sql优化,如何进行索引优化
文章目录
- 一、数据库优化
- 3. 索引如何调优
- 什么是索引
- 索引调优的核心目标
- 常见的索引类型与适用场景
- 单列索引
- 复合索引
- 唯一索引
- 全文索引
- 覆盖索引(索引覆盖查询)
- 索引调优的核心策略
- 1. 索引字段的选择
- 2. 避免索引失效
- 3. 控制索引数量
- 4. 使用覆盖索引
- 实战案例--优化用户表查询
- 实战案例--分页查询优化
- 延迟游标分页
引言: 整个专栏包括以下几个部分: 数据库优化、 接口性能优化、 Java底层数据性能调优、 中间件相关性能问题定位 以及 多线程高并发设计 等内容。
下面开启 数据库优化 部分的 第四篇文章。点击可查看第一篇文章
一、数据库优化
3. 索引如何调优
在数据库性能优化的世界里,索引绝对是“顶流”。一句话概括:索引用得好,查询快到飞起;用得不好,可能还不如不用。而实际工作中,面对慢 SQL 或者卡顿时,第一反应就是“上个索引试试”。结果呢?索引加上了,性能却不见好,有时候甚至更慢。
那么,索引到底该如何设计?如何调优才能真正发挥它的威力?----> 从索引的本质开始,一步步剖析索引调优的核心思路和常见问题。
什么是索引
1、简单来说,索引就是为了加速查询而创建的数据结构。可以把它想象成一本书的目录,假如一本书有1000 页,如果没有目录,你想找某个关键词,就得从头翻到尾。而有了目录后,你可以快速定位到关键词所在的页数,这就是索引的作用。
2、在数据库中,索引的实现通常是基于 B+树 或 哈希表 的数据结构,能够快速定位目标记录,减少查询扫描的范围。
索引调优的核心目标
目标:让查询尽量少读、不做无用功
什么意思?----> 也就是通过索引,快速缩小查询范围,减少数据库需要处理的数据量。比如,原本一条 SQL 需要扫描 1000 万条记录,有了索引后,可能只需扫描几十条甚至一条。
但要注意:索引不是越多越好,也不是随便建就有用。在实际工作中,很多性能问题反而是因为索引用错、用滥导致的。所以,索引调优的重点是在对的地方建对的索引。
常见的索引类型与适用场景
在不同场景下,我们需要选择不同类型的索引。了解索引类型,是调优的第一步。
单列索引
单列索引是最常见的索引类型,只针对一个字段进行优化。比如:对用户表的 user_id 字段建单列索引:
create index idx_user_id(这个是索引名字,可自定义) on users (user_id);
- 适应场景:针对单字段查询,如:
SELECT * FROM users WHERE user_id = 123; - 不足:当查询涉及多个字段时,单列索引可能无法发挥作用
复合索引
复合索引是对多个字段一起建立的索引,查询时可以同时利用这些字段:
create index idx_user_id_status on users (user_id, status);
适应场景:
-
查询中有多个条件时:
SELECT * FROM users WHERE user_id = 123 AND status = 1; -
涉及排序或范围查询的多字段场景:
SELECT * FROM users WHERE user_id = 123 ORDER BY status;
注意: 复合索引的字段顺序很重要,查询条件要匹配索引的前缀。例如,上述索引可以加速 user_id 的查询,但无法单独加速 status 的查询。
什么意思?----> 在复合索引中,字段顺序确实重要,主要体现在 索引的前缀匹配原则。简单来说:索引的存储结构是按照字段顺序组织的,查询时必须匹配索引的最左边字段,否则索引可能无法生效。
① 复合索引的结构
假设在 user 表上创建了一个复合索引:CREATE INDEX idx_user_name_age_city ON user(name, age, city); 数据库会按 (name, age, city) 这个顺序建立 B+树索引,存储数据时索引结构大致如下:
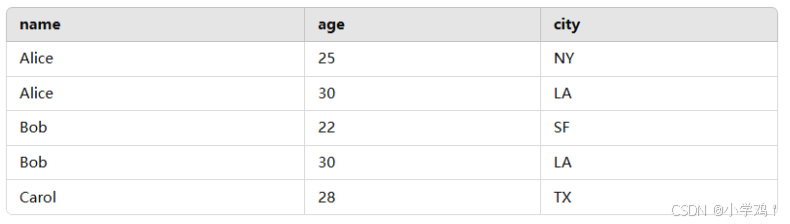
索引会先按 name 排序,然后在 name 相同的情况下按 age 排序,再在 age 相同时按 city 排序。
② 前缀匹配原则
索引查询时,必须匹配最左边的字段,否则索引无法有效利用。比如:
✅ 有效使用索引的查询:
SELECT * FROM user WHERE name = 'Alice'; -- ✅ 使用索引
SELECT * FROM user WHERE name = 'Alice' AND age = 25; -- ✅ 使用索引
SELECT * FROM user WHERE name = 'Alice' AND age = 25 AND city = 'NY'; -- ✅ 使用索引
SELECT * FROM user WHERE name = 'Alice' AND city = 'NY'; -- ✅ 仍然可以用索引(只要 name 在 WH
❌ 不能有效使用索引的查询:
SELECT * FROM user WHERE age = 25; -- ❌ 不能使用索引(跳过了 name)
SELECT * FROM user WHERE city = 'NY'; -- ❌ 不能使用索引(跳过了 name 和 age)
SELECT * FROM user WHERE age = 25 AND city = 'NY'; -- ❌ 不能使用索引(跳过了 name)
如果查询 不包含最左字段 name,那么索引会被数据库忽略,可能会导致全表扫描。
③ 范围查询的影响
如果查询条件中有范围查询(>、<、between),索引的后续字段可能无法被有效利用。
SELECT * FROM user WHERE name = 'Alice' AND age > 25 AND city = 'NY';
在这个查询中:
name = 'Alice'会用到索引age > 25仍然可以用索引(但只用于定位age > 25的起始点)city = 'NY'可能无法使用索引,因为age是范围查询,索引的后续字段city可能不会被 B+ 树有效利用。
④ 如何设计索引字段顺序
- 最常用于查询过滤的字段放在最前面(如 where 语句中最常出现的字段)
- 区分度高的字段放前面,减少扫描的行数,例如 name 比 gender 更能缩小范围
- 避免在前面使用范围查询,否则后续字段的索引效果会受限
唯一索引
唯一索引保证索引字段的值是唯一的(类似主键约束),适用于唯一性校验(如:用户邮箱、身份证号)
create unique index idx_email on users (email);
全文索引
全文索引是针对文本字段进行快速全文检索的一种索引方式,适用于模糊匹配和关键字搜索。
-- 示例:
select * from articles where match(content) against('Java');
覆盖索引(索引覆盖查询)
如果查询的数据正好包含在索引中,数据库可以直接从索引中获取数据,而不需要回表查询。
-- 示例:
SELECT user_id, status FROM users WHERE user_id = 123;
如果复合索引idx_user_id_status 覆盖了 user_id 和 status,则无需访问表的实际数据。
索引调优的核心策略
知道了索引类型后,接下来就是如何用好索引。索引调优的过程,实际上是不断减少全表扫描、减少多余计算的过程。
1. 索引字段的选择
并不是所有字段都适合建索引,在选择索引字段时,可以遵循以下原则:
-
经常作为查询条件的字段: 如果某个字段在 where 条件中经常出现,那么它是索引的候选字段
-- user_id 字段显然是查询的过滤条件,可以考虑为其创建索引 select * from orders where user_id=123; -
经常用于排序或分组的字段: 如果查询中经常对某个字段排序、分组,也可以为其建立索引。
-- 在这种情况下,可以对user_id和order_time建立复合索引 select * from orders where user_id=123 order by order_time desc; -
过滤效果好的字段: 如果某个字段的值非常稀疏(比如用户性别 M/F),建索引的效果会很差,因为过滤效果不好,而像用户 ID 这种高基数字段,建索引更有价值。
2. 避免索引失效
即使有索引,写法不当也可能导致索引失效。比如:
-
对索引字段进行函数或运算:
-- 错误: SELECT * FROM users WHERE DATE(created_at) = '2023-01-01'; -- 优化: SELECT * FROM users WHERE created_at >= '2023-01-01 00:00:00' AND created_at < '2023-01-02 00:00:00'; -
字段类型不一致:
-- 错误: SELECT * FROM users WHERE user_id = '123'; 这里user_id是INT类型,但查询时传入了字符串,导致隐式类型转换,索引失效。 -- 优化: SELECT * FROM users WHERE user_id = 123; -
模糊查询的开头是通配符:
-- 错误: SELECT * FROM users WHERE name LIKE '%Jack'; 这种写法无法使用索引。 --优化: SELECT * FROM users WHERE name LIKE 'Jack%';
3. 控制索引数量
索引并不是越多越好,过多的索引会带来以下问题:
- 占用存储空间。
- 增加写入和更新的开销。
例:如果orders表中有3个字段都建了索引:
CREATE INDEX idx_user_id ON orders (user_id);
CREATE INDEX idx_order_status ON orders (order_status);
CREATE INDEX idx_order_time ON orders (order_time);
假如插入一条数据,这条数据不仅需要写入表,还要更新 3 个索引。因此,要根据查询场景合理设计索引,避免冗余。
4. 使用覆盖索引
覆盖索引是提升查询性能的绝佳方式。通过将查询所需的字段全部放入索引中,避免回表操作:
SELECT user_id, order_status FROM orders WHERE user_id = 123;
如果索引是:那么查询的数据直接在索引中即可完成,性能会大幅提升。
CREATE INDEX idx_user_status ON orders (user_id, order_status);
实战案例–优化用户表查询
问题:用户表 users 有 1000 万条数据,查询某个用户的最近登录时间,很慢:
SELECT last_login FROM users WHERE user_id = 123;
分析:查询条件是user_id,但 last_login 字段不在索引中,并且数据量大,全表扫描性能差。
解决:创建一个覆盖索引:
CREATE INDEX idx_user_last_login ON users (user_id, last_login);
实战案例–分页查询优化
问题:订单表 orders 有 5000 万条记录,分页查询时,很慢:
SELECT * FROM orders ORDER BY order_time DESC LIMIT 100000, 10;
分析:
- LIMIT 偏移量过大(100,000):数据库需要扫描前 100,010 条记录,然后丢弃前 100,000 条数据,只返回 10 条,导致大量无用扫描。
- 排序代价高:如果
order_time没有合适的索引,数据库可能需要在ORDER BY order_time DESC过程中进行 文件排序,影响查询性能。、 - 当
OFFSET变得越来越大,例如LIMIT 1000000, 10,查询会变得 极慢,甚至可能导致数据库性能下降。
解决:延迟游标分页
SELECT * FROM orders WHERE order_time < '2023-01-01 12:00:00'
ORDER BY order_time DESC LIMIT 10;
怎么实现分页的?
每次查询时,记录 上一页的最后一条 order_time,然后用它作为 where 条件:
第一页:
SELECT * FROM orders ORDER BY order_time DESC LIMIT 10;
假设返回的最后一条记录
order_time = '2023-01-01 12:00:00'
第二页:
SELECT * FROM orders WHERE order_time < '2023-01-01 12:00:00'
ORDER BY order_time DESC LIMIT 10;
假设返回的最后一条记录
order_time = '2023-01-01 11:50:00'
第三页:
SELECT * FROM orders WHERE order_time < '2023-01-01 11:50:00'
ORDER BY order_time DESC LIMIT 10;
这样查询就能精准利用索引,不会扫描无关数据!
延迟游标分页
1、延迟游标分页的概念:
- 延迟游标分页:是一种 利用索引加速分页 的技术,避免 limit offset 方式造成的深度分页性能问题。
- 核心思想:不使用 offset 跳过数据,而是利用上一页的最后一条数据作为游标,从该数据开始查询下一页。
2、开发示例:
@Mapper
public interface OrderMapper {
// 获取第一页数据
@Select("SELECT * FROM orders ORDER BY order_time DESC LIMIT #{limit}")
List<Order> getFirstPage(@Param("limit") int limit);
// 获取下一页数据
@Select("SELECT * FROM orders WHERE order_time < #{lastOrderTime} ORDER BY order_time DESC LIMIT #{limit}")
List<Order> getNextPage(@Param("lastOrderTime") LocalDateTime lastOrderTime, @Param("limit") int limit);
}
前端传递上一页最后一条记录的 order_time,后端用 WHERE order_time < ? 查询下一页数据。
3、实际开发中的应用:订单列表、用户消息列表、文章评论、直播弹幕历史记录、社交媒体帖子流
4、场景:
| 适用 | 不适用 |
|---|---|
| 大数据量的分页查询(如千万级订单、日志、评论) | 需要跳转到指定页 |
| 基于时间、ID 等可排序字段的分页 | 需要计算总页数 |
| 需要无限滚动(如朋友圈、商品列表) |
后面会讲解索引如何调优,还会有更多文章,记得点赞订阅哦!!!。