第三章:Transformer模型探索
目录
一、Transformer综述
1.1 模型的输入与输出
1.2 Transformer LLM组件
1.3 从概率分布中选择单个token(采样/解码)
1.4 Transformer LLM的并行处理能力
1.5 通过kv-cache加速生成
1.6 Transformer 块的内部结构
1.6.1 前馈神经网络简介
1.6.2 注意力层简介
1.6.3 注意力机制的核心
1.6.4 注意力计算
1.6.5 自注意力:相关性评分
1.6.6 自注意力:信息整合
二、Transformer框架新进展
2.1 更加高效的注意力
2.1.1 局部注意力/稀疏注意力
2.1.2 多查询注意力和分组查询注意力
2.1.3 从多头注意力到多查询注意力再到分组查询注意力的优化
2.1.4 Flash Attention
2.2 Transformer块
2.3 位置嵌入(RoPE)
2.4 其他架构实验和改进
三、总结
一、Transformer综述
1.1 模型的输入与输出
将Transformer LLM视为一个软件系统,它接收文本并生成文本作为响应。如下图。

该模型不会在一次操作中生成所有文本;它实际上一次生成一个令牌。每个令牌生成步骤都是通过模型向前传递(这是机器学习的说法,即输入进入神经网络并流经计算所需的计算,从而在计算图的另一端产生输出)。
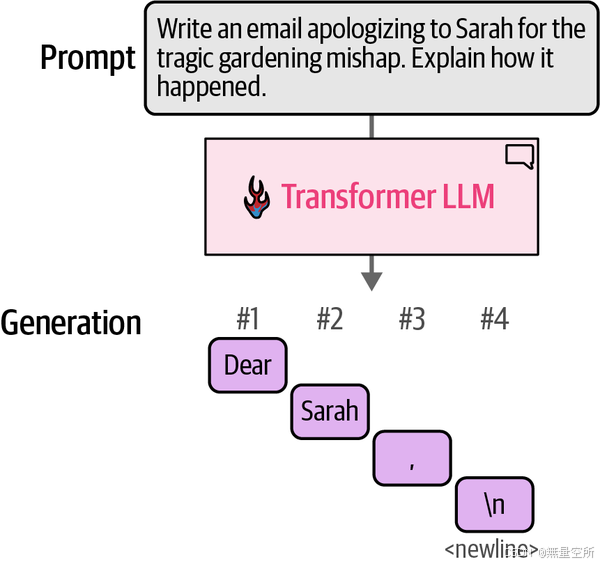
在每个令牌生成之后,我们通过将输出令牌附加到输入提示符的末尾来调整输入提示符以用于下一个生成步骤。如下图。
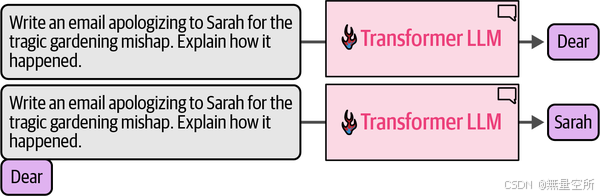
上述只利用之前的信息, 生成next token的模型被称为自回归模型
1.2 Transformer LLM组件
除了循环之外,还有两个关键的内部组件:tokenizer和语言建模头(LM head)
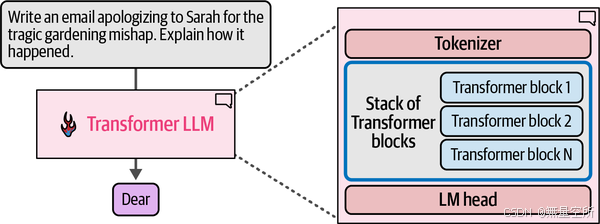
tokenizer将文本分解为一系列标记 ID,这些标记 ID 随后成为模型的输入。之后是神经网络(一个由 Transformer 块组成的堆叠,它完成了所有的处理工作)。之后是LM head,它将堆叠的输出转换为最可能的下一个标记的概率分数。
在第2章中,tokenizer包含一个标记表——标记器的词汇表。该模型具有与词汇表中的每个标记相关联的向量表示(标记嵌入)。下图显示了一个词汇表为50,000个标记的模型的词汇表和相关的标记嵌入。
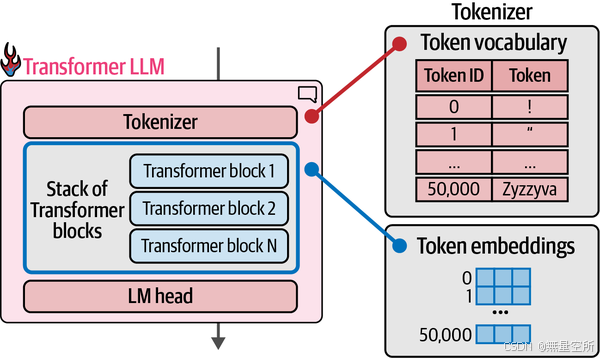
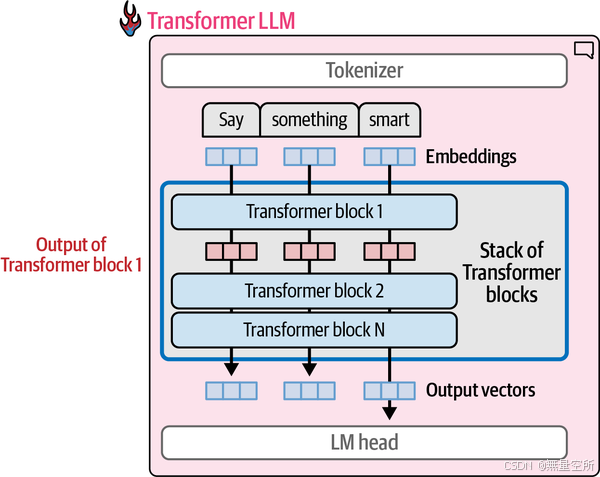
计算流程遵循箭头的方向,从上到下。对于每个生成的令牌,流程依次流过堆栈中的每个Transformer块一次,然后到达LM头部,最终输出下一个令牌的概率分布,如下图所示。
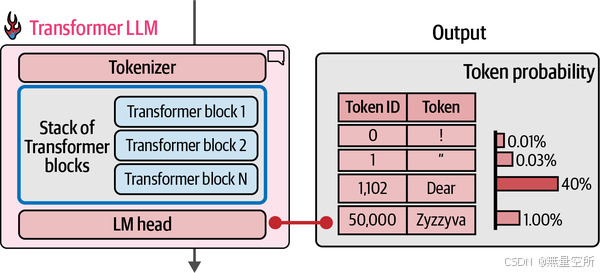
LM hea本身就是一个简单的神经网络层。它是可以附加到 Transformer 块堆叠上的多种“头部”之一,用于构建不同类型的系统。其他类型的 Transformer 头部包括序列分类头部和标记分类头部。
我们可以通过简单地打印出模型变量来显示这些层的顺序。对于这个模型,我们有:
Phi3ForCausalLM(
(model): Phi3Model(
(embed_tokens): Embedding(32064, 3072, padding_idx=32000)
(embed_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-31): 32 x Phi3DecoderLayer(
(self_attn): Phi3Attention(
(o_proj): Linear(in_features=3072, out_features=3072, bias=False)
(qkv_proj): Linear(in_features=3072, out_features=9216, bias=False)
(rotary_emb): Phi3RotaryEmbedding()
)
(mlp): Phi3MLP(
(gate_up_proj): Linear(in_features=3072, out_features=16384, bias=False)
(down_proj): Linear(in_features=8192, out_features=3072, bias=False)
(activation_fn): SiLU()
)
(input_layernorm): Phi3RMSNorm()
(resid_attn_dropout): Dropout(p=0.0, inplace=False)
(resid_mlp_dropout): Dropout(p=0.0, inplace=False)
(post_attention_layernorm): Phi3RMSNorm()
)
)
(norm): Phi3RMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=32064, bias=False)
)
这展示了模型的各种嵌套层。模型的大部分被标记为 model,后面跟着 lm_head。
在 Phi3Model 模型中,我们看到了嵌入矩阵 embed_tokens 及其维度。它包含 32,064 个标记,每个标记的向量大小为 3,072。
暂时跳过 Dropout 层,我们可以看到下一个主要组件是 Transformer 解码器层的堆叠。它包含 32 个 类型为 Phi3DecoderLayer 的块。
这些 Transformer 块中的每一个都包含一个注意力层和一个前馈神经网络(也称为 MLP 或多层感知器)。我们将在本章后面更详细地介绍这些内容。
最后,我们看到 lm_head 接收一个大小为 3,072 的向量,并输出一个与模型已知标记数量相等的向量。这个输出是每个标记的概率分数,帮助我们选择输出标记。
1.3 从概率分布中选择单个token(采样/解码)
在处理结束时,模型的输出是词汇表中每个标记的概率分数,正如上一张图中那样。
从概率分布中选择单个token的方法称为解码策略。下图展示了如何在一个例子中选择标记“Dear”。
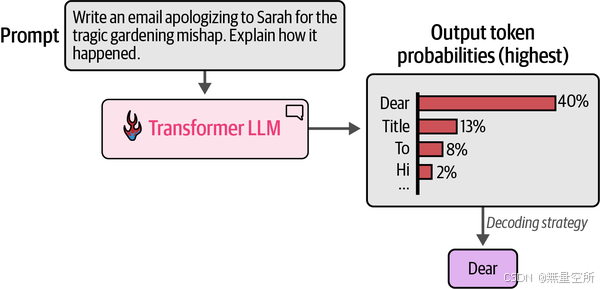
最简单的解码策略是始终选择概率分数最高的token。然而,在实践中,这种方法通常不会为大多数用例生成最佳输出。更好的方法是加入一些随机性,有时选择第二或第三高概率的标记。这里的想法是,根据概率分数从概率分布中进行采样。
对于上图中的例子来说,这意味着如果标记 “Dear” 有 40% 的概率成为下一个token,那么它就有 40% 的机会被选中(而不是贪婪搜索,贪婪搜索会直接选择它,因为它有最高的分数)。因此,通过这种方法,其他标记也会根据它们的分数有机会被选中。
每次选择最高分数的标记称为贪婪解码。如果你在大语言模型(LLM)中将温度参数设置为零,就会发生这种情况。在第 6 章中会讨论温度的概念。
让我们更仔细地看看展示这一过程的代码。在这个代码块中,我们将输入标记传递给模型,然后传递给 lm_head:
prompt = "The capital of France is"
# 对输入提示进行分词
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
# 将输入提示传递到 GPU
input_ids = input_ids.to("cuda")
# 获取模型在 lm_head 之前的输出
model_output = model.model(input_ids)
# 获取 lm_head 的输出
lm_head_output = model.lm_head(model_output[0])现在,lm_head_output 的形状是 [1, 6, 32064]。我们可以通过 lm_head_output[0, -1] 获取最后一个生成标记的标记概率分数,其中索引 0 用于批次维度,索引 -1 获取序列中的最后一个标记。这现在是一个包含所有 32,064 个标记的概率分数列表。我们可以通过 argmax 获取最高分数的标记 ID,然后将其解码为生成输出标记的文本:
token_id = lm_head_output[0, -1].argmax(-1)
tokenizer.decode(token_id)
>> 结果
Paris1.4 Transformer LLM的并行处理能力
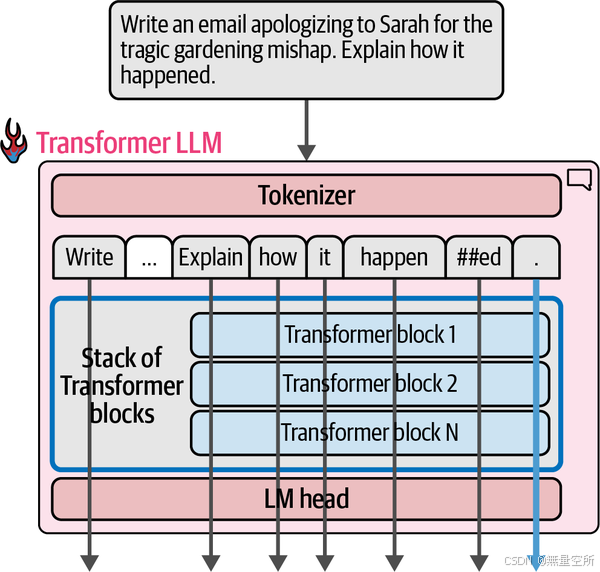
限制:一次可以处理的token数量上限。这个限制被称为模型的上下文长度(context length)。例如,一个上下文长度为 4K 的模型只能处理 4K 个标记,也只会产生 4K 个这样的流。
每个标记流都从一个输入向量开始(即嵌入向量和一些位置信息)。在流的末端,经过模型处理后会生成另一个向量,如下图所示。
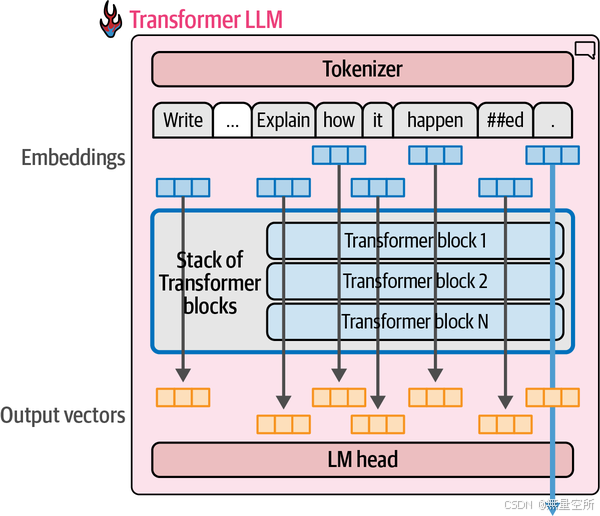
在文本生成中,只有最后一个流的输出结果被用来预测下一个token。这个输出向量是LM head计算下一个标记概率时的唯一输入。
- 问题:既然我们只保留最后一个标记的输出,为什么还要费力计算所有标记流呢?
- 答案:前面流的计算是必需的,并且会用于最终流的计算。是的,我们没有使用它们的最终输出向量,但在每个 Transformer 块中,我们会使用早期的输出(在 Transformer 块的注意力机制中)。
如果你正在跟随代码示例,回想一下 lm_head 的输出形状是 [1, 6, 32064]。这是因为它的输入形状是 [1, 6, 3072],这表示一个包含六个标记的输入字符串,每个标记由一个大小为 3,072 的向量表示,这些向量对应于经过 Transformer 块堆叠后的输出向量。
我们可以通过打印以下代码来访问这些矩阵并查看它们的维度:
model_output[0].shape
>> 结果
torch.Size([1, 6, 3072])同样,我们可以打印lm head的输出:
lm_head_output.shape
>> 输出
torch.Size([1, 6, 32064]) 1.5 通过kv-cache加速生成
在生成第二个标记时,我们只需将输出标记追加到输入中,然后再次对模型进行前向传播。如果让模型能够缓存上一次计算的结果(尤其是注意力机制中的一些特定向量),我们就无需重复计算之前的流。这次唯一需要计算的只有最后一个流。这种优化技术被称为键和值(kv)缓存,它可以显著加快生成过程。
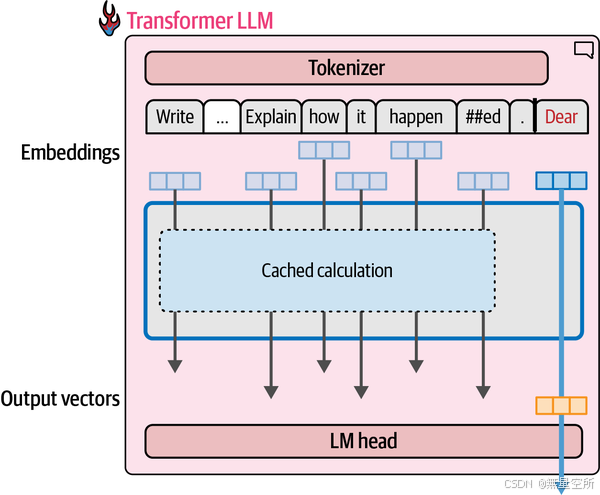
在 Hugging Face Transformers 中,缓存默认是启用的。我们可以通过将 use_cache 设置为 False 来禁用它。我们可以通过请求长文本生成,并在启用和禁用缓存的情况下对生成过程进行计时,来观察速度的差异:
prompt = "Write a very long email apologizing to Sarah for the tragic gardening mishap. Explain how it happened."
# 对输入提示进行分词
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
input_ids = input_ids.to("cuda")计算生成 100 个标记所需的时间(使用 %%timeit 命令来测量执行时间(它会多次运行命令并计算平均值)):
1)启用缓存,在配备 T4 GPU 的 Colab 上,这大约需要 4.5 秒。:
%%timeit -n 1
# 生成文本
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=100,
use_cache=True
)2)禁用缓存,结果是 21.8 秒:
%%timeit -n 1
# 生成文本
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=100,
use_cache=False
)这是一个巨大的差异。事实上,从用户体验的角度来看,即使是四秒的生成时间对于盯着屏幕等待模型输出的用户来说也显得过长。这也是为什么 LLM API 会将输出token流式传输给用户,而不是等待整个生成过程完成后再输出的原因之一。
总结
- 仅有最后⼀个token的output vector⽤于LM head⽣成output token。但其它token中间参与了attention 相关的计算,因此也是必需的。
- 前⾯内容的计算结果可以缓存, kv-cache
1.6 Transformer 块的内部结构
Transformer语言模型由一系列Transformer块组成(在原始Transformer论文中通常是6个,在许多大型语言模型中则超过100个)。每个块处理其输入,然后将处理结果传递给下一个块。
一个Transformer块(见下图)由两个连续的组件构成:
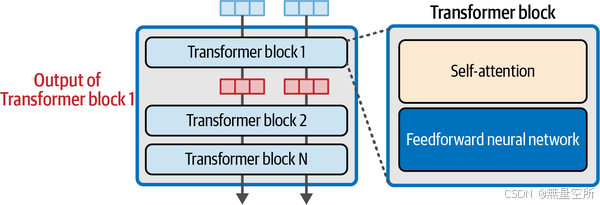
-
注意力层:主要负责将其他输入token和位置的相关信息纳入其中。
-
前馈层:占据了模型大部分的处理能力。
1.6.1 前馈神经网络简介
一个简单的例子可以帮助我们理解前馈神经网络的作用。假设我们向语言模型输入简单的短语“Shawshank”,期望它生成“Redemption”作为最可能的下一个词(这是对1994年电影的引用)。
如下图所示,模型中的前馈神经网络(在所有模型层中)是这种信息的来源。当模型成功地被训练来模拟一个庞大的文本库(其中包含许多对“Shawshank Redemption”的提及)时,它学会并存储了使其能够完成这项任务的信息和行为。
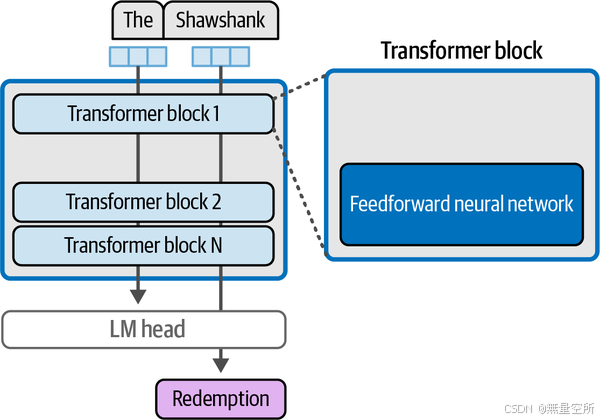
为了成功训练一个LLM,它需要记住大量的信息。但它并不是一个简单的大型数据库。模型能够利用相同的机制在数据点之间进行插值,并处理更复杂的模式,从而实现泛化——这意味着它能够在过去未见过且不在其训练数据集中的输入上表现良好。
注意:
当你使用现代商业LLM时,你得到的输出并不是严格意义上的“语言模型”所提到的输出。例如,将“Shawshank”传递给像GPT-4这样的聊天LLM,会产生以下输出:
"The Shawshank Redemption" is a 1994 film directed by Frank Darabont and is based on the novella "Rita Hayworth and Shawshank Redemption" written by Stephen King. ...等。
这是因为原始的语言模型(如GPT-3)对人们来说很难正确使用。这就是为什么语言模型随后会经过指令微调和基于人类偏好及反馈的微调,以符合人们对模型输出的期望。
1.6.2 注意力层简介
为了正确地模拟语言,上下文至关重要。仅仅基于前一个token进行记忆和插值只能让我们走这么远。我们知道这一点,因为这曾经是神经网络出现之前构建语言模型的主要方法之一(见Daniel Jurafsky和James H. Martin所著的《语音和语言处理》第3章“N-gram语言模型”)。
注意力是一种帮助模型在处理特定标记时纳入上下文的机制。考虑以下提示:
“The dog chased the squirrel because it”
为了让模型预测“it”之后的内容,它需要知道“it”指的是什么。是指狗还是松鼠?
在一个训练有素的Transformer LLM中,注意力机制会做出这个判断。注意力将上下文中的信息纳入“it”标记的表示中。我们可以在下图中看到一个简单版本的这种机制。
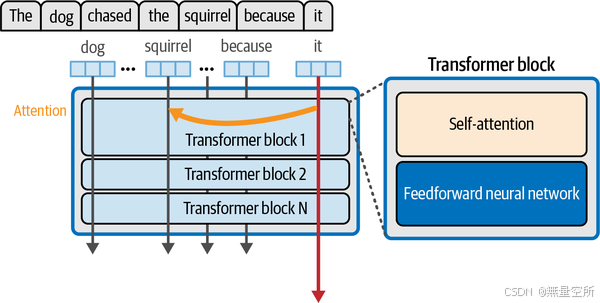
1.6.3 注意力机制的核心
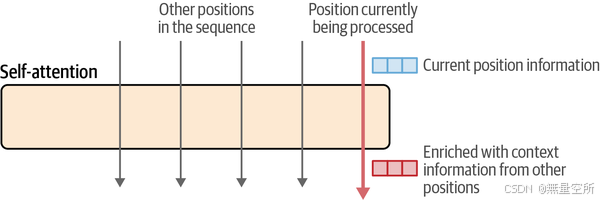
上图展示了该机制最简化的版本。它显示了多个标记位置进入注意力层;最后一个是当前正在处理的位置(粉色箭头)。注意力机制在该位置的输入向量上运行,并将上下文中的相关信息纳入到该位置的输出向量中。
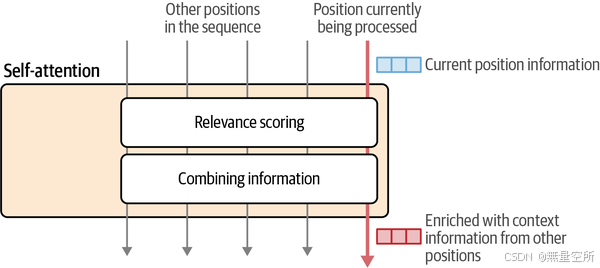
注意力机制涉及两个主要步骤:
相关性评分:为每个前一个输入标记评分,以确定它们与当前正在处理的标记的相关性(粉色箭头)。
信息整合:根据这些评分,将各个位置的信息整合到一个单一的输出向量中。
下图展示了这两个步骤。
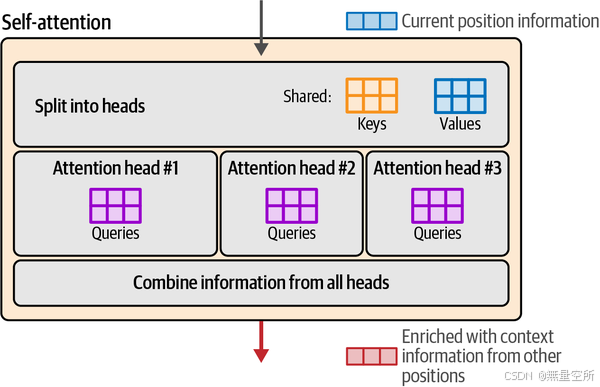
为了增强Transformer的注意力能力,注意力机制被复制并多次并行执行。每个并行的注意力执行被称为一个注意力头。这增加了模型在输入序列中模拟复杂模式的能力,这些模式需要同时关注不同的模式。
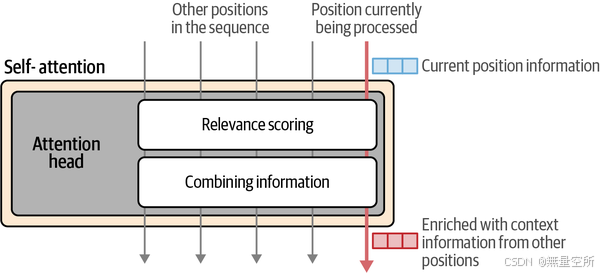
上图展示了注意力头如何并行运行的直觉,包括一个前一步骤,将信息拆分,以及一个后一步骤,将所有头的结果合并。
1.6.4 注意力计算
让我们看看在一个单独的注意力头中如何计算注意力。
在开始计算之前,让我们先了解如下组件:
注意力层(生成型LLM)正在处理一个位置的注意力。
层的输入包括:
当前位置或标记的向量表示
前一个标记的向量表示
- 目标是产生一个新的当前位置表示,该表示纳入了前一个标记的相关信息。
- 例如,如果我们正在处理句子“Sarah fed the cat because it”中的最后一个位置,我们希望“it”代表猫——因此注意力将“猫的信息”从猫标记中纳入。
- 训练过程产生了三个投影矩阵,这些矩阵产生了在这个计算中相互作用的组件:
查询投影矩阵(query projection matrix)
键投影矩阵(key projection matrix)
值投影矩阵(value projection matrix)
下图展示了在开始自注意力计算之前,所有这些组件的起始位置。为了简化,我们只看一个注意力头,因为其他头的计算是相同的,但使用它们各自的投影矩阵。
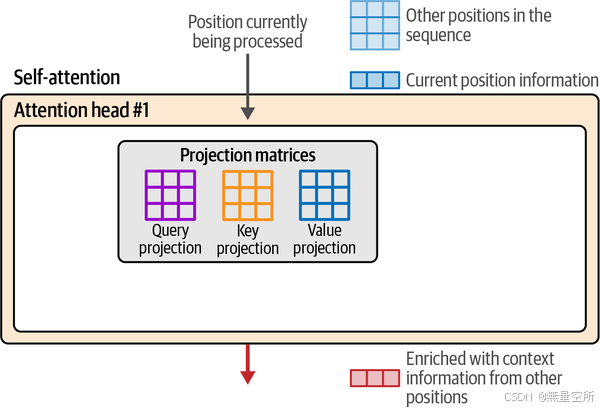
注意力首先通过将输入乘以投影矩阵来创建三个新矩阵。这些被称为查询矩阵、键矩阵和值矩阵。这些矩阵包含了输入标记的信息,这些信息被投影到三个不同的空间中,以帮助执行注意力的两个步骤:
相关性评分
信息整合
下图展示了这三个新矩阵,以及所有三个矩阵的底部一行与当前位置相关,而其上方的行与前一个位置相关。
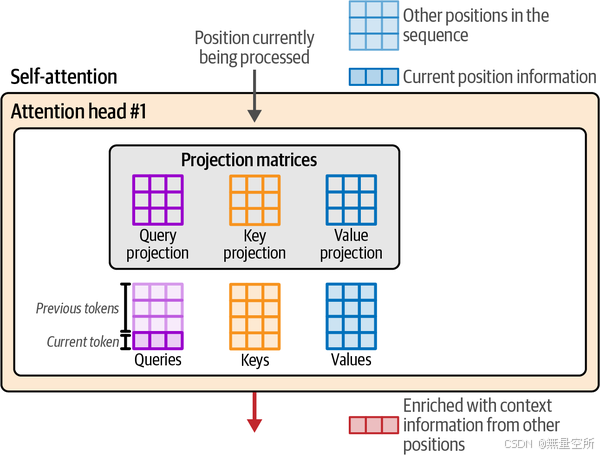
1.6.5 自注意力:相关性评分
在生成型Transformer中,我们一次生成一个标记。这意味着我们一次处理一个位置。因此,这里的注意力机制只关心这一个位置,以及如何从其他位置拉取信息来告知这个位置。
注意力的相关性评分步骤是通过将当前位置的查询向量与键矩阵相乘来完成的。这产生了一个分数,表明每个前一个标记的相关性。通过softmax操作对这些分数进行归一化,使它们的总和为1。下图展示了由此计算得出的相关性评分。
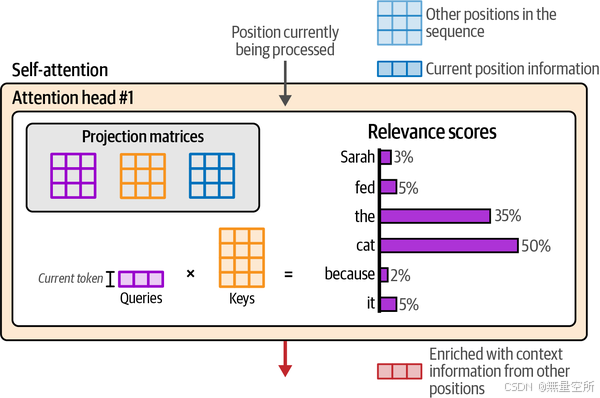
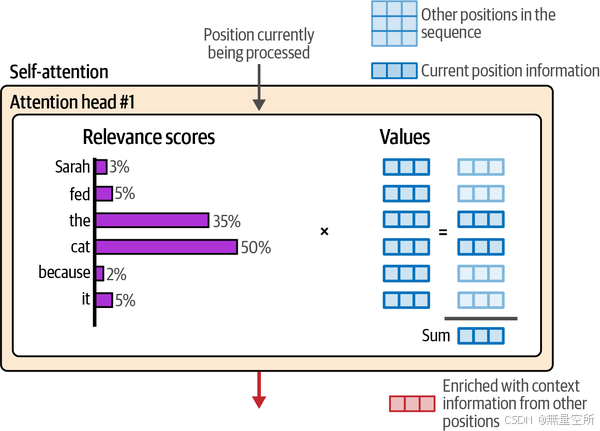
1.6.6 自注意力:信息整合
现在我们有了相关性评分,我们将每个标记的值向量乘以其评分。将这些结果向量相加,就产生了这个注意力步骤的输出,如下图所示。
总结
- 输⼊:当前位置token向量表示,前序tokens的向量表示
- 目标:为当前位置token⽣成⼀个新的表示向量,融合了前序tokens中 相关的信息
- 步骤:
- 每个token raw vector利用投影矩阵生成3个矩阵Q, K, V
- 该token和其它位置token的相关权重由Q和其它token的V计算得到
- 利用相关权重把其它token的V向量加权求和
二、Transformer框架新进展
2.1 更加高效的注意力
2.1.1 局部注意力/稀疏注意力
稀疏注意力限制了模型可以关注的上下文范围,如下图所示。
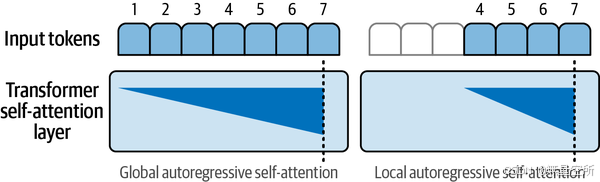
GPT-3是采用这种机制的一个模型,但它并不是在所有Transformer块中都使用稀疏注意力——如果模型只能看到少量的前一个标记,生成质量会大幅下降。GPT-3架构交替使用全注意力(Full-Attention)和高效注意力(Efficient-Attention)Transformer块。因此,Transformer块在全注意力(例如第1块和第3块)和稀疏注意力(例如第2块和第4块)之间交替。
为了展示不同类型的注意力机制,可以参考下图2.1.1,它展示了不同注意力机制的工作方式。每个图显示了在处理当前标记(深蓝色)时可以关注的前一个标记(浅蓝色)。

每一行对应一个正在处理的标记。颜色编码表示模型在处理深蓝色单元格中的标记时能够关注哪些标记。图2.1.2对此进行了更清晰的描述。
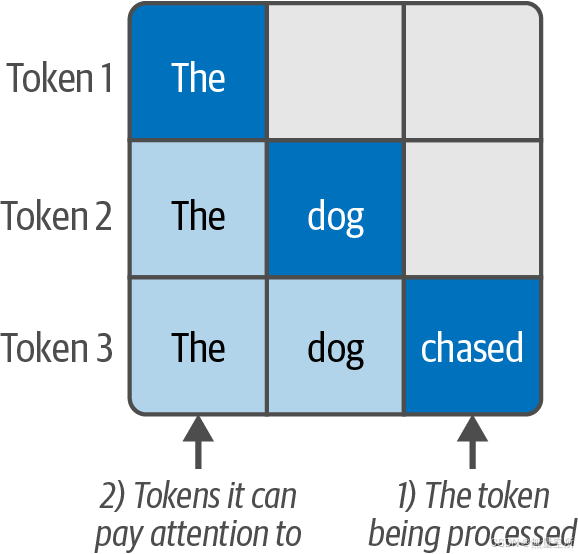
该图还展示了解码器Transformer块的自回归特性(大多数文本生成模型都是由解码器Transformer块组成);它们只能关注之前的标记。这与BERT形成了对比,BERT可以关注两侧的标记(BERT中的“B”代表双向)。
2.1.2 多查询注意力和分组查询注意力
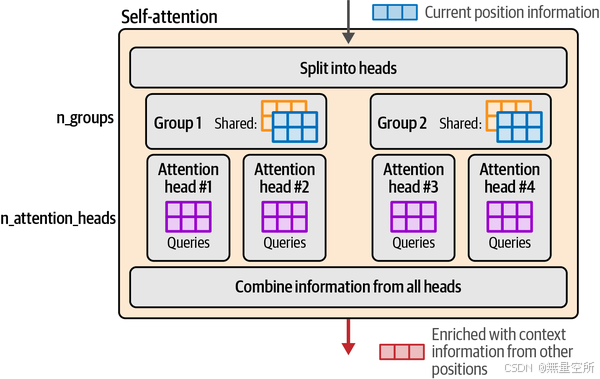
分组查询注意力(Grouped-Query Attention)是最近对Transformer注意力机制的一种优化改进,被像Llama 2和Llama 3这样的模型所采用。下图展示了这些不同类型的注意力机制。
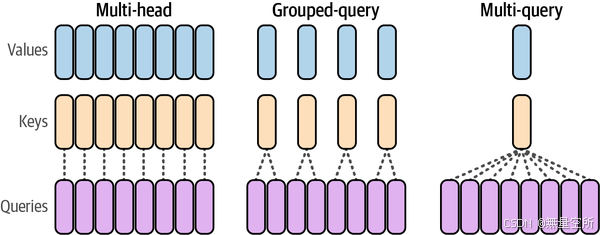
分组查询注意力是基于多查询注意力(Multi-Query Attention)发展而来的。这些方法通过减少涉及的矩阵大小,提高了大型模型的推理可扩展性。
2.1.3 从多头注意力到多查询注意力再到分组查询注意力的优化
下图展示了多头注意力机制的每个“注意力头”如何为给定输入计算其独特的查询、键和值矩阵。
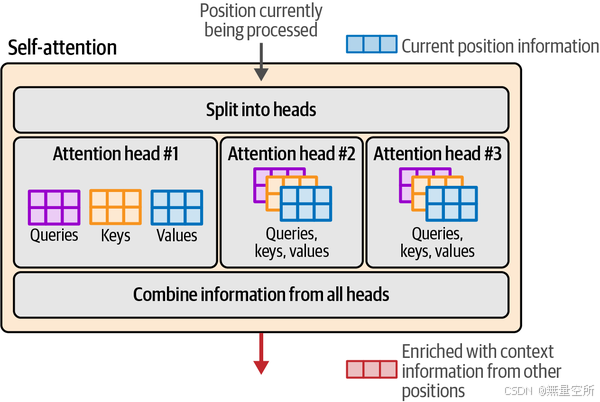
多查询注意力的优化方式是让所有头共享键和值矩阵。因此,每个头唯一独特的矩阵只有查询矩阵,如图3-27所示。
然而,随着模型规模的增大,这种优化可能会过于苛刻,我们可以承受使用更多内存以提高模型质量。这就是分组查询注意力的用武之地。它没有将键和值矩阵的数量减少到每个一个,而是允许使用更多(但少于头的数量)。下图展示了这些分组以及每个分组的注意力头如何共享键和值矩阵。
2.1.4 Flash Attention
Flash Attention是一种流行的方法和实现,它为在GPU上训练和推理Transformer语言模型提供了显著的速度提升。它通过优化在GPU的共享内存(SRAM)和高带宽内存(HBM)之间加载和移动的值,加快了注意力计算的速度。它在论文“FlashAttention: Fast and memory-efficient exact attention with IO-awareness”以及后续的“FlashAttention-2: Faster attention with better parallelism and work partitioning”中被详细描述。
2.2 Transformer块
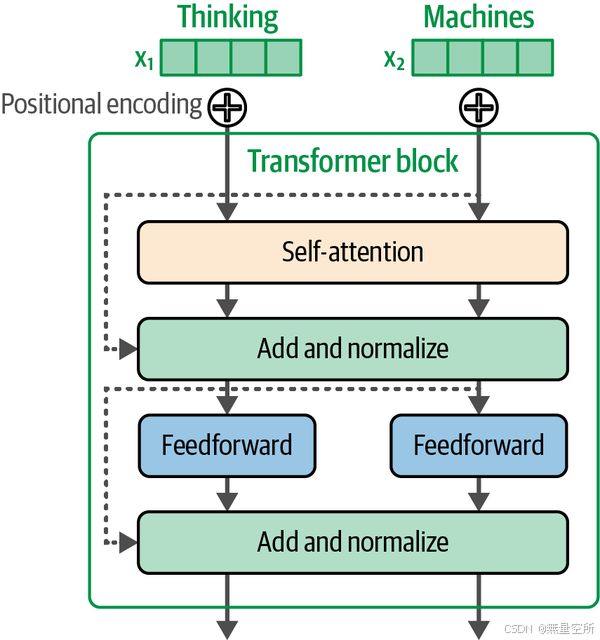
回想一下,Transformer块的两个主要组成部分是注意力层和前馈神经网络。如果更详细地观察这个模块,我们还会发现残差连接和层归一化操作,这些在下图中可以看到。
最新的Transformer模型仍然保留了主要组件,但进行了许多调整,如下图所示。
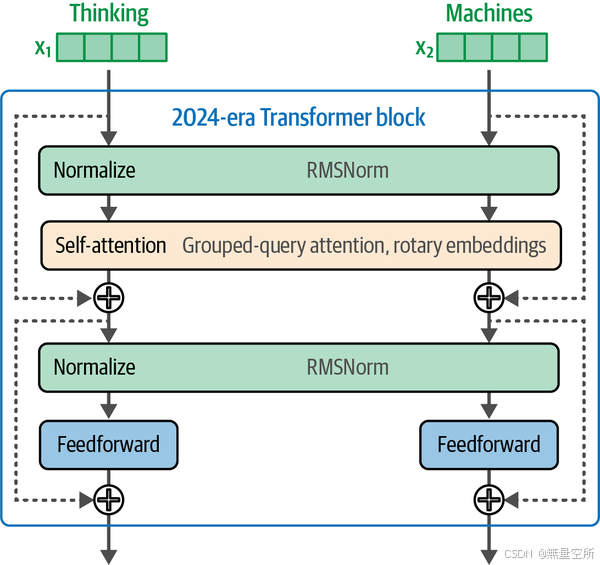
在这一版本的Transformer块中,我们可以看到的一个区别是,归一化操作发生在注意力层和前馈层之前。有研究表明,这种做法可以减少所需的训练时间(可参考文献《Transformer架构中的层归一化》)。在归一化方面的另一个改进是使用了RMSNorm,它比原始Transformer中使用的LayerNorm更简单、更高效(可参考文献《均方根层归一化》)。最后,与原始Transformer的ReLU激活函数不同,现在更常见的激活函数是像SwiGLU这样的变体(在文献《GLU变体改进Transformer》中有描述)。
2.3 位置嵌入(RoPE)
位置嵌入一直是Transformer架构的核心组成部分,它使模型能够跟踪序列/句子中标记/单词的顺序,这在语言中是不可或缺的信息来源。在过去几年提出的众多位置编码方案中,旋转位置嵌入(Rotary Position Embeddings,简称RoPE)尤其值得关注。
在原始Transformer论文及其早期变体中,位置嵌入是绝对的,本质上是将第一个标记标记为位置1,第二个标记为位置2,依此类推。这些位置嵌入可以是静态的(通过几何函数生成位置向量),也可以是学习的(在模型训练过程中分配值)。然而,当模型规模扩大时,这些方法面临一些挑战,这促使我们寻找提高效率的方法。
例如,在训练具有大上下文的模型时,训练集中的许多文档比上下文短得多。如果为一个只有10个单词的短句子分配整个4K上下文,这是非常低效的。因此,在模型训练过程中,文档会被打包到每个上下文中,如下图所示。
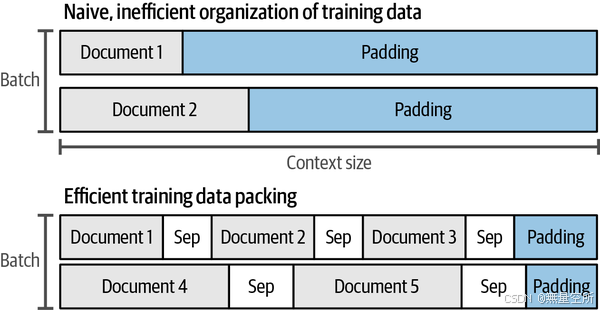
关于打包的更多内容,可以阅读“Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance”,并观看“Introducing packed BERT for 2X training speed-up in natural language processing”中的精彩可视化内容。
位置嵌入方法必须适应这种和其他实际考虑。例如,如果文档50从位置50开始,那么如果我们告诉模型第一个标记是第50个,就会误导模型,这会影响其性能(因为它会假设存在之前的上下文,而实际上前面的标记属于另一个不相关的文档,模型应该忽略)。
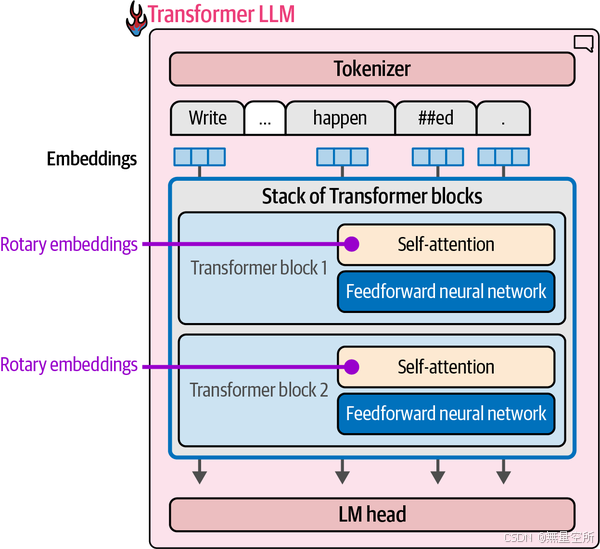
与在前向传播开始时添加的静态绝对嵌入不同,旋转嵌入是一种编码位置信息的方法,能够捕捉绝对和相对标记位置信息。它基于在嵌入空间中旋转向量的想法。在前向传播中,它们在注意力步骤中被添加,如下图所示。
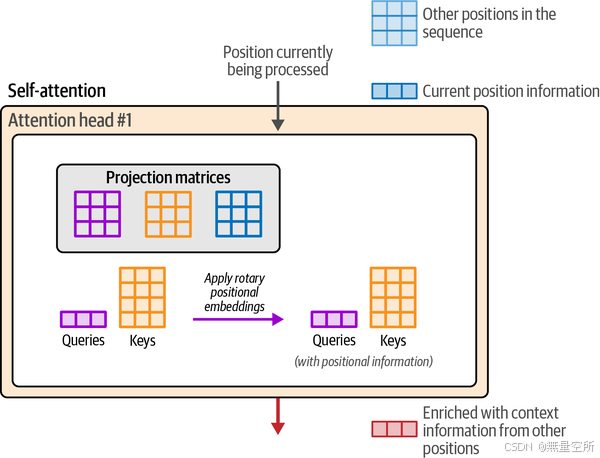
在注意力过程中,位置信息被特别地混合到查询矩阵和键矩阵中,就在我们对它们进行相关性评分之前相乘,如下图所示。
2.4 其他架构实验和改进
Transformer架构的改进和变体不断被提出和研究。“A Survey of Transformers”总结了一些主要的研究方向。Transformer架构也在不断适应超出语言模型的其他领域。计算机视觉是Transformer架构研究非常活跃的一个领域(参见“Transformers in vision: A survey”和“A survey on vision transformer”)。其他领域包括机器人技术(参见“Open X-Embodiment: Robotic learning datasets and RT-X models”)和时间序列(参见“Transformers in time series: A survey”)。
三、总结
1、Transformer语言模型逐标记生成:
Transformer语言模型一次生成一个标记。生成的输出标记会被追加到提示(prompt)中,然后更新后的提示会再次输入模型进行前向传播,以生成下一个标记。
2、Transformer语言模型的三大主要组件:
- 分词器(Tokenizer):
包含模型的标记词汇表。模型为这些标记配备了嵌入向量(token embeddings)。将文本分解为标记,并使用这些标记的嵌入向量是标记生成过程的第一步。- Transformer块堆叠:
这是模型的核心处理单元,负责大部分的计算工作。- 语言建模头(LM Head):
在生成过程的最后阶段,LM Head 会为下一个可能的标记打分,解码策略则决定选择哪个标记作为这一步的输出(有时是最可能的标记,但并非总是如此)。- 并行处理能力:
Transformer架构的一个重要优势是能够并行处理标记。每个输入标记都会进入独立的处理路径或流。模型的“上下文大小”(context size)表示模型能够处理的最大标记数量,这也是并行处理的基础。- 缓存机制:
由于Transformer语言模型通过循环逐标记生成文本,因此缓存每个步骤的处理结果可以避免重复计算(这些结果存储在各层的不同矩阵中)。
3、Transformer块的核心作用:
Transformer块是模型的主要处理单元,由两个部分组成:
- 前馈神经网络(Feedforward Neural Network):用于存储信息,并根据训练数据进行预测和插值。
- 注意力层(Attention Layer):通过整合上下文信息,使模型能够更好地捕捉语言的细微差别。
4、注意力机制的两个主要步骤:
- 相关性评分(Scoring Relevance):计算当前标记与其他标记的相关性。
- 信息整合(Combining Information):根据相关性评分,将不同位置的信息整合到一个输出向量中。
5、多头注意力的并行化:
Transformer的注意力层通过多个注意力头(attention heads)并行执行注意力操作,这些头的输出会被聚合起来,构成注意力层的最终输出。为了加速注意力计算,可以通过共享键和值矩阵(例如分组查询注意力)来优化这一过程。
6、Flash Attention等优化方法:
通过优化GPU内存系统中的操作方式,Flash Attention等方法可以显著加快注意力计算的速度。
7、Transformer的持续发展:
Transformer架构仍在不断演进,研究者们不断提出新的改进方法,以适应不同的场景,包括语言模型和其他领域的应用。
8、预告:
接下来,我们将探讨这些语言模型的实际应用。在第4章中,我们将从文本分类任务开始,这是语言人工智能中的一个常见任务。这一章将作为应用生成模型和表示模型的入门介绍。