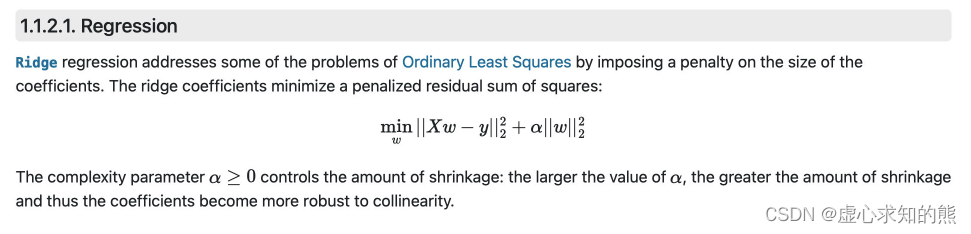文章目录
一、过拟合、正则化、特征衍生与特征重要性评估 1. 正则化(Regularization)的基本概念 2. 过拟合概念介绍 3. 正则化进行特征筛选与缓解过拟合倾向 二、sklearn 中逻辑回归的参数解释 1. 说明文档中的内容解释 2. sklearn 中逻辑回归评估器的参数解释
在了解了 sklearn 的一些常用的操作之后,接下来,我们来详细学习关于正则化的相关内容,并对 sklearn 中的逻辑回归的参数进行详细解释。 需要注意的是,由于 sklearn 内部参数的一致性,有许多参数不仅是逻辑回归的参数,更是大多数分类模型的通用参数。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib. pyplot as plt
from ML_basic_function import *
在上一篇文章当中,我们已经尝试着利用逻辑回归构建了一个多分类模型,得益于 sklearn 中良好的默认参数设置,我们在对 sklearn 中内部构造基本没有任何了解的情况下就完成了相关模型的建模。 但需要知道的事,逻辑回归作为一个诞生时间较早并且拥有深厚统计学背景的模型,其实是拥有非常多变种应用方法的,虽然我们在 Lesson 4 中就逻辑回归的基本原理、基础公式以及分类性能进行了较长时间的探讨,但实际上逻辑回归算法的模型形态和应用方式远不仅于此。 在 sklearn 中,则提供了非常丰富的逻辑回归的可选的算法参数,相当于是提供了一个集大成者的逻辑回归模型。 当然,首先我们需要介绍一个非常重要的机器学习中的概念,正则化。 在逻辑回归的说明文档中,第一个参数就是关于正则化的一个选项: from sklearn. linear_model import LogisticRegression
LogisticRegression?
也就是 penalty=‘l2’ 一项,而正则化也是机器学习中非常通用的一项操作。 接下来,我们就正则化的相关内容展开讨论。
从说明文档中得知,就是在 sklearn 中,逻辑回归模型是默认进行正则化的,即上文所述 “Regularization is applied by default”,这是一种在机器学习建模过程中常见的用法,但并非统计学常用方法。 据此我们也知道了统计学和机器学习方法之间的又一个区别,并且能够清楚的感受到 sklearn 是一个非常“机器学习”的算法库,很多时候会从便于机器学习建模的角度出发对算法进行微调。 这也是 sklearn 算法库的一大特性,这个特性在导致其非常易用的同时,也使得其很多算法和原始提出的算法会存在略微的区别,这点也是初学者需要注意的。 什么是正则化/如何进行正则化 其实机器学习中正则化(regularization)的外在形式非常简单,就是在模型的损失函数中加上一个正则化项(regularizer),有时也被称为惩罚项(penalty term),如下方程所示,其中 L 为损失函数,J 为正则化项。 通常来说,正则化项往往是关于模型参数的 1- 范数或者 2- 范数,当然也有可能是这两者的某种结合,例如 sklearn 的逻辑回归中的弹性网正则化项,其中加入模型参数的 1- 范数的正则化也被称为
l
1
l1
l 1
l
2
l2
l 2
1
N
∑
i
=
1
N
L
(
y
i
,
f
(
x
i
)
)
+
λ
J
(
f
)
\frac{1}{N}\sum^{N}_{i=1}L(y_i,f(x_i))+\lambda J{(f)}
N 1 i = 1 ∑ N L ( y i , f ( x i )) + λ J ( f ) 为何需要正则化 正则化的过程比不复杂,但何时需要进行正则化呢? 一般来说,正则化核心的作用是缓解模型过拟合倾向 。 此外,由于加入正则化项后损失函数的形体发生了变化,因此也会影响损失函数的求解过程,在某些时候,加入了正则化项之后会让损失函数的求解变得更加高效。 如此前介绍的岭回归,其实就是在线性回归的损失函数基础上加入了 w 的 1- 范数,而 Lasso 则是加入了 w 的 2- 范数。并且,对于逻辑回归来说,如果加入
l
2
l2
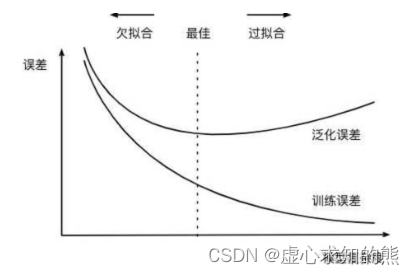
l 2 经验风险与结构风险 要讨论正则化是如何缓解过拟合倾向的问题,需要引入两个非常重要的概念:经验风险和结构风险。 在我们构建损失函数求最小值的过程,其实就是依据以往经验(也就是训练数据)追求风险最小(以往数据误差最小)的过程,而在给定一组参数后计算得出的损失函数的损失值,其实就是经验风险 。 而所谓结构风险 ,我们可以将其等价为模型复杂程度,模型越复杂,模型结构风险就越大。而正则化后的损失函数在进行最小值求解的过程中,其实是希望损失函数本身和正则化项都取得较小的值,即模型的经验风险和结构风险能够同时得到控制。 模型的经验风险需要被控制不难理解,因为我们希望模型能够尽可能的捕捉原始数据中的规律,但为何模型的结构风险也需要被控制? 核心原因在于,尽管在一定范围内模型复杂度增加能够有效提升模型性能,但模型过于复杂可能会导致另一个非常常见的问题——模型过拟合,但总的来说,一旦模型过拟合了,尽管模型经验风险在降低、但模型的泛化能力会下降。 因此,为了控制模型过拟合倾向,我们可以把模型结构风险纳入损失函数中一并考虑,当模型结构风险的增速高于损失值降低的收益时,我们就需要停止参数训练(迭代)。
同时要求模型性能和模型复杂度都在一个合理的范围内,其实等价于希望训练得到一个较小的模型同时具有较好的解释数据的能力(规律捕捉能力),这也符合奥卡姆剃刀原则。 此前我们曾深入探讨过关于机器学习建模有效性的问题,彼时我们得出的结论是当训练数据和新数据具有规律的一致性时,才能够进行建模,而只有挖掘出贯穿始终的规律(同时影响训练数据和新数据的规律),模型才能够进行有效预测。 不过,既然有些贯穿始终的全局规律,那就肯定存在一些只影响了一部分数据的局部规律。一般来说,由于全局规律影响数据较多,因此更容易被挖掘。 而局部规律只影响部分数据,因此更难被挖掘,因此从较为宽泛的角度来看,但伴随着模型性能提升,也是能够捕获很多局部规律的。 但是需要知道的是,局部规律对于新数据的预测并不能起到正面的作用,反而会影响预测结果,此时就出现模型过拟合现象。我们可以通过如下实例进行说明:
np. random. seed( 123 )
n_dots = 20
x = np. linspace( 0 , 1 , n_dots)
y = np. sqrt( x) + 0.2 * np. random. rand( n_dots) - 0.1
x
y
其中,x 是一个 0 到 1 之间等距分布 20 个点组成的 ndarray(多维数组),
y
=
x
+
r
y=\sqrt{x}+r
y = x
+ r 然后我们借助 numpy 的 polyfit 函数来进行多项式拟合,polyfit 函数会根据设置的多项式阶数,在给定数据的基础上利用最小二乘法进行拟合,并返回拟合后各阶系数。 同时,当系数计算完成后,我们还常用 ploy1d 函数逆向构造多项式方程,进而利用方程求解 y。 例如人为制造一个二阶多项式方程然后进行二阶拟合实验。 y0 = x ** 2
np. polyfit( x, y0, 2 )
能够得出多项式各阶系数,而根据该系数可用 ploy1d 逆向构造多项式方程。 p = np. poly1d( np. polyfit( x, y0, 2 ) )
print ( p)
能够看到多项式结构基本和原多项式保持一致,此时生成的 p 对象相当于是一个多项式方程,可通计算输入参数的多项式输出结果。 p( - 1 )
np. poly1d( np. polyfit( x, y, 3 ) )
接下来,进行多项式拟合。分别利用 1 阶 x 多项式、3 阶 x 多项式和 10 阶 x 多项式来拟合 y。并利用图形观察多项式的拟合度,首先我们可定义一个辅助画图函数,方便后续我们将图形画于一张画布中,进而方便观察。 def plot_polynomial_fit ( x, y, deg) :
p = np. poly1d( np. polyfit( x, y, deg) )
t = np. linspace( 0 , 1 , 200 )
plt. plot( x, y, 'ro' , t, p( t) , '-' , t, np. sqrt( t) , 'r--' )
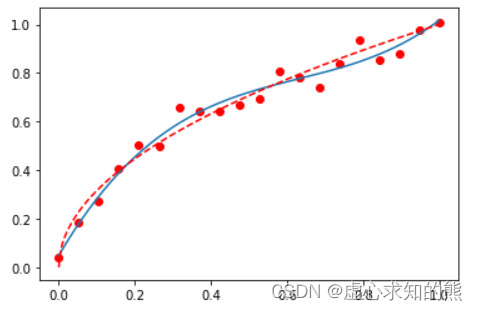
其中,t 为 [0,1] 中等距分布的 100 个点,而 p 是 deg 参数决定的多项式回归拟合方程,p(t) 即为拟合方程 x 输入 t 值时多项式输出结果,此处 plot_polynomial_fit 函数用于生成同时包含(x,y)原始值组成的红色点图、(t,p(t))组成的默认颜色的曲线图、(t,np.sqrt(t))构成的红色虚线曲线图。 测试 3 阶多项式拟合结果。 plot_polynomial_fit( x, y, 3 )
这里需要注意 (x,y) 组成的红色点图相当于带有噪声的二维空间数据分布,(t, p(t)) 构成的蓝色曲线相当于 3 阶多项式拟合原数据集((x, y)数据集)后的结果。 原始数据集包含的客观规律实际上是
y
=
x
y=\sqrt{x}
y = x
接下来,我们尝试将 1 阶拟合、3 阶拟合和 10 阶拟合绘制在一张图中。 plt. figure( figsize= ( 18 , 4 ) , dpi= 200 )
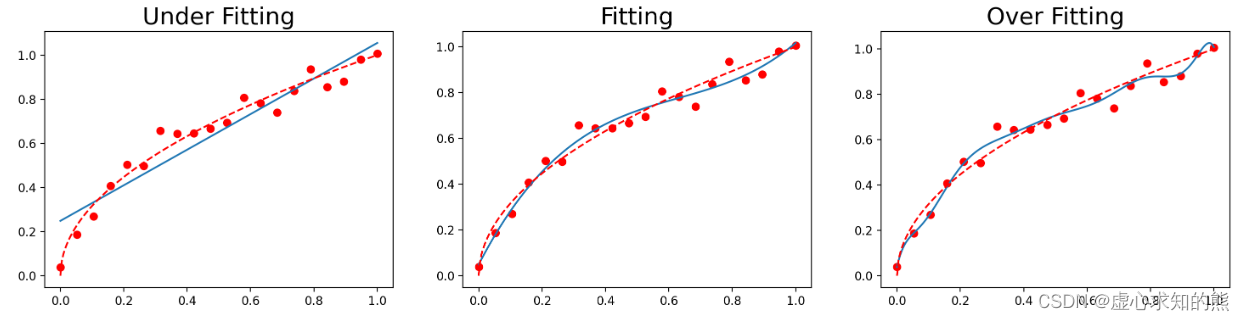
titles = [ 'Under Fitting' , 'Fitting' , 'Over Fitting' ]
for index, deg in enumerate ( [ 1 , 3 , 10 ] ) :
plt. subplot( 1 , 3 , index + 1 )
plot_polynomial_fit( x, y, deg)
plt. title( titles[ index] , fontsize= 20 )
根据最终的输出结果我们能够清楚的看到,1 阶多项式拟合的时候蓝色拟合曲线即无法捕捉数据集的分布规律,离数据集背后客观规律也很远,而三阶多项式在这两方面表现良好,十阶多项式则在数据集分布规律捕捉上表现良好,单同样偏离红色曲线较远。 此时一阶多项式实际上就是欠拟合,而十阶多项式则过分捕捉噪声数据的分布规律,而噪声之所以被称作噪声,是因为其分布本身毫无规律可言,或者其分布规律毫无价值(如此处噪声分布为均匀分布)。 因此就算十阶多项式在当前训练数据集上拟合度很高,但其捕捉到的无用规律无法推广到新的数据集上,因此该模型在测试数据集上执行过程将会有很大误差。即模型训练误差很小,但泛化误差很大。 接下来,我们尝试如何通过在模型中加入正则化项来缓解 10 阶多项式回归的过拟合倾向。 为了更加符合 sklearn 的建模风格、从而能够使用 sklearn 的诸多方法,我们将上述 10 阶多项式建模转化为一个等价的形式,即在原始数据中衍生出几个特征,分别是
x
2
x^2
x 2
x
3
x^3
x 3
x
10
x^{10}
x 10 x_l = [ ]
for i in range ( 10 ) :
x_temp = np. power( x, i+ 1 ) . reshape( - 1 , 1 )
x_l. append( x_temp)
X = np. concatenate( x_l, 1 )
X[ : 2 ]
y
当然,上述过程其实也就是比较简单的一种特征衍生方法,该方法也可以通过 sklearn 中的 PolynomialFeatures 类来进行实现。 from sklearn. preprocessing import PolynomialFeatures
PolynomialFeatures?
Name Description degree 最高阶数 interaction_only 是否只包含交叉项,交叉项指的是不同特征的乘结果 include_bias 是否只包含0阶计算结果、偏置项 计算模式 默认C模式,F模式能提高单独评估器计算效率,但会影响机器学习流中其他评估器
x. reshape( - 1 , 1 ) [ : 2 ]
PolynomialFeatures( degree= 2 ) . fit_transform( x. reshape( - 1 , 1 ) ) [ : 2 ]
PolynomialFeatures( degree= 2 , interaction_only= True ) . fit_transform( x. reshape( - 1 , 1 ) ) [ : 2 ]
poly = PolynomialFeatures( degree = 10 , include_bias= False )
poly. fit_transform( x. reshape( - 1 , 1 ) ) [ : 2 ]
接下来,围绕特征衍生后的新数据来进行线性回归建模。 from sklearn. linear_model import LinearRegression
lr = LinearRegression( )
lr. fit( X, y)
lr. coef_
from sklearn. metrics import mean_squared_error
mean_squared_error( lr. predict( X) , y)
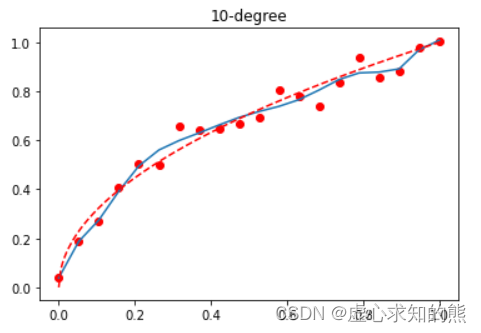
t = np. linspace( 0 , 1 , 200 )
plt. plot( x, y, 'ro' , x, lr. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
plt. title( '10-degree' )
接下来,我们尝试在线性回归的损失函数中引入正则化,来缓解 10 阶特征衍生后的过拟合问题。 根据 Lesson 3.3 的讨论我们知道,在线性回归中加入
l
2
l2
l 2
l
1
l1
l 1 因此,我们分别考虑围绕上述模型进行岭回归和 Lasso 的建模。
from sklearn. linear_model import Ridge, Lasso
Ridge?
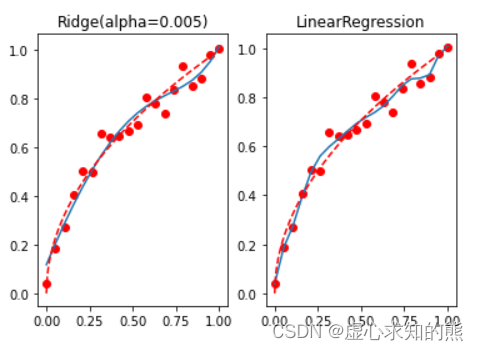
reg_rid = Ridge( alpha= 0.005 )
reg_rid. fit( X, y)
reg_rid. coef_
mean_squared_error( reg_rid. predict( X) , y)
t = np. linspace( 0 , 1 , 200 )
plt. subplot( 121 )
plt. plot( x, y, 'ro' , x, reg_rid. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
plt. title( 'Ridge(alpha=0.005)' )
plt. subplot( 122 )
plt. plot( x, y, 'ro' , x, lr. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
plt. title( 'LinearRegression' )
不难发现,
l
2
l2
l 2 Lasso?
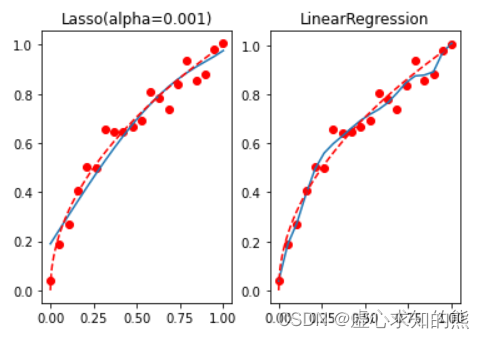
reg_las = Lasso( alpha= 0.001 )
reg_las. fit( X, y)
reg_las. coef_
mean_squared_error( reg_las. predict( X) , y)
t = np. linspace( 0 , 1 , 200 )
plt. subplot( 121 )
plt. plot( x, y, 'ro' , x, reg_las. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
plt. title( 'Lasso(alpha=0.001)' )
plt. subplot( 122 )
plt. plot( x, y, 'ro' , x, lr. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
plt. title( 'LinearRegression' )
我们发现,Lasso 的惩罚力度更强,并且迅速将一些参数清零,而这些被清零的参数,则代表对应的参数在实际建模过程中并不重要,从而达到特种重要性筛选的目的。 而在实际的建模过程中,
l
2
l2
l 2
l
1
l1
l 1 其实特征重要性和(线性方程中)特征对应系数大小并没有太大的关系,判断特种是否重要的核心还是在于观察抛弃某些特征后,建模结果是否会发生显著影响。 有上述过程,我们不难发现,
l
2
l2
l 2
l
1
l1
l 1
l
2
l2
l 2
l
1
l1
l 1 而特征重要的含义,其实是代表哪怕带入上述 3 个特征建模,依然能够达到带入所有特征建模的效果。我们可以通过下述实验进行验证:
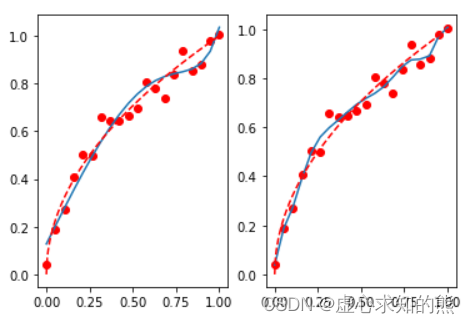
X_af = X[ : , [ 0 , 2 , 9 ] ]
lr_af = LinearRegression( )
lr_af. fit( X_af, y)
lr_af. coef_
mean_squared_error( lr_af. predict( X_af) , y)
lr_af. predict( X_af)
t = np. linspace( 0 , 1 , 200 )
plt. subplot( 121 )
plt. plot( x, y, 'ro' , x, lr_af. predict( X_af) , '-' , t, np. sqrt( t) , 'r--' )
plt. subplot( 122 )
plt. plot( x, y, 'ro' , x, lr. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
我们发现,哪怕删掉了 70% 的特征,最终建模结果仍然还是未收到太大的影响,从侧面也说明剩下 70% 的特征确实“不太重要”。 当然,在删除这些数据之后,模型过拟合的趋势略微有所好转,那如果我们继续加上
l
2
l2
l 2
reg_rid_af = Ridge( alpha= 0.05 )
reg_rid_af. fit( X_af, y)
reg_rid_af. coef_
mean_squared_error( reg_rid_af. predict( X_af) , y)
t = np. linspace( 0 , 1 , 200 )
plt. subplot( 121 )
plt. plot( x, y, 'ro' , x, reg_rid_af. predict( X_af) , '-' , t, np. sqrt( t) , 'r--' )
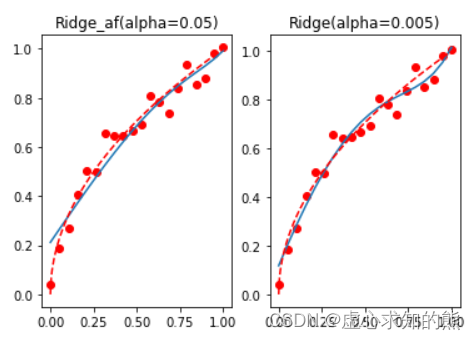
plt. title( 'Ridge_af(alpha=0.05)' )
plt. subplot( 122 )
plt. plot( x, y, 'ro' , x, reg_rid. predict( X) , '-' , t, np. sqrt( t) , 'r--' )
plt. title( 'Ridge(alpha=0.005)' )
不难发现,模型整体过拟合倾向被更进一步抑制,整体拟合效果较好。 此处虽然重点介绍关于
l
1
l1
l 1
l
2
l2
l 2 (1) 当模型效果(往往是线性模型)不佳时,可以考虑通过特征衍生的方式来进行数据的“增强”; (2) 如果出现过拟合趋势,则首先可以考虑进行不重要特征的筛选,过多的无关特征其实也会影响模型对于全局规律的判断,当然此时可以考虑使用
l
1
l1
l 1 (3) 对于过拟合趋势的抑制,仅仅踢出不重要特征还是不够的,对于线性方程类的模型来说,
l
2
l2
l 2 当然,除此以外,还有一些注意事项: (1) 首先,哪怕不进行特征筛选,
l
2
l2
l 2
l
2
l2
l 2 (2) 其次,上述参数的选取和过拟合倾向的判断,其实还是主观判断成分较多,一个更加严谨的流程是,先进行数据集的划分,然后选取更能表示模型泛化能力的评估指标,然后将特征提取(如果要做的话)、
l
2
l2
l 2 (3) 最后,需要强调的是,并非所有模型都需要/可以通过正则化来进行过拟合修正,典型的可以通过正则化来进行过拟合倾向修正的模型主要有线性回归、逻辑回归、LDA、SVM 以及一些 PCA 衍生算法(如 SparsePCA)。而树模型则不用通过正则化来进行过拟合修正。 在补充了关于正则化的相关内容之后,接下来,我们来详细讨论关于逻辑回归的参数解释。
首先,先对上述逻辑回归的说明文档中的内容进行解释。 sklearn 中逻辑回归损失函数形态 在了解了正则化的相关内容后,接下来我们观察 sklearn 官网中给出的逻辑回归加入正则化后的损失函数表达式,我们发现该表达式和此前我们推到的交叉熵损失函数的表达式还是略有差异,核心原因是 sklearn 在二分类的时候默认两个类别的标签取值为 -1 和 1,而不是 0 和 1。 我们曾在 Lesson 4.2 中进行了非常详细的关于逻辑回归损失函数的推导,此处的数学推导,我们只需将 Lesson 4.2 中公式当中的 y 的取值改为 -1 和 1 即可。 正则化后损失函数表达式 相比原始损失函数,正则化后的损失函数有两处发生了变化,其一是在原损失函数基础上乘以了系数 C,其二则是加入了正则化项。 其中系数 C 也是超参数,需要人工输入,用于调整经验风险部分和结构风险部分的权重,C 越大,经验风险部分权重越大,反之结构风险部分权重越大。 此外,在
l
2
l2
l 2
w
T
w
2
\frac{w^Tw}{2}
2 w T w 另外,sklearn 中还提供了弹性网正则化方法,其实是通过
ρ
ρ
ρ
l
1
l1
l 1
l
2
l2
l 2 不过代价是增加了一个超参数
ρ
ρ
ρ 在上述的一系列基础内容铺垫之后,接下来我们对逻辑回归评估器中的参数进行详细解释: LogisticRegression?
参数 解释 penalty 正则化项 dual 是否求解对偶问题* tol 迭代停止条件:两轮迭代损失值差值小于tol时,停止迭代 C 经验风险和结构风险在损失函数中的权重 fit_intercept 线性方程中是否包含截距项 intercept_scaling 相当于此前讨论的特征最后一列全为1的列,当使用liblinear求解参数时用于捕获截距 class_weight 各类样本权重* random_state 随机数种子 solver 损失函数求解方法* max_iter 求解参数时最大迭代次数,迭代过程满足max_iter或tol其一即停止迭代 multi_class 多分类问题时求解方法* verbose 是否输出任务进程 warm_start 是否使用上次训练结果作为本次运行初始参数 l1_ratio 当采用弹性网正则化时,
l
1
l1
l 1
ρ
\rho
ρ
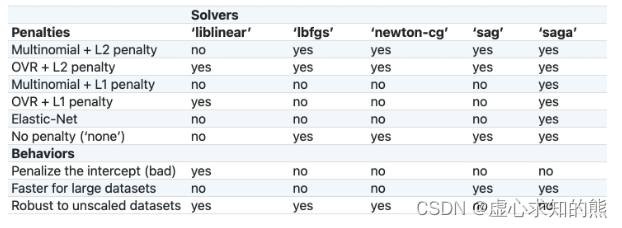
dual:是否求解对偶问题 对偶问题是约束条件相反、求解方向也相反的问题,当数据集过小而特征较多时,求解对偶问题能一定程度降低运算复杂度,其他情况建议保留默认参数取值。 class_weight:各类样本权重 class_weight 其实代表各类样本在进行损失函数计算时的数值权重。 例如假设一个二分类问题,0、1 两类的样本比例是 2:1,此时可以输入一个字典类型对象用于说明两类样本在进行损失值计算时的权重。 例如输入 {0:1, 1:3},则代表 1 类样本的每一条数据在进行损失函数值的计算时都会在原始数值上*3。 而当我们将该参数选为 balanced 时,则会自动将这个比例调整为真实样本比例的反比,以达到平衡的效果。 solver:损失函数求解方法 其实除了最小二乘法和梯度下降以外,还有非常多的关于损失函数的求解方法,而选择损失函数的参数,就是solver参数。 而当前损失函数到底采用何种优化方法进行求解,其实最终目的是希望能够更快(计算效率更高)更好(准确性更高)的来进行求解,而硬性的约束条件是损失函数的形态,此外则是用户自行选择的空间。 这里给出何时应该用哪种 solver 的参考列表,也就是官网给出的列表:
逻辑回归可选的优化方法包括: (1) liblinear,这是一种坐标轴下降法,并且该软件包中大多数算法都有 C++ 编写,运行速度很快,支持 OVR+L1 或 OVR+L2; (2) lbfgs,全称是 L-BFGS,牛顿法的一种改进算法(一种拟牛顿法),适用于小型数据集,并且支持 MVM+L2、OVR+L2 以及不带惩罚项的情况; (3) newton-cg,同样也是一种拟牛顿法,和 lbfgs 适用情况相同; (4) sag,随机平均梯度下降,随机梯度下降的改进版,类似动量法,会在下一轮随机梯度下降开始之前保留一些上一轮的梯度,从而为整个迭代过程增加惯性,除了不支持 L1 正则化的损失函数求解以外(包括弹性网正则化)其他所有损失函数的求解; (5) saga,sag 的改进版,修改了梯度惯性的计算方法,使得其支持所有情况下逻辑回归的损失函数求解; 对于逻辑回归来说,求解损失函数的硬性约束其实就是多分类问题时采用的策略以及加入的惩罚项,所以大多数情况,我们会优先根据多分类问题的策略及惩项来选取优化算法,其次,如果有多个算法可选,那么我们可以根据其他情况来进行求解器的选取,如: (1) Penalize the intercept (bad),如果要对截距项也进行惩罚,那只能选取 liblinear; (2) Faster for large datasets,如果需要对海量数据进行快速处理,则可以选取 sag 和 saga; (3) Robust to unscaled datasets,如果未对数据集进行标准化,但希望维持数据集的鲁棒性(迭代平稳高效),则可以考虑使用 liblinear、lbfgs 和 newton-cg 三种求解方法。 multi_class:选用何种方法进行多分类问题求解 可选 OVR 和 MVM,当然默认情况是 auto,此时模型会优先根据惩罚项和 solver 选择 OVR 还是 MVM,但一般来说,MVM 效果会好于 OVR。