使用GPU训练模型
1.说明
本地训练模型可以用CPU和GPU,但是GPU的性能比CPU要好得多,所以如果有独立显卡的,尽量还是用GPU来训练模型。
使用GPU需要安装Cuda和Cudnn
2.安装Cuda
安装cuda之前,首先看一下显卡支持的cuda版本,在命令行输入如下命令:
nvidia-smi显示如图:
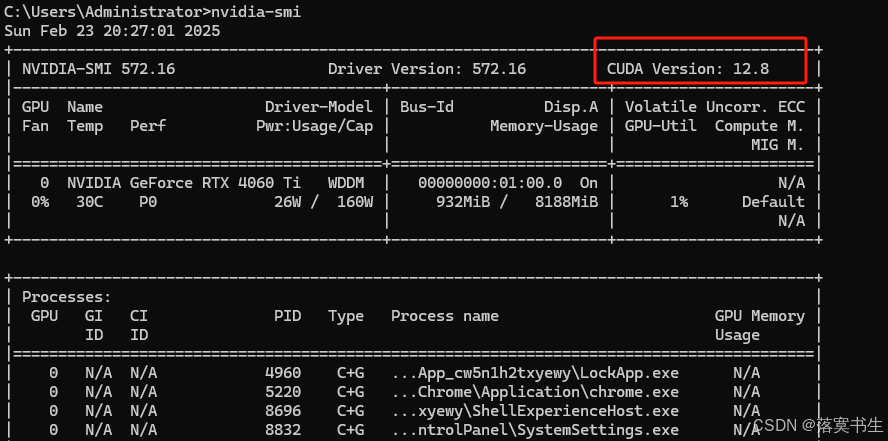
我这里支持的版本是:12.8
进入官网:https://developer.nvidia.com/cuda-toolkit-archive
找到对应的版本:
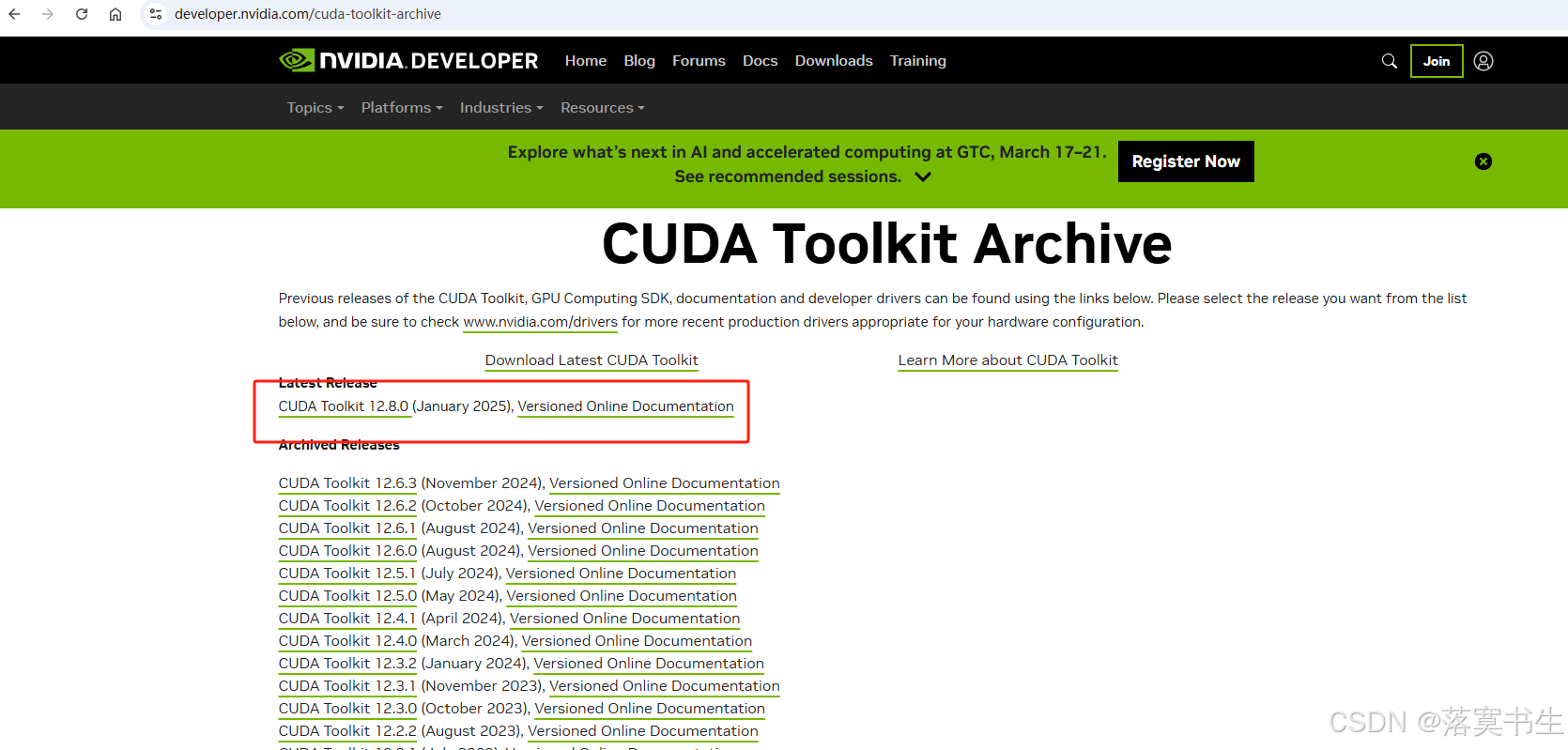
点击对应的版本,进入网页,选择你的平台,如图:
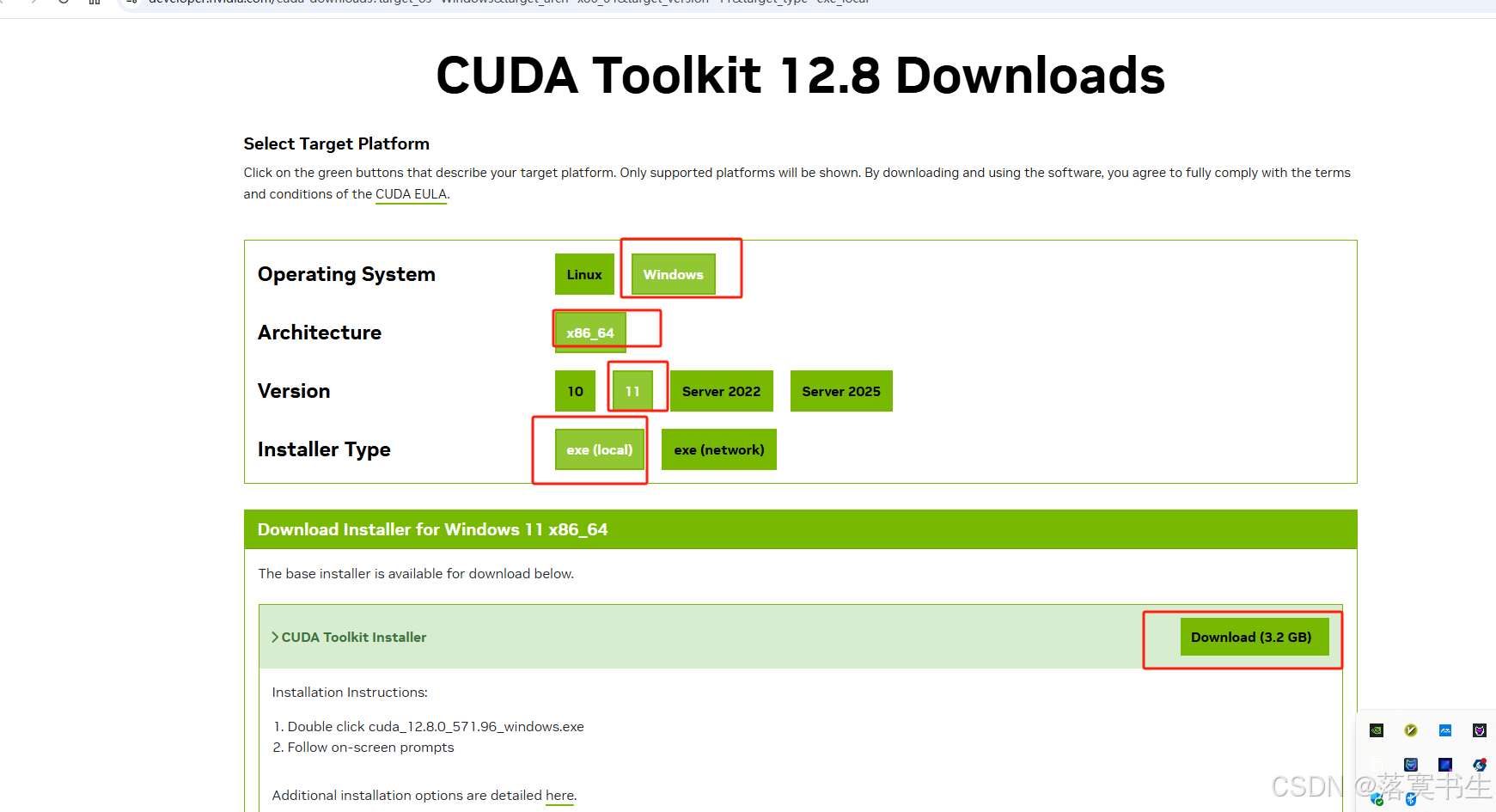
软件一共3.2G,安装软件之前,确定软件有VC++环境,不然会失败。
我是装了Visual Studio 2019
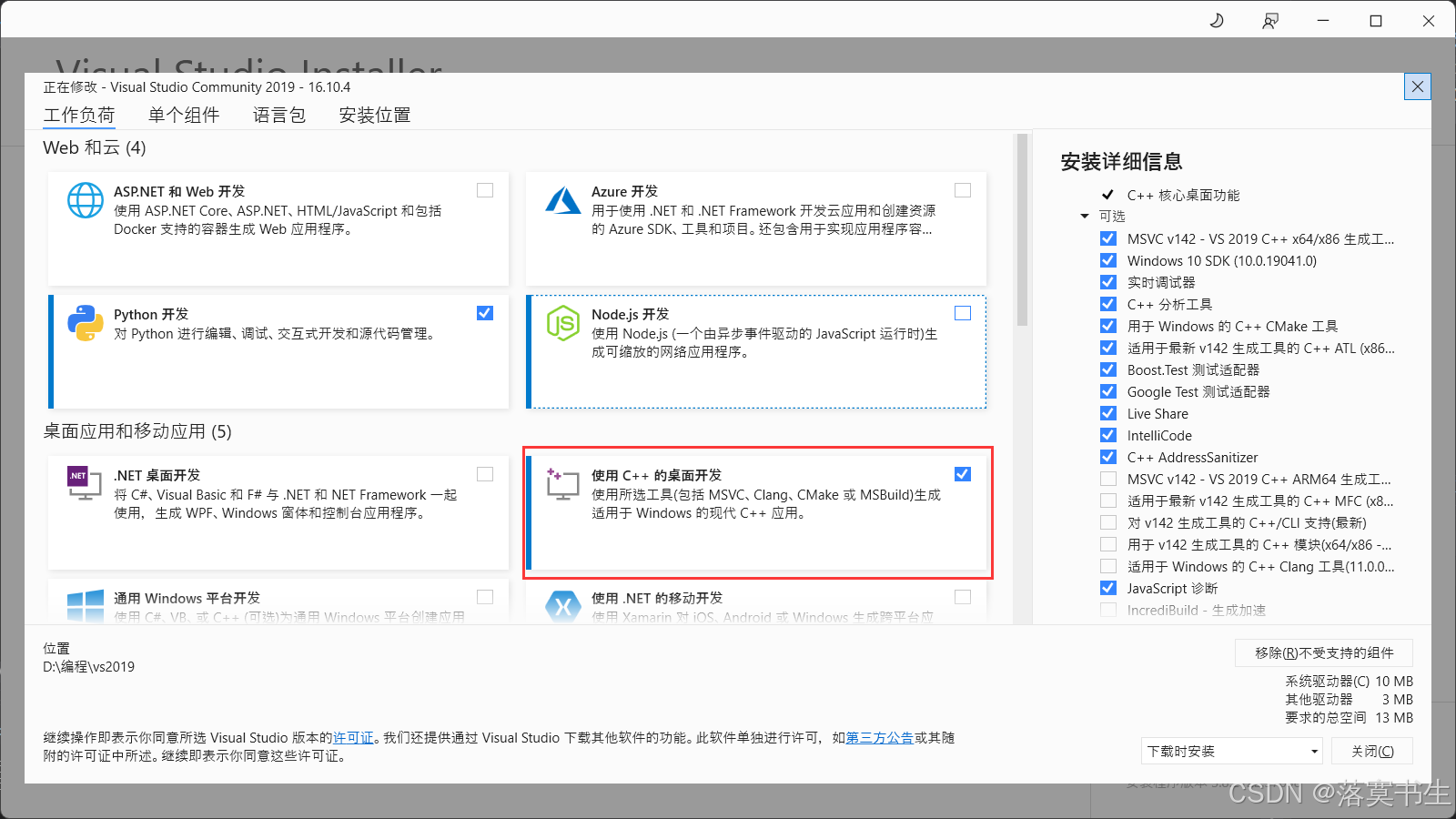
装了vc++环境之后就可以开始安装cuda,选择自定义安装,如图:
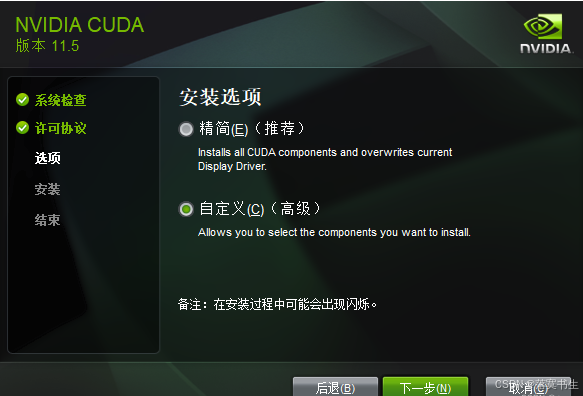
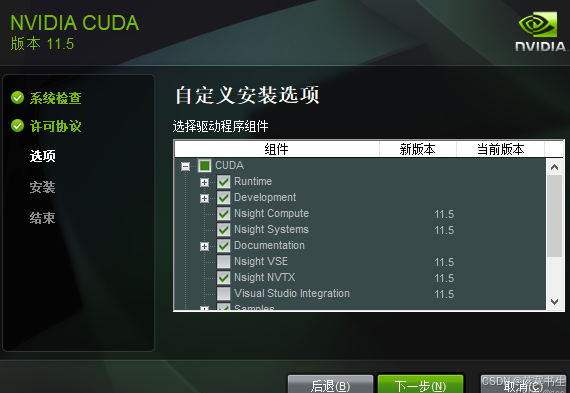
在选择组件的时候,将CUDA中的Nsight VSE和Visual Studio Integration取消勾选,后选择下一步,即可安装成功,如图:
安装完成之后,检查是否安装成功,输入命令:
nvcc -V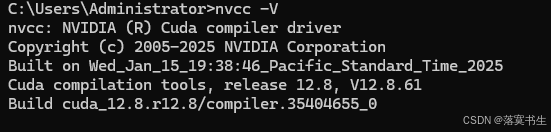
3.安装cudnn
下载地址:cuDNN 9.7.1 Downloads | NVIDIA Developer
下载合适自己的版本
如图:
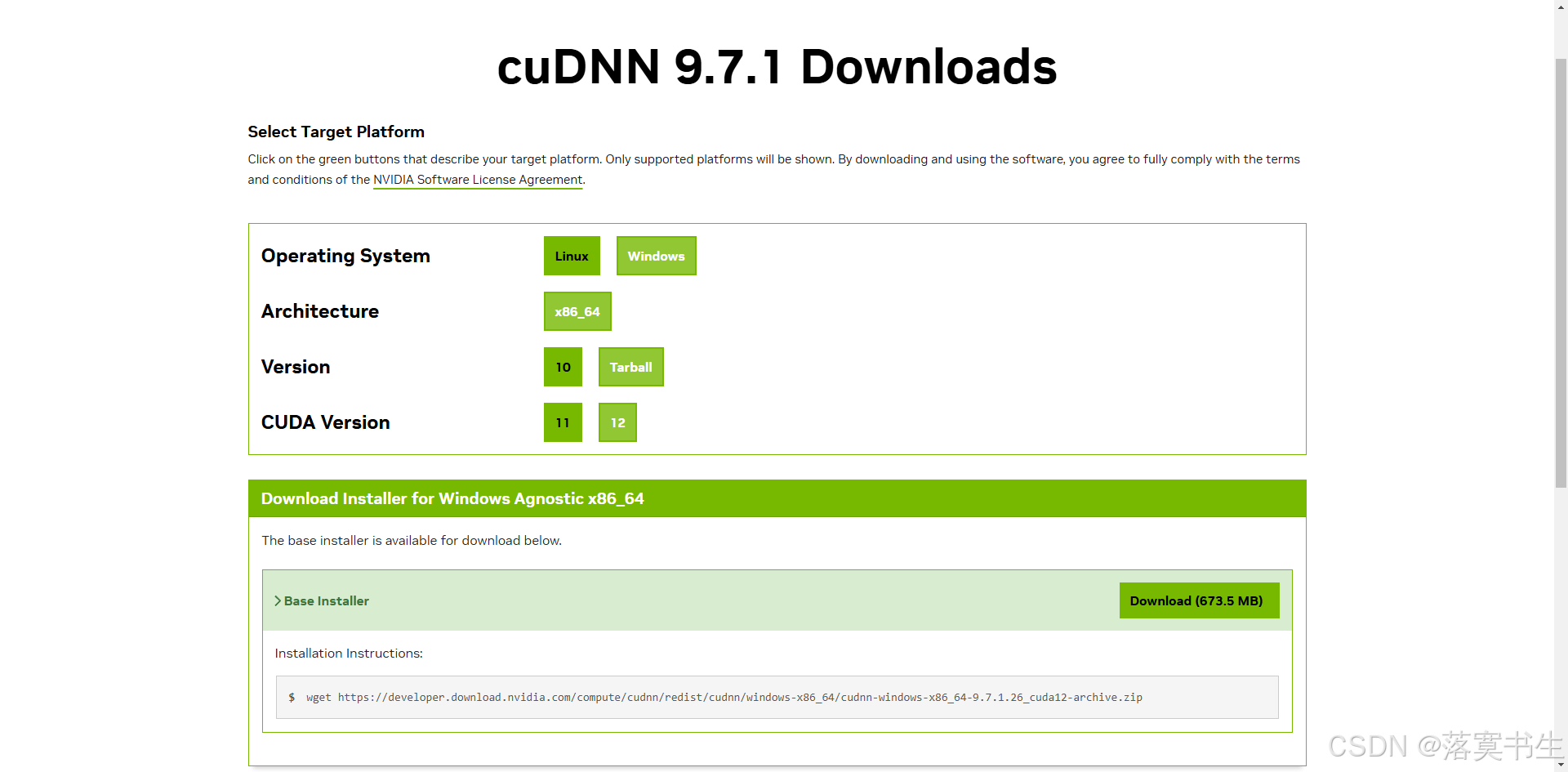
然后浏览器直接输入地址下载:
https://developer.download.nvidia.com/compute/cudnn/redist/cudnn/windows-x86_64/cudnn-windows-x86_64-9.7.1.26_cuda12-archive.zip
下载完成之后,然后解压,如图:
然后将所有文件拷贝到某个目录,我这里是:D:\program\cuda,然后设置环境变量:
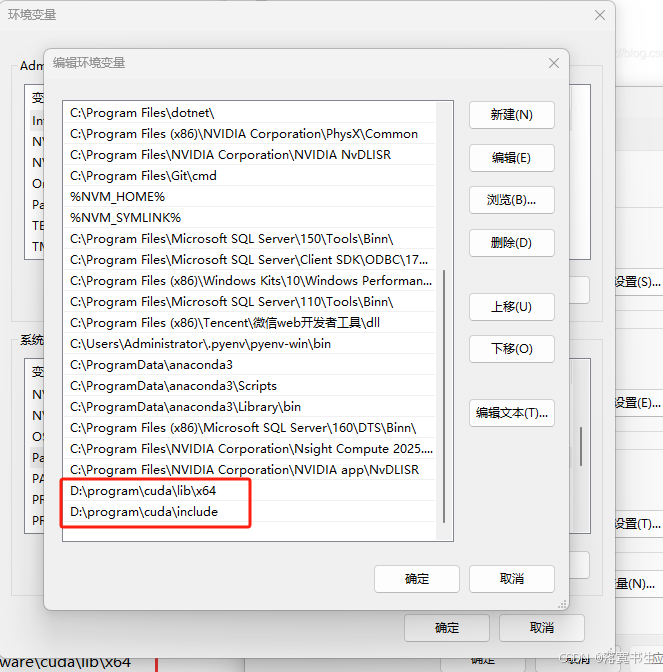
至此,就安装完成。
编写一个测试代码,看看是否支持CPU。
先装依赖:
pip install torch-2.6.0+cu126-cp312-cp312-win_amd64.whl
pip install torchaudio-2.6.0+cu126-cp312-cp312-win_amd64.whl
pip install torchvision-0.21.0+cu126-cp312-cp312-win_amd64.whlimport torch
# 检查torch是否有CUDA支持,即是否能用GPU
print(torch.cuda.is_available())
# 如果CUDA可用,它还会打印出当前默认的CUDA设备(通常是第一个GPU)
if torch.cuda.is_available():
print(torch.cuda.get_device_name(0))
print(torch.version.cuda)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)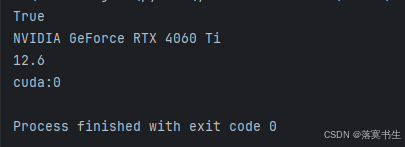
4.创建测试项目
我们使用YOLO机器学习框架来测试,创建一个python项目,然后安装如下依赖:
GPU版本的torch
pip install torch-2.6.0+cu126-cp312-cp312-win_amd64.whl
pip install torchaudio-2.6.0+cu126-cp312-cp312-win_amd64.whl
pip install torchvision-0.21.0+cu126-cp312-cp312-win_amd64.whl然后安装ultralytics等基础依赖
pip install ultralytics==8.3.75
pip install pandas==2.2.3
pip install matplotlib==3.10.0
pip install opencv-python==4.11.0.86然后准备训练数据,如图:
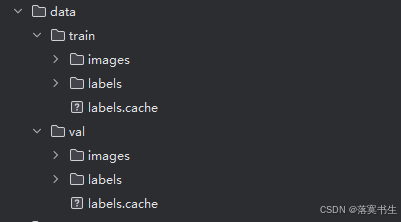
然后编写data.yaml配置文件,如图:
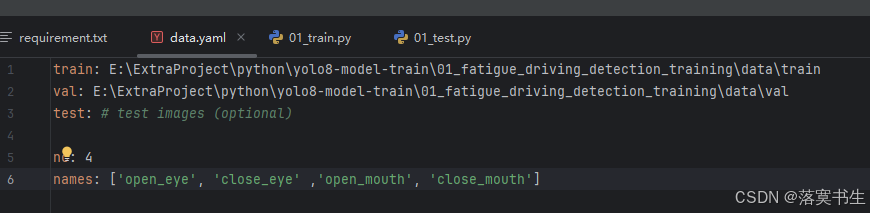
然后编写代码:
from ultralytics import YOLO
# coding:utf-8
# 根据实际情况更换基础模型
#yolov8n.pt 轻量化模型,适合嵌入式设备,速度快但精度略低。
#yolov8s.pt 小模型,适合实时任务。
#yolov8m.pt 中等大小模型,兼顾速度和精度。
#yolov8l.pt 大型模型,适合对精度要求高的任务。
#yolov8x.pt
#基础模型
model_path = '../base_model/yolov8s.pt'
data_path = './data.yaml'
if __name__ == '__main__':
model = YOLO(model_path)
# 训练模型
results = model.train(
data=data_path,
epochs=500, # 训练轮数
batch=64, # 批次大小
device='0', # 使用nvidia-smi查看gpu的序号,使用 GPU 0,如果有多个 GPU 可以使用 '0,1,2,3'
workers=0, # 数据加载工作线程数
project='runs/detect', # 保存结果的项目目录
name='fatigue_detection', # 实验名称
imgsz=640 # 图像大小
)
model.save('best_fatigue_detection.pt')如图:
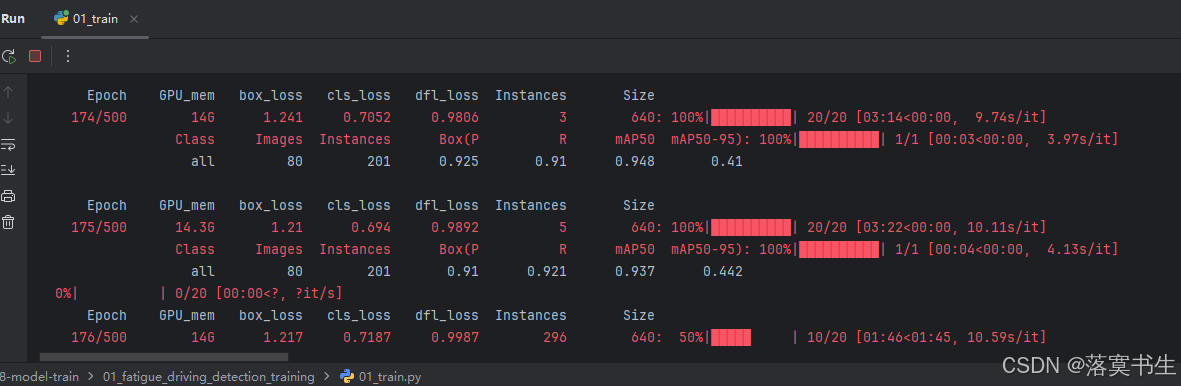
5.测试模型
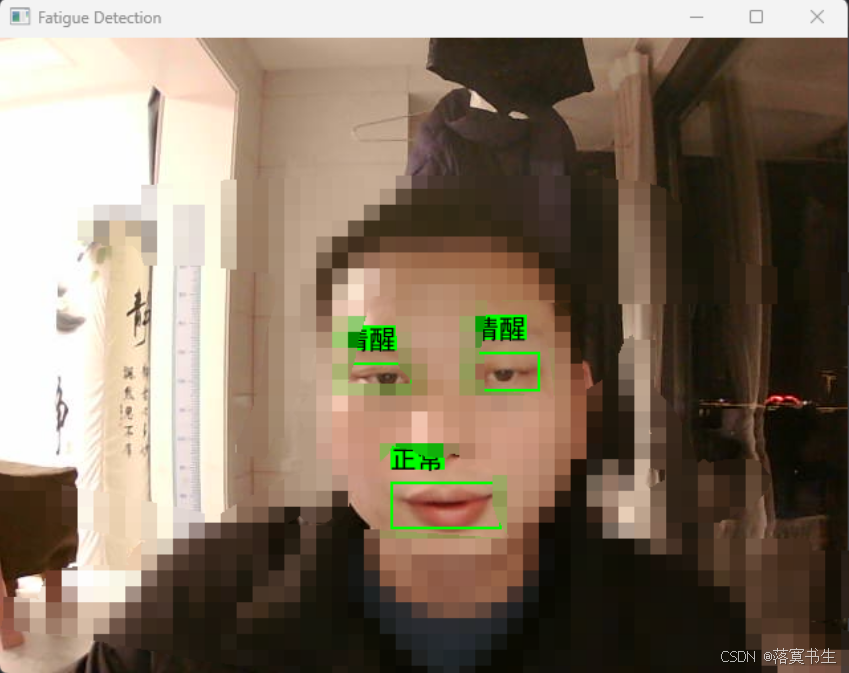
![]()
torch-gpu