop2Redis(1L,10L);
}
//测试类——————————————————————————
@SpringBootTest
class HmDianPingApplicationTests {
@Resource
private ShopServiceImpl shopService;
@Test
void contextLoads() {
shopService.aaa(1L,10L);
}
} 
为区分老缓存数据和新加入的缓存数据,我们直接修改数据库中的店铺名称,以便观察程序能否如期执行,然后同样在postman中发起大量相同的请求:
缓存工具封装
上文中无论是解决缓存穿透还是缓存击穿,他们的代码逻辑都比较复杂,如果每次开发都去重复这些代码逻辑,会大大提高开发成本,所以我们会选择将这些方案封装成工具,但在封装时我们仍会碰到不少问题,接下来我们以几个方法为例,来看一看可能存在的问题(这里并不是封装一个完整的工具类,只是以几个方法为例)。
基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
- 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
- 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
- 方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
- 方法4:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
@Component
@Slf4j
public class CacheClient {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间。
*
* @param key 缓存的键
* @param value 要缓存的对象
* @param time 过期时间
* @param unit 时间单位
*/
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
/**
* 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题。
*
* @param key 缓存的键
* @param value 要缓存的对象
* @param time 逻辑过期时间
* @param unit 时间单位
*/
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {
// 设置逻辑过期
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
// 写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
/**
* 根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题。
*
* @param keyPrefix 缓存键前缀
* @param id 查询的ID
* @param clazz 返回值类型
* @param function 对数据库执行的方法
* @param time 缓存过期时间
* @param unit 时间单位
* @param <T> 返回值类型泛型
* @param <ID> ID类型泛型
* @return 查询到的对象
*/
public <T, ID> T queryWithPassThrough(String keyPrefix, ID id, Class<T> clazz, Function<ID, T> function, Long time, TimeUnit unit) {
// 构建缓存键
String key = keyPrefix + id;
// 尝试从Redis获取数据
String json = stringRedisTemplate.opsForValue().get(key);
// 检查缓存中是否有数据
if (StrUtil.isNotBlank(json)) {
// 缓存命中,直接反序列化并返回对象
return JSONUtil.toBean(json, clazz);
}
// 判断命中的是否是空值(缓存穿透的空标记)
if (json != null) {
// 返回null,表明数据不存在
return null;
}
// 缓存未命中,从数据库查询数据
T data = function.apply(id);
// 检查数据库查询结果,防止缓存穿透
if (Objects.isNull(data)) {
// 将空值写入Redis,设置较短的过期时间
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 数据库中无数据,返回null
return null;
}
// 数据库中存在数据,序列化后存入Redis,并设置正常的过期时间
set(key, data, time, unit);
// 返回查询到的对象
return data;
}
/**
* 创建一个固定大小的线程池,用于异步执行缓存重建任务。
*/
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
/**
* 根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题。
*
* @param keyPrefix 缓存键前缀
* @param id 查询对象的ID
* @param clazz 反序列化的目标类
* @param function 数据库查询函数
* @param time 缓存过期时间
* @param unit 缓存过期时间单位
* @return 反序列化后的对象,如果缓存未命中或数据不存在则返回null
*/
public <T, ID> T queryWithLogicalExpire(String keyPrefix, ID id, Class<T> clazz, Function<ID, T> function, Long time, TimeUnit unit) {
// 构建缓存键
String key = keyPrefix + id;
// 尝试从Redis获取数据
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 检查缓存中是否有数据
if (StrUtil.isBlank(shopJson)) {
// 缓存未命中,直接返回null
return null;
}
// 缓存命中,将json反序列化为RedisData对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
// 进一步将RedisData中的数据部分反序列化为目标对象
T data = JSONUtil.toBean((JSONObject) redisData.getData(), clazz);
// 获取缓存的过期时间
LocalDateTime expireTime = redisData.getExpireTime();
// 判断缓存是否过期
if (expireTime.isAfter(LocalDateTime.now())) {
// 缓存未过期,直接返回数据
return data;
}
// 缓存已过期,需要重建缓存
// 构建互斥锁的键
String lockKey = LOCK_SHOP_KEY + id;
// 尝试获取互斥锁
boolean isLock = lockMutex(lockKey);
// 判断是否成功获取互斥锁
if (isLock) {
// 成功获取锁,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 重建缓存
// 查询数据库
T sqlData = function.apply(id);
// 设置新的过期时间并写入Redis
setWithLogicalExpire(key, sqlData, time, unit);
} catch (Exception e) {
// 处理运行时异常,可以记录日志或者进行其他异常处理
throw new RuntimeException(e);
} finally {
// 释放互斥锁
unlockMutex(lockKey);
}
});
}
// 获取锁失败或发生异常,返回查询到的过期数据对象
return data;
}
/**
* 获取互斥锁
* @param key 互斥锁的键
* @return 是否成功获取互斥锁
*/
private boolean lockMutex(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
/**
* 释放互斥锁
* @param key 互斥锁的键
*/
private void unlockMutex(String key) {
stringRedisTemplate.delete(key);
}
}
接下来修改原项目中的queryById(Long id)方法,使用上述封装的方法来实现:
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private CacheClient cacheClient;//注入封装的工具类
@Override
public Result queryById(Long id) throws Exception {
// 缓存空对象解决缓存穿透
// //旧方法
// Shop shop = queryWithPassThrough(id);
// //使用工具类
// Shop shop = cacheClient.queryWithPassThrough(CACHE_SHOP_KEY,id,Shop.class,this::getById,CACHE_SHOP_TTL,TimeUnit.MINUTES);
// 互斥锁解决缓存击穿+缓存空对象解决缓存穿透
// Shop shop = queryWithMutex(id);
//逻辑过期解决缓存击穿
// //旧方法
// Shop shop = queryWithLogicalExpire(id);
//使用工具类
Shop shop = cacheClient.queryWithLogicalExpire(CACHE_SHOP_KEY,id,Shop.class,this::getById,CACHE_SHOP_TTL,TimeUnit.MINUTES);
if (shop == null) {
return Result.fail("店铺不存在!");
}
// 返回查询到的店铺对象
return Result.ok(shop);
}
}this::getById是idParam -> getById(idParam)的简写,当this::getById被调用时,它会自动将传入的参数传递给getById方法。又或者我们可以直接使用匿名内部类来替代 Lambda 表达式:
Shop shop = cacheClient.queryWithPassThrough( CACHE_SHOP_KEY, id, Shop.class, new Function<Long, Shop>() { @Override public Shop apply(Long id) { return getById(id); } }, CACHE_SHOP_TTL, TimeUnit.MINUTES );
总结
本章我们学习了认识缓存、然后是如何添加缓存以及缓存使用中可能会出现的各种问题。
在认识缓存方面,我们主要讲了三点:
然后在项目中为代码添加redis缓存,在添加过程中发现了许多问题,例如缓存更新,有三种策略可供选择:

具体使用哪种策略要根据业务场景而定,低一致性需求使用内存淘汰或过期淘汰。高一致性需求则以主动更新为主,并以过期淘汰作为兜底方案。
而主动更新的策略又分为三种:

我们一般选择Cache Aside方案,但缓存和数据库的执行顺序也会影响系统的性能:
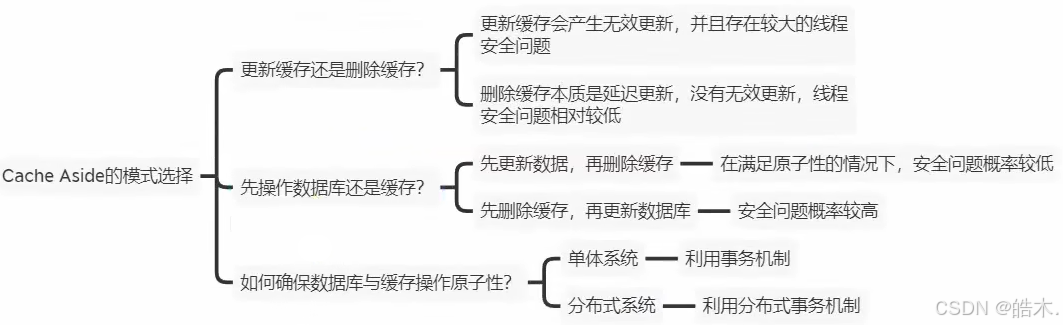
最佳的实现方案是:
查询数据时先查询缓存,如果缓存命中、直接返回,如果缓存未命中、则查询数据库,然后将数据库数据写入缓存,并返回结果。
修改数据库时,先修改数据库,然后删除缓存,可以确保两者的原子性。
然后是缓存穿透,其产生原因是:客户端请求数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
其有两种解决方案:
缓存雪崩的产生原因是:在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。解决方案有四种:
在平时编码时,做好数据的基础格式校验、加强用户权限校验、做好热点参数的限流等行为也能有效避免缓存穿透。
缓存击穿(热点Key)的产生原因主要是由于热点Key在某一时段被高并发访问,同时缓存重建耗时较长。当热点Key突然过期时,由于重建耗时长,在这段时间内大量请求会落到数据库,从而带来巨大的冲击。解决方案有两种,分别是互斥锁和逻辑过期: